Best AI tools for< Object Detection >
Infographic
20 - AI tool Sites

Ultralytics YOLO
Ultralytics YOLO is an advanced real-time object detection and image segmentation model that leverages cutting-edge advancements in deep learning and computer vision. It offers unparalleled performance in terms of speed and accuracy, making it suitable for various applications and easily adaptable to different hardware platforms. The comprehensive Ultralytics Docs provide resources to help users understand and utilize its features and capabilities, catering to both seasoned machine learning practitioners and newcomers to the field.
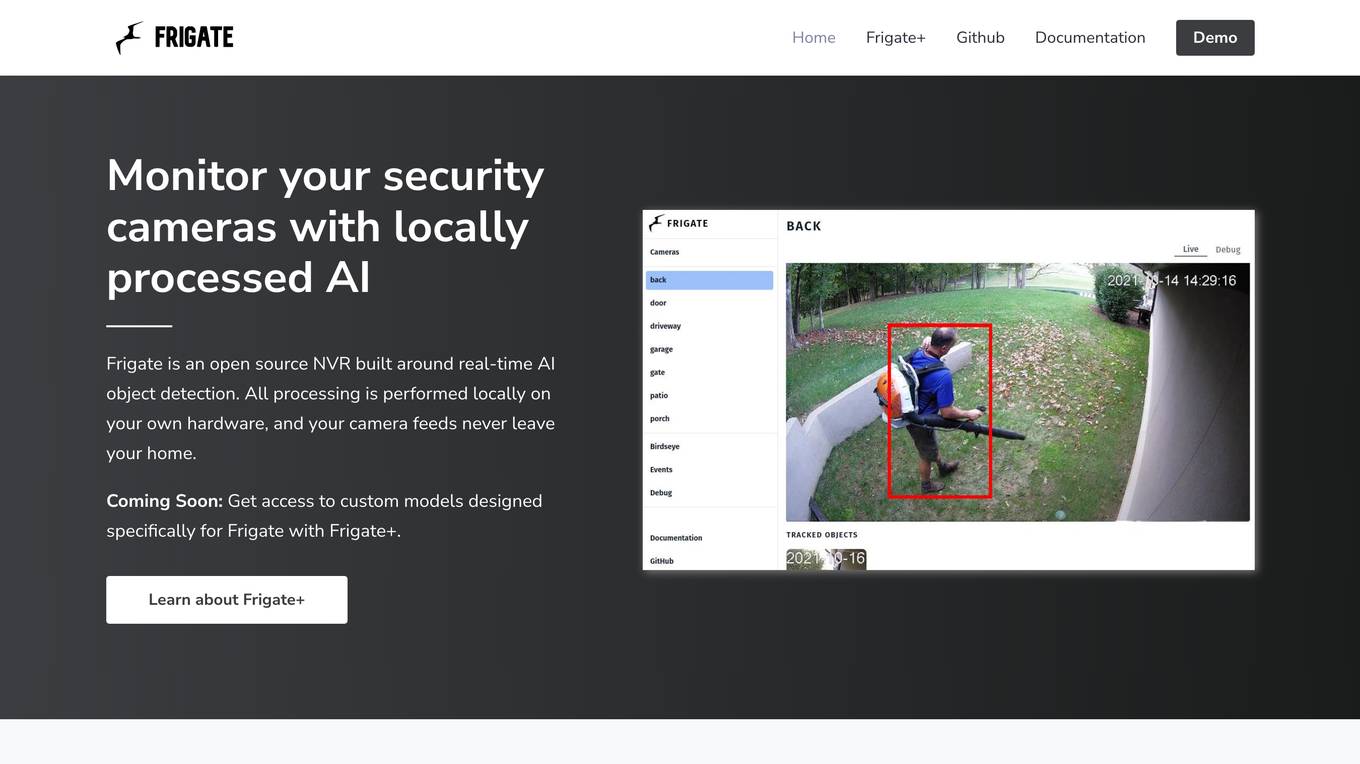
Frigate
Frigate is an open source NVR application that focuses on locally processed AI object detection for security camera monitoring. It offers custom models with Frigate+ to enhance detection accuracy. The application is designed for privacy-focused home automation enthusiasts, aiming to reduce false positives and provide real-time object tracking without sending camera feeds to the cloud. Frigate integrates with Home Assistant and other automation platforms for seamless control and automation of security systems.

