
AIT
Algorithmic Information Theory, using Binary Lambda Calculus
Stars: 169
AIT is a repository focused on Algorithmic Information Theory, specifically utilizing Binary Lambda Calculus. It provides resources and tools for studying and implementing algorithms based on information theory principles. The repository aims to explore the relationship between algorithms and information theory through the lens of Binary Lambda Calculus, offering insights into computational complexity and data compression techniques.
README:
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for AIT
Similar Open Source Tools
AIT
AIT is a repository focused on Algorithmic Information Theory, specifically utilizing Binary Lambda Calculus. It provides resources and tools for studying and implementing algorithms based on information theory principles. The repository aims to explore the relationship between algorithms and information theory through the lens of Binary Lambda Calculus, offering insights into computational complexity and data compression techniques.
dranet
Dranet is a Python library for analyzing and visualizing data from neural networks. It provides tools for interpreting model predictions, understanding feature importance, and evaluating model performance. With Dranet, users can gain insights into how neural networks make decisions and improve model transparency and interpretability.
Awesome-LLM-Psychometrics
This repository contains a collection of tools and resources for conducting psychometric analysis in the context of latent variable modeling. It includes scripts for data preprocessing, model estimation, and results interpretation. The tools provided here aim to assist researchers and practitioners in the field of psychology and related disciplines to analyze complex relationships among latent variables using advanced statistical techniques.

turftopic
Turftopic is a Python library that provides tools for sentiment analysis and topic modeling of text data. It allows users to analyze large volumes of text data to extract insights on sentiment and topics. The library includes functions for preprocessing text data, performing sentiment analysis using machine learning models, and conducting topic modeling using algorithms such as Latent Dirichlet Allocation (LDA). Turftopic is designed to be user-friendly and efficient, making it suitable for both beginners and experienced data analysts.
atomic-agents
The Atomic Agents framework is a modular and extensible tool designed for creating powerful applications. It leverages Pydantic for data validation and serialization. The framework follows the principles of Atomic Design, providing small and single-purpose components that can be combined. It integrates with Instructor for AI agent architecture and supports various APIs like Cohere, Anthropic, and Gemini. The tool includes documentation, examples, and testing features to ensure smooth development and usage.
dyad
Dyad is a lightweight Python library for analyzing dyadic data, which involves pairs of individuals and their interactions. It provides functions for computing various network metrics, visualizing network structures, and conducting statistical analyses on dyadic data. Dyad is designed to be user-friendly and efficient, making it suitable for researchers and practitioners working with relational data in fields such as social network analysis, communication studies, and psychology.
mcp-context-forge
MCP Context Forge is a powerful tool for generating context-aware data for machine learning models. It provides functionalities to create diverse datasets with contextual information, enhancing the performance of AI algorithms. The tool supports various data formats and allows users to customize the context generation process easily. With MCP Context Forge, users can efficiently prepare training data for tasks requiring contextual understanding, such as sentiment analysis, recommendation systems, and natural language processing.
nnstreamer
NNStreamer is a set of Gstreamer plugins that allow Gstreamer developers to adopt neural network models easily and efficiently and neural network developers to manage neural network pipelines and their filters easily and efficiently.

