
CyberScraper-2077
A Powerful web scraper powered by LLM | OpenAI, Gemini & Ollama
Stars: 951
CyberScraper 2077 is an advanced web scraping tool powered by AI, designed to extract data from websites with precision and style. It offers a user-friendly interface, supports multiple data export formats, operates in stealth mode to avoid detection, and promises lightning-fast scraping. The tool respects ethical scraping practices, including robots.txt and site policies. With upcoming features like proxy support and page navigation, CyberScraper 2077 is a futuristic solution for data extraction in the digital realm.
README:

Rip data from the net, leaving no trace. Welcome to the future of web scraping.
CyberScraper 2077 is not just another web scraping tool – it's a glimpse into the future of data extraction. Born from the neon-lit streets of a cyberpunk world, this AI-powered scraper uses OpenAI, Gemini and LocalLLM Models to slice through the web's defenses, extracting the data you need with unparalleled precision and style.
Whether you're a corpo data analyst, a street-smart netrunner, or just someone looking to pull information from the digital realm, CyberScraper 2077 has got you covered.

- 🤖 AI-Powered Extraction: Utilizes cutting-edge AI models to understand and parse web content intelligently.
- 🖥️ Sleek Streamlit Interface: User-friendly GUI that even a chrome-armed street samurai could navigate.
- 🔄 Multi-Format Support: Export your data in JSON, CSV, HTML, SQL or Excel – whatever fits your cyberdeck.
- 🕵️ Stealth Mode: Implemented stealth mode parameters that help avoid detection as a bot.
- 🦙 Ollama Support: Use a huge library of open source LLMs.
- ⚡ Async Operations: Lightning-fast scraping that would make a Trauma Team jealous.
- 🧠 Smart Parsing: Structures scraped content as if it was extracted straight from the engram of a master netrunner.
- 💾 Caching: Implemented content-based and query-based caching using LRU cache and a custom dictionary to reduce redundant API calls.
- 📊 Upload to Google Sheets: Now you can easily upload your extracted CSV data to Google Sheets with one click.
- 🛡️ Bypass Captcha: Bypass captcha by using the -captcha at the end of the URL. (Currently only works natively, doesn't work on Docker)
- 🌐 Current Browser: The current browser feature uses your local browser instance which will help you bypass 99% of bot detections. (Only use when necessary)
- 🔒 Proxy Mode (Coming Soon): Built-in proxy support to keep you ghosting through the net.
- 🧭 Navigate through the Pages (BETA): Navigate through the webpage and scrape data from different pages.
Check out our Redesigned and Improved Version of CyberScraper-2077 with more functionality YouTube video for a full walkthrough of CyberScraper 2077's capabilities.
Check out our first build (Old Video) YouTube video
Please follow the Docker Container Guide given below, as I won't be able to maintain another version for Windows systems.
Note: CyberScraper 2077 requires Python 3.10 or higher.
-
Clone this repository:
git clone https://github.com/itsOwen/CyberScraper-2077.git cd CyberScraper-2077 -
Create and activate a virtual environment:
virtualenv venv source venv/bin/activate # Optional
-
Install the required packages:
pip install -r requirements.txt
-
Install the playwright:
playwright install
-
Set OpenAI & Gemini Key in your environment:
Linux/Mac:
export OPENAI_API_KEY="your-api-key-here" export GOOGLE_API_KEY="your-api-key-here"
-
If you want to use Ollama:
Note: I only recommend using OpenAI and Gemini API as these models are really good at following instructions. If you are using open-source LLMs, make sure you have a good system as the speed of the data generation/presentation depends on how well your system can run the LLM. You may also have to fine-tune the prompt and add some additional filters yourself.
1. Setup Ollama using `pip install ollama`
2. Download Ollama from the official website: https://ollama.com/download
