
Awesome-Efficient-AIGC
A list of papers, docs, codes about efficient AIGC. This repo is aimed to provide the info for efficient AIGC research, including language and vision, we are continuously improving the project. Welcome to PR the works (papers, repositories) that are missed by the repo.
Stars: 145
This repository, Awesome Efficient AIGC, collects efficient approaches for AI-generated content (AIGC) to cope with its huge demand for computing resources. It includes efficient Large Language Models (LLMs), Diffusion Models (DMs), and more. The repository is continuously improving and welcomes contributions of works like papers and repositories that are missed by the collection.
README:
This repo collects efficient approaches for AI-generated content (AIGC) to cope with its huge demand for computing resources, including efficient Large Language Models (LLMs), Diffusion Models (DMs), etc. We are continuously improving the project. Welcome to PR the works (papers, repositories) missed by the repo.
- [Arxiv] Efficient Prompting Methods for Large Language Models: A Survey
- [Arxiv] Efficient Diffusion Models for Vision: A Survey
- [Arxiv] Faster and Lighter LLMs: A Survey on Current Challenges and Way Forward [code]
- [Arxiv] A Survey on Knowledge Distillation of Large Language Models [code]
- [Arxiv] Model Compression and Efficient Inference for Large Language Models: A Survey
- [Arxiv] A Survey on Transformer Compression
- [Arxiv] A Comprehensive Survey of Compression Algorithms for Language Models
- [Arxiv] Unlocking Efficiency in Large Language Model Inference: A Comprehensive Survey of Speculative Decoding [code]
[Blog]
- [Arxiv] Personal LLM Agents: Insights and Survey about the Capability, Efficiency and Security [code]
- [Arxiv] A Survey on Hardware Accelerators for Large Language Models
- [Arxiv] A Survey of Resource-efficient LLM and Multimodal Foundation Models [code]
- [Arxiv] Beyond Efficiency: A Systematic Survey of Resource-Efficient Large Language Models [code]
- [Arxiv] Towards Efficient Generative Large Language Model Serving: A Survey from Algorithms to Systems
- [Arxiv] Efficient Large Language Models: A Survey [code]
- [Arxiv] The Efficiency Spectrum of Large Language Models: An Algorithmic Survey [code]
- [Arxiv] A Survey on Model Compression for Large Language Models
- [Arxiv] A Comprehensive Survey on Knowledge Distillation of Diffusion Models
- [TACL] Compressing Large-Scale Transformer-Based Models: A Case Study on BERT
- [JSA] A Survey of Techniques for Optimizing Transformer Inference
- [Arxiv] Understanding LLMs: A Comprehensive Overview from Training to Inference








Quantization
- [arXiv] How Good Are Low-bit Quantized LLaMA3 Models? An Empirical Study [code]
[HuggingFace]
- [ArXiv] Accurate LoRA-Finetuning Quantization of LLMs via Information Retention [code]
- [ArXiv] BiLLM: Pushing the Limit of Post-Training Quantization for LLMs [code]
- [ArXiv] DB-LLM: Accurate Dual-Binarization for Efficient LLMs
- [ArXiv] Extreme Compression of Large Language Models via Additive Quantization
- [ArXiv] Quantized Side Tuning: Fast and Memory-Efficient Tuning of Quantized Large Language Models
- [ArXiv] FP6-LLM: Efficiently Serving Large Language Models Through FP6-Centric Algorithm-System Co-Design
- [ArXiv] KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization
- [ArXiv] EdgeQAT: Entropy and Distribution Guided Quantization-Aware Training for the Acceleration of Lightweight LLMs on the Edge [code]
- [ArXiv] Any-Precision LLM: Low-Cost Deployment of Multiple, Different-Sized LLMs
- [ArXiv] LQER: Low-Rank Quantization Error Reconstruction for LLMs
- [ArXiv] KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache [code]
- [ArXiv] QuIP#: Even Better LLM Quantization with Hadamard Incoherence and Lattice Codebooks [code]
- [ArXiv] L4Q: Parameter Efficient Quantization-Aware Training on Large Language Models via LoRA-wise LSQ
- [ArXiv] TP-Aware Dequantization
- [ArXiv] ApiQ: Finetuning of 2-Bit Quantized Large Language Model
- [ArXiv] Any-Precision LLM: Low-Cost Deployment of Multiple, Different-Sized LLMs
- [ArXiv] BitDistiller: Unleashing the Potential of Sub-4-Bit LLMs via Self-Distillation [code]
- [ArXiv] OneBit: Towards Extremely Low-bit Large Language Models
- [ArXiv] WKVQuant: Quantising Weight and Key/Value Cache for Large Language Models Gains More
- [ArXiv] GPTVQ: The Blessing of Dimensionality for LLM Quantization [code]
- [DAC] APTQ: Attention-aware Post-Training Mixed-Precision Quantization for Large Language Models
- [DAC] A Comprehensive Evaluation of Quantization Strategies for Large Language Models
- [ArXiv] No Token Left Behind: Reliable KV Cache Compression via Importance-Aware Mixed Precision Quantization
- [ArXiv] Evaluating Quantized Large Language Models
- [ArXiv] FlattenQuant: Breaking Through the Inference Compute-bound for Large Language Models with Per-tensor Quantization
- [ArXiv] LLM-PQ: Serving LLM on Heterogeneous Clusters with Phase-Aware Partition and Adaptive Quantization
- [ArXiv] IntactKV: Improving Large Language Model Quantization by Keeping Pivot Tokens Intact
- [ArXiv] On the Compressibility of Quantized Large Language Models
- [ArXiv] EasyQuant: An Efficient Data-free Quantization Algorithm for LLMs
- [ArXiv] QAQ: Quality Adaptive Quantization for LLM KV Cache [code]
- [ArXiv] GEAR: An Efficient KV Cache Compression Recipefor Near-Lossless Generative Inference of LLM
- [ArXiv] What Makes Quantization for Large Language Models Hard? An Empirical Study from the Lens of Perturbation
- [ArXiv] SVD-LLM: Truncation-aware Singular Value Decomposition for Large Language Model Compression [code]
- [ICLR] AffineQuant: Affine Transformation Quantization for Large Language Models [code]
- [ICLR Practical ML for Low Resource Settings Workshop] Oh! We Freeze: Improving Quantized Knowledge Distillation via Signal Propagation Analysis for Large Language Models
- [ArXiv] Accurate Block Quantization in LLMs with Outliers
- [ArXiv] QuaRot: Outlier-Free 4-Bit Inference in Rotated LLMs [code]
- [ArXiv] Minimize Quantization Output Error with Bias Compensation [code]
- [ArXiv] Cherry on Top: Parameter Heterogeneity and Quantization in Large Language Models













