
Perplexica
Perplexica is an AI-powered search engine. It is an Open source alternative to Perplexity AI
Stars: 25972

Perplexica is an open-source AI-powered search engine that utilizes advanced machine learning algorithms to provide clear answers with sources cited. It offers various modes like Copilot Mode, Normal Mode, and Focus Modes for specific types of questions. Perplexica ensures up-to-date information by using SearxNG metasearch engine. It also features image and video search capabilities and upcoming features include finalizing Copilot Mode and adding Discover and History Saving features.
README:

- Overview
- Preview
- Features
- Installation
- Using as a Search Engine
- Using Perplexica's API
- Expose Perplexica to a network
- One-Click Deployment
- Upcoming Features
- Support Us
- Contribution
- Help and Support
Perplexica is an open-source AI-powered searching tool or an AI-powered search engine that goes deep into the internet to find answers. Inspired by Perplexity AI, it's an open-source option that not just searches the web but understands your questions. It uses advanced machine learning algorithms like similarity searching and embeddings to refine results and provides clear answers with sources cited.
Using SearxNG to stay current and fully open source, Perplexica ensures you always get the most up-to-date information without compromising your privacy.
Want to know more about its architecture and how it works? You can read it here.

- Local LLMs: You can utilize local LLMs such as Qwen, DeepSeek, Llama, and Mistral.
-
Two Main Modes:
- Copilot Mode: (In development) Boosts search by generating different queries to find more relevant internet sources. Like normal search instead of just using the context by SearxNG, it visits the top matches and tries to find relevant sources to the user's query directly from the page.
- Normal Mode: Processes your query and performs a web search.
-
Focus Modes: Special modes to better answer specific types of questions. Perplexica currently has 6 focus modes:
- All Mode: Searches the entire web to find the best results.
- Writing Assistant Mode: Helpful for writing tasks that do not require searching the web.
- Academic Search Mode: Finds articles and papers, ideal for academic research.
- YouTube Search Mode: Finds YouTube videos based on the search query.
- Wolfram Alpha Search Mode: Answers queries that need calculations or data analysis using Wolfram Alpha.
- Reddit Search Mode: Searches Reddit for discussions and opinions related to the query.
- Current Information: Some search tools might give you outdated info because they use data from crawling bots and convert them into embeddings and store them in a index. Unlike them, Perplexica uses SearxNG, a metasearch engine to get the results and rerank and get the most relevant source out of it, ensuring you always get the latest information without the overhead of daily data updates.
- API: Integrate Perplexica into your existing applications and make use of its capibilities.
It has many more features like image and video search. Some of the planned features are mentioned in upcoming features.
There are mainly 2 ways of installing Perplexica - With Docker, Without Docker. Using Docker is highly recommended.
-
Ensure Docker is installed and running on your system.
-
Clone the Perplexica repository:
git clone https://github.com/ItzCrazyKns/Perplexica.git
-
After cloning, navigate to the directory containing the project files.
-
Rename the
sample.config.tomlfile toconfig.toml. For Docker setups, you need only fill in the following fields:-
OPENAI: Your OpenAI API key. You only need to fill this if you wish to use OpenAI's models. -
CUSTOM_OPENAI: Your OpenAI-API-compliant local server URL, model name, and API key. You should run your local server with host set to0.0.0.0, take note of which port number it is running on, and then use that port number to setAPI_URL = http://host.docker.internal:PORT_NUMBER. You must specify the model name, such asMODEL_NAME = "unsloth/DeepSeek-R1-0528-Qwen3-8B-GGUF:Q4_K_XL". Finally, setAPI_KEYto the appropriate value. If you have not defined an API key, just put anything you want in-between the quotation marks:API_KEY = "whatever-you-want-but-not-blank"You only need to configure these settings if you want to use a local OpenAI-compliant server, such as Llama.cpp'sllama-server. -
OLLAMA: Your Ollama API URL. You should enter it ashttp://host.docker.internal:PORT_NUMBER. If you installed Ollama on port 11434, usehttp://host.docker.internal:11434. For other ports, adjust accordingly. You need to fill this if you wish to use Ollama's models instead of OpenAI's. -
LEMONADE: Your Lemonade API URL. Since Lemonade runs directly on your local machine (not in Docker), you should enter it ashttp://host.docker.internal:PORT_NUMBER. If you installed Lemonade on port 8000, usehttp://host.docker.internal:8000. For other ports, adjust accordingly. You need to fill this if you wish to use Lemonade's models. -