3. Now type: ollama pull llama3.1 or whatever LLM you want to use.
4. Now follow the rest of the steps below.If you prefer to use Docker, follow these steps to set up and run CyberScraper 2077:
-
Ensure you have Docker installed on your system.
-
Clone this repository:
git clone https://github.com/itsOwen/CyberScraper-2077.git cd CyberScraper-2077 -
Build the Docker image:
docker build -t cyberscraper-2077 . -
Run the container:
- Without API key:
docker run -p 8501:8501 cyberscraper-2077
- With OpenAI API key:
docker run -p 8501:8501 -e OPENAI_API_KEY="your-actual-api-key" cyberscraper-2077 - With Gemini API key:
docker run -p 8501:8501 -e GOOGLE_API_KEY="your-actual-api-key" cyberscraper-2077
- Without API key:
-
Open your browser and navigate to
http://localhost:8501.
If you want to use Ollama with the Docker setup:
-
Install Ollama on your host machine following the instructions at https://ollama.com/download
-
Run Ollama on your host machine:
ollama pull llama3.1
-
Find your host machine's IP address:
- On Linux/Mac:
ifconfigorip addr show - On Windows:
ipconfig
- On Linux/Mac:
-
Run the Docker container with the host network and set the Ollama URL:
docker run -e OLLAMA_BASE_URL=http://host.docker.internal:11434 -p 8501:8501 cyberscraper-2077
On Linux you might need to use this below:
docker run -e OLLAMA_BASE_URL=http://<your-host-ip>:11434 -p 8501:8501 cyberscraper-2077
Replace
<your-host-ip>with your actual host machine IP address. -
In the Streamlit interface, select the Ollama model you want to use (e.g., "ollama:llama3.1").
Note: Ensure that your firewall allows connections to port 11434 for Ollama.
-
Fire up the Streamlit app:
streamlit run main.py
-
Open your browser and navigate to
http://localhost:8501. -
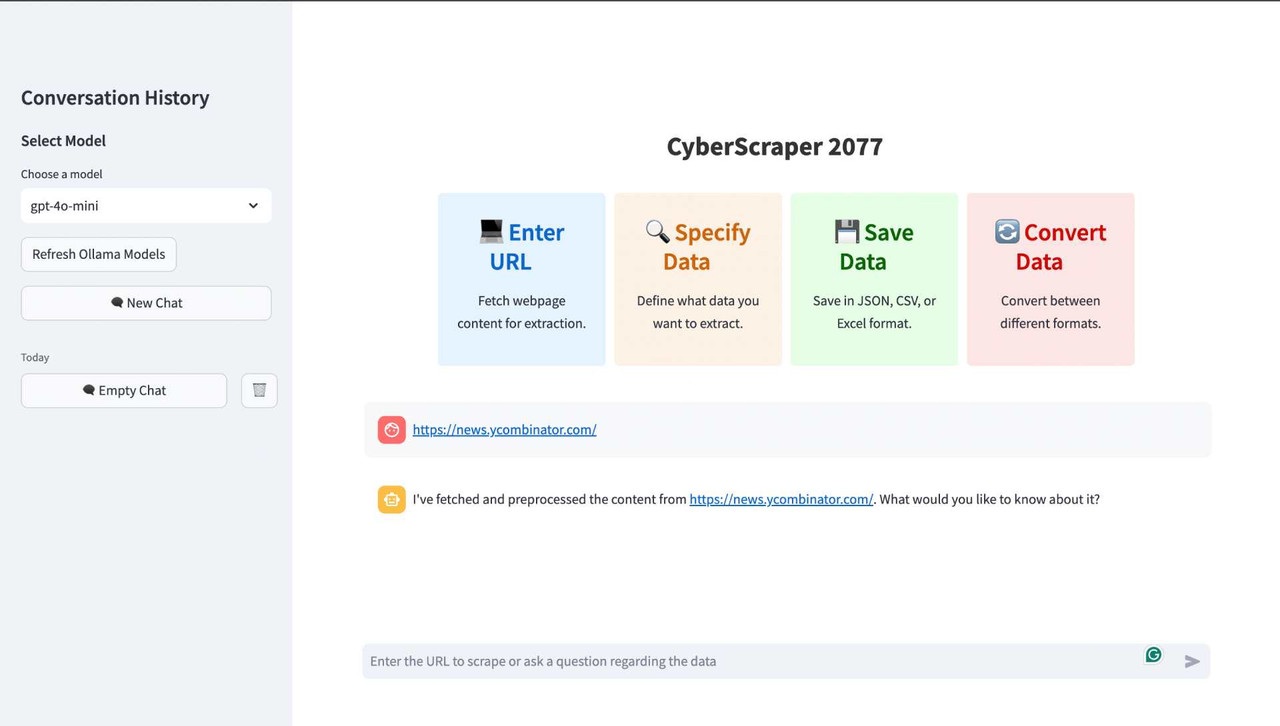
Enter the URL of the site you want to scrape or ask a question about the data you need.
-
Ask the chatbot to extract the data in any format. Select whatever data you want to export or even everything from the webpage.
-
Watch as CyberScraper 2077 tears through the net, extracting your data faster than you can say "flatline"!
Note: The multi-page scraping feature is currently in beta. While functional, you may encounter occasional issues or unexpected behavior. We appreciate your feedback and patience as we continue to improve this feature.
CyberScraper 2077 now supports multi-page scraping, allowing you to extract data from multiple pages of a website in one go. This feature is perfect for scraping paginated content, search results, or any site with data spread across multiple pages.
I suggest you enter the URL structure every time if you want to scrape multiple pages so it can detect the URL structure easily. It detects nearly all URL types.
-
Basic Usage: To scrape multiple pages, use the following format when entering the URL:
https://example.com/page 1-5 https://example.com/p/ 1-6 https://example.com/xample/something-something-1279?p=1 1-3This will scrape pages 1 through 5 of the website.
-
Custom Page Ranges: You can specify custom page ranges:
https://example.com/p/ 1-5,7,9-12 https://example.com/xample/something-something-1279?p=1 1,7,8,9This will scrape pages 1 to 5, page 7, and pages 9 to 12.
-
URL Patterns: For websites with different URL structures, you can specify a pattern:
https://example.com/search?q=cyberpunk&page={page} 1-5Replace
{page}with where the page number should be in the URL. -
Automatic Pattern Detection: If you don't specify a pattern, CyberScraper 2077 will attempt to detect the URL pattern automatically. However, for best results, specifying the pattern is recommended.
- Start with a small range of pages to test before scraping a large number.
- Be mindful of the website's load and your scraping speed to avoid overloading servers.
- Use the
simulate_humanoption for more natural scraping behavior on sites with anti-bot measures. - Regularly check the website's
robots.txtfile and terms of service to ensure compliance.
