Best AI tools for< Quantize Weight And Activations >
0 - AI tool Sites
No tools available
1 - Open Source AI Tools
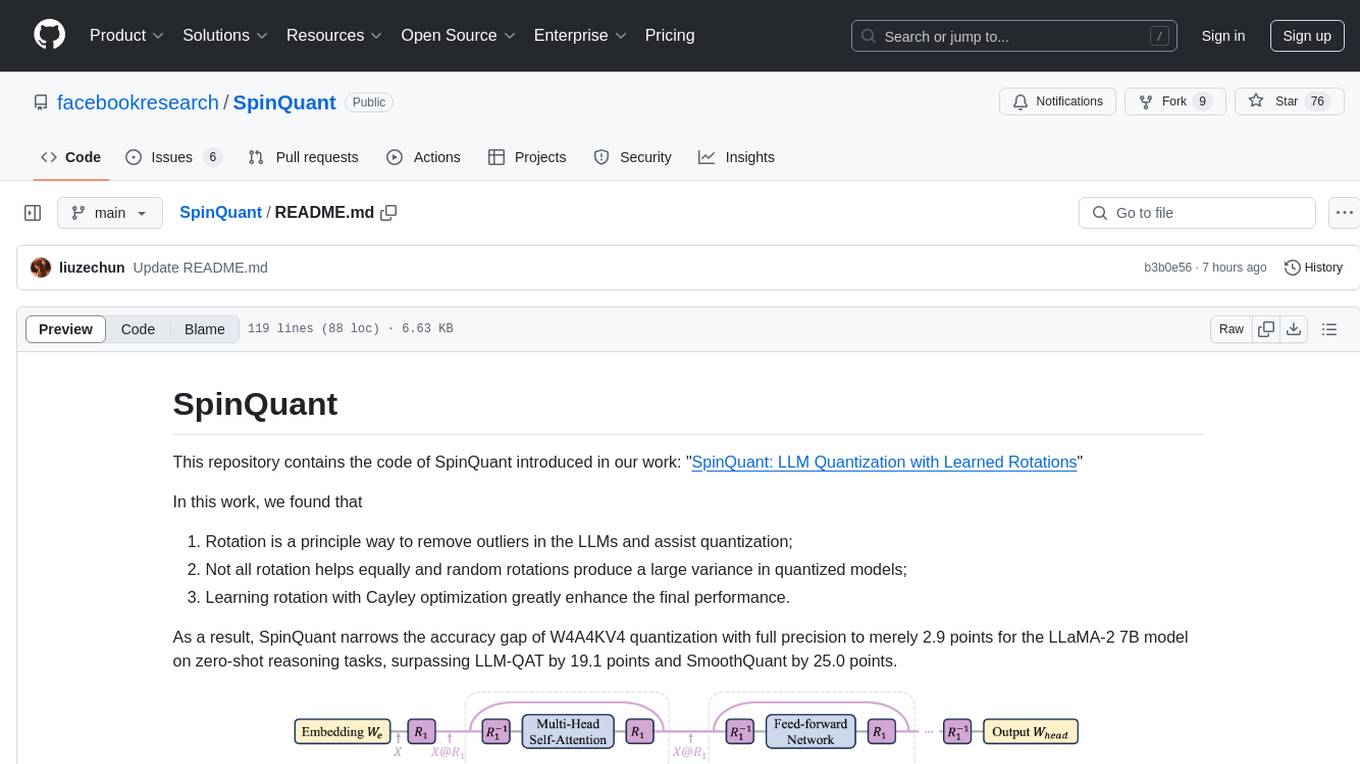
SpinQuant
SpinQuant is a tool designed for LLM quantization with learned rotations. It focuses on optimizing rotation matrices to enhance the performance of quantized models, narrowing the accuracy gap to full precision models. The tool implements rotation optimization and PTQ evaluation with optimized rotation, providing arguments for model name, batch sizes, quantization bits, and rotation options. SpinQuant is based on the findings that rotation helps in removing outliers and improving quantization, with specific enhancements achieved through learning rotation with Cayley optimization.
github
: 76
0 - OpenAI Gpts
No tools available