
SpinQuant
Code repo for the paper "SpinQuant LLM quantization with learned rotations"
Stars: 76
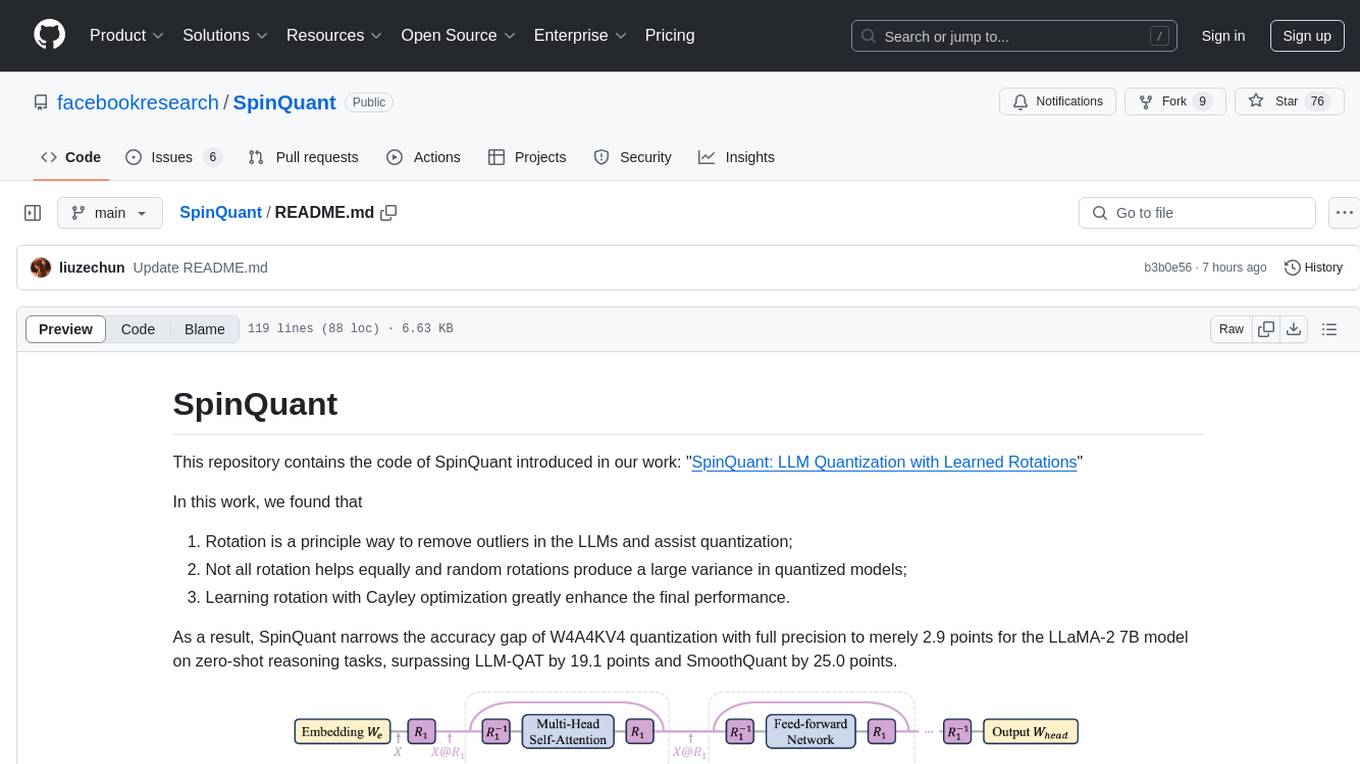
SpinQuant is a tool designed for LLM quantization with learned rotations. It focuses on optimizing rotation matrices to enhance the performance of quantized models, narrowing the accuracy gap to full precision models. The tool implements rotation optimization and PTQ evaluation with optimized rotation, providing arguments for model name, batch sizes, quantization bits, and rotation options. SpinQuant is based on the findings that rotation helps in removing outliers and improving quantization, with specific enhancements achieved through learning rotation with Cayley optimization.
README:
This repository contains the code of SpinQuant introduced in our work: "SpinQuant: LLM Quantization with Learned Rotations"
In this work, we found that
- Rotation is a principle way to remove outliers in the LLMs and assist quantization;
- Not all rotation helps equally and random rotations produce a large variance in quantized models;
- Learning rotation with Cayley optimization greatly enhance the final performance.
As a result, SpinQuant narrows the accuracy gap of W4A4KV4 quantization with full precision to merely 2.9 points for the LLaMA-2 7B model on zero-shot reasoning tasks, surpassing LLM-QAT by 19.1 points and SmoothQuant by 25.0 points.

