
ailia-models
The collection of pre-trained, state-of-the-art AI models for ailia SDK
Stars: 2168

The collection of pre-trained, state-of-the-art AI models. ailia SDK is a self-contained, cross-platform, high-speed inference SDK for AI. The ailia SDK provides a consistent C++ API across Windows, Mac, Linux, iOS, Android, Jetson, and Raspberry Pi platforms. It also supports Unity (C#), Python, Rust, Flutter(Dart) and JNI for efficient AI implementation. The ailia SDK makes extensive use of the GPU through Vulkan and Metal to enable accelerated computing. # Supported models 323 models as of April 8th, 2024
README:

The collection of pre-trained, state-of-the-art AI models.
ailia SDK is a self-contained, cross-platform, high-speed inference SDK for AI. The ailia SDK provides a consistent C++ API across Windows, Mac, Linux, iOS, Android, Jetson, and Raspberry Pi platforms. It also supports Unity (C#), Python, Rust, Flutter(Dart) and JNI for efficient AI implementation. The ailia SDK makes extensive use of the GPU through Vulkan and Metal to enable accelerated computing.
Try now on Google Colaboratory
If you would like to try on your computer:
375 models as of February 28, 2025
- 2025.02.28 Add multilingual-minilmv2
- 2025.01.02 Add qwen_audio, audiosep
- 2025.01.01 Add RT-DETRv2, gazelle, lama, anything_v3, depth_anything_controlnet, deepfacelive, llava-jp
- 2024.12.31 Add clip-japanese-base, timesfm
- 2024.12.29 Add SAM2.1, span
- 2024.12.18 Update ONNX file of prompt encoder for SAM
- 2024.12.17 Add yolov10, yolov11
- 2024.11.26 Add fast_sam
- 2024.11.19 Add qwen2_vl, live_portrait (ailia SDK 1.5)
- More information in our Wiki
| Model | Reference | Exported From | Supported Ailia Version | Blog | |
|---|---|---|---|---|---|
 |
mars | MARS: Motion-Augmented RGB Stream for Action Recognition | Pytorch | 1.2.4 and later | EN JP |
 |
st-gcn | ST-GCN | Pytorch | 1.2.5 and later | EN JP |
 |
ax_action_recognition | Realtime-Action-Recognition | Pytorch | 1.2.7 and later | |
 |
va-cnn | View Adaptive Neural Networks (VA) for Skeleton-based Human Action Recognition | Pytorch | 1.2.7 and later | |
 |
driver-action-recognition-adas | driver-action-recognition-adas-0002 | OpenVINO | 1.2.5 and later | |
 |
action_clip | ActionCLIP | Pytorch | 1.2.7 and later |
| Model | Reference | Exported From | Supported Ailia Version | Date | Blog | |
|---|---|---|---|---|---|---|
 |
mahalanobisad | MahalanobisAD-pytorch | Pytorch | 1.2.9 and later | May 2020 | |
 |
spade-pytorch | Sub-Image Anomaly Detection with Deep Pyramid Correspondences | Pytorch | 1.2.6 and later | May 2020 | |
 |
padim | PaDiM-Anomaly-Detection-Localization-master | Pytorch | 1.2.6 and later | Nov 2020 | EN JP |
 |
patchcore | PatchCore_anomaly_detection | Pytorch | 1.2.6 and later | Jun 2021 |
| Model | Reference | Exported From | Supported Ailia Version | Blog |
|---|---|---|---|---|
| qwen_audio | Qwen-Audio | Pytorch | 1.5.0 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog |
|---|---|---|---|---|
| crnn_audio_classification | crnn-audio-classification | Pytorch | 1.2.5 and later | EN JP |
| transformer-cnn-emotion-recognition | Combining Spatial and Temporal Feature Representions of Speech Emotion by Parallelizing CNNs and Transformer-Encoders | Pytorch | 1.2.5 and later | |
| audioset_tagging_cnn | PANNs: Large-Scale Pretrained Audio Neural Networks for Audio Pattern Recognition | Pytorch | 1.2.9 and later | |
| clap | CLAP | Pytorch | 1.2.6 and later | |
| microsoft clap | CLAP | Pytorch | 1.2.11 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog |
|---|---|---|---|---|
| hifigan | HiFi-GAN | Pytorch | 1.2.9 and later | |
| deep music enhancer | On Filter Generalization for Music Bandwidth Extension Using Deep Neural Networks | Pytorch | 1.2.6 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog |
|---|---|---|---|---|
| pytorch_wavenet | pytorch_wavenet | Pytorch | 1.2.14 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog |
|---|---|---|---|---|
| unet_source_separation | source_separation | Pytorch | 1.2.6 and later | EN JP |
| voicefilter | VoiceFilter | Pytorch | 1.2.7 and later | EN JP |
| rnnoise | rnnoise | Keras | 1.2.15 and later | |
| dtln | Dual-signal Transformation LSTM Network | Tensorflow | 1.3.0 and later | |
| audiosep | AudioSep | Pytorch | 1.3.0 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog |
|---|---|---|---|---|
| narabas | narabas: Japanese phoneme forced alignment tool | Pytorch | 1.2.11 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog |
|---|---|---|---|---|
| crepe | torchcrepe | Pytorch | 1.2.10 and later | JP |
| Model | Reference | Exported From | Supported Ailia Version | Blog |
|---|---|---|---|---|
| auto_speech | AutoSpeech: Neural Architecture Search for Speaker Recognition | Pytorch | 1.2.5 and later | EN JP |
| wespeaker | WeSpeaker | Onnxruntime | 1.2.9 and later | |
| pyannote-audio | Pyannote-audio | Pytorch | 1.2.15 and later | JP |
| Model | Reference | Exported From | Supported Ailia Version | Date | Blog |
|---|---|---|---|---|---|
| deepspeech2 | deepspeech.pytorch | Pytorch | 1.2.2 and later | Oct 2017 | EN JP |
| whisper | Whisper | Pytorch | 1.2.10 and later | Dec 2022 | JP |
| reazon_speech | ReazonSpeech | Pytorch | 1.4.0 and later | Jan 2023 | |
| distil-whisper | Hugging Face - Distil-Whisper | Pytorch | 1.2.16 and later | Nov 2023 | |
| reazon_speech2 | ReazonSpeech2 | Pytorch | 1.4.0 and later | Feb 2024 | |
| kotoba-whisper | kotoba-whisper | Pytorch | 1.2.16 and later | Apr 2024 |
| Model | Reference | Exported From | Supported Ailia Version | Date | Blog |
|---|---|---|---|---|---|
| pytorch-dc-tts | Efficiently Trainable Text-to-Speech System Based on Deep Convolutional Networks with Guided Attention | Pytorch | 1.2.6 and later | Oct 2017 | EN JP |
| tacotron2 | Tacotron2 | Pytorch | 1.2.15 and later | Feb 2018 | JP |
| vall-e-x | VALL-E-X | Pytorch | 1.2.15 and later | Mar 2023 | JP |
| Bert-VITS2 | Bert-VITS2 | Pytorch | 1.2.16 and later | Aug 2023 | |
| gpt-sovits | GPT-SoVITS | Pytorch | 1.4.0 and later | Feb 2024 | JP |
| gpt-sovits-v2 | GPT-SoVITS | Pytorch | 1.4.0 and later | Aug 2024 |
| Model | Reference | Exported From | Supported Ailia Version | Blog |
|---|---|---|---|---|
| silero-vad | Silero VAD | Pytorch | 1.2.15 and later | JP |
| Model | Reference | Exported From | Supported Ailia Version | Blog |
|---|---|---|---|---|
| rvc | Retrieval-based-Voice-Conversion-WebUI | Pytorch | 1.2.12 and later | JP |
| Model | Reference | Exported From | Supported Ailia Version | Blog | |
|---|---|---|---|---|---|
 |
U-2-Net | U^2-Net: Going Deeper with Nested U-Structure for Salient Object Detection | Pytorch | 1.2.2 and later | EN JP |
 |
u2net-portrait-matting | U^2-Net - Portrait matting | Pytorch | 1.2.7 and later | |
 |
u2net-human-seg | U^2-Net - human segmentation | Pytorch | 1.2.4 and later | |
 |
deep-image-matting | Deep Image Matting | Keras | 1.2.3 and later | EN JP |
 |
indexnet | Indices Matter: Learning to Index for Deep Image Matting | Pytorch | 1.2.7 and later | |
 |
modnet | MODNet: Trimap-Free Portrait Matting in Real Time | Pytorch | 1.2.7 and later | |
 |
background_matting_v2 | Real-Time High-Resolution Background Matting | Pytorch | 1.2.9 and later | |
 |
cascade_psp | CascadePSP | Pytorch | 1.2.9 and later | |
 |
rembg | Rembg | Pytorch | 1.2.4 and later | |
 |
dis_seg | Highly Accurate Dichotomous Image Segmentation | Pytorch | 1.2.10 and later | |
 |
gfm | Bridging Composite and Real: Towards End-to-end Deep Image Matting | Pytorch | 1.2.10 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog | |
|---|---|---|---|---|---|
 |
crowdcount-cascaded-mtl | CNN-based Cascaded Multi-task Learning of High-level Prior and Density Estimation for Crowd Counting (Single Image Crowd Counting) |
Pytorch | 1.2.1 and later | EN JP |
 |
c-3-framework | Crowd Counting Code Framework(C^3-Framework) | Pytorch | 1.2.5 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog | |
|---|---|---|---|---|---|
 |
clothing-detection | Clothing-Detection | Pytorch | 1.2.1 and later | EN JP |
 |
mmfashion | MMFashion | Pytorch | 1.2.5 and later | EN JP |
 |
mmfashion_tryon | MMFashion virtual try-on | Pytorch | 1.2.8 and later | |
 |
mmfashion_retrieval | MMFashion In-Shop Clothes Retrieval | Pytorch | 1.2.5 and later | |
 |
fashionai-key-points-detection | A Pytorch Implementation of Cascaded Pyramid Network for FashionAI Key Points Detection | Pytorch | 1.2.5 and later | |
 |
person-attributes-recognition-crossroad | person-attributes-recognition-crossroad-0230 | Pytorch | 1.2.10 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog | |
|---|---|---|---|---|---|
 |
monodepth2 | Monocular depth estimation from a single image | Pytorch | 1.2.2 and later | |
 |
midas | Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer |
Pytorch | 1.2.4 and later | EN JP |
 |
fcrn-depthprediction | Deeper Depth Prediction with Fully Convolutional Residual Networks | TensorFlow | 1.2.6 and later | |
 |
fast-depth | ICRA 2019 "FastDepth: Fast Monocular Depth Estimation on Embedded Systems" | Pytorch | 1.2.5 and later | |
 |
lap-depth | LapDepth-release | Pytorch | 1.2.9 and later | |
 |
hitnet | ONNX-HITNET-Stereo-Depth-estimation | Pytorch | 1.2.9 and later | |
 |
crestereo | ONNX-CREStereo-Depth-Estimation | Pytorch | 1.2.13 and later | |
 |
mobilestereonet | MobileStereoNet | Pytorch | 1.2.13 and later | |
 |
zoe_depth | ZoeDepth | Pytorch | 1.3.0 and later | |
 |
DepthAnything | DepthAnything | Pytorch | 1.2.9 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog | |
|---|---|---|---|---|---|
 |
latent-diffusion-txt2img | Latent Diffusion - txt2img | Pytorch | 1.2.10 and later | |
 |
stable-diffusion-txt2img | Stable Diffusion | Pytorch | 1.2.14 and later | JP |
 |
control_net | ControlNet | Pytorch | 1.2.15 and later | |
 |
sd-turbo | Hugging Face - SD-Turbo | Pytorch | 1.2.16 and later | |
 |
sdxl-turbo | Hugging Face - SDXL-Turbo | Pytorch | 1.2.16 and later | |
 |
latent-consistency-models | latent-consistency-models | Pytorch | 1.2.16 and later | |
 |
anything_v3 | Linaqruf/anything-v3.0 | Pytorch | 1.5.0 and later | |
 |
depth_anything_controlnet | DepthAnything | Pytorch | 1.2.16 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog | |
|---|---|---|---|---|---|
 |
riffusion | Riffusion | Pytorch | 1.2.16 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog | |
|---|---|---|---|---|---|
 |
latent-diffusion-inpainting | Latent Diffusion - inpainting | Pytorch | 1.2.10 and later | |
 |
latent-diffusion-superresolution | Latent Diffusion - Super-resolution | Pytorch | 1.2.10 and later | |
 |
DA-CLIP | DA-CLIP | Pytorch | 1.2.16 and later | |
 |
marigold | Marigold: Repurposing Diffusion-Based Image Generators for Monocular Depth Estimation | Pytorch | 1.2.16 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog | |
|---|---|---|---|---|---|
 |
yolov1-face | YOLO-Face-detection | Darknet | 1.1.0 and later | |
 |
yolov3-face | Face detection using keras-yolov3 | Keras | 1.2.1 and later | |
 |
blazeface | BlazeFace-PyTorch | Pytorch | 1.2.1 and later | EN JP |
 |
face-mask-detection | Face detection using keras-yolov3 | Keras | 1.2.1 and later | EN JP |
 |
dbface | DBFace : real-time, single-stage detector for face detection, with faster speed and higher accuracy |
Pytorch | 1.2.2 and later | |
 |
retinaface | RetinaFace: Single-stage Dense Face Localisation in the Wild. | Pytorch | 1.2.5 and later | JP |
 |
anime-face-detector | Anime Face Detector | Pytorch | 1.2.6 and later | |
 |
face-detection-adas | face-detection-adas-0001 | OpenVINO | 1.2.5 and later | |
 |
mtcnn | mtcnn | Keras | 1.2.10 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog | |
|---|---|---|---|---|---|
 |
vggface2 | VGGFace2 Dataset for Face Recognition | Caffe | 1.1.0 and later | |
 |
arcface | pytorch implement of arcface | Pytorch | 1.2.1 and later | EN JP |
 |
insightface | InsightFace: 2D and 3D Face Analysis Project | Pytorch | 1.2.5 and later | |
 |
cosface | Pytorch implementation of CosFace | Pytorch | 1.2.10 and later | |
 |
facenet_pytorch | Face Recognition Using Pytorch | Pytorch | 1.2.6 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog | |
|---|---|---|---|---|---|
 |
face_classification | Real-time face detection and emotion/gender classification | Keras | 1.1.0 and later | |
 |
age-gender-recognition-retail | age-gender-recognition-retail-0013 | OpenVINO | 1.2.5 and later | EN JP |
 |
mivolo | MiVOLO: Multi-input Transformer for Age and Gender Estimation | Pytorch | 1.2.13 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog | |
|---|---|---|---|---|---|
 |
ferplus | FER+ | CNTK | 1.2.2 and later | |
 |
hsemotion | HSEmotion (High-Speed face Emotion recognition) library | Pytorch | 1.2.5 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog | |
|---|---|---|---|---|---|
 |
gazeml | A deep learning framework based on Tensorflow for the training of high performance gaze estimation |
TensorFlow | 1.2.0 and later | |
 |
mediapipe_iris | irislandmarks.pytorch | Pytorch | 1.2.2 and later | EN JP |
 |
ax_gaze_estimation | ax Gaze Estimation | Pytorch | 1.2.2 and later | EN JP |
 |
gazelle | gazelle | Pytorch | 1.2.16 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog | |
|---|---|---|---|---|---|
 |
hopenet | deep-head-pose | Pytorch | 1.2.2 and later | EN JP |
 |
6d_repnet | 6D Rotation Representation for Unconstrained Head Pose Estimation (Pytorch) | Pytorch | 1.2.6 and later | |
 |
L2CS_Net | L2CS_Net | Pytorch | 1.2.9 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog | |
|---|---|---|---|---|---|
 |
facial_feature | kaggle-facial-keypoints | Pytorch | 1.2.0 and later | |
 |
face_alignment | 2D and 3D Face alignment library build using pytorch | Pytorch | 1.2.1 and later | EN JP |
 |
prnet | Joint 3D Face Reconstruction and Dense Alignment with Position Map Regression Network |
TensorFlow | 1.2.2 and later | |
 |
facemesh | facemesh.pytorch | Pytorch | 1.2.2 and later | EN JP |
 |
facemesh_v2 | MediaPipe Face landmark detection | Pytorch | 1.2.9 and later | JP |
 |
3ddfa | Towards Fast, Accurate and Stable 3D Dense Face Alignment | Pytorch | 1.2.10 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog | |
|---|---|---|---|---|---|
 |
ax_facial_features | ax Facial Features | Pytorch | 1.2.5 and later | EN |
 |
face-anti-spoofing | Lightweight Face Anti Spoofing | Pytorch | 1.2.5 and later | EN JP |
| Model | Reference | Exported From | Supported Ailia Version | Blog | |
|---|---|---|---|---|---|
 |
gfpgan | GFP-GAN: Towards Real-World Blind Face Restoration with Generative Facial Prior | Pytorch | 1.2.10 and later | JP |
 |
codeformer | CodeFormer: Towards Robust Blind Face Restoration with Codebook Lookup Transformer | Pytorch | 1.2.9 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog | |
|---|---|---|---|---|---|
 |
sber-swap | SberSwap | Pytorch | 1.2.12 and later | JP |
 |
facefusion | FaceFusion | ONNX Runtime | 1.2.10 and later | |
 |
deepfacelive | DeepFaceLive | ONNX Runtime | 1.2.10 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog | |
|---|---|---|---|---|---|
 |
flavr | FLAVR: Flow-Agnostic Video Representations for Fast Frame Interpolation | Pytorch | 1.2.7 and later | EN JP |
 |
cain | Channel Attention Is All You Need for Video Frame Interpolation | Pytorch | 1.2.5 and later | |
 |
film | FILM: Frame Interpolation for Large Motion | Tensorflow | 1.2.10 and later | |
 |
rife | Real-Time Intermediate Flow Estimation for Video Frame Interpolation | Pytorch | 1.2.13 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog | |
|---|---|---|---|---|---|
 |
pytorch-gan | Code repo for the Pytorch GAN Zoo project (used to train this model) | Pytorch | 1.2.4 and later | |
 |
council-gan | Council-GAN | Pytorch | 1.2.4 and later | |
 |
restyle-encoder | ReStyle | Pytorch | 1.2.9 and later | |
 |
sam | Age Transformation Using a Style-Based Regression Model | Pytorch | 1.2.9 and later | |
 |
encoder4editing | Designing an Encoder for StyleGAN Image Manipulation | Pytorch | 1.2.10 and later | |
 |
lipgan | LipGAN | Keras | 1.2.15 and later | JP |
 |
live_portrait | LivePortrait | Pytorch | 1.5.0 and later | JP |
| Model | Reference | Exported From | Supported Ailia Version | Blog | |
|---|---|---|---|---|---|
 |
yolov3-hand | Hand detection branch of Face detection using keras-yolov3 | Keras | 1.2.1 and later | |
 |
hand_detection_pytorch | hand-detection.PyTorch | Pytorch | 1.2.2 and later | |
 |
blazepalm | MediaPipePyTorch | Pytorch | 1.2.5 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog | |
|---|---|---|---|---|---|
 |
blazehand | MediaPipePyTorch | Pytorch | 1.2.5 and later | EN JP |
 |
hand3d | ColorHandPose3D network | TensorFlow | 1.2.5 and later | |
 |
minimal-hand | Minimal Hand | TensorFlow | 1.2.8 and later | |
 |
v2v-posenet | V2V-PoseNet | Pytorch | 1.2.6 and later | |
 |
hands_segmentation_pytorch | hands-segmentation-pytorch | Pytorch | 1.2.10 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog | |
|---|---|---|---|---|---|
 |
illustration2vec | Illustration2Vec | Caffe | 1.2.2 and later | |
 |
image_captioning_pytorch | Image Captioning pytorch | Pytorch | 1.2.5 and later | EN JP |
 |
blip2 | Hugging Face - BLIP-2 | Pytorch | 1.2.16 and later |

















