
data-juicer
Data processing for and with foundation models! 🍎 🍋 🌽 ➡️ ➡️🍸 🍹 🍷
Stars: 5209

Data-Juicer is a one-stop data processing system to make data higher-quality, juicier, and more digestible for LLMs. It is a systematic & reusable library of 80+ core OPs, 20+ reusable config recipes, and 20+ feature-rich dedicated toolkits, designed to function independently of specific LLM datasets and processing pipelines. Data-Juicer allows detailed data analyses with an automated report generation feature for a deeper understanding of your dataset. Coupled with multi-dimension automatic evaluation capabilities, it supports a timely feedback loop at multiple stages in the LLM development process. Data-Juicer offers tens of pre-built data processing recipes for pre-training, fine-tuning, en, zh, and more scenarios. It provides a speedy data processing pipeline requiring less memory and CPU usage, optimized for maximum productivity. Data-Juicer is flexible & extensible, accommodating most types of data formats and allowing flexible combinations of OPs. It is designed for simplicity, with comprehensive documentation, easy start guides and demo configs, and intuitive configuration with simple adding/removing OPs from existing configs.
README:
[中文主页] | [DJ-Cookbook] | [OperatorZoo] | [API] | [Awesome LLM Data]




Data-Juicer is a one-stop system to process text and multimodal data for and with foundation models (typically LLMs). We provide a playground with a managed JupyterLab. Try Data-Juicer straight away in your browser! If you find Data-Juicer useful for your research or development, please kindly support us by starting it (then be instantly notified of our new releases) and citing our works.
Platform for AI of Alibaba Cloud (PAI) has deeply integrated Data-Juicer into its data processing products. PAI is an AI Native large model and AIGC engineering platform that provides dataset management, computing power management, model tool chain, model development, model training, model deployment, and AI asset management. For documentation on data processing, please refer to: PAI-Data Processing for Large Models.
Data-Juicer is being actively updated and maintained. We will periodically enhance and add more features, data recipes and datasets. We welcome you to join us, in promoting data-model co-development along with research and applications of foundation models!
[Demo Video] DataJuicer-Agent: Quick start your data processing journey!
https://github.com/user-attachments/assets/6eb726b7-6054-4b0c-905e-506b2b9c7927
[Demo Video] DataJuicer-Sandbox: Better data-model co-dev at a lower cost!
https://github.com/user-attachments/assets/a45f0eee-0f0e-4ffe-9a42-d9a55370089d
- 🎉 [2025-09-19] Our work of Data-Juicer 2.0: Cloud-Scale Adaptive Data Processing for and with Foundation Models has been accepted as a NeurIPS'25 Spotlight (top 3.1% of all submissions)!
- 🎉 [2025-09-19] Our two works regarding data mixture/selection/synthesis: Diversity as a Reward: Fine-Tuning LLMs on a Mixture of Domain-Undetermined Data and MindGYM: What Matters in Question Synthesis for Thinking-Centric Fine-Tuning? have been accepted by NeurIPS'25!
- 🛠️ [2025-06-04] How to process feedback data in the "era of experience"? We propose Trinity-RFT: A General-Purpose and Unified Framework for Reinforcement Fine-Tuning of LLMs, which leverages Data-Juicer for its data pipelines tailored for RFT scenarios.
- 🎉 [2025-06-04] Our Data-Model Co-development Survey has been accepted by IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)! Welcome to explore and contribute the awesome-list.
