
gpupixel
Real-time image filter engine written in c++11 and based on gpu.
Stars: 1680
GPUPixel is a real-time, high-performance image and video filter library written in C++11 and based on OpenGL/ES. It incorporates a built-in beauty face filter that achieves commercial-grade beauty effects. The library is extremely easy to compile and integrate with a small size, supporting platforms including iOS, Android, Mac, Windows, and Linux. GPUPixel provides various filters like skin smoothing, whitening, face slimming, big eyes, lipstick, and blush. It supports input formats like YUV420P, RGBA, JPEG, PNG, and output formats like RGBA and YUV420P. The library's performance on devices like iPhone and Android is optimized, with low CPU usage and fast processing times. GPUPixel's lib size is compact, making it suitable for mobile and desktop applications.
README:

![]()
🌟 Join us in making GPUPixel better through discussions, issues, and PRs.
📢 Note: VNN face detection library has been replaced with Mars-Face from v1.3.0-beta
🚀 GPUPixel is a real-time, high-performance image and video filter library that's extremely easy to compile and integrate with a small footprint.
💻 GPUPixel is written in C++11 and built on OpenGL/ES, featuring built-in beauty face filters that deliver commercial-grade results.
🌐 GPUPixel supports multiple platforms including iOS, Android, Mac, Win and Linux, and can be ported to virtually any platform that supports OpenGL/ES.
Video: YouTube
| Origin | Smooth | White | ThinFace |
|---|---|---|---|
 |
 |
 |
 |
| BigEye | Lipstick | Blusher | ON-OFF |
 |
 |
 |
 |

✨ This table compares the features supported by GPUPixel, GPUImage, and Android-GPUImage:
✅: Supported | ❌: Not supported | ✏️: Planning
| GPUPixel | GPUImage | Android-GPUImage | |
|---|---|---|---|
| Filters: | ✅ | ❌ | ❌ |
| Skin Smoothing Filter | ✅ | ❌ | ❌ |
| Skin Whitening Filter | ✅ | ❌ | ❌ |
| Face Slimming Filter | ✅ | ❌ | ❌ |
| Big Eyes Filter | ✅ | ❌ | ❌ |
| Lipstick Filter | ✅ | ❌ | ❌ |
| Blush Filter | ✅ | ❌ | ❌ |
| More Build in Filter | ✅ | ✅ | ✅ |
| Input Formats: | |||
| YUV420P(I420) | ✅ | ❌ | ❌ |
| RGBA | ✅ | ✅ | ✅ |
| JPEG | ✅ | ✅ | ✅ |
| PNG | ✅ | ✅ | ✅ |
| NV21(for Android) | ✏️ | ❌ | ❌ |
| Output Formats: | |||
| RGBA | ✅ | ✅ | ✅ |
| YUV420P(I420) | ✅ | ❌ | ❌ |
| Platform: | |||
| iOS | ✅ | ✅ | ❌ |
| Mac | ✅ | ✅ | ❌ |
| Android | ✅ | ❌ | ✅ |
| Win | ✅ | ❌ | ❌ |
| Linux | ✅ | ❌ | ❌ |
⭐ Star us on GitHub to receive instant notifications about new releases!

🔍 See the docs: Introduction | Build | Demo | Integration
🤝 Help make GPUPixel better by joining our discussions, opening issues, or submitting PRs. Check our Contributing Guide to get started.
Please also consider supporting GPUPixel by sharing it on social media and at events and conferences.

💖 If you like this project, consider supporting us through the following methods:
| ☕ Support me on Ko-fi | 💝 Support on Open Collective | 💰 WeChat Sponsor |
|---|
🙏 Thank you to the following contributors for their generous support of the project:


- 📚 Docs : Online documentation
- 🐛 Issues : Report bugs or request features
- 📧 Email : Send us a message
- 📞 Contact : Get in touch with us
This repository is available under the Apache-2.0 License.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for gpupixel
Similar Open Source Tools
gpupixel
GPUPixel is a real-time, high-performance image and video filter library written in C++11 and based on OpenGL/ES. It incorporates a built-in beauty face filter that achieves commercial-grade beauty effects. The library is extremely easy to compile and integrate with a small size, supporting platforms including iOS, Android, Mac, Windows, and Linux. GPUPixel provides various filters like skin smoothing, whitening, face slimming, big eyes, lipstick, and blush. It supports input formats like YUV420P, RGBA, JPEG, PNG, and output formats like RGBA and YUV420P. The library's performance on devices like iPhone and Android is optimized, with low CPU usage and fast processing times. GPUPixel's lib size is compact, making it suitable for mobile and desktop applications.
cool-ai-stuff
This repository contains an uncensored list of free to use APIs and sites for several AI models. > _This list is mainly managed by @zukixa, the queen of zukijourney, so any decisions may have bias!~_ > > **Scroll down for the sites, APIs come first!** * * * > [!WARNING] > We are not endorsing _any_ of the listed services! Some of them might be considered controversial. We are not responsible for any legal, technical or any other damage caused by using the listed services. Data is provided without warranty of any kind. **Use these at your own risk!** * * * # APIs Table of Contents #### Overview of Existing APIs #### Overview of Existing APIs -- Top LLM Models Available #### Overview of Existing APIs -- Top Image Models Available #### Overview of Existing APIs -- Top Other Features & Models Available #### Overview of Existing APIs -- Available Donator Perks * * * ## API List:* *: This list solely covers all providers I (@zukixa) was able to collect metrics in. Any mistakes are not my responsibility, as I am either banned, or not aware of x API. \ 1: Last Updated 4/14/24 ### Overview of APIs: | Service | # of Users1 | Link | Stablity | NSFW Ok? | Open Source? | Owner(s) | Other Notes | | ----------- | ---------- | ------------------------------------------ | ------------------------------------------ | --------------------------- | ------------------------------------------------------ | -------------------------- | ----------------------------------------------------------------------------------------------------------- | | zukijourney| 4441 | D | High | On /unf/, not /v1/ | ✅, Here | @zukixa | Largest & Oldest GPT-4 API still continuously around. Offers other popular AI-related Bots too. | | Hyzenberg| 1234 | D | High | Forbidden | ❌ | @thatlukinhasguy & @voidiii | Experimental sister API to Zukijourney. Successor to HentAI | | NagaAI | 2883 | D | High | Forbidden | ❌ | @zentixua | Honorary successor to ChimeraGPT, the largest API in history (15k users). | | WebRaftAI | 993 | D | High | Forbidden | ❌ | @ds_gamer | Largest API by model count. Provides a lot of service/hosting related stuff too. | | KrakenAI | 388 | D | High | Discouraged | ❌ | @paninico | It is an API of all time. | | ShuttleAI | 3585 | D | Medium | Generally Permitted | ❌ | @xtristan | Faked GPT-4 Before 1, 2 | | Mandrill | 931 | D | Medium | Enterprise-Tier-Only | ❌ | @fredipy | DALL-E-3 access pioneering API. Has some issues with speed & stability nowadays. | oxygen | 742 | D | Medium | Donator-Only | ❌ | @thesketchubuser | Bri'ish 🤮 & Fren'sh 🤮 | | Skailar | 399 | D | Medium | Forbidden | ❌ | @aquadraws | Service is the personification of the word 'feature creep'. Lots of things announced, not much operational. |

MOSS-TTS
MOSS-TTS Family is an open-source speech and sound generation model family designed for high-fidelity, high-expressiveness, and complex real-world scenarios. It includes five production-ready models: MOSS-TTS, MOSS-TTSD, MOSS-VoiceGenerator, MOSS-TTS-Realtime, and MOSS-SoundEffect, each serving specific purposes in speech generation, dialogue, voice design, real-time interactions, and sound effect generation. The models offer features like long-speech generation, fine-grained control over phonemes and duration, multilingual synthesis, voice cloning, and real-time voice agents.

langfuse
Langfuse is a powerful tool that helps you develop, monitor, and test your LLM applications. With Langfuse, you can: * **Develop:** Instrument your app and start ingesting traces to Langfuse, inspect and debug complex logs, and manage, version, and deploy prompts from within Langfuse. * **Monitor:** Track metrics (cost, latency, quality) and gain insights from dashboards & data exports, collect and calculate scores for your LLM completions, run model-based evaluations, collect user feedback, and manually score observations in Langfuse. * **Test:** Track and test app behaviour before deploying a new version, test expected in and output pairs and benchmark performance before deploying, and track versions and releases in your application. Langfuse is easy to get started with and offers a generous free tier. You can sign up for Langfuse Cloud or deploy Langfuse locally or on your own infrastructure. Langfuse also offers a variety of integrations to make it easy to connect to your LLM applications.

