
atomic-agents
Building AI agents, atomically
Stars: 2690
The Atomic Agents framework is a modular and extensible tool designed for creating powerful applications. It leverages Pydantic for data validation and serialization. The framework follows the principles of Atomic Design, providing small and single-purpose components that can be combined. It integrates with Instructor for AI agent architecture and supports various APIs like Cohere, Anthropic, and Gemini. The tool includes documentation, examples, and testing features to ensure smooth development and usage.
README:
![]()
The Atomic Agents framework is designed around the concept of atomicity to be an extremely lightweight and modular framework for building Agentic AI pipelines and applications without sacrificing developer experience and maintainability. The framework provides a set of tools and agents that can be combined to create powerful applications. It is built on top of Instructor and leverages the power of Pydantic for data and schema validation and serialization. All logic and control flows are written in Python, enabling developers to apply familiar best practices and workflows from traditional software development without compromising flexibility or clarity.
NEW: We now also have an official subreddit at /r/AtomicAgents - Be sure to join!
If you want to learn more about the motivation and philosophy behind Atomic Agents, I suggest reading this Medium article (no account needed) or check out the overview video below:

If you just want to dive into the code straight away, I suggest checking out the quickstart video below:

While existing frameworks for agentic AI focus on building autonomous multi-agent systems, they often lack the control and predictability required for real-world applications. Businesses need AI systems that produce consistent, reliable outputs aligned with their brand and objectives.
Atomic Agents addresses this need by providing:
- Modularity: Build AI applications by combining small, reusable components.
- Predictability: Define clear input and output schemas to ensure consistent behavior.
- Extensibility: Easily swap out components or integrate new ones without disrupting the entire system.
- Control: Fine-tune each part of the system individually, from system prompts to tool integrations.
In Atomic Agents, an agent is composed of several key components:
- System Prompt: Defines the agent's behavior and purpose.
- Input Schema: Specifies the structure and validation rules for the agent's input.
- Output Schema: Specifies the structure and validation rules for the agent's output.
- Memory: Stores conversation history or other relevant data.
- Context Providers: Inject dynamic context into the agent's system prompt at runtime.
Here's a high-level architecture diagram:


