
dranet
DRANET is a Kubernetes Network Driver that uses Dynamic Resource Allocation (DRA) to deliver high-performance networking for demanding applications in Kubernetes.
Stars: 111
Dranet is a Python library for analyzing and visualizing data from neural networks. It provides tools for interpreting model predictions, understanding feature importance, and evaluating model performance. With Dranet, users can gain insights into how neural networks make decisions and improve model transparency and interpretability.
README:
DRANET is a Kubernetes Network Driver that uses Dynamic Resource Allocation (DRA) to deliver high-performance networking for demanding applications in Kubernetes.
- DRA Integration: Leverages the power of Kubernetes' Dynamic Resource Allocation.
- High-Performance Networking: Designed for demanding workloads like AI/ML applications.
- Simplified Management: Easy to deploy and manage.
- Enhanced Efficiency: Optimizes resource utilization for improved overall performance.
- Cluster-Wide Scalability: Effectively manages network resources across a large number of nodes for seamless operation in Kubernetes deployments.
Our research paper, "The Kubernetes Network Driver Model: A Composable Architecture for High-Performance Networking", provides a deep dive into the DraNet model and its impact.


The key findings include:
-
Up to 60% Bandwidth Increase: By enabling topology-aware scheduling of GPUs and NICs, DraNet boosts bus bandwidth by up to 59.6% for
all_gatherand 58.1% forall_reduceoperations in distributed AI/ML workloads. - Operational Simplicity: The paper demonstrates how the KND model used by DraNet drastically simplifies the management of high-performance hardware, replacing fragile, multi-component chains with a clean, composable architecture.
The DraNet driver communicates with the Kubelet through the DRA API and with the Container Runtime via NRI. This architectural approach ensures robust supportability and minimizes complexity, making it fully compatible with existing CNI plugins in your cluster.
Upon the creation of a Pod's network namespaces, the Container Runtime initiates a GRPC call to DraNet via NRI to execute the necessary network configurations.
A more detailed diagram illustrating this process can be found in our documentation: How It Works.
To get started with DraNet, your Kubernetes cluster needs to have Dynamic Resource Allocation (DRA) enabled. DRA is beta and is disabled by default in Kubernetes v1.32. You will need to enable both the feature gates and the API groups for DRA until it reaches GA.

If you are using KIND, you can create a cluster with the following configuration:
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
image: kindest/node:v1.34.0
- role: worker
image: kindest/node:v1.34.0
- role: worker
image: kindest/node:v1.34.0Then to create the cluster:
kind create cluster --config kind.yamlFor instructions on setting up DRA on GKE, refer to the official documentation: Set up Dynamic Resource Allocation
Install the latest stable version of DraNet using the provided manifest:
kubectl apply -f https://raw.githubusercontent.com/google/dranet/refs/heads/main/install.yamlOnce DraNet is running, you can inspect the network interfaces and their
attributes published by the drivers. Users can then create DeviceClasses,
ResourceClaims, and/or ResourceClaimTemplates to schedule pods and allocate
network devices.
For examples of how to use DraNet with DeviceClass and ResourceClaim to
attach network interfaces to pods, please refer to the Quick Start
guide.
We welcome your contributions! Please review our Contributor License Agreement and Google's Open Source Community Guidelines before you begin. All submissions require review via GitHub pull requests.
For detailed development instructions, including local development with KIND and troubleshooting tips, see our Developer Guide.
Explore more concepts and advanced topics:
- Design: Understand the architectural choices behind DraNet: Design
- RDMA: Learn about RDMA components in Linux and their interplay: RDMA
- References: A list of relevant Kubernetes Enhancement Proposals (KEPs) and presentations: References
This is not an officially supported Google product. This project is not eligible for the Google Open Source Software Vulnerability Rewards Program.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for dranet
Similar Open Source Tools
dranet
Dranet is a Python library for analyzing and visualizing data from neural networks. It provides tools for interpreting model predictions, understanding feature importance, and evaluating model performance. With Dranet, users can gain insights into how neural networks make decisions and improve model transparency and interpretability.

graphrag
The GraphRAG project is a data pipeline and transformation suite designed to extract meaningful, structured data from unstructured text using LLMs. It enhances LLMs' ability to reason about private data. The repository provides guidance on using knowledge graph memory structures to enhance LLM outputs, with a warning about the potential costs of GraphRAG indexing. It offers contribution guidelines, development resources, and encourages prompt tuning for optimal results. The Responsible AI FAQ addresses GraphRAG's capabilities, intended uses, evaluation metrics, limitations, and operational factors for effective and responsible use.