URL Example : "https://news.ycombinator.com/?p=1 1-3 or 1,2,3,4"If you want to scrape a specific page, just enter the query "please scrape page number 1 or 2". If you want to scrape all pages, simply give a query like "scrape all pages in csv" or whatever format you want.
If you encounter errors during multi-page scraping:
- Check your internet connection
- Verify the URL pattern is correct
- Ensure the website allows scraping
- Try reducing the number of pages or increasing the delay between requests
As this feature is in beta, we highly value your feedback. If you encounter any issues or have suggestions for improvement, please:
- Open an issue on our GitHub repository
- Provide detailed information about the problem, including the URL structure and number of pages you were attempting to scrape
- Share any error messages or unexpected behaviors you observed
Your input is crucial in helping us refine and stabilize this feature for future releases.
- Go to the Google Cloud Console (https://console.cloud.google.com/).
- Select your project.
- Navigate to "APIs & Services" > "Credentials".
- Find your existing OAuth 2.0 Client ID and delete it.
- Click "Create Credentials" > "OAuth client ID".
- Choose "Web application" as the application type.
- Name your client (e.g., "CyberScraper 2077 Web Client").
- Under "Authorized JavaScript origins", add:
- Under "Authorized redirect URIs", add:
- Click "Create" to generate the new client ID.
- Download the new client configuration JSON file and rename it to
client_secret.json.
Customize the PlaywrightScraper settings to fit your scraping needs. If some websites are giving you issues, you might want to check the behavior of the website:
use_stealth: bool = True,
simulate_human: bool = False,
use_custom_headers: bool = True,
hide_webdriver: bool = True,
bypass_cloudflare: bool = True:Adjust these settings based on your target website and environment for optimal results.
You can also bypass the captcha using the -captcha parameter at the end of the URL. The browser window will pop up, complete the captcha, and go back to your terminal window. Press enter and the bot will complete its task.
We welcome all cyberpunks, netrunners, and code samurais to contribute to CyberScraper 2077!
Ran into a glitch in the matrix? Let me know by adding the issue to this repo so that we can fix it together.
Q: Is CyberScraper 2077 legal to use? A: CyberScraper 2077 is designed for ethical web scraping. Always ensure you have the right to scrape a website and respect their robots.txt file.
Q: Can I use this for commercial purposes? A: Yes, under the terms of the MIT License. But remember, in Night City, there's always a price to pay. Just kidding!
This project is licensed under the MIT License - see the LICENSE file for details. Use it, mod it, sell it – just don't blame us if you end up flatlined.
Got questions? Need support? Want to hire me for a gig?
- 📧 Email: [email protected]
- 🐦 Twitter: @owensingh_
- 💬 Website: Portfolio
Listen up, choombas! Before you jack into this code, you better understand the risks:
-
This software is provided "as is", without warranty of any kind, express or implied.
-
The authors are not liable for any damages or losses resulting from the use of this software.
-
This tool is intended for educational and research purposes only. Any illegal use is strictly prohibited.
-
We do not guarantee the accuracy, completeness, or reliability of any data obtained through this tool.
-
By using this software, you acknowledge that you are doing so at your own risk.
-
You are responsible for complying with all applicable laws and regulations in your use of this software.
-
We reserve the right to modify or discontinue the software at any time without notice.
Remember, samurai: In the dark future of the NET, knowledge is power, but it's also a double-edged sword. Use this tool wisely, and may your connection always be strong and your firewalls impenetrable. Stay frosty out there in the digital frontier.

