
milvus
Milvus is a high-performance, cloud-native vector database built for scalable vector ANN search
Stars: 42672
Milvus is an open-source vector database built to power embedding similarity search and AI applications. Milvus makes unstructured data search more accessible, and provides a consistent user experience regardless of the deployment environment. Milvus 2.0 is a cloud-native vector database with storage and computation separated by design. All components in this refactored version of Milvus are stateless to enhance elasticity and flexibility. For more architecture details, see Milvus Architecture Overview. Milvus was released under the open-source Apache License 2.0 in October 2019. It is currently a graduate project under LF AI & Data Foundation.
README:


🐦 Milvus is a high-performance vector database built for scale. It powers AI applications by efficiently organizing and searching vast amounts of unstructured data, such as text, images, and multi-modal information.
🧑💻 Written in Go and C++, Milvus implements hardware acceleration for CPU/GPU to achieve best-in-class vector search performance. Thanks to its fully-distributed and K8s-native architecture, Milvus can scale horizontally, handle tens of thousands of search queries on billions of vectors, and keep data fresh with real-time streaming updates. Milvus also supports Standalone mode for single machine deployment. Milvus Lite is a lightweight version good for quickstart in python with pip install.
Want to use Milvus with zero setup? Try out Zilliz Cloud ☁️ for free. Milvus is available as a fully managed service on Zilliz Cloud, with Serverless, Dedicated and BYOC options available.
For questions about how to use Milvus, join the community on Discord to get help. For reporting problems, file bugs and feature requests in GitHub Issues or ask in Discussions.
The Milvus open-source project is under LF AI & Data Foundation, distributed with Apache 2.0 License, with Zilliz as its major contributor.
$ pip install -U pymilvusThis installs pymilvus, the Python SDK for Milvus. Use MilvusClient to create a client:
from pymilvus import MilvusClient-
You can also try Milvus Lite for quickstart by installing
pymilvus[milvus-lite]. To create a local vector database, simply instantiate a client with a local file name for persisting data:client = MilvusClient("milvus_demo.db")
-
You can also specify the credentials to connect to your deployed Milvus server or Zilliz Cloud:
client = MilvusClient( uri="<endpoint_of_self_hosted_milvus_or_zilliz_cloud>", token="<username_and_password_or_zilliz_cloud_api_key>")
With the client, you can create collection:
client.create_collection(
collection_name="demo_collection",
dimension=768, # The vectors we will use in this demo have 768 dimensions
)Ingest data:
res = client.insert(collection_name="demo_collection", data=data)Perform vector search:
query_vectors = embedding_fn.encode_queries(["Who is Alan Turing?", "What is AI?"])
res = client.search(
collection_name="demo_collection", # target collection
