
checkpoint-engine
Checkpoint-engine is a simple middleware to update model weights in LLM inference engines
Stars: 730
Checkpoint-engine is a middleware tool designed for updating model weights in LLM inference engines efficiently. It provides implementations for both Broadcast and P2P weight update methods, orchestrating the transfer process and controlling the inference engine through ZeroMQ socket. The tool optimizes weight broadcast by arranging data transfer into stages and organizing transfers into a pipeline for performance. It supports flexible installation options and is tested with various models and device setups. Checkpoint-engine also allows reusing weights from existing instances and provides a patch for FP8 quantization in vLLM.
README:
Checkpoint-engine is a simple middleware to update model weights in LLM inference engines -- a critical step in reinforcement learning. We provide an efficient and lightweight implementation for inplace weight update: updating our Kimi-K2 model (1 Trillion parameters) across thousands of GPUs takes about 20s.

The core weight update logic is in ParameterServer class, a service colocated with inference engines. It provides two implementations of weight update: Broadcast and P2P.
-
Broadcast: Used when a large number of inference instances need to update weights in synchronous. This is the fastest implementation and should be used as the default update method. See
_update_per_bucket. -
P2P: Used when new inference instances are dynamically added (due to restarts or dynamic availability) while the existing instances are already serving requests. Under this scenario, to avoid affecting the workloads on existing instances, we use the
mooncake-transfer-engineto P2P send weights from CPUs in existing instances to GPUs in new instances. See_update_per_bucket_p2p.
In the Broadcast implementation, the checkpoint-engine holds references to sharded weights in CPU memory, and need to efficiently broadcast them to a cluster of inference instances, often under a different sharding pattern. We arrange the data transfer into 3 stages:
- H2D: moving weights to GPU memory. These weights may come from disk or the training engine.
- broadcast: broadcast among checkpoint engine workers; the data results in a CUDA IPC buffer shared with inference engine.
- reload: inference engine decides what subset of weights to copy from the broadcasted data.
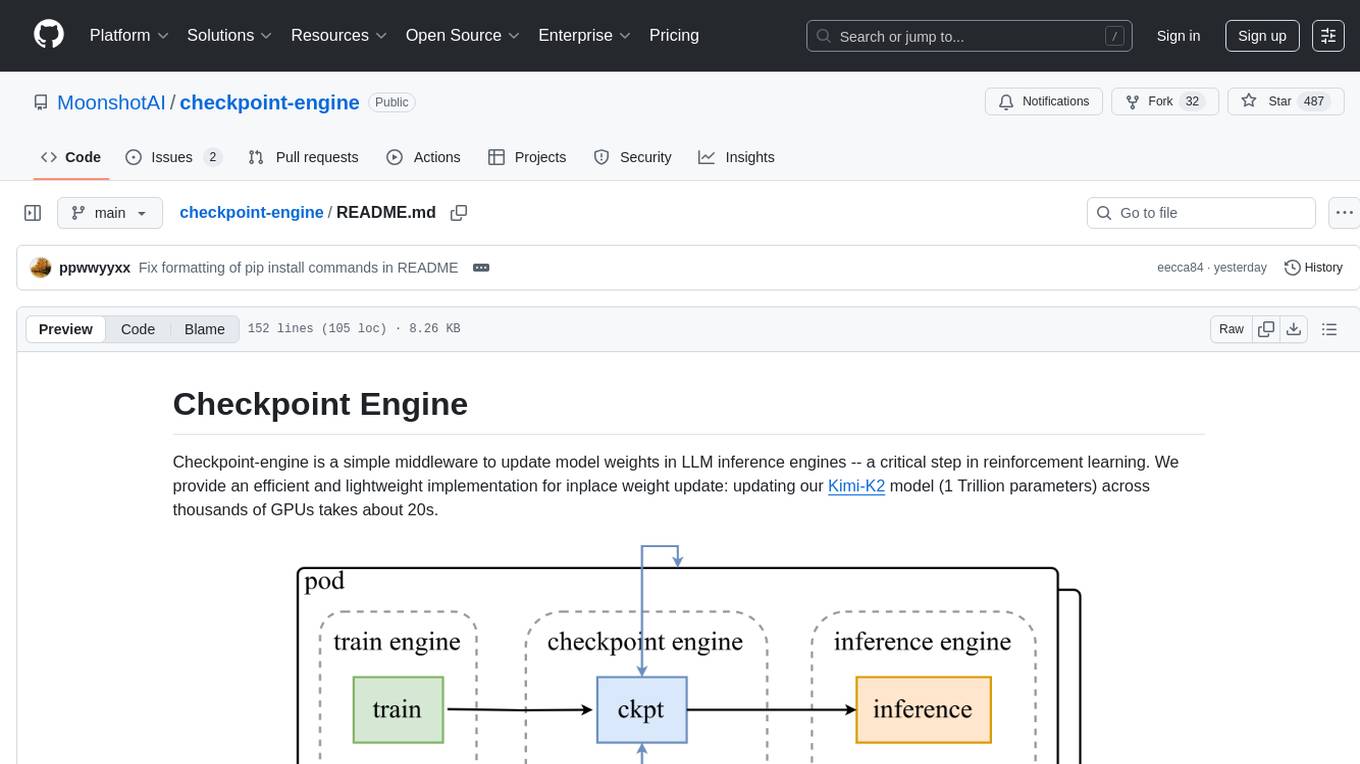
Checkpoint-engine orchestrates the entire transfer process. It first gathers necessary metadata to create a plan, including deciding the proper bucket size for data transfer. It then executes the transfer, where it controls the inference engine through a ZeroMQ socket. To maximize performance, it organizes the data transfers into a pipeline with overlapped communication and copy, illustrated below. The details can be found in Kimi-K2 Technical Report.

