
ImageIndexer
Creates an index of images, queries a local LLM and adds tags to the image metadata
Stars: 156
LLMII is a tool that uses a local AI model to label metadata and index images without relying on cloud services or remote APIs. It runs a visual language model on your computer to generate captions and keywords for images, enhancing their metadata for indexing, searching, and organization. The tool can be run multiple times on the same image files, allowing for adding new data, regenerating data, and discovering files with issues. It supports various image formats, offers a user-friendly GUI, and can utilize GPU acceleration for faster processing. LLMII requires Python 3.8 or higher and operates directly on image file metadata fields like MWG:Keyword and XMP:Identifier.
README:
LLMII uses a local AI to label metadata and index images. It does not rely on a cloud service or database.
A visual language model runs on your computer and is used to create captions and keywords for images in a directory tree. The generated information is then added to each image file's metadata. The images can then be indexed, searched, and organized by by their descriptions using any tool you like that can access the common metadata fields. The files themselves can be moved, renamed, copied, and edited without affecting the metadata.
On your first run you will need to choose a model to run. Your system specs will be shown next to state of the art models. When you launch the indexer the model will be downloaded to the LLMII 'resources' directory. From that point the entire toolset is running completely locally.

- Image Analysis: Utilizes a local AI model to generate a list of keywords and a caption for each image
- Metadata Enhancement: Can automatically edit image metadata with generated tags
- Local Processing: All processing is done locally on your machine
- Multi-Format Support: Handles a wide range of image formats, including all major raw camera files
- User-Friendly GUI: Includes a GUI and installer. Relies on Koboldcpp, a single executable, for all AI functionality
- Simple Model Selection: Choose a the state of the art model and it will be automatically downloaded and configured
- Completely Automatic Backend Configuration: The AI backend (KoboldCpp) will be downloaded and configured with optimal settings
- GPU Acceleration: Will use Apple Metal, Nvidia CUDA, or AMD (Vulkan) hardware if available to greatly speed inference
- Cross-Platform: Supports Windows, macOS ARM, and Linux
- Stop and Start Capability: Can stop and start without having to reprocess all the files again
- One or Two Step Processing: Can do keywords and a simple caption in one step, or keywords and a detailed caption in two steps
- Highly Configurable: You are in control of everything
It is recommended to have a discrete graphics processor in your machine.
This tool verifies keywords and de-pluralizes them using rules that apply to English. Using it to generate keywords in other languages may have strange results.
This tool operates directly on image file metadata. It will write to one or more of the following fields:
- MWG:Keyword
- MWG:Description
- XMP:Identifier
- XMP:Status
The "Status" and "Identifier" fields are used to track the processing state of images. The "Description" field is used for the image caption, and "Subject" or "Keyword" fields are used to hold keywords.
The use of the Identifier tag means you can manage your files and add new files, and run the tool as many times as you like without worrying about reprocessing the files that were previously keyworded by the tool.
- Python 3.8 or higher
- KoboldCPP
-
Clone the repository or download the ZIP file and extract it
-
Install Python for Windows
-
Run
llmii-windows.bat
-
Clone the repository or download the ZIP file and extract it
-
Install Python 3.7 or higher if not already installed. You can use Homebrew:
brew install python -
Install ExifTool:
brew install exiftool -
Run the script:
./llmii.sh -
If KoboldCpp fails to run, open a terminal in the 'resources' folder:
xattr -cr ./resources/koboldcpp-mac-arm64 chmod +x ./resources/koboldcpp-mac-arm64
-
Clone the repository or download and extract the ZIP file
-
Install Python 3.8 or higher if not already installed. Use your distribution's package manager, for example on Ubuntu:
sudo apt-get update sudo apt-get install python3 python3-pip -
Install ExifTool. On Ubuntu:
sudo apt-get install libimage-exiftool-perl -
Run the script:
./llmii.sh -
If KoboldCpp fails to run, open a terminal in the 'resources' folder:
chmod +x ./resources/koboldcpp-linux-x64
-
Launch the LLMII GUI:
- On Windows: Run
llmii-windows.bat - On macOS/Linux: Run
./llmii.sh
- On Windows: Run
-
Ensure KoboldCPP is running. Wait until you see the following message in the KoboldCPP window:
Please connect to custom endpoint at http://localhost:5001 -
Configure the indexing settings in the GUI
-
Click "Run Image Indexer" to start the process
-
Monitor the progress in the output area of the GUI.