datatune
Datatune is a data analysis tool designed to help users explore and analyze datasets efficiently. It provides a user-friendly interface for importing, cleaning, visualizing, and modeling data. With Datatune, users can easily perform tasks such as data preprocessing, feature engineering, model selection, and evaluation. The tool offers a variety of statistical and machine learning algorithms to support data analysis tasks. Whether you are a data scientist, analyst, or researcher, Datatune can streamline your data analysis workflow and help you derive valuable insights from your data.

phoenix
Phoenix is a tool that provides MLOps and LLMOps insights at lightning speed with zero-config observability. It offers a notebook-first experience for monitoring models and LLM Applications by providing LLM Traces, LLM Evals, Embedding Analysis, RAG Analysis, and Structured Data Analysis. Users can trace through the execution of LLM Applications, evaluate generative models, explore embedding point-clouds, visualize generative application's search and retrieval process, and statistically analyze structured data. Phoenix is designed to help users troubleshoot problems related to retrieval, tool execution, relevance, toxicity, drift, and performance degradation.
pegainfer
PegaInfer is a machine learning tool designed for predictive analytics and pattern recognition. It provides a user-friendly interface for training and deploying machine learning models without the need for extensive coding knowledge. With PegaInfer, users can easily analyze large datasets, make predictions, and uncover hidden patterns in their data. The tool supports various machine learning algorithms and allows for customization to suit specific use cases. Whether you are a data scientist, business analyst, or researcher, PegaInfer can help streamline your data analysis process and enhance decision-making capabilities.

ROGRAG
ROGRAG is a powerful open-source tool designed for data analysis and visualization. It provides a user-friendly interface for exploring and manipulating datasets, making it ideal for researchers, data scientists, and analysts. With ROGRAG, users can easily import, clean, analyze, and visualize data to gain valuable insights and make informed decisions. The tool supports a wide range of data formats and offers a variety of statistical and visualization tools to help users uncover patterns, trends, and relationships in their data. Whether you are working on exploratory data analysis, statistical modeling, or data visualization, ROGRAG is a versatile tool that can streamline your workflow and enhance your data analysis capabilities.

turftopic
Turftopic is a Python library that provides tools for sentiment analysis and topic modeling of text data. It allows users to analyze large volumes of text data to extract insights on sentiment and topics. The library includes functions for preprocessing text data, performing sentiment analysis using machine learning models, and conducting topic modeling using algorithms such as Latent Dirichlet Allocation (LDA). Turftopic is designed to be user-friendly and efficient, making it suitable for both beginners and experienced data analysts.

pdr_ai_v2
pdr_ai_v2 is a Python library for implementing machine learning algorithms and models. It provides a wide range of tools and functionalities for data preprocessing, model training, evaluation, and deployment. The library is designed to be user-friendly and efficient, making it suitable for both beginners and experienced data scientists. With pdr_ai_v2, users can easily build and deploy machine learning models for various applications, such as classification, regression, clustering, and more.

AI_Spectrum
AI_Spectrum is a versatile machine learning library that provides a wide range of tools and algorithms for building and deploying AI models. It offers a user-friendly interface for data preprocessing, model training, and evaluation. With AI_Spectrum, users can easily experiment with different machine learning techniques and optimize their models for various tasks. The library is designed to be flexible and scalable, making it suitable for both beginners and experienced data scientists.

God-Level-AI
A drill of scientific methods, processes, algorithms, and systems to build stories & models. An in-depth learning resource for humans. This repository is designed for individuals aiming to excel in the field of Data and AI, providing video sessions and text content for learning. It caters to those in leadership positions, professionals, and students, emphasizing the need for dedicated effort to achieve excellence in the tech field. The content covers various topics with a focus on practical application.
Daft
Daft is a lightweight and efficient tool for data analysis and visualization. It provides a user-friendly interface for exploring and manipulating datasets, making it ideal for both beginners and experienced data analysts. With Daft, you can easily import data from various sources, clean and preprocess it, perform statistical analysis, create insightful visualizations, and export your results in multiple formats. Whether you are a student, researcher, or business professional, Daft simplifies the process of analyzing data and deriving meaningful insights.
arconia
Arconia is a powerful open-source tool for managing and visualizing data in a user-friendly way. It provides a seamless experience for data analysts and scientists to explore, clean, and analyze datasets efficiently. With its intuitive interface and robust features, Arconia simplifies the process of data manipulation and visualization, making it an essential tool for anyone working with data.