GROQ: Your Groq API key. You only need to fill this if you wish to use Groq's hosted models.` -
ANTHROPIC: Your Anthropic API key. You only need to fill this if you wish to use Anthropic models. -
Gemini: Your Gemini API key. You only need to fill this if you wish to use Google's models. -
DEEPSEEK: Your Deepseek API key. Only needed if you want Deepseek models. -
AIMLAPI: Your AI/ML API key. Only needed if you want to use AI/ML API models and embeddings.Note: You can change these after starting Perplexica from the settings dialog.
-
SIMILARITY_MEASURE: The similarity measure to use (This is filled by default; you can leave it as is if you are unsure about it.)
-
-
Ensure you are in the directory containing the
docker-compose.yamlfile and execute:docker compose up -d
-
Wait a few minutes for the setup to complete. You can access Perplexica at http://localhost:3000 in your web browser.
Note: After the containers are built, you can start Perplexica directly from Docker without having to open a terminal.
- Install SearXNG and allow
JSONformat in the SearXNG settings. - Clone the repository and rename the
sample.config.tomlfile toconfig.tomlin the root directory. Ensure you complete all required fields in this file. - After populating the configuration run
npm i. - Install the dependencies and then execute
npm run build. - Finally, start the app by running
npm run start
Note: Using Docker is recommended as it simplifies the setup process, especially for managing environment variables and dependencies.
See the installation documentation for more information like updating, etc.
If Perplexica tells you that you haven't configured any chat model providers, ensure that:
- Your server is running on
0.0.0.0(not127.0.0.1) and on the same port you put in the API URL. - You have specified the correct model name loaded by your local LLM server.
- You have specified the correct API key, or if one is not defined, you have put something in the API key field and not left it empty.
If you're encountering an Ollama connection error, it is likely due to the backend being unable to connect to Ollama's API. To fix this issue you can:
-
Check your Ollama API URL: Ensure that the API URL is correctly set in the settings menu.
-
Update API URL Based on OS:
-
Windows: Use
http://host.docker.internal:11434 -
Mac: Use
http://host.docker.internal:11434 -
Linux: Use
http://<private_ip_of_host>:11434
Adjust the port number if you're using a different one.
-
Windows: Use
-
Linux Users - Expose Ollama to Network:
-
Inside
/etc/systemd/system/ollama.service, you need to addEnvironment="OLLAMA_HOST=0.0.0.0:11434". (Change the port number if you are using a different one.) Then reload the systemd manager configuration withsystemctl daemon-reload, and restart Ollama bysystemctl restart ollama. For more information see Ollama docs -
Ensure that the port (default is 11434) is not blocked by your firewall.
-
If you're encountering a Lemonade connection error, it is likely due to the backend being unable to connect to Lemonade's API. To fix this issue you can:
-
Check your Lemonade API URL: Ensure that the API URL is correctly set in the settings menu.
-
Update API URL Based on OS:
-
Windows: Use
http://host.docker.internal:8000 -
Mac: Use
http://host.docker.internal:8000 -
Linux: Use
http://<private_ip_of_host>:8000
Adjust the port number if you're using a different one.
-
Windows: Use
-
Ensure Lemonade Server is Running:
- Make sure your Lemonade server is running and accessible on the configured port (default is 8000).
- Verify that Lemonade is configured to accept connections from all interfaces (
0.0.0.0), not just localhost (127.0.0.1). - Ensure that the port (default is 8000) is not blocked by your firewall.
If you wish to use Perplexica as an alternative to traditional search engines like Google or Bing, or if you want to add a shortcut for quick access from your browser's search bar, follow these steps:
- Open your browser's settings.
- Navigate to the 'Search Engines' section.
- Add a new site search with the following URL:
http://localhost:3000/?q=%s. Replacelocalhostwith your IP address or domain name, and3000with the port number if Perplexica is not hosted locally. - Click the add button. Now, you can use Perplexica directly from your browser's search bar.
Perplexica also provides an API for developers looking to integrate its powerful search engine into their own applications. You can run searches, use multiple models and get answers to your queries.
For more details, check out the full documentation here.
Perplexica runs on Next.js and handles all API requests. It works right away on the same network and stays accessible even with port forwarding.