CyberScraper 2077 – Because in 2077, what makes someone a criminal? Getting caught.
Built with ❤️ and chrome by the streets of Night City | © 2077 Owen Singh
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for CyberScraper-2077
Similar Open Source Tools
CyberScraper-2077
CyberScraper 2077 is an advanced web scraping tool powered by AI, designed to extract data from websites with precision and style. It offers a user-friendly interface, supports multiple data export formats, operates in stealth mode to avoid detection, and promises lightning-fast scraping. The tool respects ethical scraping practices, including robots.txt and site policies. With upcoming features like proxy support and page navigation, CyberScraper 2077 is a futuristic solution for data extraction in the digital realm.

Perplexica
Perplexica is an open-source AI-powered search engine that utilizes advanced machine learning algorithms to provide clear answers with sources cited. It offers various modes like Copilot Mode, Normal Mode, and Focus Modes for specific types of questions. Perplexica ensures up-to-date information by using SearxNG metasearch engine. It also features image and video search capabilities and upcoming features include finalizing Copilot Mode and adding Discover and History Saving features.
MiniSearch
MiniSearch is a minimalist search engine with integrated browser-based AI. It is privacy-focused, easy to use, cross-platform, integrated, time-saving, efficient, optimized, and open-source. MiniSearch can be used for a variety of tasks, including searching the web, finding files on your computer, and getting answers to questions. It is a great tool for anyone who wants a fast, private, and easy-to-use search engine.
merlinn
Merlinn is an open-source AI-powered on-call engineer that automatically jumps into incidents & alerts, providing useful insights and RCA in real time. It integrates with popular observability tools, lives inside Slack, offers an intuitive UX, and prioritizes security. Users can self-host Merlinn, use it for free, and benefit from automatic RCA, Slack integration, integrations with various tools, intuitive UX, and security features.

