
albumentations
Fast image augmentation library and an easy-to-use wrapper around other libraries. Documentation: https://albumentations.ai/docs/ Paper about the library: https://www.mdpi.com/2078-2489/11/2/125
Stars: 13557
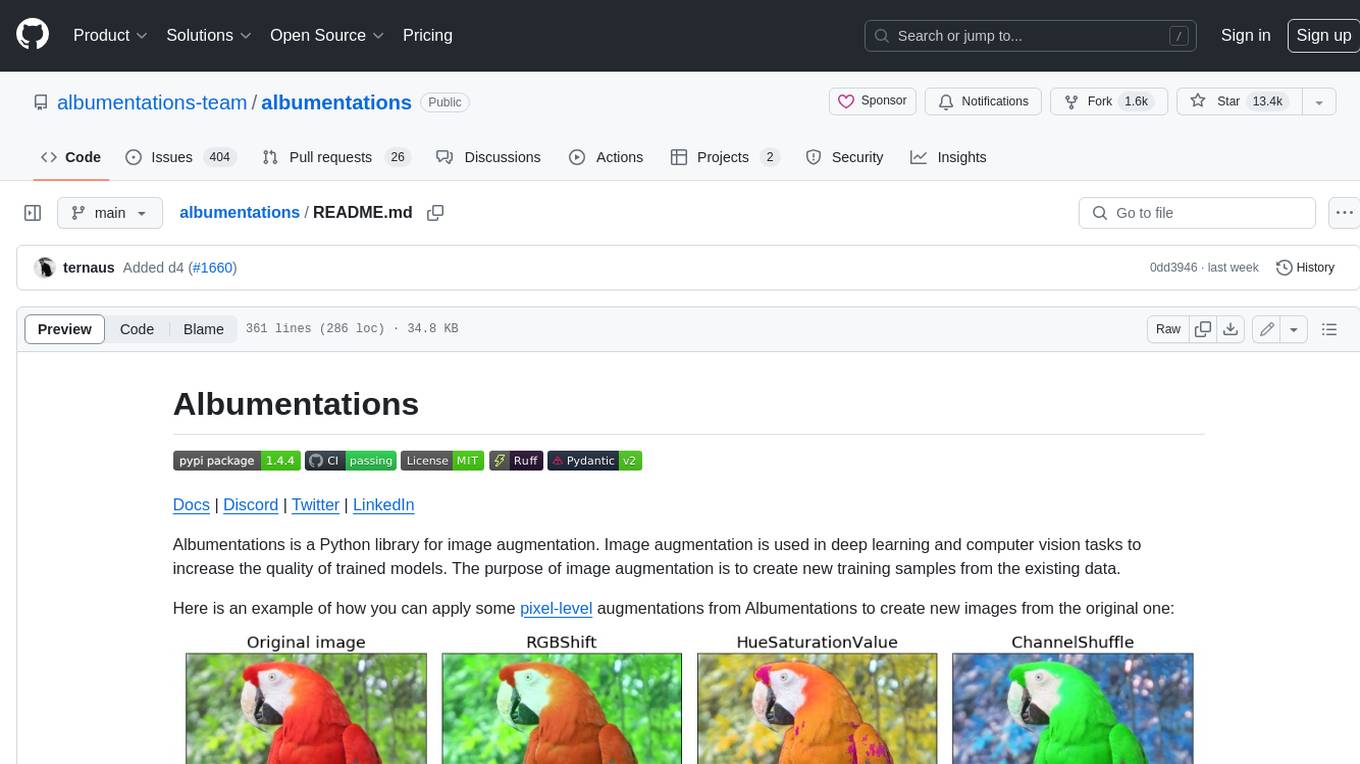
Albumentations is a Python library for image augmentation. Image augmentation is used in deep learning and computer vision tasks to increase the quality of trained models. The purpose of image augmentation is to create new training samples from the existing data.
README:
![]()


