
hold
[CVPR 2024✨Highlight] Official repository for HOLD, the first method that jointly reconstructs articulated hands and objects from monocular videos without assuming a pre-scanned object template and 3D hand-object training data.
Stars: 255
This repository contains the code for HOLD, a method that jointly reconstructs hands and objects from monocular videos without assuming a pre-scanned object template. It can reconstruct 3D geometries of novel objects and hands, enabling template-free bimanual hand-object reconstruction, textureless object interaction with hands, and multiple objects interaction with hands. The repository provides instructions to download in-the-wild videos from HOLD, preprocess and train on custom videos, a volumetric rendering framework, a generalized codebase for single and two hand interaction with objects, a viewer to interact with predictions, and code to evaluate and compare with HOLD in HO3D. The repository also includes documentation for setup, training, evaluation, visualization, preprocessing custom sequences, and using HOLD on ARCTIC.
README:
[CVPR'24 Highlight] HOLD: Category-agnostic 3D Reconstruction of Interacting Hands and Objects from Video
![]()
[ Project Page ] [ Paper ] [ SupMat ] [ ArXiv ] [ Video ] [ HOLD Account ] [ ECCV'24 HOLD+ARCTIC Challenge ]
Authors: Zicong Fan, Maria Parelli, Maria Eleni Kadoglou, Muhammed Kocabas, Xu Chen, Michael J. Black, Otmar Hilliges
🚀 Register a HOLD account here for news such as code release, downloads, and future updates!
- 2024.07.04: Join our ECCV competition: Two hand + rigid object using HOLD on ARCTIC!
- 2024.07.04: HOLD beta is released!
- 2024.04.04: HOLD is awarded CVPR highlight!
- 2024.02.27: HOLD is accepted to CVPR'24! Working on code release!

This is a repository for HOLD, a method that jointly reconstructs hands and objects from monocular videos without assuming a pre-scanned object template.
HOLD can reconstruct 3D geometries of novel objects and hands:


- Template-free bimanual hand-object reconstruction
- Textureless object interaction with hands
- Multiple objects interaction with hands

- Instructions to download in-the-wild videos from HOLD as well as preprocessed data
- Scripts to preprocess and train on custom videos
- A volumetric rendering framework to reconstruct dynamic hand-object interaction
- A generalized codebase for single and two hand interaction with objects
- A viewer to interact with the prediction
- Code to evaluate and compare with HOLD in HO3D
- [ ] Tips on good reconstruction
- [ ] Clean the code further
- [X] Support arctic for two-hand + rigid object setting
- Setup environment and downloads: see
docs/setup.md - Training, evaluation, and visualization on preprocessed sequences: see
docs/usage.md - Preprocess custom sequences: see
docs/custom.md - Data documentation (checkpoints, dataset, log folder): see
docs/data_doc.md - Instructions for using HOLD on ARCTIC: see
docs/arctic.md
Get a copy of the code:
git clone https://github.com/zc-alexfan/hold.git
cd hold; git submodule update --init --recursive-
Setup environments
- Follow the instructions here:
docs/setup.md. - You may skip external dependencies for now.
- Follow the instructions here:
-
Train on a preprocessed sequence
- Start with one of our preprocessed in-the-wild sequences, such as
hold_bottle1_itw. - Familiarize yourself with the usage guidelines in
docs/usage.mdfor this preprocessed sequence. - This will enable you to train, render HOLD, and experiment with our interactive viewer.
- At this stage, you can also explore the HOLD code in the
./codedirectory.
- Start with one of our preprocessed in-the-wild sequences, such as
-
Set up external dependencies and process custom videos
- After understanding the initial tools, set up the "external dependencies" as outlined in
docs/setup.md. - Preprocess the images from the
hold_bottle1_itwsequence by following the instructions indocs/custom.md. - Train on this sequence to learn how to build a custom dataset.
- You can capture your own custom video and reconstruct it in 3D at this point.
- Most preprocessing artifact files are documented in
docs/data_doc.md, which you can use as a reference.
- After understanding the initial tools, set up the "external dependencies" as outlined in
-
Two-hand setting: Bimanual category-agnostic reconstruction
- At this point, you can preprocess and train on a custom single-hand sequence.
- Now you can take on the bimanual category-agnostic reconstruction challenge!
- Following the instruction in
docs/arctic.mdto reconstruct two-hand manipulation of ARCTIC sequences.
@inproceedings{fan2024hold,
title={{HOLD}: Category-agnostic 3d reconstruction of interacting hands and objects from video},
author={Fan, Zicong and Parelli, Maria and Kadoglou, Maria Eleni and Kocabas, Muhammed and Chen, Xu and Black, Michael J and Hilliges, Otmar},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={494--504},
year={2024}
}✨CVPR 2023: ARCTIC is a dataset that includes accurate body/hand/object poses, multi-view RGB videos for articulated object manipulation. See our project page for details.

