
edgen
⚡ Edgen: Local, private GenAI server alternative to OpenAI. No GPU required. Run AI models locally: LLMs (Llama2, Mistral, Mixtral...), Speech-to-text (whisper) and many others.
Stars: 279
Edgen is a local GenAI API server that serves as a drop-in replacement for OpenAI's API. It provides multi-endpoint support for chat completions and speech-to-text, is model agnostic, offers optimized inference, and features model caching. Built in Rust, Edgen is natively compiled for Windows, MacOS, and Linux, eliminating the need for Docker. It allows users to utilize GenAI locally on their devices for free and with data privacy. With features like session caching, GPU support, and support for various endpoints, Edgen offers a scalable, reliable, and cost-effective solution for running GenAI applications locally.
README:

| Documentation | Blog | Discord | Roadmap |

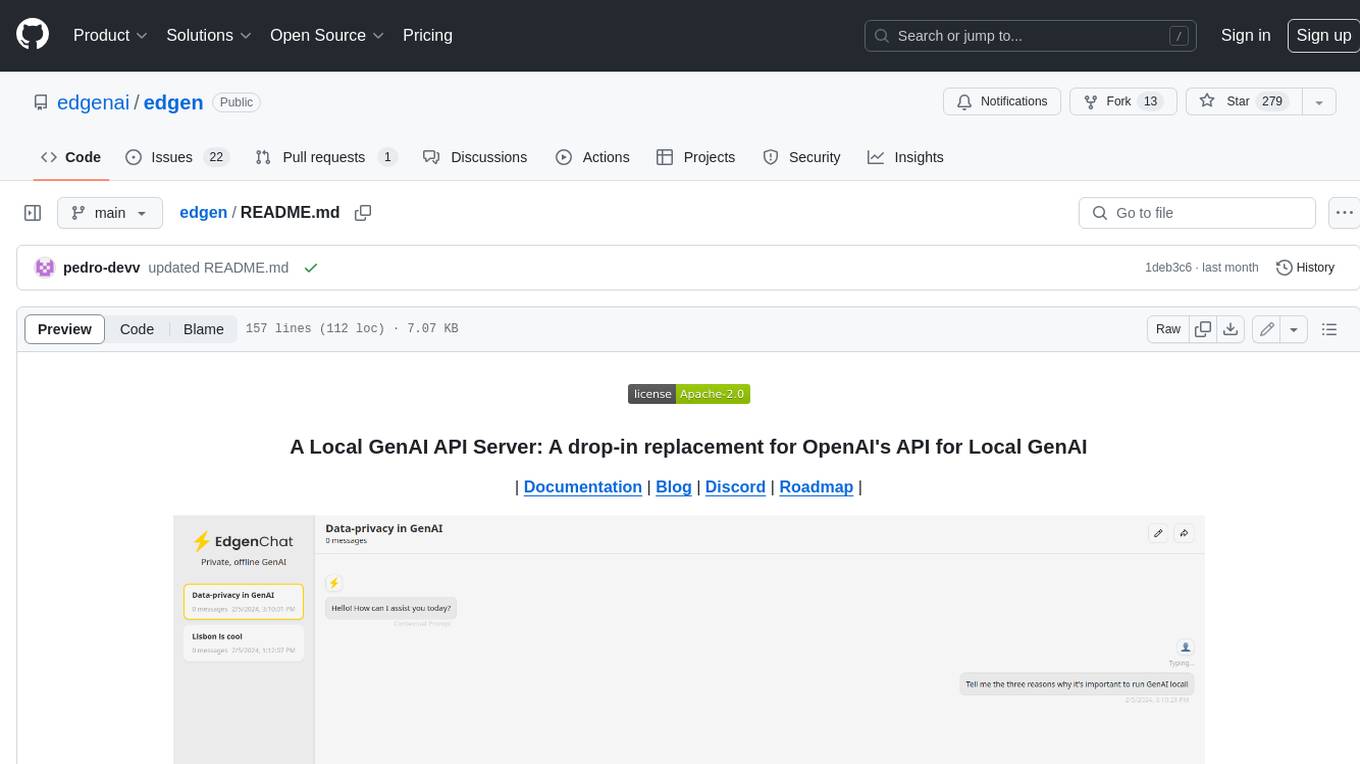
EdgenChat, a local chat app powered by ⚡Edgen
- [x] OpenAI Compliant API: ⚡Edgen implements an OpenAI compatible API, making it a drop-in replacement.
- [x] Multi-Endpoint Support: ⚡Edgen exposes multiple AI endpoints such as chat completions (LLMs) and speech-to-text (Whisper) for audio transcriptions.
- [x] Model Agnostic: LLMs (Llama2, Mistral, Mixtral...), Speech-to-text (whisper) and many others.
- [x] Optimized Inference: You don't need to take a PhD in AI optimization. ⚡Edgen abstracts the complexity of optimizing inference for different hardware, platforms and models.
- [x] Modular: ⚡Edgen is model and runtime agnostic. New models can be added easily and ⚡Edgen can select the best runtime for the user's hardware: you don't need to keep up about the latest models and ML runtimes - ⚡Edgen will do that for you.
- [x] Model Caching: ⚡Edgen caches foundational models locally, so 1 model can power hundreds of different apps - users don't need to download the same model multiple times.
- [x] Native: ⚡Edgen is built in 🦀Rust and is natively compiled to all popular platforms: Windows, MacOS and Linux. No docker required.
- [ ] Graphical Interface: A graphical user interface to help users efficiently manage their models, endpoints and permissions.
⚡Edgen lets you use GenAI in your app, completely locally on your user's devices, for free and with data-privacy. It's a drop-in replacement for OpenAI (it uses the a compatible API), supports various functions like text generation, speech-to-text and works on Windows, Linux, and MacOS.
