Best AI tools for< Optimize Inference >
20 - AI tool Sites
d-Matrix
d-Matrix is an AI tool that offers ultra-low latency batched inference for generative AI technology. It introduces Corsair™, the world's most efficient AI inference platform for datacenters, providing high performance, efficiency, and scalability for large-scale inference tasks. The tool aims to transform the economics of AI inference by delivering fast, sustainable, and scalable AI solutions without compromising on speed or usability.
Rebellions
Rebellions is an AI technology company specializing in AI chips and systems-on-chip for various applications. They focus on energy-efficient solutions and have secured significant investments to drive innovation in the field of Generative AI. Rebellions aims to reshape the future by providing versatile and efficient AI computing solutions.
Graphcore
Graphcore is a cloud-based platform that accelerates machine learning processes by harnessing the power of IPU-powered generative AI. It offers cloud services, pre-trained models, optimized inference engines, and APIs to streamline operations and bring intelligence to enterprise applications. With Graphcore, users can build and deploy AI-native products and platforms using the latest AI technologies such as LLMs, NLP, and Computer Vision.
FuriosaAI
FuriosaAI is an AI application that offers Hardware RNGD for LLM and Multimodality, as well as WARBOY for Computer Vision. It provides a comprehensive developer experience through the Furiosa SDK, Model Zoo, and Dev Support. The application focuses on efficient AI inference, high-performance LLM and multimodal deployment capabilities, and sustainable mass adoption of AI. FuriosaAI features the Tensor Contraction Processor architecture, software for streamlined LLM deployment, and a robust ecosystem support. It aims to deliver powerful and efficient deep learning acceleration while ensuring future-proof programmability and efficiency.

Tensordyne
Tensordyne is a generative AI inference compute tool designed and developed in the US and Germany. It focuses on re-engineering AI math and defining AI inference to run the biggest AI models for thousands of users at a fraction of the rack count, power, and cost. Tensordyne offers custom silicon and systems built on the Zeroth Scaling Law, enabling breakthroughs in AI technology.
Modular
Modular is a fast, scalable Gen AI inference platform that offers a comprehensive suite of tools and resources for AI development and deployment. It provides solutions for AI model development, deployment options, AI inference, research, and resources like documentation, models, tutorials, and step-by-step guides. Modular supports GPU and CPU performance, intelligent scaling to any cluster, and offers deployment options for various editions. The platform enables users to build agent workflows, utilize AI retrieval and controlled generation, develop chatbots, engage in code generation, and improve resource utilization through batch processing.

Groq
Groq is a fast AI inference tool that offers instant intelligence for openly-available models like Llama 3.1. It provides ultra-low-latency inference for cloud deployments and is compatible with other providers like OpenAI. Groq's speed is proven to be instant through independent benchmarks, and it powers leading openly-available AI models such as Llama, Mixtral, Gemma, and Whisper. The tool has gained recognition in the industry for its high-speed inference compute capabilities and has received significant funding to challenge established players like Nvidia.
Salad
Salad is a distributed GPU cloud platform that offers fully managed and massively scalable services for AI applications. It provides the lowest priced AI transcription in the market, with features like image generation, voice AI, computer vision, data collection, and batch processing. Salad democratizes cloud computing by leveraging consumer GPUs to deliver cost-effective AI/ML inference at scale. The platform is trusted by hundreds of machine learning and data science teams for its affordability, scalability, and ease of deployment.
FluidStack
FluidStack is a leading GPU cloud platform designed for AI and LLM (Large Language Model) training. It offers unlimited scale for AI training and inference, allowing users to access thousands of fully-interconnected GPUs on demand. Trusted by top AI startups, FluidStack aggregates GPU capacity from data centers worldwide, providing access to over 50,000 GPUs for accelerating training and inference. With 1000+ data centers across 50+ countries, FluidStack ensures reliable and efficient GPU cloud services at competitive prices.
ONNX Runtime
ONNX Runtime is a production-grade AI engine designed to accelerate machine learning training and inferencing in various technology stacks. It supports multiple languages and platforms, optimizing performance for CPU, GPU, and NPU hardware. ONNX Runtime powers AI in Microsoft products and is widely used in cloud, edge, web, and mobile applications. It also enables large model training and on-device training, offering state-of-the-art models for tasks like image synthesis and text generation.