Fine-tuning
- [ArXiv] BitDelta: Your Fine-Tune May Only Be Worth One Bit [code]
- [AAAI EIW Workshop 2024] QDyLoRA: Quantized Dynamic Low-Rank Adaptation for Efficient Large Language Model Tuning

Other
- [ArXiv] FlightLLM: Efficient Large Language Model Inference with a Complete Mapping Flow on FPGA
- [ArXiv] Inferflow: an Efficient and Highly Configurable Inference Engine for Large Language Models
Quantization
- [ICLR] GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers [code]
- [NeurIPS] QLORA: Efficient Finetuning of Quantized LLMs [code]
- [NeurIPS] Memory-Efficient Fine-Tuning of Compressed Large Language Models via sub-4-bit Integer Quantization
- [ICML] SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models [code]
- [ICML] FlexRound: Learnable Rounding based on Element-wise Division for Post-Training Quantization [code]
- [ICML] Understanding INT4 Quantization for Transformer Models: Latency Speedup, Composability, and Failure Cases [code]
- [ICML] GPT-Zip: Deep Compression of Finetuned Large Language Models
- [ICML] QIGen: Generating Efficient Kernels for Quantized Inference on Large Language Models [code]
- [ICML] The case for 4-bit precision: k-bit Inference Scaling Laws
- [ACL] PreQuant: A Task-agnostic Quantization Approach for Pre-trained Language Models
- [ACL] Boost Transformer-based Language Models with GPU-Friendly Sparsity and Quantization
- [EMNLP] Revisiting Block-based Quantisation: What is Important for Sub-8-bit LLM Inference?
- [EMNLP] Zero-Shot Sharpness-Aware Quantization for Pre-trained Language Models
- [EMNLP] LLM-FP4: 4-Bit Floating-Point Quantized Transformers [code]
- [EMNLP] Outlier Suppression+: Accurate quantization of large language models by equivalent and optimal shifting and scaling
- [ISCA] OliVe: Accelerating Large Language Models via Hardware-friendly Outlier-Victim Pair Quantization
- [ArXiv] ZeroQuant-V2: Exploring Post-training Quantization in LLMs from Comprehensive Study to Low Rank Compensation
- [ArXiv] LUT-GEMM: Quantized Matrix Multiplication based on LUTs for Efficient Inference in Large-Scale Generative Language Models
- [ArXiv] Quantized Distributed Training of Large Models with Convergence Guarantees
- [ArXiv] LLM-QAT: Data-Free Quantization Aware Training for Large Language Models
- [ArXiv] AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration [code]
- [ArXiv] Training Transformers with 4-bit Integers [code]
- [ArXiv] SqueezeLLM: Dense-and-Sparse Quantization [code]
- [ArXiv] Quantizable Transformers: Removing Outliers by Helping Attention Heads Do Nothing
- [ArXiv] SpQR: A Sparse-Quantized Representation for Near-Lossless LLM Weight Compression [code]
- [ArXiv] QuIP: 2-Bit Quantization of Large Language Models With Guarantees [code]
- [ArXiv] OWQ: Lessons learned from activation outliers for weight quantization in large language models
- [ArXiv] OmniQuant: Omnidirectionally Calibrated Quantization for Large Language Models [code]
- [ArXiv] RPTQ: Reorder-based Post-training Quantization for Large Language Models [code]
- [ArXiv] Integer or Floating Point? New Outlooks for Low-Bit Quantization on Large Language Models
- [ArXiv] INT2.1: Towards Fine-Tunable Quantized Large Language Models with Error Correction through Low-Rank Adaptation
- [ArXiv] INT-FP-QSim: Mixed Precision and Formats For Large Language Models and Vision Transformers [code]
- [ArXiv] Do Emergent Abilities Exist in Quantized Large Language Models: An Empirical Study
- [ArXiv] ZeroQuant-FP: A Leap Forward in LLMs Post-Training W4A8 Quantization Using Floating-Point Formats
- [ArXiv] NUPES : Non-Uniform Post-Training Quantization via Power Exponent Search
- [ArXiv] Token-Scaled Logit Distillation for Ternary Weight Generative Language Models
- [ArXiv] Gradient-Based Post-Training Quantization: Challenging the Status Quo
- [ArXiv] FineQuant: Unlocking Efficiency with Fine-Grained Weight-Only Quantization for LLMs
- [ArXiv] MEMORY-VQ: Compression for Tractable Internet-Scale Memory
- [ArXiv] FPTQ: Fine-grained Post-Training Quantization for Large Language Models
- [ArXiv] eDKM: An Efficient and Accurate Train-time Weight Clustering for Large Language Models
- [ArXiv] QuantEase: Optimization-based Quantization for Language Models - An Efficient and Intuitive Algorithm
- [ArXiv] Norm Tweaking: High-performance Low-bit Quantization of Large Language Models
- [ArXiv] Understanding the Impact of Post-Training Quantization on Large Language Models
- [ArXiv] Optimize Weight Rounding via Signed Gradient Descent for the Quantization of LLMs [code]
- [ArXiv] Efficient Post-training Quantization with FP8 Formats [code]
- [ArXiv] QA-LoRA: Quantization-Aware Low-Rank Adaptation of Large Language Models [code]
- [ArXiv] Rethinking Channel Dimensions to Isolate Outliers for Low-bit Weight Quantization of Large Language Models
- [ArXiv] ModuLoRA: Finetuning 3-Bit LLMs on Consumer GPUs by Integrating with Modular Quantizers
- [ArXiv] PB-LLM: Partially Binarized Large Language Models [code]
- [ArXiv] Dual Grained Quantization: Efficient Fine-Grained Quantization for LLM
- [ArXiv] QFT: Quantized Full-parameter Tuning of LLMs with Affordable Resources
- [ArXiv] QLLM: Accurate and Efficient Low-Bitwidth Quantization for Large Language Models
- [ArXiv] LoftQ: LoRA-Fine-Tuning-Aware Quantization for Large Language Models [code]
- [ArXiv] TEQ: Trainable Equivalent Transformation for Quantization of LLMs [code]
- [ArXiv] BitNet: Scaling 1-bit Transformers for Large Language Models [code]
- [ArXiv] FP8-LM: Training FP8 Large Language Models [code]
- [ArXiv] Atom: Low-bit Quantization for Efficient and Accurate LLM Serving [code]
- [ArXiv] LoftQ: LoRA-Fine-Tuning-Aware Quantization for Large Language Models [code]
- [ArXiv] AWEQ: Post-Training Quantization with Activation-Weight Equalization for Large Language Models
- [ArXiv] AFPQ: Asymmetric Floating Point Quantization for LLMs [code]
- [ArXiv] LQ-LoRA: Low-rank Plus Quantized Matrix Decomposition for Efficient Language Model Finetuning [code]