Press the HELP button in the settings dialog.
Consult the wiki for detailed information.
Contributions are welcome! Please feel free to submit a Pull Request.
This project is licensed under the GPLv3 License - see the LICENSE file for details.
- ExifTool for metadata manipulation
- KoboldCPP for local AI processing and for the GPU information logic
- PyQt6 for the GUI framework
- Fix Busted JSON and Json Repair for help with mangled JSON parsing
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ImageIndexer
Similar Open Source Tools
ImageIndexer
LLMII is a tool that uses a local AI model to label metadata and index images without relying on cloud services or remote APIs. It runs a visual language model on your computer to generate captions and keywords for images, enhancing their metadata for indexing, searching, and organization. The tool can be run multiple times on the same image files, allowing for adding new data, regenerating data, and discovering files with issues. It supports various image formats, offers a user-friendly GUI, and can utilize GPU acceleration for faster processing. LLMII requires Python 3.8 or higher and operates directly on image file metadata fields like MWG:Keyword and XMP:Identifier.
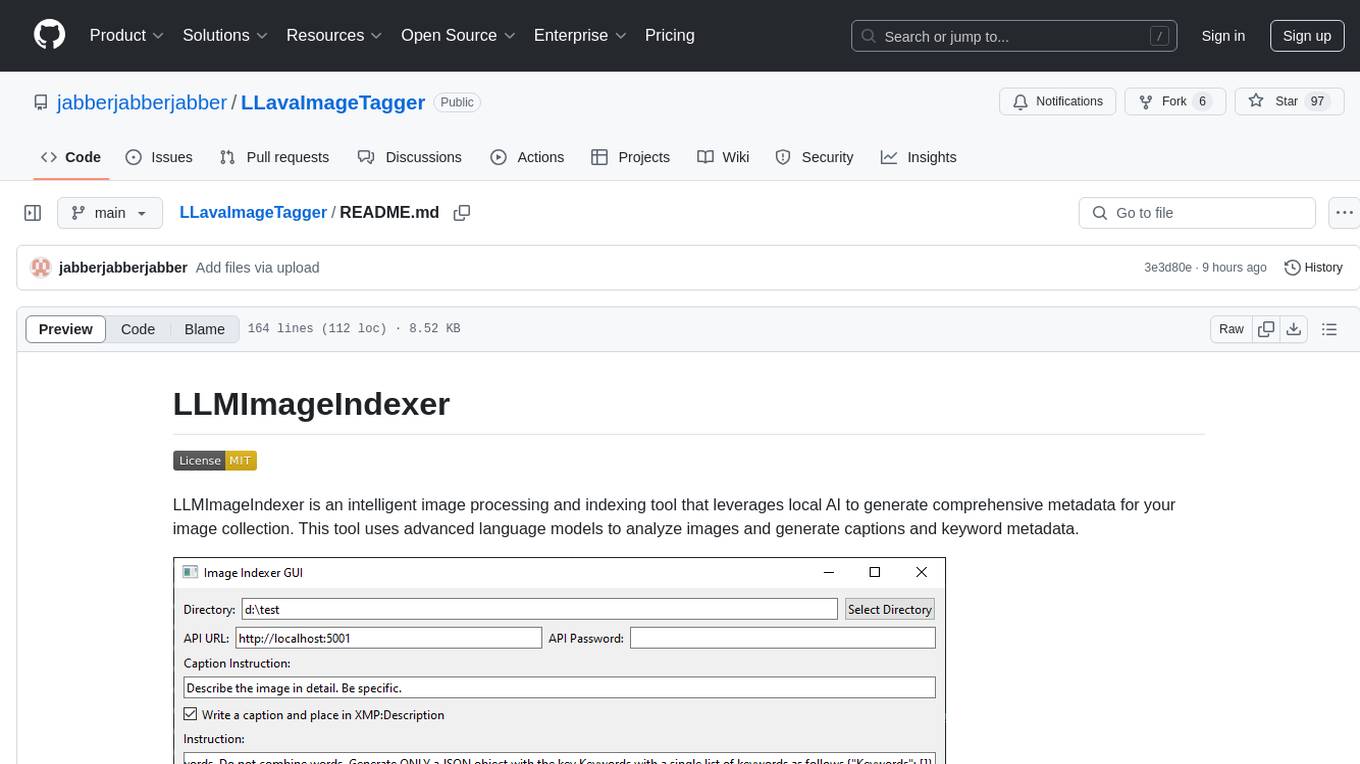
LLavaImageTagger
LLMImageIndexer is an intelligent image processing and indexing tool that leverages local AI to generate comprehensive metadata for your image collection. It uses advanced language models to analyze images and generate captions and keyword metadata. The tool offers features like intelligent image analysis, metadata enhancement, local processing, multi-format support, user-friendly GUI, GPU acceleration, cross-platform support, stop and start capability, and keyword post-processing. It operates directly on image file metadata, allowing users to manage files, add new files, and run the tool multiple times without reprocessing previously keyworded files. Installation instructions are provided for Windows, macOS, and Linux platforms, along with usage guidelines and configuration options.