Wallaroo.AI
Wallaroo.AI is an AI inference platform that offers production-grade AI inference microservices optimized on OpenVINO for cloud and Edge AI application deployments on CPUs and GPUs. It provides hassle-free AI inferencing for any model, any hardware, anywhere, with ultrafast turnkey inference microservices. The platform enables users to deploy, manage, observe, and scale AI models effortlessly, reducing deployment costs and time-to-value significantly.

Tensoic AI
Tensoic AI is an AI tool designed for custom Large Language Models (LLMs) fine-tuning and inference. It offers ultra-fast fine-tuning and inference capabilities for enterprise-grade LLMs, with a focus on use case-specific tasks. The tool is efficient, cost-effective, and easy to use, enabling users to outperform general-purpose LLMs using synthetic data. Tensoic AI generates small, powerful models that can run on consumer-grade hardware, making it ideal for a wide range of applications.
Cerebras
Cerebras is an AI tool that offers products and services related to AI supercomputers, cloud system processors, and applications for various industries. It provides high-performance computing solutions, including large language models, and caters to sectors such as health, energy, government, scientific computing, and financial services. Cerebras specializes in AI model services, offering state-of-the-art models and training services for tasks like multi-lingual chatbots and DNA sequence prediction. The platform also features the Cerebras Model Zoo, an open-source repository of AI models for developers and researchers.
Anycores
Anycores is an AI tool designed to optimize the performance of deep neural networks and reduce the cost of running AI models in the cloud. It offers a platform that provides automated solutions for tuning and inference consultation, optimized networks zoo, and platform for reducing AI model cost. Anycores focuses on faster execution, reducing inference time over 10x times, and footprint reduction during model deployment. It is device agnostic, supporting Nvidia, AMD GPUs, Intel, ARM, AMD CPUs, servers, and edge devices. The tool aims to provide highly optimized, low footprint networks tailored to specific deployment scenarios.
NeuReality
NeuReality is an AI-centric solution designed to democratize AI adoption by providing purpose-built tools for deploying and scaling inference workflows. Their innovative AI-centric architecture combines hardware and software components to optimize performance and scalability. The platform offers a one-stop shop for AI inference, addressing barriers to AI adoption and streamlining computational processes. NeuReality's tools enable users to deploy, afford, use, and manage AI more efficiently, making AI easy and accessible for a wide range of applications.
Qualcomm AI Hub
Qualcomm AI Hub is a platform that allows users to run AI models on Snapdragon® 8 Elite devices. It provides a collaborative ecosystem for model makers, cloud providers, runtime, and SDK partners to deploy on-device AI solutions quickly and efficiently. Users can bring their own models, optimize for deployment, and access a variety of AI services and resources. The platform caters to various industries such as mobile, automotive, and IoT, offering a range of models and services for edge computing.
Cast AI
Cast AI is an intelligent Kubernetes automation platform that offers live migration for AWS EKS, enabling users to migrate stateful workloads with zero downtime. The platform provides application performance automation by automating and optimizing the entire application stack, including Kubernetes cluster optimization, security, workload optimization, LLM optimization for AIOps, cost monitoring, and database optimization. Cast AI integrates with various cloud services and tools, offering solutions for migration of stateful workloads, inference at scale, and cutting AI costs without sacrificing scale. The platform helps users improve performance, reduce costs, and boost productivity through end-to-end application performance automation.

Cortex Labs
Cortex Labs is a decentralized world computer that enables AI and AI-powered decentralized applications (dApps) to run on the blockchain. It offers a Layer2 solution called ZkMatrix, which utilizes zkRollup technology to enhance transaction speed and reduce fees. Cortex Virtual Machine (CVM) supports on-chain AI inference using GPU, ensuring deterministic results across computing environments. Cortex also enables machine learning in smart contracts and dApps, fostering an open-source ecosystem for AI researchers and developers to share models. The platform aims to solve the challenge of on-chain machine learning execution efficiently and deterministically, providing tools and resources for developers to integrate AI into blockchain applications.
Inworld
Inworld is an AI framework designed for games and media, offering a production-ready framework for building AI agents with client-side logic and local model inference. It provides tools optimized for real-time data ingestion, low latency, and massive scale, enabling developers to create engaging and immersive experiences for users. Inworld allows for building custom AI agent pipelines, refining agent behavior and performance, and seamlessly transitioning from prototyping to production. With support for C++, Python, and game engines, Inworld aims to future-proof AI development by integrating 3rd-party components and foundational models to avoid vendor lock-in.
Together AI
Together AI is an AI Acceleration Cloud platform that offers fast inference, fine-tuning, and training services. It provides self-service NVIDIA GPUs, model deployment on custom hardware, AI chat app, code execution sandbox, and tools to find the right model for specific use cases. The platform also includes a model library with open-source models, documentation for developers, and resources for advancing open-source AI. Together AI enables users to leverage pre-trained models, fine-tune them, or build custom models from scratch, catering to various generative AI needs.
19 - Open Source AI Tools
edgen
Edgen is a local GenAI API server that serves as a drop-in replacement for OpenAI's API. It provides multi-endpoint support for chat completions and speech-to-text, is model agnostic, offers optimized inference, and features model caching. Built in Rust, Edgen is natively compiled for Windows, MacOS, and Linux, eliminating the need for Docker. It allows users to utilize GenAI locally on their devices for free and with data privacy. With features like session caching, GPU support, and support for various endpoints, Edgen offers a scalable, reliable, and cost-effective solution for running GenAI applications locally.