- 🔎 [2025-06-04] We introduce DetailMaster: Can Your Text-to-Image Model Handle Long Prompts? A synthetic benchmark revealing notable performance drops despite large models' proficiency with short descriptions.
- 🎉 [2025-05-06] Our work of Data-Juicer Sandbox has been accepted as a ICML'25 Spotlight (top 2.6% of all submissions)!
- 💡 [2025-03-13] We propose MindGYM: What Matters in Question Synthesis for Thinking-Centric Fine-Tuning? A new data synthesis method that enables large models to self-synthesize high-quality, low-variance data for efficient fine-tuning, (e.g., 16% gain on MathVision using only 400 samples).
- 🤝 [2025-02-28] DJ has been integrated in Ray's official Ecosystem and Example Gallery. Besides, our patch in DJ2.0 for the streaming JSON reader has been officially integrated by Apache Arrow.
- 🎉 [2025-02-27] Our work on contrastive data synthesis, ImgDiff, has been accepted by CVPR'25!
- 💡 [2025-02-05] We propose a new data selection method, Diversity as a Reward: Fine-Tuning LLMs on a Mixture of Domain-Undetermined Data. It is theoretically informed, via treating diversity as a reward, achieves better overall performance across 7 benchmarks when post-training SOTA LLMs.
- 🎉 [2025-01-11] We release our 2.0 paper, Data-Juicer 2.0: Cloud-Scale Adaptive Data Processing for and with Foundation Models. It now can process 70B data samples within 2.1h, using 6400 CPU cores on 50 Ray nodes from Alibaba Cloud cluster, and deduplicate 5TB data within 2.8h using 1280 CPU cores on 8 Ray nodes.
History News:
>- [2025-01-03] We support post-tuning scenarios better, via 20+ related new OPs, and via unified dataset format compatible to LLaMA-Factory and ModelScope-Swift.
- [2024-12-17] We propose HumanVBench, which comprises 16 human-centric tasks with synthetic data, benchmarking 22 video-MLLMs' capabilities from views of inner emotion and outer manifestations. See more details in our paper, and try to evaluate your models with it.
- [2024-11-22] We release DJ v1.0.0, in which we refactored Data-Juicer's Operator, Dataset, Sandbox and many other modules for better usability, such as supporting fault-tolerant, FastAPI and adaptive resource management.
- [2024-08-25] We give a tutorial about data processing for multimodal LLMs in KDD'2024.
- [2024-08-09] We propose Img-Diff, which enhances the performance of multimodal large language models through contrastive data synthesis, achieving a score that is 12 points higher than GPT-4V on the MMVP benchmark. See more details in our paper, and download the dataset from huggingface and modelscope.
- [2024-07-24] "Tianchi Better Synth Data Synthesis Competition for Multimodal Large Models" — Our 4th data-centric LLM competition has kicked off! Please visit the competition's official website for more information.
- [2024-07-17] We utilized the Data-Juicer Sandbox Laboratory Suite to systematically optimize data and models through a co-development workflow between data and models, achieving a new top spot on the VBench text-to-video leaderboard. The related achievements have been compiled and published in a paper, and the model has been released on the ModelScope and HuggingFace platforms.
- [2024-07-12] Our awesome list of MLLM-Data has evolved into a systemic survey from model-data co-development perspective. Welcome to explore and contribute!
- [2024-06-01] ModelScope-Sora "Data Directors" creative sprint—Our third data-centric LLM competition has kicked off! Please visit the competition's official website for more information.