data=query_vectors, # a list of one or more query vectors, supports batch
limit=2, # how many results to return (topK)
output_fields=["vector", "text", "subject"], # what fields to return
)Milvus is designed to handle vector search at scale. It stores vectors, which are learned representations of unstructured data, together with other scalar data types such as integers, strings, and JSON objects. Users can conduct efficient vector search with metadata filtering or hybrid search. Here are why developers choose Milvus as the vector database for AI applications:
High Performance at Scale and High Availability
- Milvus features a distributed architecture that separates compute and storage. Milvus can horizontally scale and adapt to diverse traffic patterns, achieving optimal performance by independently increasing query nodes for read-heavy workload and data node for write-heavy workload. The stateless microservices on K8s allow quick recovery from failure, ensuring high availability. The support for replicas further enhances fault tolerance and throughput by loading data segments on multiple query nodes. See benchmark for performance comparison.
Support for Various Vector Index Types and Hardware Acceleration
- Milvus separates the system and core vector search engine, allowing it to support all major vector index types that are optimized for different scenarios, including HNSW, IVF, FLAT (brute-force), SCANN, and DiskANN, with quantization-based variations and mmap. Milvus optimizes vector search for advanced features such as metadata filtering and range search. Additionally, Milvus implements hardware acceleration to enhance vector search performance and supports GPU indexing, such as NVIDIA's CAGRA.
Flexible Multi-tenancy and Hot/Cold Storage
- Milvus supports multi-tenancy through isolation at database, collection, partition, or partition key level. The flexible strategies allow a single cluster to handle hundreds to millions of tenants, also ensures optimized search performance and flexible access control. Milvus enhances cost-effectiveness with hot/cold storage. Frequently accessed hot data can be stored in memory or on SSDs for better performance, while less-accessed cold data is kept on slower, cost-effective storage. This mechanism can significantly reduce costs while maintaining high performance for critical tasks.
Sparse Vector for Full Text Search and Hybrid Search
- In addition to semantic search through dense vector, Milvus also natively supports full text search with BM25 as well as learned sparse embeddings such as SPLADE and BGE-M3. Users can store sparse vectors and dense vectors in the same collection, and define functions to rerank results from multiple search requests. See examples of Hybrid Search with semantic search + full text search.
Data Security and Fine-grain Access Control