easydist
EasyDist is an automated parallelization system and infrastructure designed for multiple ecosystems. It offers usability by making parallelizing training or inference code effortless with just a single line of change. It ensures ecological compatibility by serving as a centralized source of truth for SPMD rules at the operator-level for various machine learning frameworks. EasyDist decouples auto-parallel algorithms from specific frameworks and IRs, allowing for the development and benchmarking of different auto-parallel algorithms in a flexible manner. The architecture includes MetaOp, MetaIR, and the ShardCombine Algorithm for SPMD sharding rules without manual annotations.

Awesome_LLM_System-PaperList
Since the emergence of chatGPT in 2022, the acceleration of Large Language Model has become increasingly important. Here is a list of papers on LLMs inference and serving.

LLM-Viewer
LLM-Viewer is a tool for visualizing Language and Learning Models (LLMs) and analyzing performance on different hardware platforms. It enables network-wise analysis, considering factors such as peak memory consumption and total inference time cost. With LLM-Viewer, users can gain valuable insights into LLM inference and performance optimization. The tool can be used in a web browser or as a command line interface (CLI) for easy configuration and visualization. The ongoing project aims to enhance features like showing tensor shapes, expanding hardware platform compatibility, and supporting more LLMs with manual model graph configuration.

ServerlessLLM
ServerlessLLM is a fast, affordable, and easy-to-use library designed for multi-LLM serving, optimized for environments with limited GPU resources. It supports loading various leading LLM inference libraries, achieving fast load times, and reducing model switching overhead. The library facilitates easy deployment via Ray Cluster and Kubernetes, integrates with the OpenAI Query API, and is actively maintained by contributors.
sarathi-serve
Sarathi-Serve is the official OSDI'24 artifact submission for paper #444, focusing on 'Taming Throughput-Latency Tradeoff in LLM Inference'. It is a research prototype built on top of CUDA 12.1, designed to optimize throughput-latency tradeoff in Large Language Models (LLM) inference. The tool provides a Python environment for users to install and reproduce results from the associated experiments. Users can refer to specific folders for individual figures and are encouraged to cite the paper if they use the tool in their work.