For technical questions, please create an issue. For other questions, please contact the first author.
The authors would like to thank: Benjamin Pellkofer for IT/web support; Chen Guo, Egor Zakharov, Yao Feng, Artur Grigorev for insightful discussion; Yufei Ye for DiffHOI code release.
Our code benefits a lot from Vid2Avatar, aitviewer, VolSDF, NeRF++ and SNARF. If you find our work useful, consider checking out their work.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for hold
Similar Open Source Tools
hold
This repository contains the code for HOLD, a method that jointly reconstructs hands and objects from monocular videos without assuming a pre-scanned object template. It can reconstruct 3D geometries of novel objects and hands, enabling template-free bimanual hand-object reconstruction, textureless object interaction with hands, and multiple objects interaction with hands. The repository provides instructions to download in-the-wild videos from HOLD, preprocess and train on custom videos, a volumetric rendering framework, a generalized codebase for single and two hand interaction with objects, a viewer to interact with predictions, and code to evaluate and compare with HOLD in HO3D. The repository also includes documentation for setup, training, evaluation, visualization, preprocessing custom sequences, and using HOLD on ARCTIC.

Woodpecker
Woodpecker is a tool designed to correct hallucinations in Multimodal Large Language Models (MLLMs) by introducing a training-free method that picks out and corrects inconsistencies between generated text and image content. It consists of five stages: key concept extraction, question formulation, visual knowledge validation, visual claim generation, and hallucination correction. Woodpecker can be easily integrated with different MLLMs and provides interpretable results by accessing intermediate outputs of the stages. The tool has shown significant improvements in accuracy over baseline models like MiniGPT-4 and mPLUG-Owl.
MicroLens
MicroLens is a content-driven micro-video recommendation dataset at scale. It provides a large dataset with multimodal data, including raw text, images, audio, video, and video comments, for tasks such as multi-modal recommendation, foundation model building, and fairness recommendation. The dataset is available in two versions: MicroLens-50K and MicroLens-100K, with extracted features for multimodal recommendation tasks. Researchers can access the dataset through provided links and reach out to the corresponding author for the complete dataset. The repository also includes codes for various algorithms like VideoRec, IDRec, and VIDRec, each implementing different video models and baselines.