To install Atomic Agents, you can use pip:
pip install atomic-agentsMake sure you also install the provider you want to use. For example, to use OpenAI and Groq, you can install the openai and groq packages:
pip install openai groqThis also installs the CLI Atomic Assembler, which can be used to download Tools (and soon also Agents and Pipelines).
For local development, you can install from the repository:
git clone https://github.com/BrainBlend-AI/atomic-agents.git
cd atomic-agents
poetry installAtomic Agents uses a monorepo structure with the following main components:
-
atomic-agents/: The core Atomic Agents library -
atomic-assembler/: The CLI tool for managing Atomic Agents components -
atomic-examples/: Example projects showcasing Atomic Agents usage -
atomic-forge/: A collection of tools that can be used with Atomic Agents
A complete list of examples can be found in the examples directory.
We strive to thoroughly document each example, but if something is unclear, please don't hesitate to open an issue or pull request to improve the documentation.
Here's a quick snippet demonstrating how easy it is to create a powerful agent with Atomic Agents:
# Define a custom output schema
class CustomOutputSchema(BaseIOSchema):
"""
docstring for the custom output schema
"""
chat_message: str = Field(..., description="The chat message from the agent.")
suggested_questions: List[str] = Field(..., description="Suggested follow-up questions.")
# Set up the system prompt
system_prompt_generator = SystemPromptGenerator(
background=["This assistant is knowledgeable, helpful, and suggests follow-up questions."],
steps=[
"Analyze the user's input to understand the context and intent.",
"Formulate a relevant and informative response.",
"Generate 3 suggested follow-up questions for the user."
],
output_instructions=[
"Provide clear and concise information in response to user queries.",
"Conclude each response with 3 relevant suggested questions for the user."
]
)
# Initialize the agent
agent = BaseAgent(
config=BaseAgentConfig(
client=your_openai_client, # Replace with your actual client
model="gpt-4o-mini",
system_prompt_generator=system_prompt_generator,
memory=AgentMemory(),
output_schema=CustomOutputSchema
)
)
# Use the agent
response = agent.run(user_input)
print(f"Agent: {response.chat_message}")
print("Suggested questions:")
for question in response.suggested_questions:
print(f"- {question}")This snippet showcases how to create a customizable agent that responds to user queries and suggests follow-up questions. For full, runnable examples, please refer to the following files in the atomic-examples/quickstart/quickstart/ directory:
-
Basic Chatbot A minimal chatbot example to get you started.
-
Custom Chatbot A more advanced example with a custom system prompt.
-
Custom Chatbot with Schema An advanced example featuring a custom output schema.
-
Multi-Provider Chatbot Demonstrates how to use different providers such as Ollama or Groq.
In addition to the quickstart examples, we have more complex examples demonstrating the power of Atomic Agents:
-
Basic Multimodal: Demonstrates how to analyze images with text, focusing on extracting structured information from nutrition labels using GPT-4 Vision capabilities.
-
Deep Research: An advanced example showing how to perform deep research tasks.
-
Orchestration Agent: Shows how to create an Orchestrator Agent that intelligently decides between using different tools (search or calculator) based on user input.
-
RAG Chatbot: A chatbot implementation using Retrieval-Augmented Generation (RAG) to provide context-aware responses.
-
Web Search Agent: An intelligent agent that performs web searches and answers questions based on the results.
-
YouTube Summarizer: An agent that extracts and summarizes knowledge from YouTube videos.
-
YouTube to Recipe: An example that extracts structured recipe information from cooking videos, demonstrating complex information extraction and structuring.
For a complete list of examples, see the examples directory.
These examples provide a great starting point for understanding and using Atomic Agents.
Atomic Agents allows you to enhance your agents with dynamic context using Context Providers. Context Providers enable you to inject additional information into the agent's system prompt at runtime, making your agents more flexible and context-aware.
To use a Context Provider, create a class that inherits from SystemPromptContextProviderBase and implements the get_info() method, which returns the context string to be added to the system prompt.
Here's a simple example:
from atomic_agents.lib.components.system_prompt_generator import SystemPromptContextProviderBase
class SearchResultsProvider(SystemPromptContextProviderBase):
def __init__(self, title: str, search_results: List[str]):
super().__init__(title=title)
self.search_results = search_results
def get_info(self) -> str:
return "\n".join(self.search_results)You can then register your Context Provider with the agent:
# Initialize your context provider with dynamic data
search_results_provider = SearchResultsProvider(
title="Search Results",
search_results=["Result 1", "Result 2", "Result 3"]
)
# Register the context provider with the agent
agent.register_context_provider("search_results", search_results_provider)This allows your agent to include the search results (or any other context) in its system prompt, enhancing its responses based on the latest information.
Atomic Agents makes it easy to chain agents and tools together by aligning their input and output schemas. This design allows you to swap out components effortlessly, promoting modularity and reusability in your AI applications.
Suppose you have an agent that generates search queries and you want to use these queries with different search tools. By aligning the agent's output schema with the input schema of the search tool, you can easily chain them together or switch between different search providers.
Here's how you can achieve this:
import instructor
import openai
from pydantic import Field
from atomic_agents.agents.base_agent import BaseIOSchema, BaseAgent, BaseAgentConfig
from atomic_agents.lib.components.system_prompt_generator import SystemPromptGenerator
# Import the search tool you want to use
from web_search_agent.tools.searxng_search import SearxNGSearchTool
# Define the input schema for the query agent
class QueryAgentInputSchema(BaseIOSchema):
"""Input schema for the QueryAgent."""
instruction: str = Field(..., description="Instruction to generate search queries for.")
num_queries: int = Field(..., description="Number of queries to generate.")
# Initialize the query agent
query_agent = BaseAgent(
BaseAgentConfig(
client=instructor.from_openai(openai.OpenAI()),
model="gpt-4o-mini",
system_prompt_generator=SystemPromptGenerator(
background=[
"You are an intelligent query generation expert.",
"Your task is to generate a specified number of diverse and highly relevant queries based on a given instruction."
],
steps=[
"Receive the instruction and the number of queries to generate.",
"Generate the queries in JSON format."
],
output_instructions=[
"Ensure each query is unique and relevant.",
"Provide the queries in the expected schema."
],
),
input_schema=QueryAgentInputSchema,
output_schema=SearxNGSearchTool.input_schema, # Align output schema
)
)In this example:
-
Modularity: By setting the
output_schemaof thequery_agentto match theinput_schemaofSearxNGSearchTool, you can directly use the output of the agent as input to the tool. -
Swapability: If you decide to switch to a different search provider, you can import a different search tool and update the
output_schemaaccordingly.
For instance, to switch to another search service:
# Import a different search tool
from web_search_agent.tools.another_search import AnotherSearchTool
# Update the output schema
query_agent.config.output_schema = AnotherSearchTool.input_schemaThis design pattern simplifies the process of chaining agents and tools, making your AI applications more adaptable and easier to maintain.
To run the CLI, simply run the following command:
atomicOr if you installed Atomic Agents with Poetry, for example:
poetry run atomicOr if you installed Atomic Agents with uv:
uv run atomicAfter running this command, you will be presented with a menu allowing you to download tools.
Each tool's has its own:
- Input schema
- Output schema
- Usage example
- Dependencies
- Installation instructions