- [x] Session Caching: ⚡Edgen maintains top performance with big contexts (big chat histories), by caching sessions. Sessions are auto-detected in function of the chat history.
- [x] GPU support: CUDA, Vulkan. Metal
- [x] [Chat] Completions
- [x] [Audio] Transcriptions
- [x] [Embeddings] Embeddings
- [ ] [Image] Generation
- [ ] [Chat] Multimodal chat completions
- [ ] [Audio] Speech
Check in the documentation
- [x] Windows
- [x] Linux
- [x] MacOS
-
Data Private: On-device inference means users' data never leave their devices.
-
Scalable: More and more users? No need to increment cloud computing infrastructure. Just let your users use their own hardware.
-
Reliable: No internet, no downtime, no rate limits, no API keys.
-
Free: It runs locally on hardware the user already owns.
Ready to start your own GenAI application? Checkout our guides!
⚡Edgen usage:
Usage: edgen [<command>] [<args>]
Toplevel CLI commands and options. Subcommands are optional. If no command is provided "serve" will be invoked with default options.
Options:
--help display usage information
Commands:
serve Starts the edgen server. This is the default command when no
command is provided.
config Configuration-related subcommands.
version Prints the edgen version to stdout.
oasgen Generates the Edgen OpenAPI specification.
edgen serve usage:
Usage: edgen serve [-b <uri...>] [-g]
Starts the edgen server. This is the default command when no command is provided.
Options:
-b, --uri if present, one or more URIs/hosts to bind the server to.
`unix://` (on Linux), `http://`, and `ws://` are supported.
For use in scripts, it is recommended to explicitly add this
option to make your scripts future-proof.
-g, --nogui if present, edgen will not start the GUI; the default
behavior is to start the GUI.
--help display usage information
⚡Edgen also supports compilation and execution on a GPU, when building from source, through Vulkan, CUDA and Metal. The following cargo features enable the GPU:
-
llama_vulkan- execute LLM models using Vulkan. Requires a Vulkan SDK to be installed. -
llama_cuda- execute LLM models using CUDA. Requires a CUDA Toolkit to be installed. -
llama_metal- execute LLM models using Metal. -
whisper_cuda- execute Whisper models using CUDA. Requires a CUDA Toolkit to be installed.
Note that, at the moment, llama_vulkan, llama_cuda and llama_metal cannot be enabled at the same time.
Example usage (building from source, you need to first install the prerequisites):
cargo run --features llama_vulkan --release -- serve