magpie
This is the official repository for 'Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing'. Magpie is a tool designed to synthesize high-quality instruction data at scale by extracting it directly from an aligned Large Language Models (LLMs). It aims to democratize AI by generating large-scale alignment data and enhancing the transparency of model alignment processes. Magpie has been tested on various model families and can be used to fine-tune models for improved performance on alignment benchmarks such as AlpacaEval, ArenaHard, and WildBench.
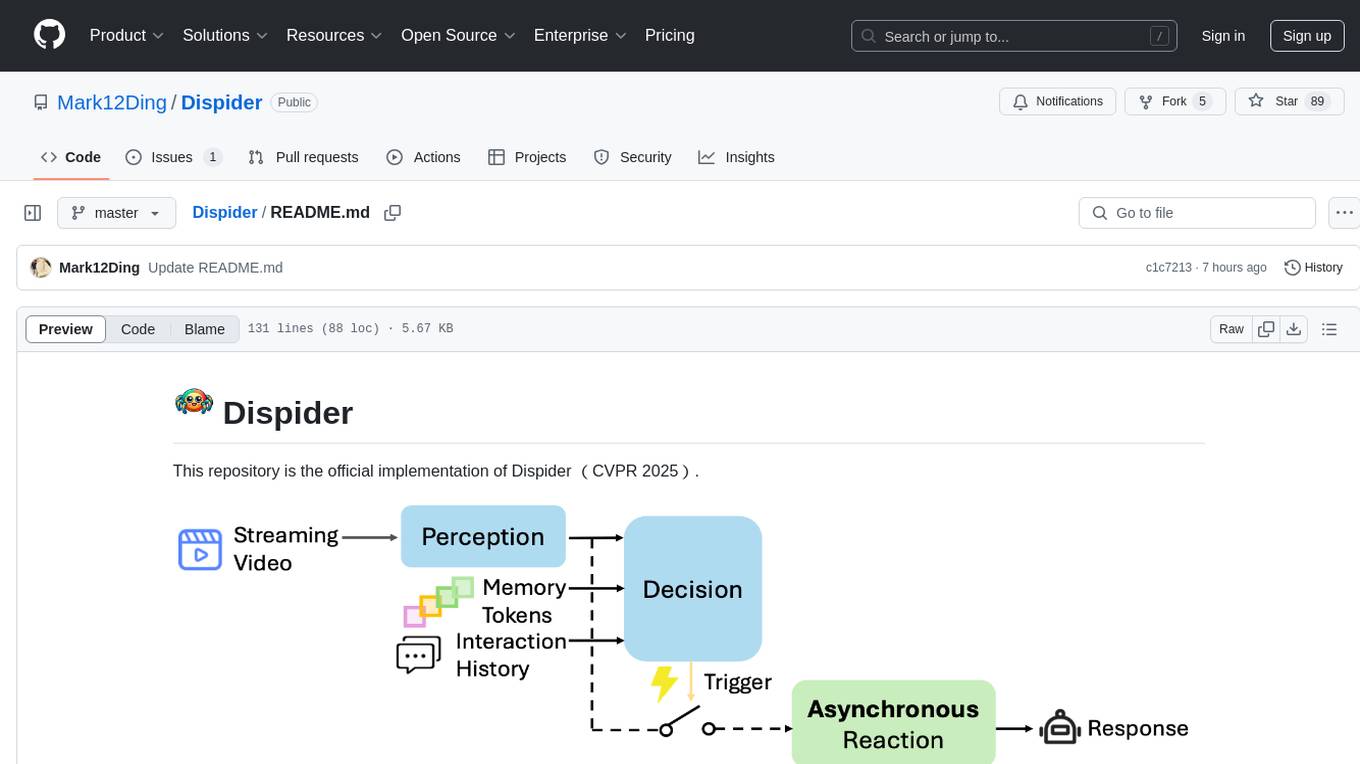
Dispider
Dispider is an implementation enabling real-time interactions with streaming videos, providing continuous feedback in live scenarios. It separates perception, decision-making, and reaction into asynchronous modules, ensuring timely interactions. Dispider outperforms VideoLLM-online on benchmarks like StreamingBench and excels in temporal reasoning. The tool requires CUDA 11.8 and specific library versions for optimal performance.

MARS5-TTS
MARS5 is a novel English speech model (TTS) developed by CAMB.AI, featuring a two-stage AR-NAR pipeline with a unique NAR component. The model can generate speech for various scenarios like sports commentary and anime with just 5 seconds of audio and a text snippet. It allows steering prosody using punctuation and capitalization in the transcript. Speaker identity is specified using an audio reference file, enabling 'deep clone' for improved quality. The model can be used via torch.hub or HuggingFace, supporting both shallow and deep cloning for inference. Checkpoints are provided for AR and NAR models, with hardware requirements of 750M+450M params on GPU. Contributions to improve model stability, performance, and reference audio selection are welcome.

