
bisheng
BISHENG is an open LLM devops platform for next generation Enterprise AI applications. Powerful and comprehensive features include: GenAI workflow, RAG, Agent, Unified model management, Evaluation, SFT, Dataset Management, Enterprise-level System Management, Observability and more.
Stars: 9705

Bisheng is a leading open-source **large model application development platform** that empowers and accelerates the development and deployment of large model applications, helping users enter the next generation of application development with the best possible experience.
README:
Proudly made by Chinese,May we, like the creators of Deepseek and Black Myth: Wukong, bring more wonder and greatness to the world.
源自中国匠心,希望我们能像 [Deepseek]、[黑神话:悟空] 团队一样,给世界带来更多美好。




BISHENG is an open LLM application devops platform, focusing on enterprise scenarios. It has been used by a large number of industry leading organizations and Fortune 500 companies.
"Bi Sheng" was the inventor of movable type printing, which played a vital role in promoting the transmission of human knowledge. We hope that BISHENG can also provide strong support for the widespread implementation of intelligent applications. Everyone is welcome to participate.
- Lingsight, a general-purpose agent with expert-level taste: Through the AGL(Agent Guidance Language) framework, we embed domain experts’ preferences, experience, and business logic into the AI, enabling the agent to exhibit “expert-level understanding” when handling tasks.
-
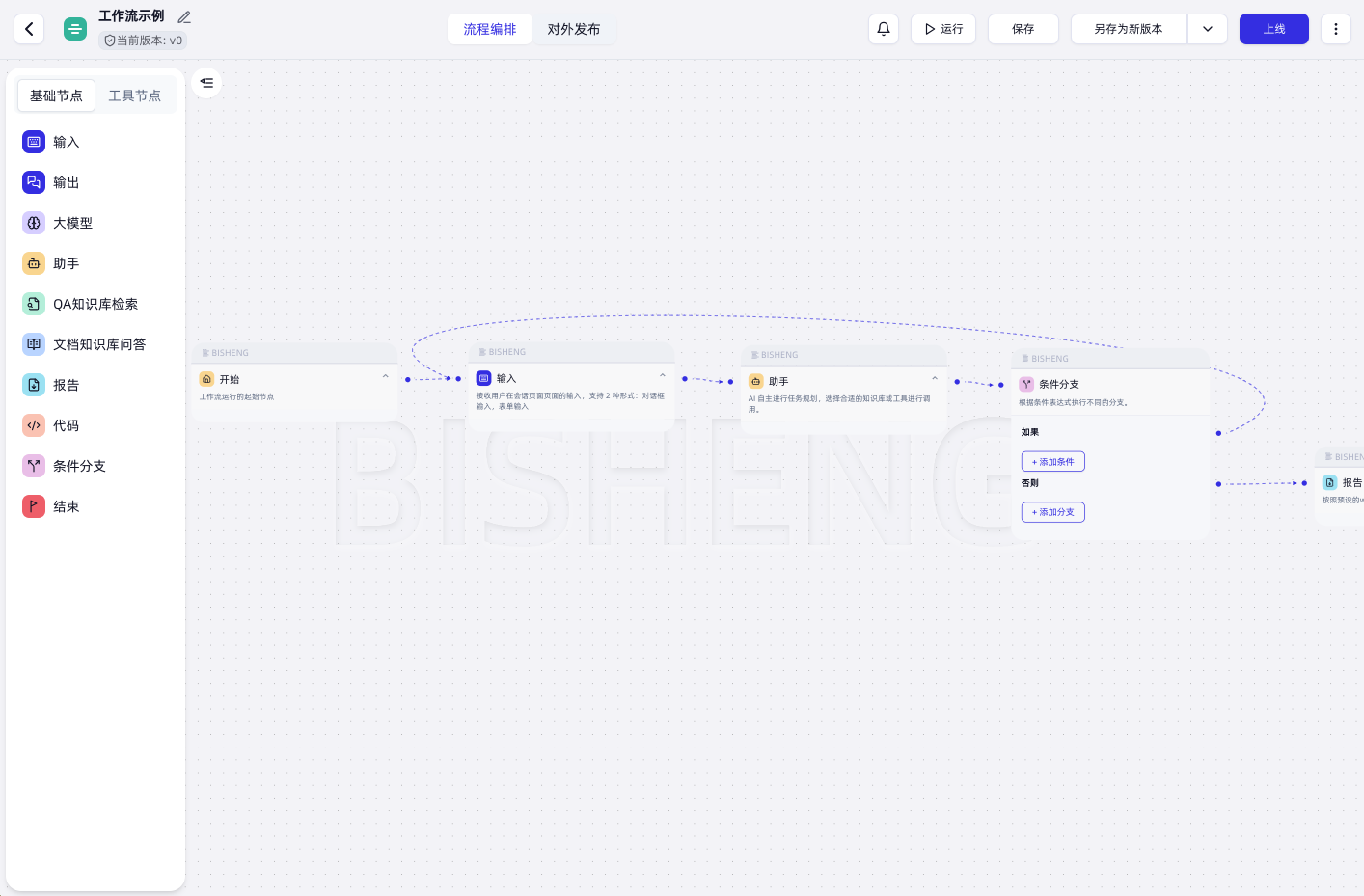
Unique BISHENG Workflow
- 🧩 Independent and comprehensive application orchestration framework: Enables the execution of various tasks within a single framework (while similar products rely on bot invocation or separate chatflow and workflow modules for different tasks).
- 🔄 Human in the loop: Allows users to intervene and provide feedback during the execution of workflows (including multi-turn conversations), whereas similar products can only execute workflows from start to finish without intervention.