- [x] Add settings page
- [x] Adding support for local LLMs
- [x] History Saving features
- [x] Introducing various Focus Modes
- [x] Adding API support
- [x] Adding Discover
- [ ] Finalizing Copilot Mode
If you find Perplexica useful, consider giving us a star on GitHub. This helps more people discover Perplexica and supports the development of new features. Your support is greatly appreciated.
We also accept donations to help sustain our project. If you would like to contribute, you can use the following options to donate. Thank you for your support!
| Ethereum |
|---|
Address: 0xB025a84b2F269570Eb8D4b05DEdaA41D8525B6DD
|
Perplexica is built on the idea that AI and large language models should be easy for everyone to use. If you find bugs or have ideas, please share them in via GitHub Issues. For more information on contributing to Perplexica you can read the CONTRIBUTING.md file to learn more about Perplexica and how you can contribute to it.
If you have any questions or feedback, please feel free to reach out to us. You can create an issue on GitHub or join our Discord server. There, you can connect with other users, share your experiences and reviews, and receive more personalized help. Click here to join the Discord server. To discuss matters outside of regular support, feel free to contact me on Discord at itzcrazykns.
Thank you for exploring Perplexica, the AI-powered search engine designed to enhance your search experience. We are constantly working to improve Perplexica and expand its capabilities. We value your feedback and contributions which help us make Perplexica even better. Don't forget to check back for updates and new features!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Perplexica
Similar Open Source Tools
Perplexica
Perplexica is an open-source AI-powered search engine that utilizes advanced machine learning algorithms to provide clear answers with sources cited. It offers various modes like Copilot Mode, Normal Mode, and Focus Modes for specific types of questions. Perplexica ensures up-to-date information by using SearxNG metasearch engine. It also features image and video search capabilities and upcoming features include finalizing Copilot Mode and adding Discover and History Saving features.
CyberScraper-2077
CyberScraper 2077 is an advanced web scraping tool powered by AI, designed to extract data from websites with precision and style. It offers a user-friendly interface, supports multiple data export formats, operates in stealth mode to avoid detection, and promises lightning-fast scraping. The tool respects ethical scraping practices, including robots.txt and site policies. With upcoming features like proxy support and page navigation, CyberScraper 2077 is a futuristic solution for data extraction in the digital realm.
MiniSearch
MiniSearch is a minimalist search engine with integrated browser-based AI. It is privacy-focused, easy to use, cross-platform, integrated, time-saving, efficient, optimized, and open-source. MiniSearch can be used for a variety of tasks, including searching the web, finding files on your computer, and getting answers to questions. It is a great tool for anyone who wants a fast, private, and easy-to-use search engine.
OpenCopilot
OpenCopilot allows you to have your own product's AI copilot. It integrates with your underlying APIs and can execute API calls whenever needed. It uses LLMs to determine if the user's request requires calling an API endpoint. Then, it decides which endpoint to call and passes the appropriate payload based on the given API definition.

