
AwesomeLLM4APR
A Systematic Literature Review on Large Language Models for Automated Program Repair
Stars: 88
Awesome LLM for APR is a repository dedicated to exploring the capabilities of Large Language Models (LLMs) in Automated Program Repair (APR). It provides a comprehensive collection of research papers, tools, and resources related to using LLMs for various scenarios such as repairing semantic bugs, security vulnerabilities, syntax errors, programming problems, static warnings, self-debugging, type errors, web UI tests, smart contracts, hardware bugs, performance bugs, API misuses, crash bugs, test case repairs, formal proofs, GitHub issues, code reviews, motion planners, human studies, and patch correctness assessments. The repository serves as a valuable reference for researchers and practitioners interested in leveraging LLMs for automated program repair.
README:


- 👏 Citation
- 💡 Repair Scenarios
- 🙆 Human Study
- 🙅 Patch Correctness Assessment
- 📊 Benchmark
- 🤔 Related APR Surveys
@article{zhang2024survey,
title={A Systematic Literature Review on Large Language Models for Automated Program Repair},
author={Zhang, Quanjun and Fang, Chunrong and Xie, Yang and Ma, Yuxiang and Sun, Weisong and Yang, Yun and Chen, Zhenyu},
journal={arXiv preprint arXiv:2405.01466}
year={2024}
}
- [ ] add SE agent-based studies for GitHub Issues
- [ ] add ISSTA 2024 Papers
- 🔥Exploring and Lifting the Robustness of LLM-powered Automated Program Repair with Metamorphic Testing[2024-arXiv] [paper]
- Divide-and-Conquer: Automating Code Revisions via Localization-and-Revision [2024-TOSEM]
- From Code to Correctness: Closing the Last Mile of Code Generation with Hierarchical Debugging [2024-arXiv] [paper] [repo]
- Automated Program Repair for Introductory Programming Assignments [2024-TLT] [paper]
- Automated Repair of AI Code with Large Language Models and Formal Verification [2024-arXiv] [paper]
- CraftRTL: High-quality Synthetic Data Generation for Verilog Code Models with Correct-by-Construction Non-Textual Representations and Targeted Code Repair [2024-arXiv-NVIDIA] [paper]
- Benchmarking Automated Program Repair: An Extensive Study on Both Real-World and Artificial Bugs [2024-ISSTA] [paper]
- Automated program repair via conversation: Fixing 162 out of 337 bugs for $0.42 each using chatgpt[2024-ISSTA] [paper]
- Leveraging Large Language Model for Automatic Patch Correctness Assessment[2024-TSE] [paper]
- Automated program repair for variability bugs in software product line systems[2024-JSS] [paper]
- PyBugHive: A Comprehensive Database of Manually Validated, Reproducible Python Bugs[2024-IEEE Access] [paper]
- 🔥Automated program repair for variability bugs in software product line systems[2024-JSS] [paper]
- 🔥A Unified Debugging Approach via LLM-Based Multi-Agent Synergy [2024-arxiv] [paper] [repo]
- 🔥How Far Can We Go with Practical Function-Level Program Repair? [2024-arxiv] [paper] [repo]
- 🔥Automated program repair via conversation: Fixing 162 out of 337 bugs for $0.42 each using chatgpt[2024-ISSTA] [paper]
Old Version: Keep the Conversation Going: Fixing 162 out of 337 bugs for $0.42 each using ChatGPT [2023-arxiv] [paper] - A Novel Approach for Automatic Program Repair using Round-Trip Translation with Large Language Models [2024-arxiv] [paper] [repo]
- Out of Context: How important is Local Context in Neural Program Repair? [2024-ICSE] [paper] [repo]
- Multi-Objective Fine-Tuning for Enhanced Program Repair with LLMs [2024-arxiv] [paper]
- Aligning LLMs for FL-free Program Repair [2024-arxiv] [paper]
- ContrastRepair: Enhancing Conversation-Based Automated Program Repair via Contrastive Test Case Pairs [2024-arxiv] [paper]
- Exploring the Potential of Pre-Trained Language Models of Code for Automated Program Repair [2024-Electronics] [paper]
- CigaR: Cost-efficient Program Repair with LLMs [2024-arxiv] [paper] [repo]
- The Fact Selection Problem in LLM-Based Program Repair [2024-arxiv] [paper] [repo]
- A Novel Approach for Automated Program Repair using Round-Trip Translation with Large Language Models [2024-arxiv] [paper] [repo]
- RepairAgent: An Autonomous, LLM-Based Agent for Program Repair [2024-arxiv] [paper]