The atomic-assembler CLI gives you complete control over your tools, avoiding the clutter of unnecessary dependencies. It makes modifying tools straightforward additionally, each tool comes with its own set of tests for reliability.
But you're not limited to the CLI! If you prefer, you can directly access the tool folders and manage them manually by simply copying and pasting as needed.

Atomic Agents depends on the Instructor package. This means that in all examples where OpenAI is used, any other API supported by Instructor can also be used—such as Ollama, Groq, Mistral, Cohere, Anthropic, Gemini, and more. For a complete list, please refer to the Instructor documentation on its GitHub page.
API documentation can be found here.
Atomic Forge is a collection of tools that can be used with Atomic Agents to extend its functionality. Current tools include:
- Calculator
- SearxNG Search
- YouTube Transcript Scraper
For more information on using and creating tools, see the Atomic Forge README.
We welcome contributions! Please see the Developer Guide for detailed information on how to contribute to Atomic Agents. Here are some quick steps:
- Fork the repository
- Create a new branch (
git checkout -b feature-branch) - Make your changes
- Run tests (
poetry run pytest --cov=atomic_agents atomic-agents) - Format your code (
poetry run black atomic-agents atomic-assembler atomic-examples atomic-forge) - Lint your code (
poetry run flake8 --extend-exclude=.venv atomic-agents atomic-assembler atomic-examples atomic-forge) - Commit your changes (
git commit -m 'Add some feature') - Push to the branch (
git push origin feature-branch) - Open a pull request
For full development setup and guidelines, please refer to the Developer Guide.
This project is licensed under the MIT License—see the LICENSE file for details.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for atomic-agents
Similar Open Source Tools
atomic-agents
The Atomic Agents framework is a modular and extensible tool designed for creating powerful applications. It leverages Pydantic for data validation and serialization. The framework follows the principles of Atomic Design, providing small and single-purpose components that can be combined. It integrates with Instructor for AI agent architecture and supports various APIs like Cohere, Anthropic, and Gemini. The tool includes documentation, examples, and testing features to ensure smooth development and usage.

llama_index
LlamaIndex is a data framework for building LLM applications. It provides tools for ingesting, structuring, and querying data, as well as integrating with LLMs and other tools. LlamaIndex is designed to be easy to use for both beginner and advanced users, and it provides a comprehensive set of features for building LLM applications.

langchain
LangChain is a framework for building LLM-powered applications that simplifies AI application development by chaining together interoperable components and third-party integrations. It helps developers connect LLMs to diverse data sources, swap models easily, and future-proof decisions as technology evolves. LangChain's ecosystem includes tools like LangSmith for agent evals, LangGraph for complex task handling, and LangGraph Platform for deployment and scaling. Additional resources include tutorials, how-to guides, conceptual guides, a forum, API reference, and chat support.

ms-agent
MS-Agent is a lightweight framework designed to empower agents with autonomous exploration capabilities. It provides a flexible and extensible architecture for creating agents capable of tasks like code generation, data analysis, and tool calling with MCP support. The framework supports multi-agent interactions, deep research, code generation, and is lightweight and extensible for various applications.