aphrodite-engine
Aphrodite is the official backend engine for PygmalionAI, serving as the inference endpoint for the website. It allows serving Hugging Face-compatible models with fast speeds. Features include continuous batching, efficient K/V management, optimized CUDA kernels, quantization support, distributed inference, and 8-bit KV Cache. The engine requires Linux OS and Python 3.8 to 3.12, with CUDA >= 11 for build requirements. It supports various GPUs, CPUs, TPUs, and Inferentia. Users can limit GPU memory utilization and access full commands via CLI.
uTensor
uTensor is an extremely light-weight machine learning inference framework built on Tensorflow and optimized for Arm targets. It consists of a runtime library and an offline tool that handles most of the model translation work. The core runtime is only ~2KB. The workflow involves constructing and training a model in Tensorflow, then using uTensor to produce C++ code for inferencing. The runtime ensures system safety, guarantees RAM usage, and focuses on clear, concise, and debuggable code. The high-level API simplifies tensor handling and operator execution for embedded systems.
edgeai
Embedded inference of Deep Learning models is quite challenging due to high compute requirements. TI’s Edge AI software product helps optimize and accelerate inference on TI’s embedded devices. It supports heterogeneous execution of DNNs across cortex-A based MPUs, TI’s latest generation C7x DSP, and DNN accelerator (MMA). The solution simplifies the product life cycle of DNN development and deployment by providing a rich set of tools and optimized libraries.
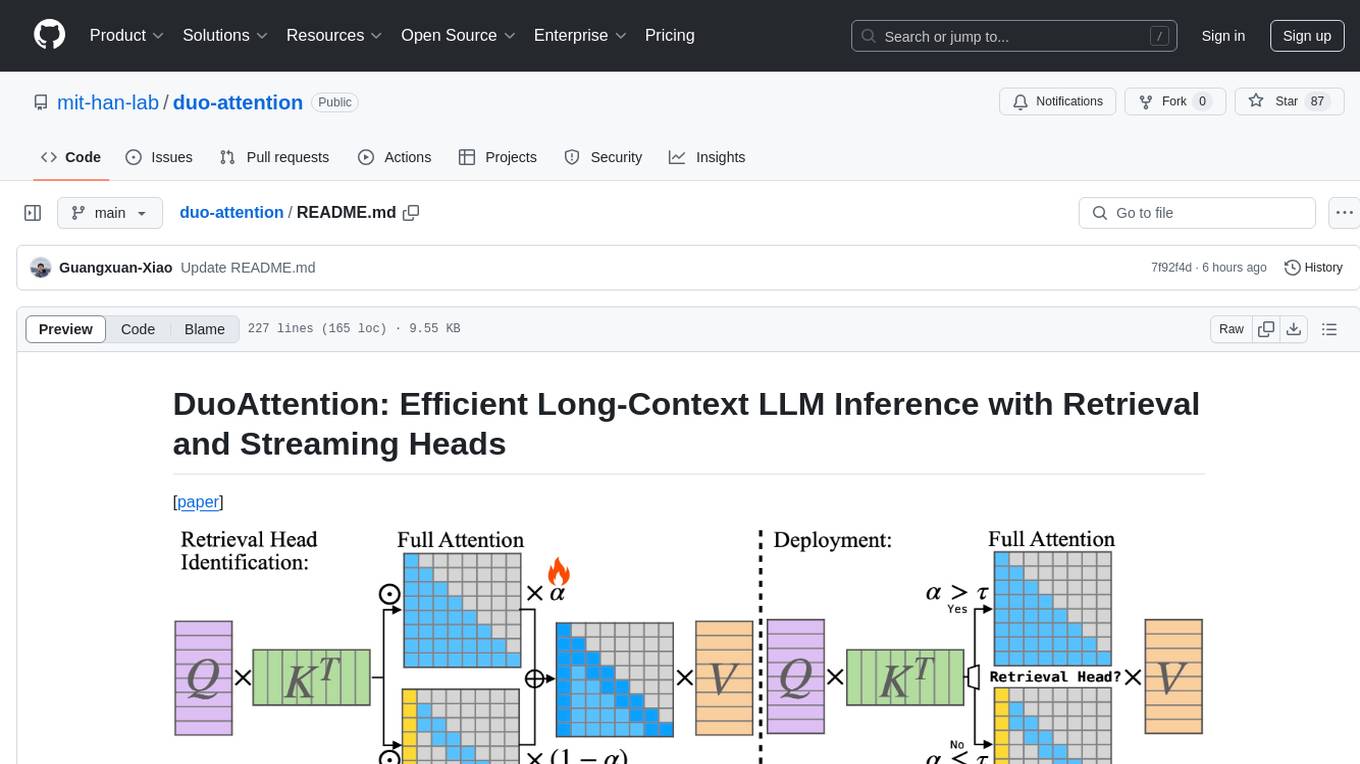
duo-attention
DuoAttention is a framework designed to optimize long-context large language models (LLMs) by reducing memory and latency during inference without compromising their long-context abilities. It introduces a concept of Retrieval Heads and Streaming Heads to efficiently manage attention across tokens. By applying a full Key and Value (KV) cache to retrieval heads and a lightweight, constant-length KV cache to streaming heads, DuoAttention achieves significant reductions in memory usage and decoding time for LLMs. The framework uses an optimization-based algorithm with synthetic data to accurately identify retrieval heads, enabling efficient inference with minimal accuracy loss compared to full attention. DuoAttention also supports quantization techniques for further memory optimization, allowing for decoding of up to 3.3 million tokens on a single GPU.
Awesome-Efficient-AIGC
This repository, Awesome Efficient AIGC, collects efficient approaches for AI-generated content (AIGC) to cope with its huge demand for computing resources. It includes efficient Large Language Models (LLMs), Diffusion Models (DMs), and more. The repository is continuously improving and welcomes contributions of works like papers and repositories that are missed by the collection.
nncf
Neural Network Compression Framework (NNCF) provides a suite of post-training and training-time algorithms for optimizing inference of neural networks in OpenVINO™ with a minimal accuracy drop. It is designed to work with models from PyTorch, TorchFX, TensorFlow, ONNX, and OpenVINO™. NNCF offers samples demonstrating compression algorithms for various use cases and models, with the ability to add different compression algorithms easily. It supports GPU-accelerated layers, distributed training, and seamless combination of pruning, sparsity, and quantization algorithms. NNCF allows exporting compressed models to ONNX or TensorFlow formats for use with OpenVINO™ toolkit, and supports Accuracy-Aware model training pipelines via Adaptive Compression Level Training and Early Exit Training.
LLMs-Zero-to-Hero
LLMs-Zero-to-Hero is a repository dedicated to training large language models (LLMs) from scratch, covering topics such as dense models, MOE models, pre-training, supervised fine-tuning, direct preference optimization, reinforcement learning from human feedback, and deploying large models. The repository provides detailed learning notes for different chapters, code implementations, and resources for training and deploying LLMs. It aims to guide users from being beginners to proficient in building and deploying large language models.