Docs | Discord | Twitter | LinkedIn
Albumentations is a Python library for image augmentation. Image augmentation is used in deep learning and computer vision tasks to increase the quality of trained models. The purpose of image augmentation is to create new training samples from the existing data.
Here is an example of how you can apply some pixel-level augmentations from Albumentations to create new images from the original one:

- Albumentations supports all common computer vision tasks such as classification, semantic segmentation, instance segmentation, object detection, and pose estimation.
- The library provides a simple unified API to work with all data types: images (RBG-images, grayscale images, multispectral images), segmentation masks, bounding boxes, and keypoints.
- The library contains more than 70 different augmentations to generate new training samples from the existing data.
- Albumentations is fast. We benchmark each new release to ensure that augmentations provide maximum speed.
- It works with popular deep learning frameworks such as PyTorch and TensorFlow. By the way, Albumentations is a part of the PyTorch ecosystem.
- Written by experts. The authors have experience both working on production computer vision systems and participating in competitive machine learning. Many core team members are Kaggle Masters and Grandmasters.
- The library is widely used in industry, deep learning research, machine learning competitions, and open source projects.

- Albumentations
Vladimir I. Iglovikov | Kaggle Grandmaster
Mikhail Druzhinin | Kaggle Expert
Alexander Buslaev — Computer Vision Engineer at Mapbox | Kaggle Master
Evegene Khvedchenya — Computer Vision Research Engineer at Piñata Farms | Kaggle Grandmaster
Albumentations requires Python 3.8 or higher. To install the latest version from PyPI:
pip install -U albumentationsOther installation options are described in the documentation.
The full documentation is available at https://albumentations.ai/docs/.
import albumentations as A
import cv2
# Declare an augmentation pipeline
transform = A.Compose([
A.RandomCrop(width=256, height=256),
A.HorizontalFlip(p=0.5),
A.RandomBrightnessContrast(p=0.2),
])
# Read an image with OpenCV and convert it to the RGB colorspace
image = cv2.imread("image.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Augment an image
transformed = transform(image=image)
transformed_image = transformed["image"]Please start with the introduction articles about why image augmentation is important and how it helps to build better models.
If you want to use Albumentations for a specific task such as classification, segmentation, or object detection, refer to the set of articles that has an in-depth description of this task. We also have a list of examples on applying Albumentations for different use cases.
We have examples of using Albumentations along with PyTorch and TensorFlow.
Check the online demo of the library. With it, you can apply augmentations to different images and see the result. Also, we have a list of all available augmentations and their targets.