Pruning and Sparsity
- [ICML] Deja Vu: Contextual Sparsity for Efficient LLMs at Inference Time [code]
- [ICML] SparseGPT: Massive Language Models Can Be Accurately Pruned in One-Shot [code]
- [ICML] LoSparse: Structured Compression of Large Language Models based on Low-Rank and Sparse Approximation [code]
- [ICML] A Simple and Effective Pruning Approach for Large Language Models [code]
- [ICLR] The Lazy Neuron Phenomenon: On Emergence of Activation Sparsity in Transformers [code]
- [ICLR] Prune and Tune: Improving Efficient Pruning Techniques for Massive Language Models
- [NeurIPS] Outlier Suppression: Pushing the Limit of Low-bit Transformer Language Models [code]
- [NeurIPS] LLM-Pruner: On the Structural Pruning of Large Language Models [code]
- [ACL] Boost Transformer-based Language Models with GPU-Friendly Sparsity and Quantization
- [AutoML] Structural Pruning of Large Language Models via Neural Architecture Search
- [VLDB] Flash-LLM: Enabling Cost-Effective and Highly-Efficient Large Generative Model Inference with Unstructured Sparsity [code]
- [ArXiv] What Matters In The Structured Pruning of Generative Language Models?
- [ArXiv] LoRAPrune: Pruning Meets Low-Rank Parameter-Efficient Fine-Tuning
- [ArXiv] SpQR: A Sparse-Quantized Representation for Near-Lossless LLM Weight Compression [code]
- [ArXiv] SqueezeLLM: Dense-and-Sparse Quantization [code]
- [ArXiv] Pruning Large Language Models via Accuracy Predictor
- [ArXiv] Sheared LLaMA: Accelerating Language Model Pre-training via Structured Pruning [code]
- [ArXiv] Outlier Weighed Layerwise Sparsity (OWL): A Missing Secret Sauce for Pruning LLMs to High Sparsity [code]
- [ArXiv] Junk DNA Hypothesis: A Task-Centric Angle of LLM Pre-trained Weights through Sparsity [code]
- [ArXiv] Compresso: Structured Pruning with Collaborative Prompting Learns Compact Large Language Models [code]
- [ArXiv] Dynamic Sparse No Training: Training-Free Fine-tuning for Sparse LLMs [code]
- [ArXiv] One-Shot Sensitivity-Aware Mixed Sparsity Pruning for Large Language Models
- [ArXiv] E-Sparse: Boosting the Large Language Model Inference through Entropy-based N:M Sparsity
- [ArXiv] LoRAShear: Efficient Large Language Model Structured Pruning and Knowledge Recovery [code]