- [2024-03-07] We release Data-Juicer v0.2.0 now! In this new version, we support more features for multimodal data (including video now), and introduce DJ-SORA to provide open large-scale, high-quality datasets for SORA-like models.
- [2024-02-20] We have actively maintained an awesome list of LLM-Data, welcome to visit and contribute!
- [2024-02-05] Our paper has been accepted by SIGMOD'24 industrial track!
- [2024-01-10] Discover new horizons in "Data Mixture"—Our second data-centric LLM competition has kicked off! Please visit the competition's official website for more information.
- [2024-01-05] We release Data-Juicer v0.1.3 now! In this new version, we support more Python versions (3.8-3.10), and support multimodal dataset converting/processing (Including texts, images, and audios. More modalities will be supported in the future). Besides, our paper is also updated to v3.
- [2023-10-13] Our first data-centric LLM competition begins! Please visit the competition's official websites, FT-Data Ranker (1B Track, 7B Track), for more information.
-
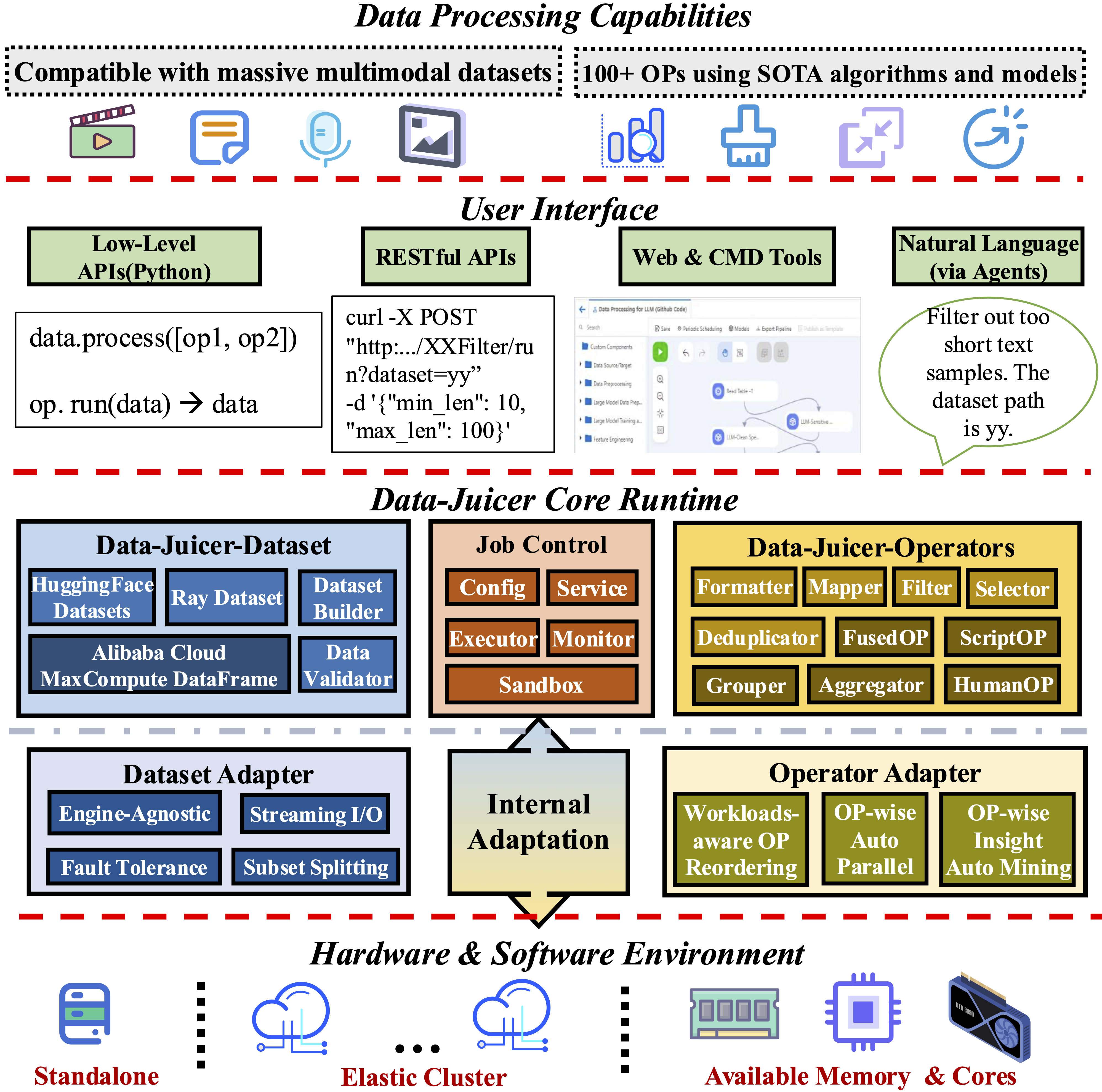
Systematic & Reusable: Empowering users with a systematic library of 100+ core OPs, and 50+ reusable config recipes and dedicated toolkits, designed to function independently of specific multimodal LLM datasets and processing pipelines. Supporting data analysis, cleaning, and synthesis in pre-training, post-tuning, en, zh, and more scenarios.
-
User-Friendly & Extensible: Designed for simplicity and flexibility, with easy-start guides, and DJ-Cookbook containing fruitful demo usages. Feel free to implement your own OPs for customizable data processing.
Data-Juicer now uses AI to automatically rewrite and optimize operator docstrings, generating detailed operator documentation to help users quickly understand the functionality and usage of each operator.
For details about the implementation of this documentation enhancement workflow, please visit the demos/op_doc_enhance_workflow folder under thedj_agentsbranch. -
Efficient & Robust: Providing performance-optimized parallel data processing (Aliyun-PAI\Ray\CUDA\OP Fusion), faster with less resource usage, verified in large-scale production environments.
-
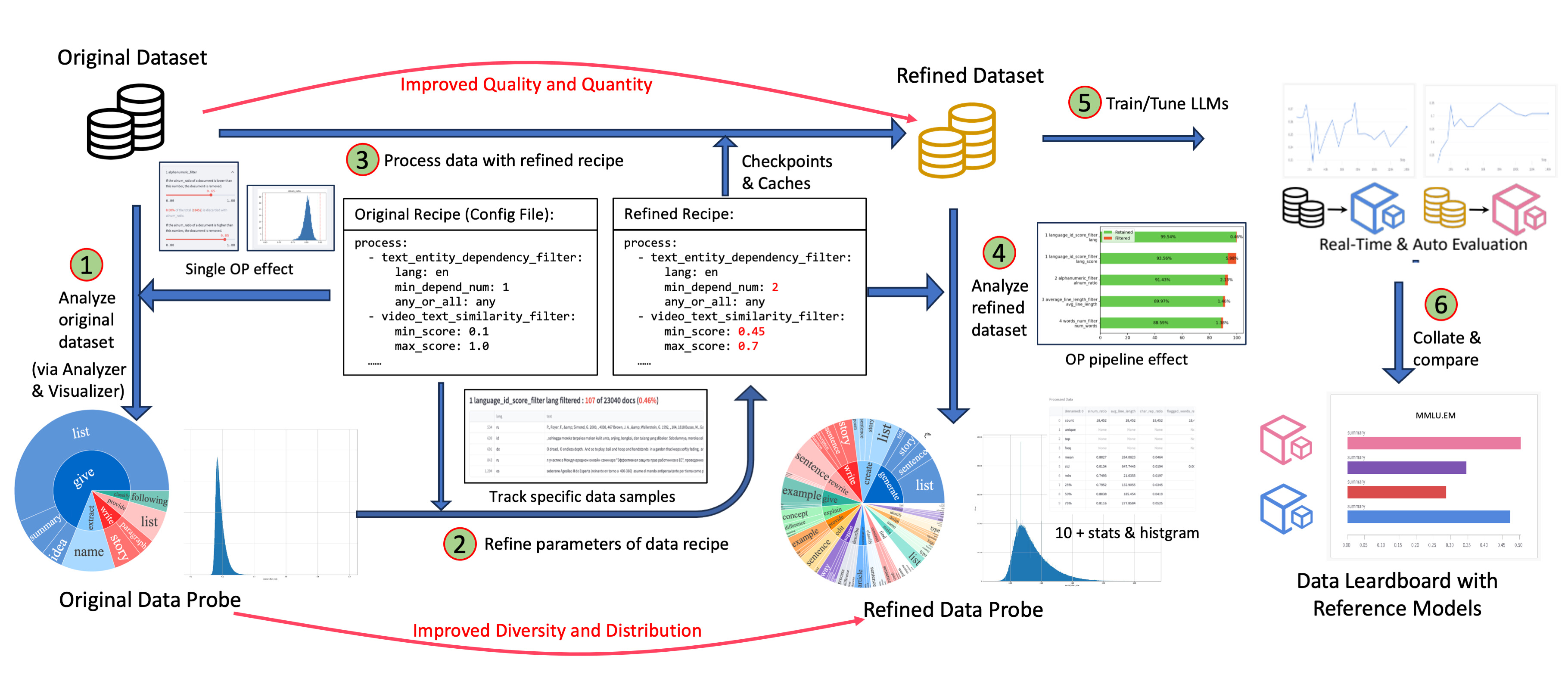
Effect-Proven & Sandbox: Supporting data-model co-development, enabling rapid iteration through the sandbox laboratory, and providing features such as feedback loops and visualization, so that you can better understand and improve your data and models. Many effect-proven datasets and models have been derived from DJ, in scenarios such as pre-training, text-to-video and image-to-text generation.
- Tutorial
- Useful documents
- Demos
- Tools
- Third-party
Data-Juicer is released under Apache License 2.0.
Data-Juicer has benefited greatly from and continues to welcome contributions at all levels: new operators (from simple functions to advanced algorithms based on existing papers), data-recipes & processing scenarios, feature requests, efficiency enhancements, bug fixes, better documentation and usage feedback. Please refer to our Developer Guide to get started. Spreading the word in the community and giving the repository a star ⭐ are also invaluable forms of support!
Our sincere gratitude goes to all our code contributors who are the cornerstone of this project. We strive to keep the list below updated and look forward to including more names (alphabetical order); please reach out if we have missed any acknowledgements.
- Initiated by: Alibaba Tongyi Lab
- Co-developed and Optimized with: Alibaba Cloud PAI, Anyscale (Ray Team), Sun Yat-sen University (Knowledge Engineering Lab), NVIDIA (NeMo Team), ...