Blackshark.ai
Blackshark.ai is an AI-based platform that generates real-time accurate semantic photorealistic 3D digital twin of the entire planet. The platform extracts insights about the planet's infrastructure from satellite and aerial imagery via machine learning at a global scale. It enriches missing attributes using AI to provide a photorealistic, geo-typical, or asset-specific digital twin. The results can be used for visualization, simulation, mapping, mixed reality environments, and other enterprise solutions. The platform offers end-to-end geospatial solutions, including globe data input sources, no-code data labeling, geointelligence at scale, 3D semantic map, and synthetic environments.
BlazeGard
BlazeGard is an AI-powered fire safety application that utilizes cutting-edge object detection technology to analyze video feeds in real-time, identifying potential fire hazards and smoke before flames erupt. It offers comprehensive protection for homes, businesses, and industrial facilities, going beyond traditional smoke detectors. BlazeGard provides early detection, real-time alerts, and peace of mind through its proactive approach to fire safety.
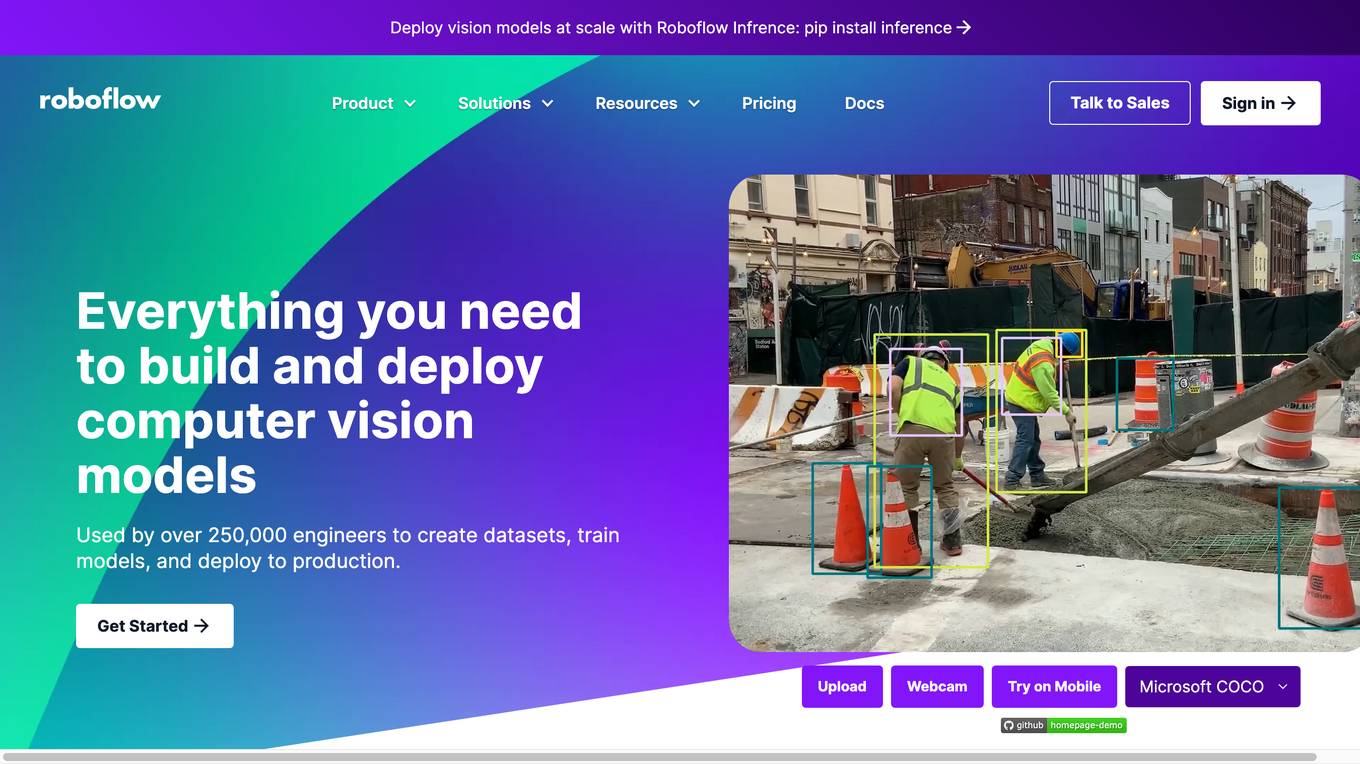
Roboflow
Roboflow is a platform that provides tools for building and deploying computer vision models. It offers a range of features, including data annotation, model training, and deployment. Roboflow is used by over 250,000 engineers to create datasets, train models, and deploy to production.
Landing AI
Landing AI is a computer vision platform and AI software company that provides a cloud-based platform for building and deploying computer vision applications. The platform includes a library of pre-trained models, a set of tools for data labeling and model training, and a deployment service that allows users to deploy their models to the cloud or edge devices. Landing AI's platform is used by a variety of industries, including automotive, electronics, food and beverage, medical devices, life sciences, agriculture, manufacturing, infrastructure, and pharma.
OpenCV
OpenCV is the world's largest computer vision library. It's open source, contains over 2500 algorithms and is operated by the non-profit Open Source Vision Foundation.

