
sec-parser
Parse SEC EDGAR HTML documents into a tree of elements that correspond to the visual (semantic) structure of the document.
Stars: 99
The `sec-parser` project simplifies extracting meaningful information from SEC EDGAR HTML documents by organizing them into semantic elements and a tree structure. It helps in parsing SEC filings for financial and regulatory analysis, analytics and data science, AI and machine learning, causal AI, and large language models. The tool is especially beneficial for AI, ML, and LLM applications by streamlining data pre-processing and feature extraction.
README:
Essentials ➔

Health ➔



Quality ➔

Distribution ➔


Community ➔



The sec-parser project simplifies extracting meaningful information from SEC EDGAR HTML documents by organizing them into semantic elements and a tree structure. Semantic elements might include section titles, paragraphs, and tables, each classified for easier data manipulation. This forms a semantic tree that corresponds to the visual and informational structure of the document. If you're familiar with the Image Semantic Segmentation concept, it's the same but applied to HTML documents.
This tool is especially beneficial for Artificial Intelligence (AI), Machine Learning (ML), and Large Language Models (LLM) applications by streamlining data pre-processing and feature extraction.
- Explore the Demo
- Read the Documentation
- Join the Discussions to get help, propose ideas, or chat with the community
- Become part of our Discord community
- Report bugs in Issues
- Stay updated and contribute to our project's direction in Announcements and Roadmap
- Learn How to Contribute
sec-parser is versatile and can be applied in various scenarios, including but not limited to:
- Financial Analysis: Extract financial data from 10-Q and 10-K filings for quantitative modeling.
- Risk Assessment: Evaluate risk factors or Management's Discussion and Analysis sections for qualitative analysis.
- Regulatory Compliance: Assist in automating compliance checks for the legal teams.
- Flexible Filtering: Easily filter SEC documents by sections and types, giving you precisely the data you need.
- Academic Research: Facilitate large-scale studies involving public financial disclosures, sentiment analysis, or corporate governance exploratory.
- Analytics Ready: Integrate parsed data seamlessly into popular analytics tools for further analysis and visualization.
- Cutting-Edge AI for SEC EDGAR: Apply advanced AI techniques like MemWalker to navigate and extract and transform complex information from SEC documents efficiently. Learn more in our blog post: Cutting-Edge AI for SEC EDGAR: Introducing MemWalker.
- AI Applications: Leverage parsed data for various AI tasks such as text summarization, sentiment analysis, and named entity recognition.
- Data Augmentation: Use authentic financial text to train and test machine learning models.
- Causal Analysis: Use parsed data to understand cause-effect relationships in financial data, beyond mere correlations.
- Predictive Modeling: Enhance predictive models by incorporating causal relationships, leading to more robust and reliable predictions.
- Decision Making: Aid decision-making processes by providing insights into the potential impact of different actions, based on causal relationships identified in the data.
- LLM Compatible: Use parsed data to facilitate complex NLU tasks with Large Language Models like ChatGPT, including question-answering, language translation, and information retrieval.