Distillation
- [ACL] Symbolic Chain-of-Thought Distillation: Small Models Can Also "Think" Step-by-Step [code]
- [ACL] Lifting the Curse of Capacity Gap in Distilling Language Models [code]
- [ACL] DISCO: Distilling Counterfactuals with Large Language Models [code]
- [ACL] SCOTT: Self-Consistent Chain-of-Thought Distillation [code]
- [ACL] AD-KD: Attribution-Driven Knowledge Distillation for Language Model Compression
- [ACL] Large Language Models Are Reasoning Teachers [code]
- [ACL] Distilling Reasoning Capabilities into Smaller Language Models
- [ACL] Cost-effective Distillation of Large Language Models [code]
- [ACL] Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes [code]
- [EMNLP] Democratizing Reasoning Ability: Tailored Learning from Large Language Model [code]
- [EMNLP] PromptMix: A Class Boundary Augmentation Method for Large Language Model Distillation [code]
- [EMNLP] MCC-KD: Multi-CoT Consistent Knowledge Distillation
- [EMNLP] Enhancing Computation Efficiency in Large Language Models through Weight and Activation Quantization
- [ArXiv] LaMini-LM: A Diverse Herd of Distilled Models from Large-Scale Instructions [code]
- [ArXiv] Task-agnostic Distillation of Encoder-Decoder Language Models
- [ArXiv] Lion: Adversarial Distillation of Closed-Source Large Language Model [code]
- [ArXiv] PaD: Program-aided Distillation Specializes Large Models in Reasoning
- [ArXiv] Large Language Model Distillation Doesn't Need a Teacher [code]
- [ArXiv] The False Promise of Imitating Proprietary LLMs
- [ArXiv] Knowledge Distillation of Large Language Models [code]
- [ArXiv] GKD: Generalized Knowledge Distillation for Auto-regressive Sequence Models
- [ArXiv] Chain-of-Thought Prompt Distillation for Multimodal Named Entity Recognition and Multimodal Relation Extraction
- [ArXiv] Sci-CoT: Leveraging Large Language Models for Enhanced Knowledge Distillation in Small Models for Scientific QA
- [ArXiv] Token-Scaled Logit Distillation for Ternary Weight Generative Language Models
- [ArXiv] Can a student Large Language Model perform as well as it's teacher?
- [ArXiv] A Speed Odyssey for Deployable Quantization of LLMs
- [ArXiv] How Does Calibration Data Affect the Post-training Pruning and Quantization of Large Language Models?
Fine-tuning
- [Nature] Parameter-efficient fine-tuning of large-scale pre-trained language models [code]
- [NeurIPS] QLORA: Efficient Finetuning of Quantized LLMs [code]
- [NeurIPS] Make Pre-trained Model Reversible: From Parameter to Memory Efficient Fine-Tuning [code]
- [ACL] Large Language Models Are Reasoning Teachers [code]
- [ArXiv] LoRAPrune: Pruning Meets Low-Rank Parameter-Efficient Fine-Tuning
- [ArXiv] Memory-Efficient Fine-Tuning of Compressed Large Language Models via sub-4-bit Integer Quantization
- [ArXiv] INT2.1: Towards Fine-Tunable Quantized Large Language Models with Error Correction through Low-Rank Adaptation
- [ArXiv] LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models [code]
- [ArXiv] QA-LoRA: Quantization-Aware Low-Rank Adaptation of Large Language Models [code]
- [ArXiv] ModuLoRA: Finetuning 3-Bit LLMs on Consumer GPUs by Integrating with Modular Quantizers
- [ArXiv] QFT: Quantized Full-parameter Tuning of LLMs with Affordable Resources
- [ArXiv] LoftQ: LoRA-Fine-Tuning-Aware Quantization for Large Language Models [code]
- [ArXiv] S-LoRA: Serving Thousands of Concurrent LoRA Adapters [code]
- [ArXiv] LQ-LoRA: Low-rank Plus Quantized Matrix Decomposition for Efficient Language Model Finetuning [code]
Other
- [ACL] Did You Read the Instructions? Rethinking the Effectiveness of Task Definitions in Instruction Learning [code]
- [EMNLP] Adapting Language Models to Compress Contexts [code]
- [EMNLP] LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models [code]
- [EMNLP] Compressing Context to Enhance Inference Efficiency of Large Language Models [code]
- [EMNLP] Batch Prompting: Efficient Inference with Large Language Model APIs [code]
- [ArXiv] Learning to Compress Prompts with Gist Tokens [code]
- [ArXiv] Efficient Prompting via Dynamic In-Context Learning
- [ArXiv] Compress, Then Prompt: Improving Accuracy-Efficiency Trade-off of LLM Inference with Transferable Prompt
- [ArXiv] In-context Autoencoder for Context Compression in a Large Language Model [code]
- [ArXiv] Discrete Prompt Compression with Reinforcement Learning
- [ArXiv] BatchPrompt: Accomplish more with less
- [ArXiv] (Dynamic) Prompting might be all you need to repair Compressed LLMs
- [ArXiv] Model Tells You What to Discard: Adaptive KV Cache Compression for LLMs
- [ArXiv] RECOMP: Improving Retrieval-Augmented LMs with Compression and Selective Augmentation [code]
- [ArXiv] HyperAttention: Long-context Attention in Near-Linear Time
- [ArXiv] LongLLMLingua: Accelerating and Enhancing LLMs in Long Context Scenarios via Prompt Compression [code]
Quantization
- [ACL] Compression of Generative Pre-trained Language Models via Quantization
- [NeurIPS] LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
- [NeurIPS] Towards Efficient Post-training Quantization of Pre-trained Language Models
- [NeurIPS] ZeroQuant: Efficient and Affordable Post-Training Quantization for Large-Scale Transformers
- [NeurIPS] BiT: Robustly Binarized Multi-distilled Transformer [code]
- [ICLR] BiBERT: Accurate Fully Binarized BERT [code]
Distillation
- [ArXiv] Explanations from Large Language Models Make Small Reasoners Better
- [ArXiv] In-context Learning Distillation: Transferring Few-shot Learning Ability of Pre-trained Language Models
Fine-tuning
Other
- [ICML] GACT: Activation Compressed Training for Generic Network Architectures
Quantization
- [ICML] I-BERT: Integer-only BERT Quantization
- [ACL] BinaryBERT: Pushing the Limit of BERT Quantization
Pruning and Sparsity
- [ACL] On the Distribution, Sparsity, and Inference-time Quantization of Attention Values in Transformers
Distillation
- [ACL] One Teacher is Enough? Pre-trained Language Model Distillation from Multiple Teachers
Quantization
- [EMNLP] Fully Quantized Transformer for Machine Translation
- [IJCAI] Towards Fully 8-bit Integer Inference for the Transformer Model
- [EMNLP] TernaryBERT: Distillation-aware Ultra-low Bit BERT
- [AAAI] Q-BERT: Hessian Based Ultra Low Precision Quantization of BERT
- [MICRO] GOBO: Quantizing Attention-Based NLP Models for Low Latency and Energy Efficient Inference
Pruning and Sparsity
- [ACL] Compressing bert: Studying the effects of weight pruning on transfer learning
Distillation
- [ICLR] Extreme Language Model Compression with Optimal Subwords and Shared Projections
Quantization
- [ICML] Efficient 8-Bit Quantization of Transformer Neural Machine Language Translation Model
- [NeurIPS] Q8BERT: Quantized 8Bit BERT
- [NeurIPS] Fully Quantized Transformer for Improved Translation
Distillation
- [NeurIPS] DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
Quantization