crawlee-python
Crawlee-python is a web scraping and browser automation library that covers crawling and scraping end-to-end, helping users build reliable scrapers fast. It allows users to crawl the web for links, scrape data, and store it in machine-readable formats without worrying about technical details. With rich configuration options, users can customize almost any aspect of Crawlee to suit their project's needs.
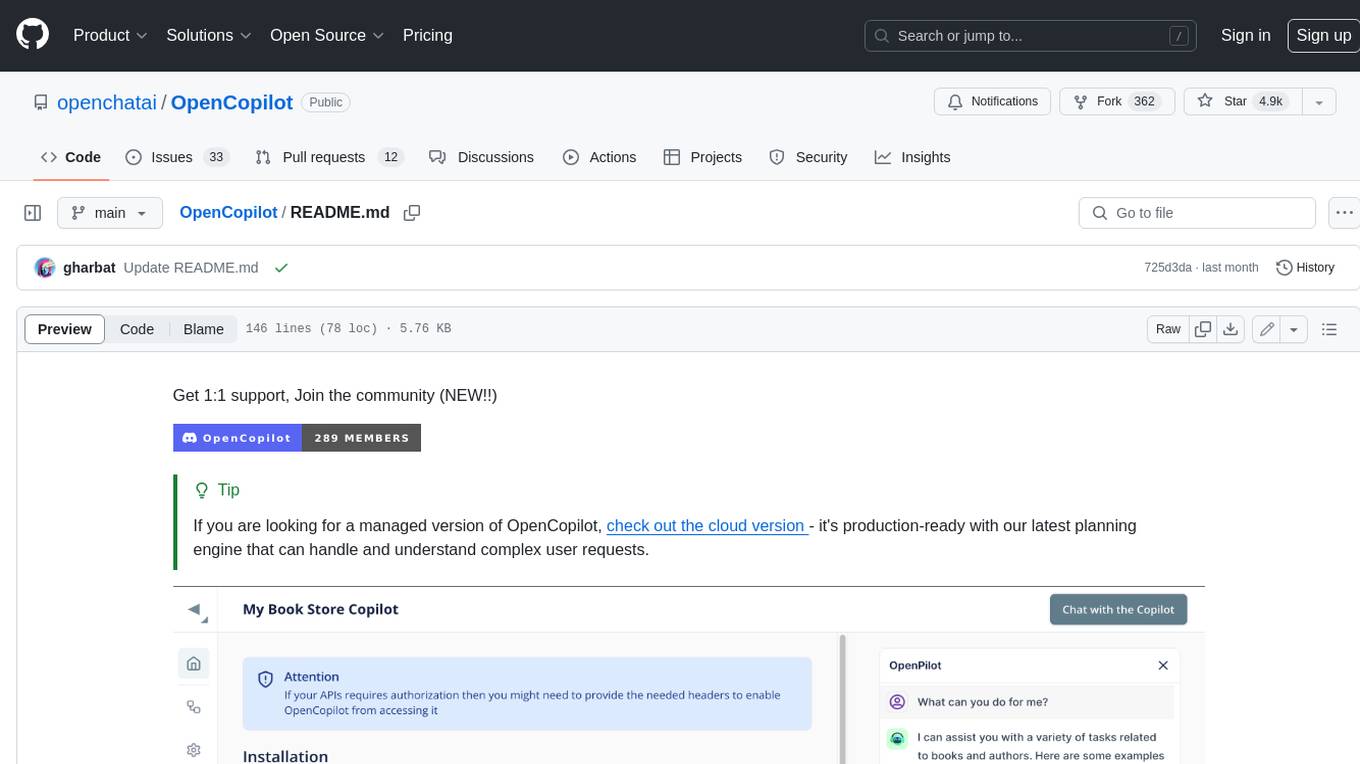
OpenCopilot
OpenCopilot allows you to have your own product's AI copilot. It integrates with your underlying APIs and can execute API calls whenever needed. It uses LLMs to determine if the user's request requires calling an API endpoint. Then, it decides which endpoint to call and passes the appropriate payload based on the given API definition.
Akagi
Akagi is a project designed to help users understand and improve their performance in Majsoul game matches in real-time. It provides educational insights and tools for analyzing gameplay. Users can install Akagi on Windows or Mac systems and follow the setup instructions to enhance their gaming experience. The project aims to offer features like Autoplay, Auto Ron, and integration with MajsoulUnlocker. It also focuses on enhancing user safety by providing guidelines to minimize the risk of account suspension. Akagi is a tool that combines MITM interception, AI decision-making, and user interaction to optimize gameplay strategies and performance.
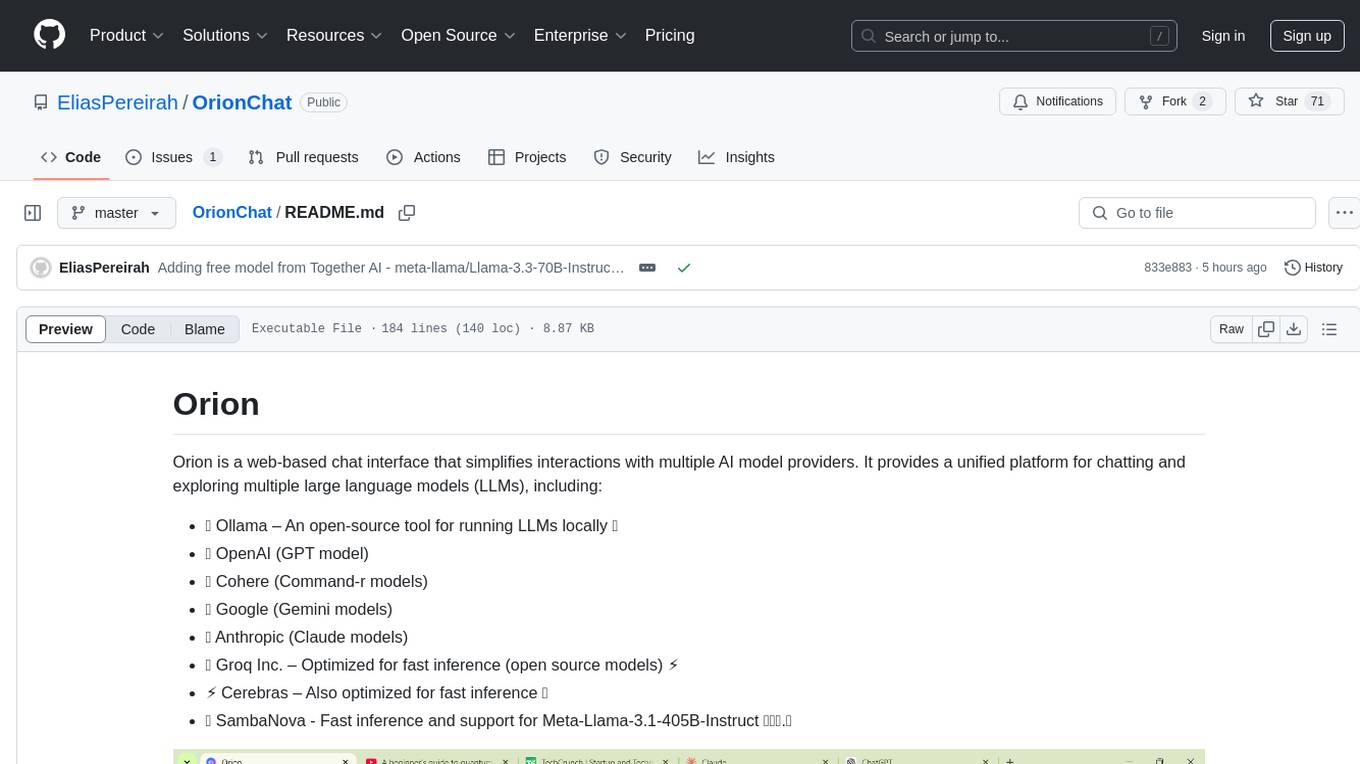
OrionChat
Orion is a web-based chat interface that simplifies interactions with multiple AI model providers. It provides a unified platform for chatting and exploring various large language models (LLMs) such as Ollama, OpenAI (GPT model), Cohere (Command-r models), Google (Gemini models), Anthropic (Claude models), Groq Inc., Cerebras, and SambaNova. Users can easily navigate and assess different AI models through an intuitive, user-friendly interface. Orion offers features like browser-based access, code execution with Google Gemini, text-to-speech (TTS), speech-to-text (STT), seamless integration with multiple AI models, customizable system prompts, language translation tasks, document uploads for analysis, and more. API keys are stored locally, and requests are sent directly to official providers' APIs without external proxies.
nobodywho
NobodyWho is a plugin for the Godot game engine that enables interaction with local LLMs for interactive storytelling. Users can install it from Godot editor or GitHub releases page, providing their own LLM in GGUF format. The plugin consists of `NobodyWhoModel` node for model file, `NobodyWhoChat` node for chat interaction, and `NobodyWhoEmbedding` node for generating embeddings. It offers a programming interface for sending text to LLM, receiving responses, and starting the LLM worker.

