
Semi-Auto-NovelAI-to-Pixiv
带有 WebUI 的 NovelAI 量产工具, 实现了批量文生图; 批量图生图; 视频转绘; 分块重绘; 批量 Vibe; 批量局部重绘; 批量超分降噪; 批量自动打码; 批量添加水印; 批量上传 Pixiv; 图片筛选; 批量抹除, 还原或导出生成信息; 法术解析; 多模型反推提示词; ChatGPT; 动态加载插件; 自动 roll 画风串; 批量 Enhance; tag选择器; 涂鸦重绘; 图片压缩整理; 批量AI工具; wildcard; ...
Stars: 242
Semi-Auto-NovelAI-to-Pixiv is a powerful tool that enables batch image generation with NovelAI, along with various other useful features in a super user-friendly interface. It allows users to create images, generate random images, upload images to Pixiv, apply filters, enhance images, add watermarks, and more. The tool also supports video-to-image conversion and various image manipulation tasks. It offers a seamless experience for users looking to automate image processing tasks.
README:


English document: README_EN.md
-
这是一个神奇项目, 实现了 NovelAI 本身无法实现的批量生图!
-
它不仅仅只能生图, 是集各种实用功能于一体的超级用户界面!
-
使用中遇到问题请加 QQ 群咨询:559063963
[!TIP] 那天大雨滂沱,雷电交加, 风儿甚是喧嚣,仿佛整个世界都在为某种未知的力量所动摇。
✨ 芝士目前已实现的功能:
-
实现动态加载插件, 提高本项目可扩展性!
-
已提交到商店的插件: 插件列表
[!TIP] 我独自一人走在湿滑泥泞的街头, 身旁只有寥寥几盏路灯在暗夜中孤寂地闪烁。
- 极低的配置需求, 极致的用户体验!
| 项目 | 说明 |
|---|---|
| NovelAI 会员 | 为了无限生成图片, 建议 25$/month 会员 |
| 魔法网络 | 为了成功发送请求, 确保你可以正常访问相关网站 |
| 1GB 显存 | 为了使用超分降噪所有引擎, 需要至少 1GB 显存 |
| 2GB 内存 | 为了流畅使用本项目, 需要至少 2GB 内存 |
| Windows 10/11(x64) | 为了使用全部功能, 需要使用 64 位 Windows10/11 |
| Microsoft Visual C++ 2015 | 为了使用超分降噪所有引擎, 需要安装运行库 |
[!WARNING] 远处传来几声猫的嘶叫,仿佛是夜晚的唯一音符,黑暗荒芜, 寒风刺骨, 伶仃孤苦。
- 如果你喜欢这个项目,请不妨点个 Star🌟,这是对开发者最大的动力
- 推荐安装 Python 3.10.11, 安装时请勾选 Add Python to PATH, 其余保持默认
- 推荐安装最新版本, 安装时一路 Next 即可
- 打开 cmd 或 powershell, 执行
git clone -b main --depth=1 https://github.com/zhulinyv/Semi-Auto-NovelAI-to-Pixiv.git
- 现在你可以直接运行项目根目录下的
run.bat来启动 WebUI, 首次启动会自动创建虚拟环境并安装依赖, 耗时较长, 可以去冲杯咖啡或继续看下方的文档
如果上述操作你觉得难以上手或出现问题, 请加群咨询或下载整合包 Semi-Auto-NovelAI-to-Pixiv
解压即用, 整合包用户请运行 整合包启动(Modpack launcher).bat
[!TIP] 月光透过稀疏的云层,洒在地面上,勾勒出一幅幽冥的画卷。
-
⚠️ 1.如果你已经启动了 WebUI, 但没有进行必要配置, 那么请转到设置页面进行必要配置 -
⚠️ 2.请不要跳过这一步, 它非常重要, 确保你已经将所有配置浏览过一遍 -
⚠️ 3.你同样可以直接编辑.env文件进行配置
[!WARNING] 那几声猫的嘶叫,时而远去,时而又近了, 不知脚下的路究竟是通向何方。
- 1.打开 https://www.pixiv.net/illustration/create 并手动上传图片
- 2.选择标签, 年龄限制, AI生成作品, 公开范围, 作品评论功能, 原创作品
- 3.F12 打开控制台并切换到网络视图
- 4.点击投稿
- 5.找到并单击 illustraion, 右侧切换到标头选项
- 6.在请求头部中可以找到 Cookie 和 X-Csrf-Token
-
运行
run.bat, 会自动打开默认浏览器并跳转到 127.0.0.1:11451 -
对于旧版用户: 不再建议运行单独脚本, 请使用 WebUI
-
如果真的需要(例如: 浏览器已添加休眠白名单但在非活动页面无法继续生成的情况), 请在 WebUI 中配置好目录等参数并单击生成独立脚本(你也可以自己阅读源代码编写独立的脚本), 然后运行根目录下的 run_stand_alone_scripts.bat
-
插件开发请移步: Wiki
[!TIP] 抬头是无尽的黑暗, 低头是无尽的黑暗, 仿佛陷入一个无边的漩涡中。
[!TIP] 黑暗如同一双无形的手,将我紧紧拥抱,深深地吞噬着我的思绪。
展开查看待办列表
- [x] 批量文生图
- [x] 批量图生图
- [x] 批量上传 Pixiv
- [x] 计算剩余点数
- [x] 批量 waifu2x
- [x] 批量局部重绘
- [x]
批量 vibe - [x] 批量打码
- [x] 用 Gradio 写一个 WebUI
- [ ]
将项目放到容器持久化运行 - [x] 修改界面样式
- [x]
添加 ChatGPT - [x]
写一个图片筛选器 - [ ]
通过账号密码获取 token - [x] 添加更多超分引擎
- [x] 添加文生图方式
- [x] 批量水印
- [x] 批量图片信息处理
- [x] 配置项界面
- [x] 打开相关文件夹功能
- [x] 合并随机蓝图等界面
- [x] 热键快速筛图
- [x] 教程和说明页面
- [x] 自定义插件
- [x] 自动生成独立脚本
- [x] 文生图指定数量
- [x] 文生图种子点击切换随机
- [x] 配置项添加是否还原图片信息
- [x] 补全独立脚本生成
- [x] 图片保存分类
- [x] 支持非文生图插件
- [x] 视频转绘
- [x] 提示词反推
- [x] 分块重绘
- [ ]
添加更多插帧引擎 - [x] 翻译剩余页面
- [x] 自动更新
- [x] 插件商店
- [x] 自定义清除元数据
- [x] 自动安装插件
- [x] 代理配置
- [x] 批量 Enhance
- [ ]
自定义保存目录 - [ ] 学习 C# 使用 wpfui 写一个启动器
- [x] YOLO 检测 NSFW
- [x] 启动 LOGO(甚至还加了个提示音)
- [x] 重新命名函数和变量
- [x] 文生图中断
- [x] 插件列表读取远程仓库
- [x] 插件更新与卸载
- [x] 图片筛选添加复制操作
- [x] 整合包
- [x] 新增打码方式
- [x] 局部重绘优化蒙版上传
- [x] 涂鸦重绘
- [ ]
局部放大重绘 - [x] 图片压缩与分类整理
- [ ] vibe 保存风格
- [x] 回退 vibe 随机图
- [x] 简化 favorite 编辑
- [ ] 学习 js 写一个自动补全
- [x] 简化 vibe 图片上传
- [x] 自定义分辨率
- [x] 提示音
- [ ] 对接 SD
- [ ] ...
本项目使用 waifu2x-ncnn-vulkan | Anime4KCPP | realcugan-ncnn-vulkan | realesrgan-ncnn-vulkan | realsr-ncnn-vulkan | srmd-cuda | srmd-ncnn-vulkan | waifu2x-caffe | waifu2x-converter 降噪和放大图片
