
kg_llm
Integrating knowledge graphs (KG) with large language models (LLM)
Stars: 86
This repository contains code associated with tutorials on implementing graph RAG using knowledge graphs and vector databases, enriching an LLM with structured data, and unraveling unstructured movie data. It includes notebooks for various tasks such as creating taxonomy, tagging movies, and working with movie data in CSV format.
README:
-
The notebook VectorVsKG.ipynb is the code associated with this tutorial: How to Implement Graph RAG Using Knowledge Graphs and Vector Databases
-
The notebook SDKG.ipynb is the code associated with this tutorial: Harnessing the Power of Knowledge Graphs: Enriching an LLM with Structured Data
-
The notebooks createTaxonomy.ipynb and tagMovies.ipynb, along with the moviesWithTags.csv are associated with this tutorial: Unraveling Unstructured Movie Data
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for kg_llm
Similar Open Source Tools
kg_llm
This repository contains code associated with tutorials on implementing graph RAG using knowledge graphs and vector databases, enriching an LLM with structured data, and unraveling unstructured movie data. It includes notebooks for various tasks such as creating taxonomy, tagging movies, and working with movie data in CSV format.

turftopic
Turftopic is a Python library that provides tools for sentiment analysis and topic modeling of text data. It allows users to analyze large volumes of text data to extract insights on sentiment and topics. The library includes functions for preprocessing text data, performing sentiment analysis using machine learning models, and conducting topic modeling using algorithms such as Latent Dirichlet Allocation (LDA). Turftopic is designed to be user-friendly and efficient, making it suitable for both beginners and experienced data analysts.
mcp-use
MCP-Use is a Python library for analyzing and processing text data using Markov Chains. It provides functionalities for generating text based on input data, calculating transition probabilities, and simulating text sequences. The library is designed to be user-friendly and efficient, making it suitable for natural language processing tasks.

datatune
Datatune is a data analysis tool designed to help users explore and analyze datasets efficiently. It provides a user-friendly interface for importing, cleaning, visualizing, and modeling data. With Datatune, users can easily perform tasks such as data preprocessing, feature engineering, model selection, and evaluation. The tool offers a variety of statistical and machine learning algorithms to support data analysis tasks. Whether you are a data scientist, analyst, or researcher, Datatune can streamline your data analysis workflow and help you derive valuable insights from your data.

upgini
Upgini is an intelligent data search engine with a Python library that helps users find and add relevant features to their ML pipeline from various public, community, and premium external data sources. It automates the optimization of connected data sources by generating an optimal set of machine learning features using large language models, GraphNNs, and recurrent neural networks. The tool aims to simplify feature search and enrichment for external data to make it a standard approach in machine learning pipelines. It democratizes access to data sources for the data science community.

Main
This repository contains material related to the new book _Synthetic Data and Generative AI_ by the author, including code for NoGAN, DeepResampling, and NoGAN_Hellinger. NoGAN is a tabular data synthesizer that outperforms GenAI methods in terms of speed and results, utilizing state-of-the-art quality metrics. DeepResampling is a fast NoGAN based on resampling and Bayesian Models with hyperparameter auto-tuning. NoGAN_Hellinger combines NoGAN and DeepResampling with the Hellinger model evaluation metric.
graph-llm-asynchow-plan
Graph-enhanced Large Language Models in Asynchronous Plan Reasoning is a repository containing code and datasets for the ICML-2024 paper. It includes naturalistic datasets, code for generating data, benchmarking experiments, and prototypical experiments. The repository also offers a train/test-split version of the dataset on huggingface. The paper focuses on utilizing large language models with graph enhancements for asynchronous plan reasoning.

cellm
Cellm is an Excel extension that allows users to leverage Large Language Models (LLMs) like ChatGPT within cell formulas. It enables users to extract AI responses to text ranges, making it useful for automating repetitive tasks that involve data processing and analysis. Cellm supports various models from Anthropic, Mistral, OpenAI, and Google, as well as locally hosted models via Llamafiles, Ollama, or vLLM. The tool is designed to simplify the integration of AI capabilities into Excel for tasks such as text classification, data cleaning, content summarization, entity extraction, and more.
PythonAiRoad
PythonAiRoad is a repository containing classic original articles source code from the 'Algorithm Gourmet House'. It is a platform for sharing algorithms and code related to artificial intelligence. Users are encouraged to contact the author for further discussions or collaborations. The repository serves as a valuable resource for those interested in AI algorithms and implementations.