- A Deep Dive into Large Language Models for Automated Bug Localization and Repair [2024-FSE/ESEC] [paper]
- Automated Program Repair in the Era of Large Pre-trained Language Models [2023-ICSE] [paper] [repo]
- Repair Is Nearly Generation: Multilingual Program Repair with LLMs [2023-AAAI] [paper]
- Retrieval-based prompt selection for code-related few-shot learning [2023-ICSE] [paper] [repo]
- What makes good in-context demonstrations for code intelligence tasks with llms? [2023-ASE] [paper] [repo]
- Fully Autonomous Programming with Large Language Models [2023-GECCO] [paper] [repo]
- Automated Program Repair Using Generative Models for Code Infilling [2023-AIED] [paper] [repo]
- STEAM: Simulating the InTeractive BEhavior of ProgrAMmers for Automatic Bug Fixing [2023-arxiv] [paper]
- Conversational automated program repair [2023-arxiv] [paper]
- Is ChatGPT the Ultimate Programming Assistant--How far is it? [2023-arxiv] [paper] [repo]
- Using Large Language Models for Bug Localization and Fixing [2023-iCAST] [paper]
- An Empirical Study on Fine-Tuning Large Language Models of Code for Automated Program Repair [2023-ASE] [paper] [repo]
- An Evaluation of the Effectiveness of OpenAI's ChatGPT for Automated Python Program Bug Fixing using QuixBugs [2023-iSEMANTIC] [paper]
- Explainable Automated Debugging via Large Language Model-driven Scientific Debugging [2023-arxiv] [paper]
- The Right Prompts for the Job: Repair Code-Review Defects with Large Language Model [2023-arxiv] [paper]
- Impact of Code Language Models on Automated Program Repair [2023-ICSE] [paper] [repo]
- Towards Generating Functionally Correct Code Edits from Natural Language Issue Descriptions [2023-arxiv] [paper]
- The Plastic Surgery Hypothesis in the Era of Large Language Models [2023-ASE] [paper] [repo]
- Exploring the Limits of ChatGPT in Software Security Applications [2023-arxiv] [paper]
- CodeScope: An Execution-based Multilingual Multitask Multidimensional Benchmark for Evaluating LLMs on Code Understanding and Generation [2023-arxiv] [paper] [repo]
- Enhancing Automated Program Repair through Fine-tuning and Prompt Engineering [2023-arxiv] [paper] [repo]
- Training Language Models for Programming Feedback Using Automated Repair Tools [2023-AIED] [paper] [repo]
- RepairLLaMA: Efficient Representations and Fine-Tuned Adapters for Program Repair [2023-arxiv] [paper] [repo]
- Automated Code Editing with Search-Generate-Modify [2023-arxiv] [paper] [repo]
- RAP-Gen: Retrieval-Augmented Patch Generation with CodeT5 for Automatic Program Repair [2023-FSE/ESEC] [paper] [repo]
- Neural Program Repair with Program Dependence Analysis and Effective Filter Mechanism [2023-arxiv] [paper]
- Coffee: Boost Your Code LLMs by Fixing Bugs with Feedback [2023-arxiv] [paper] [repo]
- A study on Prompt Design, Advantages and Limitations of ChatGPT for Deep Learning Program Repair [2023-arxiv] [paper]
- Copiloting the Copilots: Fusing Large Language Models with Completion Engines for Automated Program Repair [2023-FSE/ESEC] [paper] [repo]
- Gamma: Revisiting Template-Based Automated Program Repair Via Mask Prediction [2023-ASE] [paper] [repo]
- An Extensive Study on Model Architecture and Program Representation in the Domain of Learning-based Automated Program Repair [2023-APR] [paper] [repo]
- Improving Automated Program Repair with Domain Adaptation [2023-TOSEM] [paper] [repo]
- Enhancing Code Language Models for Program Repair by Curricular Fine-tuning Framework [2023-ICSME] [paper]
- The potential use of ChatGPT for debugging and bug fixing [2023-] [paper]
- CIRCLE: Continual Repair across Programming Languages [2022-ISSTA] [paper] [repo]
- Towards JavaScript program repair with Generative Pre-trained Transformer (GPT-2) [2022-APR] [paper] [repo]
- Fix Bugs with Transformer through a Neural-Symbolic Edit Grammar [2022-ICLR] [paper]
- Patch Generation with Language Models: Feasibility and Scaling Behavior [2022-ICLR] [paper]
- Can OpenAI's codex fix bugs?: an evaluation on QuixBugs [2022-APR] [paper]
- An Analysis of the Automatic Bug Fixing Performance of ChatGPT [2022-APR] [paper] [repo]
- Less training, more repairing please: revisiting automated program repair via zero-shot learning [2022-FSE/ESEC] [paer] [repo]