These use-cases demonstrate the flexibility and power of sec-parser in handling both traditional data extraction tasks and facilitating more advanced AI-driven analysis.
[!IMPORTANT] This project,
sec-parser, is an independent, open-source initiative and has no affiliation, endorsement, or verification by the United States Securities and Exchange Commission (SEC). It utilizes public APIs and data provided by the SEC solely for research, informational, and educational objectives. This tool is not intended for financial advisement or as a substitute for professional investment advice or compliance with securities regulations. The creators and maintainers make no warranties, expressed or implied, about the accuracy, completeness, or reliability of the data and analyses presented. Use this software at your own risk. For accurate and comprehensive financial analysis, consult with qualified financial professionals and comply with all relevant legal requirements. The project maintainers and contributors are not liable for any financial or legal consequences arising from the use of this tool.
This guide will walk you through the process of installing the sec-parser package and using it to extract the "Segment Operating Performance" section as a semantic tree from the latest Apple 10-Q filing.
[!TIP] To run the example code in a ready-to-code environment, you can use GitHub Codespaces. Click the button below to open the example code below in a codespace and start experimenting with
sec-parser:
![]()
First, install the sec-parser package using pip:
pip install sec-parserTo run the example code in this README, you'll also need the sec_downloader package:
pip install sec-downloaderOnce you've installed the necessary packages, you can start by downloading the filing from the SEC EDGAR website. Here's how you can do it:
from sec_downloader import Downloader
# Initialize the downloader with your company name and email
dl = Downloader("MyCompanyName", "[email protected]")
# Download the latest 10-Q filing for Apple
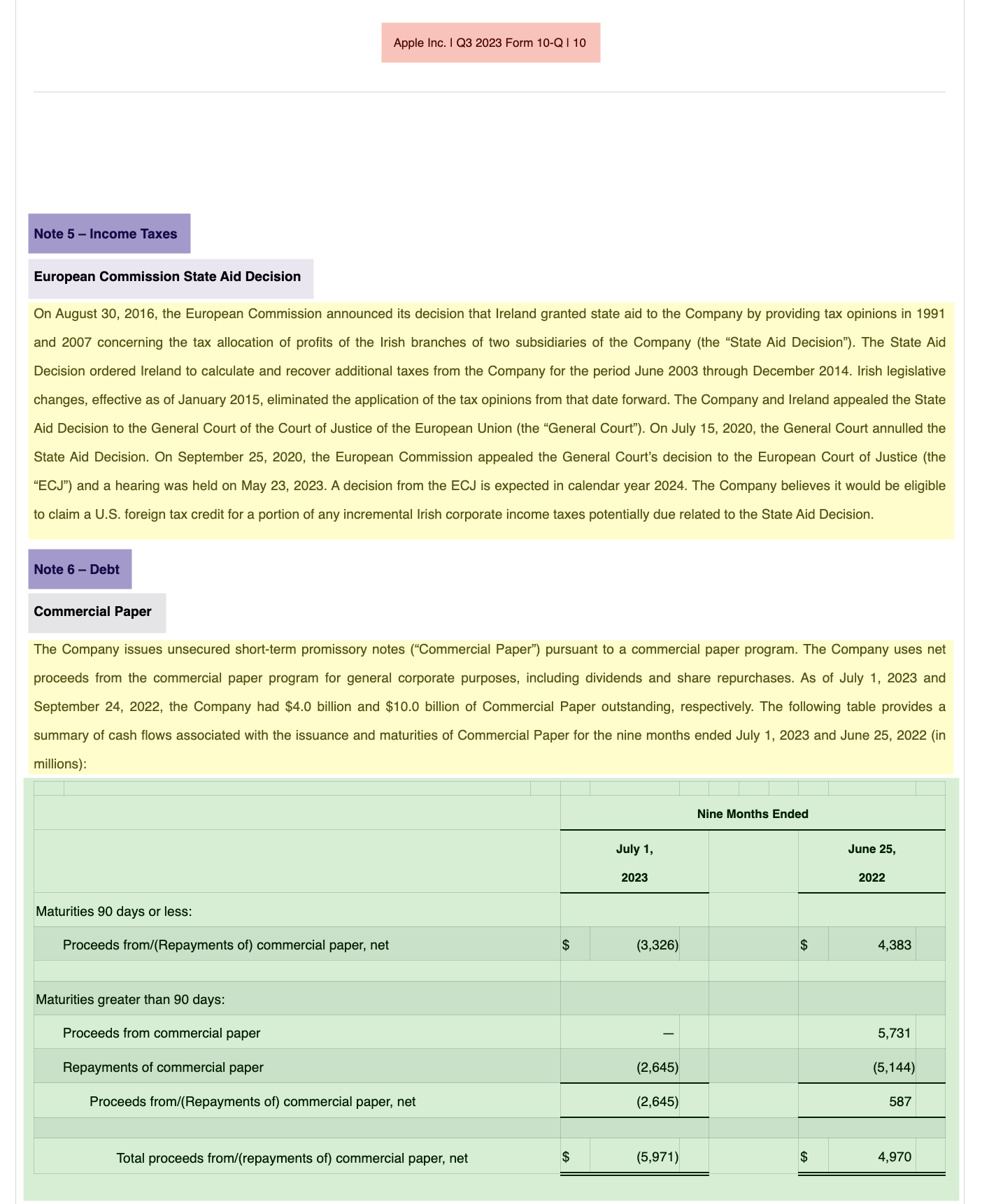
html = dl.get_filing_html(ticker="AAPL", form="10-Q")[!NOTE] The company name and email address are used to form a user-agent string that adheres to the SEC EDGAR's fair access policy for programmatic downloading. Source
[!TIP] Read sec-downloader documentation (and examples) for more advanced usage (such as downloading three latest Apple 10-Q filings instead of just one, or downloading based on a specific CIK or Filing ID (i.e. accession number)).
Now, we can parse the filing HTML into a list of semantic elements:
# Utility function to make the example code a bit more compact
def print_first_n_lines(text: str, *, n: int):
print("\n".join(text.split("\n")[:n]), "...", sep="\n")import sec_parser as sp
elements: list = sp.Edgar10QParser().parse(html)
demo_output: str = sp.render(elements)
print_first_n_lines(demo_output, n=7)TopSectionTitle: PART I — FINANCIAL INFORMATION TopSectionTitle: Item 1. Financial Statements TitleElement: CONDENSED CONSOLIDATED STATEMENTS OF OPERATIONS (Unaudited) SupplementaryText: (In millions, except number of ...housands and per share amounts) TableElement: Table with 24 rows, 80 numbers, and 1058 characters. SupplementaryText: See accompanying Notes to Conde...solidated Financial Statements. TitleElement: CONDENSED CONSOLIDATED STATEMEN...OMPREHENSIVE INCOME (Unaudited) ...
[!TIP]
FAQ: How do I get the text of each element (or all of the document)? How do I get all of the text in a specific section?
Use the
element.textfield. Check out this notebook for a full example.