pdr_ai_v2
pdr_ai_v2 is a Python library for implementing machine learning algorithms and models. It provides a wide range of tools and functionalities for data preprocessing, model training, evaluation, and deployment. The library is designed to be user-friendly and efficient, making it suitable for both beginners and experienced data scientists. With pdr_ai_v2, users can easily build and deploy machine learning models for various applications, such as classification, regression, clustering, and more.
GhidrAssist
GhidrAssist is an advanced LLM-powered plugin for interactive reverse engineering assistance in Ghidra. It integrates Large Language Models (LLMs) to provide intelligent assistance for binary exploration and reverse engineering. The tool supports various OpenAI v1-compatible APIs, including local models and cloud providers. Key features include code explanation, interactive chat, custom queries, Graph-RAG knowledge system with semantic knowledge graph, community detection, security feature extraction, semantic graph tab, extended thinking/reasoning control, ReAct agentic mode, MCP integration, function calling, actions tab, RAG (Retrieval Augmented Generation), and RLHF dataset generation. The plugin uses a modular, service-oriented architecture with core services, Graph-RAG backend, data layer, and UI components.

DB-GPT
DB-GPT is an open source AI native data app development framework with AWEL(Agentic Workflow Expression Language) and agents. It aims to build infrastructure in the field of large models, through the development of multiple technical capabilities such as multi-model management (SMMF), Text2SQL effect optimization, RAG framework and optimization, Multi-Agents framework collaboration, AWEL (agent workflow orchestration), etc. Which makes large model applications with data simpler and more convenient.

deeppowers
Deeppowers is a powerful Python library for deep learning applications. It provides a wide range of tools and utilities to simplify the process of building and training deep neural networks. With Deeppowers, users can easily create complex neural network architectures, perform efficient training and optimization, and deploy models for various tasks. The library is designed to be user-friendly and flexible, making it suitable for both beginners and experienced deep learning practitioners.

BentoVLLM
BentoVLLM is an example project demonstrating how to serve and deploy open-source Large Language Models using vLLM, a high-throughput and memory-efficient inference engine. It provides a basis for advanced code customization, such as custom models, inference logic, or vLLM options. The project allows for simple LLM hosting with OpenAI compatible endpoints without the need to write any code. Users can interact with the server using Swagger UI or other methods, and the service can be deployed to BentoCloud for better management and scalability. Additionally, the repository includes integration examples for different LLM models and tools.