MInference
MInference is a tool designed to accelerate pre-filling for long-context Language Models (LLMs) by leveraging dynamic sparse attention. It achieves up to a 10x speedup for pre-filling on an A100 while maintaining accuracy. The tool supports various decoding LLMs, including LLaMA-style models and Phi models, and provides custom kernels for attention computation. MInference is useful for researchers and developers working with large-scale language models who aim to improve efficiency without compromising accuracy.

DemoGPT
DemoGPT is an all-in-one agent library that provides tools, prompts, frameworks, and LLM models for streamlined agent development. It leverages GPT-3.5-turbo to generate LangChain code, creating interactive Streamlit applications. The tool is designed for creating intelligent, interactive, and inclusive solutions in LLM-based application development. It offers model flexibility, iterative development, and a commitment to user engagement. Future enhancements include integrating Gorilla for autonomous API usage and adding a publicly available database for refining the generation process.

merlin
Merlin is a groundbreaking model capable of generating natural language responses intricately linked with object trajectories of multiple images. It excels in predicting and reasoning about future events based on initial observations, showcasing unprecedented capability in future prediction and reasoning. Merlin achieves state-of-the-art performance on the Future Reasoning Benchmark and multiple existing multimodal language models benchmarks, demonstrating powerful multi-modal general ability and foresight minds.

MME-RealWorld
MME-RealWorld is a benchmark designed to address real-world applications with practical relevance, featuring 13,366 high-resolution images and 29,429 annotations across 43 tasks. It aims to provide substantial recognition challenges and overcome common barriers in existing Multimodal Large Language Model benchmarks, such as small data scale, restricted data quality, and insufficient task difficulty. The dataset offers advantages in data scale, data quality, task difficulty, and real-world utility compared to existing benchmarks. It also includes a Chinese version with additional images and QA pairs focused on Chinese scenarios.
nitrain
Nitrain is a framework for medical imaging AI that provides tools for sampling and augmenting medical images, training models on medical imaging datasets, and visualizing model results in a medical imaging context. It supports using pytorch, keras, and tensorflow.

ChatDev
ChatDev is a virtual software company powered by intelligent agents like CEO, CPO, CTO, programmer, reviewer, tester, and art designer. These agents collaborate to revolutionize the digital world through programming. The platform offers an easy-to-use, highly customizable, and extendable framework based on large language models, ideal for studying collective intelligence. ChatDev introduces innovative methods like Iterative Experience Refinement and Experiential Co-Learning to enhance software development efficiency. It supports features like incremental development, Docker integration, Git mode, and Human-Agent-Interaction mode. Users can customize ChatChain, Phase, and Role settings, and share their software creations easily. The project is open-source under the Apache 2.0 License and utilizes data licensed under CC BY-NC 4.0.
habitat-sim
Habitat-Sim is a high-performance physics-enabled 3D simulator with support for 3D scans of indoor/outdoor spaces, CAD models of spaces and piecewise-rigid objects, configurable sensors, robots described via URDF, and rigid-body mechanics. It prioritizes simulation speed over the breadth of simulation capabilities, achieving several thousand frames per second (FPS) running single-threaded and over 10,000 FPS multi-process on a single GPU when rendering a scene from the Matterport3D dataset. Habitat-Sim simulates a Fetch robot interacting in ReplicaCAD scenes at over 8,000 steps per second (SPS), where each ‘step’ involves rendering 1 RGBD observation (128×128 pixels) and rigid-body dynamics for 1/30sec.
talking-avatar-with-ai
The 'talking-avatar-with-ai' project is a digital human system that utilizes OpenAI's GPT-3 for generating responses, Whisper for audio transcription, Eleven Labs for voice generation, and Rhubarb Lip Sync for lip synchronization. The system allows users to interact with a digital avatar that responds with text, facial expressions, and animations, creating a realistic conversational experience. The project includes setup for environment variables, chat prompt templates, chat model configuration, and structured output parsing to enhance the interaction with the digital human.
keras-hub
KerasHub is a pretrained modeling library that provides Keras 3 implementations of popular model architectures with pretrained checkpoints. It supports text, image, and audio data for generation, classification, and other tasks. Models are compatible with JAX, TensorFlow, and PyTorch, and can be fine-tuned on GPUs and TPUs. KerasHub components are provided as Layer and Model implementations, extending the core Keras API.