ROGRAG
ROGRAG is a powerful open-source tool designed for data analysis and visualization. It provides a user-friendly interface for exploring and manipulating datasets, making it ideal for researchers, data scientists, and analysts. With ROGRAG, users can easily import, clean, analyze, and visualize data to gain valuable insights and make informed decisions. The tool supports a wide range of data formats and offers a variety of statistical and visualization tools to help users uncover patterns, trends, and relationships in their data. Whether you are working on exploratory data analysis, statistical modeling, or data visualization, ROGRAG is a versatile tool that can streamline your workflow and enhance your data analysis capabilities.

DB-GPT
DB-GPT is an open source AI native data app development framework with AWEL(Agentic Workflow Expression Language) and agents. It aims to build infrastructure in the field of large models, through the development of multiple technical capabilities such as multi-model management (SMMF), Text2SQL effect optimization, RAG framework and optimization, Multi-Agents framework collaboration, AWEL (agent workflow orchestration), etc. Which makes large model applications with data simpler and more convenient.
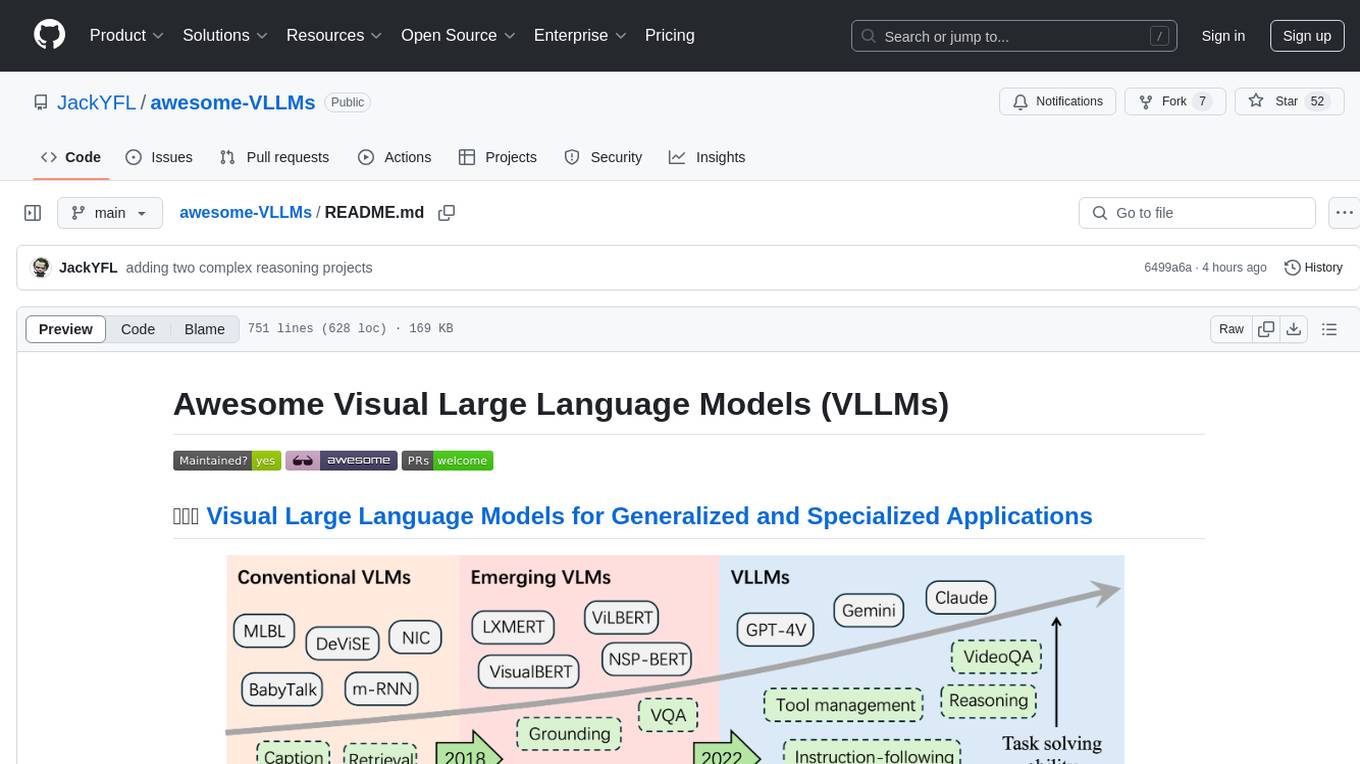
awesome-VLLMs
This repository contains a collection of pre-trained Very Large Language Models (VLLMs) that can be used for various natural language processing tasks. The models are fine-tuned on large text corpora and can be easily integrated into existing NLP pipelines for tasks such as text generation, sentiment analysis, and language translation. The repository also provides code examples and tutorials to help users get started with using these powerful language models in their projects.