context7
Context7 is a powerful tool for analyzing and visualizing data in various formats. It provides a user-friendly interface for exploring datasets, generating insights, and creating interactive visualizations. With advanced features such as data filtering, aggregation, and customization, Context7 is suitable for both beginners and experienced data analysts. The tool supports a wide range of data sources and formats, making it versatile for different use cases. Whether you are working on exploratory data analysis, data visualization, or data storytelling, Context7 can help you uncover valuable insights and communicate your findings effectively.
forecastbench
ForecastBench is a dynamic benchmark tool for evaluating LLM forecasting accuracy with human comparison groups. It provides a contamination-free environment and serves as a proxy for general intelligence. The tool offers leaderboards and datasets updated nightly, along with instructions for submitting models. Users can explore detailed information on the wiki and cite the tool using the provided BibTeX citation. Developers can set up the tool locally, run GCP Cloud Functions, and contribute to the project by following specific guidelines.

deeppowers
Deeppowers is a powerful Python library for deep learning applications. It provides a wide range of tools and utilities to simplify the process of building and training deep neural networks. With Deeppowers, users can easily create complex neural network architectures, perform efficient training and optimization, and deploy models for various tasks. The library is designed to be user-friendly and flexible, making it suitable for both beginners and experienced deep learning practitioners.
arthur-engine
The Arthur Engine is a comprehensive tool for monitoring and governing AI/ML workloads. It provides evaluation and benchmarking of machine learning models, guardrails enforcement, and extensibility for fitting into various application architectures. With support for a wide range of evaluation metrics and customizable features, the tool aims to improve model understanding, optimize generative AI outputs, and prevent data-security and compliance risks. Key features include real-time guardrails, model performance monitoring, feature importance visualization, error breakdowns, and support for custom metrics and models integration.
For similar tasks
ExplainableAI.jl
ExplainableAI.jl is a Julia package that implements interpretability methods for black-box classifiers, focusing on local explanations and attribution maps in input space. The package requires models to be differentiable with Zygote.jl. It is similar to Captum and Zennit for PyTorch and iNNvestigate for Keras models. Users can analyze and visualize explanations for model predictions, with support for different XAI methods and customization. The package aims to provide transparency and insights into model decision-making processes, making it a valuable tool for understanding and validating machine learning models.
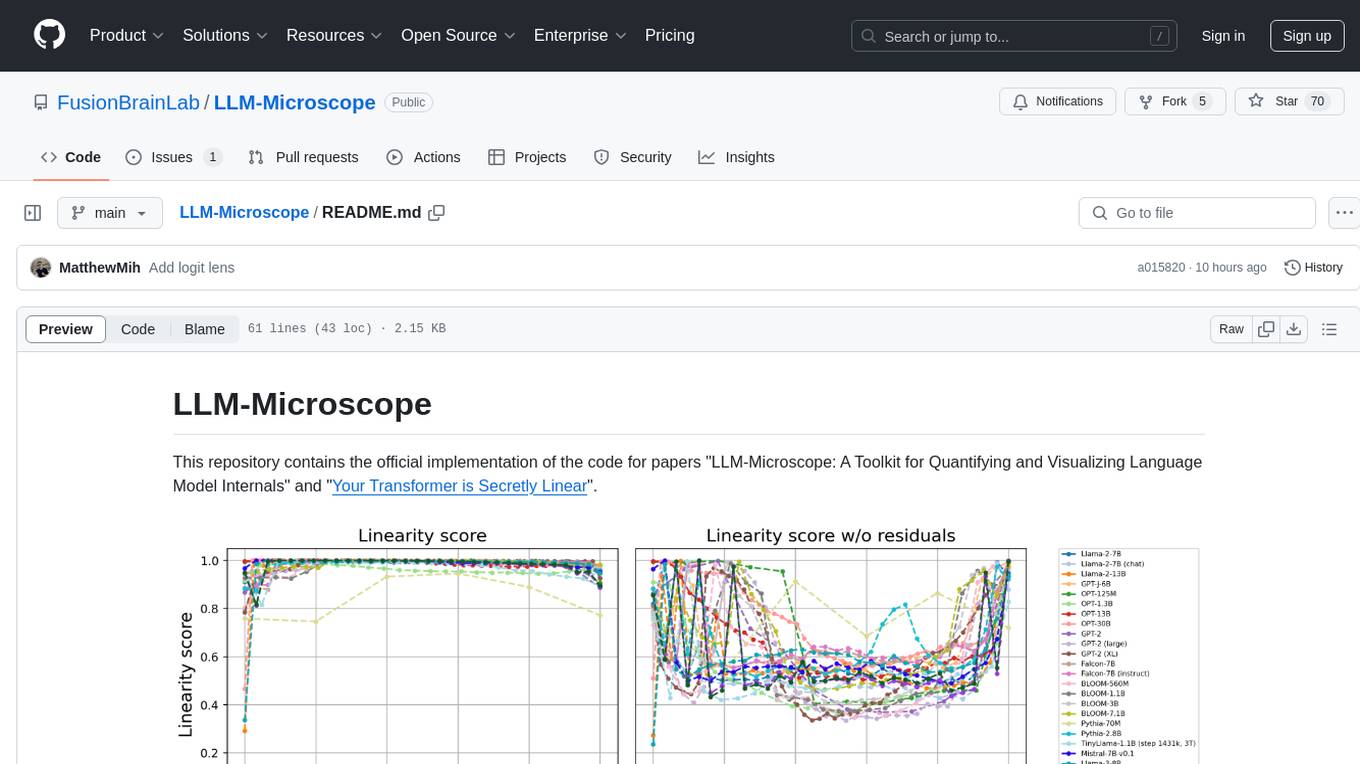
LLM-Microscope
LLM-Microscope is a toolkit designed for quantifying and visualizing language model internals. It provides functions for calculating anisotropy, intrinsic dimension, and linearity score. The toolkit also includes a Logit Lens feature for analyzing model predictions and losses. Users can easily install the toolkit using pip and explore the functionalities through provided examples.
dranet
Dranet is a Python library for analyzing and visualizing data from neural networks. It provides tools for interpreting model predictions, understanding feature importance, and evaluating model performance. With Dranet, users can gain insights into how neural networks make decisions and improve model transparency and interpretability.