cognita
Cognita is an open-source framework to organize your RAG codebase along with a frontend to play around with different RAG customizations. It provides a simple way to organize your codebase so that it becomes easy to test it locally while also being able to deploy it in a production ready environment. The key issues that arise while productionizing RAG system from a Jupyter Notebook are: 1. **Chunking and Embedding Job** : The chunking and embedding code usually needs to be abstracted out and deployed as a job. Sometimes the job will need to run on a schedule or be trigerred via an event to keep the data updated. 2. **Query Service** : The code that generates the answer from the query needs to be wrapped up in a api server like FastAPI and should be deployed as a service. This service should be able to handle multiple queries at the same time and also autoscale with higher traffic. 3. **LLM / Embedding Model Deployment** : Often times, if we are using open-source models, we load the model in the Jupyter notebook. This will need to be hosted as a separate service in production and model will need to be called as an API. 4. **Vector DB deployment** : Most testing happens on vector DBs in memory or on disk. However, in production, the DBs need to be deployed in a more scalable and reliable way. Cognita makes it really easy to customize and experiment everything about a RAG system and still be able to deploy it in a good way. It also ships with a UI that makes it easier to try out different RAG configurations and see the results in real time. You can use it locally or with/without using any Truefoundry components. However, using Truefoundry components makes it easier to test different models and deploy the system in a scalable way. Cognita allows you to host multiple RAG systems using one app. ### Advantages of using Cognita are: 1. A central reusable repository of parsers, loaders, embedders and retrievers. 2. Ability for non-technical users to play with UI - Upload documents and perform QnA using modules built by the development team. 3. Fully API driven - which allows integration with other systems. > If you use Cognita with Truefoundry AI Gateway, you can get logging, metrics and feedback mechanism for your user queries. ### Features: 1. Support for multiple document retrievers that use `Similarity Search`, `Query Decompostion`, `Document Reranking`, etc 2. Support for SOTA OpenSource embeddings and reranking from `mixedbread-ai` 3. Support for using LLMs using `Ollama` 4. Support for incremental indexing that ingests entire documents in batches (reduces compute burden), keeps track of already indexed documents and prevents re-indexing of those docs.
open-source-slack-ai
This repository provides a ready-to-run basic Slack AI solution that allows users to summarize threads and channels using OpenAI. Users can generate thread summaries, channel overviews, channel summaries since a specific time, and full channel summaries. The tool is powered by GPT-3.5-Turbo and an ensemble of NLP models. It requires Python 3.8 or higher, an OpenAI API key, Slack App with associated API tokens, Poetry package manager, and ngrok for local development. Users can customize channel and thread summaries, run tests with coverage using pytest, and contribute to the project for future enhancements.
SeaGOAT
SeaGOAT is a local search tool that leverages vector embeddings to enable you to search your codebase semantically. It is designed to work on Linux, macOS, and Windows and can process files in various formats, including text, Markdown, Python, C, C++, TypeScript, JavaScript, HTML, Go, Java, PHP, and Ruby. SeaGOAT uses a vector database called ChromaDB and a local vector embedding engine to provide fast and accurate search results. It also supports regular expression/keyword-based matches. SeaGOAT is open-source and licensed under an open-source license, and users are welcome to examine the source code, raise concerns, or create pull requests to fix problems.
testzeus-hercules
Hercules is the world’s first open-source testing agent designed to handle the toughest testing tasks for modern web applications. It turns simple Gherkin steps into fully automated end-to-end tests, making testing simple, reliable, and efficient. Hercules adapts to various platforms like Salesforce and is suitable for CI/CD pipelines. It aims to democratize and disrupt test automation, making top-tier testing accessible to everyone. The tool is transparent, reliable, and community-driven, empowering teams to deliver better software. Hercules offers multiple ways to get started, including using PyPI package, Docker, or building and running from source code. It supports various AI models, provides detailed installation and usage instructions, and integrates with Nuclei for security testing and WCAG for accessibility testing. The tool is production-ready, open core, and open source, with plans for enhanced LLM support, advanced tooling, improved DOM distillation, community contributions, extensive documentation, and a bounty program.
OrionChat
Orion is a web-based chat interface that simplifies interactions with multiple AI model providers. It provides a unified platform for chatting and exploring various large language models (LLMs) such as Ollama, OpenAI (GPT model), Cohere (Command-r models), Google (Gemini models), Anthropic (Claude models), Groq Inc., Cerebras, and SambaNova. Users can easily navigate and assess different AI models through an intuitive, user-friendly interface. Orion offers features like browser-based access, code execution with Google Gemini, text-to-speech (TTS), speech-to-text (STT), seamless integration with multiple AI models, customizable system prompts, language translation tasks, document uploads for analysis, and more. API keys are stored locally, and requests are sent directly to official providers' APIs without external proxies.