storm
STORM is a LLM system that writes Wikipedia-like articles from scratch based on Internet search. While the system cannot produce publication-ready articles that often require a significant number of edits, experienced Wikipedia editors have found it helpful in their pre-writing stage. **Try out our [live research preview](https://storm.genie.stanford.edu/) to see how STORM can help your knowledge exploration journey and please provide feedback to help us improve the system 🙏!**
For similar tasks

MathCoder
MathCoder is a repository focused on enhancing mathematical reasoning by fine-tuning open-source language models to use code for modeling and deriving math equations. It introduces MathCodeInstruct dataset with solutions interleaving natural language, code, and execution results. The repository provides MathCoder models capable of generating code-based solutions for challenging math problems, achieving state-of-the-art scores on MATH and GSM8K datasets. It offers tools for model deployment, inference, and evaluation, along with a citation for referencing the work.
AlphaFold3
AlphaFold3 is an implementation of the Alpha Fold 3 model in PyTorch for accurate structure prediction of biomolecular interactions. It includes modules for genetic diffusion and full model examples for forward pass computations. The tool allows users to generate random pair and single representations, operate on atomic coordinates, and perform structure predictions based on input tensors. The implementation also provides functionalities for training and evaluating the model.
hold
This repository contains the code for HOLD, a method that jointly reconstructs hands and objects from monocular videos without assuming a pre-scanned object template. It can reconstruct 3D geometries of novel objects and hands, enabling template-free bimanual hand-object reconstruction, textureless object interaction with hands, and multiple objects interaction with hands. The repository provides instructions to download in-the-wild videos from HOLD, preprocess and train on custom videos, a volumetric rendering framework, a generalized codebase for single and two hand interaction with objects, a viewer to interact with predictions, and code to evaluate and compare with HOLD in HO3D. The repository also includes documentation for setup, training, evaluation, visualization, preprocessing custom sequences, and using HOLD on ARCTIC.
AliceVision
AliceVision is a photogrammetric computer vision framework which provides a 3D reconstruction pipeline. It is designed to process images from different viewpoints and create detailed 3D models of objects or scenes. The framework includes various algorithms for feature detection, matching, and structure from motion. AliceVision is suitable for researchers, developers, and enthusiasts interested in computer vision, photogrammetry, and 3D modeling. It can be used for applications such as creating 3D models of buildings, archaeological sites, or objects for virtual reality and augmented reality experiences.
For similar jobs
hold
This repository contains the code for HOLD, a method that jointly reconstructs hands and objects from monocular videos without assuming a pre-scanned object template. It can reconstruct 3D geometries of novel objects and hands, enabling template-free bimanual hand-object reconstruction, textureless object interaction with hands, and multiple objects interaction with hands. The repository provides instructions to download in-the-wild videos from HOLD, preprocess and train on custom videos, a volumetric rendering framework, a generalized codebase for single and two hand interaction with objects, a viewer to interact with predictions, and code to evaluate and compare with HOLD in HO3D. The repository also includes documentation for setup, training, evaluation, visualization, preprocessing custom sequences, and using HOLD on ARCTIC.