- Milvus ensures data security by implementing mandatory user authentication, TLS encryption, and Role-Based Access Control (RBAC). User authentication ensures that only authorized users with valid credentials can access the database, while TLS encryption secures all communications within the network. Additionally, RBAC allows for fine-grained access control by assigning specific permissions to users based on their roles. These features make Milvus a robust and secure choice for enterprise applications, protecting sensitive data from unauthorized access and potential breaches.
Milvus is trusted by AI developers to build applications such as text and image search, Retrieval-Augmented Generation (RAG), and recommendation systems. Milvus powers many mission-critical businesses for startups and enterprises.
Here is a selection of demos and tutorials to show how to build various types of AI applications made with Milvus:
You can explore a comprehensive Tutorials Overview covering topics such as Retrieval-Augmented Generation (RAG), Semantic Search, Hybrid Search, Question Answering, Recommendation Systems, and various quick-start guides. These resources are designed to help you get started quickly and efficiently.
| Tutorial | Use Case | Related Milvus Features |
|---|---|---|
| Build RAG with Milvus | RAG | vector search |
| Advanced RAG Optimizations | RAG | vector search, full text search |
| Full Text Search with Milvus | Text Search | full text search |
| Hybrid Search with Milvus | Hybrid Search | hybrid search, multi vector, dense embedding, sparse embedding |
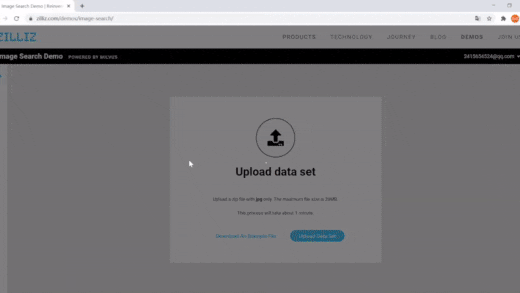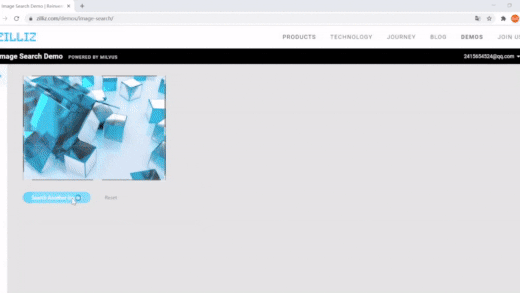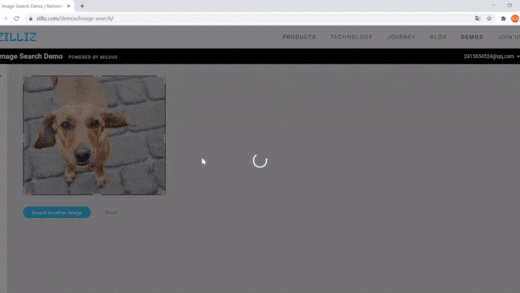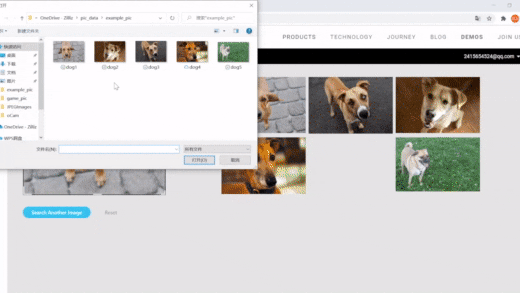
| Image Search with Milvus | Semantic Search | vector search, dynamic field |
| Multimodal Search using Multi Vectors | Semantic Search | multi vector, hybrid search |
| Movie Recommendation with Milvus | Recommendation System | vector search |
| Graph RAG with Milvus | RAG | graph search |
| Contextual Retrieval with Milvus | Quickstart | vector search |
| Vector Visualization | Quickstart | vector search |
| HDBSCAN Clustering with Milvus | Quickstart | vector search |
| Use ColPali for Multi-Modal Retrieval with Milvus | Quickstart | vector search |
|
|
|
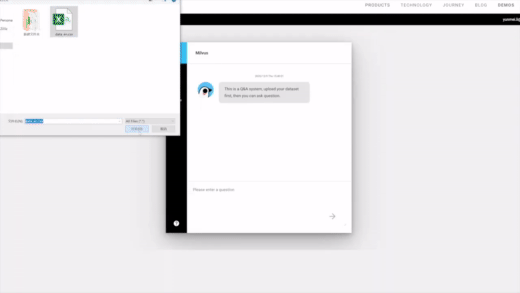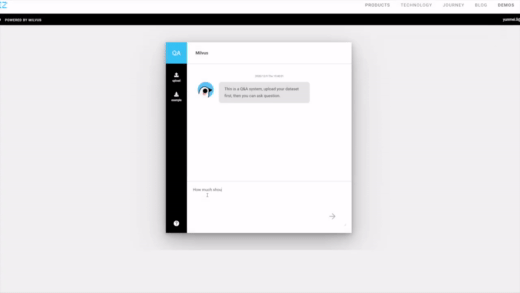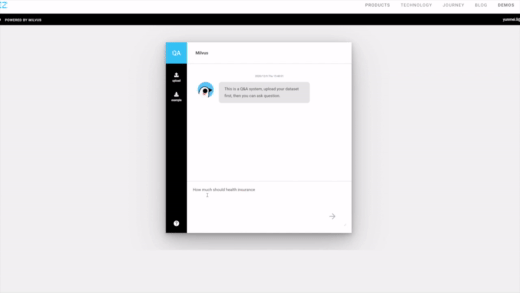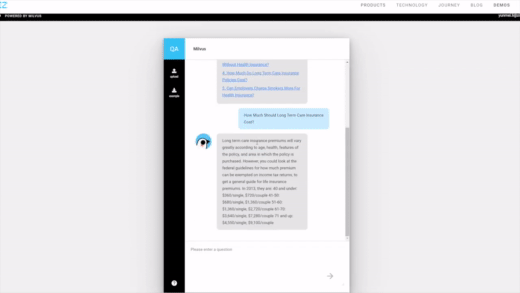
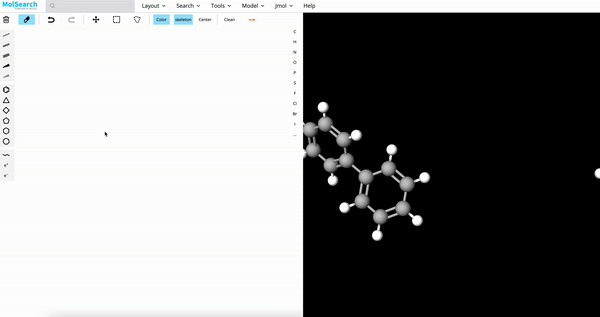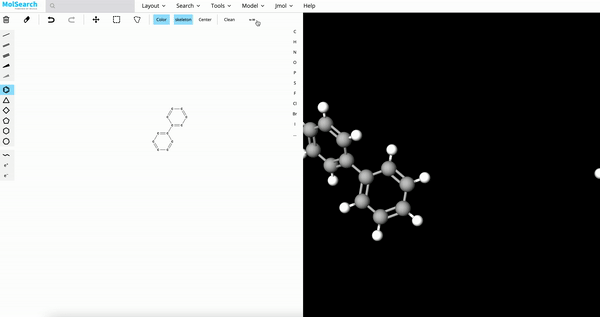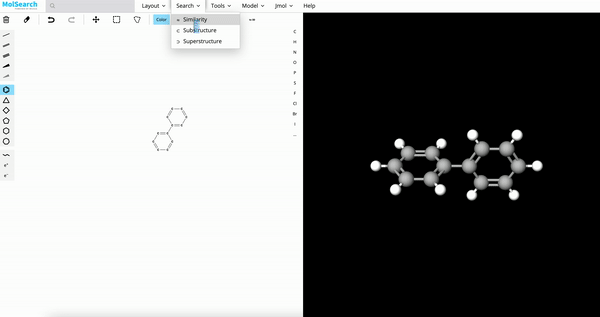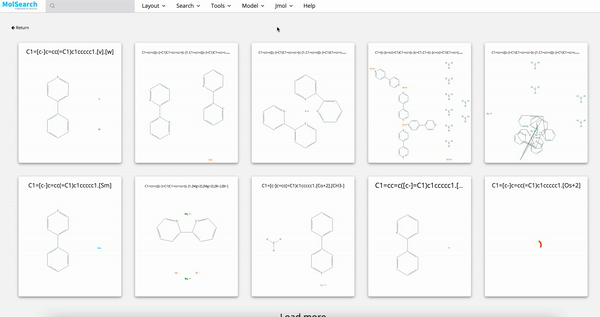
| Image Search | RAG | Drug Discovery |
|---|
Milvus integrates with a comprehensive suite of AI development tools, such as LangChain, LlamaIndex, OpenAI and HuggingFace, making it an ideal vector store for GenAI applications such as Retrieval-Augmented Generation (RAG). Milvus works with both open-source embedding models and embedding services, in text, image and video modalities. Milvus also provides a convenient utility pymilvus[model], users can use the simple wrapper code to transform unstructured data into vector embeddings and leverage reranking models for optimized search results. The Milvus ecosystem also includes Attu for GUI-based administration, Birdwatcher for system debugging, Prometheus/Grafana for monitoring, Milvus CDC for data synchronization, VTS for data migration and data connectors for Spark, Kafka, Fivetran, and Airbyte to build search pipelines.