本项目使用 Genshin-Sync 上传图片至 Pixiv
本项目使用 GPT4FREE 提供 GPT 服务
本项目使用 novelai-image-metadata 抹除元数据
本项目使用 SmilingWolf/wd-tagger 反推提示词
本项目使用 rife-ncnn-vulkan 处理分块重绘图片接缝
本项目使用 300画风法典 提供的部分画风串
本项目使用 涩涩法典梦神版 提供的各种动作提示词
[!NOTE] 坠落, 坠落。
免责声明: 本软件仅提供技术服务,开发者不对用户使用本软件可能引发的任何法律责任或损失承担责任, 用户应对其使用本软件及其结果负全部责任
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Semi-Auto-NovelAI-to-Pixiv
Similar Open Source Tools
Semi-Auto-NovelAI-to-Pixiv
Semi-Auto-NovelAI-to-Pixiv is a powerful tool that enables batch image generation with NovelAI, along with various other useful features in a super user-friendly interface. It allows users to create images, generate random images, upload images to Pixiv, apply filters, enhance images, add watermarks, and more. The tool also supports video-to-image conversion and various image manipulation tasks. It offers a seamless experience for users looking to automate image processing tasks.
FastGPT
FastGPT is a knowledge base Q&A system based on the LLM large language model, providing out-of-the-box data processing, model calling and other capabilities. At the same time, you can use Flow to visually arrange workflows to achieve complex Q&A scenarios!
ChatGPT-On-CS
ChatGPT-On-CS is an intelligent chatbot tool based on large models, supporting various platforms like WeChat, Taobao, Bilibili, Douyin, Weibo, and more. It can handle text, voice, and image inputs, access external resources through plugins, and customize enterprise AI applications based on proprietary knowledge bases. Users can set custom replies, utilize ChatGPT interface for intelligent responses, send images and binary files, and create personalized chatbots using knowledge base files. The tool also features platform-specific plugin systems for accessing external resources and supports enterprise AI applications customization.
midjourney-proxy
Midjourney-proxy is a proxy for the Discord channel of MidJourney, enabling API-based calls for AI drawing. It supports Imagine instructions, adding image base64 as a placeholder, Blend and Describe commands, real-time progress tracking, Chinese prompt translation, prompt sensitive word pre-detection, user-token connection to WSS, multi-account configuration, and more. For more advanced features, consider using midjourney-proxy-plus, which includes Shorten, focus shifting, image zooming, local redrawing, nearly all associated button actions, Remix mode, seed value retrieval, account pool persistence, dynamic maintenance, /info and /settings retrieval, account settings configuration, Niji bot robot, InsightFace face replacement robot, and an embedded management dashboard.
LLM-Dojo
LLM-Dojo is an open-source platform for learning and practicing large models, providing a framework for building custom large model training processes, implementing various tricks and principles in the llm_tricks module, and mainstream model chat templates. The project includes an open-source large model training framework, detailed explanations and usage of the latest LLM tricks, and a collection of mainstream model chat templates. The term 'Dojo' symbolizes a place dedicated to learning and practice, borrowing its meaning from martial arts training.
ai-tag
AI tag generator that combines 40,000 tags from Bilibili UP main Twelve Today is also very cute with Chinese translations from Novelai, providing Chinese search and tag generation services. It offers a tag community for magicians to directly copy and generate spells. Always free, no ads, no commercial use. The project includes a pure tag parsing library, independent spell parsing library, tag data repository, and a new gallery page with waterfall flow for viewing community images.