- Used by & Valuable Feedback from: AgentScope, Alibaba Group, Ant Group, BYD Auto, Bytedance, CAS, DiffSynth-Studio, EasyAnimate, Eval-Scope, JD.com, LLaMA-Factory, Nanjing University, OPPO, Peking University, RM-Gallery, RUC, Tsinghua University, Trinity-RFT, UCAS, Xiaohongshu, Xiaomi, Ximalaya, Zhejiang University, ...
- Inspired by: Data-Juicer also thanks pioneering open-source projects such as Apache Arrow, BLOOM, RedPajama-Data, Ray, Hugging Face Datasets, ...
We look forward to your feedback and collaboration, including partnership inquiries or proposals for new sub-projects related to Data-Juicer. Feel free to contact via issues, PRs, Slack channel, DingDing group, and e-mails.
If you find Data-Juicer useful for your research or development, please kindly cite the following works, 1.0paper, 2.0paper.
@inproceedings{djv1,
title={Data-Juicer: A One-Stop Data Processing System for Large Language Models},
author={Daoyuan Chen and Yilun Huang and Zhijian Ma and Hesen Chen and Xuchen Pan and Ce Ge and Dawei Gao and Yuexiang Xie and Zhaoyang Liu and Jinyang Gao and Yaliang Li and Bolin Ding and Jingren Zhou},
booktitle={International Conference on Management of Data},
year={2024}
}
@article{djv2,
title={Data-Juicer 2.0: Cloud-Scale Adaptive Data Processing for and with Foundation Models},
author={Chen, Daoyuan and Huang, Yilun and Pan, Xuchen and Jiang, Nana and Wang, Haibin and Zhang, Yilei and Ge, Ce and Chen, Yushuo and Zhang, Wenhao and Ma, Zhijian and Huang, Jun and Lin, Wei and Li, Yaliang and Ding, Bolin and Zhou, Jingren},
journal={Advances in Neural Information Processing Systems},
year={2025}
}
More data-related papers from the Data-Juicer Team:
>-
(ICML'25 Spotlight) Data-Juicer Sandbox: A Feedback-Driven Suite for Multimodal Data-Model Co-development
-
(CVPR'25) ImgDiff: Contrastive Data Synthesis for Vision Large Language Models
-
(NeurIPS'25) Diversity as a Reward: Fine-Tuning LLMs on a Mixture of Domain-Undetermined Data
-
(NeurIPS'25) MindGYM: What Matters in Question Synthesis for Thinking-Centric Fine-Tuning?
-
(Benchmark Data) HumanVBench: Exploring Human-Centric Video Understanding Capabilities of MLLMs with Synthetic Benchmark Data
-
(Benchmark Data) DetailMaster: Can Your Text-to-Image Model Handle Long Prompts?
-
(Data Scaling) BiMix: A Bivariate Data Mixing Law for Language Model Pretraining
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for data-juicer
Similar Open Source Tools
data-juicer
Data-Juicer is a one-stop data processing system to make data higher-quality, juicier, and more digestible for LLMs. It is a systematic & reusable library of 80+ core OPs, 20+ reusable config recipes, and 20+ feature-rich dedicated toolkits, designed to function independently of specific LLM datasets and processing pipelines. Data-Juicer allows detailed data analyses with an automated report generation feature for a deeper understanding of your dataset. Coupled with multi-dimension automatic evaluation capabilities, it supports a timely feedback loop at multiple stages in the LLM development process. Data-Juicer offers tens of pre-built data processing recipes for pre-training, fine-tuning, en, zh, and more scenarios. It provides a speedy data processing pipeline requiring less memory and CPU usage, optimized for maximum productivity. Data-Juicer is flexible & extensible, accommodating most types of data formats and allowing flexible combinations of OPs. It is designed for simplicity, with comprehensive documentation, easy start guides and demo configs, and intuitive configuration with simple adding/removing OPs from existing configs.