| Model | Reference | Exported From | Supported Ailia Version | Blog | |
|---|---|---|---|---|---|
 |
vit | Pytorch reimplementation of the Vision Transformer (An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale) | Pytorch | 1.2.7 and later | EN JP |
 |
swin-transformer | Swin Transformer | Pytorch | 1.2.6 and later | |
 |
clip | CLIP | Pytorch | 1.2.9 and later | EN JP |
 |
japanese-clip | Japanese-CLIP | Pytorch | 1.2.15 and later | |
 |
japanese-stable-clip-vit-l-16 | japanese-stable-clip-vit-l-16 | Pytorch | 1.2.11 and later | |
 |
clip-japanese-base | line-corporation/clip-japanese-base | Pytorch | 1.2.16 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog | |
|---|---|---|---|---|---|
 |
partialconv | Partial Convolution Layer for Padding and Image Inpainting | Pytorch | 1.2.0 and later | |
 |
weather-prediction-from-image | Weather Prediction From Image - (Warmth Of Image) | Keras | 1.2.5 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog | |
|---|---|---|---|---|---|
 |
inpainting-with-partial-conv | pytorch-inpainting-with-partial-conv | PyTorch | 1.2.6 and later | EN JP |
 |
inpainting_gmcnn | Image Inpainting via Generative Multi-column Convolutional Neural Networks | TensorFlow | 1.2.6 and later | |
 |
3d-photo-inpainting | 3D Photography using Context-aware Layered Depth Inpainting | Pytorch | 1.2.7 and later | |
 |
deepfillv2 | Free-Form Image Inpainting with Gated Convolution | Pytorch | 1.2.9 and later | |
 |
lama | LaMa: Resolution-robust Large Mask Inpainting with Fourier Convolutions | Pytorch | 1.2.13 and later |

















| Model | Reference | Exported From | Supported Ailia Version | Blog | |
|---|---|---|---|---|---|
 |
nafnet | NAFNet: Nonlinear Activation Free Network for Image Restoration | Pytorch | 1.2.10 and later |






