oumi
Oumi is an open-source platform for building state-of-the-art foundation models, offering tools for data preparation, training, evaluation, and deployment. It supports training and fine-tuning models with various parameters, working with text and multimodal models, synthesizing and curating training data, deploying models efficiently, evaluating models comprehensively, and running on different platforms. Oumi provides a consistent API, reliability, and flexibility for research purposes.

unstract
Unstract is a no-code platform that enables users to launch APIs and ETL pipelines to structure unstructured documents. With Unstract, users can go beyond co-pilots by enabling machine-to-machine automation. Unstract's Prompt Studio provides a simple, no-code approach to creating prompts for LLMs, vector databases, embedding models, and text extractors. Users can then configure Prompt Studio projects as API deployments or ETL pipelines to automate critical business processes that involve complex documents. Unstract supports a wide range of LLM providers, vector databases, embeddings, text extractors, ETL sources, and ETL destinations, providing users with the flexibility to choose the best tools for their needs.
runanywhere-sdks
RunAnywhere is an on-device AI tool for mobile apps that allows users to run LLMs, speech-to-text, text-to-speech, and voice assistant features locally, ensuring privacy, offline functionality, and fast performance. The tool provides a range of AI capabilities without relying on cloud services, reducing latency and ensuring that no data leaves the device. RunAnywhere offers SDKs for Swift (iOS/macOS), Kotlin (Android), React Native, and Flutter, making it easy for developers to integrate AI features into their mobile applications. The tool supports various models for LLM, speech-to-text, and text-to-speech, with detailed documentation and installation instructions available for each platform.
llama-stack
Llama Stack defines and standardizes core building blocks for AI application development, providing a unified API layer, plugin architecture, prepackaged distributions, developer interfaces, and standalone applications. It offers flexibility in infrastructure choice, consistent experience with unified APIs, and a robust ecosystem with integrated distribution partners. The tool simplifies building, testing, and deploying AI applications with various APIs and environments, supporting local development, on-premises, cloud, and mobile deployments.
visionOS-examples
visionOS-examples is a repository containing accelerators for Spatial Computing. It includes examples such as Local Large Language Model, Chat Apple Vision Pro, WebSockets, Anchor To Head, Hand Tracking, Battery Life, Countdown, Plane Detection, Timer Vision, and PencilKit for visionOS. The repository showcases various functionalities and features for Apple Vision Pro, offering tools for developers to enhance their visionOS apps with capabilities like hand tracking, plane detection, and real-time cryptocurrency prices.

DataFlow
DataFlow is a data preparation and training system designed to parse, generate, process, and evaluate high-quality data from noisy sources, improving the performance of large language models in specific domains. It constructs diverse operators and pipelines, validated to enhance domain-oriented LLM's performance in fields like healthcare, finance, and law. DataFlow also features an intelligent DataFlow-agent capable of dynamically assembling new pipelines by recombining existing operators on demand.
albumentations
Albumentations is a Python library for image augmentation. Image augmentation is used in deep learning and computer vision tasks to increase the quality of trained models. The purpose of image augmentation is to create new training samples from the existing data.