- A list of papers that cite Albumentations.
- A list of teams that were using Albumentations and took high places in machine learning competitions.
- Open source projects that use Albumentations.
Pixel-level transforms will change just an input image and will leave any additional targets such as masks, bounding boxes, and keypoints unchanged. The list of pixel-level transforms:
- AdvancedBlur
- Blur
- CLAHE
- ChannelDropout
- ChannelShuffle
- ChromaticAberration
- ColorJitter
- Defocus
- Downscale
- Emboss
- Equalize
- FDA
- FancyPCA
- FromFloat
- GaussNoise
- GaussianBlur
- GlassBlur
- HistogramMatching
- HueSaturationValue
- ISONoise
- ImageCompression
- InvertImg
- MedianBlur
- MotionBlur
- MultiplicativeNoise
- Normalize
- PixelDistributionAdaptation
- Posterize
- RGBShift
- RandomBrightnessContrast
- RandomFog
- RandomGamma
- RandomGravel
- RandomRain
- RandomShadow
- RandomSnow
- RandomSunFlare
- RandomToneCurve
- RingingOvershoot
- Sharpen
- Solarize
- Spatter
- Superpixels
- TemplateTransform
- ToFloat
- ToGray
- ToRGB
- ToSepia
- UnsharpMask
- ZoomBlur
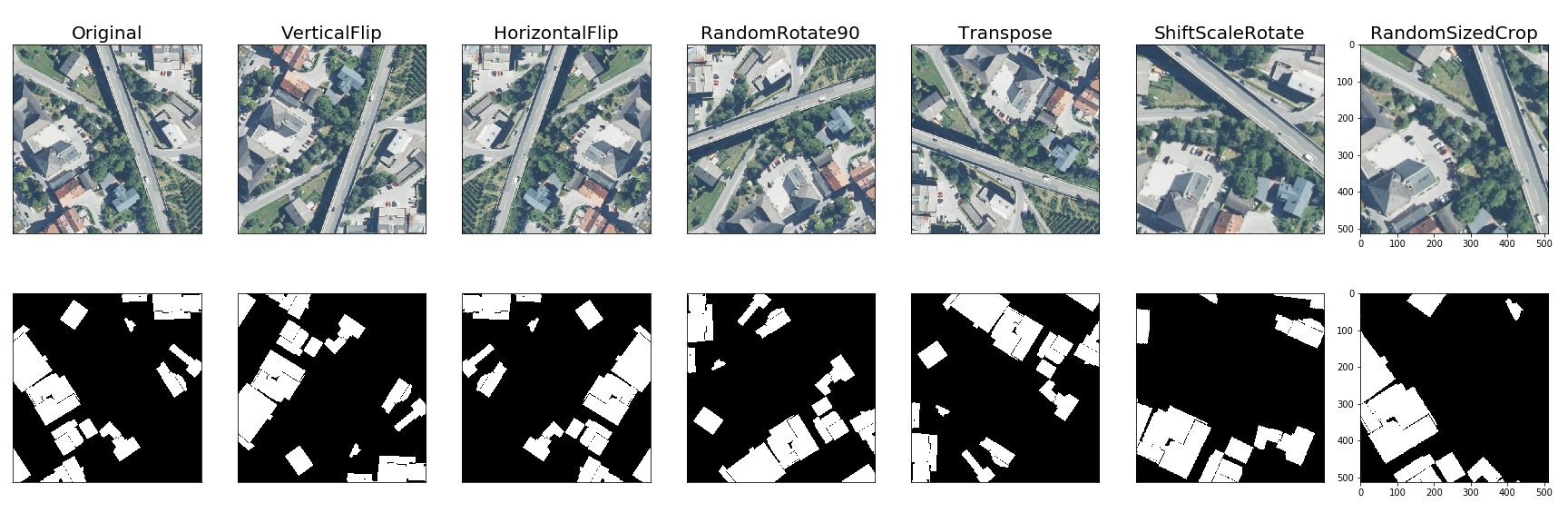
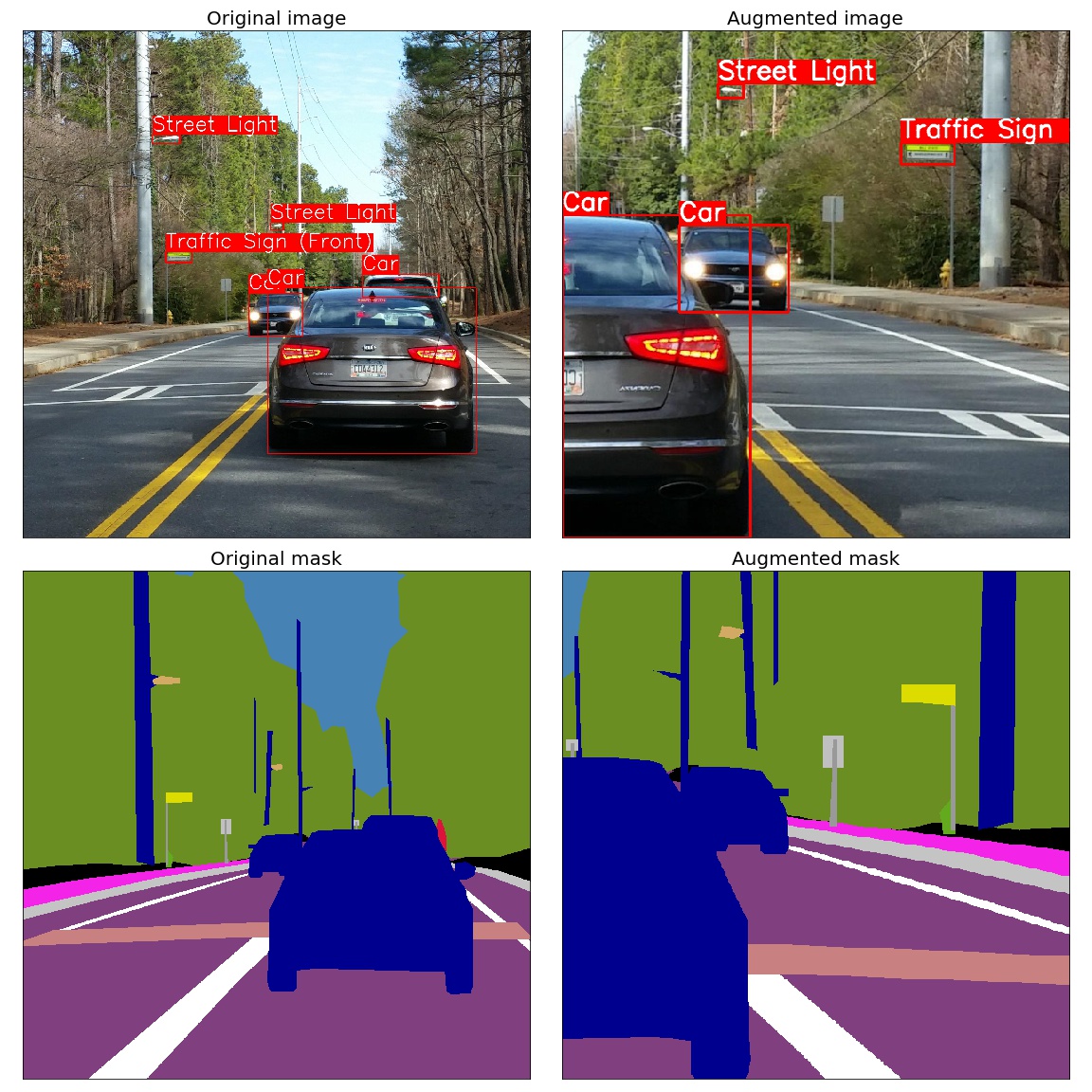
Spatial-level transforms will simultaneously change both an input image as well as additional targets such as masks, bounding boxes, and keypoints. The following table shows which additional targets are supported by each transform.
| Transform | Image | Mask | BBoxes | Keypoints |