Check out https://milvus.io/docs/integrations_overview.md for more details.
For guidance on installation, usage, deployment, and administration, check out Milvus Docs. For technical milestones and enhancement proposals, check out issues on GitHub.
The Milvus open-source project accepts contributions from everyone. See Guidelines for Contributing for details on submitting patches and the development workflow. See our community repository to learn about project governance and access more community resources.
Requirements:
-
Linux systems (Ubuntu 20.04 or later recommended):
Go: >= 1.21 CMake: >= 3.26.4 && CMake < 4 GCC: 9.5 Python: > 3.8 and <= 3.11
-
MacOS systems with x86_64 (Big Sur 11.5 or later recommended):
Go: >= 1.21 CMake: >= 3.26.4 && CMake < 4 llvm: >= 15 Python: > 3.8 and <= 3.11
-
MacOS systems with Apple Silicon (Monterey 12.0.1 or later recommended):
Go: >= 1.21 (Arch=ARM64) CMake: >= 3.26.4 && CMake < 4 llvm: >= 15 Python: > 3.8 and <= 3.11
Clone Milvus repo and build.
# Clone github repository.
$ git clone https://github.com/milvus-io/milvus.git
# Install third-party dependencies.
$ cd milvus/
$ ./scripts/install_deps.sh
# Compile Milvus.
$ makeFor full instructions, see developer's documentation.
Join the Milvus community on Discord to share your suggestions, advice, and questions with our engineering team.
To learn the latest news about Milvus, follow us on social media:
You can also check out our FAQ page to discover solutions or answers to your issues or questions, and subscribe to Milvus mailing lists:
Reference to cite when you use Milvus in a research paper:
@inproceedings{2021milvus,
title={Milvus: A Purpose-Built Vector Data Management System},
author={Wang, Jianguo and Yi, Xiaomeng and Guo, Rentong and Jin, Hai and Xu, Peng and Li, Shengjun and Wang, Xiangyu and Guo, Xiangzhou and Li, Chengming and Xu, Xiaohai and others},
booktitle={Proceedings of the 2021 International Conference on Management of Data},
pages={2614--2627},
year={2021}
}
@article{2022manu,
title={Manu: a cloud native vector database management system},
author={Guo, Rentong and Luan, Xiaofan and Xiang, Long and Yan, Xiao and Yi, Xiaomeng and Luo, Jigao and Cheng, Qianya and Xu, Weizhi and Luo, Jiarui and Liu, Frank and others},
journal={Proceedings of the VLDB Endowment},
volume={15},
number={12},
pages={3548--3561},
year={2022},
publisher={VLDB Endowment}
}
















































































































































































































































































































































































































