Awesome-LLMs-for-Video-Understanding
Awesome-LLMs-for-Video-Understanding is a repository dedicated to exploring Video Understanding with Large Language Models. It provides a comprehensive survey of the field, covering models, pretraining, instruction tuning, and hybrid methods. The repository also includes information on tasks, datasets, and benchmarks related to video understanding. Contributors are encouraged to add new papers, projects, and materials to enhance the repository.
AI0x0.com
AI 0x0 is a versatile AI query generation desktop floating assistant application that supports MacOS and Windows. It allows users to utilize AI capabilities in any desktop software to query and generate text, images, audio, and video data, helping them work more efficiently. The application features a dynamic desktop floating ball, floating dialogue bubbles, customizable presets, conversation bookmarking, preset packages, network acceleration, query mode, input mode, mouse navigation, deep customization of ChatGPT Next Web, support for full-format libraries, online search, voice broadcasting, voice recognition, voice assistant, application plugins, multi-model support, online text and image generation, image recognition, frosted glass interface, light and dark theme adaptation for each language model, and free access to all language models except Chat0x0 with a key.
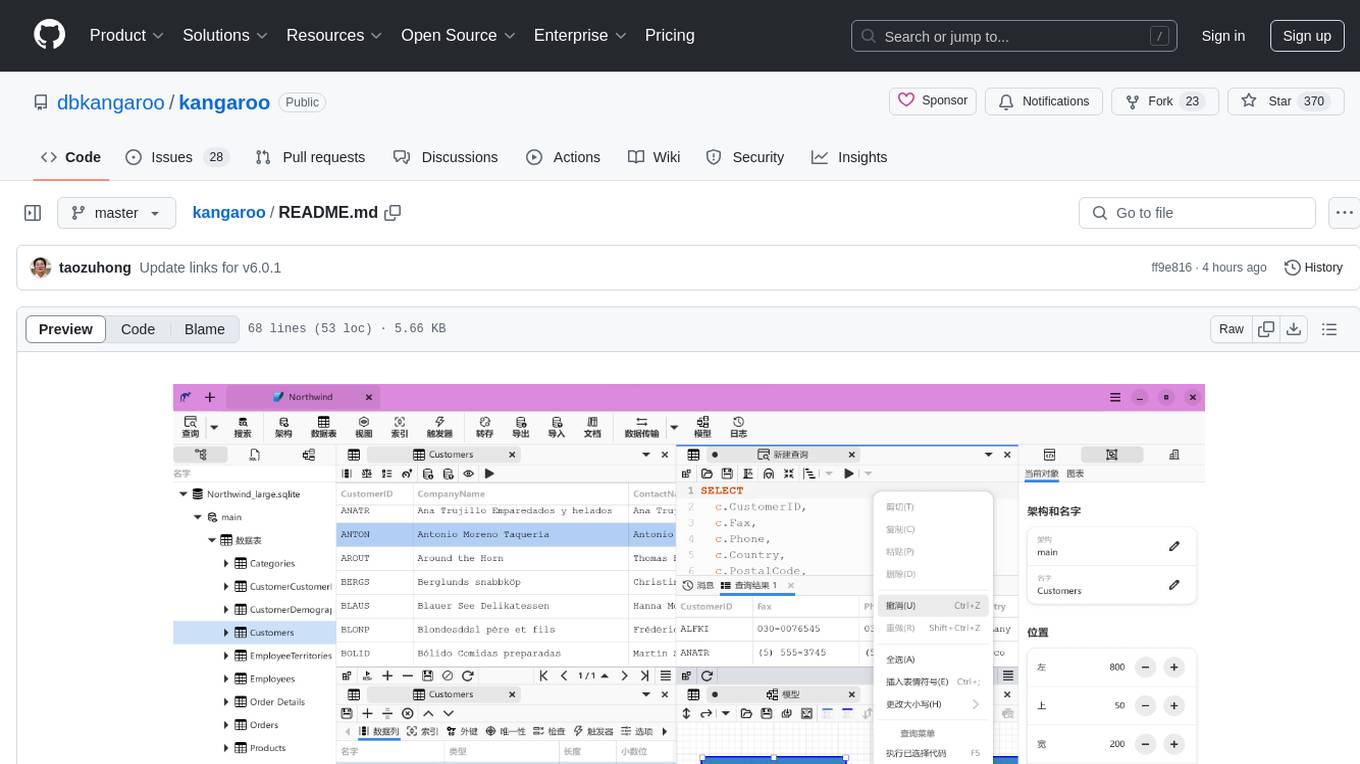
kangaroo
Kangaroo is an AI-powered SQL client and admin tool for popular databases like SQLite, MySQL, PostgreSQL, etc. It supports various functionalities such as table design, query, model, sync, export/import, and more. The tool is designed to be comfortable, fun, and developer-friendly, with features like code intellisense and autocomplete. Kangaroo aims to provide a seamless experience for database management across different operating systems.
web-builder
Web Builder is a low-code front-end framework based on Material for Angular, offering a rich component library for excellent digital innovation experience. It allows rapid construction of modern responsive UI, multi-theme, multi-language web pages through drag-and-drop visual configuration. The framework includes a beautiful admin theme, complete front-end solutions, and AI integration in the Pro version for optimizing copy, creating components, and generating pages with a single sentence.