upgini
Upgini is an intelligent data search engine with a Python library that helps users find and add relevant features to their ML pipeline from various public, community, and premium external data sources. It automates the optimization of connected data sources by generating an optimal set of machine learning features using large language models, GraphNNs, and recurrent neural networks. The tool aims to simplify feature search and enrichment for external data to make it a standard approach in machine learning pipelines. It democratizes access to data sources for the data science community.
edge-ai-libraries
The Edge AI Libraries project is a collection of libraries, microservices, and tools for Edge application development. It includes sample applications showcasing generic AI use cases. Key components include Anomalib, Dataset Management Framework, Deep Learning Streamer, ECAT EnableKit, EtherCAT Masterstack, FLANN, OpenVINO toolkit, Audio Analyzer, ORB Extractor, PCL, PLCopen Servo, Real-time Data Agent, RTmotion, Audio Intelligence, Deep Learning Streamer Pipeline Server, Document Ingestion, Model Registry, Multimodal Embedding Serving, Time Series Analytics, Vector Retriever, Visual-Data Preparation, VLM Inference Serving, Intel Geti, Intel SceneScape, Visual Pipeline and Platform Evaluation Tool, Chat Question and Answer, Document Summarization, PLCopen Benchmark, PLCopen Databus, Video Search and Summarization, Isolation Forest Classifier, Random Forest Microservices. Visit sub-directories for instructions and guides.
xorq
Xorq (formerly LETSQL) is a data processing library built on top of Ibis and DataFusion to write multi-engine data workflows. It provides a flexible and powerful tool for processing and analyzing data from various sources, enabling users to create complex data pipelines and perform advanced data transformations.
arconia
Arconia is a powerful open-source tool for managing and visualizing data in a user-friendly way. It provides a seamless experience for data analysts and scientists to explore, clean, and analyze datasets efficiently. With its intuitive interface and robust features, Arconia simplifies the process of data manipulation and visualization, making it an essential tool for anyone working with data.