Quantization
- [ICLR] Analog Bits: Generating Discrete Data using Diffusion Models with Self-Conditioning
- [CVPR] Post-training Quantization on Diffusion Models [code]
- [CVPR] Regularized Vector Quantization for Tokenized Image Synthesis
- [ICCV] Q-Diffusion: Quantizing Diffusion Models [code]
- [NeurIPS] Q-DM: An Efficient Low-bit Quantized Diffusion Model
- [NeurIPS] PTQD: Accurate Post-Training Quantization for Diffusion Models [code]
- [NeurIPS] Temporal Dynamic Quantization for Diffusion Models
- [ArXiv] Towards Accurate Data-free Quantization for Diffusion Models
- [ArXiv] Finite Scalar Quantization: VQ-VAE Made Simple [code]
- [ArXiv] EfficientDM: Efficient Quantization-Aware Fine-Tuning of Low-Bit Diffusion Models




Pruning and Sparsity
- [TPAMI] Efficient Spatially Sparse Inference for Conditional GANs and Diffusion Models [code]
- [ArXiv] Structural Pruning for Diffusion Models [code]
Distillation
- [CVPR] On Distillation of Guided Diffusion Models
- [ICME] Accelerating Diffusion Sampling with Classifier-based Feature Distillation [code]
- [ICML] Accelerating Diffusion-based Combinatorial Optimization Solvers by Progressive Distillation [code]
- [ICML] Towards Safe Self-Distillation of Internet-Scale Text-to-Image Diffusion Models [code]
- [ArXiv] BOOT: Data-free Distillation of Denoising Diffusion Models with Bootstrapping
- [ArXiv] SnapFusion: Text-to-Image Diffusion Model on Mobile Devices within Two Seconds
- [ArXiv] Catch-Up Distillation: You Only Need to Train Once for Accelerating Sampling [code]
- [ArXiv] Knowledge Distillation in Iterative Generative Models for Improved Sampling Speed
- [ArXiv] On Architectural Compression of Text-to-Image Diffusion Models
- [ArXiv] Progressive Distillation for Fast Sampling of Diffusion Models
Other
- [ArXiv] AutoDiffusion: Training-Free Optimization of Time Steps and Architectures for Automated Diffusion Model Acceleration
- [ArXiv] Spiking-Diffusion: Vector Quantized Discrete Diffusion Model with Spiking Neural Networks [code]
-
https://github.com/htqin/Awesome-Model-Quantization
-
https://github.com/Zhen-Dong/Awesome-Quantization-Papers
-
https://github.com/HuangOwen/Awesome-LLM-Compression
-
https://github.com/horseee/Awesome-Efficient-LLM
-
https://github.com/DefTruth/Awesome-LLM-Inference
-
https://github.com/A-suozhang/Awesome-Efficient-Diffusion