We can also construct a semantic tree to allow for easy filtering by parent sections:
tree = sp.TreeBuilder().build(elements)
demo_output: str = sp.render(tree)
print_first_n_lines(demo_output, n=7)TopSectionTitle: PART I — FINANCIAL INFORMATION ├── TopSectionTitle: Item 1. Financial Statements │ ├── TitleElement: CONDENSED CONSOLIDATED STATEMENTS OF OPERATIONS (Unaudited) │ │ ├── SupplementaryText: (In millions, except number of ...housands and per share amounts) │ │ ├── TableElement: Table with 24 rows, 80 numbers, and 1058 characters. │ │ ├── SupplementaryText: See accompanying Notes to Conde...solidated Financial Statements. │ ├── TitleElement: CONDENSED CONSOLIDATED STATEMEN...OMPREHENSIVE INCOME (Unaudited) ...
[!TIP]
Feel free to experiment with the example code provided above. You can easily do this by launching a GitHub Codespace for the
sec-parserrepository, which will set up a development environment for you in the cloud:
This is a great way to play around with the code without having to set up anything on your local machine. Give it a try!
For more examples and advanced usage, you can continue learning how to use sec-parser by referring to the User Guide, Developer Guide, and Documentation.
This was an example of 10-Q SEC Form parsing. How do we parse other SEC Form types, such as 10-K, 8-K, S-1, etc.?
Please refer to this document.
Your turn to explore the capabilities of sec-parser! With the tools and examples provided, you can now dive into parsing and analyzing SEC filings.
The semantic elements and tree structures created by the parser will serve as a solid foundation for your financial analysis and research tasks with the tools of your choice.
For a tailored experience, consider using our free and open-source library for AI-powered financial analysis:
pip install sec-aiTo ensure your code remains functional even when we change the internal structure of sec-parser, it's recommended to avoid deep imports. Here is an example of a deep import (not recommended):
[!CAUTION]
from sec_parser.semantic_tree.internal_utils.core import SomeInternalClass
Instead, use the suggested ways to import modules from sec-parser:
-
import sec_parser as sp. This imports the main package assp. You can then access its functionalities usingsp.prefix.
-
from sec_parser import SomeClass: This allows you to directly useSomeClasswithout any prefix.
-
import sec_parser.semantic_tree: This imports thesemantic_treesubmodule, and you can access its classes and functions usingsemantic_tree.prefix.
-
from sec_parser.semantic_tree import SomeClass: This imports a specific classSomeClassfrom thesemantic_treesubmodule.
[!NOTE] The main package
sec_parsercontains only the most common functionalities. For specialized tasks, please use submodule or submodule-level imports.
For information about setting up the development environment, coding standards, and contribution workflows, please refer to our CONTRIBUTING.md guide.
This project is licensed under the MIT License - see the LICENSE file for details.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for sec-parser
Similar Open Source Tools
sec-parser
The `sec-parser` project simplifies extracting meaningful information from SEC EDGAR HTML documents by organizing them into semantic elements and a tree structure. It helps in parsing SEC filings for financial and regulatory analysis, analytics and data science, AI and machine learning, causal AI, and large language models. The tool is especially beneficial for AI, ML, and LLM applications by streamlining data pre-processing and feature extraction.