airbyte_serverless
AirbyteServerless is a lightweight tool designed to simplify the management of Airbyte connectors. It offers a serverless mode for running connectors, allowing users to easily move data from any source to their data warehouse. Unlike the full Airbyte-Open-Source-Platform, AirbyteServerless focuses solely on the Extract-Load process without a UI, database, or transform layer. It provides a CLI tool, 'abs', for managing connectors, creating connections, running jobs, selecting specific data streams, handling secrets securely, and scheduling remote runs. The tool is scalable, allowing independent deployment of multiple connectors. It aims to streamline the connector management process and provide a more agile alternative to the comprehensive Airbyte platform.
actions
Sema4.ai Action Server is a tool that allows users to build semantic actions in Python to connect AI agents with real-world applications. It enables users to create custom actions, skills, loaders, and plugins that securely connect any AI Assistant platform to data and applications. The tool automatically creates and exposes an API based on function declaration, type hints, and docstrings by adding '@action' to Python scripts. It provides an end-to-end stack supporting various connections between AI and user's apps and data, offering ease of use, security, and scalability.
openui
OpenUI is a tool designed to simplify the process of building UI components by allowing users to describe UI using their imagination and see it rendered live. It supports converting HTML to React, Svelte, Web Components, etc. The tool is open source and aims to make UI development fun, fast, and flexible. It integrates with various AI services like OpenAI, Groq, Gemini, Anthropic, Cohere, and Mistral, providing users with the flexibility to use different models. OpenUI also supports LiteLLM for connecting to various LLM services and allows users to create custom proxy configs. The tool can be run locally using Docker or Python, and it offers a development environment for quick setup and testing.
Akagi
Akagi is a project designed to help users understand and improve their performance in Majsoul game matches in real-time. It provides educational insights and tools for analyzing gameplay. Users can install Akagi on Windows or Mac systems and follow the setup instructions to enhance their gaming experience. The project aims to offer features like Autoplay, Auto Ron, and integration with MajsoulUnlocker. It also focuses on enhancing user safety by providing guidelines to minimize the risk of account suspension. Akagi is a tool that combines MITM interception, AI decision-making, and user interaction to optimize gameplay strategies and performance.
robocorp
Robocorp is a platform that allows users to create, deploy, and operate Python automations and AI actions. It provides an easy way to extend the capabilities of AI agents, assistants, and copilots with custom actions written in Python. Users can create and deploy tools, skills, loaders, and plugins that securely connect any AI Assistant platform to their data and applications. The Robocorp Action Server makes Python scripts compatible with ChatGPT and LangChain by automatically creating and exposing an API based on function declaration, type hints, and docstrings. It simplifies the process of developing and deploying AI actions, enabling users to interact with AI frameworks effortlessly.
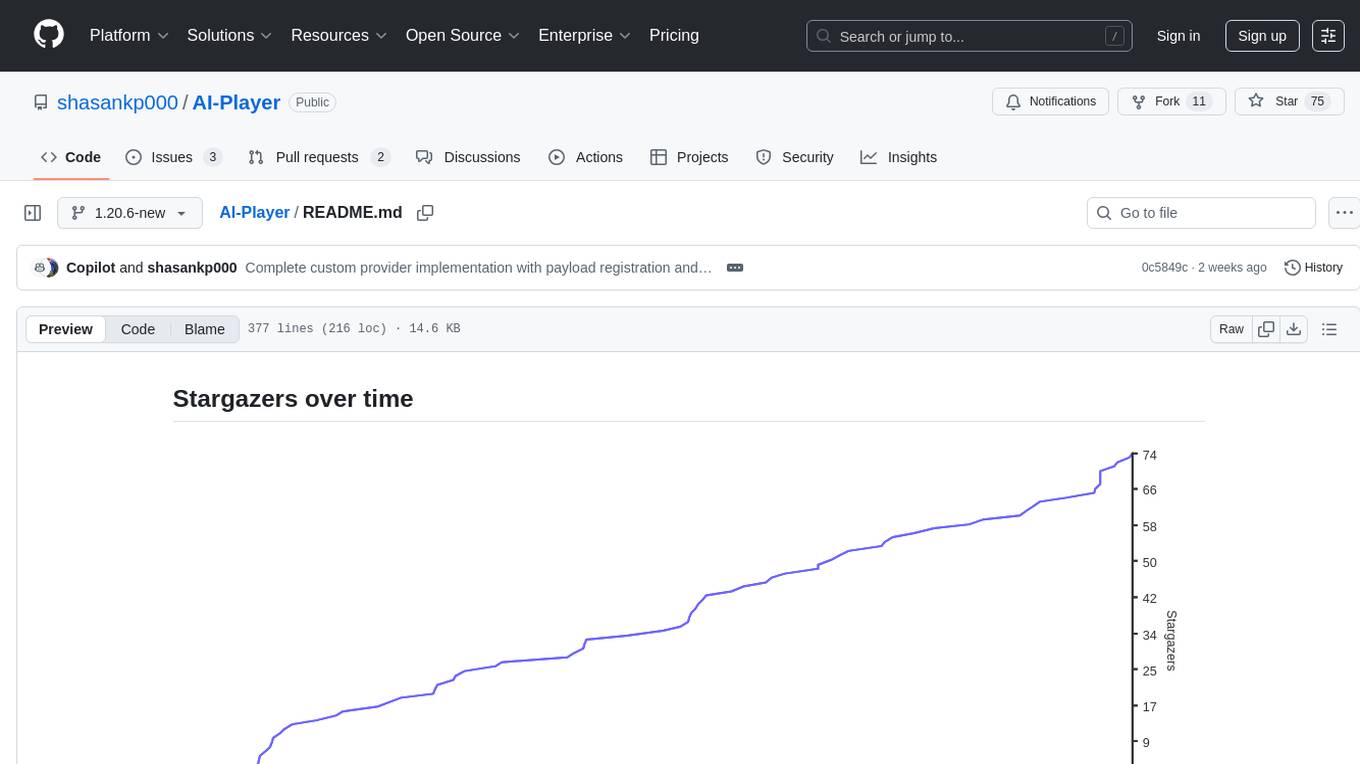
AI-Player
AI-Player is a Minecraft mod that adds an 'intelligent' second player to the game to combat loneliness while playing solo. It aims to enhance gameplay by providing companionship and interactive features. The mod leverages advanced AI algorithms and integrates with external tools to enhance the player experience. Developed with a focus on addressing the social aspect of gaming, AI-Player is a community-driven project that continues to evolve with user feedback and contributions.
nobodywho
NobodyWho is a plugin for the Godot game engine that enables interaction with local LLMs for interactive storytelling. Users can install it from Godot editor or GitHub releases page, providing their own LLM in GGUF format. The plugin consists of `NobodyWhoModel` node for model file, `NobodyWhoChat` node for chat interaction, and `NobodyWhoEmbedding` node for generating embeddings. It offers a programming interface for sending text to LLM, receiving responses, and starting the LLM worker.
For similar tasks
Perplexica