lemonai
LemonAI is a versatile machine learning library designed to simplify the process of building and deploying AI models. It provides a wide range of tools and algorithms for data preprocessing, model training, and evaluation. With LemonAI, users can easily experiment with different machine learning techniques and optimize their models for various tasks. The library is well-documented and beginner-friendly, making it suitable for both novice and experienced data scientists. LemonAI aims to streamline the development of AI applications and empower users to create innovative solutions using state-of-the-art machine learning methods.

AI_Spectrum
AI_Spectrum is a versatile machine learning library that provides a wide range of tools and algorithms for building and deploying AI models. It offers a user-friendly interface for data preprocessing, model training, and evaluation. With AI_Spectrum, users can easily experiment with different machine learning techniques and optimize their models for various tasks. The library is designed to be flexible and scalable, making it suitable for both beginners and experienced data scientists.
HyperAgent
HyperAgent is a powerful tool for automating repetitive tasks in web scraping and data extraction. It provides a user-friendly interface to create custom web scraping scripts without the need for extensive coding knowledge. With HyperAgent, users can easily extract data from websites, transform it into structured formats, and save it for further analysis. The tool supports various data formats and offers scheduling options for automated data extraction at regular intervals. HyperAgent is suitable for individuals and businesses looking to streamline their data collection processes and improve efficiency in extracting information from the web.