RainbowGPT
RainbowGPT is a versatile tool that offers a range of functionalities, including Stock Analysis for financial decision-making, MySQL Management for database navigation, and integration of AI technologies like GPT-4 and ChatGlm3. It provides a user-friendly interface suitable for all skill levels, ensuring seamless information flow and continuous expansion of emerging technologies. The tool enhances adaptability, creativity, and insight, making it a valuable asset for various projects and tasks.

Biomni
Biomni is a general-purpose biomedical AI agent designed to autonomously execute a wide range of research tasks across diverse biomedical subfields. By integrating cutting-edge large language model (LLM) reasoning with retrieval-augmented planning and code-based execution, Biomni helps scientists dramatically enhance research productivity and generate testable hypotheses.

deep-research
Deep Research is a lightning-fast tool that uses powerful AI models to generate comprehensive research reports in just a few minutes. It leverages advanced 'Thinking' and 'Task' models, combined with an internet connection, to provide fast and insightful analysis on various topics. The tool ensures privacy by processing and storing all data locally. It supports multi-platform deployment, offers support for various large language models, web search functionality, knowledge graph generation, research history preservation, local and server API support, PWA technology, multi-key payload support, multi-language support, and is built with modern technologies like Next.js and Shadcn UI. Deep Research is open-source under the MIT License.

kollektiv
Kollektiv is a Retrieval-Augmented Generation (RAG) system designed to enable users to chat with their favorite documentation easily. It aims to provide LLMs with access to the most up-to-date knowledge, reducing inaccuracies and improving productivity. The system utilizes intelligent web crawling, advanced document processing, vector search, multi-query expansion, smart re-ranking, AI-powered responses, and dynamic system prompts. The technical stack includes Python/FastAPI for backend, Supabase, ChromaDB, and Redis for storage, OpenAI and Anthropic Claude 3.5 Sonnet for AI/ML, and Chainlit for UI. Kollektiv is licensed under a modified version of the Apache License 2.0, allowing free use for non-commercial purposes.

exospherehost
Exosphere is an open source infrastructure designed to run AI agents at scale for large data and long running flows. It allows developers to define plug and playable nodes that can be run on a reliable backbone in the form of a workflow, with features like dynamic state creation at runtime, infinite parallel agents, persistent state management, and failure handling. This enables the deployment of production agents that can scale beautifully to build robust autonomous AI workflows.

bigcodebench
BigCodeBench is an easy-to-use benchmark for code generation with practical and challenging programming tasks. It aims to evaluate the true programming capabilities of large language models (LLMs) in a more realistic setting. The benchmark is designed for HumanEval-like function-level code generation tasks, but with much more complex instructions and diverse function calls. BigCodeBench focuses on the evaluation of LLM4Code with diverse function calls and complex instructions, providing precise evaluation & ranking and pre-generated samples to accelerate code intelligence research. It inherits the design of the EvalPlus framework but differs in terms of execution environment and test evaluation.

sdialog
SDialog is an MIT-licensed open-source toolkit for building, simulating, and evaluating LLM-based conversational agents end-to-end. It aims to bridge agent construction, user simulation, dialog generation, and evaluation in a single reproducible workflow, enabling the generation of reliable, controllable dialog systems or data at scale. The toolkit standardizes a Dialog schema, offers persona-driven multi-agent simulation with LLMs, provides composable orchestration for precise control over behavior and flow, includes built-in evaluation metrics, and offers mechanistic interpretability. It allows for easy creation of user-defined components and interoperability across various AI platforms.

premsql
PremSQL is an open-source library designed to help developers create secure, fully local Text-to-SQL solutions using small language models. It provides essential tools for building and deploying end-to-end Text-to-SQL pipelines with customizable components, ideal for secure, autonomous AI-powered data analysis. The library offers features like Local-First approach, Customizable Datasets, Robust Executors and Evaluators, Advanced Generators, Error Handling and Self-Correction, Fine-Tuning Support, and End-to-End Pipelines. Users can fine-tune models, generate SQL queries from natural language inputs, handle errors, and evaluate model performance against predefined metrics. PremSQL is extendible for customization and private data usage.

giskard
Giskard is an open-source Python library that automatically detects performance, bias & security issues in AI applications. The library covers LLM-based applications such as RAG agents, all the way to traditional ML models for tabular data.