- 💥 Powerful: Supports loops, parallelism, batch processing, conditional logic, and free combination of all logic components. It also handles complex scenarios such as multi-type input/output, report generation, content review, and more.
- 🖐️ User-friendly and intuitive: Operations like loops, parallelism, and batch processing, which require specialized components in similar products, can be easily visualized in BISHENG as a "flowchart" (drawing a loop forms a loop, aligning elements creates parallelism, and selecting multiple items enables batch processing).
-
Designed for Enterprise Applications: Document review, fixed-layout report generation, multi-agent collaboration, policy update comparison, support ticket assistance, customer service assistance, meeting minutes generation, resume screening, call record analysis, unstructured data governance, knowledge mining, data analysis, and more.
The platform supports the construction of highly complex enterprise application scenarios and offers deep optimization with hundreds of components and thousands of parameters.
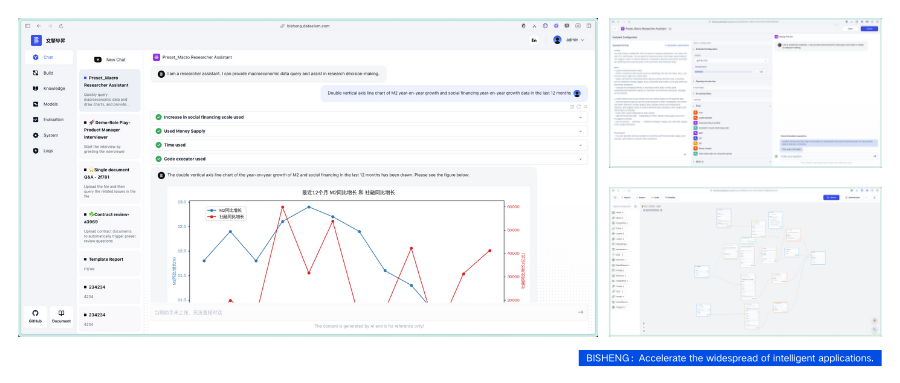
- Enterprise-grade features are the fundamental guarantee for application implementation: security review, RBAC, user group management, traffic control by group, SSO/LDAP, vulnerability scanning and patching, high availability deployment solutions, monitoring, statistics, and more.
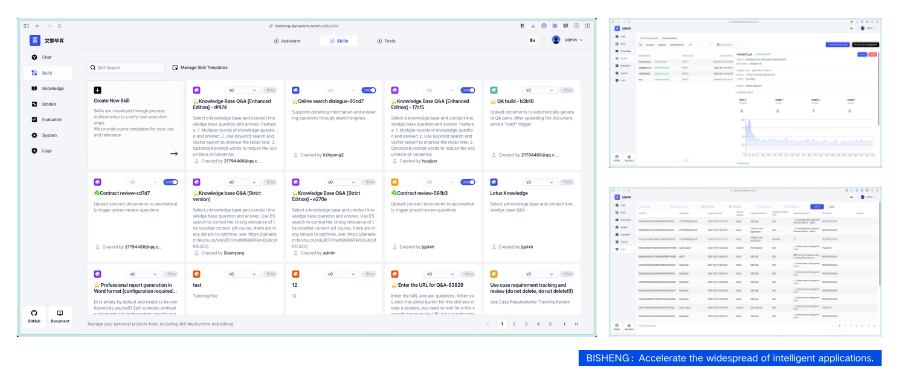
- High-Precision Document Parsing: Our high-precision document parsing model is trained on a vast amount of high-quality data accumulated over past 5 years. It includes high-precision printed text, handwritten text, and rare character recognition models, table recognition models, layout analysis models, and seal models., table recognition models, layout analysis models, and seal models. You can deploy it privately for free.