aphrodite-engine
Aphrodite is an inference engine optimized for serving HuggingFace-compatible models at scale. It leverages vLLM's Paged Attention technology to deliver high-performance model inference for multiple concurrent users. The engine supports continuous batching, efficient key/value management, optimized CUDA kernels, quantization support, distributed inference, and modern samplers. It can be easily installed and launched, with Docker support for deployment. Aphrodite requires Linux or Windows OS, Python 3.8 to 3.12, and CUDA >= 11. It is designed to utilize 90% of GPU VRAM but offers options to limit memory usage. Contributors are welcome to enhance the engine.

llmaz
llmaz is an easy, advanced inference platform for large language models on Kubernetes. It aims to provide a production-ready solution that integrates with state-of-the-art inference backends. The platform supports efficient model distribution, accelerator fungibility, SOTA inference, various model providers, multi-host support, and scaling efficiency. Users can quickly deploy LLM services with minimal configurations and benefit from a wide range of advanced inference backends. llmaz is designed to optimize cost and performance while supporting cutting-edge researches like Speculative Decoding or Splitwise on Kubernetes.

xllm
xLLM is an efficient LLM inference framework optimized for Chinese AI accelerators, enabling enterprise-grade deployment with enhanced efficiency and reduced cost. It adopts a service-engine decoupled inference architecture, achieving breakthrough efficiency through technologies like elastic scheduling, dynamic PD disaggregation, multi-stream parallel computing, graph fusion optimization, and global KV cache management. xLLM supports deployment of mainstream large models on Chinese AI accelerators, empowering enterprises in scenarios like intelligent customer service, risk control, supply chain optimization, ad recommendation, and more.
Awesome-LLM-Ensemble
Awesome-LLM-Ensemble is a collection of papers on LLM Ensemble, focusing on the comprehensive use of multiple large language models to benefit from their individual strengths. It provides a systematic review of recent developments in LLM Ensemble, including taxonomy, methods for ensemble before, during, and after inference, benchmarks, applications, and related surveys.