Pipelining naturally requires more GPU memory. When memory is not enough, checkpoint-engine will fallback to serial execution.
| Model | Device Info | GatherMetas | Update (Broadcast) | Update (P2P) |
|---|---|---|---|---|
| GLM-4.5-Air (BF16) | 8xH800 TP8 | 0.17s | 3.94s (1.42GiB) | 8.83s (4.77GiB) |
| Qwen3-235B-A22B-Instruct-2507 (BF16) | 8xH800 TP8 | 0.46s | 6.75s (2.69GiB) | 16.47s (4.05GiB) |
| DeepSeek-V3.1 (FP8) | 16xH20 TP16 | 1.44s | 12.22s (2.38GiB) | 25.77s (3.61GiB) |
| Kimi-K2-Instruct (FP8) | 16xH20 TP16 | 1.81s | 15.45s (2.93GiB) | 36.24s (4.46GiB) |
| DeepSeek-V3.1 (FP8) | 256xH20 TP16 | 1.40s | 13.88s (2.54GiB) | 33.30s (3.86 GiB) |
| Kimi-K2-Instruct (FP8) | 256xH20 TP16 | 1.88s | 21.50s (2.99GiB) | 34.49s (4.57 GiB) |
All results above are tested by examples/update.py and use vLLM v0.10.2rc1 as inference engine. Some notes:
- FP8 test needs additional vLLM patches, see FP8 quantization.
- Device Info: we tested various combination of devices and parallelism setups. For example, a 256-GPU TP16 setup means that we deploy 16 vLLM instances, each with 16-way tensor parallelism.
- Since update duration is related to IPC bucket size, we provide the bucket size in the table.
- The P2P time were tested for updating no more than two nodes (16 GPUs) (
ParameterServer.update(ranks=range(0, 16))) out of the entire cluster.
Use the fastest broadcast implementation
pip install checkpoint-engineUse the flexible P2P implementation, notice this will install mooncake-transfer-engine to support RDMA transfer between different ranks.
pip install 'checkpoint-engine[p2p]'If set NCCL_IB_HCA env, checkpoint-engine will use it to auto select net devices for different ranks. If not set, it will read all RDMA devices and try to divide them into each rank.
Prepare an H800 or H20 machine with 8 GPUs with latest vLLM. Be sure to include /collective_rpc API endpoint commit (available in main branch) since checkpoint-engine will use this endpoint to update weights.
cd /opt && git clone https://github.com/vllm-project/vllm && cd vllm
uv venv --python 3.12 --seed
source .venv/bin/activate
VLLM_USE_PRECOMPILED=1 uv pip install --editable .Install checkpoint-engine
uv pip install 'checkpoint-engine[p2p]'We use Qwen/Qwen3-235B-A22B-Instruct-2507 (BF16) as the test model
hf download Qwen/Qwen3-235B-A22B-Instruct-2507 --local-dir /opt/models/Qwen/Qwen3-235B-A22B-Instruct-2507/Start vLLM in dev mode and set --load-format dummy. Notice that we also set --worker-extension-cls=checkpoint_engine.worker.VllmColocateWorkerExtension
VLLM_SERVER_DEV_MODE=1 python3 -m vllm.entrypoints.openai.api_server --host 0.0.0.0 --port 19730 --trust-remote-code \
--tensor-parallel-size=8 --max-model-len 4096 --load-format dummy \
--served-model-name checkpoint-engine-demo --model /opt/models/Qwen/Qwen3-235B-A22B-Instruct-2507/ \