ChatGPT-On-CS
This project is an intelligent dialogue customer service tool based on a large model, which supports access to platforms such as WeChat, Qianniu, Bilibili, Douyin Enterprise, Douyin, Doudian, Weibo chat, Xiaohongshu professional account operation, Xiaohongshu, Zhihu, etc. You can choose GPT3.5/GPT4.0/ Lazy Treasure Box (more platforms will be supported in the future), which can process text, voice and pictures, and access external resources such as operating systems and the Internet through plug-ins, and support enterprise AI applications customized based on their own knowledge base.
springboot-openai-chatgpt
The springboot-openai-chatgpt repository is an open-source project for a super AI brain that utilizes GPT technology to quickly generate language content such as copies, love letters, and questions. Users can input keywords to enhance work efficiency and creativity. The AI brain combines powerful question-answering systems and knowledge graphs to provide comprehensive and accurate answers. It supports programming tasks, generates code using GPT, and continuously strengthens its capabilities with growing data to provide superior intelligent applications.

do-research-in-AI
This repository is a collection of research lectures and experience sharing posts from frontline researchers in the field of AI. It aims to help individuals upgrade their research skills and knowledge through insightful talks and experiences shared by experts. The content covers various topics such as evaluating research papers, choosing research directions, research methodologies, and tips for writing high-quality scientific papers. The repository also includes discussions on academic career paths, research ethics, and the emotional aspects of research work. Overall, it serves as a valuable resource for individuals interested in advancing their research capabilities in the field of AI.