- Framing Program Repair as Code Completion [2022-APR] [paper] [repo]
- DEAR A Novel Deep Learning-based Approach for Automated Program Repair [2022-ICSE] [paper] [repo]
- Generating Bug-Fixes Using Pretrained Transformers [2021-PLDI] [paper]
- Applying CodeBERT for Automated Program Repair of Java Simple Bugs [2021-MSR] [paper] [repo]
- CURE Code-Aware Neural Machine Translation for Automatic Program Repair [2021-ICSE] [paper] [repo]
-
🔥Automated Repair of AI Code with Large Language Models and Formal Verification [2024-arXiv] [paper]
-
🔥NAVRepair: Node-type Aware C/C++ Code Vulnerability Repair [2024-arxiv] [paper]
-
Enhanced Automated Code Vulnerability Repair using Large Language Models [2024-arxiv] [paper]
-
Out of Sight, Out of Mind: Better Automatic Vulnerability Repair by Broadening Input Ranges and Sources [2024-ICSE] [paper] [repo]
-
A Study of Vulnerability Repair in JavaScript Programs with Large Language Models [2024-arxiv] [paper] [repo]
-
Chain-of-Thought Prompting of Large Language Models for Discovering and Fixing Software Vulnerabilities [2024-arxiv] [paper]
-
Pre-trained Model-based Automated Software Vulnerability Repair: How Far are We? [2023-TDSC] [paper] [repo]
-
Examining zero-shot vulnerability repair with large language models [2023-S&P] [paper] [repo]
-
An Empirical Study on Fine-Tuning Large Language Models of Code for Automated Program Repair [2023-ASE] [paper] [repo]
-
A New Era in Software Security: Towards Self-Healing Software via Large Language Models and Formal Verification [2023-arxiv] [paper]
-
Exploring the Limits of ChatGPT in Software Security Applications [2023-arxiv] [paper]
-
ZeroLeak: Using LLMs for Scalable and Cost Effective Side-Channel Patching [2023-arxiv] [paper]
-
How ChatGPT is Solving Vulnerability Management Problem [2023-arxiv] [paper] [repo]
-
How Effective Are Neural Networks for Fixing Security Vulnerabilities [2023-ISSTA] [paper] [repo]
-
Vision Transformer-Inspired Automated Vulnerability Repair [2023-TOSEM] [paper] [repo]
-
Can large language models find and fix vulnerable software? [2023-arxiv] [paper]
-
VulRepair: A T5-Based Automated Software Vulnerability Repair [2022-FSE/ESEC] [paper] [repo]
- A Novel Approach for Automated Program Repair using Round-Trip Translation with Large Language Models [2024-arxiv] [paper] [repo]
- Repair Is Nearly Generation: Multilingual Program Repair with LLMs [2023-AAAI] [paper]
- Fixing Rust Compilation Errors using LLMs [2023-arxiv] [paper]
- An Empirical Study on Fine-Tuning Large Language Models of Code for Automated Program Repair [2023-ASE] [paper] [repo]
- A Chain of AI-based Solutions for Resolving FQNs and Fixing Syntax Errors in Partial Code [2023-arxiv] [paper] [repo]
- The Right Prompts for the Job: Repair Code-Review Defects with Large Language Model [2023-arxiv] [paper]
- SYNSHINE: improved fixing of Syntax Errors [2022-TSE] [paper] [repo]
- 🔥CraftRTL: High-quality Synthetic Data Generation for Verilog Code Models with Correct-by-Construction Non-Textual Representations and Targeted Code Repair [2024-arXiv-NVIDIA] [paper]
- A Unified Debugging Approach via LLM-Based Multi-Agent Synergy [2024-arXiv] [paper] [repo]
- PyDex: Repairing Bugs in Introductory Python Assignments using LLMs [2024-OOPSLA] [paper] [repo]
- DebugBench: Evaluating Debugging Capability of Large Language Models [2024-arxiv] [paper] [repo]
- ContrastRepair: Enhancing Conversation-Based Automated Program Repair via Contrastive Test Case Pairs [2024-arxiv] [paper]
- ConDefects: A New Dataset to Address the Data Leakage Concern for LLM-based Fault Localization and Program Repair [2024-arxiv] [paper] [repo]
- Peer-aided Repairer: Empowering Large Language Models to Repair Advanced Student Assignments [2024-arxiv] [paper]
- Improved Program Repair Methods using Refactoring with GPT Models [2024-SIGCSE TS] [paper] [repo]
- A critical review of large language model on software engineering: An example from chatgpt and automated program repair [2023-arxiv] [paper] [repo]
- Automated Repair of Programs from Large Language Models [2023-ICSE] [paper] [repo]
- FixEval: Execution-based Evaluation of Program Fixes for Programming Problems [2023-APR] [paper] [repo]