|---|---|---|---|---|
| Affine | ✓ | ✓ | ✓ | ✓ |
| BBoxSafeRandomCrop | ✓ | ✓ | ✓ | |
| CenterCrop | ✓ | ✓ | ✓ | ✓ |
| CoarseDropout | ✓ | ✓ | ✓ | |
| Crop | ✓ | ✓ | ✓ | ✓ |
| CropAndPad | ✓ | ✓ | ✓ | ✓ |
| CropNonEmptyMaskIfExists | ✓ | ✓ | ✓ | ✓ |
| D4 | ✓ | ✓ | ✓ | ✓ |
| ElasticTransform | ✓ | ✓ | ✓ | |
| Flip | ✓ | ✓ | ✓ | ✓ |
| GridDistortion | ✓ | ✓ | ✓ | |
| GridDropout | ✓ | ✓ | ||
| HorizontalFlip | ✓ | ✓ | ✓ | ✓ |
| Lambda | ✓ | ✓ | ✓ | ✓ |
| LongestMaxSize | ✓ | ✓ | ✓ | ✓ |
| MaskDropout | ✓ | ✓ | ||
| Morphological | ✓ | ✓ | ||
| NoOp | ✓ | ✓ | ✓ | ✓ |
| OpticalDistortion | ✓ | ✓ | ✓ | |
| PadIfNeeded | ✓ | ✓ | ✓ | ✓ |
| Perspective | ✓ | ✓ | ✓ | ✓ |
| PiecewiseAffine | ✓ | ✓ | ✓ | ✓ |
| PixelDropout | ✓ | ✓ | ||
| RandomCrop | ✓ | ✓ | ✓ | ✓ |
| RandomCropFromBorders | ✓ | ✓ | ✓ | ✓ |
| RandomGridShuffle | ✓ | ✓ | ✓ | |
| RandomResizedCrop | ✓ | ✓ | ✓ | ✓ |
| RandomRotate90 | ✓ | ✓ | ✓ | ✓ |
| RandomScale | ✓ | ✓ | ✓ | ✓ |
| RandomSizedBBoxSafeCrop | ✓ | ✓ | ✓ | |
| RandomSizedCrop | ✓ | ✓ | ✓ | ✓ |
| Resize | ✓ | ✓ | ✓ | ✓ |
| Rotate | ✓ | ✓ | ✓ | ✓ |
| SafeRotate | ✓ | ✓ | ✓ | ✓ |
| ShiftScaleRotate | ✓ | ✓ | ✓ | ✓ |
| SmallestMaxSize | ✓ | ✓ | ✓ | ✓ |
| Transpose | ✓ | ✓ | ✓ | ✓ |
| VerticalFlip | ✓ | ✓ | ✓ | ✓ |
| XYMasking | ✓ | ✓ | ✓ |
Transforms that mix several images into one
| Transform | Image | Mask | BBoxes | Keypoints | Global Label |
|---|---|---|---|---|---|
| MixUp | ✓ | ✓ | ✓ |