all-in-rag
All-in-RAG is a comprehensive repository for all things related to Randomized Algorithms and Graphs. It provides a wide range of resources, including implementations of various randomized algorithms, graph data structures, and visualization tools. The repository aims to serve as a one-stop solution for researchers, students, and enthusiasts interested in exploring the intersection of randomized algorithms and graph theory. Whether you are looking to study theoretical concepts, implement algorithms in practice, or visualize graph structures, All-in-RAG has got you covered.
kirara-ai
Kirara AI is a chatbot that supports mainstream large language models and chat platforms. It provides features such as image sending, keyword-triggered replies, multi-account support, personality settings, and support for various chat platforms like QQ, Telegram, Discord, and WeChat. The tool also supports HTTP server for Web API, popular large models like OpenAI and DeepSeek, plugin mechanism, conditional triggers, admin commands, drawing models, voice replies, multi-turn conversations, cross-platform message sending, custom workflows, web management interface, and built-in Frpc intranet penetration.
handy-ollama
Handy-Ollama is a tutorial for deploying Ollama with hands-on practice, making the deployment of large language models accessible to everyone. The tutorial covers a wide range of content from basic to advanced usage, providing clear steps and practical tips for beginners and experienced developers to learn Ollama from scratch, deploy large models locally, and develop related applications. It aims to enable users to run large models on consumer-grade hardware, deploy models locally, and manage models securely and reliably.
NarratoAI
NarratoAI is an automated video narration tool that provides an all-in-one solution for script writing, automated video editing, voice-over, and subtitle generation. It is powered by LLM to enhance efficient content creation. The tool aims to simplify the process of creating film commentary and editing videos by automating various tasks such as script writing and voice-over generation. NarratoAI offers a user-friendly interface for users to easily generate video scripts, edit videos, and customize video parameters. With future plans to optimize story generation processes and support additional large models, NarratoAI is a versatile tool for content creators looking to streamline their video production workflow.
ComfyUI-OllamaGemini
ComfyUI GeminiOllama Extension integrates Google's Gemini API, OpenAI (ChatGPT), Anthropic's Claude, Ollama, Qwen, and image processing tools into ComfyUI for leveraging powerful models and features directly within workflows. Features include multiple AI API integrations, advanced prompt engineering, Gemini image generation, background removal, SVG conversion, FLUX resolutions, ComfyUI Styler, smart prompt generator, and more. The extension offers comprehensive API integration, advanced prompt engineering with researched templates, high-quality tools like Smart Prompt Generator and BRIA RMBG, and supports video & audio processing. It provides a single interface to access powerful AI models, transform prompts into detailed instructions, and use various tools for image processing, styling, and content generation.
chatgpt-mirai-qq-bot
Kirara AI is a chatbot that supports mainstream language models and chat platforms. It features various functionalities such as image sending, keyword-triggered replies, multi-account support, content moderation, personality settings, and support for platforms like QQ, Telegram, Discord, and WeChat. It also offers HTTP server capabilities, plugin support, conditional triggers, admin commands, drawing models, voice replies, multi-turn conversations, cross-platform message sending, and custom workflows. The tool can be accessed via HTTP API for integration with other platforms.
my-neuro