- Refining ChatGPT-Generated Code: Characterizing and Mitigating Code Quality Issues [2023-TOSEM] [paper] [repo]
- Repairing bugs in python assignments using large language models [2022-arixv] [paper]
- Frustrated with Code Quality Issues? LLMs can Help! [2024-FSE/ESEC] [paper] [repo]
- SkipAnalyzer: An Embodied Agent for Code Analysis with Large Language Models [2023-arxiv] [paper] [repo]
- RAP-Gen: Retrieval-Augmented Patch Generation with CodeT5 for Automatic Program Repair [2023-FSE/ESEC] [paper] [repo]
- InferFix: End-to-End Program Repair with LLMs over Retrieval-Augmented Prompts [2023-FSE/ESEC] [paper] [repo]
- Can LLMs Patch Security Issues [2023-arxiv] [paper] [repo]
- Improving Automated Program Repair with Domain Adaptation [2023-TOSEM] [paper] [repo]
- An empirical study of deep transfer learning-based program repair for Kotlin projects [2022-FSE/ESEC] [paper]
- TFix-Learning to Fix Coding Errors with a Text-to-Text Transformer [2021-PMLR] [paper] [repo]
- From Code to Correctness: Closing the Last Mile of Code Generation with Hierarchical Debugging [2024-arXiv] [paper] [repo]
- Teaching Large Language Models to Self-Debug [2024-ICLR] [paper]
- OpenCodeInterpreter: Integrating Code Generation with Execution and Refinement [2024-arxiv] [paper] [repo]
- CYCLE: Learning to Self-Refine the Code Generation [2024-OOPSLA] [paper] [repo]
- LDB: A Large Language Model Debugger via Verifying Runtime Execution Step by Step [2024-arxiv] [paper] [repo]
- Leveraging Print Debugging to Improve Code Generation in Large Language Models [2024-arxiv] [paper]
- SelfEvolve: A Code Evolution Framework via Large Language Models [2023-arxiv] [paper]
- Self-Refine: Iterative Refinement with Self-Feedback [2023-NeurIPS] [paper] [repo]
- AgentCoder: Multi Agent-Code Generation with Iterative Testing and Optimisation [2023-arxiv] [paper]
- Self-Edit: Fault-Aware Code Editor for Code Generation [2023-ACL] [paper] [repo]
- Is Self-Repair a Silver Bullet for Code Generation? [2023-ICLR] [paper] [repo]
- Domain Knowledge Matters: Improving Prompts with Fix Templates for Repairing Python Type Errors [2024-ICSE] [paper] [repo]
- PyTy: Repairing Static Type Errors in Python [2024-ICSE] [paper] [repo]
- GPT-3-Powered Type Error Debugging: Investigating the Use of Large Language Models for Code Repair [2023-SLE] [paper] [repo]
- Guiding ChatGPT to Fix Web UI Tests via Explanation-Consistency Checking [2023-arxiv] [paper]
- ACFIX: Guiding LLMs with Mined Common RBAC Practices for Context-Aware Repair of Access Control Vulnerabilities in Smart Contracts [2024-arxiv] [paper]
- Evaluating ChatGPT for Smart Contracts Vulnerability Correction [2023-COMPSAC] [paper] [repo]
- On Hardware Security Bug Code Fixes By Prompting Large Language Models [2024-TIFS] [paper] [repo]
Its pre-print: Fixing Hardware Security Bugs with Large Language Models [2022-arXiv] [paper] - HDLdebugger: Streamlining HDL debugging with Large Language Models [2024-arxiv] [paper]
- RTLFixer: Automatically Fixing RTL Syntax Errors with Large Language Models [2023-arxiv] [paper]
- LLM4SecHW: Leveraging domain-specific large language model for hardware debugging [2023-AsianHOST] [paper]
- RAPGen: An Approach for Fixing Code Inefficiencies in Zero-Shot [2023-arxiv] [paper]
- DeepDev-PERF: A Deep Learning-Based Approach for Improving Software Performance [2022-FSE/ESEC] [paper] [repo]
- Automated Test Case Repair Using Language Models [2024-arxiv] [paper]
- Identify and Update Test Cases when Production Code Changes: A Transformer-based Approach [2023-ASE]
- Baldur: Whole-Proof Generation and Repair with Large Language Models [2023-FSE/ESEC] [paper]
- Lost in Translation: A Study of Bugs Introduced by Large Language Models while Translating Code [2024-ICSE] [paper] [repo]
- Exploring the Potential of ChatGPT in Automated Code Refinement: An Empirical Study [2024-ICSE] [paper] [repo]
- DrPlanner: Diagnosis and Repair of Motion Planners Using Large Language Models [2024-arxiv] [paper] [repo]
- Exploring Experiences with Automated Program Repair in Practice [2024-ICSE] [paper]
- Revisiting Unnaturalness for Automated Program Repair in the Era of Large Language Models [2024-arxiv] [papper] [repo]
