
Awesome-LLM-Compression
Awesome LLM compression research papers and tools.
Stars: 1450
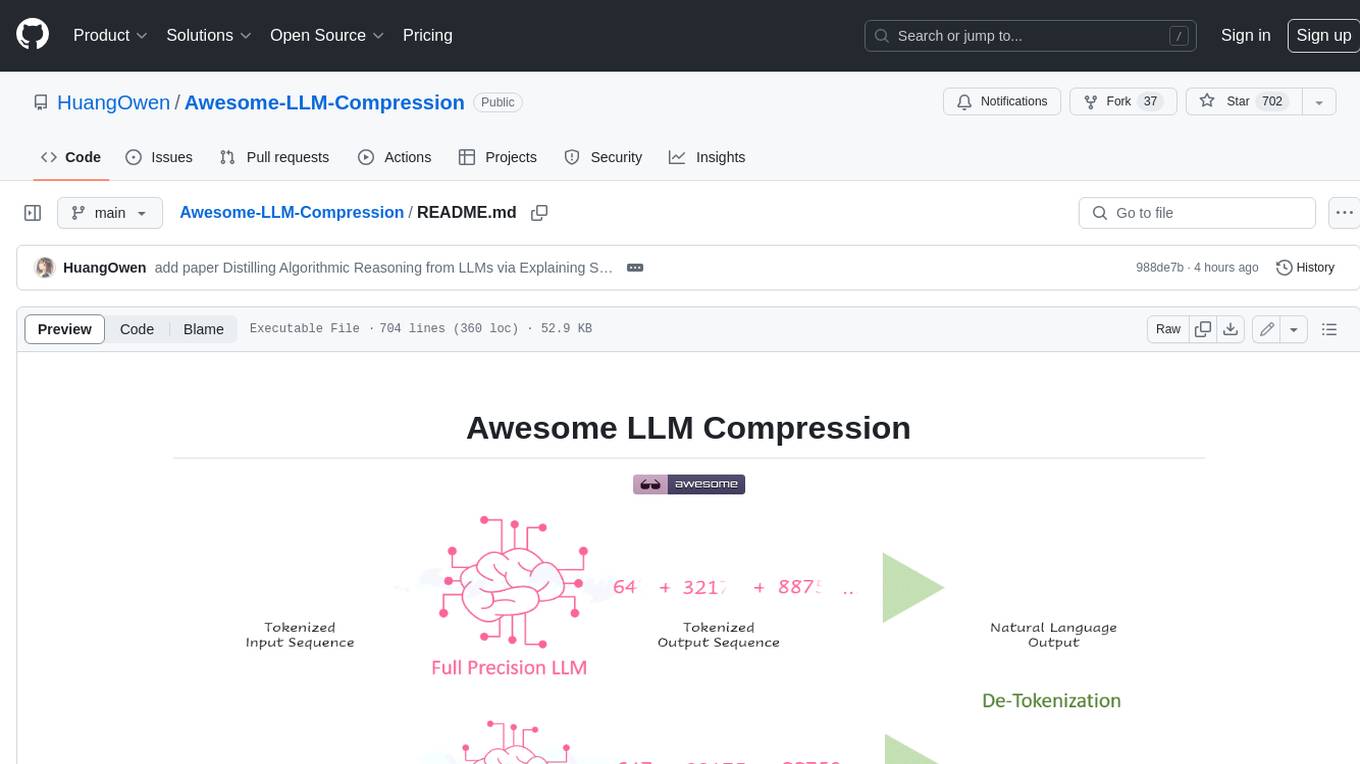
Awesome LLM compression research papers and tools to accelerate LLM training and inference.
README:



Awesome LLM compression research papers and tools to accelerate LLM training and inference.
-
A Survey on Model Compression for Large Language Models
TACL [Paper] -
The Cost of Compression: Investigating the Impact of Compression on Parametric Knowledge in Language Models
EMNLP 2023 [Paper] [Code] -
The Efficiency Spectrum of Large Language Models: An Algorithmic Survey
Arxiv 2023 [Paper] -
Efficient Large Language Models: A Survey
TMLR [Paper] [GitHub Page] -
Towards Efficient Generative Large Language Model Serving: A Survey from Algorithms to Systems
ICML 2024 Tutorial [Paper] [Tutorial] -
Understanding LLMs: A Comprehensive Overview from Training to Inference
Arxiv 2024 [Paper] -
Faster and Lighter LLMs: A Survey on Current Challenges and Way Forward
IJCAI 2024 (Survey Track) [Paper] [GitHub Page] -
A Survey of Resource-efficient LLM and Multimodal Foundation Models
Arxiv 2024 [Paper] -
A Survey on Hardware Accelerators for Large Language Models
Arxiv 2024 [Paper] -
A Comprehensive Survey of Compression Algorithms for Language Models
Arxiv 2024 [Paper] -
A Survey on Transformer Compression
Arxiv 2024 [Paper] -
Model Compression and Efficient Inference for Large Language Models: A Survey
Arxiv 2024 [Paper] -
LLM Inference Unveiled: Survey and Roofline Model Insights
Arxiv 2024 [Paper] -
A Survey on Knowledge Distillation of Large Language Models
Arxiv 2024 [Paper] [GitHub Page] -
Efficient Prompting Methods for Large Language Models: A Survey
Arxiv 2024 [Paper] -
Survey on Knowledge Distillation for Large Language Models: Methods, Evaluation, and Application
Arxiv 2024 [Paper] -
On-Device Language Models: A Comprehensive Review
Arxiv 2024 [Paper] [GitHub Page] [Download On-device LLMs] -
A Survey of Low-bit Large Language Models: Basics, Systems, and Algorithms
Arxiv 2024 [Paper] -
Contextual Compression in Retrieval-Augmented Generation for Large Language Models: A Survey
Arxiv 2024 [Paper] -
Prompt Compression for Large Language Models: A Survey
Arxiv 2024 [Paper] -
A Comprehensive Study on Quantization Techniques for Large Language Models
Arxiv 2024 [Paper] -
A Survey on Large Language Model Acceleration based on KV Cache Management
Arxiv 2024 [Paper] -
Efficient AI in Practice: Training and Deployment of Efficient LLMs for Industry Applications
Arxiv 2025 [Paper] -
Key, Value, Compress: A Systematic Exploration of KV Cache Compression Techniques
CICC 2025 [Paper] -
Are We There Yet? A Measurement Study of Efficiency for LLM Applications on Mobile Devices
Arxiv 2025 [Paper]
-
ZeroQuant: Efficient and Affordable Post-Training Quantization for Large-Scale Transformers
NeurIPS 2022 [Paper] [Code (DeepSpeed)] -
LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
NeurIPS 2022 [Paper] [Code] -
Outlier Suppression: Pushing the Limit of Low-bit Transformer Language Models
NeurIPS 2022 [Paper] [Code] -
LUT-GEMM: Quantized Matrix Multiplication based on LUTs for Efficient Inference in Large-Scale Generative Language Models
ICLR 2024 [Paper] -
SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models
ICML 2023 [Paper] [Code] -
FlexRound: Learnable Rounding based on Element-wise Division for Post-Training Quantization
ICML 2023 [Paper] [Code (DeepSpeed)] -
Understanding INT4 Quantization for Transformer Models: Latency Speedup, Composability, and Failure Cases
ICML 2023 [Paper] [Code] -
The case for 4-bit precision: k-bit Inference Scaling Laws
ICML 2023 [Paper] -
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
ICLR 2023 [Paper] [Code] -
PreQuant: A Task-agnostic Quantization Approach for Pre-trained Language Models
ACL 2023 [Paper] -
Boost Transformer-based Language Models with GPU-Friendly Sparsity and Quantization
ACL 2023 [Paper] -
QLoRA: Efficient Finetuning of Quantized LLMs
NeurIPS 2023 [Paper] [Code] -
The Quantization Model of Neural Scaling
NeurIPS 2023 [Paper] -
Quantized Distributed Training of Large Models with Convergence Guarantees
ICML 2023 [Paper] -
RPTQ: Reorder-based Post-training Quantization for Large Language Models
Arxiv 2023 [Paper] [Code] -
ZeroQuant-V2: Exploring Post-training Quantization in LLMs from Comprehensive Study to Low Rank Compensation
AAAI 2024 [Paper] [Code] -
Integer or Floating Point? New Outlooks for Low-Bit Quantization on Large Language Models
ICML 2024 [Paper] -
Memory-Efficient Fine-Tuning of Compressed Large Language Models via sub-4-bit Integer Quantization
NeurIPS 2023 [Paper] -
Compress, Then Prompt: Improving Accuracy-Efficiency Trade-off of LLM Inference with Transferable Prompt
Arxiv 2023 [Paper] -
AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration
MLSys 2024 (Best Paper 🏆) [Paper] [Code] -
LLM-QAT: Data-Free Quantization Aware Training for Large Language Models
ACL Findings 2024 [Paper] [Code] -
SpQR: A Sparse-Quantized Representation for Near-Lossless LLM Weight Compression
ICLR 2024 [Paper] [Code] -
OWQ: Lessons learned from activation outliers for weight quantization in large language models
AAAI 2024 [Paper] -
SqueezeLLM: Dense-and-Sparse Quantization
ICML 2024 [Paper] [Code] -
INT2.1: Towards Fine-Tunable Quantized Large Language Models with Error Correction through Low-Rank Adaptation
Arxiv 2023 [Paper] -
LQ-LoRA: Low-rank Plus Quantized Matrix Decomposition for Efficient Language Model Finetuning
ICLR 2024 [Paper] -
INT-FP-QSim: Mixed Precision and Formats For Large Language Models and Vision Transformers
Arxiv 2023 [Paper] [Code] -
QIGen: Generating Efficient Kernels for Quantized Inference on Large Language Models
Arxiv 2023 [Paper] [Code] -
Do Emergent Abilities Exist in Quantized Large Language Models: An Empirical Study
COLING 2024 [Paper] -
ZeroQuant-FP: A Leap Forward in LLMs Post-Training W4A8 Quantization Using Floating-Point Formats
Arxiv 2023 [Paper] [Code (DeepSpeed)] -
OliVe: Accelerating Large Language Models via Hardware-friendly Outlier-Victim Pair Quantization
ISCA 2023 [Paper] -
NUPES : Non-Uniform Post-Training Quantization via Power Exponent Search
Arxiv 2023 [Paper] -
GPT-Zip: Deep Compression of Finetuned Large Language Models
ICML 2023 Workshop ES-FoMO [Paper] -
Generating Efficient Kernels for Quantized Inference on Large Language Models
ICML 2023 Workshop ES-FoMO [Paper] -
Gradient-Based Post-Training Quantization: Challenging the Status Quo
Arxiv 2023 [Paper] -
FineQuant: Unlocking Efficiency with Fine-Grained Weight-Only Quantization for LLMs
Arxiv 2023 [Paper] -
OmniQuant: Omnidirectionally Calibrated Quantization for Large Language Models
ICLR 2024 [Paper] [Code] -
FPTQ: Fine-grained Post-Training Quantization for Large Language Models
Arxiv 2023 [Paper] -
eDKM: An Efficient and Accurate Train-time Weight Clustering for Large Language Models
IEEE Computer Architecture Letters 2023 [Paper] -
QuantEase: Optimization-based Quantization for Language Models -- An Efficient and Intuitive Algorithm
Arxiv 2023 [Paper] -
Norm Tweaking: High-performance Low-bit Quantization of Large Language Models
AAAI 2024 [Paper] -
Understanding the Impact of Post-Training Quantization on Large-scale Language Models
Arxiv 2023 [Paper] -
MEMORY-VQ: Compression for Tractable Internet-Scale Memory
NAACL 2024 [Paper] -
Optimize Weight Rounding via Signed Gradient Descent for the Quantization of LLMs
EMNLP Findings 2024 [Paper] [Code] -
Efficient Post-training Quantization with FP8 Formats
MLSys 2024 [Paper] [Code (Intel® Neural Compressor)] -
QA-LoRA: Quantization-Aware Low-Rank Adaptation of Large Language Models
ICLR 2024 [Paper] [Code] -
Rethinking Channel Dimensions to Isolate Outliers for Low-bit Weight Quantization of Large Language Models
ICLR 2024 [Paper] [Code] -
ModuLoRA: Finetuning 3-Bit LLMs on Consumer GPUs by Integrating with Modular Quantizers
TMLR (Featured Certification 🌟) [Paper] -
PB-LLM: Partially Binarized Large Language Models
ICLR 2024 [Paper] [Code] -
Dual Grained Quantization: Efficient Fine-Grained Quantization for LLM
Arxiv 2023 [Paper] -
QLLM: Accurate and Efficient Low-Bitwidth Quantization for Large Language Models
ICLR 2024 [Paper] [Code] -
LoftQ: LoRA-Fine-Tuning-Aware Quantization for Large Language Models
ICLR 2024 [Paper] [Code] -
QFT: Quantized Full-parameter Tuning of LLMs with Affordable Resources
Arxiv 2023 [Paper] -
TEQ: Trainable Equivalent Transformation for Quantization of LLMs
Arxiv 2023 [Paper] [Code (Intel® Neural Compressor)] -
BitNet: Scaling 1-bit Transformers for Large Language Models
Arxiv 2023 [Paper] [Code] -
FP8-LM: Training FP8 Large Language Models
Arxiv 2023 [Paper] [Code] -
QUIK: Towards End-to-End 4-Bit Inference on Generative Large Language Models
EMNLP 2024 [Paper] [Code] -
AFPQ: Asymmetric Floating Point Quantization for LLMs
ACL Findings 2024 [Paper] [Code] -
AWEQ: Post-Training Quantization with Activation-Weight Equalization for Large Language Models
Arxiv 2023 [Paper] -
Atom: Low-bit Quantization for Efficient and Accurate LLM Serving
MLSys 2024 [Paper] [Code] -
QMoE: Practical Sub-1-Bit Compression of Trillion-Parameter Models
Arxiv 2023 [Paper] -
Dissecting the Runtime Performance of the Training, Fine-tuning, and Inference of Large Language Models
Arxiv 2023 [Paper] -
How Does Calibration Data Affect the Post-training Pruning and Quantization of Large Language Models?