For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for milvus
Similar Open Source Tools
milvus
Milvus is an open-source vector database built to power embedding similarity search and AI applications. Milvus makes unstructured data search more accessible, and provides a consistent user experience regardless of the deployment environment. Milvus 2.0 is a cloud-native vector database with storage and computation separated by design. All components in this refactored version of Milvus are stateless to enhance elasticity and flexibility. For more architecture details, see Milvus Architecture Overview. Milvus was released under the open-source Apache License 2.0 in October 2019. It is currently a graduate project under LF AI & Data Foundation.
awesome-LLM-AIOps
The 'awesome-LLM-AIOps' repository is a curated list of academic research and industrial materials related to Large Language Models (LLM) and Artificial Intelligence for IT Operations (AIOps). It covers various topics such as incident management, log analysis, root cause analysis, incident mitigation, and incident postmortem analysis. The repository provides a comprehensive collection of papers, projects, and tools related to the application of LLM and AI in IT operations, offering valuable insights and resources for researchers and practitioners in the field.
EvalAI
EvalAI is an open-source platform for evaluating and comparing machine learning (ML) and artificial intelligence (AI) algorithms at scale. It provides a central leaderboard and submission interface, making it easier for researchers to reproduce results mentioned in papers and perform reliable & accurate quantitative analysis. EvalAI also offers features such as custom evaluation protocols and phases, remote evaluation, evaluation inside environments, CLI support, portability, and faster evaluation.
LLM-for-misinformation-research
LLM-for-misinformation-research is a curated paper list of misinformation research using large language models (LLMs). The repository covers methods for detection and verification, tools for fact-checking complex claims, decision-making and explanation, claim matching, post-hoc explanation generation, and other tasks related to combating misinformation. It includes papers on fake news detection, rumor detection, fact verification, and more, showcasing the application of LLMs in various aspects of misinformation research.
LLM-IR-Bias-Fairness-Survey
LLM-IR-Bias-Fairness-Survey is a collection of papers related to bias and fairness in Information Retrieval (IR) with Large Language Models (LLMs). The repository organizes papers according to a survey paper titled 'Bias and Unfairness in Information Retrieval Systems: New Challenges in the LLM Era'. The survey provides a comprehensive review of emerging issues related to bias and unfairness in the integration of LLMs into IR systems, categorizing mitigation strategies into data sampling and distribution reconstruction approaches.
chatgpt-auto-refresh
ChatGPT Auto Refresh is a userscript that keeps ChatGPT sessions fresh by eliminating network errors and Cloudflare checks. It removes the 10-minute time limit from conversations when Chat History is disabled, ensuring a seamless experience. The tool is safe, lightweight, and a time-saver, allowing users to keep their sessions alive without constant copy/paste/refresh actions. It works even in background tabs, providing convenience and efficiency for users interacting with ChatGPT. The tool relies on the chatgpt.js library and is compatible with various browsers using Tampermonkey, making it accessible to a wide range of users.
NL2SQL_Handbook
NL2SQL Handbook provides a comprehensive overview of Natural Language to SQL (NL2SQL) advancements, including survey papers, tutorial slides, and a river diagram of NL2SQL methods. It covers the evolution of NL2SQL solutions, module-based methods, benchmark development, and future directions. The repository also offers practical guides for beginners, access to high-performance language models, and evaluation metrics for NL2SQL models.
chatgpt.js
chatgpt.js is a powerful JavaScript library that allows for super easy interaction w/ the ChatGPT DOM. * Feature-rich * Object-oriented * Easy-to-use * Lightweight (yet optimally performant)
chinmaykaitade
Chinmay Kaitade is a MERN Stack Developer and AI Enthusiast from India. He is an Electrical Engineer turned Full Stack Developer and AI/ML Enthusiast, passionate about crafting innovative web applications and contributing to Open Source projects. His mission is to build scalable web applications using his full-stack expertise and emerging AI/ML knowledge. Connect with him on LinkedIn for new projects and collaborations.
LLMFarm
LLMFarm is an iOS and MacOS app designed to work with large language models (LLM). It allows users to load different LLMs with specific parameters, test the performance of various LLMs on iOS and macOS, and identify the most suitable model for their projects. The tool is based on ggml and llama.cpp by Georgi Gerganov and incorporates sources from rwkv.cpp by saharNooby, Mia by byroneverson, and LlamaChat by alexrozanski. LLMFarm features support for MacOS (13+) and iOS (16+), various inferences and sampling methods, Metal compatibility (not supported on Intel Mac), model setting templates, LoRA adapters support, LoRA finetune support, LoRA export as model support, and more. It also offers a range of inferences including LLaMA, GPTNeoX, Replit, GPT2, Starcoder, RWKV, Falcon, MPT, Bloom, and others. Additionally, it supports multimodal models like LLaVA, Obsidian, and MobileVLM. Users can customize inference options through JSON files and access supported models for download.
Awesome-System2-Reasoning-LLM
The Awesome-System2-Reasoning-LLM repository is dedicated to a survey paper titled 'From System 1 to System 2: A Survey of Reasoning Large Language Models'. It explores the development of reasoning Large Language Models (LLMs), their foundational technologies, benchmarks, and future directions. The repository provides resources and updates related to the research, tracking the latest developments in the field of reasoning LLMs.
lobe-cli-toolbox
Lobe CLI Toolbox is an AI CLI Toolbox designed to enhance git commit and i18n workflow efficiency. It includes tools like Lobe Commit for generating Gitmoji-based commit messages and Lobe i18n for automating the i18n translation process. The toolbox also features Lobe label for automatically copying issues labels from a template repo. It supports features such as automatic splitting of large files, incremental updates, and customization options for the OpenAI model, API proxy, and temperature.
Awesome-LLMs-in-Graph-tasks
This repository is a collection of papers on leveraging Large Language Models (LLMs) in Graph Tasks. It provides a comprehensive overview of how LLMs can enhance graph-related tasks by combining them with traditional Graph Neural Networks (GNNs). The integration of LLMs with GNNs allows for capturing both structural and contextual aspects of nodes in graph data, leading to more powerful graph learning. The repository includes summaries of various models that leverage LLMs to assist in graph-related tasks, along with links to papers and code repositories for further exploration.
AIAS
AIAS is a comprehensive AI training platform that offers courses and practical examples in various AI fields such as traditional image processing, deep learning algorithms, JavaAI applications, NLP, web development, image generation, and desktop application development. The platform also provides SDKs for tasks like image recognition, OCR, natural language processing, audio processing, video analysis, and big data analysis. Users can access training materials, source code, and tools for developing AI applications across different domains.