pdr_ai_v2
pdr_ai_v2 is a Python library for implementing machine learning algorithms and models. It provides a wide range of tools and functionalities for data preprocessing, model training, evaluation, and deployment. The library is designed to be user-friendly and efficient, making it suitable for both beginners and experienced data scientists. With pdr_ai_v2, users can easily build and deploy machine learning models for various applications, such as classification, regression, clustering, and more.

unstructured
The `unstructured` library provides open-source components for ingesting and pre-processing images and text documents, such as PDFs, HTML, Word docs, and many more. The use cases of `unstructured` revolve around streamlining and optimizing the data processing workflow for LLMs. `unstructured` modular functions and connectors form a cohesive system that simplifies data ingestion and pre-processing, making it adaptable to different platforms and efficient in transforming unstructured data into structured outputs.

datatune
Datatune is a data analysis tool designed to help users explore and analyze datasets efficiently. It provides a user-friendly interface for importing, cleaning, visualizing, and modeling data. With Datatune, users can easily perform tasks such as data preprocessing, feature engineering, model selection, and evaluation. The tool offers a variety of statistical and machine learning algorithms to support data analysis tasks. Whether you are a data scientist, analyst, or researcher, Datatune can streamline your data analysis workflow and help you derive valuable insights from your data.
oci-data-science-ai-samples
The Oracle Cloud Infrastructure Data Science and AI services Examples repository provides demos, tutorials, and code examples showcasing various features of the OCI Data Science service and AI services. It offers tools for data scientists to develop and deploy machine learning models efficiently, with features like Accelerated Data Science SDK, distributed training, batch processing, and machine learning pipelines. Whether you're a beginner or an experienced practitioner, OCI Data Science Services provide the resources needed to build, train, and deploy models easily.
agent-pod
Agent POD is a project focused on capturing and storing personal digital data in a user-controlled environment, with the goal of enabling agents to interact with the data. It explores questions related to structuring information, creating an efficient data capture system, integrating with protocols like SOLID, and enabling data storage for groups. The project aims to transition from traditional data-storing apps to a system where personal data is owned and controlled by the user, facilitating the creation of 'solid-first' apps.

ROGRAG
ROGRAG is a powerful open-source tool designed for data analysis and visualization. It provides a user-friendly interface for exploring and manipulating datasets, making it ideal for researchers, data scientists, and analysts. With ROGRAG, users can easily import, clean, analyze, and visualize data to gain valuable insights and make informed decisions. The tool supports a wide range of data formats and offers a variety of statistical and visualization tools to help users uncover patterns, trends, and relationships in their data. Whether you are working on exploratory data analysis, statistical modeling, or data visualization, ROGRAG is a versatile tool that can streamline your workflow and enhance your data analysis capabilities.
PerforatedAI
PerforatedAI is a machine learning tool designed to automate the process of analyzing and extracting information from perforated documents. It uses advanced OCR technology to accurately identify and extract data from documents with perforations, such as surveys, questionnaires, and forms. The tool can handle various types of perforations and is capable of processing large volumes of documents quickly and efficiently. PerforatedAI streamlines the data extraction process, saving time and reducing errors associated with manual data entry. It is a valuable tool for businesses and organizations that deal with large amounts of perforated documents on a regular basis.