Arxiv 2023 [Paper] -
A Speed Odyssey for Deployable Quantization of LLMs
Arxiv 2023 [Paper] -
Enabling Fast 2-bit LLM on GPUs: Memory Alignment, Sparse Outlier, and Asynchronous Dequantization
Arxiv 2023 [Paper] -
Quantizable Transformers: Removing Outliers by Helping Attention Heads Do Nothing
NeurIPS 2023 [Paper] [Code] -
Efficient LLM Inference on CPUs
NeurIPS 2023 on Efficient Natural Language and Speech Processing [Paper] [Code] -
The Cost of Compression: Investigating the Impact of Compression on Parametric Knowledge in Language Models
EMNLP Findings 2023 [Paper] -
Zero-Shot Sharpness-Aware Quantization for Pre-trained Language Models
EMNLP 2023 [Paper] -
Revisiting Block-based Quantisation: What is Important for Sub-8-bit LLM Inference?
EMNLP 2023 [Paper] [Code] -
Outlier Suppression+: Accurate quantization of large language models by equivalent and optimal shifting and scaling
EMNLP 2023 [Paper] -
Watermarking LLMs with Weight Quantization
EMNLP 2023 [Paper] [Code] -
Enhancing Computation Efficiency in Large Language Models through Weight and Activation Quantization
EMNLP 2023 [Paper] -
LLM-FP4: 4-Bit Floating-Point Quantized Transformers
EMNLP 2023 [Paper] [Code] -
Agile-Quant: Activation-Guided Quantization for Faster Inference of LLMs on the Edge
AAAI 2024 [Paper] -
SmoothQuant+: Accurate and Efficient 4-bit Post-Training WeightQuantization for LLM
Arxiv 2023 [Paper] -
CBQ: Cross-Block Quantization for Large Language Models
Arxiv 2023 [Paper] -
ZeroQuant(4+2): Redefining LLMs Quantization with a New FP6-Centric Strategy for Diverse Generative Tasks
Arxiv 2023 [Paper] -
QuIP: 2-Bit Quantization of Large Language Models With Guarantees
NeurIPS 2023 [Paper] [Code] -
A Performance Evaluation of a Quantized Large Language Model on Various Smartphones
Arxiv 2023 [Paper] -
DeltaZip: Multi-Tenant Language Model Serving via Delta Compression
Arxiv 2023 [Paper] [Code] -
FlightLLM: Efficient Large Language Model Inference with a Complete Mapping Flow on FPGA
FPGA 2024 [Paper] -
Extreme Compression of Large Language Models via Additive Quantization
ICML 2024 [Paper] [Code] -
Quantized Side Tuning: Fast and Memory-Efficient Tuning of Quantized Large Language Models
Arxiv 2024 [Paper] -
Inferflow: an Efficient and Highly Configurable Inference Engine for Large Language Models
Arxiv 2024 [Paper] -
FP6-LLM: Efficiently Serving Large Language Models Through FP6-Centric Algorithm-System Co-Design
USENIX ATC 2024 [Paper] -
Can Large Language Models Understand Context?
Arxiv 2024 [Paper] -
EdgeQAT: Entropy and Distribution Guided Quantization-Aware Training for the Acceleration of Lightweight LLMs on the Edge
Arxiv 2024 [Paper] [Code] -
Any-Precision LLM: Low-Cost Deployment of Multiple, Different-Sized LLMs
Arxiv 2024 [Paper] -
LQER: Low-Rank Quantization Error Reconstruction for LLMs
ICML 2024 [Paper] -
BiLLM: Pushing the Limit of Post-Training Quantization for LLMs
Arxiv 2024 [Paper] [Code] -
QuIP#: Even Better LLM Quantization with Hadamard Incoherence and Lattice Codebooks
ICML 2024 [Paper] [Code] -
L4Q: Parameter Efficient Quantization-Aware Training on Large Language Models via LoRA-wise LSQ
Arxiv 2024 [Paper] -
TP-Aware Dequantization
Arxiv 2024 [Paper] -
ApiQ: Finetuning of 2-Bit Quantized Large Language Model
EMNLP 2024 [Paper] -
Accurate LoRA-Finetuning Quantization of LLMs via Information Retention
Arxiv 2024 [Paper] [Code] -
BitDelta: Your Fine-Tune May Only Be Worth One Bit
Arxiv 2024 [Paper] [Code] -
QDyLoRA: Quantized Dynamic Low-Rank Adaptation for Efficient Large Language Model Tuning
EMNLP 2024 Industry Track [Paper] -
Any-Precision LLM: Low-Cost Deployment of Multiple, Different-Sized LLMs
ICML 2024 [Paper] -
BitDistiller: Unleashing the Potential of Sub-4-Bit LLMs via Self-Distillation
ACL 2024 [Paper] [Code] -
OneBit: Towards Extremely Low-bit Large Language Models
Arxiv 2024 [Paper] -
DB-LLM: Accurate Dual-Binarization for Efficient LLMs
ACL Findings 2024 [Paper] -
WKVQuant: Quantizing Weight and Key/Value Cache for Large Language Models Gains More
Arxiv 2024 [Paper] -
GPTVQ: The Blessing of Dimensionality for LLM Quantization
Arxiv 2024 [Paper] [Code] -
APTQ: Attention-aware Post-Training Mixed-Precision Quantization for Large Language Models
DAC 2024 [Paper] -
A Comprehensive Evaluation of Quantization Strategies for Large Language Models
DAC 2024 [Paper] -
Evaluating Quantized Large Language Models
Arxiv 2024 [Paper] -
FlattenQuant: Breaking Through the Inference Compute-bound for Large Language Models with Per-tensor Quantization
Arxiv 2024 [Paper] -
LLM-PQ: Serving LLM on Heterogeneous Clusters with Phase-Aware Partition and Adaptive Quantization
Arxiv 2024 [Paper] -
IntactKV: Improving Large Languagze Model Quantization by Keeping Pivot Tokens Intact
ACL Findings 2024 [Paper] [Code] -
On the Compressibility of Quantized Large Language Models
Arxiv 2024 [Paper] -
EasyQuant: An Efficient Data-free Quantization Algorithm for LLMs
Arxiv 2024 [Paper] -
What Makes Quantization for Large Language Models Hard? An Empirical Study from the Lens of Perturbation
Arxiv 2024 [Paper] -
AffineQuant: Affine Transformation Quantization for Large Language Models
ICLR 2024 [Paper] [Code] -
Oh! We Freeze: Improving Quantized Knowledge Distillation via Signal Propagation Analysis for Large Language Models
ICLR Practical ML for Low Resource Settings Workshop 2024 [Paper] -
Accurate Block Quantization in LLMs with Outliers
Arxiv 2024 [Paper] -
QuaRot: Outlier-Free 4-Bit Inference in Rotated LLMs
Arxiv 2024 [Paper] [Code] -
Minimize Quantization Output Error with Bias Compensation
Arxiv 2024 [Paper] [Code] -
Cherry on Top: Parameter Heterogeneity and Quantization in Large Language Models
Arxiv 2024 [Paper] -
Increased LLM Vulnerabilities from Fine-tuning and Quantization
Arxiv 2024 [Paper] -
Quantization of Large Language Models with an Overdetermined Basis
Arxiv 2024 [Paper] -
How Good Are Low-bit Quantized LLaMA3 Models? An Empirical Study
Arxiv 2024 [Paper] [Code] [Model] -
How to Parameterize Asymmetric Quantization Ranges for Quantization-Aware Training
Arxiv 2024 [Paper] -
Mitigating the Impact of Outlier Channels for Language Model Quantization with Activation Regularization
Arxiv 2024 [Paper] [Code] -
When Quantization Affects Confidence of Large Language Models?
NAACL 2024 [Paper] -
QServe: W4A8KV4 Quantization and System Co-design for Efficient LLM Serving
Arxiv 2024 [Paper] [Code] -
Learning from Students: Applying t-Distributions to Explore Accurate and Efficient Formats for LLMs
ICML 2024 [Paper] -
LLM-QBench: A Benchmark Towards the Best Practice for Post-training Quantization of Large Language Models
Arxiv 2024 [Paper] [Code] -
SKVQ: Sliding-window Key and Value Cache Quantization for Large Language Models
Arxiv 2024 [Paper] -
Combining multiple post-training techniques to achieve most efficient quantized LLMs
Arxiv 2024 [Paper] -
Edge Intelligence Optimization for Large Language Model Inference with Batching and Quantization
Arxiv 2024 [Paper] -
SliM-LLM: Salience-Driven Mixed-Precision Quantization for Large Language Models
Arxiv 2024 [Paper] [Code] -
OAC: Output-adaptive Calibration for Accurate Post-training Quantization
Arxiv 2024 [Paper] -
PV-Tuning: Beyond Straight-Through Estimation for Extreme LLM Compression
Arxiv 2024 [Paper] -
SpinQuant -- LLM quantization with learned rotations
ICLR 2025 [Paper] -
Compressing Large Language Models using Low Rank and Low Precision Decomposition
Arxiv 2024 [Paper] [Code] -
Athena: Efficient Block-Wise Post-Training Quantization for Large Language Models Using Second-Order Matrix Derivative Information
Arxiv 2024 [Paper] -
Exploiting LLM Quantization
Arxiv 2024 [Paper] -
One QuantLLM for ALL: Fine-tuning Quantized LLMs Once for Efficient Deployments
Arxiv 2024 [Paper] -
LCQ: Low-Rank Codebook based Quantization for Large Language Models
Arxiv 2024 [Paper] -
LoQT: Low Rank Adapters for Quantized Training
Arxiv 2024 [Paper] [Code] -
CLAQ: Pushing the Limits of Low-Bit Post-Training Quantization for LLMs
Arxiv 2024 [Paper] [Code] -
I-LLM: Efficient Integer-Only Inference for Fully-Quantized Low-Bit Large Language Models
Arxiv 2024 [Paper] -
Outliers and Calibration Sets have Diminishing Effect on Quantization of Modern LLMs
Arxiv 2024 [Paper] -
DuQuant: Distributing Outliers via Dual Transformation Makes Stronger Quantized LLMs
NeurIPS 2024 [Paper] [Code] -
ShiftAddLLM: Accelerating Pretrained LLMs via Post-Training Multiplication-Less Reparameterization
Arxiv 2024 [Paper] [Code] -
Low-Rank Quantization-Aware Training for LLMs
Arxiv 2024 [Paper] -
TernaryLLM: Ternarized Large Language Model
Arxiv 2024 [Paper] -
Examining Post-Training Quantization for Mixture-of-Experts: A Benchmark
Arxiv 2024 [Paper] [Code] -
Delta-CoMe: Training-Free Delta-Compression with Mixed-Precision for Large Language Models
Arxiv 2024 [Paper] -
QQQ: Quality Quattuor-Bit Quantization for Large Language Models
Arxiv 2024 [Paper] [Code] -
QTIP: Quantization with Trellises and Incoherence Processing
NeurIPS 2024 [Paper] [Code] -
Prefixing Attention Sinks can Mitigate Activation Outliers for Large Language Model Quantization
EMNLP 2024 [Paper] -
Mixture of Scales: Memory-Efficient Token-Adaptive Binarization for Large Language Models
Arxiv 2024 [Paper] -
Tender: Accelerating Large Language Models via Tensor Decomposition and Runtime Requantization
ISCA 2024 [Paper] -
SDQ: Sparse Decomposed Quantization for LLM Inference
Arxiv 2024 [Paper] -
Attention-aware Post-training Quantization without Backpropagation
Arxiv 2024 [Paper] -
EDGE-LLM: Enabling Efficient Large Language Model Adaptation on Edge Devices via Layerwise Unified Compression and Adaptive Layer Tuning and Voting
Arxiv 2024 [Paper] [Code] -
Compensate Quantization Errors: Make Weights Hierarchical to Compensate Each Other
Arxiv 2024 [Paper] -
Layer-Wise Quantization: A Pragmatic and Effective Method for Quantizing LLMs Beyond Integer Bit-Levels
Arxiv 2024 [Paper] [Code] -
CDQuant: Accurate Post-training Weight Quantization of Large Pre-trained Models using Greedy Coordinate Descent
Arxiv 2024 [Paper] -
OutlierTune: Efficient Channel-Wise Quantization for Large Language Models
Arxiv 2024 [Paper] -
T-MAC: CPU Renaissance via Table Lookup for Low-Bit LLM Deployment on Edge
Arxiv 2024 [Paper] [Code] -
GPTQT: Quantize Large Language Models Twice to Push the Efficiency
ICORIS 2024 [Paper] -
Improving Conversational Abilities of Quantized Large Language Models via Direct Preference Alignment
ACL 2024 [Paper] -
How Does Quantization Affect Multilingual LLMs?