CyberScraper-2077
CyberScraper 2077 is an advanced web scraping tool powered by AI, designed to extract data from websites with precision and style. It offers a user-friendly interface, supports multiple data export formats, operates in stealth mode to avoid detection, and promises lightning-fast scraping. The tool respects ethical scraping practices, including robots.txt and site policies. With upcoming features like proxy support and page navigation, CyberScraper 2077 is a futuristic solution for data extraction in the digital realm.

Open_Data_QnA
Open Data QnA is a Python library that allows users to interact with their PostgreSQL or BigQuery databases in a conversational manner, without needing to write SQL queries. The library leverages Large Language Models (LLMs) to bridge the gap between human language and database queries, enabling users to ask questions in natural language and receive informative responses. It offers features such as conversational querying with multiturn support, table grouping, multi schema/dataset support, SQL generation, query refinement, natural language responses, visualizations, and extensibility. The library is built on a modular design and supports various components like Database Connectors, Vector Stores, and Agents for SQL generation, validation, debugging, descriptions, embeddings, responses, and visualizations.
Local-Multimodal-AI-Chat
Local Multimodal AI Chat is a multimodal chat application that integrates various AI models to manage audio, images, and PDFs seamlessly within a single interface. It offers local model processing with Ollama for data privacy, integration with OpenAI API for broader AI capabilities, audio chatting with Whisper AI for accurate voice interpretation, and PDF chatting with Chroma DB for efficient PDF interactions. The application is designed for AI enthusiasts and developers seeking a comprehensive solution for multimodal AI technologies.
