
HPT
HPT - Open Multimodal LLMs from HyperGAI
Stars: 236

Hyper-Pretrained Transformers (HPT) is a novel multimodal LLM framework from HyperGAI, trained for vision-language models capable of understanding both textual and visual inputs. The repository contains the open-source implementation of inference code to reproduce the evaluation results of HPT Air on different benchmarks. HPT has achieved competitive results with state-of-the-art models on various multimodal LLM benchmarks. It offers models like HPT 1.5 Air and HPT 1.0 Air, providing efficient solutions for vision-and-language tasks.
README:
Hyper-Pretrained Transformers (HPT) is a novel multimodal LLM framework from HyperGAI, and has been trained for vision-language models that are capable of understanding both textual and visual inputs. HPT has achieved highly competitive results with state-of-the-art models on a variety of multimodal LLM benchmarks. This repository contains the open-source implementation of inference code to reproduce the evaluation results of HPT Air on different benchmarks.
- [5/03] 🔥 Releasing HPT 1.5 Air, our best open-sourced 8B Multimodal LLM with Llama 3. Built with Meta Llama 3, Our hyper capable HPT 1.5 Air packs a punch on real world understanding and complex reasoning. HPT Air 1.5 achieves the best results among <10B models across a wide range of challenging benchmarks (MMMU, POPE, SEED-I, and more). HPT 1.5 Air is publicly available on [HuggingFace Repository] and [GitHub]. Please read our our [technical blog post] for more details.
- [3/16] HPT 1.0 Air is out, our most efficient model as a cost-effective solution that is capable of solving a wide range of vision-and-language tasks. HPT 1.0 Air is publicly available and achieves state-of-the-art results among all the open-source multimodal LLM models of similar or smaller sizes on the challenging MMMU benchmark. Please read our [technical blog post] and [HuggingFace Repository] for more details.
- Overview of Model Achitecture
- Quick Start
- Evaluations
- Benchmarks
- Pretrained Models Used
- Disclaimer and Responsible Use
- Contact Us
- License
- Acknowledgements

pip install -r requirements.txt
pip install -e .
You can download the model weights from HF into your [Local Path] and set the global_model_path as your [Local Path] in the model config file:
git lfs install
git clone https://huggingface.co/HyperGAI/HPT [Local Path]
or directly set global_model_path as the HF repo-id ('HyperGAI/HPT').
You can also set other strategies in the config file that are different from our default settings.
After setting up the config file, launch the model demo for a quick trial:
python demo/demo.py --image_path [Image] --text [Text] --model [Config]
Example:
python demo/demo.py --image_path demo/einstein.jpg --text 'Question: What is unusual about this image?\nAnswer:' --model hpt-air-demo
You can design different prompts here to boost the question.
Launch the model for evaluation:
torchrun --nproc-per-node=8 run.py --data [Dataset] --model [Config]
Example for HPT 1.5 Air:
torchrun --nproc-per-node=8 run.py --data MMMU_DEV_VAL --model hpt-air-1-5
For HPT 1.5 Air

HPT 1.5 Air
-
Pretrained LLM: Llama3-8B-Instruct
-
Pretrained Visual Encoder: siglip-so400m-patch14-384
HPT 1.0 Air
-
Pretrained LLM: Yi-6B-Chat
-
Pretrained Visual Encoder: clip-vit-large-patch14-336
Note that the HPT Air is a quick open release of our models to facilitate the open, responsible AI research and community development. It does not have any moderation mechanism and provides no guarantees on their results. We hope to engage with the community to make the model finely respect guardrails to allow practical adoptions in real-world applications requiring moderated outputs.
- Contact: [email protected]
- Follow us on Twitter.
- Follow us on Linkedin.
- Visit our website to learn more about us.
This project is released under the Apache 2.0 license. Parts of this project contain code and models from other sources, which are subject to their respective licenses and you need to apply their respective license if you want to use for commercial purposes.
The evaluation code for running this demo was extended based on the VLMEvalKit project. We also thank OpenAI for open-sourcing their visual encoder models and 01.AI and Meta for open-sourcing their large language models.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for HPT
Similar Open Source Tools
HPT
Hyper-Pretrained Transformers (HPT) is a novel multimodal LLM framework from HyperGAI, trained for vision-language models capable of understanding both textual and visual inputs. The repository contains the open-source implementation of inference code to reproduce the evaluation results of HPT Air on different benchmarks. HPT has achieved competitive results with state-of-the-art models on various multimodal LLM benchmarks. It offers models like HPT 1.5 Air and HPT 1.0 Air, providing efficient solutions for vision-and-language tasks.