prompt-in-context-learning
An Open-Source Engineering Guide for Prompt-in-context-learning from EgoAlpha Lab. 📝 Papers | ⚡️ Playground | 🛠 Prompt Engineering | 🌍 ChatGPT Prompt | ⛳ LLMs Usage Guide > **⭐️ Shining ⭐️:** This is fresh, daily-updated resources for in-context learning and prompt engineering. As Artificial General Intelligence (AGI) is approaching, let’s take action and become a super learner so as to position ourselves at the forefront of this exciting era and strive for personal and professional greatness. The resources include: _🎉Papers🎉_: The latest papers about _In-Context Learning_ , _Prompt Engineering_ , _Agent_ , and _Foundation Models_. _🎉Playground🎉_: Large language models(LLMs)that enable prompt experimentation. _🎉Prompt Engineering🎉_: Prompt techniques for leveraging large language models. _🎉ChatGPT Prompt🎉_: Prompt examples that can be applied in our work and daily lives. _🎉LLMs Usage Guide🎉_: The method for quickly getting started with large language models by using LangChain. In the future, there will likely be two types of people on Earth (perhaps even on Mars, but that's a question for Musk): - Those who enhance their abilities through the use of AIGC; - Those whose jobs are replaced by AI automation. 💎EgoAlpha: Hello! human👤, are you ready?
openclaw
OpenClaw is a personal AI assistant that runs on your own devices, answering you on various channels like WhatsApp, Telegram, Slack, Discord, and more. It can speak and listen on different platforms and render a live Canvas you control. The Gateway serves as the control plane, while the assistant is the main product. It provides a local, fast, and always-on single-user assistant experience. The preferred setup involves running the onboarding wizard in your terminal to guide you through setting up the gateway, workspace, channels, and skills. The tool supports various models and authentication methods, with a focus on security and privacy.
For similar tasks