--worker-extension-cls checkpoint_engine.worker.VllmColocateWorkerExtensionMeanwhile, use this command to update weights by checkpoint-engine. No need to wait for vLLM to get ready.
torchrun --nproc-per-node 8 examples/update.py --update-method all --checkpoint-path /opt/models/Qwen/Qwen3-235B-A22B-Instruct-2507/New checkpoint-engine instances can join existing instances and reuse their weights. This is simple to achieve.
First, start the existing instances with --save-metas-file global_metas.pkl to save global metas to a file and use --sleep-time 300 to make sure they stay alive.
torchrun --nproc-per-node 8 examples/update.py --checkpoint-path $MODEL_PATH \
--sleep-time 300 --save-metas-file global_metas.pklAfter a checkpoint is registered, new instances can obtain a copy of the checkpoint by setting --load-metas-file global_metas.pkl.
torchrun --nproc-per-node 8 examples/update.py --load-metas-file global_metas.pklFP8 quantization currently do not natively work in vLLM when updating weights.
We provide a simple patch in patches/vllm_fp8.patch to handle the correct weight update.
Notice this patch is only tested in DeepSeek-V3.1 and Kimi-K2. Other models may meet some compatible issues.
A PR is opened to the vLLM project and waiting to discuss and review.
Run a simple correctness test for checkpoint_engine
torchrun --nproc-per-node 8 tests/test_update.py- This project is currently only tested with vLLM. But it is easy to integrate with other frameworks like SGLang.
- The perfect three-stage pipeline mentioned in our paper is currently not implemented. This could be useful for architectures where H2D and broadcast do not conflict in PCIE.
- The P2P update method is currently not the optimal implementation since it will receive data only in rank 0 and broadcast to others synchronizely. This is a potential optimization in the future.
This open source project uses the same vLLM interface in https://github.com/vllm-project/vllm/pull/24295 . Thanks for the comments and insights from youkaichao.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for checkpoint-engine
Similar Open Source Tools
checkpoint-engine
Checkpoint-engine is a middleware tool designed for updating model weights in LLM inference engines efficiently. It provides implementations for both Broadcast and P2P weight update methods, orchestrating the transfer process and controlling the inference engine through ZeroMQ socket. The tool optimizes weight broadcast by arranging data transfer into stages and organizing transfers into a pipeline for performance. It supports flexible installation options and is tested with various models and device setups. Checkpoint-engine also allows reusing weights from existing instances and provides a patch for FP8 quantization in vLLM.