magpie
This is the official repository for 'Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing'. Magpie is a tool designed to synthesize high-quality instruction data at scale by extracting it directly from an aligned Large Language Models (LLMs). It aims to democratize AI by generating large-scale alignment data and enhancing the transparency of model alignment processes. Magpie has been tested on various model families and can be used to fine-tune models for improved performance on alignment benchmarks such as AlpacaEval, ArenaHard, and WildBench.

long-llms-learning
A repository sharing the panorama of the methodology literature on Transformer architecture upgrades in Large Language Models for handling extensive context windows, with real-time updating the newest published works. It includes a survey on advancing Transformer architecture in long-context large language models, flash-ReRoPE implementation, latest news on data engineering, lightning attention, Kimi AI assistant, chatglm-6b-128k, gpt-4-turbo-preview, benchmarks like InfiniteBench and LongBench, long-LLMs-evals for evaluating methods for enhancing long-context capabilities, and LLMs-learning for learning technologies and applicated tasks about Large Language Models.
model2vec
Model2Vec is a technique to turn any sentence transformer into a really small static model, reducing model size by 15x and making the models up to 500x faster, with a small drop in performance. It outperforms other static embedding models like GLoVe and BPEmb, is lightweight with only `numpy` as a major dependency, offers fast inference, dataset-free distillation, and is integrated into Sentence Transformers, txtai, and Chonkie. Model2Vec creates powerful models by passing a vocabulary through a sentence transformer model, reducing dimensionality using PCA, and weighting embeddings using zipf weighting. Users can distill their own models or use pre-trained models from the HuggingFace hub. Evaluation can be done using the provided evaluation package. Model2Vec is licensed under MIT.

R1-Searcher
R1-searcher is a tool designed to incentivize the search capability in large reasoning models (LRMs) via reinforcement learning. It enables LRMs to invoke web search and obtain external information during the reasoning process by utilizing a two-stage outcome-supervision reinforcement learning approach. The tool does not require instruction fine-tuning for cold start and is compatible with existing Base LLMs or Chat LLMs. It includes training code, inference code, model checkpoints, and a detailed technical report.

MME-RealWorld
MME-RealWorld is a benchmark designed to address real-world applications with practical relevance, featuring 13,366 high-resolution images and 29,429 annotations across 43 tasks. It aims to provide substantial recognition challenges and overcome common barriers in existing Multimodal Large Language Model benchmarks, such as small data scale, restricted data quality, and insufficient task difficulty. The dataset offers advantages in data scale, data quality, task difficulty, and real-world utility compared to existing benchmarks. It also includes a Chinese version with additional images and QA pairs focused on Chinese scenarios.

CogVideo
CogVideo is an open-source repository that provides pretrained text-to-video models for generating videos based on input text. It includes models like CogVideoX-2B and CogVideo, offering powerful video generation capabilities. The repository offers tools for inference, fine-tuning, and model conversion, along with demos showcasing the model's capabilities through CLI, web UI, and online experiences. CogVideo aims to facilitate the creation of high-quality videos from textual descriptions, catering to a wide range of applications.