For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Awesome-Efficient-AIGC
Similar Open Source Tools
Awesome-Efficient-AIGC
This repository, Awesome Efficient AIGC, collects efficient approaches for AI-generated content (AIGC) to cope with its huge demand for computing resources. It includes efficient Large Language Models (LLMs), Diffusion Models (DMs), and more. The repository is continuously improving and welcomes contributions of works like papers and repositories that are missed by the collection.
Efficient_Foundation_Model_Survey
Efficient Foundation Model Survey is a comprehensive analysis of resource-efficient large language models (LLMs) and multimodal foundation models. The survey covers algorithmic and systemic innovations to support the growth of large models in a scalable and environmentally sustainable way. It explores cutting-edge model architectures, training/serving algorithms, and practical system designs. The goal is to provide insights on tackling resource challenges posed by large foundation models and inspire future breakthroughs in the field.
LLM-Discrete-Tokenization-Survey
The repository contains a comprehensive survey paper on Discrete Tokenization for Multimodal Large Language Models (LLMs). It covers various techniques, applications, and challenges related to discrete tokenization in the context of LLMs. The survey explores the use of vector quantization, product quantization, and other methods for tokenizing different modalities like text, image, audio, video, graph, and more. It also discusses the integration of discrete tokenization with LLMs for tasks such as image generation, speech recognition, recommendation systems, and multimodal understanding and generation.
awesome-llm-understanding-mechanism
This repository is a collection of papers focused on understanding the internal mechanism of large language models (LLM). It includes research on topics such as how LLMs handle multilingualism, learn in-context, and handle factual associations. The repository aims to provide insights into the inner workings of transformer-based language models through a curated list of papers and surveys.
awesome_LLM-harmful-fine-tuning-papers
This repository is a comprehensive survey of harmful fine-tuning attacks and defenses for large language models (LLMs). It provides a curated list of must-read papers on the topic, covering various aspects such as alignment stage defenses, fine-tuning stage defenses, post-fine-tuning stage defenses, mechanical studies, benchmarks, and attacks/defenses for federated fine-tuning. The repository aims to keep researchers updated on the latest developments in the field and offers insights into the vulnerabilities and safeguards related to fine-tuning LLMs.
AwesomeLLM4APR
Awesome LLM for APR is a repository dedicated to exploring the capabilities of Large Language Models (LLMs) in Automated Program Repair (APR). It provides a comprehensive collection of research papers, tools, and resources related to using LLMs for various scenarios such as repairing semantic bugs, security vulnerabilities, syntax errors, programming problems, static warnings, self-debugging, type errors, web UI tests, smart contracts, hardware bugs, performance bugs, API misuses, crash bugs, test case repairs, formal proofs, GitHub issues, code reviews, motion planners, human studies, and patch correctness assessments. The repository serves as a valuable reference for researchers and practitioners interested in leveraging LLMs for automated program repair.
efficient-transformers
Efficient Transformers Library provides reimplemented blocks of Large Language Models (LLMs) to make models functional and highly performant on Qualcomm Cloud AI 100. It includes graph transformations, handling for under-flows and overflows, patcher modules, exporter module, sample applications, and unit test templates. The library supports seamless inference on pre-trained LLMs with documentation for model optimization and deployment. Contributions and suggestions are welcome, with a focus on testing changes for model support and common utilities.
Awesome-System2-Reasoning-LLM
The Awesome-System2-Reasoning-LLM repository is dedicated to a survey paper titled 'From System 1 to System 2: A Survey of Reasoning Large Language Models'. It explores the development of reasoning Large Language Models (LLMs), their foundational technologies, benchmarks, and future directions. The repository provides resources and updates related to the research, tracking the latest developments in the field of reasoning LLMs.
Awesome-TimeSeries-SpatioTemporal-LM-LLM
Awesome-TimeSeries-SpatioTemporal-LM-LLM is a curated list of Large (Language) Models and Foundation Models for Temporal Data, including Time Series, Spatio-temporal, and Event Data. The repository aims to summarize recent advances in Large Models and Foundation Models for Time Series and Spatio-Temporal Data with resources such as papers, code, and data. It covers various applications like General Time Series Analysis, Transportation, Finance, Healthcare, Event Analysis, Climate, Video Data, and more. The repository also includes related resources, surveys, and papers on Large Language Models, Foundation Models, and their applications in AIOps.
Awesome-Graph-LLM
Awesome-Graph-LLM is a curated collection of research papers exploring the intersection of graph-based techniques with Large Language Models (LLMs). The repository aims to bridge the gap between LLMs and graph structures prevalent in real-world applications by providing a comprehensive list of papers covering various aspects of graph reasoning, node classification, graph classification/regression, knowledge graphs, multimodal models, applications, and tools. It serves as a valuable resource for researchers and practitioners interested in leveraging LLMs for graph-related tasks.

Awesome-Text2SQL
Awesome Text2SQL is a curated repository containing tutorials and resources for Large Language Models, Text2SQL, Text2DSL, Text2API, Text2Vis, and more. It provides guidelines on converting natural language questions into structured SQL queries, with a focus on NL2SQL. The repository includes information on various models, datasets, evaluation metrics, fine-tuning methods, libraries, and practice projects related to Text2SQL. It serves as a comprehensive resource for individuals interested in working with Text2SQL and related technologies.
Awesome-Quantization-Papers
This repo contains a comprehensive paper list of **Model Quantization** for efficient deep learning on AI conferences/journals/arXiv. As a highlight, we categorize the papers in terms of model structures and application scenarios, and label the quantization methods with keywords.