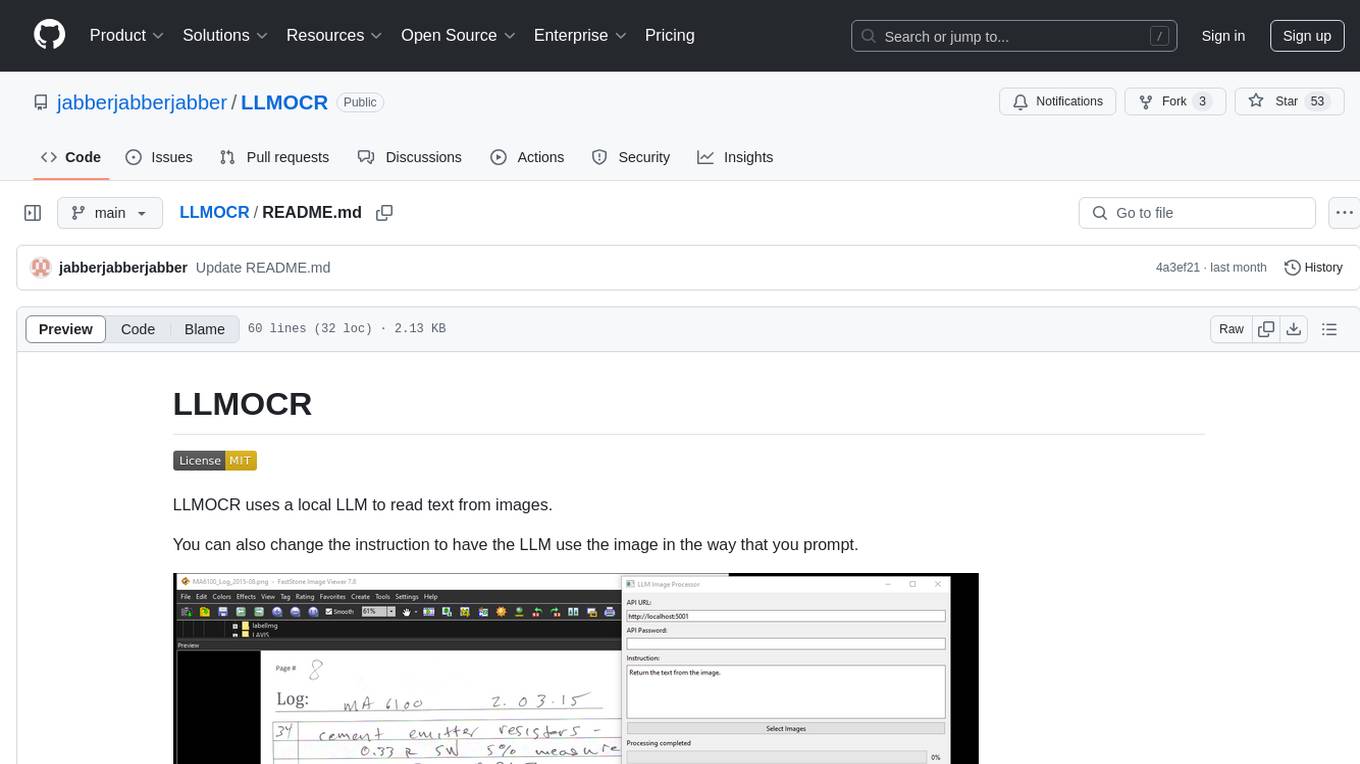
LLMOCR
LLMOCR is a tool that utilizes a local Large Language Model (LLM) to extract text from images. It offers a user-friendly GUI and supports GPU acceleration for faster inference. The tool is cross-platform, compatible with Windows, macOS ARM, and Linux. Users can prompt the LLM to process images in a customized way. The processing is done locally on the user's machine, ensuring data privacy and security. LLMOCR requires Python 3.8 or higher and KoboldCPP for installation and operation.
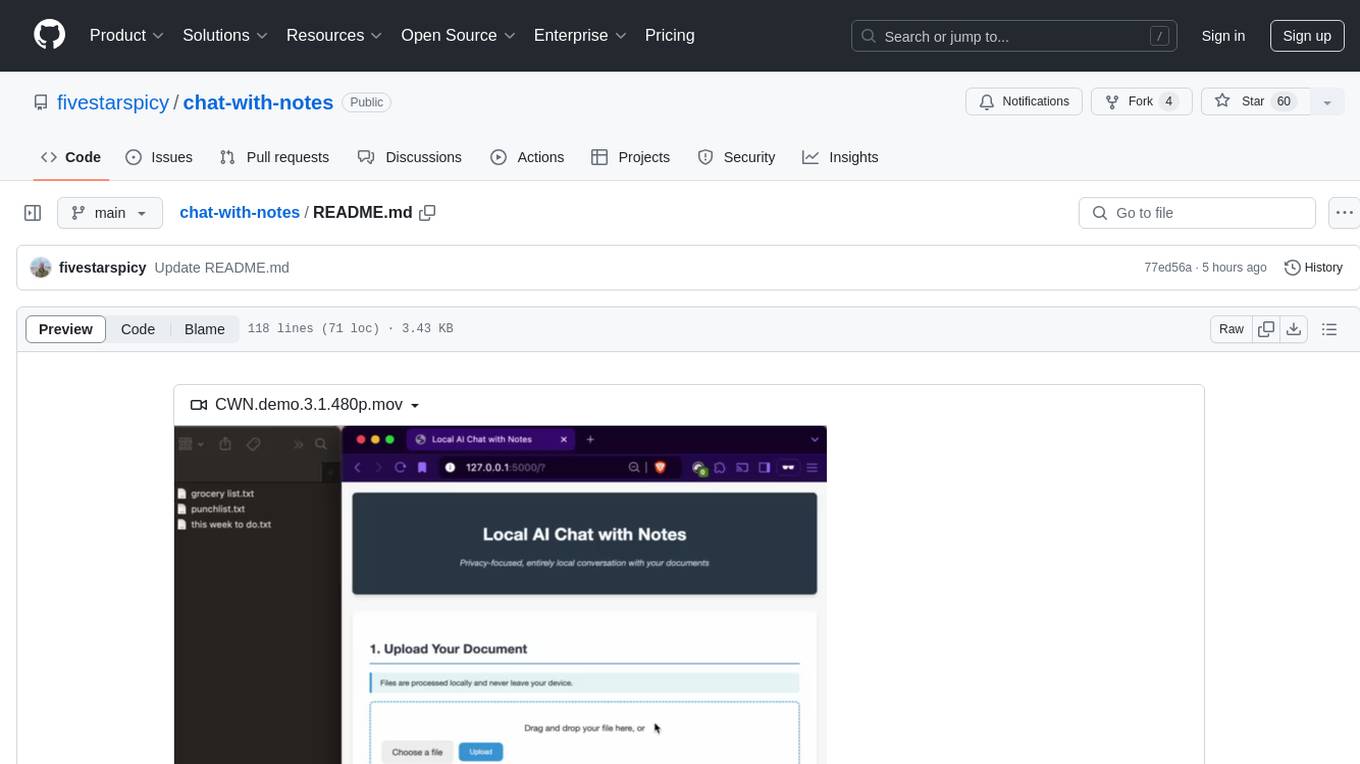
chat-with-notes
Chat-with-Notes is a Flask web application that enables users to upload text files, view their content, and engage with an AI chatbot for discussions. The application prioritizes privacy by utilizing a locally hosted Ollama Llama 3.1 (8B) model for AI responses, ensuring data security. Users can upload files during conversations, clear chat history, and export chat logs. The tool operates locally, requiring Python 3.x, pip, Git, and a locally running Ollama Llama 3.1 (8B) model as prerequisites.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

CLIPPyX
CLIPPyX is a powerful system-wide image search and management tool that offers versatile search options to find images based on their content, text, and visual similarity. With advanced features, users can effortlessly locate desired images across their entire computer's disk(s), regardless of their location or file names. The tool utilizes OpenAI's CLIP for image embeddings and text-based search, along with OCR for extracting text from images. It also employs Voidtools Everything SDK to list paths of all images on the system. CLIPPyX server receives search queries and queries collections of image embeddings and text embeddings to return relevant images.

azure-search-openai-demo