cellm
Cellm is an Excel extension that allows users to leverage Large Language Models (LLMs) like ChatGPT within cell formulas. It enables users to extract AI responses to text ranges, making it useful for automating repetitive tasks that involve data processing and analysis. Cellm supports various models from Anthropic, Mistral, OpenAI, and Google, as well as locally hosted models via Llamafiles, Ollama, or vLLM. The tool is designed to simplify the integration of AI capabilities into Excel for tasks such as text classification, data cleaning, content summarization, entity extraction, and more.
For similar tasks

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

sorrentum
Sorrentum is an open-source project that aims to combine open-source development, startups, and brilliant students to build machine learning, AI, and Web3 / DeFi protocols geared towards finance and economics. The project provides opportunities for internships, research assistantships, and development grants, as well as the chance to work on cutting-edge problems, learn about startups, write academic papers, and get internships and full-time positions at companies working on Sorrentum applications.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

zep-python
Zep is an open-source platform for building and deploying large language model (LLM) applications. It provides a suite of tools and services that make it easy to integrate LLMs into your applications, including chat history memory, embedding, vector search, and data enrichment. Zep is designed to be scalable, reliable, and easy to use, making it a great choice for developers who want to build LLM-powered applications quickly and easily.

telemetry-airflow
This repository codifies the Airflow cluster that is deployed at workflow.telemetry.mozilla.org (behind SSO) and commonly referred to as "WTMO" or simply "Airflow". Some links relevant to users and developers of WTMO: * The `dags` directory in this repository contains some custom DAG definitions * Many of the DAGs registered with WTMO don't live in this repository, but are instead generated from ETL task definitions in bigquery-etl * The Data SRE team maintains a WTMO Developer Guide (behind SSO)

mojo
Mojo is a new programming language that bridges the gap between research and production by combining Python syntax and ecosystem with systems programming and metaprogramming features. Mojo is still young, but it is designed to become a superset of Python over time.

pandas-ai
PandasAI is a Python library that makes it easy to ask questions to your data in natural language. It helps you to explore, clean, and analyze your data using generative AI.

databend
Databend is an open-source cloud data warehouse that serves as a cost-effective alternative to Snowflake. With its focus on fast query execution and data ingestion, it's designed for complex analysis of the world's largest datasets.
For similar jobs

lollms-webui
LoLLMs WebUI (Lord of Large Language Multimodal Systems: One tool to rule them all) is a user-friendly interface to access and utilize various LLM (Large Language Models) and other AI models for a wide range of tasks. With over 500 AI expert conditionings across diverse domains and more than 2500 fine tuned models over multiple domains, LoLLMs WebUI provides an immediate resource for any problem, from car repair to coding assistance, legal matters, medical diagnosis, entertainment, and more. The easy-to-use UI with light and dark mode options, integration with GitHub repository, support for different personalities, and features like thumb up/down rating, copy, edit, and remove messages, local database storage, search, export, and delete multiple discussions, make LoLLMs WebUI a powerful and versatile tool.
Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

minio
MinIO is a High Performance Object Storage released under GNU Affero General Public License v3.0. It is API compatible with Amazon S3 cloud storage service. Use MinIO to build high performance infrastructure for machine learning, analytics and application data workloads.

mage-ai
Mage is an open-source data pipeline tool for transforming and integrating data. It offers an easy developer experience, engineering best practices built-in, and data as a first-class citizen. Mage makes it easy to build, preview, and launch data pipelines, and provides observability and scaling capabilities. It supports data integrations, streaming pipelines, and dbt integration.

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.
tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

airbyte
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.