CVF Open Access
The Computer Vision Foundation (CVF) is a non-profit organization dedicated to advancing the field of computer vision. CVF organizes several conferences and workshops each year, including the International Conference on Computer Vision (ICCV), the Conference on Computer Vision and Pattern Recognition (CVPR), and the Winter Conference on Applications of Computer Vision (WACV). CVF also publishes the International Journal of Computer Vision (IJCV) and the Computer Vision and Image Understanding (CVIU) journal. The CVF Open Access website provides access to the full text of all CVF-sponsored conference papers. These papers are available for free download in PDF format. The CVF Open Access website also includes links to the arXiv versions of the papers, where available.

Viso Suite
Viso Suite is a no-code computer vision platform that enables users to build, deploy, and scale computer vision applications. It provides a comprehensive set of tools for data collection, annotation, model training, application development, and deployment. Viso Suite is trusted by leading Fortune Global companies and has been used to develop a wide range of computer vision applications, including object detection, image classification, facial recognition, and anomaly detection.
Anduril Industries
Anduril Industries is a defense technology company that develops autonomous systems for land, sea, and air. The company's products include the Lattice operating system, which powers a family of autonomous systems that provide integrated, persistent awareness and security. Anduril also develops counter-UAS, counter-intrusion, and maritime counter-intrusion systems. The company's mission is to transform defense capabilities with advanced technology.
Orbbec
Orbbec is a leading provider of 3D vision technology, offering a wide range of 3D cameras and sensors for various applications. With a focus on AI, optics, and advanced algorithms, Orbbec empowers developers and enterprises to create immersive experiences, precise measurements, and advanced visualizations. Their products include stereo vision cameras, ToF cameras, structured light cameras, camera computers, and lidar sensors, catering to industries such as manufacturing, healthcare, robotics, fitness, logistics, and retail.
Datature
Datature is an all-in-one platform for building and deploying computer vision models. It provides tools for data management, annotation, training, and deployment, making it easy to develop and implement computer vision solutions. Datature is used by a variety of industries, including healthcare, retail, manufacturing, and agriculture.

OpenCV.ai
OpenCV.ai is a leading provider of computer vision software and services. The company's team of experts has extensive experience in developing optimized large-scale computer vision solutions. OpenCV.ai's expertise is helping businesses grow in a variety of industries, including medicine, manufacturing, and retail. The company's solutions are used by startups and Fortune 500 companies alike.

AEye
AEye is a leading provider of software-defined lidar solutions for autonomous applications. Our 4Sight Intelligent Sensing Platform provides accurate, reliable, and real-time perception data to enable safer and more efficient navigation. AEye's lidar products are designed to meet the unique requirements of automotive, trucking, and smart infrastructure applications.
OpenCV
OpenCV is a library of programming functions mainly aimed at real-time computer vision. Originally developed by Intel, it was later supported by Willow Garage and is now maintained by Itseez. OpenCV is cross-platform and free for use under the open-source BSD license.
NVIDIA
NVIDIA is a world leader in artificial intelligence computing. The company's products and services are used by businesses and governments around the world to develop and deploy AI applications. NVIDIA's AI platform includes hardware, software, and tools that make it easy to build and train AI models. The company also offers a range of cloud-based AI services that make it easy to deploy and manage AI applications. NVIDIA's AI platform is used in a wide variety of industries, including healthcare, manufacturing, retail, and transportation. The company's AI technology is helping to improve the efficiency and accuracy of a wide range of tasks, from medical diagnosis to product design.