Co-LLM-Agents
This repository contains code for building cooperative embodied agents modularly with large language models. The agents are trained to perform tasks in two different environments: ThreeDWorld Multi-Agent Transport (TDW-MAT) and Communicative Watch-And-Help (C-WAH). TDW-MAT is a multi-agent environment where agents must transport objects to a goal position using containers. C-WAH is an extension of the Watch-And-Help challenge, which enables agents to send messages to each other. The code in this repository can be used to train agents to perform tasks in both of these environments.

GPT4Point
GPT4Point is a unified framework for point-language understanding and generation. It aligns 3D point clouds with language, providing a comprehensive solution for tasks such as 3D captioning and controlled 3D generation. The project includes an automated point-language dataset annotation engine, a novel object-level point cloud benchmark, and a 3D multi-modality model. Users can train and evaluate models using the provided code and datasets, with a focus on improving models' understanding capabilities and facilitating the generation of 3D objects.

asreview
The ASReview project implements active learning for systematic reviews, utilizing AI-aided pipelines to assist in finding relevant texts for search tasks. It accelerates the screening of textual data with minimal human input, saving time and increasing output quality. The software offers three modes: Oracle for interactive screening, Exploration for teaching purposes, and Simulation for evaluating active learning models. ASReview LAB is designed to support decision-making in any discipline or industry by improving efficiency and transparency in screening large amounts of textual data.

Groma
Groma is a grounded multimodal assistant that excels in region understanding and visual grounding. It can process user-defined region inputs and generate contextually grounded long-form responses. The tool presents a unique paradigm for multimodal large language models, focusing on visual tokenization for localization. Groma achieves state-of-the-art performance in referring expression comprehension benchmarks. The tool provides pretrained model weights and instructions for data preparation, training, inference, and evaluation. Users can customize training by starting from intermediate checkpoints. Groma is designed to handle tasks related to detection pretraining, alignment pretraining, instruction finetuning, instruction following, and more.

amber-train
Amber is the first model in the LLM360 family, an initiative for comprehensive and fully open-sourced LLMs. It is a 7B English language model with the LLaMA architecture. The model type is a language model with the same architecture as LLaMA-7B. It is licensed under Apache 2.0. The resources available include training code, data preparation, metrics, and fully processed Amber pretraining data. The model has been trained on various datasets like Arxiv, Book, C4, Refined-Web, StarCoder, StackExchange, and Wikipedia. The hyperparameters include a total of 6.7B parameters, hidden size of 4096, intermediate size of 11008, 32 attention heads, 32 hidden layers, RMSNorm ε of 1e^-6, max sequence length of 2048, and a vocabulary size of 32000.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.