jiwu-mall-chat-tauri
Jiwu Chat Tauri APP is a desktop chat application based on Nuxt3 + Tauri + Element Plus framework. It provides a beautiful user interface with integrated chat and social functions. It also supports AI shopping chat and global dark mode. Users can engage in real-time chat, share updates, and interact with AI customer service through this application.
For similar tasks
gpupixel
GPUPixel is a real-time, high-performance image and video filter library written in C++11 and based on OpenGL/ES. It incorporates a built-in beauty face filter that achieves commercial-grade beauty effects. The library is extremely easy to compile and integrate with a small size, supporting platforms including iOS, Android, Mac, Windows, and Linux. GPUPixel provides various filters like skin smoothing, whitening, face slimming, big eyes, lipstick, and blush. It supports input formats like YUV420P, RGBA, JPEG, PNG, and output formats like RGBA and YUV420P. The library's performance on devices like iPhone and Android is optimized, with low CPU usage and fast processing times. GPUPixel's lib size is compact, making it suitable for mobile and desktop applications.
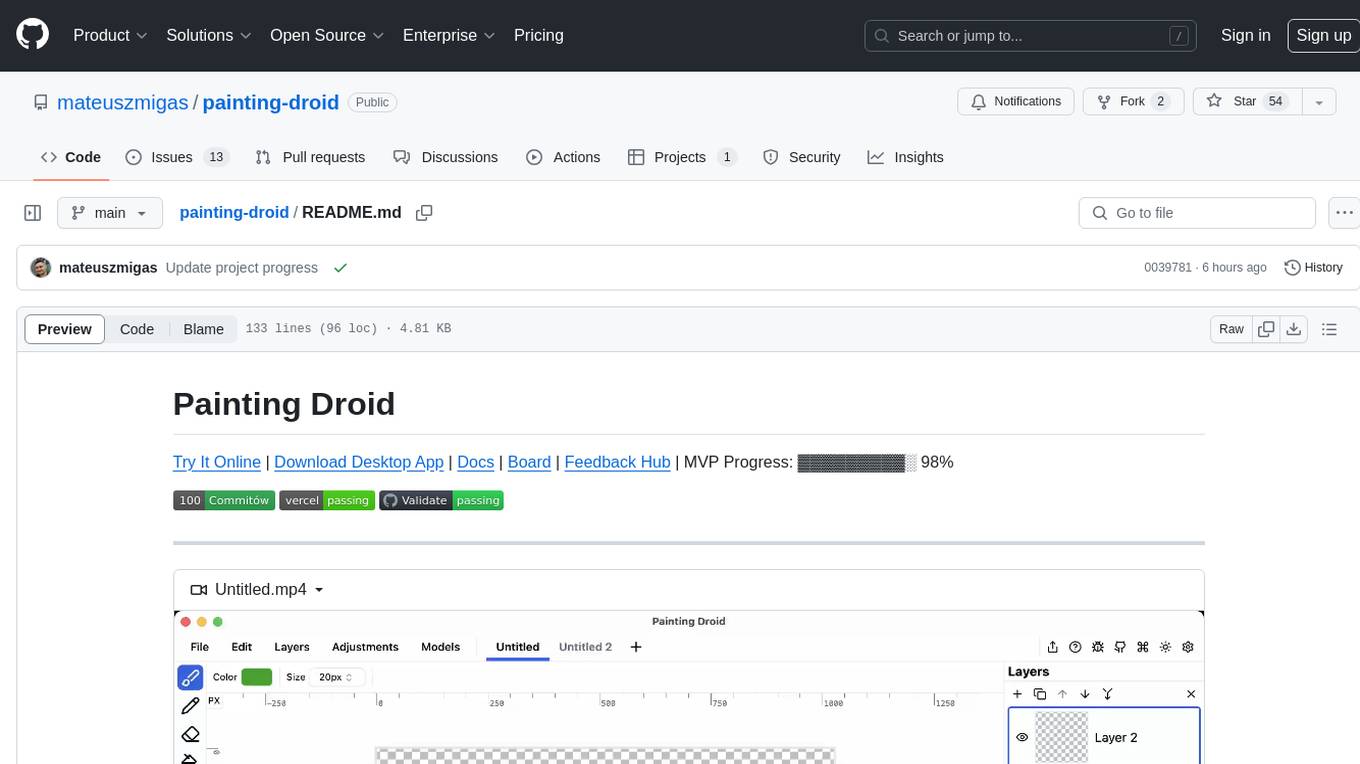
painting-droid
Painting Droid is an AI-powered cross-platform painting app inspired by MS Paint, expandable with plugins and open. It utilizes various AI models, from paid providers to self-hosted open-source models, as well as some lightweight ones built into the app. Features include regular painting app features, AI-generated content filling and augmentation, filters and effects, image manipulation, plugin support, and cross-platform compatibility.
Semi-Auto-NovelAI-to-Pixiv
Semi-Auto-NovelAI-to-Pixiv is a powerful tool that enables batch image generation with NovelAI, along with various other useful features in a super user-friendly interface. It allows users to create images, generate random images, upload images to Pixiv, apply filters, enhance images, add watermarks, and more. The tool also supports video-to-image conversion and various image manipulation tasks. It offers a seamless experience for users looking to automate image processing tasks.
Topaz-Video-AI
Topaz-Video-AI is a software tool designed to enhance video quality and provide various editing features. Users can utilize this tool to improve the visual appeal of their videos by applying filters, adjusting colors, and enhancing details. The software offers a user-friendly interface and a range of customization options to cater to different editing needs. Despite potential triggers from antivirus programs, Topaz-Video-AI is safe to use and has been tested by numerous users. By following the provided instructions, users can easily download, install, and run the software to enhance their video content.
aice_ps
Aice PS is a powerful web-based AI photo editor that utilizes Google aistudio's advanced capabilities to make professional image editing and creation simple and intuitive. Users can enhance images, apply creative filters, make professional adjustments, and even generate new images from scratch using simple text prompts. The tool combines various cutting-edge AI capabilities to provide a one-stop creative image and video solution, including AI image generation, intelligent editing, creative filters, professional adjustments, AI inspiration suggestions, intelligent synthesis, texture overlay, one-click cutout, time travel effects, BeatSync for music and image synchronization, NB prompt word library, basic editing toolkit, and more.