To run the benchmark yourself, follow the instructions in benchmark/README.md
Results for running the benchmark on the first 2000 images from the ImageNet validation set using an AMD Ryzen Threadripper 3970X CPU. The table shows how many images per second can be processed on a single core; higher is better.
| Library | Version |
|---|---|
| Python | 3.10.13 (main, Sep 11 2023, 13:44:35) [GCC 11.2.0] |
| albumentations | 1.4.1 |
| imgaug | 0.4.0 |
| torchvision | 0.17.1+rocm5.7 |
| numpy | 1.26.4 |
| opencv-python-headless | 4.9.0.80 |
| scikit-image | 0.22.0 |
| scipy | 1.12.0 |
| pillow | 10.2.0 |
| kornia | 0.7.2 |
| augly | 1.0.0 |
| albumentations 1.4.0 |
torchvision 0.17.1+rocm5.7 |
kornia 0.7.2 |
augly 1.0.0 |
imgaug 0.4.0 |
|
|---|---|---|---|---|---|
| HorizontalFlip | 9843 ± 2135 | 2436 ± 29 | 1014 ± 3 | 3663 ± 18 | 4884 ± 51 |
| VerticalFlip | 9898 ± 18 | 2570 ± 37 | 1024 ± 4 | 5325 ± 13 | 8683 ± 5 |
| Rotate | 610 ± 4 | 153 ± 2 | 204 ± 1 | 626 ± 3 | 499 ± 5 |
| Affine | 1705 ± 67 | 159 ± 1 | 200 ± 1 | - | 663 ± 24 |
| Equalize | 1061 ± 14 | 337 ± 1 | 77 ± 1 | - | 845 ± 33 |
| RandomCrop64 | 203197 ± 2105 | 15931 ± 27 | 837 ± 2 | 21858 ± 362 | 5681 ± 96 |
| RandomResizedCrop | 2998 ± 30 | 1160 ± 4 | 190 ± 1 | - | - |
| ShiftRGB | 1400 ± 3 | - | 435 ± 1 | - | 1528 ± 6 |
| Resize | 2581 ± 3 | 1239 ± 1 | 197 ± 1 | 431 ± 1 | 1728 ± 1 |
| RandomGamma | 4556 ± 3 | 230 ± 1 | 205 ± 1 | - | 2282 ± 110 |
| Grayscale | 7234 ± 4 | 1539 ± 7 | 444 ± 3 | 2606 ± 2 | 918 ± 42 |
| ColorJitter | 452 ± 43 | 51 ± 1 | 50 ± 1 | 221 ± 1 | - |
| RandomPerspective | 465 ± 1 | 121 ± 1 | 115 ± 1 | - | 433 ± 16 |
| GaussianBlur | 2315 ± 9 | 106 ± 2 | 72 ± 1 | 161 ± 1 | 1213 ± 3 |
| MedianBlur | 3711 ± 2 | - | 2 ± 1 | - | 566 ± 3 |
| MotionBlur | 2763 ± 25 | - | 101 ± 4 | - | 508 ± 2 |
| Posterize | 4238 ± 51 | 2581 ± 20 | 284 ± 4 | - | 1893 ± 9 |
| JpegCompression | 208 ± 1 | - | - | 692 ± 4 | 435 ± 1 |
| GaussianNoise | 64 ± 9 | - | - | 67 ± 1 | 212 ± 16 |
| Elastic | 129 ± 1 | 3 ± 1 | 1 ± 1 | - | 128 ± 1 |
To create a pull request to the repository, follow the documentation at CONTRIBUTING.md
In some systems, in the multiple GPU regime, PyTorch may deadlock the DataLoader if OpenCV was compiled with OpenCL optimizations. Adding the following two lines before the library import may help. For more details https://github.com/pytorch/pytorch/issues/1355
cv2.setNumThreads(0)
cv2.ocl.setUseOpenCL(False)If you find this library useful for your research, please consider citing Albumentations: Fast and Flexible Image Augmentations:
@Article{info11020125,
AUTHOR = {Buslaev, Alexander and Iglovikov, Vladimir I. and Khvedchenya, Eugene and Parinov, Alex and Druzhinin, Mikhail and Kalinin, Alexandr A.},
TITLE = {Albumentations: Fast and Flexible Image Augmentations},
JOURNAL = {Information},
VOLUME = {11},
YEAR = {2020},
NUMBER = {2},
ARTICLE-NUMBER = {125},
URL = {https://www.mdpi.com/2078-2489/11/2/125},
ISSN = {2078-2489},
DOI = {10.3390/info11020125}
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for albumentations
Similar Open Source Tools
albumentations
Albumentations is a Python library for image augmentation. Image augmentation is used in deep learning and computer vision tasks to increase the quality of trained models. The purpose of image augmentation is to create new training samples from the existing data.