| Model | Reference | Exported From | Supported Ailia Version | Blog | |
|---|---|---|---|---|---|
 |
landmarks_classifier_asia | Landmarks classifier_asia_V1.1 | TensorFlow Hub | 1.2.4 and later | EN JP |
 |
places365 | Release of Places365-CNNs | Pytorch | 1.2.5 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog | |
|---|---|---|---|---|---|
 |
mlsd | M-LSD: Towards Light-weight and Real-time Line Segment Detection | TensorFlow | 1.2.8 and later | EN JP |
 |
dexined | DexiNed: Dense Extreme Inception Network for Edge Detection | Pytorch | 1.2.5 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog | |
|---|---|---|---|---|---|
 |
agllnet | AGLLNet: Attention Guided Low-light Image Enhancement (IJCV 2021) | Pytorch | 1.2.9 and later | EN JP |
 |
drbn_skf | DRBN SKF | Pytorch | 1.2.14 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog |
|---|---|---|---|---|
| bert | pytorch-pretrained-bert | Pytorch | 1.2.2 and later | EN JP |
| bert_maskedlm | huggingface/transformers | Pytorch | 1.2.5 and later | |
| bert_question_answering | huggingface/transformers | Pytorch | 1.2.5 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog |
|---|---|---|---|---|
| sentence_transformers_japanese | sentence transformers | Pytorch | 1.2.7 and later | JP |
| multilingual-e5 | multilingual-e5-base | Pytorch | 1.2.15 and later | JP |
| glucose | GLuCoSE (General Luke-based Contrastive Sentence Embedding)-base-Japanese | Pytorch | 1.2.15 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog |
|---|---|---|---|---|
| bert_insert_punctuation | bert-japanese | Pytorch | 1.2.15 and later | |
| t5_whisper_medical | error correction of medical terms using t5 | Pytorch | 1.2.13 and later | |
| bertjsc | bertjsc | Pytorch | 1.2.15 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog |
|---|---|---|---|---|
| soundchoice-g2p | Hugging Face - speechbrain/soundchoice-g2p | Pytorch | 1.2.16 and later | |
| g2p_en | g2p_en | Pytorch | 1.2.14 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog |
|---|---|---|---|---|
| bert_ner | huggingface/transformers | Pytorch | 1.2.5 and later | |
| t5_base_japanese_ner | t5-japanese | Pytorch | 1.2.13 and later | |
| bert_ner_japanese | jurabi/bert-ner-japanese | Pytorch | 1.2.10 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog |
|---|---|---|---|---|
| cross_encoder_mmarco | jeffwan/mmarco-mMiniLMv2-L12-H384-v | Pytorch | 1.2.10 and later | JP |
| japanese-reranker-cross-encoder | hotchpotch/japanese-reranker-cross-encoder-large-v1 | Pytorch | 1.2.16 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog |
|---|---|---|---|---|
| gpt2 | GPT-2 | Pytorch | 1.2.7 and later | |
| rinna_gpt2 | japanese-pretrained-models | Pytorch | 1.2.7 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog |
|---|---|---|---|---|
| bert_sentiment_analysis | huggingface/transformers | Pytorch | 1.2.5 and later | |
| bert_tweets_sentiment | huggingface/transformers | Pytorch | 1.2.5 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog |
|---|---|---|---|---|
| bert_sum_ext | BERTSUMEXT | Pytorch | 1.2.7 and later | |
| presumm | PreSumm | Pytorch | 1.2.8 and later | |
| t5_base_japanese_title_generation | t5-japanese | Pytorch | 1.2.13 and later | JP |
| t5_base_summarization | t5-japanese | Pytorch | 1.2.13 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog |
|---|---|---|---|---|
| fugumt-en-ja | Fugu-Machine Translator | Pytorch | 1.2.9 and later | JP |
| fugumt-ja-en | Fugu-Machine Translator | Pytorch | 1.2.10 abd later |
| Model | Reference | Exported From | Supported Ailia Version | Blog |
|---|---|---|---|---|
| bert_zero_shot_classification | huggingface/transformers | Pytorch | 1.2.5 and later | |
| multilingual-minilmv2 | MoritzLaurer/multilingual-MiniLMv2-L12-mnli-xnli | Pytorch | 1.2.10 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog |
|---|---|---|---|---|
| bert-network-packet-flow-header-payload | bert-network-packet-flow-header-payload | Pytorch | 1.2.10 and later | |
| falcon-adapter-network-packet | falcon-adapter-network-packet | Pytorch | 1.2.10 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog | |
|---|---|---|---|---|---|
 |
nerf | NeRF: Neural Radiance Fields | Tensorflow | 1.2.10 and later | EN JP |
 |
TripoSR | TripoSR | Pytorch | 1.2.6 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog |
|---|---|---|---|---|
| clip-based-nsfw-detector | CLIP-based-NSFW-Detector | Keras | 1.2.10 and later | JP |
