LLMBox
LLMBox is a comprehensive library designed for implementing Large Language Models (LLMs) with a focus on a unified training pipeline and comprehensive model evaluation. It serves as a one-stop solution for training and utilizing LLMs, offering flexibility and efficiency in both training and utilization stages. The library supports diverse training strategies, comprehensive datasets, tokenizer vocabulary merging, data construction strategies, parameter efficient fine-tuning, and efficient training methods. For utilization, LLMBox provides comprehensive evaluation on various datasets, in-context learning strategies, chain-of-thought evaluation, evaluation methods, prefix caching for faster inference, support for specific LLM models like vLLM and Flash Attention, and quantization options. The tool is suitable for researchers and developers working with LLMs for natural language processing tasks.

crawl4ai
Crawl4AI is a powerful and free web crawling service that extracts valuable data from websites and provides LLM-friendly output formats. It supports crawling multiple URLs simultaneously, replaces media tags with ALT, and is completely free to use and open-source. Users can integrate Crawl4AI into Python projects as a library or run it as a standalone local server. The tool allows users to crawl and extract data from specified URLs using different providers and models, with options to include raw HTML content, force fresh crawls, and extract meaningful text blocks. Configuration settings can be adjusted in the `crawler/config.py` file to customize providers, API keys, chunk processing, and word thresholds. Contributions to Crawl4AI are welcome from the open-source community to enhance its value for AI enthusiasts and developers.
distilabel
Distilabel is a framework for synthetic data and AI feedback for AI engineers that require high-quality outputs, full data ownership, and overall efficiency. It helps you synthesize data and provide AI feedback to improve the quality of your AI models. With Distilabel, you can: * **Synthesize data:** Generate synthetic data to train your AI models. This can help you to overcome the challenges of data scarcity and bias. * **Provide AI feedback:** Get feedback from AI models on your data. This can help you to identify errors and improve the quality of your data. * **Improve your AI output quality:** By using Distilabel to synthesize data and provide AI feedback, you can improve the quality of your AI models and get better results.
MetaGPT
MetaGPT is a multi-agent framework that enables GPT to work in a software company, collaborating to tackle more complex tasks. It assigns different roles to GPTs to form a collaborative entity for complex tasks. MetaGPT takes a one-line requirement as input and outputs user stories, competitive analysis, requirements, data structures, APIs, documents, etc. Internally, MetaGPT includes product managers, architects, project managers, and engineers. It provides the entire process of a software company along with carefully orchestrated SOPs. MetaGPT's core philosophy is "Code = SOP(Team)", materializing SOP and applying it to teams composed of LLMs.

swiftide
Swiftide is a fast, streaming indexing and query library tailored for Retrieval Augmented Generation (RAG) in AI applications. It is built in Rust, utilizing parallel, asynchronous streams for blazingly fast performance. With Swiftide, users can easily build AI applications from idea to production in just a few lines of code. The tool addresses frustrations around performance, stability, and ease of use encountered while working with Python-based tooling. It offers features like fast streaming indexing pipeline, experimental query pipeline, integrations with various platforms, loaders, transformers, chunkers, embedders, and more. Swiftide aims to provide a platform for data indexing and querying to advance the development of automated Large Language Model (LLM) applications.

Easy-Translate
Easy-Translate is a script designed for translating large text files with a single command. It supports various models like M2M100, NLLB200, SeamlessM4T, LLaMA, and Bloom. The tool is beginner-friendly and offers seamless and customizable features for advanced users. It allows acceleration on CPU, multi-CPU, GPU, multi-GPU, and TPU, with support for different precisions and decoding strategies. Easy-Translate also provides an evaluation script for translations. Built on HuggingFace's Transformers and Accelerate library, it supports prompt usage and loading huge models efficiently.
For similar tasks
sec-parser
The `sec-parser` project simplifies extracting meaningful information from SEC EDGAR HTML documents by organizing them into semantic elements and a tree structure. It helps in parsing SEC filings for financial and regulatory analysis, analytics and data science, AI and machine learning, causal AI, and large language models. The tool is especially beneficial for AI, ML, and LLM applications by streamlining data pre-processing and feature extraction.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.