Awesome-Robotics-3D
Awesome-Robotics-3D is a curated list of 3D Vision papers related to Robotics domain, focusing on large models like LLMs/VLMs. It includes papers on Policy Learning, Pretraining, VLM and LLM, Representations, and Simulations, Datasets, and Benchmarks. The repository is maintained by Zubair Irshad and welcomes contributions and suggestions for adding papers. It serves as a valuable resource for researchers and practitioners in the field of Robotics and Computer Vision.

kan-gpt
The KAN-GPT repository is a PyTorch implementation of Generative Pre-trained Transformers (GPTs) using Kolmogorov-Arnold Networks (KANs) for language modeling. It provides a model for generating text based on prompts, with a focus on improving performance compared to traditional MLP-GPT models. The repository includes scripts for training the model, downloading datasets, and evaluating model performance. Development tasks include integrating with other libraries, testing, and documentation.
For similar tasks

aimet
AIMET is a library that provides advanced model quantization and compression techniques for trained neural network models. It provides features that have been proven to improve run-time performance of deep learning neural network models with lower compute and memory requirements and minimal impact to task accuracy. AIMET is designed to work with PyTorch, TensorFlow and ONNX models. We also host the AIMET Model Zoo - a collection of popular neural network models optimized for 8-bit inference. We also provide recipes for users to quantize floating point models using AIMET.

hqq
HQQ is a fast and accurate model quantizer that skips the need for calibration data. It's super simple to implement (just a few lines of code for the optimizer). It can crunch through quantizing the Llama2-70B model in only 4 minutes! 🚀

llm-resource
llm-resource is a comprehensive collection of high-quality resources for Large Language Models (LLM). It covers various aspects of LLM including algorithms, training, fine-tuning, alignment, inference, data engineering, compression, evaluation, prompt engineering, AI frameworks, AI basics, AI infrastructure, AI compilers, LLM application development, LLM operations, AI systems, and practical implementations. The repository aims to gather and share valuable resources related to LLM for the community to benefit from.
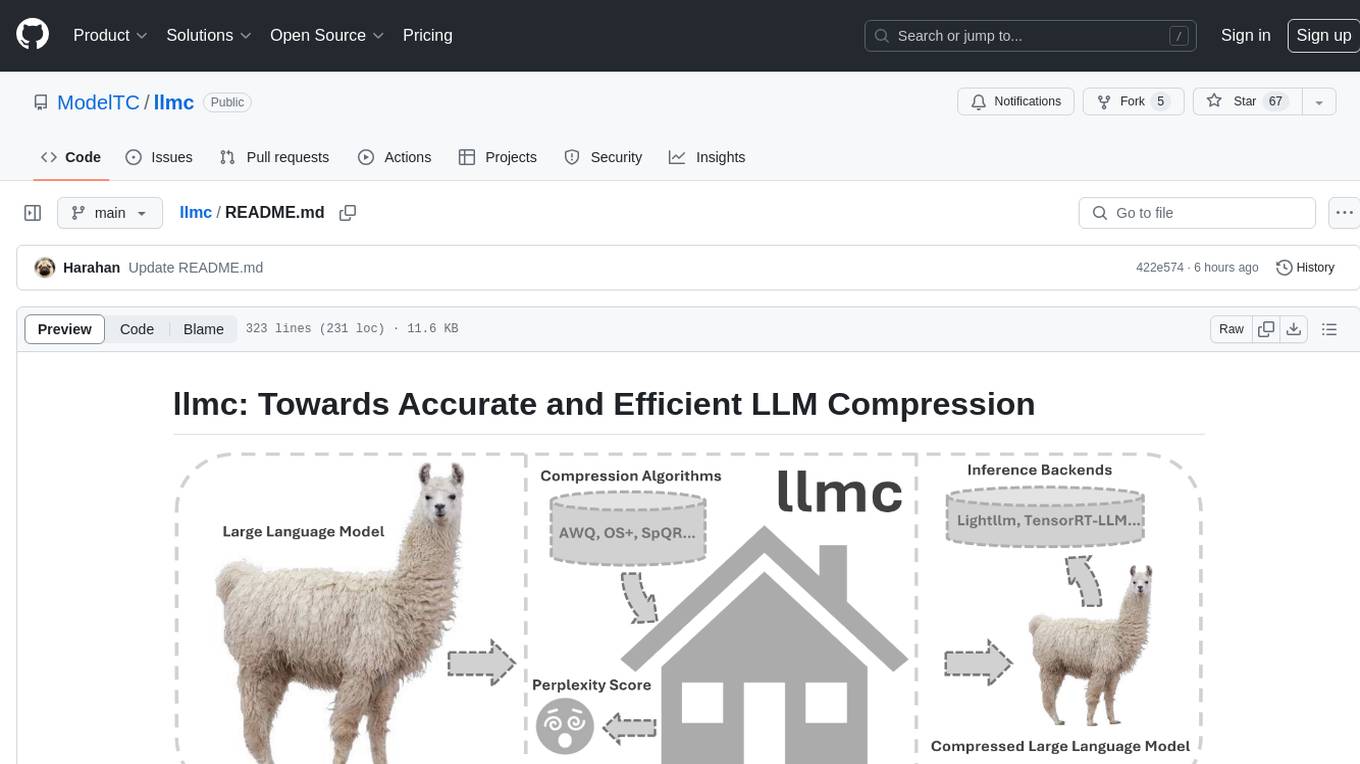
llmc
llmc is an off-the-shell tool designed for compressing LLM, leveraging state-of-the-art compression algorithms to enhance efficiency and reduce model size without compromising performance. It provides users with the ability to quantize LLMs, choose from various compression algorithms, export transformed models for further optimization, and directly infer compressed models with a shallow memory footprint. The tool supports a range of model types and quantization algorithms, with ongoing development to include pruning techniques. Users can design their configurations for quantization and evaluation, with documentation and examples planned for future updates. llmc is a valuable resource for researchers working on post-training quantization of large language models.