TensorFlow
TensorFlow is an end-to-end platform for machine learning. It provides a wide range of tools and resources to help developers build, train, and deploy ML models. TensorFlow is used by researchers and developers all over the world to solve real-world problems in a variety of domains, including computer vision, natural language processing, and robotics.
Grok-1.5 Vision
Grok-1.5 Vision (Grok-1.5V) is a groundbreaking multimodal AI model developed by Elon Musk's research lab, x.AI. This advanced model has the potential to revolutionize the field of artificial intelligence and shape the future of various industries. Grok-1.5V combines the capabilities of computer vision, natural language processing, and other AI techniques to provide a comprehensive understanding of the world around us. With its ability to analyze and interpret visual data, Grok-1.5V can assist in tasks such as object recognition, image classification, and scene understanding. Additionally, its natural language processing capabilities enable it to comprehend and generate human language, making it a powerful tool for communication and information retrieval. Grok-1.5V's multimodal nature sets it apart from traditional AI models, allowing it to handle complex tasks that require a combination of visual and linguistic understanding. This makes it a valuable asset for applications in fields such as healthcare, manufacturing, and customer service.
fast.ai
fast.ai is a non-profit organization that provides free online courses and resources on deep learning and artificial intelligence. The organization was founded in 2016 by Jeremy Howard and Rachel Thomas, and has since grown to a community of over 100,000 learners from all over the world. fast.ai's mission is to make deep learning accessible to everyone, regardless of their background or experience. The organization's courses are taught by leading experts in the field, and are designed to be practical and hands-on. fast.ai also offers a variety of resources to help learners get started with deep learning, including a forum, a wiki, and a blog.
Amazon Science
Amazon Science is a research and development organization within Amazon that focuses on developing new technologies and products in the fields of artificial intelligence, machine learning, and computer science. The organization is home to a team of world-renowned scientists and engineers who are working on a wide range of projects, including developing new algorithms for machine learning, building new computer vision systems, and creating new natural language processing tools. Amazon Science is also responsible for developing new products and services that use these technologies, such as the Amazon Echo and the Amazon Fire TV.
5 - Open Source Tools
Awesome-Segment-Anything
The Segment Anything Model (SAM) is a powerful tool that allows users to segment any object in an image with just a few clicks. This makes it a great tool for a variety of tasks, such as object detection, tracking, and editing. SAM is also very easy to use, making it a great option for both beginners and experienced users.
albumentations
Albumentations is a Python library for image augmentation. Image augmentation is used in deep learning and computer vision tasks to increase the quality of trained models. The purpose of image augmentation is to create new training samples from the existing data.

clarifai-python
The Clarifai Python SDK offers a comprehensive set of tools to integrate Clarifai's AI platform to leverage computer vision capabilities like classification , detection ,segementation and natural language capabilities like classification , summarisation , generation , Q&A ,etc into your applications. With just a few lines of code, you can leverage cutting-edge artificial intelligence to unlock valuable insights from visual and textual content.

ailia-models
The collection of pre-trained, state-of-the-art AI models. ailia SDK is a self-contained, cross-platform, high-speed inference SDK for AI. The ailia SDK provides a consistent C++ API across Windows, Mac, Linux, iOS, Android, Jetson, and Raspberry Pi platforms. It also supports Unity (C#), Python, Rust, Flutter(Dart) and JNI for efficient AI implementation. The ailia SDK makes extensive use of the GPU through Vulkan and Metal to enable accelerated computing. # Supported models 323 models as of April 8th, 2024

edenai-apis
Eden AI aims to simplify the use and deployment of AI technologies by providing a unique API that connects to all the best AI engines. With the rise of **AI as a Service** , a lot of companies provide off-the-shelf trained models that you can access directly through an API. These companies are either the tech giants (Google, Microsoft , Amazon) or other smaller, more specialized companies, and there are hundreds of them. Some of the most known are : DeepL (translation), OpenAI (text and image analysis), AssemblyAI (speech analysis). There are **hundreds of companies** doing that. We're regrouping the best ones **in one place** !
20 - OpenAI Gpts
Object Detection Mate
An Object Detection chatbot assistant offering educational materials, code examples, and multilingual support.

Pixie: Computer Vision Engineer
Expert in computer vision, deep learning, ready to assist you with 3d and geometric computer vision. https://github.com/kornia/pixie
Deep Learning Master
Guiding you through the depths of deep learning with accuracy and respect.
Interactive Spring API Creator
Pass in the attributes of Pojo entity class objects, generate corresponding addition, deletion, modification, and pagination query functions, including generating database connection configuration files yaml and database script files, as well as XML dynamic SQL concatenation statements.

Sherlock Holmes AI: Echoes of Baker Street
AI detective in a Victorian London metaverse, guiding through AI-generated mysteries.
Whodunit guessing game
Who let the dogs out? Who stole your favorite toy? Who moved my cheese? Let’s find out!
Everyday Object Storyteller
I craft stories from the perspective of objects, from mundane to horror.
16-bit Multiview
Multiple perspective 16-bit sprite/pixel art objects/characters. Just name an object. A great starting point for 2d game assets.
3D Illustrations Creator by Mojju
Experience bespoke 3D illustration creation with 3D Illustrations Creator by Mojju. Specializing in modern, minimalistic 3D designs with a playful touch, it transforms your ideas into visually appealing single-object illustrations.

Stardust meaning?
What is Stardust lyrics meaning? Stardust singer:Jill Cunniff,album:,album_time:. Click The LINK For More ↓↓↓