tt-metal
TT-NN is a python & C++ Neural Network OP library. It provides a low-level programming model, TT-Metalium, enabling kernel development for Tenstorrent hardware.

mscclpp
MSCCL++ is a GPU-driven communication stack for scalable AI applications. It provides a highly efficient and customizable communication stack for distributed GPU applications. MSCCL++ redefines inter-GPU communication interfaces, delivering a highly efficient and customizable communication stack for distributed GPU applications. Its design is specifically tailored to accommodate diverse performance optimization scenarios often encountered in state-of-the-art AI applications. MSCCL++ provides communication abstractions at the lowest level close to hardware and at the highest level close to application API. The lowest level of abstraction is ultra light weight which enables a user to implement logics of data movement for a collective operation such as AllReduce inside a GPU kernel extremely efficiently without worrying about memory ordering of different ops. The modularity of MSCCL++ enables a user to construct the building blocks of MSCCL++ in a high level abstraction in Python and feed them to a CUDA kernel in order to facilitate the user's productivity. MSCCL++ provides fine-grained synchronous and asynchronous 0-copy 1-sided abstracts for communication primitives such as `put()`, `get()`, `signal()`, `flush()`, and `wait()`. The 1-sided abstractions allows a user to asynchronously `put()` their data on the remote GPU as soon as it is ready without requiring the remote side to issue any receive instruction. This enables users to easily implement flexible communication logics, such as overlapping communication with computation, or implementing customized collective communication algorithms without worrying about potential deadlocks. Additionally, the 0-copy capability enables MSCCL++ to directly transfer data between user's buffers without using intermediate internal buffers which saves GPU bandwidth and memory capacity. MSCCL++ provides consistent abstractions regardless of the location of the remote GPU (either on the local node or on a remote node) or the underlying link (either NVLink/xGMI or InfiniBand). This simplifies the code for inter-GPU communication, which is often complex due to memory ordering of GPU/CPU read/writes and therefore, is error-prone.
mlir-air
This repository contains tools and libraries for building AIR platforms, runtimes and compilers.
For similar jobs

stable-diffusion.cpp
The stable-diffusion.cpp repository provides an implementation for inferring stable diffusion in pure C/C++. It offers features such as support for different versions of stable diffusion, lightweight and dependency-free implementation, various quantization support, memory-efficient CPU inference, GPU acceleration, and more. Users can download the built executable program or build it manually. The repository also includes instructions for downloading weights, building from scratch, using different acceleration methods, running the tool, converting weights, and utilizing various features like Flash Attention, ESRGAN upscaling, PhotoMaker support, and more. Additionally, it mentions future TODOs and provides information on memory requirements, bindings, UIs, contributors, and references.