EMNLP Findings 2024 [Paper] -
RoLoRA: Fine-tuning Rotated Outlier-free LLMs for Effective Weight-Activation Quantization
EMNLP Findings 2024 [Paper] [Code] -
Q-GaLore: Quantized GaLore with INT4 Projection and Layer-Adaptive Low-Rank Gradients
Arxiv 2024 [Paper] [Code] -
FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision
Arxiv 2024 [Paper] [Code] -
Accuracy is Not All You Need
Arxiv 2024 [Paper] -
BitNet b1.58 Reloaded: State-of-the-art Performance Also on Smaller Networks
Arxiv 2024 [Paper] -
LeanQuant: Accurate Large Language Model Quantization with Loss-Error-Aware Grid
Arxiv 2024 [Paper] -
Fast Matrix Multiplications for Lookup Table-Quantized LLMs
EMNLP Findings 2024 [Paper] [Code] -
EfficientQAT: Efficient Quantization-Aware Training for Large Language Models
Arxiv 2024 [Paper] [Code] -
LRQ: Optimizing Post-Training Quantization for Large Language Models by Learning Low-Rank Weight-Scaling Matrices
Arxiv 2024 [Paper] [Code] -
Exploring Quantization for Efficient Pre-Training of Transformer Language Models
EMNLP Findings 2024 [Paper] [Code] -
Spectra: A Comprehensive Study of Ternary, Quantized, and FP16 Language Models
Arxiv 2024 [Paper] [Code] -
Mamba-PTQ: Outlier Channels in Recurrent Large Language Models
Efficient Systems for Foundation Models Workshop @ ICML 2024 [Paper] -
Compensate Quantization Errors+: Quantized Models Are Inquisitive Learners
Arxiv 2024 [Paper] -
Accurate and Efficient Fine-Tuning of Quantized Large Language Models Through Optimal Balance
Arxiv 2024 [Paper] [Code] -
STBLLM: Breaking the 1-Bit Barrier with Structured Binary LLMs
Arxiv 2024 [Paper] -
Advancing Multimodal Large Language Models with Quantization-Aware Scale Learning for Efficient Adaptation
ACM MM 2024 [Paper] -
ABQ-LLM: Arbitrary-Bit Quantized Inference Acceleration for Large Language Models
Arxiv 2024 [Paper] -
MARLIN: Mixed-Precision Auto-Regressive Parallel Inference on Large Language Models
Arxiv 2024 [Paper] [Code (Marlin)] [Code (Sparse Marlin)] -
Matmul or No Matmal in the Era of 1-bit LLMs
Arxiv 2024 [Paper] -
MobileQuant: Mobile-friendly Quantization for On-device Language Models
EMNLP Findings 2024 [Paper] [Code] -
GIFT-SW: Gaussian noise Injected Fine-Tuning of Salient Weights for LLMs
Arxiv 2024 [Paper] [Code] -
Foundations of Large Language Model Compression -- Part 1: Weight Quantization
Arxiv 2024 [Paper] [Code] -
OPAL: Outlier-Preserved Microscaling Quantization A ccelerator for Generative Large Language Models
DAC 2024 [Paper] -
VPTQ: Extreme Low-bit Vector Post-Training Quantization for Large Language Models
EMNLP 2024 [Paper] [Code] -
Scaling FP8 training to trillion-token LLMs
Arxiv 2024 [Paper] -
Accumulator-Aware Post-Training Quantization
Arxiv 2024 [Paper] -
Efficient Arbitrary Precision Acceleration for Large Language Models on GPU Tensor Cores
Arxiv 2024 [Paper] -
Rotated Runtime Smooth: Training-Free Activation Smoother for accurate INT4 inference
Arxiv 2024 [Paper] [Code] -
EXAQ: Exponent Aware Quantization For LLMs Acceleration
Arxiv 2024 [Paper] -
ARB-LLM: Alternating Refined Binarizations for Large Language Models
Arxiv 2024 [Paper] [Code] -
PrefixQuant: Static Quantization Beats Dynamic through Prefixed Outliers in LLMs
Arxiv 2024 [Paper] [Code] -
SpaLLM: Unified Compressive Adaptation of Large Language Models with Sketching
Arxiv 2024 [Paper] -
Scaling Laws for Mixed quantization in Large Language Models
Arxiv 2024 [Paper] -
Q-VLM: Post-training Quantization for Large Vision-Language Models
NeurIPS 2024 [Paper] [Code] -
CrossQuant: A Post-Training Quantization Method with Smaller Quantization Kernel for Precise Large Language Model Compression
Arxiv 2024 [Paper] -
FlatQuant: Flatness Matters for LLM Quantization
Arxiv 2024 [Paper] [Code] -
DeltaDQ: Ultra-High Delta Compression for Fine-Tuned LLMs via Group-wise Dropout and Separate Quantization
Arxiv 2024 [Paper] -
QEFT: Quantization for Efficient Fine-Tuning of LLMs
EMNLP Findings 2024 [Paper] [Code] -
Continuous Approximations for Improving Quantization Aware Training of LLMs
Arxiv 2024 [Paper] -
DAQ: Density-Aware Post-Training Weight-Only Quantization For LLMs
Arxiv 2024 [Paper] -
COMET: Towards Partical W4A4KV4 LLMs Serving
Arxiv 2024 [Paper] -
Scaling laws for post-training quantized large language models
Arxiv 2024 [Paper] -
Channel-Wise Mixed-Precision Quantization for Large Language Models
Arxiv 2024 [Paper] -
Understanding the difficulty of low-precision post-training quantization of large language models
Arxiv 2024 [Paper] -
QuAILoRA: Quantization-Aware Initialization for LoRA
NeurIPS Workshop on Efficient Natural Language and Speech Processing (ENLSP-IV) 2024 [Paper] -
SDP4Bit: Toward 4-bit Communication Quantization in Sharded Data Parallelism for LLM Training
NeurIPS 2024 [Paper] -
Pyramid Vector Quantization for LLMs
Arxiv 2024 [Paper] -
TesseraQ: Ultra Low-Bit LLM Post-Training Quantization with Block Reconstruction
Arxiv 2024 [Paper] [Code] -
COAT: Compressing Optimizer states and Activation for Memory-Efficient FP8 Training
Arxiv 2024 [Paper] [Code] -
GWQ: Gradient-Aware Weight Quantization for Large Language Models
Arxiv 2024 [Paper] -
"Give Me BF16 or Give Me Death"? Accuracy-Performance Trade-Offs in LLM Quantization
Arxiv 2024 [Paper] -
Interactions Across Blocks in Post-Training Quantization of Large Language Models
Arxiv 2024 [Paper] -
BitNet a4.8: 4-bit Activations for 1-bit LLMs
Arxiv 2024 [Paper] -
The Super Weight in Large Language Models
Arxiv 2024 [Paper] [Code] -
ASER: Activation Smoothing and Error Reconstruction for Large Language Model Quantization
Arxiv 2024 [Paper] -
Towards Low-bit Communication for Tensor Parallel LLM Inference
Arxiv 2024 [Paper] -
AMXFP4: Taming Activation Outliers with Asymmetric Microscaling Floating-Point for 4-bit LLM Inference
Arxiv 2024 [Paper] [Code] -
Scaling Laws for Precision
Arxiv 2024 [Paper] -
BitMoD: Bit-serial Mixture-of-Datatype LLM Acceleration
HPCA 2025 [Paper] [Code] -
SageAttention2 Technical Report: Accurate 4 Bit Attention for Plug-and-play Inference Acceleration
Arxiv 2024 [Paper] [Code] -
AutoMixQ: Self-Adjusting Quantization for High Performance Memory-Efficient Fine-Tuning
Arxiv 2024 [Paper] -
Anda: Unlocking Efficient LLM Inference with a Variable-Length Grouped Activation Data Format
HPCA 2025 [Paper] -
MixPE: Quantization and Hardware Co-design for Efficient LLM Inference
Arxiv 2024 [Paper] -
Pushing the Limits of Large Language Model Quantization via the Linearity Theorem
Arxiv 2024 [Paper] -
Low-Bit Quantization Favors Undertrained LLMs: Scaling Laws for Quantized LLMs with 100T Training Tokens
Arxiv 2024 [Paper] [Models] -
DFRot: Achieving Outlier-Free and Massive Activation-Free for Rotated LLMs with Refined Rotation
Arxiv 2024 [Paper] [Code] -
RILQ: Rank-Insensitive LoRA-based Quantization Error Compensation for Boosting 2-bit Large Language Model Accuracy
Arxiv 2024 [Paper] -
CPTQuant -- A Novel Mixed Precision Post-Training Quantization Techniques for Large Language Models
Arxiv 2024 [Paper] -
SKIM: Any-bit Quantization Pushing The Limits of Post-Training Quantization
Arxiv 2024 [Paper] -
Direct Quantized Training of Language Models with Stochastic Rounding
Arxiv 2024 [Paper] [Code] -
Taming Sensitive Weights : Noise Perturbation Fine-tuning for Robust LLM Quantization
Arxiv 2024 [Paper] -
Low-Rank Correction for Quantized LLMs
Arxiv 2024 [Paper] -
CRVQ: Channel-relaxed Vector Quantization for Extreme Compression of LLMs
Arxiv 2024 [Paper] -
ResQ: Mixed-Precision Quantization of Large Language Models with Low-Rank Residuals
Arxiv 2024 [Paper] [Code] -
MixLLM: LLM Quantization with Global Mixed-precision between Output-features and Highly-efficient System Design
Arxiv 2024 [Paper] -
GQSA: Group Quantization and Sparsity for Accelerating Large Language Model Inference
Arxiv 2024 [Paper] -
LSAQ: Layer-Specific Adaptive Quantization for Large Language Model Deployment
Arxiv 2024 [Paper] -
Pushing the Envelope of Low-Bit LLM via Dynamic Error Compensation
Arxiv 2024 [Paper] -
HALO: Hadamard-Assisted Lossless Optimization for Efficient Low-Precision LLM Training and Fine-Tuning
Arxiv 2025 [Paper] -
The Power of Negative Zero: Datatype Customization for Quantized Large Language Models
Arxiv 2025 [Paper] -
FlexQuant: Elastic Quantization Framework for Locally Hosted LLM on Edge Devices
Arxiv 2025 [Paper] -
Rethinking Post-Training Quantization: Introducing a Statistical Pre-Calibration Approach
Arxiv 2025 [Paper] -
Qrazor: Reliable and effortless 4-bit llm quantization by significant data razoring
Arxiv 2025 [Paper] -
OstQuant: Refining Large Language Model Quantization with Orthogonal and Scaling Transformations for Better Distribution Fitting
ICLR 2025 [Paper] [Code] -
HWPQ: Hessian-free Weight Pruning-Quantization For LLM Compression And Acceleration
Arxiv 2025 [Paper] -
Progressive Binarization with Semi-Structured Pruning for LLMs
Arxiv 2025 [Paper] [Code] -
Unlocking Efficient Large Inference Models: One-Bit Unrolling Tips the Scales
Arxiv 2025 [Paper] -
QuEST: Stable Training of LLMs with 1-Bit Weights and Activations
Arxiv 2025 [Paper] -
ParetoQ: Scaling Laws in Extremely Low-bit LLM Quantization
Arxiv 2025 [Paper] -
Systematic Outliers in Large Language Models
ICLR 2025 [Paper] [Code] -
Can Post-Training Quantization Benefit from an Additional QLoRA Integration?
NAACL 2025 [Paper] -
1bit-Merging: Dynamic Quantized Merging for Large Language Models
Arxiv 2025 [Paper] -
Towards Efficient Pre-training: Exploring FP4 Precision in Large Language Models
Arxiv 2025 [Paper] -
Continual Quantization-Aware Pre-Training: When to transition from 16-bit to 1.58-bit pre-training for BitNet language models?