- An Empirical Study of Adoption of ChatGPT for Bug Fixing among Professional Developers [2023-ITA] [paper]
- 🔥Leveraging Large Language Model for Automatic Patch Correctness Assessment[2024-TSE] [paper]
- APPT Boosting Automated Patch Correctness Prediction via Pre-trained Language Model [2024-TSE] [paper] [repo]
- The Best of Both Worlds: Combining Learned Embeddings with Engineered Features for Accurate Prediction of Correct Patches [2023-TOSME] [paper] [repo]
- Invalidator: Automated Patch Correctness Assessment via Semantic and Syntactic Reasoning [2023-TSE] [paper] [repo]
- PatchZero: Zero-Shot Automatic Patch Correctness Assessment [2023-arxiv] [paper]
- Is this Change the Answer to that Problem? Correlating Descriptions of Bug and Code Changes for Evaluating Patch Correctness [2021-ASE] [paper] [repo]
- Evaluating representation learning of code changes for predicting patch correctness in program repair [2020-ASE] [paper] [repo]
- 🔥MuBench: Benchmarking Automated Program Repair: An Extensive Study on Both Real-World and Artificial Bugs [2024-ISSTA] [paper]
- CodeEditorBench: Evaluating Code Editing Capability of Large Language Models [2024-arxiv] [paper] [repo]
- GitBug-Java: A Reproducible Benchmark of Recent Java Bugs [2024-arxiv] [paper] [repo]
- SWE-bench: Can Language Models Resolve Real-World GitHub Issues? [2024-ICLR] [paper] [repo]
- DebugBench: Evaluating Debugging Capability of Large Language Models [2024-arxiv] [paper] [repo]
- ConDefects: A New Dataset to Address the Data Leakage Concern for LLM-based Fault Localization and Program Repair [2024-arxiv] [paper] [repo]
- A critical review of large language model on software engineering: An example from chatgpt and automated program repair [2023-arxiv] [paper] [repo]
- CodeScope: An Execution-based Multilingual Multitask Multidimensional Benchmark for Evaluating LLMs on Code Understanding and Generation [2023-arxiv] [paper] [repo]
- FixEval: Execution-based Evaluation of Program Fixes for Programming Problems [2023-APR] [paper] [repo]
- A Survey of Learning-based Automated Program Repair [2023-TOSEM] [paper] [repo]
- Automatic Software Repair: A Bibliography [2018-CSUR] paper]
- Automatic Software Repair: A Survey [2017-TSE] paper]
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for AwesomeLLM4APR
Similar Open Source Tools
AwesomeLLM4APR
Awesome LLM for APR is a repository dedicated to exploring the capabilities of Large Language Models (LLMs) in Automated Program Repair (APR). It provides a comprehensive collection of research papers, tools, and resources related to using LLMs for various scenarios such as repairing semantic bugs, security vulnerabilities, syntax errors, programming problems, static warnings, self-debugging, type errors, web UI tests, smart contracts, hardware bugs, performance bugs, API misuses, crash bugs, test case repairs, formal proofs, GitHub issues, code reviews, motion planners, human studies, and patch correctness assessments. The repository serves as a valuable reference for researchers and practitioners interested in leveraging LLMs for automated program repair.

Efficient-LLMs-Survey
This repository provides a systematic and comprehensive review of efficient LLMs research. We organize the literature in a taxonomy consisting of three main categories, covering distinct yet interconnected efficient LLMs topics from **model-centric** , **data-centric** , and **framework-centric** perspective, respectively. We hope our survey and this GitHub repository can serve as valuable resources to help researchers and practitioners gain a systematic understanding of the research developments in efficient LLMs and inspire them to contribute to this important and exciting field.
awesome-llm-understanding-mechanism
This repository is a collection of papers focused on understanding the internal mechanism of large language models (LLM). It includes research on topics such as how LLMs handle multilingualism, learn in-context, and handle factual associations. The repository aims to provide insights into the inner workings of transformer-based language models through a curated list of papers and surveys.