If you find our code useful for your research, please consider citing:
@article{liu2024spinquant,
title={SpinQuant--LLM quantization with learned rotations},
author={Liu, Zechun and Zhao, Changsheng and Fedorov, Igor and Soran, Bilge and Choudhary, Dhruv and Krishnamoorthi, Raghuraman and Chandra, Vikas and Tian, Yuandong and Blankevoort, Tijmen},
journal={arXiv preprint arXiv:2405.16406},
year={2024}
}
- python 3.9, pytorch >= 2.0
- pip install -r requirement.txt
- git clone https://github.com/Dao-AILab/fast-hadamard-transform.git
cd fast-hadamard-transform
pip install .
Step 1: Optimize Rotation Matrix
- For LLaMA-2 7B/13B and LLaMA-3 8B models:
bash10_optimize_rotation.sh $model_name $w_bit $a_bit $kv_bit
e.g.,bash 10_optimize_rotation.sh meta-llama/Llama-2-7b 4 4 4for 4-bit weight 4-bit activation and 4-bit kv-cache on Llama-2-7b model. - For LLaMA-2 70B and LLaMA-3 70B models:
bash11_optimize_rotation_fsdp.sh $model_name $w_bit $a_bit $kv_bit
e.g.,bash 11_optimize_rotation_fsdp.sh meta-llama/Llama-2-70b 4 4 4for 4-bit weight 4-bit activation and 4-bit kv-cache on Llama-2-70b model.
Step 2: Run PTQ evaluation with optimized rotation
- bash
2_eval_ptq.sh $model_name $w_bit $a_bit $kv_bit
Others
- If using GPTQ quantization method in Step 2 for quantizing both weight and activations, we optimize the rotation matrices with respect to a network where only activations are quantized.
e.g.bash 10_optimize_rotation.sh meta-llama/Llama-2-7b 16 4 4followed bybash 2_eval_ptq.sh meta-llama/Llama-2-7b 4 4 4with the--optimized_rotation_pathpointing to the rotation optimized for W16A4KV4.
-
--input_model: The model name (or path to the weights) -
--output_rotation_path: The local path we want to store the oprimized rotation matrix -
--per_device_train_batch_size: The batch size for rotation optimization -
--per_device_eval_batch_size: The batch size for PPL evaluation -
--a_bits: The number of bits for activation quantization -
--w_bits: The number of bits for weight quantization -
--v_bits: The number of bits for value quantization -
--k_bits: The number of bits for key quantization -
--w_clip: Whether using the grid search to find best weight clipping range -
--w_rtn: Whether we want to use round-to-nearest quantization. If not having--w_rtn, we are using GPTQ quantization. -
--rotate: Whether we want to rotate the model -
--optimized_rotation_path: The checkpoint path of optimized rotation; Use random rotation if path is not given
| Model | LLaMA-3 8B | LLaMA-3 70B | LLaMA-2 7B | LLaMA-2 13B | LLaMA-2 70B | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Method | Zero-shot | Wiki2 | Zero-shot | Wiki2 | Zero-shot | Wiki2 | Zero-shot | Wiki2 | Zero-shot | Wiki2 |
| FloatingPoint | 69.6 | 6.1 | 74.5 | 2.8 | 66.9 | 5.5 | 68.3 | 5.0 | 72.9 | 3.3 |