Arxiv 2025 [Paper] -
QuZO: Quantized Zeroth-Order Fine-Tuning for Large Language Models
Arxiv 2025 [Paper] -
Benchmarking Post-Training Quantization in LLMs: Comprehensive Taxonomy, Unified Evaluation, and Comparative Analysis
Arxiv 2025 [Paper] -
Compression Scaling Laws:Unifying Sparsity and Quantization
Arxiv 2025 [Paper] -
M-ANT: Efficient Low-bit Group Quantization for LLMs via Mathematically Adaptive Numerical Type
Arxiv 2025 [Paper] -
Identifying Sensitive Weights via Post-quantization Integral
Arxiv 2025 [Paper] -
RSQ: Learning from Important Tokens Leads to Better Quantized LLMs
Arxiv 2025 [Paper] [Code] -
Universality of Layer-Level Entropy-Weighted Quantization Beyond Model Architecture and Size
Arxiv 2025 [Paper] -
Towards Superior Quantization Accuracy: A Layer-sensitive Approach
Arxiv 2025 [Paper] -
MergeQuant: Accurate 4-bit Static Quantization of Large Language Models by Channel-wise Calibration
Arxiv 2025 [Paper] -
ClusComp: A Simple Paradigm for Model Compression and Efficient Finetuning
Arxiv 2025 [Paper] -
MoQa: Rethinking MoE Quantization with Multi-stage Data-model Distribution Awareness
Arxiv 2025 [Paper] -
GPTQv2: Efficient Finetuning-Free Quantization for Asymmetric Calibration
Arxiv 2025 [Paper] [Code]
-
The Lazy Neuron Phenomenon: On Emergence of Activation Sparsity in Transformers
ICLR 2023 [Paper] -
Deja Vu: Contextual Sparsity for Efficient LLMs at Inference Time
ICML 2023 [Paper] [Code] -
LoSparse: Structured Compression of Large Language Models based on Low-Rank and Sparse Approximation
ICML 2023 [Paper] [Code] -
LLM-Pruner: On the Structural Pruning of Large Language Models
NeurIPS 2023 [Paper] [Code] -
ZipLM: Inference-Aware Structured Pruning of Language Models
NeurIPS 2023 [Paper] [Code] -
H2O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models
NeurIPS 2023 [Paper] [Code] -
The Emergence of Essential Sparsity in Large Pre-trained Models: The Weights that Matter
NeurIPS 2023 [Paper] [Code] -
Learning to Compress Prompts with Gist Tokens
NeurIPS 2023 [Paper] -
Dynamic Context Pruning for Efficient and Interpretable Autoregressive Transformers
NeurIPS 2023 [Paper] -
Prune and Tune: Improving Efficient Pruning Techniques for Massive Language Models
ICLR 2023 TinyPapers [Paper] -
SparseGPT: Massive Language Models Can Be Accurately Pruned in One-Shot
ICML 2023 [Paper] [Code] -
AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning
ICLR 2023 [Paper] -
Rethinking the Role of Scale for In-Context Learning: An Interpretability-based Case Study at 66 Billion Scale
ACL 2023 [Paper] [Code] -
Structured Pruning for Efficient Generative Pre-trained Language Models
ACL 2023 [Paper] -
A Simple and Effective Pruning Approach for Large Language Models
ICLR 2024 [Paper] [Code] -
Pruning Meets Low-Rank Parameter-Efficient Fine-Tuning
ACL Findings 2024 [Paper] -
Structural pruning of large language models via neural architecture search
AutoML 2023 [Paper] -
Pruning Large Language Models via Accuracy Predictor
ICASSP 2024 [Paper] -
Flash-LLM: Enabling Cost-Effective and Highly-Efficient Large Generative Model Inference with Unstructured Sparsity
VLDB 2024 [Paper] [Cde] -
Compressing LLMs: The Truth is Rarely Pure and Never Simple
ICLR 2024 [Paper] -
Pruning Small Pre-Trained Weights Irreversibly and Monotonically Impairs "Difficult" Downstream Tasks in LLMs
ICML 2024 [Paper] [Code] -
Compresso: Structured Pruning with Collaborative Prompting Learns Compact Large Language Models
Arxiv 2023 [Paper] [Code] -
Outlier Weighed Layerwise Sparsity (OWL): A Missing Secret Sauce for Pruning LLMs to High Sparsity
Arxiv 2023 [Paper] [Code] -
Sheared LLaMA: Accelerating Language Model Pre-training via Structured Pruning
Arxiv 2023 [Paper] [Code] -
Dynamic Sparse No Training: Training-Free Fine-tuning for Sparse LLMs
ICLR 2024 [Paper] [Code] -
One-Shot Sensitivity-Aware Mixed Sparsity Pruning for Large Language Models
ICASSP 2024 [Paper] -
Survival of the Most Influential Prompts: Efficient Black-Box Prompt Search via Clustering and Pruning
EMNLP Findings 2023 [Paper] -
The Cost of Compression: Investigating the Impact of Compression on Parametric Knowledge in Language Models
EMNLP Findings 2023 [Paper] -
Divergent Token Metrics: Measuring degradation to prune away LLM components -- and optimize quantization
Arxiv 2023 [Paper] -
LoRAShear: Efficient Large Language Model Structured Pruning and Knowledge Recovery
Arxiv 2023 [Paper] -
ReLU Strikes Back: Exploiting Activation Sparsity in Large Language Models
Arxiv 2023 [Paper] -
E-Sparse: Boosting the Large Language Model Inference through Entropy-based N:M Sparsity
Arxiv 2023 [Paper] -
Beyond Size: How Gradients Shape Pruning Decisions in Large Language Models
Arxiv 2023 [Paper] [Code] -
On the Impact of Calibration Data in Post-training Quantization and Pruning
ACL 2024 [Paper] -
BESA: Pruning Large Language Models with Blockwise Parameter-Efficient Sparsity Allocation
OpenReview [Paper] [Code] -
PUSHING GRADIENT TOWARDS ZERO: A NOVEL PRUNING METHOD FOR LARGE LANGUAGE MODELS
OpenReview 2023 [Paper] -
Plug-and-Play: An Efficient Post-training Pruning Method for Large Language Models
ICLR 2024 [Paper] [Code] -
Lighter, yet More Faithful: Investigating Hallucinations in Pruned Large Language Models for Abstractive Summarization
Arxiv 2023 [Paper] [Code] -
LORAPRUNE: PRUNING MEETS LOW-RANK PARAMETER-EFFICIENT FINE-TUNING
Arxiv 2023 [Paper] -
Mini-GPTs: Efficient Large Language Models through Contextual Pruning
Arxiv 2023 [Paper] [Code] -
The LLM Surgeon
Arxiv 2023 [Paper] -
Fluctuation-based Adaptive Structured Pruning for Large Language Models
AAAI 2024 [Paper] -
How to Prune Your Language Model: Recovering Accuracy on the "Sparsity May Cry'' Benchmark
CPAL 2024 [Paper] -
PERP: Rethinking the Prune-Retrain Paradigm in the Era of LLMs
Arxiv 2023 [Paper] -
Fast and Optimal Weight Update for Pruned Large Language Models
Arxiv 2024 [Paper] -
APT: Adaptive Pruning and Tuning Pretrained Language Models for Efficient Training and Inference
Arxiv 2024 [Paper] -
Scaling Sparse Fine-Tuning to Large Language Models
Arxiv 2024 [Paper] -
SliceGPT: Compress Large Language Models by Deleting Rows and Columns
ICLR 2024 [Paper] [Code] -
Shortened LLaMA: A Simple Depth Pruning for Large Language Models
Arxiv 2024 [Paper] -
Everybody Prune Now: Structured Pruning of LLMs with only Forward Passes
Arxiv 2024 [Paper] [Code] -
NutePrune: Efficient Progressive Pruning with Numerous Teachers for Large Language Models
Arxiv 2024 [Paper] -
LaCo: Large Language Model Pruning via Layer Collapse
EMNLP Findings 2024 [Paper] -
Why Lift so Heavy? Slimming Large Language Models by Cutting Off the Layers
Arxiv 2024 [Paper] -
EBFT: Effective and Block-Wise Fine-Tuning for Sparse LLMs
Arxiv 2024 [Paper] [Code] -
Data-free Weight Compress and Denoise for Large Language Models
Arxiv 2024 [Paper] -
Gradient-Free Adaptive Global Pruning for Pre-trained Language Models
Arxiv 2024 [Paper] -
ShortGPT: Layers in Large Language Models are More Redundant Than You Expect
Arxiv 2024 [Paper] -
LLaVA-PruMerge: Adaptive Token Reduction for Efficient Large Multimodal Models
Arxiv 2024 [Paper] [Code] -
Compressing Large Language Models by Streamlining the Unimportant Layer
Arxiv 2024 [Paper] -
LoRAP: Transformer Sub-Layers Deserve Differentiated Structured Compression for Large Language Models
Arxiv 2024 [Paper] -
LoNAS: Elastic Low-Rank Adapters for Efficient Large Language Models
COLING 2024 [Paper] [Code] -
Shears: Unstructured Sparsity with Neural Low-rank Adapter Search
NAACL 2024 [Paper] [Code] -
Eigenpruning
NAACL 2024 Abstract [Paper] -
OpenBA-V2: Reaching 77.3% High Compression Ratio with Fast Multi-Stage Pruning
Arxiv 2024 [Paper] -
Pruning as a Domain-specific LLM Extractor
NAACL 2024 Findings [Paper] [Code] -
Differentiable Model Scaling using Differentiable Topk
ICML 2024 [Paper] -
COPAL: Continual Pruning in Large Language Generative Models
ICML 2024 [Paper] -
Pruner-Zero: Evolving Symbolic Pruning Metric from scratch for Large Language Models
ICML 2024 [Paper] [Code] -
Feature-based Low-Rank Compression of Large Language Models via Bayesian Optimization
ACL Findings 2024 [Paper] -
Surgical Feature-Space Decomposition of LLMs: Why, When and How?
ACL 2024 [Paper] -
Pruning Large Language Models to Intra-module Low-rank Architecture with Transitional Activations
ACL Findings 2024 [Paper] -
Light-PEFT: Lightening Parameter-Efficient Fine-Tuning via Early Pruning
ACL Findings 2024 [Paper] [Code] -
Quest: Query-Aware Sparsity for Efficient Long-Context LLM Inference
ICML 2024 [Paper] [Code] -
MoreauPruner: Robust Pruning of Large Language Models against Weight Perturbations
Arxiv 2024 [Paper] [Code] -
ALPS: Improved Optimization for Highly Sparse One-Shot Pruning for Large Language Models
Arxiv 2024 [Paper] -
HiP Attention: Sparse Sub-Quadratic Attention with Hierarchical Attention Pruning
Arxiv 2024 [Paper] -
Optimization-based Structural Pruning for Large Language Models without Back-Propagation
Arxiv 2024 [Paper] -
BlockPruner: Fine-grained Pruning for Large Language Models
Arxiv 2024 [Paper] [Code] -
Rethinking Pruning Large Language Models: Benefits and Pitfalls of Reconstruction Error Minimization
Arxiv 2024 [Paper] -
RankAdaptor: Hierarchical Dynamic Low-Rank Adaptation for Structural Pruned LLMs
Arxiv 2024 [Paper] -
What Matters in Transformers? Not All Attention is Needed
Arxiv 2024 [Paper] [Code] -
Pruning via Merging: Compressing LLMs via Manifold Alignment Based Layer Merging
EMNLP 2024 [Paper] -
ShadowLLM: Predictor-based Contextual Sparsity for Large Language Models
Arxiv 2024 [Paper] [Code] -
Finding Transformer Circuits with Edge Pruning
Arxiv 2024 [Paper] [Code] -
Efficient Expert Pruning for Sparse Mixture-of-Experts Language Models: Enhancing Performance and Reducing Inference Costs
Arxiv 2024 [Paper] [Code] -
MINI-LLM: Memory-Efficient Structured Pruning for Large Language Models
Arxiv 2024 [Paper] -
Reconstruct the Pruned Model without Any Retraining
Arxiv 2024 [Paper] -
A deeper look at depth pruning of LLMs
ICML TF2M Workshop 2024 [Paper] [Code] -
Greedy Output Approximation: Towards Efficient Structured Pruning for LLMs Without Retraining
Arxiv 2024 [Paper] -
Pruning Large Language Models with Semi-Structural Adaptive Sparse Training