MiniCheck
MiniCheck is an efficient fact-checking tool designed to verify claims against grounding documents using large language models. It provides a sentence-level fact-checking model that can be used to evaluate the consistency of claims with the provided documents. MiniCheck offers different models, including Bespoke-MiniCheck-7B, which is the state-of-the-art and commercially usable. The tool enables users to fact-check multi-sentence claims by breaking them down into individual sentences for optimal performance. It also supports automatic prefix caching for faster inference when repeatedly fact-checking the same document with different claims.

OREAL
OREAL is a reinforcement learning framework designed for mathematical reasoning tasks, aiming to achieve optimal performance through outcome reward-based learning. The framework utilizes behavior cloning, reshaping rewards, and token-level reward models to address challenges in sparse rewards and partial correctness. OREAL has achieved significant results, with a 7B model reaching 94.0 pass@1 accuracy on MATH-500 and surpassing previous 32B models. The tool provides training tutorials and Hugging Face model repositories for easy access and implementation.

SwiftSage
SwiftSage is a tool designed for conducting experiments in the field of machine learning and artificial intelligence. It provides a platform for researchers and developers to implement and test various algorithms and models. The tool is particularly useful for exploring new ideas and conducting experiments in a controlled environment. SwiftSage aims to streamline the process of developing and testing machine learning models, making it easier for users to iterate on their ideas and achieve better results. With its user-friendly interface and powerful features, SwiftSage is a valuable tool for anyone working in the field of AI and ML.

Vision-LLM-Alignment
Vision-LLM-Alignment is a repository focused on implementing alignment training for visual large language models (LLMs), including SFT training, reward model training, and PPO/DPO training. It supports various model architectures and provides datasets for training. The repository also offers benchmark results and installation instructions for users.
aligner
Aligner is a model-agnostic alignment tool that learns correctional residuals between preferred and dispreferred answers using a small model. It can be directly applied to various open-source and API-based models with only one-off training, suitable for rapid iteration and improving model performance. Aligner has shown significant improvements in helpfulness, harmlessness, and honesty dimensions across different large language models.