Awesome-System2-Reasoning-LLM
The Awesome-System2-Reasoning-LLM repository is dedicated to a survey paper titled 'From System 1 to System 2: A Survey of Reasoning Large Language Models'. It explores the development of reasoning Large Language Models (LLMs), their foundational technologies, benchmarks, and future directions. The repository provides resources and updates related to the research, tracking the latest developments in the field of reasoning LLMs.
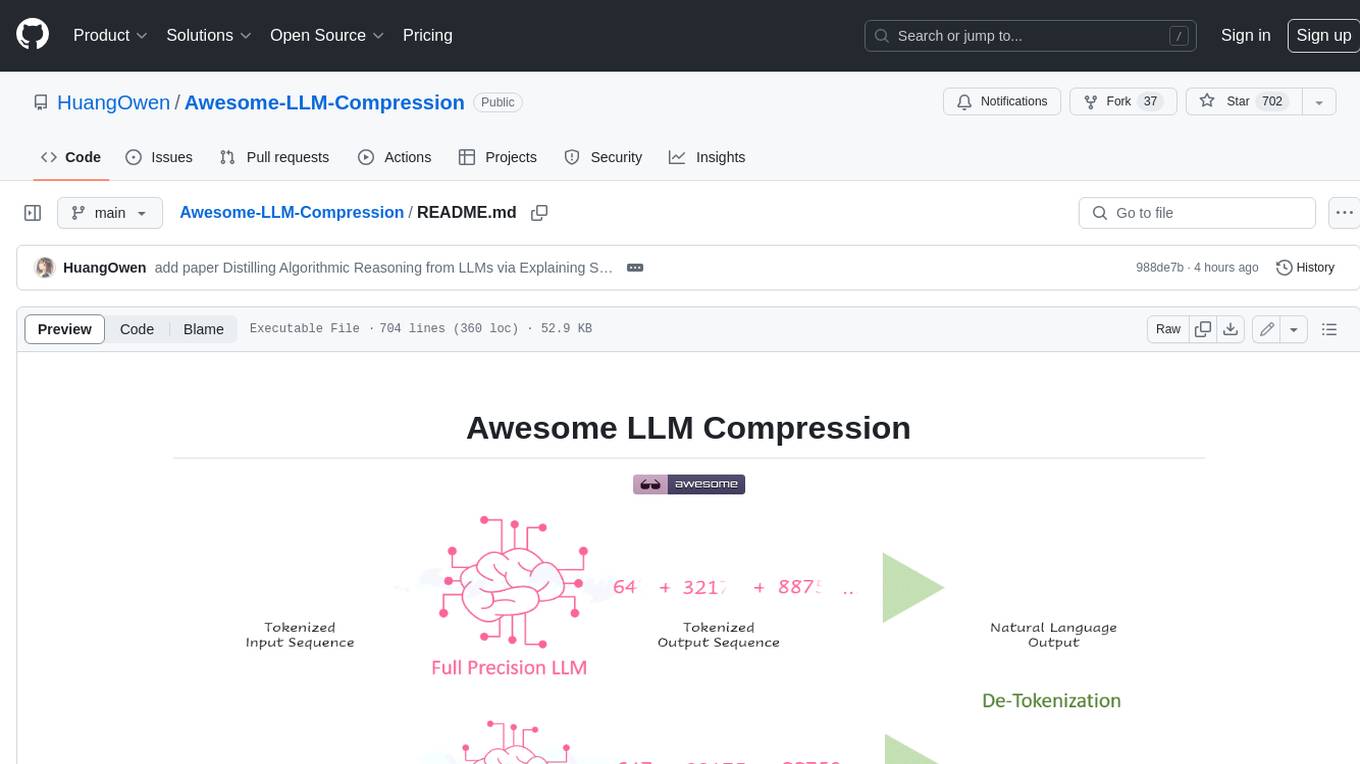
Awesome-LLM-Compression
Awesome LLM compression research papers and tools to accelerate LLM training and inference.