Arxiv 2024 [Paper] -
A Convex-optimization-based Layer-wise Post-training Pruner for Large Language Models
Arxiv 2024 [Paper] -
ThinK: Thinner Key Cache by Query-Driven Pruning
Arxiv 2024 [Paper] -
MoDeGPT: Modular Decomposition for Large Language Model Compression
Arxiv 2024 [Paper] -
LLM-Barber: Block-Aware Rebuilder for Sparsity Mask in One-Shot for Large Language Models
Arxiv 2024 [Paper] [Code] -
LLM Pruning and Distillation in Practice: The Minitron Approach
Arxiv 2024 [Paper] [Models] -
Training-Free Activation Sparsity in Large Language Models
Arxiv 2024 [Paper] -
Enhancing One-shot Pruned Pre-trained Language Models through Sparse-Dense-Sparse Mechanism
COLING 2025 [Paper] -
PAT: Pruning-Aware Tuning for Large Language Models
Arxiv 2024 [Paper] [Code] -
Sirius: Contextual Sparsity with Correction for Efficient LLMs
Arxiv 2024 [Paper] [Code] -
STUN: Structured-Then-Unstructured Pruning for Scalable MoE Pruning
Arxiv 2024 [Paper] -
DISP-LLM: Dimension-Independent Structural Pruning for Large Language Models
NeurIPS 2024 [Paper] -
Search for Efficient Large Language Models
NeurIPS 2024 [Paper] -
SlimGPT: Layer-wise Structured Pruning for Large Language Models
NeurIPS 2024 [Paper] -
Learn To be Efficient: Build Structured Sparsity in Large Language Models
NeurIPS 2024 [Paper] -
ALS: Adaptive Layer Sparsity for Large Language Models via Activation Correlation Assessment
NeurIPS 2024 [Paper] -
Getting Free Bits Back from Rotational Symmetries in LLMs
Arxiv 2024 [Paper] -
SLiM: One-shot Quantized Sparse Plus Low-rank Approximation of LLMs
Arxiv 2024 [Paper] [Code] -
Self-Data Distillation for Recovering Quality in Pruned Large Language Models
NeurIPS 2024 Machine Learning and Compression Workshop [Paper] -
EvoPress: Towards Optimal Dynamic Model Compression via Evolutionary Search
Arxiv 2024 [Paper] [Code] -
Pruning Foundation Models for High Accuracy without Retraining
EMNLP Findings 2024 [Paper] [Code] -
Beware of Calibration Data for Pruning Large Language Models
Arxiv 2024 [Paper] -
SQFT: Low-cost Model Adaptation in Low-precision Sparse Foundation Models
EMNLP Findings 2024 [Paper] [Code] -
Change Is the Only Constant: Dynamic LLM Slicing based on Layer Redundancy
EMNLP Findings 2024 [Paper] [Code] -
Scaling Law for Post-training after Model Pruning
Arxiv 2024 [Paper] -
LEMON: Reviving Stronger and Smaller LMs from Larger LMs with Linear Parameter Fusion
ACL 2024 [Paper] -
TrimLLM: Progressive Layer Dropping for Domain-Specific LLMs
Arxiv 2024 [Paper] -
FTP: A Fine-grained Token-wise Pruner for Large Language Models via Token Routing
Arxiv 2024 [Paper] -
Activation Sparsity Opportunities for Compressing General Large Language Models
Arxiv 2024 [Paper] -
FASP: Fast and Accurate Structured Pruning of Large Language Models
Arxiv 2025 [Paper] -
MultiPruner: Balanced Structure Removal in Foundation Models
Arxiv 2025 [Paper] [Code] -
Mamba-Shedder: Post-Transformer Compression for Efficient Selective Structured State Space Models
NAACL 2025 [Paper] [Code] -
Zeroth-Order Adaptive Neuron Alignment Based Pruning without Retraining
Arxiv 2025 [Paper] [Code] -
2SSP: A Two-Stage Framework for Structured Pruning of LLMs
Arxiv 2025 [Paper] [Code] -
You Only Prune Once: Designing Calibration-Free Model Compression With Policy Learning
ICLR 2025 [Paper] -
HWPQ: Hessian-free Weight Pruning-Quantization For LLM Compression And Acceleration
Arxiv 2025 [Paper] -
Pivoting Factorization: A Compact Meta Low-Rank Representation of Sparsity for Efficient Inference in Large Language Models
Arxiv 2025 [Paper] -
Twilight: Adaptive Attention Sparsity with Hierarchical Top-p Pruning
Arxiv 2025 [Paper] -
Adapt-Pruner: Adaptive Structural Pruning for Efficient Small Language Model Training
Arxiv 2025 [Paper] -
Dobi-SVD: Differentiable SVD for LLM Compression and Some New Perspectives
ICLR 2025 [Paper] [Homepage] -
EfficientLLM: Scalable Pruning-Aware Pretraining for Architecture-Agnostic Edge Language Models
Arxiv 2025 [Paper] [Code] -
DarwinLM: Evolutionary Structured Pruning of Large Language Models
Arxiv 2025 [Paper] -
MaskPrune: Mask-based LLM Pruning for Layer-wise Uniform Structures
Arxiv 2025 [Paper] -
Determining Layer-wise Sparsity for Large Language Models Through a Theoretical Perspective
Arxiv 2025 [Paper] -
PPC-GPT: Federated Task-Specific Compression of Large Language Models via Pruning and Chain-of-Thought Distillation
Arxiv 2025 [Paper] -
Compression Scaling Laws: Unifying Sparsity and Quantization
Arxiv 2025 [Paper] -
PASER: Post-Training Data Selection for Efficient Pruned Large Language Model Recovery
Arxiv 2025 [Paper] -
Týr-the-Pruner: Unlocking Accurate 50% Structural Pruning for LLMs via Global Sparsity Distribution Optimization
Arxiv 2025 [Paper]
-
Lifting the Curse of Capacity Gap in Distilling Language Models
ACL 2023 [Paper] [Code] -
Symbolic Chain-of-Thought Distillation: Small Models Can Also "Think" Step-by-Step
ACL 2023 [Paper] -
Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes
ACL 2023 [Paper] -
SCOTT: Self-Consistent Chain-of-Thought Distillation
ACL 2023 [Paper] -
DISCO: Distilling Counterfactuals with Large Language Models
ACL 2023 [Paper] [Code] -
LaMini-LM: A Diverse Herd of Distilled Models from Large-Scale Instructions
Arxiv 2023 [Paper] [Code] -
How To Train Your (Compressed) Large Language Model
Arxiv 2023 [Paper] -
The False Promise of Imitating Proprietary LLMs
Arxiv 2023 [Paper] -
GPT4All: Training an Assistant-style Chatbot with Large Scale Data Distillation from GPT-3.5-Turbo
Arxiv 2023 [Paper] [Code] -
PaD: Program-aided Distillation Specializes Large Models in Reasoning
Arxiv 2023 [Paper] -
MiniLLM: Knowledge Distillation of Large Language Models
ICLR 2024 [Paper] [Code] -
On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes
ICLR 2024 [Paper] -
GKD: Generalized Knowledge Distillation for Auto-regressive Sequence Models
ICLR 2024 [Paper] -
Chain-of-Thought Prompt Distillation for Multimodal Named Entity and Multimodal Relation Extraction
Arxiv 2023 [Paper] -
Task-agnostic Distillation of Encoder-Decoder Language Models
Arxiv 2023 [Paper] -
Sci-CoT: Leveraging Large Language Models for Enhanced Knowledge Distillation in Small Models for Scientific QA
Arxiv 2023 [Paper] -
Baby Llama: knowledge distillation from an ensemble of teachers trained on a small dataset with no performance penalty
CoNLL 2023 [Paper] [Code] -
Can a student Large Language Model perform as well as it's teacher?
Arxiv 2023 [Paper] -
Multistage Collaborative Knowledge Distillation from Large Language Models
ACL 2024 [Paper] [Code] -
Lion: Adversarial Distillation of Closed-Source Large Language Model
EMNLP 2023 [Paper] [Code] -
MCC-KD: Multi-CoT Consistent Knowledge Distillation
EMNLP 2023 [Paper] -
PromptMix: A Class Boundary Augmentation Method for Large Language Model Distillation
EMNLP 2023 [Paper] -
YODA: Teacher-Student Progressive Learning for Language Models
Arxiv 2023 [Paper] -
Knowledge Fusion of Large Language Models
ICLR 2024 [Paper] [Code] -
Knowledge Distillation for Closed-Source Language Models
Arxiv 2024 [Paper] -
TinyLLM: Learning a Small Student from Multiple Large Language Models
Arxiv 2024 [Paper] -
Towards Cross-Tokenizer Distillation: the Universal Logit Distillation Loss for LLMs
Arxiv 2024 [Paper] -
Revisiting Knowledge Distillation for Autoregressive Language Models
ACL 2024 [Paper] -
Sinkhorn Distance Minimization for Knowledge Distillation
COLING 2024 [Paper] -
Divide-or-Conquer? Which Part Should You Distill Your LLM?
Arxiv 2024 [Paper] -
Learning to Maximize Mutual Information for Chain-of-Thought Distillation
ACL 2024 Findings [Paper] -
DistiLLM: Towards Streamlined Distillation for Large Language Models
ICML 2024 [Paper] [Code] -
Efficiently Distilling LLMs for Edge Applications
NAACL 2024 [Paper] -
Rethinking Kullback-Leibler Divergence in Knowledge Distillation for Large Language Models
Arxiv 2024 [Paper] -
Distilling Algorithmic Reasoning from LLMs via Explaining Solution Programs
Arxiv 2024 [Paper] -
Direct Preference Knowledge Distillation for Large Language Models
Arxiv 2024 [Paper] [Codes] -
Dual-Space Knowledge Distillation for Large Language Models
Arxiv 2024 [Paper] [Codes] -
DDK: Distilling Domain Knowledge for Efficient Large Language Models
Arxiv 2024 [Paper] -
Compact Language Models via Pruning and Knowledge Distillation
Arxiv 2024 [Paper] [Code] -
LLM Pruning and Distillation in Practice: The Minitron Approach
Arxiv 2024 [Paper] [Models] -
The Mamba in the Llama: Distilling and Accelerating Hybrid Models
Arxiv 2024 [Paper] -
DocKD: Knowledge Distillation from LLMs for Open-World Document Understanding Models
EMNLP 2024 [Paper] -
SWITCH: Studying with Teacher for Knowledge Distillation of Large Language Models
Arxiv 2024 [Paper] -
Mentor-KD: Making Small Language Models Better Multi-step Reasoners
EMNLP 2024 [Paper] [Code] -
Exploring and Enhancing the Transfer of Distribution in Knowledge Distillation for Autoregressive Language Models
Arxiv 2024 [Paper] -
LLM-Neo: Parameter Efficient Knowledge Distillation for Large Language Models
Arxiv 2024 [Paper] [Code] -
Enhancing Knowledge Distillation for LLMs with Response-Priming Prompting
Arxiv 2024 [Paper] [Code] -
Feature Alignment-Based Knowledge Distillation for Efficient Compression of Large Language Models
Arxiv 2024 [Paper] -
Large Language Models Compression via Low-Rank Feature Distillation
Arxiv 2024 [Paper] -
Lillama: Large Language Models Compression via Low-Rank Feature Distillation
NAACL 2025 [Paper] [Code] -
Multi-Level Optimal Transport for Universal Cross-Tokenizer Knowledge Distillation on Language Models
AAAI 2025 [Paper] -
Chunk-Distilled Language Modeling
Arxiv 2025 [Paper] -
CODI: Compressing Chain-of-Thought into Continuous Space via Self-Distillation
Arxiv 2025 [Paper] -
Every Expert Matters: Towards Effective Knowledge Distillation for Mixture-of-Experts Language Models
Arxiv 2025 [Paper] -
TinyR1-32B-Preview: Boosting Accuracy with Branch-Merge Distillation
Arxiv 2025 [Paper]
-
Did You Read the Instructions? Rethinking the Effectiveness of Task Definitions in Instruction Learning
ACL 2023 [Paper] [Code] -
Batch Prompting: Efficient Inference with Large Language Model APIs
EMNLP 2023 [Paper] [Code] -