DataFlow
DataFlow is a data preparation and training system designed to parse, generate, process, and evaluate high-quality data from noisy sources, improving the performance of large language models in specific domains. It constructs diverse operators and pipelines, validated to enhance domain-oriented LLM's performance in fields like healthcare, finance, and law. DataFlow also features an intelligent DataFlow-agent capable of dynamically assembling new pipelines by recombining existing operators on demand.

MOSS-TTS
MOSS-TTS Family is an open-source speech and sound generation model family designed for high-fidelity, high-expressiveness, and complex real-world scenarios. It includes five production-ready models: MOSS-TTS, MOSS-TTSD, MOSS-VoiceGenerator, MOSS-TTS-Realtime, and MOSS-SoundEffect, each serving specific purposes in speech generation, dialogue, voice design, real-time interactions, and sound effect generation. The models offer features like long-speech generation, fine-grained control over phonemes and duration, multilingual synthesis, voice cloning, and real-time voice agents.
gpupixel
GPUPixel is a real-time, high-performance image and video filter library written in C++11 and based on OpenGL/ES. It incorporates a built-in beauty face filter that achieves commercial-grade beauty effects. The library is extremely easy to compile and integrate with a small size, supporting platforms including iOS, Android, Mac, Windows, and Linux. GPUPixel provides various filters like skin smoothing, whitening, face slimming, big eyes, lipstick, and blush. It supports input formats like YUV420P, RGBA, JPEG, PNG, and output formats like RGBA and YUV420P. The library's performance on devices like iPhone and Android is optimized, with low CPU usage and fast processing times. GPUPixel's lib size is compact, making it suitable for mobile and desktop applications.