| Model | Reference | Exported From | Supported Ailia Version | Date | Blog | |
|---|---|---|---|---|---|---|
 |
glip | GLIP | Pytorch | 1.2.13 and later | Dec 2021 | |
 |
dab-detr | DAB-DETR | Pytorch | 1.2.12 and later | Jan 2022 | |
 |
detic | Detecting Twenty-thousand Classes using Image-level Supervision | Pytorch | 1.2.10 and later | Jan 2022 | EN JP |
 |
groundingdino | Grounding DINO | Pytorch | 1.2.16 and later | Mar 2023 | JP |
 |
rt-detr-v2 | RT-DETR | Pytorch | 1.2.13 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog | |
|---|---|---|---|---|---|
 |
mobile_object_localizer | mobile_object_localizer_v1 | TensorFlow Hub | 1.2.6 and later | EN JP |
 |
sku110k-densedet | SKU110K-DenseDet | Pytorch | 1.2.9 and later | EN JP |
 |
traffic-sign-detection | Traffic Sign Detection | Tensorflow | 1.2.10 and later | EN JP |
 |
footandball | FootAndBall: Integrated player and ball detector | Pytorch | 1.2.0 and later | |
 |
qrcode_wechatqrcode | qrcode_wechatqrcode | Caffe | 1.2.15 and later | |
 |
layout_parsing | unstructured-inference | Pytorch | 1.2.9 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog | |
|---|---|---|---|---|---|
 |
3d_bbox | 3D Bounding Box Estimation Using Deep Learning and Geometry | Pytorch | 1.2.6 and later | |
 |
3d-object-detection.pytorch | 3d-object-detection.pytorch | Pytorch | 1.2.8 and later | EN JP |
 |
mediapipe_objectron | MediaPipe Objectron | TensorFlow Lite | 1.2.5 and later | |
 |
egonet | EgoNet | Pytorch | 1.2.9 and later | |
 |
d4lcn | D4LCN | Pytorch | 1.2.9 and later | |
 |
did_m3d | DID M3D | Pytorch | 1.2.11 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog | |
|---|---|---|---|---|---|
 |
deepsort | Deep Sort with PyTorch | Pytorch | 1.2.3 and later | EN JP |
 |
person_reid_baseline_pytorch | UTS-Person-reID-Practical | Pytorch | 1.2.6 and later | |
 |
abd_net | Attentive but Diverse Person Re-Identification | Pytorch | 1.2.7 and later | |
 |
siam-mot | SiamMOT | Pytorch | 1.2.9 and later | |
 |
bytetrack | ByteTrack | Pytorch | 1.2.5 and later | EN JP |
 |
qd-3dt | Monocular Quasi-Dense 3D Object Tracking | Pytorch | 1.2.11 and later | |
 |
strong_sort | StrongSORT | Pytorch | 1.2.15 and later | |
 |
centroids-reid | On the Unreasonable Effectiveness of Centroids in Image Retrieval | Pytorch | 1.2.9 and later | |
 |
deepsort_vehicle | Multi-Camera Live Object Tracking | Pytorch | 1.2.9 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog | |
|---|---|---|---|---|---|
 |
raft | RAFT: Recurrent All Pairs Field Transforms for Optical Flow | Pytorch | 1.2.6 and later | EN JP |
| Model | Reference | Exported From | Supported Ailia Version | Blog | |
|---|---|---|---|---|---|
 |
pointnet_pytorch | PointNet.pytorch | Pytorch | 1.2.6 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog | |
|---|---|---|---|---|---|
 |
openpose | Code repo for realtime multi-person pose estimation in CVPR'17 (Oral) | Caffe | 1.2.1 and later | |
 |
lightweight-human-pose-estimation | Fast and accurate human pose estimation in PyTorch. Contains implementation of "Real-time 2D Multi-Person Pose Estimation on CPU: Lightweight OpenPose" paper. |
Pytorch | 1.2.1 and later | EN JP |
 |
pose_resnet | Simple Baselines for Human Pose Estimation and Tracking | Pytorch | 1.2.1 and later | EN JP |
 |
blazepose | MediaPipePyTorch | Pytorch | 1.2.5 and later | |
 |
efficientpose | Code repo for EfficientPose | TensorFlow | 1.2.6 and later | |
 |
movenet | Code repo for movenet | TensorFlow | 1.2.8 and later | EN JP |
 |
animalpose | MMPose - 2D animal pose estimation | Pytorch | 1.2.7 and later | EN JP |
 |
mediapipe_holistic | MediaPipe Holistic | TensorFlow | 1.2.9 and later | |
 |
ap-10k | AP-10K | Pytorch | 1.2.4 and later | |
 |
posenet | PoseNet Pytorch | Pytorch | 1.2.10 and later | |
 |
e2pose | E2Pose | Tensorflow | 1.2.5 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog | |
|---|---|---|---|---|---|
 |
lightweight-human-pose-estimation-3d | Real-time 3D multi-person pose estimation demo in PyTorch. OpenVINO backend can be used for fast inference on CPU. |
Pytorch | 1.2.1 and later | |
 |
3d-pose-baseline | A simple baseline for 3d human pose estimation in tensorflow. Presented at ICCV 17. |
TensorFlow | 1.2.3 and later | |
 |
pose-hg-3d | Towards 3D Human Pose Estimation in the Wild: a Weakly-supervised Approach | Pytorch | 1.2.6 and later | |
 |
blazepose-fullbody | MediaPipe | TensorFlow Lite | 1.2.5 and later | EN JP |
 |
3dmppe_posenet | PoseNet of "Camera Distance-aware Top-down Approach for 3D Multi-person Pose Estimation from a Single RGB Image" | Pytorch | 1.2.6 and later | |
 |
gast | A Graph Attention Spatio-temporal Convolutional Networks for 3D Human Pose Estimation in Video (GAST-Net) | Pytorch | 1.2.7 and later | EN JP |
 |
mediapipe_pose_world_landmarks | MediaPipe Pose real-world 3D coordinates | TensorFlow Lite | 1.2.10 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog | |
|---|---|---|---|---|---|
 |
codes-for-lane-detection | Codes-for-Lane-Detection | Pytorch | 1.2.6 and later | EN JP |
 |
roneld | RONELD-Lane-Detection | Pytorch | 1.2.6 and later | |
 |
road-segmentation-adas | road-segmentation-adas-0001 | OpenVINO | 1.2.5 and later | |
 |
cdnet | CDNet | Pytorch | 1.2.5 and later | |
 |
lstr | LSTR | Pytorch | 1.2.8 and later | |
 |
ultra-fast-lane-detection | Ultra-Fast-Lane-Detection | Pytorch | 1.2.6 and later | |
 |
yolop | YOLOP | Pytorch | 1.2.6 and later | |
 |
hybridnets | HybridNets | Pytorch | 1.2.6 and later | |
 |
polylanenet | PolyLaneNet | Pytorch | 1.2.9 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog | |
|---|---|---|---|---|---|
 |
rotnet | CNNs for predicting the rotation angle of an image to correct its orientation | Keras | 1.2.1 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog | |
|---|---|---|---|---|---|
 |
adain | Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization | Pytorch | 1.2.1 and later | EN JP |
 |
psgan | PSGAN: Pose and Expression Robust Spatial-Aware GAN for Customizable Makeup Transfer | Pytorch | 1.2.7 and later | |
 |
beauty_gan | BeautyGAN | Pytorch | 1.2.7 and later | |
 |
animeganv2 | PyTorch Implementation of AnimeGANv2 | Pytorch | 1.2.5 and later | |
 |
pix2pixHD | pix2pixHD: High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs | Pytorch | 1.2.6 and later | |
 |
EleGANt | EleGANt: Exquisite and Locally Editable GAN for Makeup Transfer | Pytorch | 1.2.15 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog | |
|---|---|---|---|---|---|
 |
srresnet | Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network | Pytorch | 1.2.0 and later | EN JP |
 |
edsr | Enhanced Deep Residual Networks for Single Image Super-Resolution | Pytorch | 1.2.6 and later | EN JP |
 |
han | Single Image Super-Resolution via a Holistic Attention Network | Pytorch | 1.2.6 and later | |
 |
real-esrgan | Real-ESRGAN | Pytorch | 1.2.9 and later | |
 |
rcan-it | Revisiting RCAN: Improved Training for Image Super-Resolution | Pytorch | 1.2.10 and later | |
 |
swinir | SwinIR: Image Restoration Using Swin Transformer | Pytorch | 1.2.12 and later | |
 |
Hat | Hat | Pytorch | 1.2.6 and later | |
 |
SPAN | SPAN | Pytorch | 1.2.14 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog | |
|---|---|---|---|---|---|
 |
craft_pytorch | CRAFT: Character-Region Awareness For Text detection | Pytorch | 1.2.2 and later | |
 |
pixel_link | Pixel-Link | TensorFlow | 1.2.6 and later | |
 |
east | EAST: An Efficient and Accurate Scene Text Detector | TensorFlow | 1.2.6 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog | |
|---|---|---|---|---|---|
 |
etl | Japanese Character Classification | Keras | 1.1.0 and later | JP |
 |
deep-text-recognition-benchmark | deep-text-recognition-benchmark | Pytorch | 1.2.6 and later | |
 |
crnn.pytorch | Convolutional Recurrent Neural Network | Pytorch | 1.2.6 and later | |
 |
paddleocr | PaddleOCR : Awesome multilingual OCR toolkits based on PaddlePaddle | Pytorch | 1.2.6 and later | EN JP |
 |
easyocr | Ready-to-use OCR with 80+ supported languages | Pytorch | 1.2.6 and later | |
 |
ndlocr_text_recognition | NDL OCR | Pytorch | 1.2.5 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog |
|---|---|---|---|---|
| informer2020 | Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting (AAAI'21 Best Paper) | Pytorch | 1.2.10 and later | |
| timesfm | TimesFM | Pytorch | 1.2.16 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog | |
|---|---|---|---|---|---|
 |
vehicle-attributes-recognition-barrier | vehicle-attributes-recognition-barrier-0042 | OpenVINO | 1.2.5 and later | EN JP |
 |
vehicle-license-plate-detection-barrier | vehicle-license-plate-detection-barrier-0106 | OpenVINO | 1.2.5 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog | |
|---|---|---|---|---|---|
 |
llava | LLaVA | Pytorch | 1.2.16 and later | |
 |
florence2 | Hugging Face - microsoft/Florence-2-base | Pytorch | 1.2.16 and later | |
 |
qwen2_vl | Qwen2-VL | Pytorch | 1.5.0 and later | |
 |
llava-jp | LLaVA-JP | Pytorch | 1.5.0 and later |
| Model | Reference | Exported From | Supported Ailia Version | Blog |
|---|---|---|---|---|
| acculus-pose | Acculus, Inc. | Caffe | 1.2.3 and later |
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ailia-models
Similar Open Source Tools
ailia-models
The collection of pre-trained, state-of-the-art AI models. ailia SDK is a self-contained, cross-platform, high-speed inference SDK for AI. The ailia SDK provides a consistent C++ API across Windows, Mac, Linux, iOS, Android, Jetson, and Raspberry Pi platforms. It also supports Unity (C#), Python, Rust, Flutter(Dart) and JNI for efficient AI implementation. The ailia SDK makes extensive use of the GPU through Vulkan and Metal to enable accelerated computing. # Supported models 323 models as of April 8th, 2024