uzu
uzu is a high-performance inference engine for AI models on Apple Silicon. It features a simple, high-level API, hybrid architecture for GPU kernel computation, unified model configurations, traceable computations, and utilizes unified memory on Apple devices. The tool provides a CLI mode for running models, supports its own model format, and offers prebuilt Swift and TypeScript frameworks for bindings. Users can quickly start by adding the uzu dependency to their Cargo.toml and creating an inference Session with a specific model and configuration. Performance benchmarks show metrics for various models on Apple M2, highlighting the tokens/s speed for each model compared to llama.cpp with bf16/f16 precision.

ml-retreat
ML-Retreat is a comprehensive machine learning library designed to simplify and streamline the process of building and deploying machine learning models. It provides a wide range of tools and utilities for data preprocessing, model training, evaluation, and deployment. With ML-Retreat, users can easily experiment with different algorithms, hyperparameters, and feature engineering techniques to optimize their models. The library is built with a focus on scalability, performance, and ease of use, making it suitable for both beginners and experienced machine learning practitioners.
ai-edge-quantizer
AI Edge Quantizer is a tool designed for advanced developers to quantize converted LiteRT models. It aims to optimize performance on resource-demanding models by providing quantization recipes for edge device deployment. The tool supports dynamic quantization, weight-only quantization, and static quantization methods, allowing users to customize the quantization process for different hardware deployments. Users can specify quantization recipes to apply to source models, resulting in quantized LiteRT models ready for deployment. The tool also includes advanced features such as selective quantization and mixed precision schemes for fine-tuning quantization recipes.
milvus
Milvus is an open-source vector database built to power embedding similarity search and AI applications. Milvus makes unstructured data search more accessible, and provides a consistent user experience regardless of the deployment environment. Milvus 2.0 is a cloud-native vector database with storage and computation separated by design. All components in this refactored version of Milvus are stateless to enhance elasticity and flexibility. For more architecture details, see Milvus Architecture Overview. Milvus was released under the open-source Apache License 2.0 in October 2019. It is currently a graduate project under LF AI & Data Foundation.

auto-round
AutoRound is an advanced weight-only quantization algorithm for low-bits LLM inference. It competes impressively against recent methods without introducing any additional inference overhead. The method adopts sign gradient descent to fine-tune rounding values and minmax values of weights in just 200 steps, often significantly outperforming SignRound with the cost of more tuning time for quantization. AutoRound is tailored for a wide range of models and consistently delivers noticeable improvements.
graphbit
GraphBit is an industry-grade agentic AI framework built for developers and AI teams that demand stability, scalability, and low resource usage. It is written in Rust for maximum performance and safety, delivering significantly lower CPU usage and memory footprint compared to leading alternatives. The framework is designed to run multi-agent workflows in parallel, persist memory across steps, recover from failures, and ensure 100% task success under load. With lightweight architecture, observability, and concurrency support, GraphBit is suitable for deployment in high-scale enterprise environments and low-resource edge scenarios.

deepteam
Deepteam is a powerful open-source tool designed for deep learning projects. It provides a user-friendly interface for training, testing, and deploying deep neural networks. With Deepteam, users can easily create and manage complex models, visualize training progress, and optimize hyperparameters. The tool supports various deep learning frameworks and allows seamless integration with popular libraries like TensorFlow and PyTorch. Whether you are a beginner or an experienced deep learning practitioner, Deepteam simplifies the development process and accelerates model deployment.

deeppowers
Deeppowers is a powerful Python library for deep learning applications. It provides a wide range of tools and utilities to simplify the process of building and training deep neural networks. With Deeppowers, users can easily create complex neural network architectures, perform efficient training and optimization, and deploy models for various tasks. The library is designed to be user-friendly and flexible, making it suitable for both beginners and experienced deep learning practitioners.
verl-tool
The verl-tool is a versatile command-line utility designed to streamline various tasks related to version control and code management. It provides a simple yet powerful interface for managing branches, merging changes, resolving conflicts, and more. With verl-tool, users can easily track changes, collaborate with team members, and ensure code quality throughout the development process. Whether you are a beginner or an experienced developer, verl-tool offers a seamless experience for version control operations.
FLAME
FLAME is a lightweight and efficient deep learning framework designed for edge devices. It provides a simple and user-friendly interface for developing and deploying deep learning models on resource-constrained devices. With FLAME, users can easily build and optimize neural networks for tasks such as image classification, object detection, and natural language processing. The framework supports various neural network architectures and optimization techniques, making it suitable for a wide range of applications in the field of edge computing.