The project aims to create a personalized AI character, a lifelike AI companion - shaping the ideal image of TA in your mind through your data imprint. The project is inspired by neuro sama, hence named my-neuro. The project can train voice, personality, and replace images. It serves as a workspace where you can use packaged tools to step by step draw and realize the ideal AI image in your mind. The deployment of the current document requires less than 6GB of VRAM, compatible with Windows systems, and requires an API-KEY. The project offers features like low latency, real-time interruption, emotion simulation, visual capabilities integration, voice model training support, desktop control, live streaming on platforms like Bilibili, and more. It aims to provide a comprehensive AI experience with features like long-term memory, AI customization, and emotional interactions.
For similar tasks
Semi-Auto-NovelAI-to-Pixiv
Semi-Auto-NovelAI-to-Pixiv is a powerful tool that enables batch image generation with NovelAI, along with various other useful features in a super user-friendly interface. It allows users to create images, generate random images, upload images to Pixiv, apply filters, enhance images, add watermarks, and more. The tool also supports video-to-image conversion and various image manipulation tasks. It offers a seamless experience for users looking to automate image processing tasks.
gpupixel
GPUPixel is a real-time, high-performance image and video filter library written in C++11 and based on OpenGL/ES. It incorporates a built-in beauty face filter that achieves commercial-grade beauty effects. The library is extremely easy to compile and integrate with a small size, supporting platforms including iOS, Android, Mac, Windows, and Linux. GPUPixel provides various filters like skin smoothing, whitening, face slimming, big eyes, lipstick, and blush. It supports input formats like YUV420P, RGBA, JPEG, PNG, and output formats like RGBA and YUV420P. The library's performance on devices like iPhone and Android is optimized, with low CPU usage and fast processing times. GPUPixel's lib size is compact, making it suitable for mobile and desktop applications.
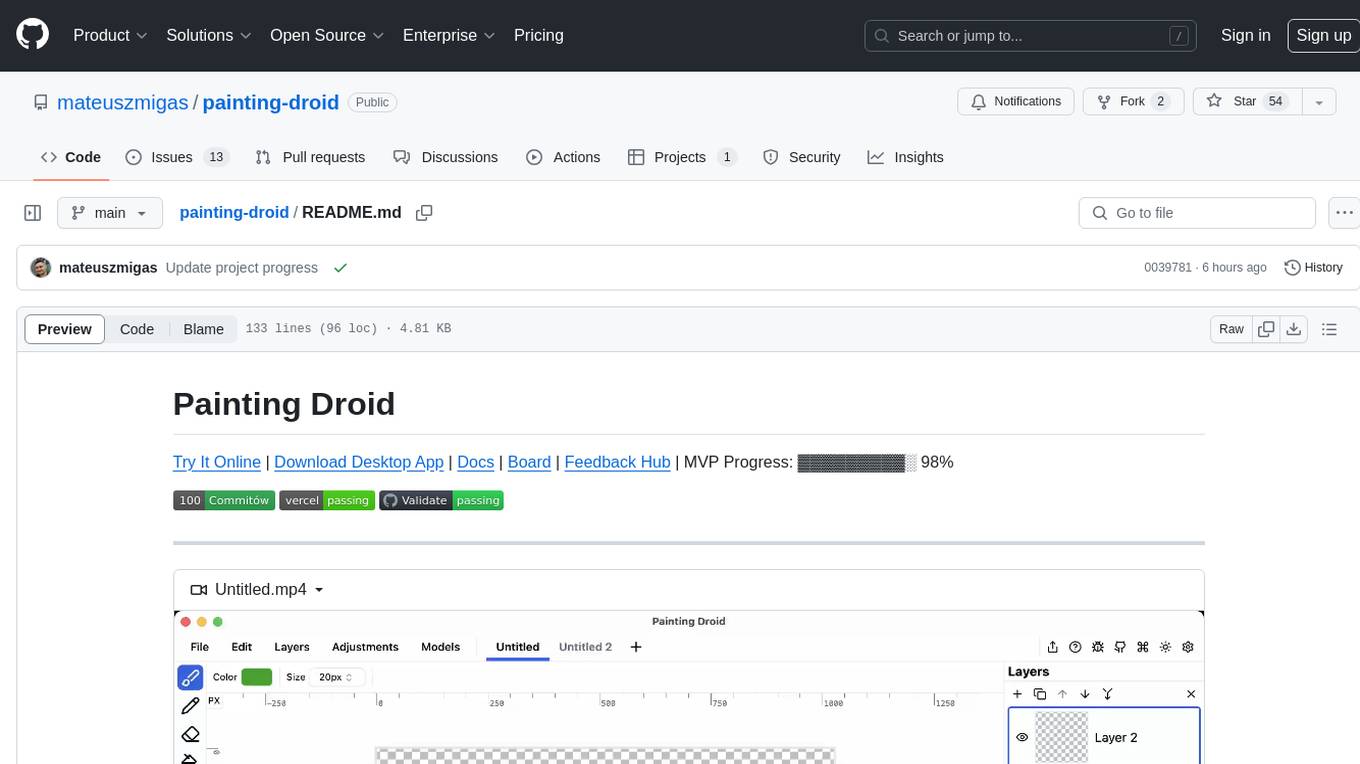
painting-droid
Painting Droid is an AI-powered cross-platform painting app inspired by MS Paint, expandable with plugins and open. It utilizes various AI models, from paid providers to self-hosted open-source models, as well as some lightweight ones built into the app. Features include regular painting app features, AI-generated content filling and augmentation, filters and effects, image manipulation, plugin support, and cross-platform compatibility.
Topaz-Video-AI
Topaz-Video-AI is a software tool designed to enhance video quality and provide various editing features. Users can utilize this tool to improve the visual appeal of their videos by applying filters, adjusting colors, and enhancing details. The software offers a user-friendly interface and a range of customization options to cater to different editing needs. Despite potential triggers from antivirus programs, Topaz-Video-AI is safe to use and has been tested by numerous users. By following the provided instructions, users can easily download, install, and run the software to enhance their video content.
aice_ps
Aice PS is a powerful web-based AI photo editor that utilizes Google aistudio's advanced capabilities to make professional image editing and creation simple and intuitive. Users can enhance images, apply creative filters, make professional adjustments, and even generate new images from scratch using simple text prompts. The tool combines various cutting-edge AI capabilities to provide a one-stop creative image and video solution, including AI image generation, intelligent editing, creative filters, professional adjustments, AI inspiration suggestions, intelligent synthesis, texture overlay, one-click cutout, time travel effects, BeatSync for music and image synchronization, NB prompt word library, basic editing toolkit, and more.