Perplexica is an open-source AI-powered search engine that utilizes advanced machine learning algorithms to provide clear answers with sources cited. It offers various modes like Copilot Mode, Normal Mode, and Focus Modes for specific types of questions. Perplexica ensures up-to-date information by using SearxNG metasearch engine. It also features image and video search capabilities and upcoming features include finalizing Copilot Mode and adding Discover and History Saving features.
embedchain
Embedchain is an Open Source Framework for personalizing LLM responses. It simplifies the creation and deployment of personalized AI applications by efficiently managing unstructured data, generating relevant embeddings, and storing them in a vector database. With diverse APIs, users can extract contextual information, find precise answers, and engage in interactive chat conversations tailored to their data. The framework follows the design principle of being 'Conventional but Configurable' to cater to both software engineers and machine learning engineers.
Awesome_Mamba
Awesome Mamba is a curated collection of groundbreaking research papers and articles on Mamba Architecture, a pioneering framework in deep learning known for its selective state spaces and efficiency in processing complex data structures. The repository offers a comprehensive exploration of Mamba architecture through categorized research papers covering various domains like visual recognition, speech processing, remote sensing, video processing, activity recognition, image enhancement, medical imaging, reinforcement learning, natural language processing, 3D recognition, multi-modal understanding, time series analysis, graph neural networks, point cloud analysis, and tabular data handling.
WeeklySpatialAI
WeeklySpatialAI is a weekly online meetup for the Spatial AI KR community to share the latest news and resources in the Spatial AI field. It aims to facilitate information exchange among professionals, students, and professors, covering topics such as latest papers, industry updates, new technologies/products, development tips, job postings, and useful tech blogs.
Verbiverse
Verbiverse is a tool that uses a large language model to assist in reading PDFs and watching videos, aimed at improving language proficiency. It provides a more convenient and efficient way to use large models through predefined prompts, designed for those looking to enhance their language skills. The tool analyzes unfamiliar words and sentences in foreign language PDFs or video subtitles, providing better contextual understanding compared to traditional dictionary translations or ambiguous meanings. It offers features such as automatic loading of subtitles, word analysis by clicking or double-clicking, and a word database for collecting words. Users can run the tool on Windows x86_64 or ubuntu_22.04 x86_64 platforms by downloading the precompiled packages or by cloning the source code and setting up a virtual environment with Python. It is recommended to use a local model or smaller PDF files for testing due to potential token consumption issues with large files.
duckduckgo_search
Duckduckgo_search is a Python library that enables AI chat and search functionalities for text, news, images, and videos using the DuckDuckGo.com search engine. It provides various methods for different search types such as text, images, videos, and news. The library also supports search operators, regions, proxy settings, and exception handling. Users can interact with the DuckDuckGo API to retrieve search results based on specific queries and parameters.
mu
Mu is a collection of simple tools for everyday use that respect users' time by providing utilities without ads, algorithms, or tracking. It includes features like personalized dashboard, microblogging, AI-powered chat, RSS feeds with AI summaries, ad-free YouTube viewing, private messaging & email, and crypto payments. Users can self-host Mu or use the hosted version at mu.xyz. The tools are designed to be small, focused, and do one thing well, enhancing some features with AI capabilities like auto-tagging topics, summarizing articles, and providing knowledge assistance.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.
For similar jobs
Perplexica
Perplexica is an open-source AI-powered search engine that utilizes advanced machine learning algorithms to provide clear answers with sources cited. It offers various modes like Copilot Mode, Normal Mode, and Focus Modes for specific types of questions. Perplexica ensures up-to-date information by using SearxNG metasearch engine. It also features image and video search capabilities and upcoming features include finalizing Copilot Mode and adding Discover and History Saving features.