This sample demonstrates a few approaches for creating ChatGPT-like experiences over your own data using the Retrieval Augmented Generation pattern. It uses Azure OpenAI Service to access a GPT model (gpt-35-turbo), and Azure AI Search for data indexing and retrieval. The repo includes sample data so it's ready to try end to end. In this sample application we use a fictitious company called Contoso Electronics, and the experience allows its employees to ask questions about the benefits, internal policies, as well as job descriptions and roles.

vector-vein
VectorVein is a no-code AI workflow software inspired by LangChain and langflow, aiming to combine the powerful capabilities of large language models and enable users to achieve intelligent and automated daily workflows through simple drag-and-drop actions. Users can create powerful workflows without the need for programming, automating all tasks with ease. The software allows users to define inputs, outputs, and processing methods to create customized workflow processes for various tasks such as translation, mind mapping, summarizing web articles, and automatic categorization of customer reviews.
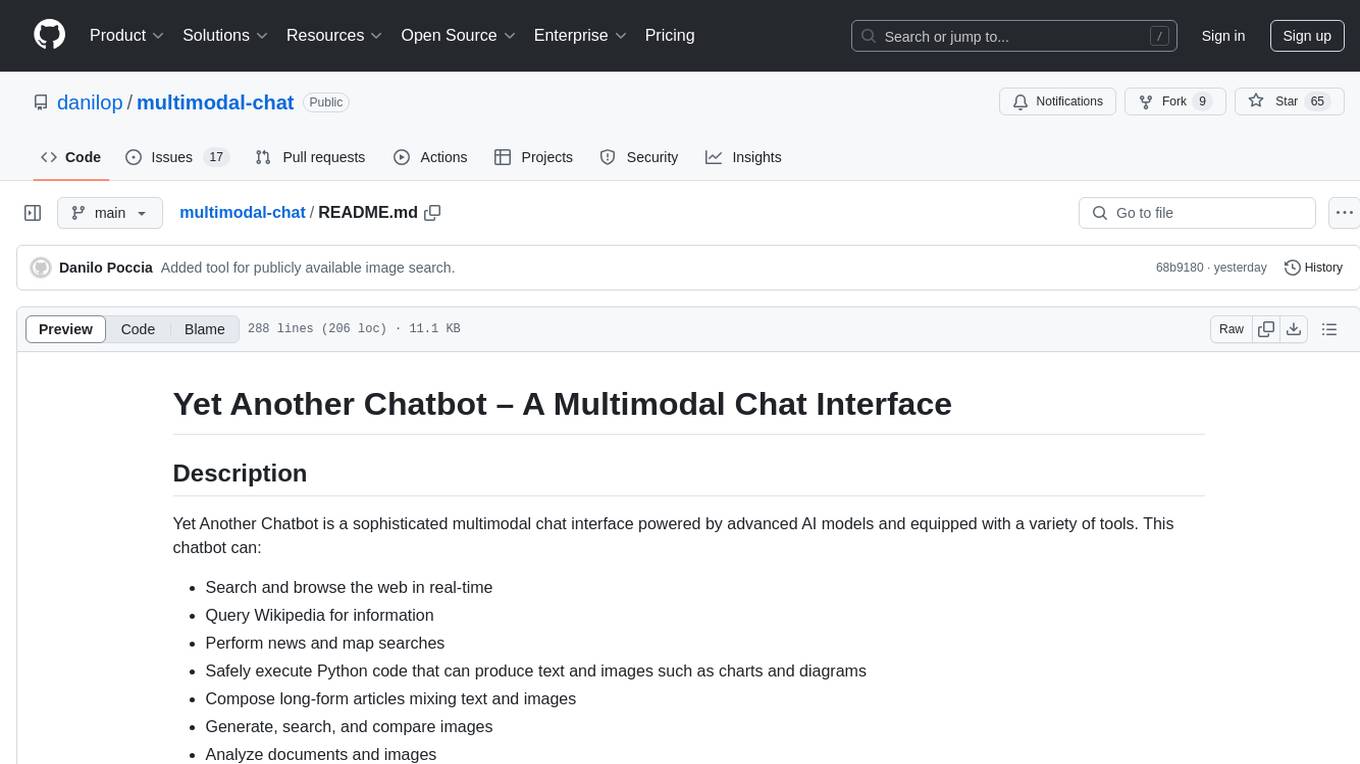
multimodal-chat
Yet Another Chatbot is a sophisticated multimodal chat interface powered by advanced AI models and equipped with a variety of tools. This chatbot can search and browse the web in real-time, query Wikipedia for information, perform news and map searches, execute Python code, compose long-form articles mixing text and images, generate, search, and compare images, analyze documents and images, search and download arXiv papers, save conversations as text and audio files, manage checklists, and track personal improvements. It offers tools for web interaction, Wikipedia search, Python scripting, content management, image handling, arXiv integration, conversation generation, file management, personal improvement, and checklist management.