stable-diffusion.cpp
The stable-diffusion.cpp repository provides an implementation for inferring stable diffusion in pure C/C++. It offers features such as support for different versions of stable diffusion, lightweight and dependency-free implementation, various quantization support, memory-efficient CPU inference, GPU acceleration, and more. Users can download the built executable program or build it manually. The repository also includes instructions for downloading weights, building from scratch, using different acceleration methods, running the tool, converting weights, and utilizing various features like Flash Attention, ESRGAN upscaling, PhotoMaker support, and more. Additionally, it mentions future TODOs and provides information on memory requirements, bindings, UIs, contributors, and references.

joliGEN
JoliGEN is an integrated framework for training custom generative AI image-to-image models. It implements GAN, Diffusion, and Consistency models for various image translation tasks, including domain and style adaptation with conservation of semantics. The tool is designed for real-world applications such as Controlled Image Generation, Augmented Reality, Dataset Smart Augmentation, and Synthetic to Real transforms. JoliGEN allows for fast and stable training with a REST API server for simplified deployment. It offers a wide range of options and parameters with detailed documentation available for models, dataset formats, and data augmentation.
ShapeLLM
ShapeLLM is the first 3D Multimodal Large Language Model designed for embodied interaction, exploring a universal 3D object understanding with 3D point clouds and languages. It supports single-view colored point cloud input and introduces a robust 3D QA benchmark, 3D MM-Vet, encompassing various variants. The model extends the powerful point encoder architecture, ReCon++, achieving state-of-the-art performance across a range of representation learning tasks. ShapeLLM can be used for tasks such as training, zero-shot understanding, visual grounding, few-shot learning, and zero-shot learning on 3D MM-Vet.
gpupixel
GPUPixel is a real-time, high-performance image and video filter library written in C++11 and based on OpenGL/ES. It incorporates a built-in beauty face filter that achieves commercial-grade beauty effects. The library is extremely easy to compile and integrate with a small size, supporting platforms including iOS, Android, Mac, Windows, and Linux. GPUPixel provides various filters like skin smoothing, whitening, face slimming, big eyes, lipstick, and blush. It supports input formats like YUV420P, RGBA, JPEG, PNG, and output formats like RGBA and YUV420P. The library's performance on devices like iPhone and Android is optimized, with low CPU usage and fast processing times. GPUPixel's lib size is compact, making it suitable for mobile and desktop applications.
mediapipe-rs
MediaPipe-rs is a Rust library designed for MediaPipe tasks on WasmEdge WASI-NN. It offers easy-to-use low-code APIs similar to mediapipe-python, with low overhead and flexibility for custom media input. The library supports various tasks like object detection, image classification, gesture recognition, and more, including TfLite models, TF Hub models, and custom models. Users can create task instances, run sessions for pre-processing, inference, and post-processing, and speed up processing by reusing sessions. The library also provides support for audio tasks using audio data from symphonia, ffmpeg, or raw audio. Users can choose between CPU, GPU, or TPU devices for processing.
LL3DA
LL3DA is a Large Language 3D Assistant that responds to both visual and textual interactions within complex 3D environments. It aims to help Large Multimodal Models (LMM) comprehend, reason, and plan in diverse 3D scenes by directly taking point cloud input and responding to textual instructions and visual prompts. LL3DA achieves remarkable results in 3D Dense Captioning and 3D Question Answering, surpassing various 3D vision-language models. The code is fully released, allowing users to train customized models and work with pre-trained weights. The tool supports training with different LLM backends and provides scripts for tuning and evaluating models on various tasks.

generative-models
Generative Models by Stability AI is a repository that provides various generative models for research purposes. It includes models like Stable Video 4D (SV4D) for video synthesis, Stable Video 3D (SV3D) for multi-view synthesis, SDXL-Turbo for text-to-image generation, and more. The repository focuses on modularity and implements a config-driven approach for building and combining submodules. It supports training with PyTorch Lightning and offers inference demos for different models. Users can access pre-trained models like SDXL-base-1.0 and SDXL-refiner-1.0 under a CreativeML Open RAIL++-M license. The codebase also includes tools for invisible watermark detection in generated images.