| W4A16KV16 | ||||||||||
| RTN | 65.4 | 7.8 | 35.5 | 1e5 | 63.6 | 7.2 | 57.9 | 6.4 | 69.2 | 4.6 |
| SmoothQuant | 61.0 | 10.7 | 66.9 | 12.0 | 59.1 | 7.5 | 63.3 | 6.1 | 70.2 | 4.1 |
| LLM-QAT | 67.7 | 7.1 | -- | -- | 64.9 | 5.9 | -- | -- | -- | -- |
| GPTQ | 66.5 | 7.2 | 35.7 | 1e5 | 64.5 | 11.3 | 64.7 | 5.6 | 71.9 | 3.9 |
| QuaRot | 68.4 | 6.4 | 70.3 | 7.9 | 65.8 | 5.6 | 68.3 | 5.0 | 72.2 | 3.5 |
| SpinQuant | 68.5 | 6.4 | 71.6 | 4.8 | 65.9 | 5.6 | 68.5 | 5.0 | 72.6 | 3.5 |
| W4A4KV16 | ||||||||||
| RTN | 38.5 | 9e2 | 35.6 | 1e5 | 35.6 | 2e3 | 35.3 | 7e3 | 35.1 | 2e5 |
| SmoothQuant | 40.3 | 8e2 | 55.3 | 18.0 | 41.8 | 2e2 | 44.9 | 34.5 | 64.6 | 57.1 |
| LLM-QAT | 44.9 | 42.9 | -- | -- | 47.8 | 12.9 | -- | -- | -- | -- |
| GPTQ | 37.0 | 9e2 | 35.3 | 1e5 | 36.8 | 8e3 | 35.3 | 5e3 | 35.5 | 2e6 |
| QuaRot | 63.8 | 7.9 | 65.4 | 20.4 | 63.5 | 6.1 | 66.7 | 5.4 | 70.4 | 3.9 |
| SpinQuant | 65.8 | 7.1 | 69.5 | 5.5 | 64.1 | 5.9 | 67.2 | 5.2 | 71.0 | 3.8 |
| W4A4KV4 | ||||||||||
| RTN | 38.2 | 1e3 | 35.2 | 1e5 | 37.1 | 2e3 | 35.4 | 7e3 | 35.0 | 2e5 |
| SmoothQuant | 38.7 | 1e3 | 52.4 | 22.1 | 39.0 | 6e2 | 40.5 | 56.6 | 55.9 | 10.5 |
| LLM-QAT | 43.2 | 52.5 | -- | -- | 44.9 | 14.9 | -- | -- | -- | -- |
| GPTQ | 37.1 | 1e3 | 35.1 | 1e5 | 36.8 | 9e3 | 35.2 | 5e3 | 35.6 | 1e6 |
| QuaRot | 63.3 | 8.0 | 65.1 | 20.2 | 62.5 | 6.4 | 66.2 | 5.4 | 70.3 | 3.9 |
| SpinQuant | 65.2 | 7.3 | 69.3 | 5.5 | 64.0 | 5.9 | 66.9 | 5.3 | 71.2 | 3.8 |
You can download the optimized rotation matrices here.
The results reported in the paper is run with the internal LLaMA codebase in Meta. We reproduced our experiments with HuggingFace codebase and released code here, which partially based on HuggingFace transformers, QuaRot, QuIP# and Optimization-on-Stiefel-Manifold-via-Cayley-Transform.
Zechun Liu, Reality Labs, Meta Inc (zechunliu at meta dot com)
Changsheng Zhao, Reality Labs, Meta Inc (cszhao at meta dot com)
MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases [Paper] [Code]
LLM-QAT: Data-Free Quantization Aware Training for Large Language Models [Paper] [Code]
BiT is CC-BY-NC 4.0 licensed as of now.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for SpinQuant
Similar Open Source Tools
SpinQuant
SpinQuant is a tool designed for LLM quantization with learned rotations. It focuses on optimizing rotation matrices to enhance the performance of quantized models, narrowing the accuracy gap to full precision models. The tool implements rotation optimization and PTQ evaluation with optimized rotation, providing arguments for model name, batch sizes, quantization bits, and rotation options. SpinQuant is based on the findings that rotation helps in removing outliers and improving quantization, with specific enhancements achieved through learning rotation with Cayley optimization.