Awesome-LLM-Post-training
The Awesome-LLM-Post-training repository is a curated collection of influential papers, code implementations, benchmarks, and resources related to Large Language Models (LLMs) Post-Training Methodologies. It covers various aspects of LLMs, including reasoning, decision-making, reinforcement learning, reward learning, policy optimization, explainability, multimodal agents, benchmarks, tutorials, libraries, and implementations. The repository aims to provide a comprehensive overview and resources for researchers and practitioners interested in advancing LLM technologies.
awesome-ai4db-paper
The 'awesome-ai4db-paper' repository is a curated paper list focusing on AI for database (AI4DB) theory, frameworks, resources, and tools for data engineers. It includes a collection of research papers related to learning-based query optimization, training data set preparation, cardinality estimation, query-driven approaches, data-driven techniques, hybrid methods, pretraining models, plan hints, cost models, SQL embedding, join order optimization, query rewriting, end-to-end systems, text-to-SQL conversion, traditional database technologies, storage solutions, learning-based index design, and a learning-based configuration advisor. The repository aims to provide a comprehensive resource for individuals interested in AI applications in the field of database management.
AI-resources
AI-resources is a repository containing links to various resources for learning Artificial Intelligence. It includes video lectures, courses, tutorials, and open-source libraries related to deep learning, reinforcement learning, machine learning, and more. The repository categorizes resources for beginners, average users, and advanced users/researchers, providing a comprehensive collection of materials to enhance knowledge and skills in AI.

Awesome-Text2SQL
Awesome Text2SQL is a curated repository containing tutorials and resources for Large Language Models, Text2SQL, Text2DSL, Text2API, Text2Vis, and more. It provides guidelines on converting natural language questions into structured SQL queries, with a focus on NL2SQL. The repository includes information on various models, datasets, evaluation metrics, fine-tuning methods, libraries, and practice projects related to Text2SQL. It serves as a comprehensive resource for individuals interested in working with Text2SQL and related technologies.
awesome-AIOps
awesome-AIOps is a curated list of academic researches and industrial materials related to Artificial Intelligence for IT Operations (AIOps). It includes resources such as competitions, white papers, blogs, tutorials, benchmarks, tools, companies, academic materials, talks, workshops, papers, and courses covering various aspects of AIOps like anomaly detection, root cause analysis, incident management, microservices, dependency tracing, and more.
llm-continual-learning-survey
This repository is an updating survey for Continual Learning of Large Language Models (CL-LLMs), providing a comprehensive overview of various aspects related to the continual learning of large language models. It covers topics such as continual pre-training, domain-adaptive pre-training, continual fine-tuning, model refinement, model alignment, multimodal LLMs, and miscellaneous aspects. The survey includes a collection of relevant papers, each focusing on different areas within the field of continual learning of large language models.

AI-System-School
AI System School is a curated list of research in machine learning systems, focusing on ML/DL infra, LLM infra, domain-specific infra, ML/LLM conferences, and general resources. It provides resources such as data processing, training systems, video systems, autoML systems, and more. The repository aims to help users navigate the landscape of AI systems and machine learning infrastructure, offering insights into conferences, surveys, books, videos, courses, and blogs related to the field.

Awesome-LLMs-on-device
Welcome to the ultimate hub for on-device Large Language Models (LLMs)! This repository is your go-to resource for all things related to LLMs designed for on-device deployment. Whether you're a seasoned researcher, an innovative developer, or an enthusiastic learner, this comprehensive collection of cutting-edge knowledge is your gateway to understanding, leveraging, and contributing to the exciting world of on-device LLMs.

LLM-Tool-Survey
This repository contains a collection of papers related to tool learning with large language models (LLMs). The papers are organized according to the survey paper 'Tool Learning with Large Language Models: A Survey'. The survey focuses on the benefits and implementation of tool learning with LLMs, covering aspects such as task planning, tool selection, tool calling, response generation, benchmarks, evaluation, challenges, and future directions in the field. It aims to provide a comprehensive understanding of tool learning with LLMs and inspire further exploration in this emerging area.

ColossalAI
Colossal-AI is a deep learning system for large-scale parallel training. It provides a unified interface to scale sequential code of model training to distributed environments. Colossal-AI supports parallel training methods such as data, pipeline, tensor, and sequence parallelism and is integrated with heterogeneous training and zero redundancy optimizer.
For similar tasks
AwesomeLLM4APR
Awesome LLM for APR is a repository dedicated to exploring the capabilities of Large Language Models (LLMs) in Automated Program Repair (APR). It provides a comprehensive collection of research papers, tools, and resources related to using LLMs for various scenarios such as repairing semantic bugs, security vulnerabilities, syntax errors, programming problems, static warnings, self-debugging, type errors, web UI tests, smart contracts, hardware bugs, performance bugs, API misuses, crash bugs, test case repairs, formal proofs, GitHub issues, code reviews, motion planners, human studies, and patch correctness assessments. The repository serves as a valuable reference for researchers and practitioners interested in leveraging LLMs for automated program repair.