KULLM
KULLM (구름) is a Korean Large Language Model developed by Korea University NLP & AI Lab and HIAI Research Institute. It is based on the upstage/SOLAR-10.7B-v1.0 model and has been fine-tuned for instruction. The model has been trained on 8×A100 GPUs and is capable of generating responses in Korean language. KULLM exhibits hallucination and repetition phenomena due to its decoding strategy. Users should be cautious as the model may produce inaccurate or harmful results. Performance may vary in benchmarks without a fixed system prompt.

MMMU
MMMU is a benchmark designed to evaluate multimodal models on college-level subject knowledge tasks, covering 30 subjects and 183 subfields with 11.5K questions. It focuses on advanced perception and reasoning with domain-specific knowledge, challenging models to perform tasks akin to those faced by experts. The evaluation of various models highlights substantial challenges, with room for improvement to stimulate the community towards expert artificial general intelligence (AGI).

1filellm
1filellm is a command-line data aggregation tool designed for LLM ingestion. It aggregates and preprocesses data from various sources into a single text file, facilitating the creation of information-dense prompts for large language models. The tool supports automatic source type detection, handling of multiple file formats, web crawling functionality, integration with Sci-Hub for research paper downloads, text preprocessing, and token count reporting. Users can input local files, directories, GitHub repositories, pull requests, issues, ArXiv papers, YouTube transcripts, web pages, Sci-Hub papers via DOI or PMID. The tool provides uncompressed and compressed text outputs, with the uncompressed text automatically copied to the clipboard for easy pasting into LLMs.

gpt-researcher
GPT Researcher is an autonomous agent designed for comprehensive online research on a variety of tasks. It can produce detailed, factual, and unbiased research reports with customization options. The tool addresses issues of speed, determinism, and reliability by leveraging parallelized agent work. The main idea involves running 'planner' and 'execution' agents to generate research questions, seek related information, and create research reports. GPT Researcher optimizes costs and completes tasks in around 3 minutes. Features include generating long research reports, aggregating web sources, an easy-to-use web interface, scraping web sources, and exporting reports to various formats.

ChatTTS
ChatTTS is a generative speech model optimized for dialogue scenarios, providing natural and expressive speech synthesis with fine-grained control over prosodic features. It supports multiple speakers and surpasses most open-source TTS models in terms of prosody. The model is trained with 100,000+ hours of Chinese and English audio data, and the open-source version on HuggingFace is a 40,000-hour pre-trained model without SFT. The roadmap includes open-sourcing additional features like VQ encoder, multi-emotion control, and streaming audio generation. The tool is intended for academic and research use only, with precautions taken to limit potential misuse.

HebTTS
HebTTS is a language modeling approach to diacritic-free Hebrew text-to-speech (TTS) system. It addresses the challenge of accurately mapping text to speech in Hebrew by proposing a language model that operates on discrete speech representations and is conditioned on a word-piece tokenizer. The system is optimized using weakly supervised recordings and outperforms diacritic-based Hebrew TTS systems in terms of content preservation and naturalness of generated speech.

do-research-in-AI
This repository is a collection of research lectures and experience sharing posts from frontline researchers in the field of AI. It aims to help individuals upgrade their research skills and knowledge through insightful talks and experiences shared by experts. The content covers various topics such as evaluating research papers, choosing research directions, research methodologies, and tips for writing high-quality scientific papers. The repository also includes discussions on academic career paths, research ethics, and the emotional aspects of research work. Overall, it serves as a valuable resource for individuals interested in advancing their research capabilities in the field of AI.