Awesome-Efficient-LLM
Awesome-Efficient-LLM is a curated list focusing on efficient large language models. It includes topics such as knowledge distillation, network pruning, quantization, inference acceleration, efficient MOE, efficient architecture of LLM, KV cache compression, text compression, low-rank decomposition, hardware/system, tuning, and survey. The repository provides a collection of papers and projects related to improving the efficiency of large language models through various techniques like sparsity, quantization, and compression.

TensorRT-Model-Optimizer
The NVIDIA TensorRT Model Optimizer is a library designed to quantize and compress deep learning models for optimized inference on GPUs. It offers state-of-the-art model optimization techniques including quantization and sparsity to reduce inference costs for generative AI models. Users can easily stack different optimization techniques to produce quantized checkpoints from torch or ONNX models. The quantized checkpoints are ready for deployment in inference frameworks like TensorRT-LLM or TensorRT, with planned integrations for NVIDIA NeMo and Megatron-LM. The tool also supports 8-bit quantization with Stable Diffusion for enterprise users on NVIDIA NIM. Model Optimizer is available for free on NVIDIA PyPI, and this repository serves as a platform for sharing examples, GPU-optimized recipes, and collecting community feedback.

Awesome_LLM_System-PaperList
Since the emergence of chatGPT in 2022, the acceleration of Large Language Model has become increasingly important. Here is a list of papers on LLMs inference and serving.
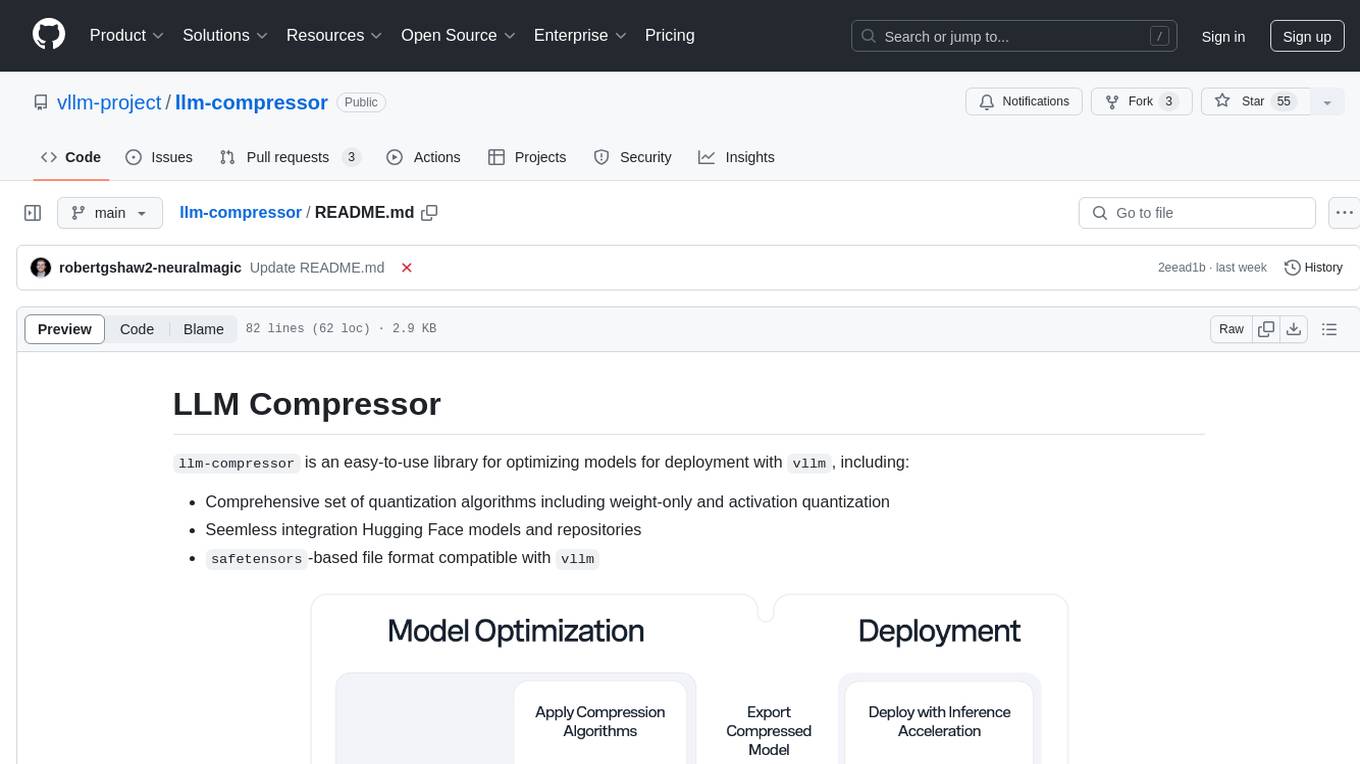
llm-compressor
llm-compressor is an easy-to-use library for optimizing models for deployment with vllm. It provides a comprehensive set of quantization algorithms, seamless integration with Hugging Face models and repositories, and supports mixed precision, activation quantization, and sparsity. Supported algorithms include PTQ, GPTQ, SmoothQuant, and SparseGPT. Installation can be done via git clone and local pip install. Compression can be easily applied by selecting an algorithm and calling the oneshot API. The library also offers end-to-end examples for model compression. Contributions to the code, examples, integrations, and documentation are appreciated.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.