- A community for sharing best practices across various enterprise scenarios: An open repository of application cases and best practices.
Please ensure the following conditions are met before installing BISHENG:
- CPU >= 4 Virtual Cores
- RAM >= 16 GB
- Docker 19.03.9+
- Docker Compose 1.25.1+
Recommended hardware condition: 18 virtual cores, 48G. In addition to installing BISHENG, we will also install the following third-party components by default: ES, Milvus, and Onlyoffice.
Download BISHENG
git clone https://github.com/dataelement/bisheng.git
# Enter the installation directory
cd bisheng/docker
# If the system does not have the git command, you can download the BISHENG code as a zip file.
wget https://github.com/dataelement/bisheng/archive/refs/heads/main.zip
# Unzip and enter the installation directory
unzip main.zip && cd bisheng-main/dockerStart BISHENG
docker compose -f docker-compose.yml -p bisheng up -dAfter the startup is complete, access http://IP:3001 in the browser. The login page will appear, proceed with user registration.
By default, the first registered user will become the system admin.
For more installation and deployment issues, refer to::Self-hosting
This repo benefits from langchain langflow unstructured and LLaMA-Factory . Thanks for their wonderful works.
Thank you to our contributors:
Welcome to join our discussion group

For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for bisheng
Similar Open Source Tools
bisheng
Bisheng is a leading open-source **large model application development platform** that empowers and accelerates the development and deployment of large model applications, helping users enter the next generation of application development with the best possible experience.

DB-GPT
DB-GPT is an open source AI native data app development framework with AWEL(Agentic Workflow Expression Language) and agents. It aims to build infrastructure in the field of large models, through the development of multiple technical capabilities such as multi-model management (SMMF), Text2SQL effect optimization, RAG framework and optimization, Multi-Agents framework collaboration, AWEL (agent workflow orchestration), etc. Which makes large model applications with data simpler and more convenient.

deeppowers
Deeppowers is a powerful Python library for deep learning applications. It provides a wide range of tools and utilities to simplify the process of building and training deep neural networks. With Deeppowers, users can easily create complex neural network architectures, perform efficient training and optimization, and deploy models for various tasks. The library is designed to be user-friendly and flexible, making it suitable for both beginners and experienced deep learning practitioners.
FastGPT
FastGPT is a knowledge base Q&A system based on the LLM large language model, providing out-of-the-box data processing, model calling and other capabilities. At the same time, you can use Flow to visually arrange workflows to achieve complex Q&A scenarios!