⚡Edgen architecture overview
If you don't know where to start, check Edgen's roadmap! Before you start working on something, see if there's an existing issue/pull-request. Pop into Discord to check with the team or see if someone's already tackling it.
- Edgen Discord server: Real time discussions with the ⚡Edgen team and other users.
- GitHub issues: Feature requests, bugs.
- GitHub discussions: Q&A.
- Blog: Big announcements.
-
llama.cpp,whisper.cpp, andggmlfor being an excellent getting-on point for this space.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for edgen
Similar Open Source Tools
edgen
Edgen is a local GenAI API server that serves as a drop-in replacement for OpenAI's API. It provides multi-endpoint support for chat completions and speech-to-text, is model agnostic, offers optimized inference, and features model caching. Built in Rust, Edgen is natively compiled for Windows, MacOS, and Linux, eliminating the need for Docker. It allows users to utilize GenAI locally on their devices for free and with data privacy. With features like session caching, GPU support, and support for various endpoints, Edgen offers a scalable, reliable, and cost-effective solution for running GenAI applications locally.

llm-answer-engine
This repository contains the code and instructions needed to build a sophisticated answer engine that leverages the capabilities of Groq, Mistral AI's Mixtral, Langchain.JS, Brave Search, Serper API, and OpenAI. Designed to efficiently return sources, answers, images, videos, and follow-up questions based on user queries, this project is an ideal starting point for developers interested in natural language processing and search technologies.

opencompass
OpenCompass is a one-stop platform for large model evaluation, aiming to provide a fair, open, and reproducible benchmark for large model evaluation. Its main features include: * Comprehensive support for models and datasets: Pre-support for 20+ HuggingFace and API models, a model evaluation scheme of 70+ datasets with about 400,000 questions, comprehensively evaluating the capabilities of the models in five dimensions. * Efficient distributed evaluation: One line command to implement task division and distributed evaluation, completing the full evaluation of billion-scale models in just a few hours. * Diversified evaluation paradigms: Support for zero-shot, few-shot, and chain-of-thought evaluations, combined with standard or dialogue-type prompt templates, to easily stimulate the maximum performance of various models. * Modular design with high extensibility: Want to add new models or datasets, customize an advanced task division strategy, or even support a new cluster management system? Everything about OpenCompass can be easily expanded! * Experiment management and reporting mechanism: Use config files to fully record each experiment, and support real-time reporting of results.
restai
RestAI is an AIaaS (AI as a Service) platform that allows users to create and consume AI agents (projects) using a simple REST API. It supports various types of agents, including RAG (Retrieval-Augmented Generation), RAGSQL (RAG for SQL), inference, vision, and router. RestAI features automatic VRAM management, support for any public LLM supported by LlamaIndex or any local LLM supported by Ollama, a user-friendly API with Swagger documentation, and a frontend for easy access. It also provides evaluation capabilities for RAG agents using deepeval.
ChatGPT-desktop
ChatGPT Desktop Application is a multi-platform tool that provides a powerful AI wrapper for generating text. It offers features like text-to-speech, exporting chat history in various formats, automatic application upgrades, system tray hover window, support for slash commands, customization of global shortcuts, and pop-up search. The application is built using Tauri and aims to enhance user experience by simplifying text generation tasks. It is available for Mac, Windows, and Linux, and is designed for personal learning and research purposes.

preswald
Preswald is a full-stack platform for building, deploying, and managing interactive data applications in Python. It simplifies the process by combining ingestion, storage, transformation, and visualization into one lightweight SDK. With Preswald, users can connect to various data sources, customize app themes, and easily deploy apps locally. The platform focuses on code-first simplicity, end-to-end coverage, and efficiency by design, making it suitable for prototyping internal tools or deploying production-grade apps with reduced complexity and cost.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.