Sentient
Sentient is a personal, private, and interactive AI companion developed by Existence. The project aims to build a completely private AI companion that is deeply personalized and context-aware of the user. It utilizes automation and privacy to create a true companion for humans. The tool is designed to remember information about the user and use it to respond to queries and perform various actions. Sentient features a local and private environment, MBTI personality test, integrations with LinkedIn, Reddit, and more, self-managed graph memory, web search capabilities, multi-chat functionality, and auto-updates for the app. The project is built using technologies like ElectronJS, Next.js, TailwindCSS, FastAPI, Neo4j, and various APIs.
open-source-slack-ai
This repository provides a ready-to-run basic Slack AI solution that allows users to summarize threads and channels using OpenAI. Users can generate thread summaries, channel overviews, channel summaries since a specific time, and full channel summaries. The tool is powered by GPT-3.5-Turbo and an ensemble of NLP models. It requires Python 3.8 or higher, an OpenAI API key, Slack App with associated API tokens, Poetry package manager, and ngrok for local development. Users can customize channel and thread summaries, run tests with coverage using pytest, and contribute to the project for future enhancements.

dataline
DataLine is an AI-driven data analysis and visualization tool designed for technical and non-technical users to explore data quickly. It offers privacy-focused data storage on the user's device, supports various data sources, generates charts, executes queries, and facilitates report building. The tool aims to speed up data analysis tasks for businesses and individuals by providing a user-friendly interface and natural language querying capabilities.
Kuebiko
Kuebiko is a Twitch Chat Bot that reads twitch chat and generates text-to-speech responses using Google Cloud API and OpenAI's GPT-3 text completion model. It allows users to set up their own VTuber AI similar to 'Neuro-Sama'. The project is built with Python and requires setting up various API keys and configurations to enable the bot functionality. Users can customize the voice of their VTuber and route audio using VBAudio Cable. Kuebiko provides a unique way to interact with viewers through chat responses and captions in OBS.
TerminalGPT
TerminalGPT is a terminal-based ChatGPT personal assistant app that allows users to interact with OpenAI GPT-3.5 and GPT-4 language models. It offers advantages over browser-based apps, such as continuous availability, faster replies, and tailored answers. Users can use TerminalGPT in their IDE terminal, ensuring seamless integration with their workflow. The tool prioritizes user privacy by not using conversation data for model training and storing conversations locally on the user's machine.
obsidian-chat-cbt-plugin
ChatCBT is an AI-powered journaling assistant for Obsidian, inspired by cognitive behavioral therapy (CBT). It helps users reframe negative thoughts and rewire reactions to distressful situations. The tool provides kind and objective responses to uncover negative thinking patterns, store conversations privately, and summarize reframed thoughts. Users can choose between a cloud-based AI service (OpenAI) or a local and private service (Ollama) for handling data. ChatCBT is not a replacement for therapy but serves as a journaling assistant to help users gain perspective on their problems.