Adapting Language Models to Compress Contexts
EMNLP 2023 [Paper] [Code] -
Compressing Context to Enhance Inference Efficiency of Large Language Models
EMNLP 2023 [Paper] [Code] -
LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models
EMNLP 2023 [Paper] [Code] -
Vector-Quantized Prompt Learning for Paraphrase Generation
EMNLP Findings 2023 [Paper] -
Efficient Prompting via Dynamic In-Context Learning
Arxiv 2023 [Paper] -
Learning to Compress Prompts with Gist Tokens
NeurIPS 2023 [Paper] [Code] -
In-context Autoencoder for Context Compression in a Large Language Model
ICLR 2024 [Paper] -
Discrete Prompt Compression with Reinforcement Learning
Arxiv 2023 [Paper] [Code] -
BatchPrompt: Accomplish more with less
Arxiv 2023 [Paper] -
(Dynamic) Prompting might be all you need to repair Compressed LLMs
Arxiv 2023 [Paper] -
RECOMP: Improving Retrieval-Augmented LMs with Compression and Selective Augmentation
Arxiv 2023 [Paper] [Code] -
LongLLMLingua: Accelerating and Enhancing LLMs in Long Context Scenarios via Prompt Compression
ACL 2023 [Paper] [Code] -
Extending Context Window of Large Language Models via Semantic Compression
Arxiv 2023 [Paper] -
Fewer is More: Boosting LLM Reasoning with Reinforced Context Pruning
EMNLP 2024 [Paper] [Code] -
The Impact of Reasoning Step Length on Large Language Models
ACL 2024 Findings [Paper] -
Compressed Context Memory For Online Language Model Interaction
ICLR 2024 [Paper] [Code] -
Learning to Compress Prompt in Natural Language Formats
Arxiv 2024 [Paper] -
Say More with Less: Understanding Prompt Learning Behaviors through Gist Compression
Arxiv 2024 [Paper] [Code] -
StreamingDialogue: Prolonged Dialogue Learning via Long Context Compression with Minimal Losses
Arxiv 2024 [Paper] -
LLMLingua-2: Data Distillation for Efficient and Faithful Task-Agnostic Prompt Compression
Arxiv 2024 [Paper] [Code] -
PCToolkit: A Unified Plug-and-Play Prompt Compression Toolkit of Large Language Models
Arxiv 2024 [Paper] [Code] -
PROMPT-SAW: Leveraging Relation-Aware Graphs for Textual Prompt Compression
Arxiv 2024 [Paper] -
Prompts As Programs: A Structure-Aware Approach to Efficient Compile-Time Prompt Optimization
Arxiv 2024 [Paper] [Code] -
Adapting LLMs for Efficient Context Processing through Soft Prompt Compression
IPCA 2024 [Paper] -
Compressing Long Context for Enhancing RAG with AMR-based Concept Distillation
Arxiv 2024 [Paper] -
Unifying Demonstration Selection and Compression for In-Context Learning
Arxiv 2024 [Paper] -
SelfCP: Compressing Long Prompt to 1/12 Using the Frozen Large Language Model Itself
Arxiv 2024 [Paper] -
Fundamental Limits of Prompt Compression: A Rate-Distortion Framework for Black-Box Language Models
Arxiv 2024 [Paper] -
QUITO: Accelerating Long-Context Reasoning through Query-Guided Context Compression
Arxiv 2024 [Paper] [Code] -
500xCompressor: Generalized Prompt Compression for Large Language Models
Arxiv 2024 [Paper] -
Enhancing and Accelerating Large Language Models via Instruction-Aware Contextual Compression
Arxiv 2024 [Paper] -
Prompt Compression with Context-Aware Sentence Encoding for Fast and Improved LLM Inference
Arxiv 2024 [Paper] [Code] -
Learning to Compress Contexts for Efficient Knowledge-based Visual Question Answering
Arxiv 2024 [Paper] -
Parse Trees Guided LLM Prompt Compression
Arxiv 2024 [Paper] -
AlphaZip: Neural Network-Enhanced Lossless Text Compression
Arxiv 2024 [Paper] -
Discovering the Gems in Early Layers: Accelerating Long-Context LLMs with 1000x Input Token Reduction
Arxiv 2024 [Paper] [Code] -
Perception Compressor:A training-free prompt compression method in long context scenarios
Arxiv 2024 [Paper] -
From Reading to Compressing: Exploring the Multi-document Reader for Prompt Compression
EMNLP Findings 2024 [Paper] [Code] -
Selection-p: Self-Supervised Task-Agnostic Prompt Compression for Faithfulness and Transferability
EMNLP Findings 2024 [Paper] -
Style-Compress: An LLM-Based Prompt Compression Framework Considering Task-Specific Styles
EMNLP Findings 2024 [Paper] -
ICPC: In-context Prompt Compression with Faster Inference
Arxiv 2025 [Paper] -
Efficient Prompt Compression with Evaluator Heads for Long-Context Transformer Inference
Arxiv 2025 [Paper] -
LCIRC: A Recurrent Compression Approach for Efficient Long-form Context and Query Dependent Modeling in LLMs
NAACL 2025 [Paper] -
TokenSkip: Controllable Chain-of-Thought Compression in LLMs
Arxiv 2025 [Paper] -
Task-agnostic Prompt Compression with Context-aware Sentence Embedding and Reward-guided Task Descriptor
Arxiv 2025 [Paper] -
LightThinker: Thinking Step-by-Step Compression
Arxiv 2025 [Paper] [Code] -
BatchGEMBA: Token-Efficient Machine Translation Evaluation with Batched Prompting and Prompt Compression
Arxiv 2025 [Paper] [Code] -
EFPC: Towards Efficient and Flexible Prompt Compression
Arxiv 2025 [Paper] -
KV-Distill: Nearly Lossless Learnable Context Compression for LLMs
Arxiv 2025 [Paper] -
Text Compression for Efficient Language Generation
NAACL Student Research Workshop (SRW) 2025 [Paper] -
Understanding and Improving Information Preservation in Prompt Compression for LLMs
Arxiv 2025 [Paper]
-
Scissorhands: Exploiting the Persistence of Importance Hypothesis for LLM KV Cache Compression at Test Time
NeurIPS 2023 [Paper] -
Model Tells You What to Discard: Adaptive KV Cache Compression for LLMs
ICLR 2024 [Paper] -
KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization
NeurIPS 2024 [Paper] -
KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache
ICML 2024 [Paper] [Code] -
No Token Left Behind: Reliable KV Cache Compression via Importance-Aware Mixed Precision Quantization
Arxiv 2024 [Paper] -
Keyformer: KV Cache Reduction through Key Tokens Selection for Efficient Generative Inference
MLSys 2024 [Paper] -
GEAR: An Efficient KV Cache Compression Recipefor Near-Lossless Generative Inference of LLM
Arxiv 2024 [Paper] -
QAQ: Quality Adaptive Quantization for LLM KV Cache
Arxiv 2024 [Paper] [Code] -
KV Cache is 1 Bit Per Channel: Efficient Large Language Model Inference with Coupled Quantization
Arxiv 2024 [Paper] -
PyramidInfer: Pyramid KV Cache Compression for High-throughput LLM Inference
ACL 2024 [Paper] -
Unlocking Data-free Low-bit Quantization with Matrix Decomposition for KV Cache Compression
Arxiv 2024 [Paper] -
ZipCache: Accurate and Efficient KV Cache Quantization with Salient Token Identification
Arxiv 2024 [Paper] -
MiniCache: KV Cache Compression in Depth Dimension for Large Language Models
Arxiv 2024 [Paper] -
PyramidKV: Dynamic KV Cache Compression based on Pyramidal Information Funneling
Arxiv 2024 [Paper] -
QJL: 1-Bit Quantized JL Transform for KV Cache Quantization with Zero Overhead
Arxiv 2024 [Paper] [Code] -
Effectively Compress KV Heads for LLM
Arxiv 2024 [Paper] -
A Simple and Effective L2 Norm-Based Strategy for KV Cache Compression
EMNLP 2024 [Paper] -
PQCache: Product Quantization-based KVCache for Long Context LLM Inference
Arxiv 2024 [Paper] -
Palu: Compressing KV-Cache with Low-Rank Projection
Arxiv 2024 [Paper] [Code] -
RazorAttention: Efficient KV Cache Compression Through Retrieval Heads
Arxiv 2024 [Paper] -
Finch: Prompt-guided Key-Value Cache Compression
Arxiv 2024 [Paper] -
Zero-Delay QKV Compression for Mitigating KV Cache and Network Bottlenecks in LLM Inference
Arxiv 2024 [Paper] -
Eigen Attention: Attention in Low-Rank Space for KV Cache Compression
EMNLP Findings 2024 [Paper] [Code] -
CSKV: Training-Efficient Channel Shrinking for KV Cache in Long-Context Scenarios
Arxiv 2024 [Paper] [Code] -
LoRC: Low-Rank Compression for LLMs KV Cache with a Progressive Compression Strategy
Arxiv 2024 [Paper] -
SimLayerKV: A Simple Framework for Layer-Level KV Cache Reduction
Arxiv 2024 [Paper] [Code] -
MatryoshkaKV: Adaptive KV Compression via Trainable Orthogonal Projection
Arxiv 2024 [Paper] -
AsymKV: Enabling 1-Bit Quantization of KV Cache with Layer-Wise Asymmetric Quantization Configurations
Arxiv 2024 [Paper] -
Residual vector quantization for KV cache compression in large language model
Arxiv 2024 [Paper] [Code] -
Lossless KV Cache Compression to 2%
Arxiv 2024 [Paper] -
KVSharer: Efficient Inference via Layer-Wise Dissimilar KV Cache Sharing
Arxiv 2024 [Paper] [Code] -
Not All Heads Matter: A Head-Level KV Cache Compression Method with Integrated Retrieval and Reasoning
Arxiv 2024 [Paper] [Code] -
NACL: A General and Effective KV Cache Eviction Framework for LLMs at Inference Time
ACL 2024 [Paper] [Code] -
DHA: Learning Decoupled-Head Attention from Transformer Checkpoints via Adaptive Heads Fusion
NeurIPS 2024 [Paper] -
MiniKV: Pushing the Limits of LLM Inference via 2-Bit Layer-Discriminative KV Cache
Arxiv 2024 [Paper] -
Compressing KV Cache for Long-Context LLM Inference with Inter-Layer Attention Similarity
Arxiv 2024 [Paper] -
Unifying KV Cache Compression for Large Language Models with LeanKV
Arxiv 2024 [Paper] -
ClusterKV: Manipulating LLM KV Cache in Semantic Space for Recallable Compression
Arxiv 2024 [Paper] -
Lexico: Extreme KV Cache Compression via Sparse Coding over Universal Dictionaries
Arxiv 2024 [Paper] [Code] -
ZigZagkv: Dynamic KV Cache Compression for Long-context Modeling based on Layer Uncertainty
Arxiv 2024 [Paper] -
SepLLM: Accelerate Large Language Models by Compressing One Segment into One Separator
Arxiv 2024 [Paper] [Code] -
More Tokens, Lower Precision: Towards the Optimal Token-Precision Trade-off in KV Cache Compression
Arxiv 2024 [Paper] -
SCOPE: Optimizing Key-Value Cache Compression in Long-context Generation
Arxiv 2024 [Paper] [Code] -
DynamicKV: Task-Aware Adaptive KV Cache Compression for Long Context LLMs
Arxiv 2024 [Paper] -
TreeKV: Smooth Key-Value Cache Compression with Tree Structures
Arxiv 2025 [Paper] -
RotateKV: Accurate and Robust 2-Bit KV Cache Quantization for LLMs via Outlier-Aware Adaptive Rotations
Arxiv 2025 [Paper] -
Cache Me If You Must: Adaptive Key-Value Quantization for Large Language Models
Arxiv 2025 [Paper] -
ChunkKV: Semantic-Preserving KV Cache Compression for Efficient Long-Context LLM Inference
Arxiv 2025 [Paper] -
FastKV: KV Cache Compression for Fast Long-Context Processing with Token-Selective Propagation
Arxiv 2025 [Paper] [Code] -
Can LLMs Maintain Fundamental Abilities under KV Cache Compression?