StableSwarmUI
StableSwarmUI is a modular Stable Diffusion web user interface that emphasizes making power tools easily accessible, high performance, and extensible. It is designed to be a one-stop-shop for all things Stable Diffusion, providing a wide range of features and capabilities to enhance the user experience.
upscayl
Upscayl is a free and open-source AI image upscaler that uses advanced AI algorithms to enlarge and enhance low-resolution images without losing quality. It is a cross-platform application built with the Linux-first philosophy, available on all major desktop operating systems. Upscayl utilizes Real-ESRGAN and Vulkan architecture for image enhancement, and its backend is fully open-source under the AGPLv3 license. It is important to note that a Vulkan compatible GPU is required for Upscayl to function effectively.

ailia-models
The collection of pre-trained, state-of-the-art AI models. ailia SDK is a self-contained, cross-platform, high-speed inference SDK for AI. The ailia SDK provides a consistent C++ API across Windows, Mac, Linux, iOS, Android, Jetson, and Raspberry Pi platforms. It also supports Unity (C#), Python, Rust, Flutter(Dart) and JNI for efficient AI implementation. The ailia SDK makes extensive use of the GPU through Vulkan and Metal to enable accelerated computing. # Supported models 323 models as of April 8th, 2024
For similar jobs

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

daily-poetry-image
Daily Chinese ancient poetry and AI-generated images powered by Bing DALL-E-3. GitHub Action triggers the process automatically. Poetry is provided by Today's Poem API. The website is built with Astro.

exif-photo-blog
EXIF Photo Blog is a full-stack photo blog application built with Next.js, Vercel, and Postgres. It features built-in authentication, photo upload with EXIF extraction, photo organization by tag, infinite scroll, light/dark mode, automatic OG image generation, a CMD-K menu with photo search, experimental support for AI-generated descriptions, and support for Fujifilm simulations. The application is easy to deploy to Vercel with just a few clicks and can be customized with a variety of environment variables.

SillyTavern
SillyTavern is a user interface you can install on your computer (and Android phones) that allows you to interact with text generation AIs and chat/roleplay with characters you or the community create. SillyTavern is a fork of TavernAI 1.2.8 which is under more active development and has added many major features. At this point, they can be thought of as completely independent programs.

Twitter-Insight-LLM
This project enables you to fetch liked tweets from Twitter (using Selenium), save it to JSON and Excel files, and perform initial data analysis and image captions. This is part of the initial steps for a larger personal project involving Large Language Models (LLMs).

AISuperDomain
Aila Desktop Application is a powerful tool that integrates multiple leading AI models into a single desktop application. It allows users to interact with various AI models simultaneously, providing diverse responses and insights to their inquiries. With its user-friendly interface and customizable features, Aila empowers users to engage with AI seamlessly and efficiently. Whether you're a researcher, student, or professional, Aila can enhance your AI interactions and streamline your workflow.
ChatGPT-On-CS
This project is an intelligent dialogue customer service tool based on a large model, which supports access to platforms such as WeChat, Qianniu, Bilibili, Douyin Enterprise, Douyin, Doudian, Weibo chat, Xiaohongshu professional account operation, Xiaohongshu, Zhihu, etc. You can choose GPT3.5/GPT4.0/ Lazy Treasure Box (more platforms will be supported in the future), which can process text, voice and pictures, and access external resources such as operating systems and the Internet through plug-ins, and support enterprise AI applications customized based on their own knowledge base.

obs-localvocal
LocalVocal is a live-streaming AI assistant plugin for OBS that allows you to transcribe audio speech into text and perform various language processing functions on the text using AI / LLMs (Large Language Models). It's privacy-first, with all data staying on your machine, and requires no GPU, cloud costs, network, or downtime.