DataFlow
DataFlow is a data preparation and training system designed to parse, generate, process, and evaluate high-quality data from noisy sources, improving the performance of large language models in specific domains. It constructs diverse operators and pipelines, validated to enhance domain-oriented LLM's performance in fields like healthcare, finance, and law. DataFlow also features an intelligent DataFlow-agent capable of dynamically assembling new pipelines by recombining existing operators on demand.

CogVLM2
CogVLM2 is a new generation of open source models that offer significant improvements in benchmarks such as TextVQA and DocVQA. It supports 8K content length, image resolution up to 1344 * 1344, and both Chinese and English languages. The project provides basic calling methods, fine-tuning examples, and OpenAI API format calling examples to help developers quickly get started with the model.

VoiceBench
VoiceBench is a repository containing code and data for benchmarking LLM-Based Voice Assistants. It includes a leaderboard with rankings of various voice assistant models based on different evaluation metrics. The repository provides setup instructions, datasets, evaluation procedures, and a curated list of awesome voice assistants. Users can submit new voice assistant results through the issue tracker for updates on the ranking list.

TRACE
TRACE is a temporal grounding video model that utilizes causal event modeling to capture videos' inherent structure. It presents a task-interleaved video LLM model tailored for sequential encoding/decoding of timestamps, salient scores, and textual captions. The project includes various model checkpoints for different stages and fine-tuning on specific datasets. It provides evaluation codes for different tasks like VTG, MVBench, and VideoMME. The repository also offers annotation files and links to raw videos preparation projects. Users can train the model on different tasks and evaluate the performance based on metrics like CIDER, METEOR, SODA_c, F1, mAP, Hit@1, etc. TRACE has been enhanced with trace-retrieval and trace-uni models, showing improved performance on dense video captioning and general video understanding tasks.

ClawRouter
ClawRouter is a tool designed to route every request to the cheapest model that can handle it, offering a wallet-based system with 30+ models available without the need for API keys. It provides 100% local routing with 14-dimension weighted scoring, zero external calls for routing decisions, and supports various models from providers like OpenAI, Anthropic, Google, DeepSeek, xAI, and Moonshot. Users can pay per request with USDC on Base, benefiting from an open-source, MIT-licensed, fully inspectable routing logic. The tool is optimized for agent swarm and multi-step workflows, offering cost-efficient solutions for parallel web research, multi-agent orchestration, and long-running automation tasks.
MMOS
MMOS (Mix of Minimal Optimal Sets) is a dataset designed for math reasoning tasks, offering higher performance and lower construction costs. It includes various models and data subsets for tasks like arithmetic reasoning and math word problem solving. The dataset is used to identify minimal optimal sets through reasoning paths and statistical analysis, with a focus on QA-pairs generated from open-source datasets. MMOS also provides an auto problem generator for testing model robustness and scripts for training and inference.

MOSS-TTS
MOSS-TTS Family is an open-source speech and sound generation model family designed for high-fidelity, high-expressiveness, and complex real-world scenarios. It includes five production-ready models: MOSS-TTS, MOSS-TTSD, MOSS-VoiceGenerator, MOSS-TTS-Realtime, and MOSS-SoundEffect, each serving specific purposes in speech generation, dialogue, voice design, real-time interactions, and sound effect generation. The models offer features like long-speech generation, fine-grained control over phonemes and duration, multilingual synthesis, voice cloning, and real-time voice agents.

denodo-ai-sdk
Denodo AI SDK is a tool that enables users to create AI chatbots and agents that provide accurate and context-aware answers using enterprise data. It connects to the Denodo Platform, supports popular LLMs and vector stores, and includes a sample chatbot and simple APIs for quick setup. The tool also offers benchmarks for evaluating LLM performance and provides guidance on configuring DeepQuery for different LLM providers.

Awesome-LLMs-for-Video-Understanding
Awesome-LLMs-for-Video-Understanding is a repository dedicated to exploring Video Understanding with Large Language Models. It provides a comprehensive survey of the field, covering models, pretraining, instruction tuning, and hybrid methods. The repository also includes information on tasks, datasets, and benchmarks related to video understanding. Contributors are encouraged to add new papers, projects, and materials to enhance the repository.