llm-d-kv-cache-manager
Efficiently caching Key & Value (KV) tensors is crucial for optimizing LLM inference. Reusing the KV-Cache significantly improves Time To First Token (TTFT) and overall throughput, maximizing system resource-utilization. `llm-d-kv-cache-manager` is a pluggable service enabling KV-Cache Aware Routing for vLLM-based serving platforms, with a high-performance KV-Cache Indexer component tracking KV-Block locality across vLLM pods. It provides intelligent routing for optimal KV-cache-aware placement decisions.
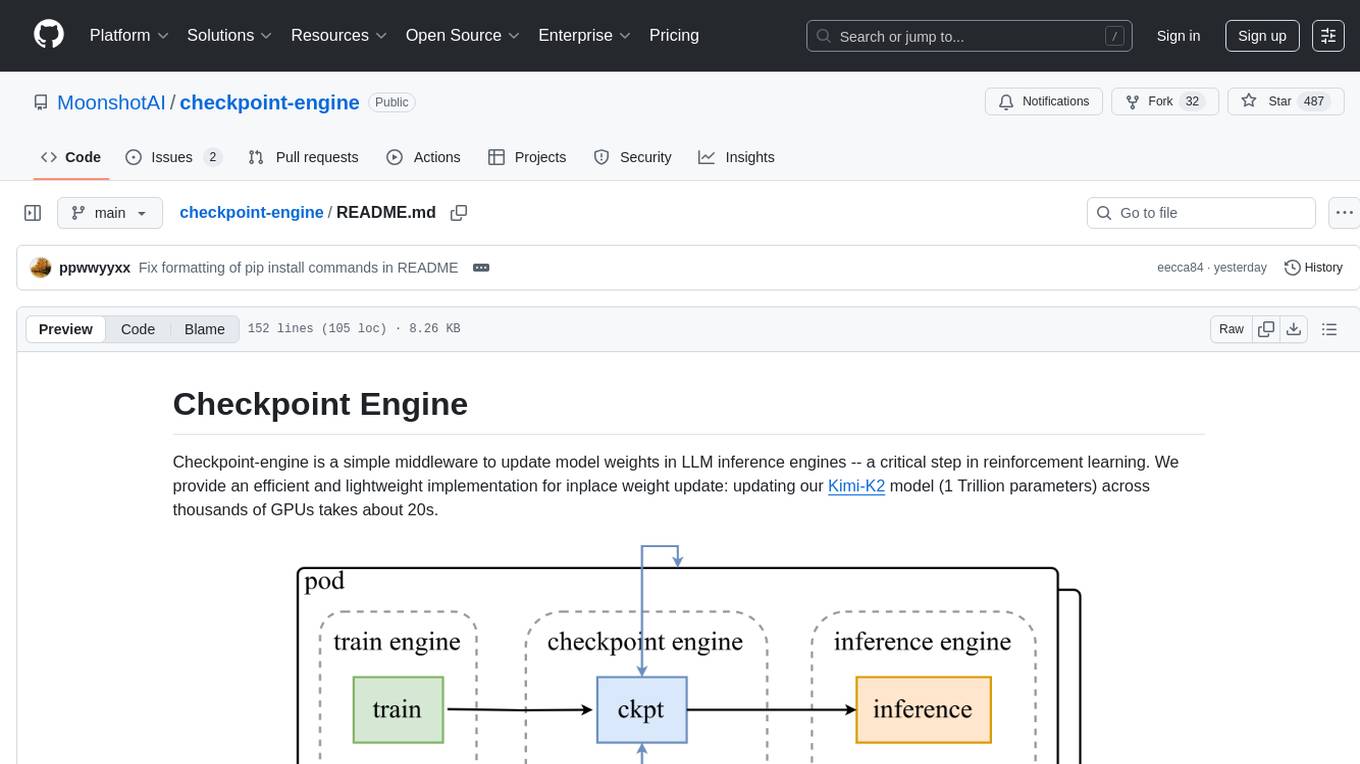
checkpoint-engine
Checkpoint-engine is a middleware tool designed for updating model weights in LLM inference engines efficiently. It provides implementations for both Broadcast and P2P weight update methods, orchestrating the transfer process and controlling the inference engine through ZeroMQ socket. The tool optimizes weight broadcast by arranging data transfer into stages and organizing transfers into a pipeline for performance. It supports flexible installation options and is tested with various models and device setups. Checkpoint-engine also allows reusing weights from existing instances and provides a patch for FP8 quantization in vLLM.
20 - OpenAI Gpts



InsightIQ - Influencer Marketing
Find influencers across Instagram, TikTok, and YouTube whose audience aligns with your target demographic to effectively engage with your customers.

Social Media Assistant - videos & trends
Explore TikTok & social media trends, make effective videos, and optimize your content for virality. Previously called "Viral Video Generator by trendup".
Hashtagger
I suggest trending hashtags for social media posts based on content and platform.


Xアカウント分析GPTs
X(旧Twitter)アカウントの運用に関する専門的なアドバイスを提供するために設計されています。ユーザーが持つXアカウントのデータを分析し、エンゲージメントの向上、フォロワーの興味が高いトピックの把握、最適な投稿時間の特定などを行うことで、効果的なソーシャルメディア戦略を構築をサポートします。具体的には、ユーザーから提供されるXのアナリティクスデータを元に、高いエンゲージメントを得たツイートの特徴やエンゲージメントが低いツイートの改善点、インプレッションが高いツイートの分析などを行います。
Tweet Composer
I assist with composing impactful tweets on X aka. Twitter, suggesting hashtags, and optimal posting times.



VlogGPT
Maximize your vlog's potential with VlogGPT! Get innovative content ideas, audience growth strategies, and insights to create a top vlog on YouTube and more.