cognita
Cognita is an open-source framework to organize your RAG codebase along with a frontend to play around with different RAG customizations. It provides a simple way to organize your codebase so that it becomes easy to test it locally while also being able to deploy it in a production ready environment. The key issues that arise while productionizing RAG system from a Jupyter Notebook are: 1. **Chunking and Embedding Job** : The chunking and embedding code usually needs to be abstracted out and deployed as a job. Sometimes the job will need to run on a schedule or be trigerred via an event to keep the data updated. 2. **Query Service** : The code that generates the answer from the query needs to be wrapped up in a api server like FastAPI and should be deployed as a service. This service should be able to handle multiple queries at the same time and also autoscale with higher traffic. 3. **LLM / Embedding Model Deployment** : Often times, if we are using open-source models, we load the model in the Jupyter notebook. This will need to be hosted as a separate service in production and model will need to be called as an API. 4. **Vector DB deployment** : Most testing happens on vector DBs in memory or on disk. However, in production, the DBs need to be deployed in a more scalable and reliable way. Cognita makes it really easy to customize and experiment everything about a RAG system and still be able to deploy it in a good way. It also ships with a UI that makes it easier to try out different RAG configurations and see the results in real time. You can use it locally or with/without using any Truefoundry components. However, using Truefoundry components makes it easier to test different models and deploy the system in a scalable way. Cognita allows you to host multiple RAG systems using one app. ### Advantages of using Cognita are: 1. A central reusable repository of parsers, loaders, embedders and retrievers. 2. Ability for non-technical users to play with UI - Upload documents and perform QnA using modules built by the development team. 3. Fully API driven - which allows integration with other systems. > If you use Cognita with Truefoundry AI Gateway, you can get logging, metrics and feedback mechanism for your user queries. ### Features: 1. Support for multiple document retrievers that use `Similarity Search`, `Query Decompostion`, `Document Reranking`, etc 2. Support for SOTA OpenSource embeddings and reranking from `mixedbread-ai` 3. Support for using LLMs using `Ollama` 4. Support for incremental indexing that ingests entire documents in batches (reduces compute burden), keeps track of already indexed documents and prevents re-indexing of those docs.
For similar tasks

mage-ai
Mage is an open-source data pipeline tool for transforming and integrating data. It offers an easy developer experience, engineering best practices built-in, and data as a first-class citizen. Mage makes it easy to build, preview, and launch data pipelines, and provides observability and scaling capabilities. It supports data integrations, streaming pipelines, and dbt integration.

nucliadb
NucliaDB is a robust database that allows storing and searching on unstructured data. It is an out of the box hybrid search database, utilizing vector, full text and graph indexes. NucliaDB is written in Rust and Python. We designed it to index large datasets and provide multi-teanant support. When utilizing NucliaDB with Nuclia cloud, you are able to the power of an NLP database without the hassle of data extraction, enrichment and inference. We do all the hard work for you.

LLMstudio
LLMstudio by TensorOps is a platform that offers prompt engineering tools for accessing models from providers like OpenAI, VertexAI, and Bedrock. It provides features such as Python Client Gateway, Prompt Editing UI, History Management, and Context Limit Adaptability. Users can track past runs, log costs and latency, and export history to CSV. The tool also supports automatic switching to larger-context models when needed. Coming soon features include side-by-side comparison of LLMs, automated testing, API key administration, project organization, and resilience against rate limits. LLMstudio aims to streamline prompt engineering, provide execution history tracking, and enable effortless data export, offering an evolving environment for teams to experiment with advanced language models.
CyberScraper-2077
CyberScraper 2077 is an advanced web scraping tool powered by AI, designed to extract data from websites with precision and style. It offers a user-friendly interface, supports multiple data export formats, operates in stealth mode to avoid detection, and promises lightning-fast scraping. The tool respects ethical scraping practices, including robots.txt and site policies. With upcoming features like proxy support and page navigation, CyberScraper 2077 is a futuristic solution for data extraction in the digital realm.
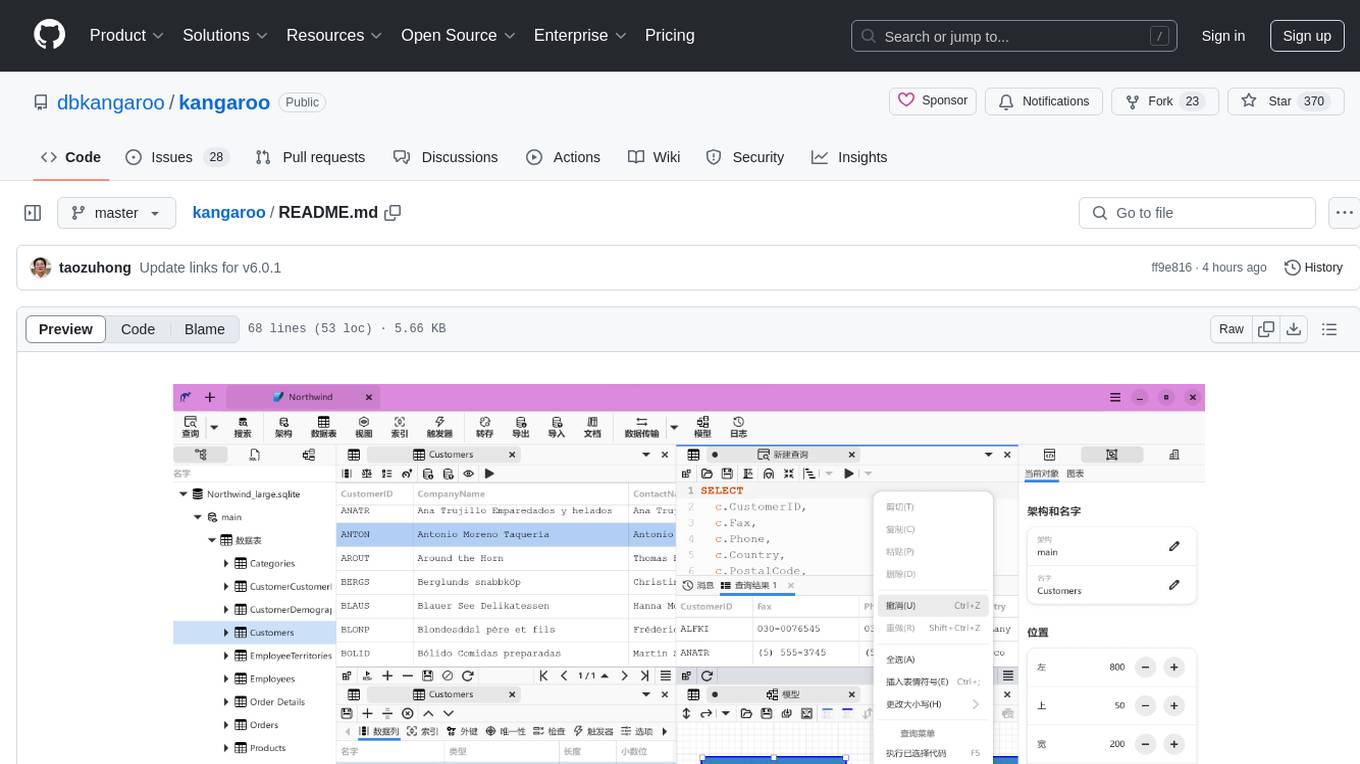
kangaroo
Kangaroo is an AI-powered SQL client and admin tool for popular databases like SQLite, MySQL, PostgreSQL, etc. It supports various functionalities such as table design, query, model, sync, export/import, and more. The tool is designed to be comfortable, fun, and developer-friendly, with features like code intellisense and autocomplete. Kangaroo aims to provide a seamless experience for database management across different operating systems.
emdash
Emdash is an AI-powered tool designed to help users organize text snippets for better retention and learning. It utilizes on-device AI analysis to identify passages with similar ideas from different authors, offers instant semantic search capabilities, allows users to tag, rate, note, and reflect on content, and enables exporting to epub format for e-reader review. Users can also discover forgotten ideas through random exploration, rephrase concepts using metaphors, and import highlights from Kindle or other sources. Emdash is open-source, offline-first, and supports various data formats for import and export.
pennywiseai-tracker
PennyWise AI Tracker is a free and open-source expense tracker that uses on-device AI to turn bank SMS into a clean and searchable money timeline. It offers smart SMS parsing, clear insights, subscription tracking, on-device AI assistant, auto-categorization, data export, and supports major Indian banks. All processing happens on the user's device for privacy. The tool is designed for Android users in India who want automatic expense tracking from bank SMS, with clean categories, subscription detection, and clear insights.