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

zep-python
Zep is an open-source platform for building and deploying large language model (LLM) applications. It provides a suite of tools and services that make it easy to integrate LLMs into your applications, including chat history memory, embedding, vector search, and data enrichment. Zep is designed to be scalable, reliable, and easy to use, making it a great choice for developers who want to build LLM-powered applications quickly and easily.

lollms
LoLLMs Server is a text generation server based on large language models. It provides a Flask-based API for generating text using various pre-trained language models. This server is designed to be easy to install and use, allowing developers to integrate powerful text generation capabilities into their applications.

LlamaIndexTS
LlamaIndex.TS is a data framework for your LLM application. Use your own data with large language models (LLMs, OpenAI ChatGPT and others) in Typescript and Javascript.

semantic-kernel
Semantic Kernel is an SDK that integrates Large Language Models (LLMs) like OpenAI, Azure OpenAI, and Hugging Face with conventional programming languages like C#, Python, and Java. Semantic Kernel achieves this by allowing you to define plugins that can be chained together in just a few lines of code. What makes Semantic Kernel _special_ , however, is its ability to _automatically_ orchestrate plugins with AI. With Semantic Kernel planners, you can ask an LLM to generate a plan that achieves a user's unique goal. Afterwards, Semantic Kernel will execute the plan for the user.

botpress
Botpress is a platform for building next-generation chatbots and assistants powered by OpenAI. It provides a range of tools and integrations to help developers quickly and easily create and deploy chatbots for various use cases.
BotSharp
BotSharp is an open-source machine learning framework for building AI bot platforms. It provides a comprehensive set of tools and components for developing and deploying intelligent virtual assistants. BotSharp is designed to be modular and extensible, allowing developers to easily integrate it with their existing systems and applications. With BotSharp, you can quickly and easily create AI-powered chatbots, virtual assistants, and other conversational AI applications.

qdrant
Qdrant is a vector similarity search engine and vector database. It is written in Rust, which makes it fast and reliable even under high load. Qdrant can be used for a variety of applications, including: * Semantic search * Image search * Product recommendations * Chatbots * Anomaly detection Qdrant offers a variety of features, including: * Payload storage and filtering * Hybrid search with sparse vectors * Vector quantization and on-disk storage * Distributed deployment * Highlighted features such as query planning, payload indexes, SIMD hardware acceleration, async I/O, and write-ahead logging Qdrant is available as a fully managed cloud service or as an open-source software that can be deployed on-premises.
For similar jobs

db2rest
DB2Rest is a modern low-code REST DATA API platform that simplifies the development of intelligent applications. It seamlessly integrates existing and new databases with language models (LMs/LLMs) and vector stores, enabling the rapid delivery of context-aware, reasoning applications without vendor lock-in.

mage-ai
Mage is an open-source data pipeline tool for transforming and integrating data. It offers an easy developer experience, engineering best practices built-in, and data as a first-class citizen. Mage makes it easy to build, preview, and launch data pipelines, and provides observability and scaling capabilities. It supports data integrations, streaming pipelines, and dbt integration.

airbyte
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.

telemetry-airflow
This repository codifies the Airflow cluster that is deployed at workflow.telemetry.mozilla.org (behind SSO) and commonly referred to as "WTMO" or simply "Airflow". Some links relevant to users and developers of WTMO: * The `dags` directory in this repository contains some custom DAG definitions * Many of the DAGs registered with WTMO don't live in this repository, but are instead generated from ETL task definitions in bigquery-etl * The Data SRE team maintains a WTMO Developer Guide (behind SSO)

airflow
Apache Airflow (or simply Airflow) is a platform to programmatically author, schedule, and monitor workflows. When workflows are defined as code, they become more maintainable, versionable, testable, and collaborative. Use Airflow to author workflows as directed acyclic graphs (DAGs) of tasks. The Airflow scheduler executes your tasks on an array of workers while following the specified dependencies. Rich command line utilities make performing complex surgeries on DAGs a snap. The rich user interface makes it easy to visualize pipelines running in production, monitor progress, and troubleshoot issues when needed.

airbyte-platform
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's low-code Connector Development Kit (CDK). Airbyte is used by data engineers and analysts at companies of all sizes to move data for a variety of purposes, including data warehousing, data analysis, and machine learning.

chronon
Chronon is a platform that simplifies and improves ML workflows by providing a central place to define features, ensuring point-in-time correctness for backfills, simplifying orchestration for batch and streaming pipelines, offering easy endpoints for feature fetching, and guaranteeing and measuring consistency. It offers benefits over other approaches by enabling the use of a broad set of data for training, handling large aggregations and other computationally intensive transformations, and abstracting away the infrastructure complexity of data plumbing.