bisheng
Bisheng is a leading open-source **large model application development platform** that empowers and accelerates the development and deployment of large model applications, helping users enter the next generation of application development with the best possible experience.
langgraphjs
LangGraph.js is a library for building stateful, multi-actor applications with LLMs, offering benefits such as cycles, controllability, and persistence. It allows defining flows involving cycles, providing fine-grained control over application flow and state. Inspired by Pregel and Apache Beam, it includes features like loops, persistence, human-in-the-loop workflows, and streaming support. LangGraph integrates seamlessly with LangChain.js and LangSmith but can be used independently.
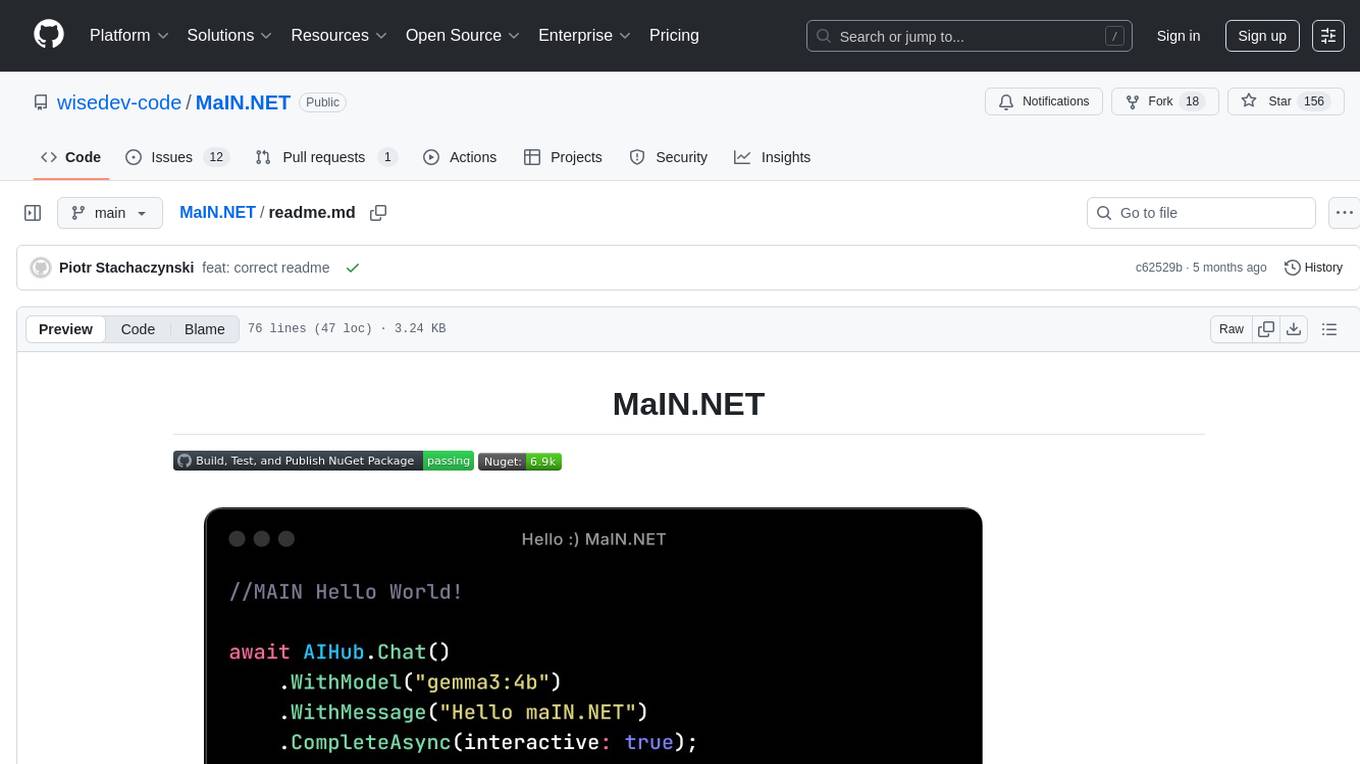
MaIN.NET
MaIN.NET (Modular Artificial Intelligence Network) is a versatile .NET package designed to streamline the integration of large language models (LLMs) into advanced AI workflows. It offers a flexible and robust foundation for developing chatbots, automating processes, and exploring innovative AI techniques. The package connects diverse AI methods into one unified ecosystem, empowering developers with a low-code philosophy to create powerful AI applications with ease.
Ivy-Framework
Ivy-Framework is a powerful tool for building internal applications with AI assistance using C# codebase. It provides a CLI for project initialization, authentication integrations, database support, LLM code generation, secrets management, container deployment, hot reload, dependency injection, state management, routing, and external widget framework. Users can easily create data tables for sorting, filtering, and pagination. The framework offers a seamless integration of front-end and back-end development, making it ideal for developing robust internal tools and dashboards.
arcade-ai
Arcade AI is a developer-focused tooling and API platform designed to enhance the capabilities of LLM applications and agents. It simplifies the process of connecting agentic applications with user data and services, allowing developers to concentrate on building their applications. The platform offers prebuilt toolkits for interacting with various services, supports multiple authentication providers, and provides access to different language models. Users can also create custom toolkits and evaluate their tools using Arcade AI. Contributions are welcome, and self-hosting is possible with the provided documentation.
agentic-qe
Agentic Quality Engineering Fleet (Agentic QE) is a comprehensive tool designed for quality engineering tasks. It offers a Domain-Driven Design architecture with 13 bounded contexts and 60 specialized QE agents. The tool includes features like TinyDancer intelligent model routing, ReasoningBank learning with Dream cycles, HNSW vector search, Coherence Verification, and integration with other tools like Claude Flow and Agentic Flow. It provides capabilities for test generation, coverage analysis, quality assessment, defect intelligence, requirements validation, code intelligence, security compliance, contract testing, visual accessibility, chaos resilience, learning optimization, and enterprise integration. The tool supports various protocols, LLM providers, and offers a vast library of QE skills for different testing scenarios.
OpenViking
OpenViking is an open-source Context Database designed specifically for AI Agents. It aims to solve challenges in agent development by unifying memories, resources, and skills in a filesystem management paradigm. The tool offers tiered context loading, directory recursive retrieval, visualized retrieval trajectory, and automatic session management. Developers can interact with OpenViking like managing local files, enabling precise context manipulation and intuitive traceable operations. The tool supports various model services like OpenAI and Volcengine, enhancing semantic retrieval and context understanding for AI Agents.
For similar tasks