coral-cloud
Coral Cloud Resorts is a sample hospitality application that showcases Data Cloud, Agents, and Prompts. It provides highly personalized guest experiences through smart automation, content generation, and summarization. The app requires licenses for Data Cloud, Agents, Prompt Builder, and Einstein for Sales. Users can activate features, deploy metadata, assign permission sets, import sample data, and troubleshoot common issues. Additionally, the repository offers integration with modern web development tools like Prettier, ESLint, and pre-commit hooks for code formatting and linting.
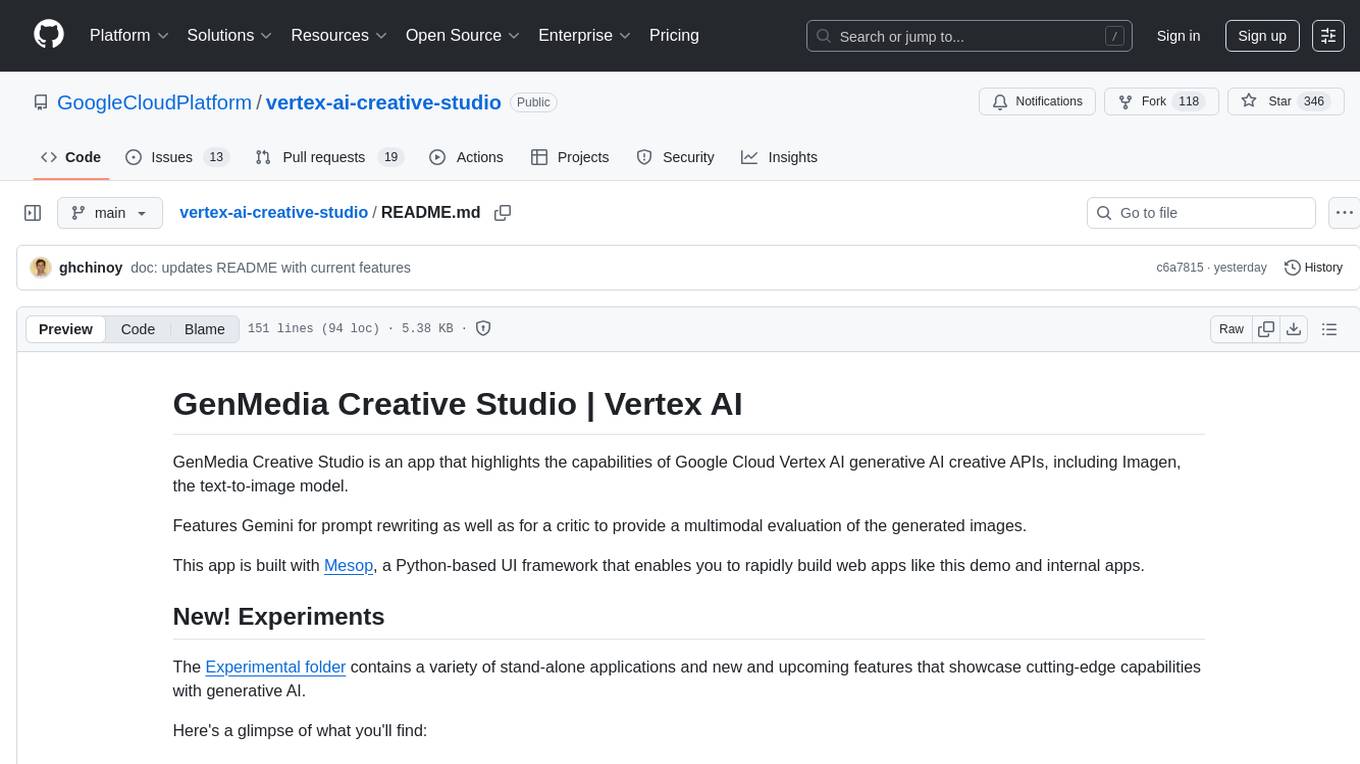
vertex-ai-creative-studio
GenMedia Creative Studio is an application showcasing the capabilities of Google Cloud Vertex AI generative AI creative APIs. It includes features like Gemini for prompt rewriting and multimodal evaluation of generated images. The app is built with Mesop, a Python-based UI framework, enabling rapid development of web and internal apps. The Experimental folder contains stand-alone applications and upcoming features demonstrating cutting-edge generative AI capabilities, such as image generation, prompting techniques, and audio/video tools.
burpference
Burpference is an open-source extension designed to capture in-scope HTTP requests and responses from Burp's proxy history and send them to a remote LLM API in JSON format. It automates response capture, integrates with APIs, optimizes resource usage, provides color-coded findings visualization, offers comprehensive logging, supports native Burp reporting, and allows flexible configuration. Users can customize system prompts, API keys, and remote hosts, and host models locally to prevent high inference costs. The tool is ideal for offensive web application engagements to surface findings and vulnerabilities.
litlytics