Arxiv 2025 [Paper] -
PolarQuant: Quantizing KV Caches with Polar Transformation
Arxiv 2025 [Paper] -
BalanceKV: KV Cache Compression through Discrepancy Theory
Arxiv 2025 [Paper] -
Unshackling Context Length: An Efficient Selective Attention Approach through Query-Key Compression
Arxiv 2025 [Paper] -
RocketKV: Accelerating Long-Context LLM Inference via Two-Stage KV Cache Compression
Arxiv 2025 [Paper] -
More for Keys, Less for Values: Adaptive KV Cache Quantization
Arxiv 2025 [Paper] [Code] -
SVDq: 1.25-bit and 410x Key Cache Compression for LLM Attention
Arxiv 2025 [Paper] -
DBudgetKV: Dynamic Budget in KV Cache Compression for Ensuring Optimal Performance
Arxiv 2025 [Paper] -
BaKlaVa -- Budgeted Allocation of KV cache for Long-context Inference
Arxiv 2025 [Paper] -
WeightedKV: Attention Scores Weighted Key-Value Cache Merging for Large Language Models
ICASSP 2025 [Paper] -
KVCrush: Key value cache size-reduction using similarity in head-behaviour
Arxiv 2025 [Paper] -
Q-Filters: Leveraging QK Geometry for Efficient KV Cache Compression
Arxiv 2025 [Paper] [Code] -
Beyond RAG: Task-Aware KV Cache Compression for Comprehensive Knowledge Reasoning
Arxiv 2025 [Paper] -
FastCache: Optimizing Multimodal LLM Serving through Lightweight KV-Cache Compression Framework
Arxiv 2025 [Paper] -
LLMs Know What to Drop: Self-Attention Guided KV Cache Eviction for Efficient Long-Context Inference
ICLR 2025 [Paper] -
ZeroMerge: Parameter-Free KV Cache Compression for Memory-Efficient Long-Context LLMs
Arxiv 2025 [Paper] [Code] -
Limits of KV Cache Compression for Tensor Attention based Autoregressive Transformers
Arxiv 2025 [Paper] -
Plug-and-Play 1.x-Bit KV Cache Quantization for Video Large Language Models
Arxiv 2025 [Paper] [Code] -
OmniKV: Dynamic Context Selection for Efficient Long-Context LLMs
ICLR 2025 [Paper] -
WindowKV: Task-Adaptive Group-Wise KV Cache Window Selection for Efficient LLM Inference
Arxiv 2025 [Paper] [Code] -
xKV: Cross-Layer SVD for KV-Cache Compression
Arxiv 2025 [Paper] [Code] -
LogQuant: Log-Distributed 2-Bit Quantization of KV Cache with Superior Accuracy Preservation
ICLR 2025 Workshop on Sparsity in LLMs (SLLM) [Paper] [Code] -
AirCache: Activating Inter-modal Relevancy KV Cache Compression for Efficient Large Vision-Language Model Inference
Arxiv 2025 [Paper] -
Rethinking Key-Value Cache Compression Techniques for Large Language Model Serving
MLSys 2025 [Paper] [Code]
-
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
NeurIPS 2022 [Paper] [Code] -
TensorGPT: Efficient Compression of the Embedding Layer in LLMs based on the Tensor-Train Decomposition
Arxiv 2023 [Paper] -
Dynamic Context Pruning for Efficient and Interpretable Autoregressive Transformers
NeurIPS 2023 [Paper] -
SkipDecode: Autoregressive Skip Decoding with Batching and Caching for Efficient LLM Inference
Arxiv 2023 [Paper] -
Scaling In-Context Demonstrations with Structured Attention
Arxiv 2023 [Paper] -
Response Length Perception and Sequence Scheduling: An LLM-Empowered LLM Inference Pipeline
Arxiv 2023 [Paper] [Code] -
CPET: Effective Parameter-Efficient Tuning for Compressed Large Language Models
Arxiv 2023 [Paper] -
Ternary Singular Value Decomposition as a Better Parameterized Form in Linear Mapping
Arxiv 2023 [Paper] -
LLMCad: Fast and Scalable On-device Large Language Model Inference
Arxiv 2023 [Paper] -
vLLM: Efficient Memory Management for Large Language Model Serving with PagedAttention
Arxiv 2023 [Paper] -
LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models
Arxiv 2023 [Paper] [Code] -
LORD: Low Rank Decomposition Of Monolingual Code LLMs For One-Shot Compression
Arxiv 2023 [Paper] [Code] -
Mixture of Tokens: Efficient LLMs through Cross-Example Aggregation
Arxiv 2023 [Paper] -
Efficient Streaming Language Models with Attention Sinks
Arxiv 2023 [Paper] [Code] -
Efficient Large Language Models Fine-Tuning On Graphs
Arxiv 2023 [Paper] -
SparQ Attention: Bandwidth-Efficient LLM Inference
Arxiv 2023 [Paper] -
Rethinking Compression: Reduced Order Modelling of Latent Features in Large Language Models
Arxiv 2023 [Paper] -
PowerInfer: Fast Large Language Model Serving with a Consumer-grade GPU
Arxiv 2023 [Paper] [Code] -
Text Alignment Is An Efficient Unified Model for Massive NLP Tasks
NeurIPS 2023 [Paper] [Code] -
Context Compression for Auto-regressive Transformers with Sentinel Tokens
EMNLP 2023 [Paper] [Code] -
TCRA-LLM: Token Compression Retrieval Augmented Large Language Model for Inference Cost Reduction
EMNLP Findings 2023 [Paper] -
Retrieval-based Knowledge Transfer: An Effective Approach for Extreme Large Language Model Compression
EMNLP Findings 2023 [Paper] -
FFSplit: Split Feed-Forward Network For Optimizing Accuracy-Efficiency Trade-off in Language Model Inference
Arxiv 2024 [Paper] -
LoMA: Lossless Compressed Memory Attention
Arxiv 2024 [Paper] -
Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads
Arxiv 2024 [Paper] [Code] -
BiTA: Bi-Directional Tuning for Lossless Acceleration in Large Language Models
Arxiv 2024 [Paper] [Code] -
CompactifAI: Extreme Compression of Large Language Models using Quantum-Inspired Tensor Networks
Arxiv 2024 [Paper] -
MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases
ICML 2024 [Paper] [Code] -
BAdam: A Memory Efficient Full Parameter Training Method for Large Language Models
Arxiv 2024 [Paper] [Code] -
NoMAD-Attention: Efficient LLM Inference on CPUs Through Multiply-add-free Attention
Arxiv 2024 [Paper] -
Not all Layers of LLMs are Necessary during Inference
Arxiv 2024 [Paper] -
GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection
Arxiv 2024 [Paper] -
Dynamic Memory Compression: Retrofitting LLMs for Accelerated Inference
Arxiv 2024 [Paper] -
Smart-Infinity: Fast Large Language Model Training using Near-Storage Processing on a Real System
HPCA 2024 [Paper] -
ALoRA: Allocating Low-Rank Adaptation for Fine-tuning Large Language Models
Arxiv 2024 [Paper] -
SVD-LLM: Truncation-aware Singular Value Decomposition for Large Language Model Compression
ICLR 2025 [Paper] [Code] -
Parameter Efficient Quasi-Orthogonal Fine-Tuning via Givens Rotation
Arxiv 2024 [Paper] -
Training LLMs over Neurally Compressed Text
Arxiv 2024 [Paper] -
TriForce: Lossless Acceleration of Long Sequence Generation with Hierarchical Speculative Decoding
Arxiv 2024 [Paper] [Code] -
SnapKV: LLM Knows What You are Looking for Before Generation
Arxiv 2024 [Paper] [Code] -
Characterizing the Accuracy - Efficiency Trade-off of Low-rank Decomposition in Language Models
Arxiv 2024 [Paper] -
KV-Runahead: Scalable Causal LLM Inference by Parallel Key-Value Cache Generation
ICML 2024 [Paper] -
Token-wise Influential Training Data Retrieval for Large Language Models
ACL 2024 [Paper] [Code] -
Basis Selection: Low-Rank Decomposition of Pretrained Large Language Models for Target Applications
Arxiv 2024 [Paper] -
Demystifying the Compression of Mixture-of-Experts Through a Unified Framework
Arxiv 2024 [Paper] [Code] -
LazyLLM: Dynamic Token Pruning for Efficient Long Context LLM Inference
Arxiv 2024 [Paper] -
AdaCoder: Adaptive Prompt Compression for Programmatic Visual Question Answering
Arxiv 2024 [Paper] -
CaM: Cache Merging for Memory-efficient LLMs Inference
ICML 2024 [Paper] [Code] -
CLLMs: Consistency Large Language Models
ICML 2024 [Paper] [Code] -
MoDeGPT: Modular Decomposition for Large Language Model Compression
Arxiv 2024 [Paper] -
Accelerating Large Language Model Training with Hybrid GPU-based Compression
Arxiv 2024 [Paper] -
Language Models as Zero-shot Lossless Gradient Compressors: Towards General Neural Parameter Prior Models
NeurIPS 2024 [Paper] -
KV-Compress: Paged KV-Cache Compression with Variable Compression Rates per Attention Head
Arxiv 2024 [Paper] -
InfiniPot: Infinite Context Processing on Memory-Constrained LLMs
EMNLP 2024 [Paper] -
SageAttention: Accurate 8-Bit Attention for Plug-and-play Inference Acceleration
Arxiv 2024 [Paper] [Code] -
UNComp: Uncertainty-Aware Long-Context Compressor for Efficient Large Language Model Inference
Arxiv 2024 [Paper] -
Basis Sharing: Cross-Layer Parameter Sharing for Large Language Model Compression
Arxiv 2024 [Paper] [Code] -
Rodimus*: Breaking the Accuracy-Efficiency Trade-Off with Efficient Attentions
Arxiv 2024 [Paper] -
DuoAttention: Efficient Long-Context LLM Inference with Retrieval and Streaming Heads
Arxiv 2024 [Paper] [Code] -
Progressive Mixed-Precision Decoding for Efficient LLM Inference
Arxiv 2024 [Paper] -
EoRA: Training-free Compensation for Compressed LLM with Eigenspace Low-Rank Approximation
Arxiv 2024 [Paper] -
LLMCBench: Benchmarking Large Language Model Compression for Efficient Deployment
NeurIPS 2024 Datasets and Benchmarks Track [Paper] [Code] -
NeuZip: Memory-Efficient Training and Inference with Dynamic Compression of Neural Networks
Arxiv 2024 [paper] [Code] -
BitStack: Any-Size Compression of Large Language Models in Variable Memory Environments
ICLR 2025 [Paper] [Code] -
LLM Vocabulary Compression for Low-Compute Environments
Machine Learning and Compression Workshop @ NeurIPS 2024 [paper] -
SWSC: Shared Weight for Similar Channel in LLM
Arxiv 2025 [paper] -
Sigma: Differential Rescaling of Query, Key and Value for Efficient Language Models
Arxiv 2025 [paper] -
FlexiGPT: Pruning and Extending Large Language Models with Low-Rank Weight Sharing
NAACL 2025 [paper] -
AdaSVD: Adaptive Singular Value Decomposition for Large Language Models
Arxiv 2025 [paper] [Code] -
HASSLE-free: A unified Framework for Sparse plus Low-Rank Matrix Decomposition for LLMs
Arxiv 2025 [paper] -
Choose Your Model Size: Any Compression by a Single Gradient Descent
Arxiv 2025 [paper] -
Delta Decompression for MoE-based LLMs Compression
Arxiv 2025 [paper] [Code] -
ByteScale: Efficient Scaling of LLM Training with a 2048K Context Length on More Than 12,000 GPUs
Arxiv 2025 [paper] -
SVD-LLM V2: Optimizing Singular Value Truncation for Large Language Model Compression
NAACL 2025 [paper] [Code] -
Large Language Model Compression via the Nested Activation-Aware Decomposition
Arxiv 2025 [paper] -
PromptDistill: Query-based Selective Token Retention in Intermediate Layers for Efficient Large Language Model Inference
Arxiv 2025 [paper] [Code] -
When Reasoning Meets Compression: Benchmarking Compressed Large Reasoning Models on Complex Reasoning Tasks
Arxiv 2025 [Paper]
-
BMCook: Model Compression for Big Models [Code]
-
llama.cpp: Inference of LLaMA model in pure C/C++ [Code]
-
LangChain: Building applications with LLMs through composability [Code]
-
GPTQ-for-LLaMA: 4 bits quantization of LLaMA using GPTQ [Code]
-
Alpaca-CoT: An Instruction Fine-Tuning Platform with Instruction Data Collection and Unified Large Language Models Interface [Code]
-
vllm: A high-throughput and memory-efficient inference and serving engine for LLMs [Code]
-
LLaMA Efficient Tuning: Fine-tuning LLaMA with PEFT (PT+SFT+RLHF with QLoRA) [Code]
-
gpt-fast: Simple and efficient pytorch-native transformer text generation in <1000 LOC of python. [Code]
-
Efficient-Tuning-LLMs: (Efficient Finetuning of QLoRA LLMs). QLoRA, LLama, bloom, baichuan-7B, GLM [Code]
-
bitsandbytes: 8-bit CUDA functions for PyTorch [Code]
-
ExLlama: A more memory-efficient rewrite of the HF transformers implementation of Llama for use with quantized weights. [Code]
-
lit-gpt: Hackable implementation of state-of-the-art open-source LLMs based on nanoGPT. Supports flash attention, 4-bit and 8-bit quantization, LoRA and LLaMA-Adapter fine-tuning, pre-training. [Code]
-
Lit-LLaMA: Implementation of the LLaMA language model based on nanoGPT. Supports flash attention, Int8 and GPTQ 4bit quantization, LoRA and LLaMA-Adapter fine-tuning, pre-training. [Code]
-
lama.onnx: LLaMa/RWKV onnx models, quantization and testcase [Code]
-
fastLLaMa: An experimental high-performance framework for running Decoder-only LLMs with 4-bit quantization in Python using a C/C++ backend. [Code]
-
Sparsebit: A model compression and acceleration toolbox based on pytorch. [Code]
-
llama2.c: Inference Llama 2 in one file of pure C [Code]
-
Megatron-LM: Ongoing research training transformer models at scale [Code]
-
ggml: Tensor library for machine learning [Code]
-
LLamaSharp: C#/.NET binding of llama.cpp, including LLaMa/GPT model inference and quantization, ASP.NET core integration and UI [Code]
-
rwkv.cpp: NT4/INT5/INT8 and FP16 inference on CPU for RWKV language model [Code]
-
Can my GPU run this LLM?: Calculate GPU memory requirement & breakdown for training/inference of LLM models. Supports ggml/bnb quantization [Code]
-
TinyChatEngine: On-Device LLM Inference Library [Code]
-
TensorRT-LLM: TensorRT-LLM provides users with an easy-to-use Python API to define Large Language Models (LLMs) and build TensorRT engines that contain state-of-the-art optimizations to perform inference efficiently on NVIDIA GPUs. [Code]
-
IntLLaMA: A fast and light quantization solution for LLaMA [Code]
-
EasyLLM: Built upon Megatron-Deepspeed and HuggingFace Trainer, EasyLLM has reorganized the code logic with a focus on usability. While enhancing usability, it also ensures training efficiency [Code]
-
GreenBit LLaMA: Advanced Ultra-Low Bitrate Compression Techniques for the LLaMA Family of LLMs [Code]
-
Intel® Neural Compressor: An open-source Python library supporting popular model compression techniques on all mainstream deep learning frameworks (TensorFlow, PyTorch, ONNX Runtime, and MXNet) [Code]
-
LLM-Viewer: Analyze the inference of Large Language Models (LLMs). Analyze aspects like computation, storage, transmission, and hardware roofline model in a user-friendly interface. [Code]
-
LLaMA3-Quantization: A repository dedicated to evaluating the performance of quantizied LLaMA3 using various quantization methods. [Code]
-
LLamaSharp: A C#/.NET library to run LLM models (🦙LLaMA/LLaVA) on your local device efficiently. [Code]
-
Green-bit-LLM: A toolkit for fine-tuning, inferencing, and evaluating GreenBitAI's LLMs. [Code] [Model]
-
Bitorch Engine: Streamlining AI with Open-Source Low-Bit Quantization. [Code]
-
llama-zip: LLM-powered lossless compression tool [Code]
-
LLaMA-Factory: Unify Efficient Fine-Tuning of 100+ LLMs [Code]
-
LLMC: A tool designed for LLM Compression. [Code]
-
BitBLAS: BitBLAS is a library to support mixed-precision matrix multiplications, especially for quantized LLM deployment. [Code]
-
AutoFP8: Open-source FP8 quantization library for producing compressed checkpoints for running in vLLM [Code]
-
AutoGGUF: automatically quant GGUF models [Code]
-
Transformer Compression: For releasing code related to compression methods for transformers, accompanying our publications [Code]
-
Electron-BitNet: Running Microsoft's BitNet via Electron [Code]
-
FastAPI-BitNet: a combination of Uvicorn, FastAPI (Python) and Docker to provide a reliable REST API for testing Microsoft's BitNet out locally [Code]
-
kvpress: LLM KV cache compression made easy [Code]
This is an active repository and your contributions are always welcome! Before you add papers/tools into the awesome list, please make sure that:
- The paper or tools is related to Large Language Models (LLMs). If the compression algorithms or tools are only evaluated on small-scale language models (e.g., BERT), they should not be included in the list.