bisheng
Bisheng is a leading open-source **large model application development platform** that empowers and accelerates the development and deployment of large model applications, helping users enter the next generation of application development with the best possible experience.
multimodal_cognitive_ai
The multimodal cognitive AI repository focuses on research work related to multimodal cognitive artificial intelligence. It explores the integration of multiple modes of data such as text, images, and audio to enhance AI systems' cognitive capabilities. The repository likely contains code, datasets, and research papers related to multimodal AI applications, including natural language processing, computer vision, and audio processing. Researchers and developers interested in advancing AI systems' understanding of multimodal data can find valuable resources and insights in this repository.
llm_rl
llm_rl is a repository that combines llm (language model) and rl (reinforcement learning) techniques. It likely focuses on using language models in reinforcement learning tasks, such as natural language understanding and generation. The repository may contain implementations of algorithms that leverage both llm and rl to improve performance in various tasks. Developers interested in exploring the intersection of language models and reinforcement learning may find this repository useful for research and experimentation.
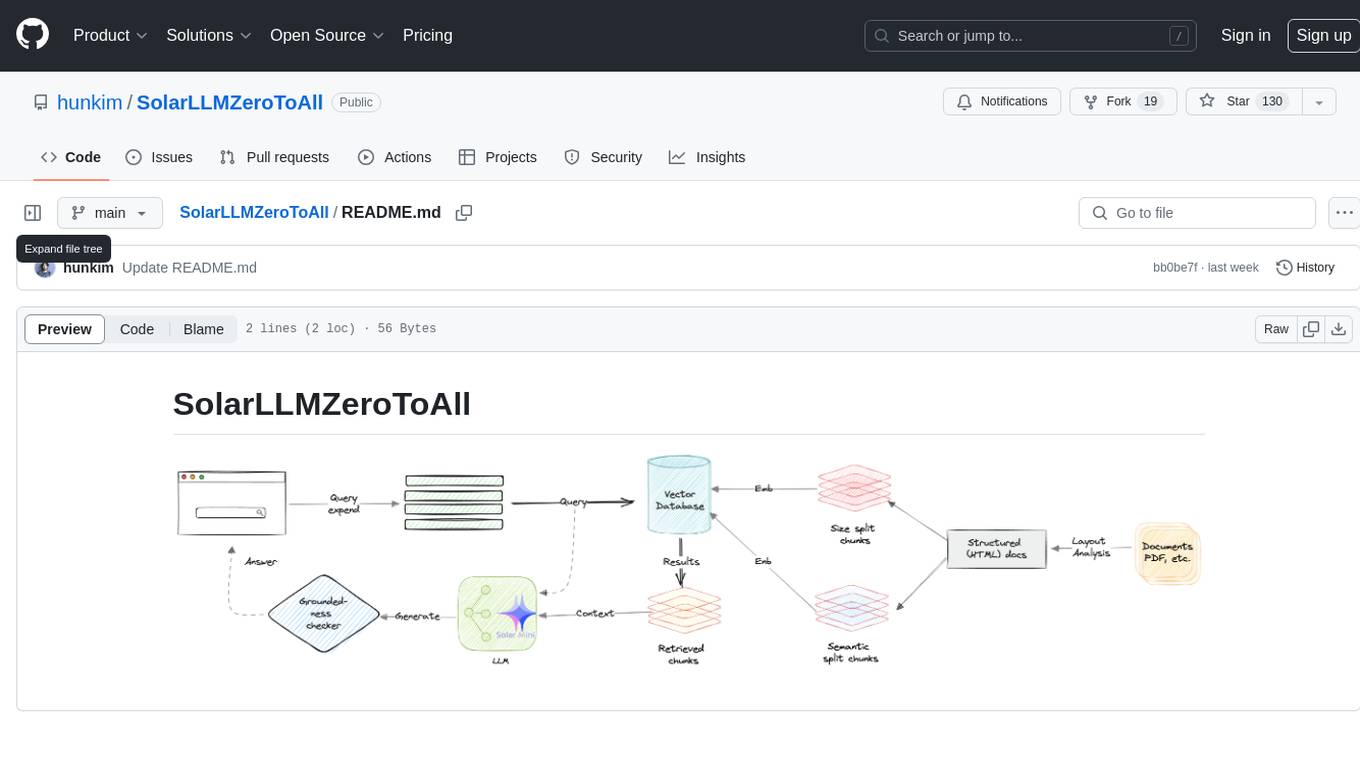
SolarLLMZeroToAll
SolarLLMZeroToAll is a comprehensive repository that provides a step-by-step guide and resources for learning and implementing Solar Longitudinal Learning Machines (SolarLLM) from scratch. The repository covers various aspects of SolarLLM, including theory, implementation, and applications, making it suitable for beginners and advanced users interested in solar energy forecasting and machine learning. The materials include detailed explanations, code examples, datasets, and visualization tools to facilitate understanding and practical implementation of SolarLLM models.
MaxKB
MaxKB is a knowledge base Q&A system based on the LLM large language model. MaxKB = Max Knowledge Base, which aims to become the most powerful brain of the enterprise.
kg_llm
This repository contains code associated with tutorials on implementing graph RAG using knowledge graphs and vector databases, enriching an LLM with structured data, and unraveling unstructured movie data. It includes notebooks for various tasks such as creating taxonomy, tagging movies, and working with movie data in CSV format.

flashinfer
FlashInfer is a library for Language Languages Models that provides high-performance implementation of LLM GPU kernels such as FlashAttention, PageAttention and LoRA. FlashInfer focus on LLM serving and inference, and delivers state-the-art performance across diverse scenarios.

enterprise-h2ogpte
Enterprise h2oGPTe - GenAI RAG is a repository containing code examples, notebooks, and benchmarks for the enterprise version of h2oGPTe, a powerful AI tool for generating text based on the RAG (Retrieval-Augmented Generation) architecture. The repository provides resources for leveraging h2oGPTe in enterprise settings, including implementation guides, performance evaluations, and best practices. Users can explore various applications of h2oGPTe in natural language processing tasks, such as text generation, content creation, and conversational AI.
For similar tasks

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

sorrentum
Sorrentum is an open-source project that aims to combine open-source development, startups, and brilliant students to build machine learning, AI, and Web3 / DeFi protocols geared towards finance and economics. The project provides opportunities for internships, research assistantships, and development grants, as well as the chance to work on cutting-edge problems, learn about startups, write academic papers, and get internships and full-time positions at companies working on Sorrentum applications.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

zep-python
Zep is an open-source platform for building and deploying large language model (LLM) applications. It provides a suite of tools and services that make it easy to integrate LLMs into your applications, including chat history memory, embedding, vector search, and data enrichment. Zep is designed to be scalable, reliable, and easy to use, making it a great choice for developers who want to build LLM-powered applications quickly and easily.