EVE
EVE is an official PyTorch implementation of Unveiling Encoder-Free Vision-Language Models. The project aims to explore the removal of vision encoders from Vision-Language Models (VLMs) and transfer LLMs to encoder-free VLMs efficiently. It also focuses on bridging the performance gap between encoder-free and encoder-based VLMs. EVE offers a superior capability with arbitrary image aspect ratio, data efficiency by utilizing publicly available data for pre-training, and training efficiency with a transparent and practical strategy for developing a pure decoder-only architecture across modalities.

oumi
Oumi is an open-source platform for building state-of-the-art foundation models, offering tools for data preparation, training, evaluation, and deployment. It supports training and fine-tuning models with various parameters, working with text and multimodal models, synthesizing and curating training data, deploying models efficiently, evaluating models comprehensively, and running on different platforms. Oumi provides a consistent API, reliability, and flexibility for research purposes.
FaceAISDK_Android
FaceAI SDK is an on-device offline face detection, recognition, liveness detection, anti-spoofing, and 1:N/M:N face search SDK. It enables quick integration to achieve on-device face recognition, face search, and other functions. The SDK performs all functions offline on the device without the need for internet connection, ensuring privacy and security. It supports various actions for liveness detection, custom camera management, and clear imaging even in challenging lighting conditions.
microgpt-c
MicroGPT-C is a project that focuses on tiny specialist models working together to outperform monoliths on specific tasks. It is a C port of a Python GPT model, rewritten in pure C99 with zero dependencies. The project explores the concept of coordinated intelligence through 'organelles' that differentiate based on training data, resulting in improved performance across logic games and real-world data experiments.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

langfuse
Langfuse is a powerful tool that helps you develop, monitor, and test your LLM applications. With Langfuse, you can: * **Develop:** Instrument your app and start ingesting traces to Langfuse, inspect and debug complex logs, and manage, version, and deploy prompts from within Langfuse. * **Monitor:** Track metrics (cost, latency, quality) and gain insights from dashboards & data exports, collect and calculate scores for your LLM completions, run model-based evaluations, collect user feedback, and manually score observations in Langfuse. * **Test:** Track and test app behaviour before deploying a new version, test expected in and output pairs and benchmark performance before deploying, and track versions and releases in your application. Langfuse is easy to get started with and offers a generous free tier. You can sign up for Langfuse Cloud or deploy Langfuse locally or on your own infrastructure. Langfuse also offers a variety of integrations to make it easy to connect to your LLM applications.
pdf_oxide
PDF Oxide is a fast PDF library for Python and Rust that offers text extraction, image extraction, and markdown conversion. It is built on a Rust core, providing high performance with a mean processing time of 0.8ms per document. The library is 5 times faster than PyMuPDF and 15 times faster than pypdf, with a 100% pass rate on 3,830 real-world PDFs. It supports text extraction, image extraction, PDF creation, and editing, and offers a dual-language API with Python bindings. PDF Oxide is licensed under MIT and Apache-2.0, allowing free usage in both commercial and open-source projects.