axoned
Axone is a public dPoS layer 1 designed for connecting, sharing, and monetizing resources in the AI stack. It is an open network for collaborative AI workflow management compatible with any data, model, or infrastructure, allowing sharing of data, algorithms, storage, compute, APIs, both on-chain and off-chain. The 'axoned' node of the AXONE network is built on Cosmos SDK & Tendermint consensus, enabling companies & individuals to define on-chain rules, share off-chain resources, and create new applications. Validators secure the network by maintaining uptime and staking $AXONE for rewards. The blockchain supports various platforms and follows Semantic Versioning 2.0.0. A docker image is available for quick start, with documentation on querying networks, creating wallets, starting nodes, and joining networks. Development involves Go and Cosmos SDK, with smart contracts deployed on the AXONE blockchain. The project provides a Makefile for building, installing, linting, and testing. Community involvement is encouraged through Discord, open issues, and pull requests.
langstream
LangStream is a tool for natural language processing tasks, providing a CLI for easy installation and usage. Users can try sample applications like Chat Completions and create their own applications using the developer documentation. It supports running on Kubernetes for production-ready deployment, with support for various Kubernetes distributions and external components like Apache Kafka or Apache Pulsar cluster. Users can deploy LangStream locally using minikube and manage the cluster with mini-langstream. Development requirements include Docker, Java 17, Git, Python 3.11+, and PIP, with the option to test local code changes using mini-langstream.

atomic_agents
Atomic Agents is a modular and extensible framework designed for creating powerful applications. It follows the principles of Atomic Design, emphasizing small and single-purpose components. Leveraging Pydantic for data validation and serialization, the framework offers a set of tools and agents that can be combined to build AI applications. It depends on the Instructor package and supports various APIs like OpenAI, Cohere, Anthropic, and Gemini. Atomic Agents is suitable for developers looking to create AI agents with a focus on modularity and flexibility.
writer-framework
Writer Framework is an open-source framework for creating AI applications. It allows users to build user interfaces using a visual editor and write the backend code in Python. The framework is fast, flexible, and provides separation of concerns between UI and business logic. It is reactive and state-driven, highly customizable without requiring CSS, fast in event handling, developer-friendly with easy installation and quick start options, and contains full documentation for using its AI module and deployment options.
atomic-agents
The Atomic Agents framework is a modular and extensible tool designed for creating powerful applications. It leverages Pydantic for data validation and serialization. The framework follows the principles of Atomic Design, providing small and single-purpose components that can be combined. It integrates with Instructor for AI agent architecture and supports various APIs like Cohere, Anthropic, and Gemini. The tool includes documentation, examples, and testing features to ensure smooth development and usage.
ai-self-coding-book
The 'ai-self-coding-book' repository is a guidebook that aims to teach how to create complex applications with commercial value using natural language and AI, rather than simple toy projects. It provides insights on AI programming concepts and practical applications, emphasizing real-world use cases and best practices for development.
anda
Anda is an AI agent framework built with Rust, integrating ICP blockchain and TEE support. It aims to create a network of highly composable, autonomous AI agents across industries to advance artificial intelligence. Key features include composability, simplicity, trustworthiness, autonomy, and perpetual memory. Anda's vision is to build a collaborative network of agents leading to a super AGI system, revolutionizing AI technology applications and creating value for society.
wxflows
watsonx.ai Flows Engine is a powerful tool for building, running, and deploying AI agents. It allows users to create tools from various data sources and deploy them to the cloud. The tools built with watsonx.ai Flows Engine can be integrated into any Agentic Framework using the SDK for Python & JavaScript. The platform offers a range of tools and integrations, including exchange, wikipedia, google_books, math, and weather. Users can also build their own tools and leverage integrations like LangGraph, LangChain, watsonx.ai, and OpenAI. Examples of applications built with watsonx.ai Flows Engine include an end-to-end Agent Chat App, Text-to-SQL Agent, YouTube transcription agent, Math agent, and more. The platform provides comprehensive support through Discord for any questions or feedback.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.