Awesome-LLM-Eval
Awesome-LLM-Eval: a curated list of tools, benchmarks, demos, papers for Large Language Models (like ChatGPT, LLaMA, GLM, Baichuan, etc) Evaluation on Language capabilities, Knowledge, Reasoning, Fairness and Safety.

LLamaTuner
LLamaTuner is a repository for the Efficient Finetuning of Quantized LLMs project, focusing on building and sharing instruction-following Chinese baichuan-7b/LLaMA/Pythia/GLM model tuning methods. The project enables training on a single Nvidia RTX-2080TI and RTX-3090 for multi-round chatbot training. It utilizes bitsandbytes for quantization and is integrated with Huggingface's PEFT and transformers libraries. The repository supports various models, training approaches, and datasets for supervised fine-tuning, LoRA, QLoRA, and more. It also provides tools for data preprocessing and offers models in the Hugging Face model hub for inference and finetuning. The project is licensed under Apache 2.0 and acknowledges contributions from various open-source contributors.
step_into_llm
The 'step_into_llm' repository is dedicated to the 昇思MindSpore technology open class, which focuses on exploring cutting-edge technologies, combining theory with practical applications, expert interpretations, open sharing, and empowering competitions. The repository contains course materials, including slides and code, for the ongoing second phase of the course. It covers various topics related to large language models (LLMs) such as Transformer, BERT, GPT, GPT2, and more. The course aims to guide developers interested in LLMs from theory to practical implementation, with a special emphasis on the development and application of large models.
2020-12th-ironman
This repository contains tutorial content for the 12th iT Help Ironman competition, focusing on machine learning algorithms and their practical applications. The tutorials cover topics such as AI model integration, API server deployment techniques, and hands-on programming exercises. The series is presented in video format and will be compiled into an e-book in the future. Suitable for those familiar with Python, interested in implementing AI prediction models, data analysis, and backend integration and deployment of AI models.
ruoyi-vue-pro
The ruoyi-vue-pro repository is an open-source project that provides a comprehensive development platform with various functionalities such as system features, infrastructure, member center, data reports, workflow, payment system, mall system, ERP system, CRM system, and AI big model. It is built using Java backend with Spring Boot framework and Vue frontend with different versions like Vue3 with element-plus, Vue3 with vben(ant-design-vue), and Vue2 with element-ui. The project aims to offer a fast development platform for developers and enterprises, supporting features like dynamic menu loading, button-level access control, SaaS multi-tenancy, code generator, real-time communication, integration with third-party services like WeChat, Alipay, and cloud services, and more.
yudao-boot-mini
yudao-boot-mini is an open-source project focused on developing a rapid development platform for developers in China. It includes features like system functions, infrastructure, member center, data reports, workflow, mall system, WeChat official account, CRM, ERP, etc. The project is based on Spring Boot with Java backend and Vue for frontend. It offers various functionalities such as user management, role management, menu management, department management, workflow management, payment system, code generation, API documentation, database documentation, file service, WebSocket integration, message queue, Java monitoring, and more. The project is licensed under the MIT License, allowing both individuals and enterprises to use it freely without restrictions.
yudao-cloud
Yudao-cloud is an open-source project designed to provide a fast development platform for developers in China. It includes various system functions, infrastructure, member center, data reports, workflow, mall system, WeChat public account, CRM, ERP, etc. The project is based on Java backend with Spring Boot and Spring Cloud Alibaba microservices architecture. It supports multiple databases, message queues, authentication systems, dynamic menu loading, SaaS multi-tenant system, code generator, real-time communication, integration with third-party services like WeChat, Alipay, and more. The project is well-documented and follows the Alibaba Java development guidelines, ensuring clean code and architecture.
llm-book
The 'llm-book' repository is dedicated to the introduction of large-scale language models, focusing on natural language processing tasks. The code is designed to run on Google Colaboratory and utilizes datasets and models available on the Hugging Face Hub. Note that as of July 28, 2023, there are issues with the MARC-ja dataset links, but an alternative notebook using the WRIME Japanese sentiment analysis dataset has been added. The repository covers various chapters on topics such as Transformers, fine-tuning language models, entity recognition, summarization, document embedding, question answering, and more.
so-vits-models
This repository collects various LLM, AI-related models, applications, and datasets, including LLM-Chat for dialogue models, LLMs for large models, so-vits-svc for sound-related models, stable-diffusion for image-related models, and virtual-digital-person for generating videos. It also provides resources for deep learning courses and overviews, AI competitions, and specific AI tasks such as text, image, voice, and video processing.
aidea-server
AIdea Server is an open-source Golang-based server that integrates mainstream large language models and drawing models. It supports various functionalities including OpenAI's GPT-3.5 and GPT-4, Anthropic's Claude instant and Claude 2.1, Google's Gemini Pro, as well as Chinese models like Tongyi Qianwen, Wenxin Yiyuan, and more. It also supports open-source large models like Yi 34B, Llama2, and AquilaChat 7B. Additionally, it provides features for text-to-image, super-resolution, coloring black and white images, generating art fonts and QR codes, among others.

kumo-search
Kumo search is an end-to-end search engine framework that supports full-text search, inverted index, forward index, sorting, caching, hierarchical indexing, intervention system, feature collection, offline computation, storage system, and more. It runs on the EA (Elastic automic infrastructure architecture) platform, enabling engineering automation, service governance, real-time data, service degradation, and disaster recovery across multiple data centers and clusters. The framework aims to provide a ready-to-use search engine framework to help users quickly build their own search engines. Users can write business logic in Python using the AOT compiler in the project, which generates C++ code and binary dynamic libraries for rapid iteration of the search engine.
awesome-hosting
awesome-hosting is a curated list of hosting services sorted by minimal plan price. It includes various categories such as Web Services Platform, Backend-as-a-Service, Lambda, Node.js, Static site hosting, WordPress hosting, VPS providers, managed databases, GPU cloud services, and LLM/Inference API providers. Each category lists multiple service providers along with details on their minimal plan, trial options, free tier availability, open-source support, and specific features. The repository aims to help users find suitable hosting solutions based on their budget and requirements.
yudao-ui-admin-vue3
The yudao-ui-admin-vue3 repository is an open-source project focused on building a fast development platform for developers in China. It utilizes Vue3 and Element Plus to provide features such as configurable themes, internationalization, dynamic route permission generation, common component encapsulation, and rich examples. The project supports the latest front-end technologies like Vue3 and Vite4, and also includes tools like TypeScript, pinia, vueuse, vue-i18n, vue-router, unocss, iconify, and wangeditor. It offers a range of development tools and features for system functions, infrastructure, workflow management, payment systems, member centers, data reporting, e-commerce systems, WeChat public accounts, ERP systems, and CRM systems.
For similar tasks

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.