InternVL
InternVL scales up the ViT to _**6B parameters**_ and aligns it with LLM. It is a vision-language foundation model that can perform various tasks, including: **Visual Perception** - Linear-Probe Image Classification - Semantic Segmentation - Zero-Shot Image Classification - Multilingual Zero-Shot Image Classification - Zero-Shot Video Classification **Cross-Modal Retrieval** - English Zero-Shot Image-Text Retrieval - Chinese Zero-Shot Image-Text Retrieval - Multilingual Zero-Shot Image-Text Retrieval on XTD **Multimodal Dialogue** - Zero-Shot Image Captioning - Multimodal Benchmarks with Frozen LLM - Multimodal Benchmarks with Trainable LLM - Tiny LVLM InternVL has been shown to achieve state-of-the-art results on a variety of benchmarks. For example, on the MMMU image classification benchmark, InternVL achieves a top-1 accuracy of 51.6%, which is higher than GPT-4V and Gemini Pro. On the DocVQA question answering benchmark, InternVL achieves a score of 82.2%, which is also higher than GPT-4V and Gemini Pro. InternVL is open-sourced and available on Hugging Face. It can be used for a variety of applications, including image classification, object detection, semantic segmentation, image captioning, and question answering.
Botright
Botright is a tool designed for browser automation that focuses on stealth and captcha solving. It uses a real Chromium-based browser for enhanced stealth and offers features like browser fingerprinting and AI-powered captcha solving. The tool is suitable for developers looking to automate browser tasks while maintaining anonymity and bypassing captchas. Botright is available in async mode and can be easily integrated with existing Playwright code. It provides solutions for various captchas such as hCaptcha, reCaptcha, and GeeTest, with high success rates. Additionally, Botright offers browser stealth techniques and supports different browser functionalities for seamless automation.
runanywhere-sdks
RunAnywhere is an on-device AI tool for mobile apps that allows users to run LLMs, speech-to-text, text-to-speech, and voice assistant features locally, ensuring privacy, offline functionality, and fast performance. The tool provides a range of AI capabilities without relying on cloud services, reducing latency and ensuring that no data leaves the device. RunAnywhere offers SDKs for Swift (iOS/macOS), Kotlin (Android), React Native, and Flutter, making it easy for developers to integrate AI features into their mobile applications. The tool supports various models for LLM, speech-to-text, and text-to-speech, with detailed documentation and installation instructions available for each platform.

unstract
Unstract is a no-code platform that enables users to launch APIs and ETL pipelines to structure unstructured documents. With Unstract, users can go beyond co-pilots by enabling machine-to-machine automation. Unstract's Prompt Studio provides a simple, no-code approach to creating prompts for LLMs, vector databases, embedding models, and text extractors. Users can then configure Prompt Studio projects as API deployments or ETL pipelines to automate critical business processes that involve complex documents. Unstract supports a wide range of LLM providers, vector databases, embeddings, text extractors, ETL sources, and ETL destinations, providing users with the flexibility to choose the best tools for their needs.
For similar tasks
albumentations
Albumentations is a Python library for image augmentation. Image augmentation is used in deep learning and computer vision tasks to increase the quality of trained models. The purpose of image augmentation is to create new training samples from the existing data.
For similar jobs
albumentations
Albumentations is a Python library for image augmentation. Image augmentation is used in deep learning and computer vision tasks to increase the quality of trained models. The purpose of image augmentation is to create new training samples from the existing data.

clarifai-python
The Clarifai Python SDK offers a comprehensive set of tools to integrate Clarifai's AI platform to leverage computer vision capabilities like classification , detection ,segementation and natural language capabilities like classification , summarisation , generation , Q&A ,etc into your applications. With just a few lines of code, you can leverage cutting-edge artificial intelligence to unlock valuable insights from visual and textual content.

ailia-models
The collection of pre-trained, state-of-the-art AI models. ailia SDK is a self-contained, cross-platform, high-speed inference SDK for AI. The ailia SDK provides a consistent C++ API across Windows, Mac, Linux, iOS, Android, Jetson, and Raspberry Pi platforms. It also supports Unity (C#), Python, Rust, Flutter(Dart) and JNI for efficient AI implementation. The ailia SDK makes extensive use of the GPU through Vulkan and Metal to enable accelerated computing. # Supported models 323 models as of April 8th, 2024

edenai-apis
Eden AI aims to simplify the use and deployment of AI technologies by providing a unique API that connects to all the best AI engines. With the rise of **AI as a Service** , a lot of companies provide off-the-shelf trained models that you can access directly through an API. These companies are either the tech giants (Google, Microsoft , Amazon) or other smaller, more specialized companies, and there are hundreds of them. Some of the most known are : DeepL (translation), OpenAI (text and image analysis), AssemblyAI (speech analysis). There are **hundreds of companies** doing that. We're regrouping the best ones **in one place** !
Awesome-Segment-Anything
The Segment Anything Model (SAM) is a powerful tool that allows users to segment any object in an image with just a few clicks. This makes it a great tool for a variety of tasks, such as object detection, tracking, and editing. SAM is also very easy to use, making it a great option for both beginners and experienced users.