Woodpecker
Woodpecker is a tool designed to correct hallucinations in Multimodal Large Language Models (MLLMs) by introducing a training-free method that picks out and corrects inconsistencies between generated text and image content. It consists of five stages: key concept extraction, question formulation, visual knowledge validation, visual claim generation, and hallucination correction. Woodpecker can be easily integrated with different MLLMs and provides interpretable results by accessing intermediate outputs of the stages. The tool has shown significant improvements in accuracy over baseline models like MiniGPT-4 and mPLUG-Owl.
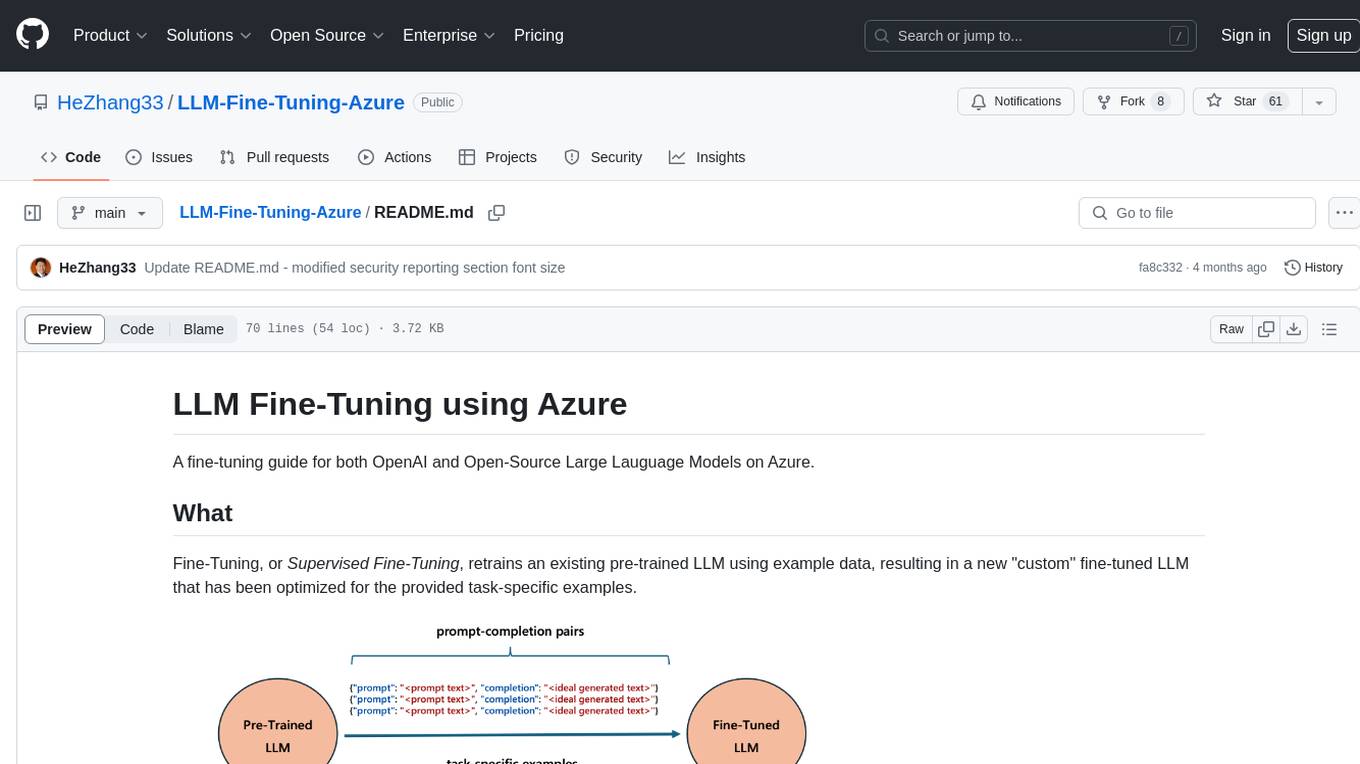
LLM-Fine-Tuning-Azure
A fine-tuning guide for both OpenAI and Open-Source Large Language Models on Azure. Fine-Tuning retrains an existing pre-trained LLM using example data, resulting in a new 'custom' fine-tuned LLM optimized for task-specific examples. Use cases include improving LLM performance on specific tasks and introducing information not well represented by the base LLM model. Suitable for cases where latency is critical, high accuracy is required, and clear evaluation metrics are available. Learning path includes labs for fine-tuning GPT and Llama2 models via Dashboards and Python SDK.

aimo-progress-prize
This repository contains the training and inference code needed to replicate the winning solution to the AI Mathematical Olympiad - Progress Prize 1. It consists of fine-tuning DeepSeekMath-Base 7B, high-quality training datasets, a self-consistency decoding algorithm, and carefully chosen validation sets. The training methodology involves Chain of Thought (CoT) and Tool Integrated Reasoning (TIR) training stages. Two datasets, NuminaMath-CoT and NuminaMath-TIR, were used to fine-tune the models. The models were trained using open-source libraries like TRL, PyTorch, vLLM, and DeepSpeed. Post-training quantization to 8-bit precision was done to improve performance on Kaggle's T4 GPUs. The project structure includes scripts for training, quantization, and inference, along with necessary installation instructions and hardware/software specifications.