pdr_ai_v2
pdr_ai_v2 is a Python library for implementing machine learning algorithms and models. It provides a wide range of tools and functionalities for data preprocessing, model training, evaluation, and deployment. The library is designed to be user-friendly and efficient, making it suitable for both beginners and experienced data scientists. With pdr_ai_v2, users can easily build and deploy machine learning models for various applications, such as classification, regression, clustering, and more.

lemonai
LemonAI is a versatile machine learning library designed to simplify the process of building and deploying AI models. It provides a wide range of tools and algorithms for data preprocessing, model training, and evaluation. With LemonAI, users can easily experiment with different machine learning techniques and optimize their models for various tasks. The library is well-documented and beginner-friendly, making it suitable for both novice and experienced data scientists. LemonAI aims to streamline the development of AI applications and empower users to create innovative solutions using state-of-the-art machine learning methods.

deepteam
Deepteam is a powerful open-source tool designed for deep learning projects. It provides a user-friendly interface for training, testing, and deploying deep neural networks. With Deepteam, users can easily create and manage complex models, visualize training progress, and optimize hyperparameters. The tool supports various deep learning frameworks and allows seamless integration with popular libraries like TensorFlow and PyTorch. Whether you are a beginner or an experienced deep learning practitioner, Deepteam simplifies the development process and accelerates model deployment.

open-ai
Open AI is a powerful tool for artificial intelligence research and development. It provides a wide range of machine learning models and algorithms, making it easier for developers to create innovative AI applications. With Open AI, users can explore cutting-edge technologies such as natural language processing, computer vision, and reinforcement learning. The platform offers a user-friendly interface and comprehensive documentation to support users in building and deploying AI solutions. Whether you are a beginner or an experienced AI practitioner, Open AI offers the tools and resources you need to accelerate your AI projects and stay ahead in the rapidly evolving field of artificial intelligence.

agenta
Agenta is an open-source LLM developer platform for prompt engineering, evaluation, human feedback, and deployment of complex LLM applications. It provides tools for prompt engineering and management, evaluation, human annotation, and deployment, all without imposing any restrictions on your choice of framework, library, or model. Agenta allows developers and product teams to collaborate in building production-grade LLM-powered applications in less time.

tensorzero
TensorZero is an open-source platform that helps LLM applications graduate from API wrappers into defensible AI products. It enables a data & learning flywheel for LLMs by unifying inference, observability, optimization, and experimentation. The platform includes a high-performance model gateway, structured schema-based inference, observability, experimentation, and data warehouse for analytics. TensorZero Recipes optimize prompts and models, and the platform supports experimentation features and GitOps orchestration for deployment.

enterprise-h2ogpte
Enterprise h2oGPTe - GenAI RAG is a repository containing code examples, notebooks, and benchmarks for the enterprise version of h2oGPTe, a powerful AI tool for generating text based on the RAG (Retrieval-Augmented Generation) architecture. The repository provides resources for leveraging h2oGPTe in enterprise settings, including implementation guides, performance evaluations, and best practices. Users can explore various applications of h2oGPTe in natural language processing tasks, such as text generation, content creation, and conversational AI.

BentoVLLM
BentoVLLM is an example project demonstrating how to serve and deploy open-source Large Language Models using vLLM, a high-throughput and memory-efficient inference engine. It provides a basis for advanced code customization, such as custom models, inference logic, or vLLM options. The project allows for simple LLM hosting with OpenAI compatible endpoints without the need to write any code. Users can interact with the server using Swagger UI or other methods, and the service can be deployed to BentoCloud for better management and scalability. Additionally, the repository includes integration examples for different LLM models and tools.
llmgateway
The llmgateway repository is a tool that provides a gateway for interacting with various LLM (Large Language Model) models. It allows users to easily access and utilize pre-trained language models for tasks such as text generation, sentiment analysis, and language translation. The tool simplifies the process of integrating LLMs into applications and workflows, enabling developers to leverage the power of state-of-the-art language models for various natural language processing tasks.
MaIN.NET
MaIN.NET (Modular Artificial Intelligence Network) is a versatile .NET package designed to streamline the integration of large language models (LLMs) into advanced AI workflows. It offers a flexible and robust foundation for developing chatbots, automating processes, and exploring innovative AI techniques. The package connects diverse AI methods into one unified ecosystem, empowering developers with a low-code philosophy to create powerful AI applications with ease.
AimRT
AimRT is a basic runtime framework for modern robotics, developed in modern C++ with lightweight and easy deployment. It integrates research and development for robot applications in various deployment scenarios, providing debugging tools and observability support. AimRT offers a plug-in development interface compatible with ROS2, HTTP, Grpc, and other ecosystems for progressive system upgrades.