AI_Spectrum
AI_Spectrum is a versatile machine learning library that provides a wide range of tools and algorithms for building and deploying AI models. It offers a user-friendly interface for data preprocessing, model training, and evaluation. With AI_Spectrum, users can easily experiment with different machine learning techniques and optimize their models for various tasks. The library is designed to be flexible and scalable, making it suitable for both beginners and experienced data scientists.
public
This public repository contains API, tools, and packages for Datagrok, a web-based data analytics platform. It offers support for scientific domains, applications, connectors to web services, visualizations, file importing, scientific methods in R, Python, or Julia, file metadata extractors, custom predictive models, platform enhancements, and more. The open-source packages are free to use, with restrictions on server computational capacities for the public environment. Academic institutions can use Datagrok for research and education, benefiting from reproducible and scalable computations and data augmentation capabilities. Developers can contribute by creating visualizations, scientific methods, file editors, connectors to web services, and more.
raft
RAFT (Reusable Accelerated Functions and Tools) is a C++ header-only template library with an optional shared library that contains fundamental widely-used algorithms and primitives for machine learning and information retrieval. The algorithms are CUDA-accelerated and form building blocks for more easily writing high performance applications.

data-juicer
Data-Juicer is a one-stop data processing system to make data higher-quality, juicier, and more digestible for LLMs. It is a systematic & reusable library of 80+ core OPs, 20+ reusable config recipes, and 20+ feature-rich dedicated toolkits, designed to function independently of specific LLM datasets and processing pipelines. Data-Juicer allows detailed data analyses with an automated report generation feature for a deeper understanding of your dataset. Coupled with multi-dimension automatic evaluation capabilities, it supports a timely feedback loop at multiple stages in the LLM development process. Data-Juicer offers tens of pre-built data processing recipes for pre-training, fine-tuning, en, zh, and more scenarios. It provides a speedy data processing pipeline requiring less memory and CPU usage, optimized for maximum productivity. Data-Juicer is flexible & extensible, accommodating most types of data formats and allowing flexible combinations of OPs. It is designed for simplicity, with comprehensive documentation, easy start guides and demo configs, and intuitive configuration with simple adding/removing OPs from existing configs.
For similar tasks
kg_llm
This repository contains code associated with tutorials on implementing graph RAG using knowledge graphs and vector databases, enriching an LLM with structured data, and unraveling unstructured movie data. It includes notebooks for various tasks such as creating taxonomy, tagging movies, and working with movie data in CSV format.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.