InternVL
InternVL scales up the ViT to _**6B parameters**_ and aligns it with LLM. It is a vision-language foundation model that can perform various tasks, including: **Visual Perception** - Linear-Probe Image Classification - Semantic Segmentation - Zero-Shot Image Classification - Multilingual Zero-Shot Image Classification - Zero-Shot Video Classification **Cross-Modal Retrieval** - English Zero-Shot Image-Text Retrieval - Chinese Zero-Shot Image-Text Retrieval - Multilingual Zero-Shot Image-Text Retrieval on XTD **Multimodal Dialogue** - Zero-Shot Image Captioning - Multimodal Benchmarks with Frozen LLM - Multimodal Benchmarks with Trainable LLM - Tiny LVLM InternVL has been shown to achieve state-of-the-art results on a variety of benchmarks. For example, on the MMMU image classification benchmark, InternVL achieves a top-1 accuracy of 51.6%, which is higher than GPT-4V and Gemini Pro. On the DocVQA question answering benchmark, InternVL achieves a score of 82.2%, which is also higher than GPT-4V and Gemini Pro. InternVL is open-sourced and available on Hugging Face. It can be used for a variety of applications, including image classification, object detection, semantic segmentation, image captioning, and question answering.

clarifai-python
The Clarifai Python SDK offers a comprehensive set of tools to integrate Clarifai's AI platform to leverage computer vision capabilities like classification , detection ,segementation and natural language capabilities like classification , summarisation , generation , Q&A ,etc into your applications. With just a few lines of code, you can leverage cutting-edge artificial intelligence to unlock valuable insights from visual and textual content.

X-AnyLabeling
X-AnyLabeling is a robust annotation tool that seamlessly incorporates an AI inference engine alongside an array of sophisticated features. Tailored for practical applications, it is committed to delivering comprehensive, industrial-grade solutions for image data engineers. This tool excels in swiftly and automatically executing annotations across diverse and intricate tasks.
ailia-models
The collection of pre-trained, state-of-the-art AI models. ailia SDK is a self-contained, cross-platform, high-speed inference SDK for AI. The ailia SDK provides a consistent C++ API across Windows, Mac, Linux, iOS, Android, Jetson, and Raspberry Pi platforms. It also supports Unity (C#), Python, Rust, Flutter(Dart) and JNI for efficient AI implementation. The ailia SDK makes extensive use of the GPU through Vulkan and Metal to enable accelerated computing. # Supported models 323 models as of April 8th, 2024

edenai-apis
Eden AI aims to simplify the use and deployment of AI technologies by providing a unique API that connects to all the best AI engines. With the rise of **AI as a Service** , a lot of companies provide off-the-shelf trained models that you can access directly through an API. These companies are either the tech giants (Google, Microsoft , Amazon) or other smaller, more specialized companies, and there are hundreds of them. Some of the most known are : DeepL (translation), OpenAI (text and image analysis), AssemblyAI (speech analysis). There are **hundreds of companies** doing that. We're regrouping the best ones **in one place** !

NanoLLM
NanoLLM is a tool designed for optimized local inference for Large Language Models (LLMs) using HuggingFace-like APIs. It supports quantization, vision/language models, multimodal agents, speech, vector DB, and RAG. The tool aims to provide efficient and effective processing for LLMs on local devices, enhancing performance and usability for various AI applications.

open-ai
Open AI is a powerful tool for artificial intelligence research and development. It provides a wide range of machine learning models and algorithms, making it easier for developers to create innovative AI applications. With Open AI, users can explore cutting-edge technologies such as natural language processing, computer vision, and reinforcement learning. The platform offers a user-friendly interface and comprehensive documentation to support users in building and deploying AI solutions. Whether you are a beginner or an experienced AI practitioner, Open AI offers the tools and resources you need to accelerate your AI projects and stay ahead in the rapidly evolving field of artificial intelligence.
For similar jobs
ailia-models
The collection of pre-trained, state-of-the-art AI models. ailia SDK is a self-contained, cross-platform, high-speed inference SDK for AI. The ailia SDK provides a consistent C++ API across Windows, Mac, Linux, iOS, Android, Jetson, and Raspberry Pi platforms. It also supports Unity (C#), Python, Rust, Flutter(Dart) and JNI for efficient AI implementation. The ailia SDK makes extensive use of the GPU through Vulkan and Metal to enable accelerated computing. # Supported models 323 models as of April 8th, 2024

Applio
Applio is a VITS-based Voice Conversion tool focused on simplicity, quality, and performance. It features a user-friendly interface, cross-platform compatibility, and a range of customization options. Applio is suitable for various tasks such as voice cloning, voice conversion, and audio editing. Its key features include a modular codebase, hop length implementation, translations in over 30 languages, optimized requirements, streamlined installation, hybrid F0 estimation, easy-to-use UI, optimized code and dependencies, plugin system, overtraining detector, model search, enhancements in pretrained models, voice blender, accessibility improvements, new F0 extraction methods, output format selection, hashing system, model download system, TTS enhancements, split audio, Discord presence, Flask integration, and support tab.
human
AI-powered 3D Face Detection & Rotation Tracking, Face Description & Recognition, Body Pose Tracking, 3D Hand & Finger Tracking, Iris Analysis, Age & Gender & Emotion Prediction, Gaze Tracking, Gesture Recognition, Body Segmentation

llama_ros
This repository provides a set of ROS 2 packages to integrate llama.cpp into ROS 2. By using the llama_ros packages, you can easily incorporate the powerful optimization capabilities of llama.cpp into your ROS 2 projects by running GGUF-based LLMs and VLMs.