Fast-dLLM
Fast-DLLM is a diffusion-based Large Language Model (LLM) inference acceleration framework that supports efficient inference for models like Dream and LLaDA. It offers fast inference support, multiple optimization strategies, code generation, evaluation capabilities, and an interactive chat interface. Key features include Key-Value Cache for Block-Wise Decoding, Confidence-Aware Parallel Decoding, and overall performance improvements. The project structure includes directories for Dream and LLaDA model-related code, with installation and usage instructions provided for using the LLaDA and Dream models.
For similar tasks

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

jupyter-ai
Jupyter AI connects generative AI with Jupyter notebooks. It provides a user-friendly and powerful way to explore generative AI models in notebooks and improve your productivity in JupyterLab and the Jupyter Notebook. Specifically, Jupyter AI offers: * An `%%ai` magic that turns the Jupyter notebook into a reproducible generative AI playground. This works anywhere the IPython kernel runs (JupyterLab, Jupyter Notebook, Google Colab, Kaggle, VSCode, etc.). * A native chat UI in JupyterLab that enables you to work with generative AI as a conversational assistant. * Support for a wide range of generative model providers, including AI21, Anthropic, AWS, Cohere, Gemini, Hugging Face, NVIDIA, and OpenAI. * Local model support through GPT4All, enabling use of generative AI models on consumer grade machines with ease and privacy.

khoj
Khoj is an open-source, personal AI assistant that extends your capabilities by creating always-available AI agents. You can share your notes and documents to extend your digital brain, and your AI agents have access to the internet, allowing you to incorporate real-time information. Khoj is accessible on Desktop, Emacs, Obsidian, Web, and Whatsapp, and you can share PDF, markdown, org-mode, notion files, and GitHub repositories. You'll get fast, accurate semantic search on top of your docs, and your agents can create deeply personal images and understand your speech. Khoj is self-hostable and always will be.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).

danswer
Danswer is an open-source Gen-AI Chat and Unified Search tool that connects to your company's docs, apps, and people. It provides a Chat interface and plugs into any LLM of your choice. Danswer can be deployed anywhere and for any scale - on a laptop, on-premise, or to cloud. Since you own the deployment, your user data and chats are fully in your own control. Danswer is MIT licensed and designed to be modular and easily extensible. The system also comes fully ready for production usage with user authentication, role management (admin/basic users), chat persistence, and a UI for configuring Personas (AI Assistants) and their Prompts. Danswer also serves as a Unified Search across all common workplace tools such as Slack, Google Drive, Confluence, etc. By combining LLMs and team specific knowledge, Danswer becomes a subject matter expert for the team. Imagine ChatGPT if it had access to your team's unique knowledge! It enables questions such as "A customer wants feature X, is this already supported?" or "Where's the pull request for feature Y?"

infinity
Infinity is an AI-native database designed for LLM applications, providing incredibly fast full-text and vector search capabilities. It supports a wide range of data types, including vectors, full-text, and structured data, and offers a fused search feature that combines multiple embeddings and full text. Infinity is easy to use, with an intuitive Python API and a single-binary architecture that simplifies deployment. It achieves high performance, with 0.1 milliseconds query latency on million-scale vector datasets and up to 15K QPS.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.
LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.