litegraph
LiteGraph is a property graph database designed for knowledge and artificial intelligence applications. It supports graph relationships, tags, labels, metadata, data, and vectors. LiteGraph can be used in-process with LiteGraphClient or as a standalone RESTful server with LiteGraph.Server. The latest version includes major internal refactor, batch APIs, enumeration APIs, statistics APIs, database caching, vector search enhancements, and bug fixes. LiteGraph allows for simple embedding into applications without user configuration. Users can create tenants, graphs, nodes, edges, and perform operations like finding routes and exporting to GEXF file. It also provides features for working with object labels, tags, data, and vectors, enabling filtering and searching based on various criteria. LiteGraph offers REST API deployment with LiteGraph.Server and Docker support with a Docker image available on Docker Hub.
For similar jobs

lollms-webui
LoLLMs WebUI (Lord of Large Language Multimodal Systems: One tool to rule them all) is a user-friendly interface to access and utilize various LLM (Large Language Models) and other AI models for a wide range of tasks. With over 500 AI expert conditionings across diverse domains and more than 2500 fine tuned models over multiple domains, LoLLMs WebUI provides an immediate resource for any problem, from car repair to coding assistance, legal matters, medical diagnosis, entertainment, and more. The easy-to-use UI with light and dark mode options, integration with GitHub repository, support for different personalities, and features like thumb up/down rating, copy, edit, and remove messages, local database storage, search, export, and delete multiple discussions, make LoLLMs WebUI a powerful and versatile tool.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

minio
MinIO is a High Performance Object Storage released under GNU Affero General Public License v3.0. It is API compatible with Amazon S3 cloud storage service. Use MinIO to build high performance infrastructure for machine learning, analytics and application data workloads.
mage-ai
Mage is an open-source data pipeline tool for transforming and integrating data. It offers an easy developer experience, engineering best practices built-in, and data as a first-class citizen. Mage makes it easy to build, preview, and launch data pipelines, and provides observability and scaling capabilities. It supports data integrations, streaming pipelines, and dbt integration.

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

airbyte
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.