Instrukt
Instrukt is a terminal-based AI integrated environment that allows users to create and instruct modular AI agents, generate document indexes for question-answering, and attach tools to any agent. It provides a platform for users to interact with AI agents in natural language and run them inside secure containers for performing tasks. The tool supports custom AI agents, chat with code and documents, tools customization, prompt console for quick interaction, LangChain ecosystem integration, secure containers for agent execution, and developer console for debugging and introspection. Instrukt aims to make AI accessible to everyone by providing tools that empower users without relying on external APIs and services.
partcad
PartCAD is a tool for documenting manufacturable physical products, providing tools to maintain product information and streamline workflows at all product lifecycle phases. It is a next-generation CAD tool that focuses on specifying manufacturable physical products using computer-aided design in a more generic sense, including the use of AI models. PartCAD offers modular and reusable packages for product information, generating outputs like product documentation, bill of materials, sourcing information, and manufacturing process specifications. It integrates with third-party tools for iterative improvements, design validation, and manufacturing processes verification. PartCAD also offers supplementary products like a CRM and inventory tool for managing part manufacturing and assembly shops. By enabling easy switching between third-party tools, PartCAD creates a competitive environment for service providers and ensures data sovereignty for users.
portia-sdk-python
Portia AI is an open source developer framework for predictable, stateful, authenticated agentic workflows. It allows developers to have oversight over their multi-agent deployments and focuses on production readiness. The framework supports iterating on agents' reasoning, extensive tool support including MCP support, authentication for API and web agents, and is production-ready with features like attribute multi-agent runs, large inputs and outputs storage, and connecting any LLM. Portia AI aims to provide a flexible and reliable platform for developing AI agents with tools, authentication, and smart control.
OpenAI-Api-Unreal
The OpenAIApi Plugin provides access to the OpenAI API in Unreal Engine, allowing users to generate images, transcribe speech, and power NPCs using advanced AI models. It offers blueprint nodes for making API calls, setting parameters, and accessing completion values. Users can authenticate using an API key directly or as an environment variable. The plugin supports various tasks such as generating images, transcribing speech, and interacting with NPCs through chat endpoints.
zero-true
Zero-True is a Python and SQL reactive computational notebook designed for building and collaborating on data-driven applications. It offers an integrated and simple environment with transparent updates, dynamic and interactive UI rendering, fast prototyping capabilities, and open-source community contributions. Users can create rich, reactive apps with ease and publish them confidently. Zero-True aims to improve data accessibility and foster collaboration among users.
UFO
UFO is a UI-focused dual-agent framework to fulfill user requests on Windows OS by seamlessly navigating and operating within individual or spanning multiple applications.