LitLytics is an affordable analytics platform leveraging LLMs for automated data analysis. It simplifies analytics for teams without data scientists, generates custom pipelines, and allows customization. Cost-efficient with low data processing costs. Scalable and flexible, works with CSV, PDF, and plain text data formats.
For similar tasks
ImageIndexer
LLMII is a tool that uses a local AI model to label metadata and index images without relying on cloud services or remote APIs. It runs a visual language model on your computer to generate captions and keywords for images, enhancing their metadata for indexing, searching, and organization. The tool can be run multiple times on the same image files, allowing for adding new data, regenerating data, and discovering files with issues. It supports various image formats, offers a user-friendly GUI, and can utilize GPU acceleration for faster processing. LLMII requires Python 3.8 or higher and operates directly on image file metadata fields like MWG:Keyword and XMP:Identifier.

NanoLLM
NanoLLM is a tool designed for optimized local inference for Large Language Models (LLMs) using HuggingFace-like APIs. It supports quantization, vision/language models, multimodal agents, speech, vector DB, and RAG. The tool aims to provide efficient and effective processing for LLMs on local devices, enhancing performance and usability for various AI applications.

HPT
Hyper-Pretrained Transformers (HPT) is a novel multimodal LLM framework from HyperGAI, trained for vision-language models capable of understanding both textual and visual inputs. The repository contains the open-source implementation of inference code to reproduce the evaluation results of HPT Air on different benchmarks. HPT has achieved competitive results with state-of-the-art models on various multimodal LLM benchmarks. It offers models like HPT 1.5 Air and HPT 1.0 Air, providing efficient solutions for vision-and-language tasks.