MiniAI-Face-Recognition-LivenessDetection-ServerSDK
The MiniAiLive Face Recognition LivenessDetection Server SDK provides system integrators with fast, flexible, and extremely precise facial recognition that can be deployed across various scenarios, including security, access control, public safety, fintech, smart retail, and home protection. The SDK is fully on-premise, meaning all processing happens on the hosting server, and no data leaves the server. The project structure includes bin, cpp, flask, model, python, test_image, and Dockerfile directories. To set up the project on Linux, download the repo, install system dependencies, and copy libraries into the system folder. For Windows, contact MiniAiLive via email. The C++ example involves replacing the license key in main.cpp, building the project, and running it. The Python example requires installing dependencies and running the project. The Python Flask example involves replacing the license key in app.py, installing dependencies, and running the project. The Docker Flask example includes building the docker image and running it. To request a license, contact MiniAiLive. Contributions to the project are welcome by following specific steps. An online demo is available at https://demo.miniai.live. Related products include MiniAI-Face-Recognition-LivenessDetection-AndroidSDK, MiniAI-Face-Recognition-LivenessDetection-iOS-SDK, MiniAI-Face-LivenessDetection-AndroidSDK, MiniAI-Face-LivenessDetection-iOS-SDK, MiniAI-Face-Matching-AndroidSDK, and MiniAI-Face-Matching-iOS-SDK. MiniAiLive is a leading AI solutions company specializing in computer vision and machine learning technologies.

MiniAI-Face-LivenessDetection-AndroidSDK
The MiniAiLive Face Liveness Detection Android SDK provides advanced computer vision techniques to enhance security and accuracy on Android platforms. It offers 3D Passive Face Liveness Detection capabilities, ensuring that users are physically present and not using spoofing methods to access applications or services. The SDK is fully on-premise, with all processing happening on the hosting server, ensuring data privacy and security.

blinkid-ios
BlinkID iOS is a mobile SDK that enables developers to easily integrate ID scanning and data extraction capabilities into their iOS applications. The SDK supports scanning and processing various types of identity documents, such as passports, driver's licenses, and ID cards. It provides accurate and fast data extraction, including personal information and document details. With BlinkID iOS, developers can enhance their apps with secure and reliable ID verification functionality, improving user experience and streamlining identity verification processes.
cheat-sheet-pdf
The Cheat-Sheet Collection for DevOps, Engineers, IT professionals, and more is a curated list of cheat sheets for various tools and technologies commonly used in the software development and IT industry. It includes cheat sheets for Nginx, Docker, Ansible, Python, Go (Golang), Git, Regular Expressions (Regex), PowerShell, VIM, Jenkins, CI/CD, Kubernetes, Linux, Redis, Slack, Puppet, Google Cloud Developer, AI, Neural Networks, Machine Learning, Deep Learning & Data Science, PostgreSQL, Ajax, AWS, Infrastructure as Code (IaC), System Design, and Cyber Security.
L1B3RT45
L1B3RT45 is a tool designed for jailbreaking all flagship AI models. It is part of the FREEAI project and is named LIBERTAS. Users can join the BASI Discord community for support. The tool was created with love by Pliny the Prompter.
card-scanner-flutter
Card Scanner Flutter is a fast, accurate, and secure plugin for Flutter that allows users to scan debit and credit cards offline. It can scan card details such as the card number, expiry date, card holder name, and card issuer. Powered by Google's Machine Learning models, the plugin offers great performance and accuracy. Users can control parameters for speed and accuracy balance and benefit from an intuitive API. Suitable for various jobs such as mobile app developer, fintech product manager, software engineer, data scientist, and UI/UX designer. AI keywords include card scanner, flutter plugin, debit card, credit card, machine learning. Users can use this tool to scan cards, verify card details, extract card information, validate card numbers, and enhance security.
ai_automation_suggester
An integration for Home Assistant that leverages AI models to understand your unique home environment and propose intelligent automations. By analyzing your entities, devices, areas, and existing automations, the AI Automation Suggester helps you discover new, context-aware use cases you might not have considered, ultimately streamlining your home management and improving efficiency, comfort, and convenience. The tool acts as a personal automation consultant, providing actionable YAML-based automations that can save energy, improve security, enhance comfort, and reduce manual intervention. It turns the complexity of a large Home Assistant environment into actionable insights and tangible benefits.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.