comfyui_LLM_Polymath
LLM Polymath Chat Node is an advanced Chat Node for ComfyUI that integrates large language models to build text-driven applications and automate data processes, enhancing prompt responses by incorporating real-time web search, linked content extraction, and custom agent instructions. It supports both OpenAI’s GPT-like models and alternative models served via a local Ollama API. The core functionalities include Comfy Node Finder and Smart Assistant, along with additional agents like Flux Prompter, Custom Instructors, Python debugger, and scripter. The tool offers features for prompt processing, web search integration, model & API integration, custom instructions, image handling, logging & debugging, output compression, and more.
upscayl
Upscayl is a free and open-source AI image upscaler that uses advanced AI algorithms to enlarge and enhance low-resolution images without losing quality. It is a cross-platform application built with the Linux-first philosophy, available on all major desktop operating systems. Upscayl utilizes Real-ESRGAN and Vulkan architecture for image enhancement, and its backend is fully open-source under the AGPLv3 license. It is important to note that a Vulkan compatible GPU is required for Upscayl to function effectively.
obsidian-arcana
Arcana is a plugin for Obsidian that offers a collection of AI-powered tools inspired by famous historical figures to enhance creativity and productivity. It includes tools for conversation, text-to-speech transcription, speech-to-text replies, metadata markup, text generation, file moving, flashcard generation, auto tagging, and note naming. Users can interact with these tools using the command palette and sidebar views, with an OpenAI API key required for usage. The plugin aims to assist users in various note-taking and knowledge management tasks within the Obsidian vault environment.
For similar tasks
edgen
Edgen is a local GenAI API server that serves as a drop-in replacement for OpenAI's API. It provides multi-endpoint support for chat completions and speech-to-text, is model agnostic, offers optimized inference, and features model caching. Built in Rust, Edgen is natively compiled for Windows, MacOS, and Linux, eliminating the need for Docker. It allows users to utilize GenAI locally on their devices for free and with data privacy. With features like session caching, GPU support, and support for various endpoints, Edgen offers a scalable, reliable, and cost-effective solution for running GenAI applications locally.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

LocalAI
LocalAI is a free and open-source OpenAI alternative that acts as a drop-in replacement REST API compatible with OpenAI (Elevenlabs, Anthropic, etc.) API specifications for local AI inferencing. It allows users to run LLMs, generate images, audio, and more locally or on-premises with consumer-grade hardware, supporting multiple model families and not requiring a GPU. LocalAI offers features such as text generation with GPTs, text-to-audio, audio-to-text transcription, image generation with stable diffusion, OpenAI functions, embeddings generation for vector databases, constrained grammars, downloading models directly from Huggingface, and a Vision API. It provides a detailed step-by-step introduction in its Getting Started guide and supports community integrations such as custom containers, WebUIs, model galleries, and various bots for Discord, Slack, and Telegram. LocalAI also offers resources like an LLM fine-tuning guide, instructions for local building and Kubernetes installation, projects integrating LocalAI, and a how-tos section curated by the community. It encourages users to cite the repository when utilizing it in downstream projects and acknowledges the contributions of various software from the community.

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.

glide
Glide is a cloud-native LLM gateway that provides a unified REST API for accessing various large language models (LLMs) from different providers. It handles LLMOps tasks such as model failover, caching, key management, and more, making it easy to integrate LLMs into applications. Glide supports popular LLM providers like OpenAI, Anthropic, Azure OpenAI, AWS Bedrock (Titan), Cohere, Google Gemini, OctoML, and Ollama. It offers high availability, performance, and observability, and provides SDKs for Python and NodeJS to simplify integration.

jupyter-ai
Jupyter AI connects generative AI with Jupyter notebooks. It provides a user-friendly and powerful way to explore generative AI models in notebooks and improve your productivity in JupyterLab and the Jupyter Notebook. Specifically, Jupyter AI offers: * An `%%ai` magic that turns the Jupyter notebook into a reproducible generative AI playground. This works anywhere the IPython kernel runs (JupyterLab, Jupyter Notebook, Google Colab, Kaggle, VSCode, etc.). * A native chat UI in JupyterLab that enables you to work with generative AI as a conversational assistant. * Support for a wide range of generative model providers, including AI21, Anthropic, AWS, Cohere, Gemini, Hugging Face, NVIDIA, and OpenAI. * Local model support through GPT4All, enabling use of generative AI models on consumer grade machines with ease and privacy.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).

infinity
Infinity is an AI-native database designed for LLM applications, providing incredibly fast full-text and vector search capabilities. It supports a wide range of data types, including vectors, full-text, and structured data, and offers a fused search feature that combines multiple embeddings and full text. Infinity is easy to use, with an intuitive Python API and a single-binary architecture that simplifies deployment. It achieves high performance, with 0.1 milliseconds query latency on million-scale vector datasets and up to 15K QPS.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.