mlx-vlm
MLX-VLM is a package designed for running Vision LLMs on Mac systems using MLX. It provides a convenient way to install and utilize the package for processing large language models related to vision tasks. The tool simplifies the process of running LLMs on Mac computers, offering a seamless experience for users interested in leveraging MLX for vision-related projects.

lightllm
LightLLM is a Python-based LLM (Large Language Model) inference and serving framework known for its lightweight design, scalability, and high-speed performance. It offers features like tri-process asynchronous collaboration, Nopad for efficient attention operations, dynamic batch scheduling, FlashAttention integration, tensor parallelism, Token Attention for zero memory waste, and Int8KV Cache. The tool supports various models like BLOOM, LLaMA, StarCoder, Qwen-7b, ChatGLM2-6b, Baichuan-7b, Baichuan2-7b, Baichuan2-13b, InternLM-7b, Yi-34b, Qwen-VL, Llava-7b, Mixtral, Stablelm, and MiniCPM. Users can deploy and query models using the provided server launch commands and interact with multimodal models like QWen-VL and Llava using specific queries and images.

MotionLLM
MotionLLM is a framework for human behavior understanding that leverages Large Language Models (LLMs) to jointly model videos and motion sequences. It provides a unified training strategy, dataset MoVid, and MoVid-Bench for evaluating human behavior comprehension. The framework excels in captioning, spatial-temporal comprehension, and reasoning abilities.
Vitron
Vitron is a unified pixel-level vision LLM designed for comprehensive understanding, generating, segmenting, and editing static images and dynamic videos. It addresses challenges in existing vision LLMs such as superficial instance-level understanding, lack of unified support for images and videos, and insufficient coverage across various vision tasks. The tool requires Python >= 3.8, Pytorch == 2.1.0, and CUDA Version >= 11.8 for installation. Users can deploy Gradio demo locally and fine-tune their models for specific tasks.
awesome-sound_event_detection
The 'awesome-sound_event_detection' repository is a curated reading list focusing on sound event detection and Sound AI. It includes research papers covering various sub-areas such as learning formulation, network architecture, pooling functions, missing or noisy audio, data augmentation, representation learning, multi-task learning, few-shot learning, zero-shot learning, knowledge transfer, polyphonic sound event detection, loss functions, audio and visual tasks, audio captioning, audio retrieval, audio generation, and more. The repository provides a comprehensive collection of papers, datasets, and resources related to sound event detection and Sound AI, making it a valuable reference for researchers and practitioners in the field.
For similar jobs
ImageIndexer
LLMII is a tool that uses a local AI model to label metadata and index images without relying on cloud services or remote APIs. It runs a visual language model on your computer to generate captions and keywords for images, enhancing their metadata for indexing, searching, and organization. The tool can be run multiple times on the same image files, allowing for adding new data, regenerating data, and discovering files with issues. It supports various image formats, offers a user-friendly GUI, and can utilize GPU acceleration for faster processing. LLMII requires Python 3.8 or higher and operates directly on image file metadata fields like MWG:Keyword and XMP:Identifier.
DiffusionToolkit
Diffusion Toolkit is an image metadata-indexer and viewer for AI-generated images. It helps you organize, search, and sort your ever-growing collection. Key features include: - Scanning images and storing prompts and other metadata (PNGInfo) - Searching for images using simple queries or filters - Viewing images and metadata easily - Tagging images with favorites, ratings, and NSFW flags - Sorting images by date created, aesthetic score, or rating - Auto-tagging NSFW images by keywords - Blurring images tagged as NSFW - Creating and managing albums - Viewing and searching prompts - Drag-and-drop functionality Diffusion Toolkit supports various image formats, including JPG/JPEG, PNG, WebP, and TXT metadata. It also supports metadata formats from popular AI image generators like AUTOMATIC1111, InvokeAI, NovelAI, Stable Diffusion, and more. You can use Diffusion Toolkit even on images without metadata and still enjoy features like rating and album management.
pictureChange
The 'pictureChange' repository is a plugin that supports image processing using Baidu AI, stable diffusion webui, and suno music composition AI. It also allows for file summarization and image summarization using AI. The plugin supports various stable diffusion models, administrator control over group chat features, concurrent control, and custom templates for image and text generation. It can be deployed on WeChat enterprise accounts, personal accounts, and public accounts.