vllm
vLLM is a fast and easy-to-use library for LLM inference and serving. It is designed to be efficient, flexible, and easy to use. vLLM can be used to serve a variety of LLM models, including Hugging Face models. It supports a variety of decoding algorithms, including parallel sampling, beam search, and more. vLLM also supports tensor parallelism for distributed inference and streaming outputs. It is open-source and available on GitHub.
airllm
AirLLM is a tool that optimizes inference memory usage, enabling large language models to run on low-end GPUs without quantization, distillation, or pruning. It supports models like Llama3.1 on 8GB VRAM. The tool offers model compression for up to 3x inference speedup with minimal accuracy loss. Users can specify compression levels, profiling modes, and other configurations when initializing models. AirLLM also supports prefetching and disk space management. It provides examples and notebooks for easy implementation and usage.
trae-agent
Trae-agent is a Python library for building and training reinforcement learning agents. It provides a simple and flexible framework for implementing various reinforcement learning algorithms and experimenting with different environments. With Trae-agent, users can easily create custom agents, define reward functions, and train them on a variety of tasks. The library also includes utilities for visualizing agent performance and analyzing training results, making it a valuable tool for both beginners and experienced researchers in the field of reinforcement learning.
ktransformers
KTransformers is a flexible Python-centric framework designed to enhance the user's experience with advanced kernel optimizations and placement/parallelism strategies for Transformers. It provides a Transformers-compatible interface, RESTful APIs compliant with OpenAI and Ollama, and a simplified ChatGPT-like web UI. The framework aims to serve as a platform for experimenting with innovative LLM inference optimizations, focusing on local deployments constrained by limited resources and supporting heterogeneous computing opportunities like GPU/CPU offloading of quantized models.
Fast-LLM
Fast-LLM is an open-source library designed for training large language models with exceptional speed, scalability, and flexibility. Built on PyTorch and Triton, it offers optimized kernel efficiency, reduced overheads, and memory usage, making it suitable for training models of all sizes. The library supports distributed training across multiple GPUs and nodes, offers flexibility in model architectures, and is easy to use with pre-built Docker images and simple configuration. Fast-LLM is licensed under Apache 2.0, developed transparently on GitHub, and encourages contributions and collaboration from the community.
For similar tasks
edgen
Edgen is a local GenAI API server that serves as a drop-in replacement for OpenAI's API. It provides multi-endpoint support for chat completions and speech-to-text, is model agnostic, offers optimized inference, and features model caching. Built in Rust, Edgen is natively compiled for Windows, MacOS, and Linux, eliminating the need for Docker. It allows users to utilize GenAI locally on their devices for free and with data privacy. With features like session caching, GPU support, and support for various endpoints, Edgen offers a scalable, reliable, and cost-effective solution for running GenAI applications locally.

easydist
EasyDist is an automated parallelization system and infrastructure designed for multiple ecosystems. It offers usability by making parallelizing training or inference code effortless with just a single line of change. It ensures ecological compatibility by serving as a centralized source of truth for SPMD rules at the operator-level for various machine learning frameworks. EasyDist decouples auto-parallel algorithms from specific frameworks and IRs, allowing for the development and benchmarking of different auto-parallel algorithms in a flexible manner. The architecture includes MetaOp, MetaIR, and the ShardCombine Algorithm for SPMD sharding rules without manual annotations.

Awesome_LLM_System-PaperList
Since the emergence of chatGPT in 2022, the acceleration of Large Language Model has become increasingly important. Here is a list of papers on LLMs inference and serving.

LLM-Viewer
LLM-Viewer is a tool for visualizing Language and Learning Models (LLMs) and analyzing performance on different hardware platforms. It enables network-wise analysis, considering factors such as peak memory consumption and total inference time cost. With LLM-Viewer, users can gain valuable insights into LLM inference and performance optimization. The tool can be used in a web browser or as a command line interface (CLI) for easy configuration and visualization. The ongoing project aims to enhance features like showing tensor shapes, expanding hardware platform compatibility, and supporting more LLMs with manual model graph configuration.

ServerlessLLM
ServerlessLLM is a fast, affordable, and easy-to-use library designed for multi-LLM serving, optimized for environments with limited GPU resources. It supports loading various leading LLM inference libraries, achieving fast load times, and reducing model switching overhead. The library facilitates easy deployment via Ray Cluster and Kubernetes, integrates with the OpenAI Query API, and is actively maintained by contributors.
sarathi-serve
Sarathi-Serve is the official OSDI'24 artifact submission for paper #444, focusing on 'Taming Throughput-Latency Tradeoff in LLM Inference'. It is a research prototype built on top of CUDA 12.1, designed to optimize throughput-latency tradeoff in Large Language Models (LLM) inference. The tool provides a Python environment for users to install and reproduce results from the associated experiments. Users can refer to specific folders for individual figures and are encouraged to cite the paper if they use the tool in their work.