telemetry-airflow
This repository codifies the Airflow cluster that is deployed at workflow.telemetry.mozilla.org (behind SSO) and commonly referred to as "WTMO" or simply "Airflow". Some links relevant to users and developers of WTMO: * The `dags` directory in this repository contains some custom DAG definitions * Many of the DAGs registered with WTMO don't live in this repository, but are instead generated from ETL task definitions in bigquery-etl * The Data SRE team maintains a WTMO Developer Guide (behind SSO)

mojo
Mojo is a new programming language that bridges the gap between research and production by combining Python syntax and ecosystem with systems programming and metaprogramming features. Mojo is still young, but it is designed to become a superset of Python over time.

pandas-ai
PandasAI is a Python library that makes it easy to ask questions to your data in natural language. It helps you to explore, clean, and analyze your data using generative AI.

databend
Databend is an open-source cloud data warehouse that serves as a cost-effective alternative to Snowflake. With its focus on fast query execution and data ingestion, it's designed for complex analysis of the world's largest datasets.
For similar jobs
RLHF-Reward-Modeling
This repository, RLHF-Reward-Modeling, is dedicated to training reward models for DRL-based RLHF (PPO), Iterative SFT, and iterative DPO. It provides state-of-the-art performance in reward models with a base model size of up to 13B. The installation instructions involve setting up the environment and aligning the handbook. Dataset preparation requires preprocessing conversations into a standard format. The code can be run with Gemma-2b-it, and evaluation results can be obtained using provided datasets. The to-do list includes various reward models like Bradley-Terry, preference model, regression-based reward model, and multi-objective reward model. The repository is part of iterative rejection sampling fine-tuning and iterative DPO.
AIT
AIT is a repository focused on Algorithmic Information Theory, specifically utilizing Binary Lambda Calculus. It provides resources and tools for studying and implementing algorithms based on information theory principles. The repository aims to explore the relationship between algorithms and information theory through the lens of Binary Lambda Calculus, offering insights into computational complexity and data compression techniques.
AlgoListed
Algolisted is a pioneering platform dedicated to algorithmic problem-solving, offering a centralized hub for a diverse array of algorithmic challenges. It provides an immersive online environment for programmers to enhance their skills through Data Structures and Algorithms (DSA) sheets, academic progress tracking, resume refinement with OpenAI integration, adaptive testing, and job opportunity listings. The project is built on the MERN stack, Flask, Beautiful Soup, and Selenium,GEN AI, and deployed on Firebase. Algolisted aims to be a reliable companion in the pursuit of coding knowledge and proficiency.
RAM
This repository, RAM, focuses on developing advanced algorithms and methods for Reasoning, Alignment, Memory. It contains projects related to these areas and is maintained by a team of individuals. The repository is licensed under the MIT License.
oat
Oat is a simple and efficient framework for running online LLM alignment algorithms. It implements a distributed Actor-Learner-Oracle architecture, with components optimized using state-of-the-art tools. Oat simplifies the experimental pipeline of LLM alignment by serving an Oracle online for preference data labeling and model evaluation. It provides a variety of oracles for simulating feedback and supports verifiable rewards. Oat's modular structure allows for easy inheritance and modification of classes, enabling rapid prototyping and experimentation with new algorithms. The framework implements cutting-edge online algorithms like PPO for math reasoning and various online exploration algorithms.

all-in-rag
All-in-RAG is a comprehensive repository for all things related to Randomized Algorithms and Graphs. It provides a wide range of resources, including implementations of various randomized algorithms, graph data structures, and visualization tools. The repository aims to serve as a one-stop solution for researchers, students, and enthusiasts interested in exploring the intersection of randomized algorithms and graph theory. Whether you are looking to study theoretical concepts, implement algorithms in practice, or visualize graph structures, All-in-RAG has got you covered.
leetcode-py
A Python package to generate professional LeetCode practice environments. Features automated problem generation from LeetCode URLs, beautiful data structure visualizations (TreeNode, ListNode, GraphNode), and comprehensive testing with 10+ test cases per problem. Built with professional development practices including CI/CD, type hints, and quality gates. The tool provides a modern Python development environment with production-grade features such as linting, test coverage, logging, and CI/CD pipeline. It also offers enhanced data structure visualization for debugging complex structures, flexible notebook support, and a powerful CLI for generating problems anywhere.
OpenCatEsp32
OpenCat code running on BiBoard, a high-performance ESP32 quadruped robot development board. The board is mainly designed for developers and engineers working on multi-degree-of-freedom (MDOF) Multi-legged robots with up to 12 servos.