raga-llm-hub
Raga LLM Hub is a comprehensive evaluation toolkit for Language and Learning Models (LLMs) with over 100 meticulously designed metrics. It allows developers and organizations to evaluate and compare LLMs effectively, establishing guardrails for LLMs and Retrieval Augmented Generation (RAG) applications. The platform assesses aspects like Relevance & Understanding, Content Quality, Hallucination, Safety & Bias, Context Relevance, Guardrails, and Vulnerability scanning, along with Metric-Based Tests for quantitative analysis. It helps teams identify and fix issues throughout the LLM lifecycle, revolutionizing reliability and trustworthiness.
For similar tasks
HPT
Hyper-Pretrained Transformers (HPT) is a novel multimodal LLM framework from HyperGAI, trained for vision-language models capable of understanding both textual and visual inputs. The repository contains the open-source implementation of inference code to reproduce the evaluation results of HPT Air on different benchmarks. HPT has achieved competitive results with state-of-the-art models on various multimodal LLM benchmarks. It offers models like HPT 1.5 Air and HPT 1.0 Air, providing efficient solutions for vision-and-language tasks.

learnopencv
LearnOpenCV is a repository containing code for Computer Vision, Deep learning, and AI research articles shared on the blog LearnOpenCV.com. It serves as a resource for individuals looking to enhance their expertise in AI through various courses offered by OpenCV. The repository includes a wide range of topics such as image inpainting, instance segmentation, robotics, deep learning models, and more, providing practical implementations and code examples for readers to explore and learn from.

spark-free-api
Spark AI Free 服务 provides high-speed streaming output, multi-turn dialogue support, AI drawing support, long document interpretation, and image parsing. It offers zero-configuration deployment, multi-token support, and automatic session trace cleaning. It is fully compatible with the ChatGPT interface. The repository includes multiple free-api projects for various AI services. Users can access the API for tasks such as chat completions, AI drawing, document interpretation, image analysis, and ssoSessionId live checking. The project also provides guidelines for deployment using Docker, Docker-compose, Render, Vercel, and native deployment methods. It recommends using custom clients for faster and simpler access to the free-api series projects.

mlx-vlm
MLX-VLM is a package designed for running Vision LLMs on Mac systems using MLX. It provides a convenient way to install and utilize the package for processing large language models related to vision tasks. The tool simplifies the process of running LLMs on Mac computers, offering a seamless experience for users interested in leveraging MLX for vision-related projects.

clarifai-python-grpc
This is the official Clarifai gRPC Python client for interacting with their recognition API. Clarifai offers a platform for data scientists, developers, researchers, and enterprises to utilize artificial intelligence for image, video, and text analysis through computer vision and natural language processing. The client allows users to authenticate, predict concepts in images, and access various functionalities provided by the Clarifai API. It follows a versioning scheme that aligns with the backend API updates and includes specific instructions for installation and troubleshooting. Users can explore the Clarifai demo, sign up for an account, and refer to the documentation for detailed information.

horde-worker-reGen
This repository provides the latest implementation for the AI Horde Worker, allowing users to utilize their graphics card(s) to generate, post-process, or analyze images for others. It offers a platform where users can create images and earn 'kudos' in return, granting priority for their own image generations. The repository includes important details for setup, recommendations for system configurations, instructions for installation on Windows and Linux, basic usage guidelines, and information on updating the AI Horde Worker. Users can also run the worker with multiple GPUs and receive notifications for updates through Discord. Additionally, the repository contains models that are licensed under the CreativeML OpenRAIL License.

geospy
Geospy is a Python tool that utilizes Graylark's AI-powered geolocation service to determine the location where photos were taken. It allows users to analyze images and retrieve information such as country, city, explanation, coordinates, and Google Maps links. The tool provides a seamless way to integrate geolocation services into various projects and applications.

Awesome-Colorful-LLM
Awesome-Colorful-LLM is a meticulously assembled anthology of vibrant multimodal research focusing on advancements propelled by large language models (LLMs) in domains such as Vision, Audio, Agent, Robotics, and Fundamental Sciences like Mathematics. The repository contains curated collections of works, datasets, benchmarks, projects, and tools related to LLMs and multimodal learning. It serves as a comprehensive resource for researchers and practitioners interested in exploring the intersection of language models and various modalities for tasks like image understanding, video pretraining, 3D modeling, document understanding, audio analysis, agent learning, robotic applications, and mathematical research.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.