lmdeploy
LMDeploy is a toolkit for compressing, deploying, and serving LLM, developed by the MMRazor and MMDeploy teams. It has the following core features: * **Efficient Inference** : LMDeploy delivers up to 1.8x higher request throughput than vLLM, by introducing key features like persistent batch(a.k.a. continuous batching), blocked KV cache, dynamic split&fuse, tensor parallelism, high-performance CUDA kernels and so on. * **Effective Quantization** : LMDeploy supports weight-only and k/v quantization, and the 4-bit inference performance is 2.4x higher than FP16. The quantization quality has been confirmed via OpenCompass evaluation. * **Effortless Distribution Server** : Leveraging the request distribution service, LMDeploy facilitates an easy and efficient deployment of multi-model services across multiple machines and cards. * **Interactive Inference Mode** : By caching the k/v of attention during multi-round dialogue processes, the engine remembers dialogue history, thus avoiding repetitive processing of historical sessions.
ring-attention-pytorch
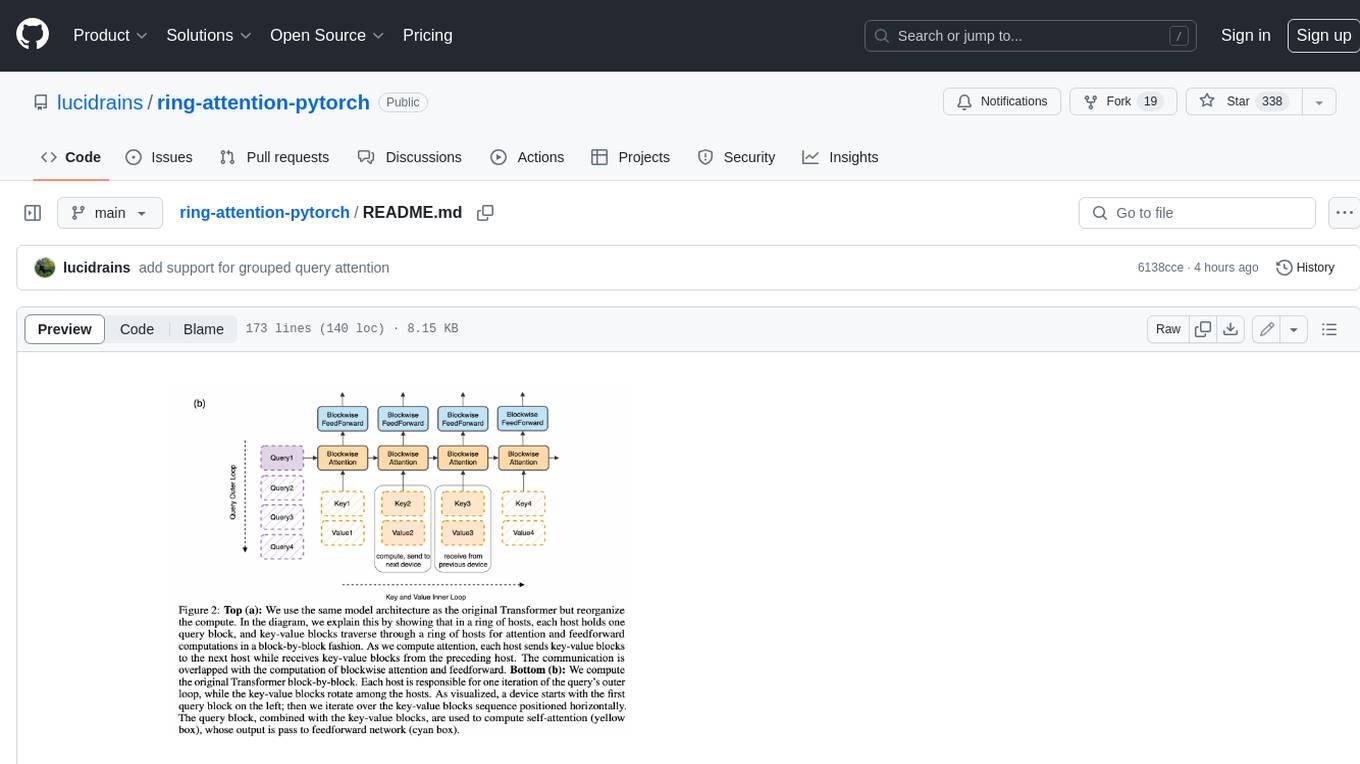
This repository contains an implementation of Ring Attention, a technique for processing large sequences in transformers. Ring Attention splits the data across the sequence dimension and applies ring reduce to the processing of the tiles of the attention matrix, similar to flash attention. It also includes support for Striped Attention, a follow-up paper that permutes the sequence for better workload balancing for autoregressive transformers, and grouped query attention, which saves on communication costs during the ring reduce. The repository includes a CUDA version of the flash attention kernel, which is used for the forward and backward passes of the ring attention. It also includes logic for splitting the sequence evenly among ranks, either within the attention function or in the external ring transformer wrapper, and basic test cases with two processes to check for equivalent output and gradients.
albumentations
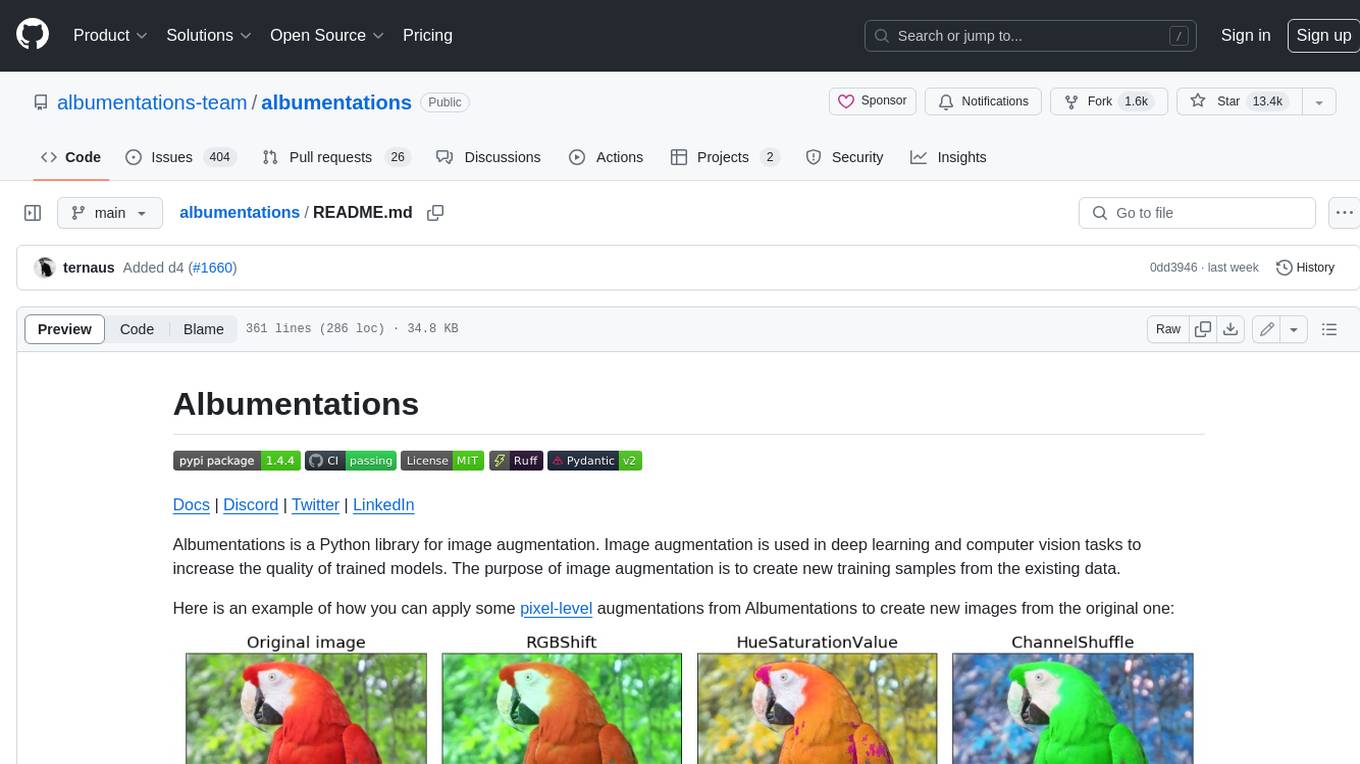
Albumentations is a Python library for image augmentation. Image augmentation is used in deep learning and computer vision tasks to increase the quality of trained models. The purpose of image augmentation is to create new training samples from the existing data.
clarifai-python
The Clarifai Python SDK offers a comprehensive set of tools to integrate Clarifai's AI platform to leverage computer vision capabilities like classification , detection ,segementation and natural language capabilities like classification , summarisation , generation , Q&A ,etc into your applications. With just a few lines of code, you can leverage cutting-edge artificial intelligence to unlock valuable insights from visual and textual content.