aphrodite-engine
Aphrodite is the official backend engine for PygmalionAI, serving as the inference endpoint for the website. It allows serving Hugging Face-compatible models with fast speeds. Features include continuous batching, efficient K/V management, optimized CUDA kernels, quantization support, distributed inference, and 8-bit KV Cache. The engine requires Linux OS and Python 3.8 to 3.12, with CUDA >= 11 for build requirements. It supports various GPUs, CPUs, TPUs, and Inferentia. Users can limit GPU memory utilization and access full commands via CLI.
uTensor
uTensor is an extremely light-weight machine learning inference framework built on Tensorflow and optimized for Arm targets. It consists of a runtime library and an offline tool that handles most of the model translation work. The core runtime is only ~2KB. The workflow involves constructing and training a model in Tensorflow, then using uTensor to produce C++ code for inferencing. The runtime ensures system safety, guarantees RAM usage, and focuses on clear, concise, and debuggable code. The high-level API simplifies tensor handling and operator execution for embedded systems.
For similar jobs

llm-resource
llm-resource is a comprehensive collection of high-quality resources for Large Language Models (LLM). It covers various aspects of LLM including algorithms, training, fine-tuning, alignment, inference, data engineering, compression, evaluation, prompt engineering, AI frameworks, AI basics, AI infrastructure, AI compilers, LLM application development, LLM operations, AI systems, and practical implementations. The repository aims to gather and share valuable resources related to LLM for the community to benefit from.

LitServe
LitServe is a high-throughput serving engine designed for deploying AI models at scale. It generates an API endpoint for models, handles batching, streaming, and autoscaling across CPU/GPUs. LitServe is built for enterprise scale with a focus on minimal, hackable code-base without bloat. It supports various model types like LLMs, vision, time-series, and works with frameworks like PyTorch, JAX, Tensorflow, and more. The tool allows users to focus on model performance rather than serving boilerplate, providing full control and flexibility.

how-to-optim-algorithm-in-cuda
This repository documents how to optimize common algorithms based on CUDA. It includes subdirectories with code implementations for specific optimizations. The optimizations cover topics such as compiling PyTorch from source, NVIDIA's reduce optimization, OneFlow's elementwise template, fast atomic add for half data types, upsample nearest2d optimization in OneFlow, optimized indexing in PyTorch, OneFlow's softmax kernel, linear attention optimization, and more. The repository also includes learning resources related to deep learning frameworks, compilers, and optimization techniques.

aiac
AIAC is a library and command line tool to generate Infrastructure as Code (IaC) templates, configurations, utilities, queries, and more via LLM providers such as OpenAI, Amazon Bedrock, and Ollama. Users can define multiple 'backends' targeting different LLM providers and environments using a simple configuration file. The tool allows users to ask a model to generate templates for different scenarios and composes an appropriate request to the selected provider, storing the resulting code to a file and/or printing it to standard output.

ENOVA
ENOVA is an open-source service for Large Language Model (LLM) deployment, monitoring, injection, and auto-scaling. It addresses challenges in deploying stable serverless LLM services on GPU clusters with auto-scaling by deconstructing the LLM service execution process and providing configuration recommendations and performance detection. Users can build and deploy LLM with few command lines, recommend optimal computing resources, experience LLM performance, observe operating status, achieve load balancing, and more. ENOVA ensures stable operation, cost-effectiveness, efficiency, and strong scalability of LLM services.

jina
Jina is a tool that allows users to build multimodal AI services and pipelines using cloud-native technologies. It provides a Pythonic experience for serving ML models and transitioning from local deployment to advanced orchestration frameworks like Docker-Compose, Kubernetes, or Jina AI Cloud. Users can build and serve models for any data type and deep learning framework, design high-performance services with easy scaling, serve LLM models while streaming their output, integrate with Docker containers via Executor Hub, and host on CPU/GPU using Jina AI Cloud. Jina also offers advanced orchestration and scaling capabilities, a smooth transition to the cloud, and easy scalability and concurrency features for applications. Users can deploy to their own cloud or system with Kubernetes and Docker Compose integration, and even deploy to JCloud for autoscaling and monitoring.

vidur
Vidur is a high-fidelity and extensible LLM inference simulator designed for capacity planning, deployment configuration optimization, testing new research ideas, and studying system performance of models under different workloads and configurations. It supports various models and devices, offers chrome trace exports, and can be set up using mamba, venv, or conda. Users can run the simulator with various parameters and monitor metrics using wandb. Contributions are welcome, subject to a Contributor License Agreement and adherence to the Microsoft Open Source Code of Conduct.

AI-System-School
AI System School is a curated list of research in machine learning systems, focusing on ML/DL infra, LLM infra, domain-specific infra, ML/LLM conferences, and general resources. It provides resources such as data processing, training systems, video systems, autoML systems, and more. The repository aims to help users navigate the landscape of AI systems and machine learning infrastructure, offering insights into conferences, surveys, books, videos, courses, and blogs related to the field.