- The paper should be inserted in the correct position in chronological order (publication/arxiv release time).
- The link to [Paper] should be the arxiv page, not the pdf page if this is a paper posted on arxiv.
- If the paper is accpeted, please use the correct publication venue instead of arxiv
Thanks again for all the awesome contributors to this list!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Awesome-LLM-Compression
Similar Open Source Tools
Awesome-LLM-Compression
Awesome LLM compression research papers and tools to accelerate LLM training and inference.
Efficient-LLMs-Survey
This repository provides a systematic and comprehensive review of efficient LLMs research. We organize the literature in a taxonomy consisting of three main categories, covering distinct yet interconnected efficient LLMs topics from **model-centric** , **data-centric** , and **framework-centric** perspective, respectively. We hope our survey and this GitHub repository can serve as valuable resources to help researchers and practitioners gain a systematic understanding of the research developments in efficient LLMs and inspire them to contribute to this important and exciting field.

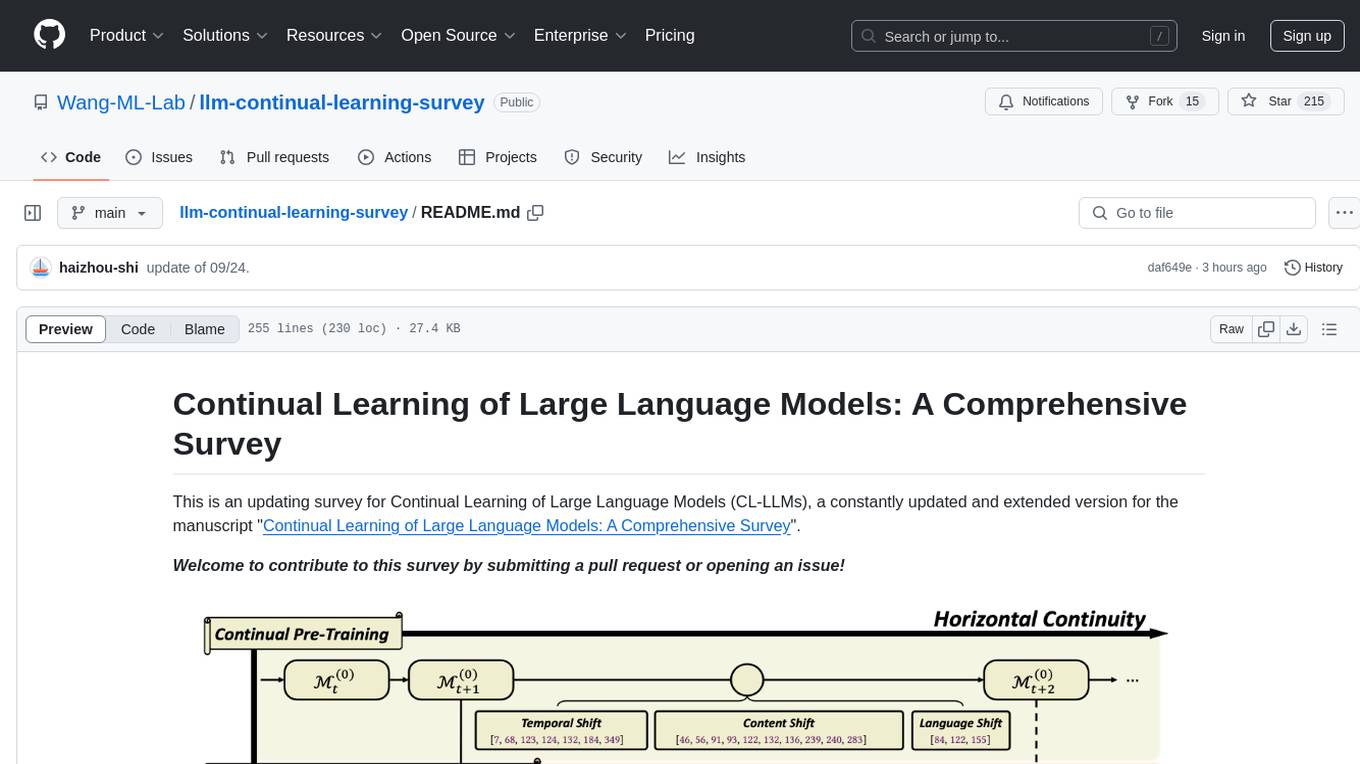
llm-continual-learning-survey
This repository is an updating survey for Continual Learning of Large Language Models (CL-LLMs), providing a comprehensive overview of various aspects related to the continual learning of large language models. It covers topics such as continual pre-training, domain-adaptive pre-training, continual fine-tuning, model refinement, model alignment, multimodal LLMs, and miscellaneous aspects. The survey includes a collection of relevant papers, each focusing on different areas within the field of continual learning of large language models.

Awesome-LLMs-on-device
Welcome to the ultimate hub for on-device Large Language Models (LLMs)! This repository is your go-to resource for all things related to LLMs designed for on-device deployment. Whether you're a seasoned researcher, an innovative developer, or an enthusiastic learner, this comprehensive collection of cutting-edge knowledge is your gateway to understanding, leveraging, and contributing to the exciting world of on-device LLMs.
AwesomeLLM4APR
Awesome LLM for APR is a repository dedicated to exploring the capabilities of Large Language Models (LLMs) in Automated Program Repair (APR). It provides a comprehensive collection of research papers, tools, and resources related to using LLMs for various scenarios such as repairing semantic bugs, security vulnerabilities, syntax errors, programming problems, static warnings, self-debugging, type errors, web UI tests, smart contracts, hardware bugs, performance bugs, API misuses, crash bugs, test case repairs, formal proofs, GitHub issues, code reviews, motion planners, human studies, and patch correctness assessments. The repository serves as a valuable reference for researchers and practitioners interested in leveraging LLMs for automated program repair.
Awesome-LLM4RS-Papers
This paper list is about Large Language Model-enhanced Recommender System. It also contains some related works. Keywords: recommendation system, large language models
awesome-llm-understanding-mechanism
This repository is a collection of papers focused on understanding the internal mechanism of large language models (LLM). It includes research on topics such as how LLMs handle multilingualism, learn in-context, and handle factual associations. The repository aims to provide insights into the inner workings of transformer-based language models through a curated list of papers and surveys.
Awesome-LLM-Post-training
The Awesome-LLM-Post-training repository is a curated collection of influential papers, code implementations, benchmarks, and resources related to Large Language Models (LLMs) Post-Training Methodologies. It covers various aspects of LLMs, including reasoning, decision-making, reinforcement learning, reward learning, policy optimization, explainability, multimodal agents, benchmarks, tutorials, libraries, and implementations. The repository aims to provide a comprehensive overview and resources for researchers and practitioners interested in advancing LLM technologies.
Awesome-LLM4Graph-Papers
A collection of papers and resources about Large Language Models (LLM) for Graph Learning (Graph). Integrating LLMs with graph learning techniques to enhance performance in graph learning tasks. Categorizes approaches based on four primary paradigms and nine secondary-level categories. Valuable for research or practice in self-supervised learning for recommendation systems.
Awesome_Mamba
Awesome Mamba is a curated collection of groundbreaking research papers and articles on Mamba Architecture, a pioneering framework in deep learning known for its selective state spaces and efficiency in processing complex data structures. The repository offers a comprehensive exploration of Mamba architecture through categorized research papers covering various domains like visual recognition, speech processing, remote sensing, video processing, activity recognition, image enhancement, medical imaging, reinforcement learning, natural language processing, 3D recognition, multi-modal understanding, time series analysis, graph neural networks, point cloud analysis, and tabular data handling.
awesome-ai4db-paper
The 'awesome-ai4db-paper' repository is a curated paper list focusing on AI for database (AI4DB) theory, frameworks, resources, and tools for data engineers. It includes a collection of research papers related to learning-based query optimization, training data set preparation, cardinality estimation, query-driven approaches, data-driven techniques, hybrid methods, pretraining models, plan hints, cost models, SQL embedding, join order optimization, query rewriting, end-to-end systems, text-to-SQL conversion, traditional database technologies, storage solutions, learning-based index design, and a learning-based configuration advisor. The repository aims to provide a comprehensive resource for individuals interested in AI applications in the field of database management.

LLM-Tool-Survey
This repository contains a collection of papers related to tool learning with large language models (LLMs). The papers are organized according to the survey paper 'Tool Learning with Large Language Models: A Survey'. The survey focuses on the benefits and implementation of tool learning with LLMs, covering aspects such as task planning, tool selection, tool calling, response generation, benchmarks, evaluation, challenges, and future directions in the field. It aims to provide a comprehensive understanding of tool learning with LLMs and inspire further exploration in this emerging area.

Awesome-Text2SQL
Awesome Text2SQL is a curated repository containing tutorials and resources for Large Language Models, Text2SQL, Text2DSL, Text2API, Text2Vis, and more. It provides guidelines on converting natural language questions into structured SQL queries, with a focus on NL2SQL. The repository includes information on various models, datasets, evaluation metrics, fine-tuning methods, libraries, and practice projects related to Text2SQL. It serves as a comprehensive resource for individuals interested in working with Text2SQL and related technologies.
Awesome-LLM-Survey
This repository, Awesome-LLM-Survey, serves as a comprehensive collection of surveys related to Large Language Models (LLM). It covers various aspects of LLM, including instruction tuning, human alignment, LLM agents, hallucination, multi-modal capabilities, and more. Researchers are encouraged to contribute by updating information on their papers to benefit the LLM survey community.
Awesome-RL-based-LLM-Reasoning
This repository is dedicated to enhancing Language Model (LLM) reasoning with reinforcement learning (RL). It includes a collection of the latest papers, slides, and materials related to RL-based LLM reasoning, aiming to facilitate quick learning and understanding in this field. Starring this repository allows users to stay updated and engaged with the forefront of RL-based LLM reasoning.
For similar tasks
Awesome-LLM-Compression
Awesome LLM compression research papers and tools to accelerate LLM training and inference.

maxtext
MaxText is a high-performance, highly scalable, open-source LLM written in pure Python/Jax and targeting Google Cloud TPUs and GPUs for training and inference. MaxText achieves high MFUs and scales from single host to very large clusters while staying simple and "optimization-free" thanks to the power of Jax and the XLA compiler. MaxText aims to be a launching off point for ambitious LLM projects both in research and production. We encourage users to start by experimenting with MaxText out of the box and then fork and modify MaxText to meet their needs.

swift
SWIFT (Scalable lightWeight Infrastructure for Fine-Tuning) supports training, inference, evaluation and deployment of nearly **200 LLMs and MLLMs** (multimodal large models). Developers can directly apply our framework to their own research and production environments to realize the complete workflow from model training and evaluation to application. In addition to supporting the lightweight training solutions provided by [PEFT](https://github.com/huggingface/peft), we also provide a complete **Adapters library** to support the latest training techniques such as NEFTune, LoRA+, LLaMA-PRO, etc. This adapter library can be used directly in your own custom workflow without our training scripts. To facilitate use by users unfamiliar with deep learning, we provide a Gradio web-ui for controlling training and inference, as well as accompanying deep learning courses and best practices for beginners. Additionally, we are expanding capabilities for other modalities. Currently, we support full-parameter training and LoRA training for AnimateDiff.
ipex-llm
IPEX-LLM is a PyTorch library for running Large Language Models (LLMs) on Intel CPUs and GPUs with very low latency. It provides seamless integration with various LLM frameworks and tools, including llama.cpp, ollama, Text-Generation-WebUI, HuggingFace transformers, and more. IPEX-LLM has been optimized and verified on over 50 LLM models, including LLaMA, Mistral, Mixtral, Gemma, LLaVA, Whisper, ChatGLM, Baichuan, Qwen, and RWKV. It supports a range of low-bit inference formats, including INT4, FP8, FP4, INT8, INT2, FP16, and BF16, as well as finetuning capabilities for LoRA, QLoRA, DPO, QA-LoRA, and ReLoRA. IPEX-LLM is actively maintained and updated with new features and optimizations, making it a valuable tool for researchers, developers, and anyone interested in exploring and utilizing LLMs.
llm-twin-course
The LLM Twin Course is a free, end-to-end framework for building production-ready LLM systems. It teaches you how to design, train, and deploy a production-ready LLM twin of yourself powered by LLMs, vector DBs, and LLMOps good practices. The course is split into 11 hands-on written lessons and the open-source code you can access on GitHub. You can read everything and try out the code at your own pace.
Awesome-LLM-Inference
Awesome-LLM-Inference: A curated list of 📙Awesome LLM Inference Papers with Codes, check 📖Contents for more details. This repo is still updated frequently ~ 👨💻 Welcome to star ⭐️ or submit a PR to this repo!
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.