InternVL
InternVL scales up the ViT to _**6B parameters**_ and aligns it with LLM. It is a vision-language foundation model that can perform various tasks, including: **Visual Perception** - Linear-Probe Image Classification - Semantic Segmentation - Zero-Shot Image Classification - Multilingual Zero-Shot Image Classification - Zero-Shot Video Classification **Cross-Modal Retrieval** - English Zero-Shot Image-Text Retrieval - Chinese Zero-Shot Image-Text Retrieval - Multilingual Zero-Shot Image-Text Retrieval on XTD **Multimodal Dialogue** - Zero-Shot Image Captioning - Multimodal Benchmarks with Frozen LLM - Multimodal Benchmarks with Trainable LLM - Tiny LVLM InternVL has been shown to achieve state-of-the-art results on a variety of benchmarks. For example, on the MMMU image classification benchmark, InternVL achieves a top-1 accuracy of 51.6%, which is higher than GPT-4V and Gemini Pro. On the DocVQA question answering benchmark, InternVL achieves a score of 82.2%, which is also higher than GPT-4V and Gemini Pro. InternVL is open-sourced and available on Hugging Face. It can be used for a variety of applications, including image classification, object detection, semantic segmentation, image captioning, and question answering.

goodai-ltm-benchmark
This repository contains code and data for replicating experiments on Long-Term Memory (LTM) abilities of conversational agents. It includes a benchmark for testing agents' memory performance over long conversations, evaluating tasks requiring dynamic memory upkeep and information integration. The repository supports various models, datasets, and configurations for benchmarking and reporting results.

LLamaTuner
LLamaTuner is a repository for the Efficient Finetuning of Quantized LLMs project, focusing on building and sharing instruction-following Chinese baichuan-7b/LLaMA/Pythia/GLM model tuning methods. The project enables training on a single Nvidia RTX-2080TI and RTX-3090 for multi-round chatbot training. It utilizes bitsandbytes for quantization and is integrated with Huggingface's PEFT and transformers libraries. The repository supports various models, training approaches, and datasets for supervised fine-tuning, LoRA, QLoRA, and more. It also provides tools for data preprocessing and offers models in the Hugging Face model hub for inference and finetuning. The project is licensed under Apache 2.0 and acknowledges contributions from various open-source contributors.
llmq
llm.q is an implementation of (quantized) large language model training in CUDA, inspired by llm.c. It is particularly aimed at medium-sized training setups, i.e., a single node with multiple GPUs. The code is written in C++20 and requires CUDA 12 or later. It depends on nccl for communication, and cudnn for fast attention. Multi-GPU training can either be run in multi-process mode (requires OpenMPI) or in multi-thread mode. Additional header-only dependencies are automatically downloaded by cmake during the build process. The tool provides detailed instructions on data preparation, training runs, inspecting logs, evaluations, and a larger example for real training runs. It also offers detailed usage instructions covering model configuration, data configuration, optimization parameters, checkpointing, output, low-bit settings, activation checkpointing/recomputation, multi-GPU settings, offloading, algorithm selection, and Python bindings. The code organization includes directories for kernels, models, training, and utilities. Speed benchmarks for different GPU configurations are provided, along with testing details for recomputation, fixed reference, and Python reference tests.

Awesome-Knowledge-Distillation-of-LLMs
A collection of papers related to knowledge distillation of large language models (LLMs). The repository focuses on techniques to transfer advanced capabilities from proprietary LLMs to smaller models, compress open-source LLMs, and refine their performance. It covers various aspects of knowledge distillation, including algorithms, skill distillation, verticalization distillation in fields like law, medical & healthcare, finance, science, and miscellaneous domains. The repository provides a comprehensive overview of the research in the area of knowledge distillation of LLMs.
go-cyber
Cyber is a superintelligence protocol that aims to create a decentralized and censorship-resistant internet. It uses a novel consensus mechanism called CometBFT and a knowledge graph to store and process information. Cyber is designed to be scalable, secure, and efficient, and it has the potential to revolutionize the way we interact with the internet.
For similar tasks
SpinQuant
SpinQuant is a tool designed for LLM quantization with learned rotations. It focuses on optimizing rotation matrices to enhance the performance of quantized models, narrowing the accuracy gap to full precision models. The tool implements rotation optimization and PTQ evaluation with optimized rotation, providing arguments for model name, batch sizes, quantization bits, and rotation options. SpinQuant is based on the findings that rotation helps in removing outliers and improving quantization, with specific enhancements achieved through learning rotation with Cayley optimization.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.