joliGEN
JoliGEN is an integrated framework for training custom generative AI image-to-image models. It implements GAN, Diffusion, and Consistency models for various image translation tasks, including domain and style adaptation with conservation of semantics. The tool is designed for real-world applications such as Controlled Image Generation, Augmented Reality, Dataset Smart Augmentation, and Synthetic to Real transforms. JoliGEN allows for fast and stable training with a REST API server for simplified deployment. It offers a wide range of options and parameters with detailed documentation available for models, dataset formats, and data augmentation.
ShapeLLM
ShapeLLM is the first 3D Multimodal Large Language Model designed for embodied interaction, exploring a universal 3D object understanding with 3D point clouds and languages. It supports single-view colored point cloud input and introduces a robust 3D QA benchmark, 3D MM-Vet, encompassing various variants. The model extends the powerful point encoder architecture, ReCon++, achieving state-of-the-art performance across a range of representation learning tasks. ShapeLLM can be used for tasks such as training, zero-shot understanding, visual grounding, few-shot learning, and zero-shot learning on 3D MM-Vet.
gpupixel
GPUPixel is a real-time, high-performance image and video filter library written in C++11 and based on OpenGL/ES. It incorporates a built-in beauty face filter that achieves commercial-grade beauty effects. The library is extremely easy to compile and integrate with a small size, supporting platforms including iOS, Android, Mac, Windows, and Linux. GPUPixel provides various filters like skin smoothing, whitening, face slimming, big eyes, lipstick, and blush. It supports input formats like YUV420P, RGBA, JPEG, PNG, and output formats like RGBA and YUV420P. The library's performance on devices like iPhone and Android is optimized, with low CPU usage and fast processing times. GPUPixel's lib size is compact, making it suitable for mobile and desktop applications.
mediapipe-rs
MediaPipe-rs is a Rust library designed for MediaPipe tasks on WasmEdge WASI-NN. It offers easy-to-use low-code APIs similar to mediapipe-python, with low overhead and flexibility for custom media input. The library supports various tasks like object detection, image classification, gesture recognition, and more, including TfLite models, TF Hub models, and custom models. Users can create task instances, run sessions for pre-processing, inference, and post-processing, and speed up processing by reusing sessions. The library also provides support for audio tasks using audio data from symphonia, ffmpeg, or raw audio. Users can choose between CPU, GPU, or TPU devices for processing.
hold
This repository contains the code for HOLD, a method that jointly reconstructs hands and objects from monocular videos without assuming a pre-scanned object template. It can reconstruct 3D geometries of novel objects and hands, enabling template-free bimanual hand-object reconstruction, textureless object interaction with hands, and multiple objects interaction with hands. The repository provides instructions to download in-the-wild videos from HOLD, preprocess and train on custom videos, a volumetric rendering framework, a generalized codebase for single and two hand interaction with objects, a viewer to interact with predictions, and code to evaluate and compare with HOLD in HO3D. The repository also includes documentation for setup, training, evaluation, visualization, preprocessing custom sequences, and using HOLD on ARCTIC.
LL3DA
LL3DA is a Large Language 3D Assistant that responds to both visual and textual interactions within complex 3D environments. It aims to help Large Multimodal Models (LMM) comprehend, reason, and plan in diverse 3D scenes by directly taking point cloud input and responding to textual instructions and visual prompts. LL3DA achieves remarkable results in 3D Dense Captioning and 3D Question Answering, surpassing various 3D vision-language models. The code is fully released, allowing users to train customized models and work with pre-trained weights. The tool supports training with different LLM backends and provides scripts for tuning and evaluating models on various tasks.

generative-models
Generative Models by Stability AI is a repository that provides various generative models for research purposes. It includes models like Stable Video 4D (SV4D) for video synthesis, Stable Video 3D (SV3D) for multi-view synthesis, SDXL-Turbo for text-to-image generation, and more. The repository focuses on modularity and implements a config-driven approach for building and combining submodules. It supports training with PyTorch Lightning and offers inference demos for different models. Users can access pre-trained models like SDXL-base-1.0 and SDXL-refiner-1.0 under a CreativeML Open RAIL++-M license. The codebase also includes tools for invisible watermark detection in generated images.