Best AI tools for< Cache Models >
6 - AI tool Sites

Default Web Site Page
The website page appears to be a default error page indicating that the site is not accessible. It provides information for the website owner on potential reasons for the error, such as IP address changes, DNS settings, server misconfigurations, or server migrations. The page advises on steps to potentially resolve the issue, including clearing DNS cache and verifying Apache settings. The copyright information at the bottom indicates it is powered by cPanel, L.L.C.

Default Web Site Page
The website page provides a default message indicating that the site is inaccessible. It suggests contacting the hosting provider if the IP address has changed or if there is a server misconfiguration. The message also advises checking DNS settings and clearing the DNS cache. It mentions the possibility of the site moving to a different server and provides a copyright notice from cPanel, L.L.C.
DataGPT
DataGPT is a conversational AI data analyst that provides instant analysis and answers to any data-related question in everyday language. It connects to any data source and automatically defines and suggests the most relevant metrics and dimensions. DataGPT's core analytics engine carries out intricate analysis against all data, checking every segment, identifying anomalies, detecting outliers, diving into funnel analytics, or conducting robust comparative analysis to reveal accurate results. The AI-powered onboarding agent guides users through the setup process, and the Lightning Cache boosts query speeds 100x over current data warehouses. The Data Navigator allows users to freely explore any part of their data with just a few clicks. DataGPT empowers decision-makers by replacing specialized dashboards with an 'ask me anything' interface, enabling them to access essential insights on demand.
Application Error
The website seems to be experiencing an application error, which indicates a technical issue with the application. It may be a temporary problem that needs to be resolved by the website's developers. An application error can occur due to various reasons such as bugs in the code, server issues, or database problems. Users encountering this error may need to refresh the page, clear their cache, or contact the website's support team for assistance.
imgix
imgix is an end-to-end visual media solution that enables users to create, transform, and optimize captivating images and videos for an unparalleled visual experience. It simplifies the complex visual media technology, improves web performance, and delivers responsive design. Trusted by innovative companies worldwide, imgix offers features such as easy cloud storage connection, intelligent compression, fast loading with a globally distributed CDN, over 150 image operations, video streaming, asset management, intuitive analytics, and powerful SDKs & tools.
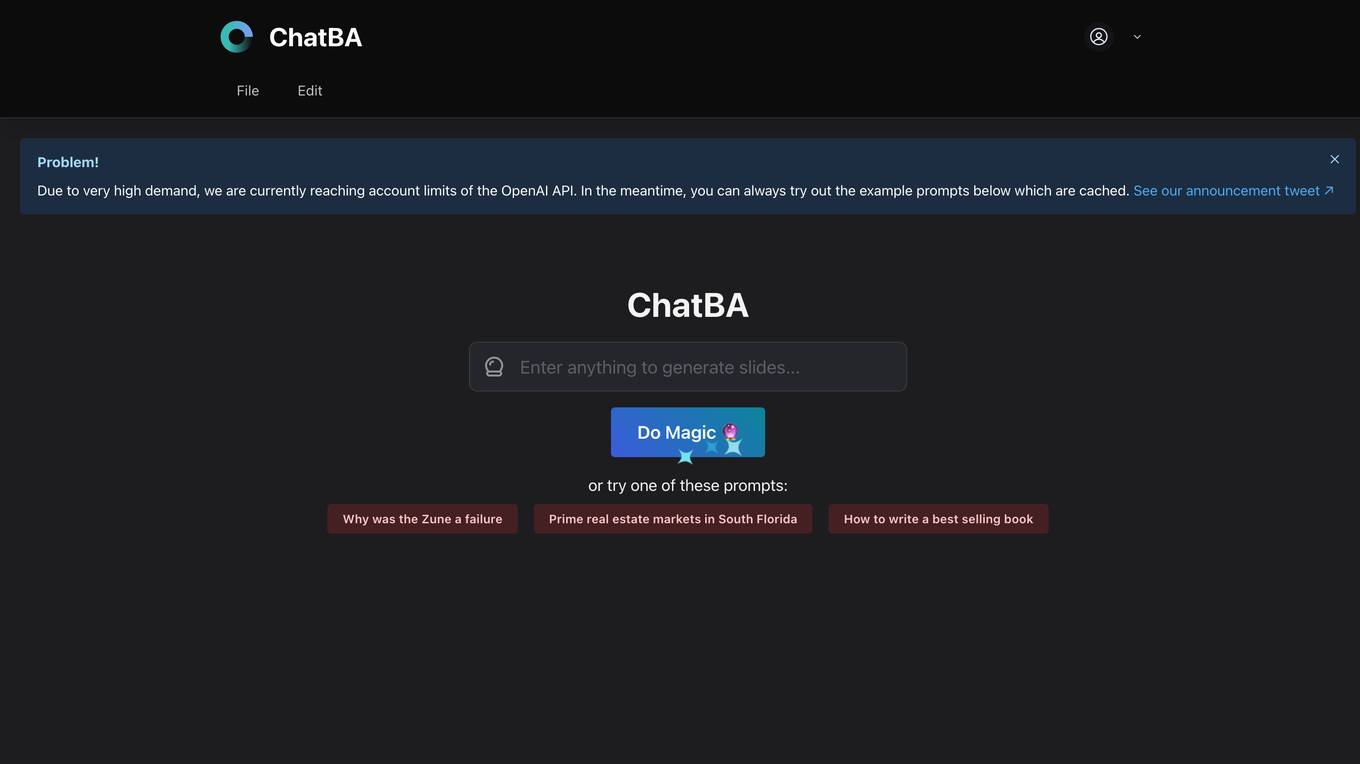
ChatBA
ChatBA is a generative AI tool designed for creating presentation slides effortlessly. It utilizes advanced AI technology to assist users in generating content for their slides by providing example prompts and suggestions. Due to high demand, the tool is currently reaching account limits of the OpenAI API, but users can still explore cached prompts. ChatBA aims to streamline the process of slide creation by offering a user-friendly interface and AI-powered assistance.
1 - Open Source AI Tools
edgen
Edgen is a local GenAI API server that serves as a drop-in replacement for OpenAI's API. It provides multi-endpoint support for chat completions and speech-to-text, is model agnostic, offers optimized inference, and features model caching. Built in Rust, Edgen is natively compiled for Windows, MacOS, and Linux, eliminating the need for Docker. It allows users to utilize GenAI locally on their devices for free and with data privacy. With features like session caching, GPU support, and support for various endpoints, Edgen offers a scalable, reliable, and cost-effective solution for running GenAI applications locally.
2 - OpenAI Gpts

TYPO3 GPT
Specialist for technical and editorial TYPO3 support. // FEATURES: Optional browsing via external api with 'web: search query' and optimized GitHub access.