
gpt4all
GPT4All: Run Local LLMs on Any Device. Open-source and available for commercial use.
Stars: 72866

GPT4All is an ecosystem to run powerful and customized large language models that work locally on consumer grade CPUs and any GPU. Note that your CPU needs to support AVX or AVX2 instructions. Learn more in the documentation. A GPT4All model is a 3GB - 8GB file that you can download and plug into the GPT4All open-source ecosystem software. Nomic AI supports and maintains this software ecosystem to enforce quality and security alongside spearheading the effort to allow any person or enterprise to easily train and deploy their own on-edge large language models.
README:
Now with support for DeepSeek R1 Distillations
Website • Documentation • Discord • YouTube Tutorial
GPT4All runs large language models (LLMs) privately on everyday desktops & laptops.
No API calls or GPUs required - you can just download the application and get started.
Read about what's new in our blog.
https://github.com/nomic-ai/gpt4all/assets/70534565/513a0f15-4964-4109-89e4-4f9a9011f311
GPT4All is made possible by our compute partner Paperspace.
 Windows Installer
Windows Installer
—
 macOS Installer
—
macOS Installer
—
—
 Ubuntu Installer
—
Ubuntu Installer
—
The Windows and Linux builds require Intel Core i3 2nd Gen / AMD Bulldozer, or better.
The Windows ARM build supports Qualcomm Snapdragon and Microsoft SQ1/SQ2 processors.
The Linux build is x86-64 only (no ARM).
The macOS build requires Monterey 12.6 or newer. Best results with Apple Silicon M-series processors.
See the full System Requirements for more details.
Flathub (community maintained)
gpt4all gives you access to LLMs with our Python client around llama.cpp implementations.
Nomic contributes to open source software like llama.cpp to make LLMs accessible and efficient for all.
pip install gpt4allfrom gpt4all import GPT4All
model = GPT4All("Meta-Llama-3-8B-Instruct.Q4_0.gguf") # downloads / loads a 4.66GB LLM
with model.chat_session():
print(model.generate("How can I run LLMs efficiently on my laptop?", max_tokens=1024))🦜🔗 Langchain 🗃️ Weaviate Vector Database - module docs 🔭 OpenLIT (OTel-native Monitoring) - Docs
-
July 2nd, 2024: V3.0.0 Release
- Fresh redesign of the chat application UI
- Improved user workflow for LocalDocs
- Expanded access to more model architectures
-
October 19th, 2023: GGUF Support Launches with Support for:
- Mistral 7b base model, an updated model gallery on our website, several new local code models including Rift Coder v1.5
- Nomic Vulkan support for Q4_0 and Q4_1 quantizations in GGUF.
- Offline build support for running old versions of the GPT4All Local LLM Chat Client.
- September 18th, 2023: Nomic Vulkan launches supporting local LLM inference on NVIDIA and AMD GPUs.
- July 2023: Stable support for LocalDocs, a feature that allows you to privately and locally chat with your data.
- June 28th, 2023: Docker-based API server launches allowing inference of local LLMs from an OpenAI-compatible HTTP endpoint.
GPT4All welcomes contributions, involvement, and discussion from the open source community! Please see CONTRIBUTING.md and follow the issues, bug reports, and PR markdown templates.
Check project discord, with project owners, or through existing issues/PRs to avoid duplicate work.
Please make sure to tag all of the above with relevant project identifiers or your contribution could potentially get lost.
Example tags: backend, bindings, python-bindings, documentation, etc.
If you utilize this repository, models or data in a downstream project, please consider citing it with:
@misc{gpt4all,
author = {Yuvanesh Anand and Zach Nussbaum and Brandon Duderstadt and Benjamin Schmidt and Andriy Mulyar},
title = {GPT4All: Training an Assistant-style Chatbot with Large Scale Data Distillation from GPT-3.5-Turbo},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/nomic-ai/gpt4all}},
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for gpt4all
Similar Open Source Tools
gpt4all
GPT4All is an ecosystem to run powerful and customized large language models that work locally on consumer grade CPUs and any GPU. Note that your CPU needs to support AVX or AVX2 instructions. Learn more in the documentation. A GPT4All model is a 3GB - 8GB file that you can download and plug into the GPT4All open-source ecosystem software. Nomic AI supports and maintains this software ecosystem to enforce quality and security alongside spearheading the effort to allow any person or enterprise to easily train and deploy their own on-edge large language models.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.
lunary
Lunary is an open-source observability and prompt platform for Large Language Models (LLMs). It provides a suite of features to help AI developers take their applications into production, including analytics, monitoring, prompt templates, fine-tuning dataset creation, chat and feedback tracking, and evaluations. Lunary is designed to be usable with any model, not just OpenAI, and is easy to integrate and self-host.

superduper
superduper.io is a Python framework that integrates AI models, APIs, and vector search engines directly with existing databases. It allows hosting of models, streaming inference, and scalable model training/fine-tuning. Key features include integration of AI with data infrastructure, inference via change-data-capture, scalable model training, model chaining, simple Python interface, Python-first approach, working with difficult data types, feature storing, and vector search capabilities. The tool enables users to turn their existing databases into centralized repositories for managing AI model inputs and outputs, as well as conducting vector searches without the need for specialized databases.
langflow
Langflow is an open-source Python-powered visual framework designed for building multi-agent and RAG applications. It is fully customizable, language model agnostic, and vector store agnostic. Users can easily create flows by dragging components onto the canvas, connect them, and export the flow as a JSON file. Langflow also provides a command-line interface (CLI) for easy management and configuration, allowing users to customize the behavior of Langflow for development or specialized deployment scenarios. The tool can be deployed on various platforms such as Google Cloud Platform, Railway, and Render. Contributors are welcome to enhance the project on GitHub by following the contributing guidelines.

AIOS
AIOS, a Large Language Model (LLM) Agent operating system, embeds large language model into Operating Systems (OS) as the brain of the OS, enabling an operating system "with soul" -- an important step towards AGI. AIOS is designed to optimize resource allocation, facilitate context switch across agents, enable concurrent execution of agents, provide tool service for agents, maintain access control for agents, and provide a rich set of toolkits for LLM Agent developers.
job-llm
ResumeFlow is an automated system utilizing Large Language Models (LLMs) to streamline the job application process. It aims to reduce human effort in various steps of job hunting by integrating LLM technology. Users can access ResumeFlow as a web tool, install it as a Python package, or download the source code. The project focuses on leveraging LLMs to automate tasks such as resume generation and refinement, making job applications smoother and more efficient.
chainlit
Chainlit is an open-source async Python framework which allows developers to build scalable Conversational AI or agentic applications. It enables users to create ChatGPT-like applications, embedded chatbots, custom frontends, and API endpoints. The framework provides features such as multi-modal chats, chain of thought visualization, data persistence, human feedback, and an in-context prompt playground. Chainlit is compatible with various Python programs and libraries, including LangChain, Llama Index, Autogen, OpenAI Assistant, and Haystack. It offers a range of examples and a cookbook to showcase its capabilities and inspire users. Chainlit welcomes contributions and is licensed under the Apache 2.0 license.
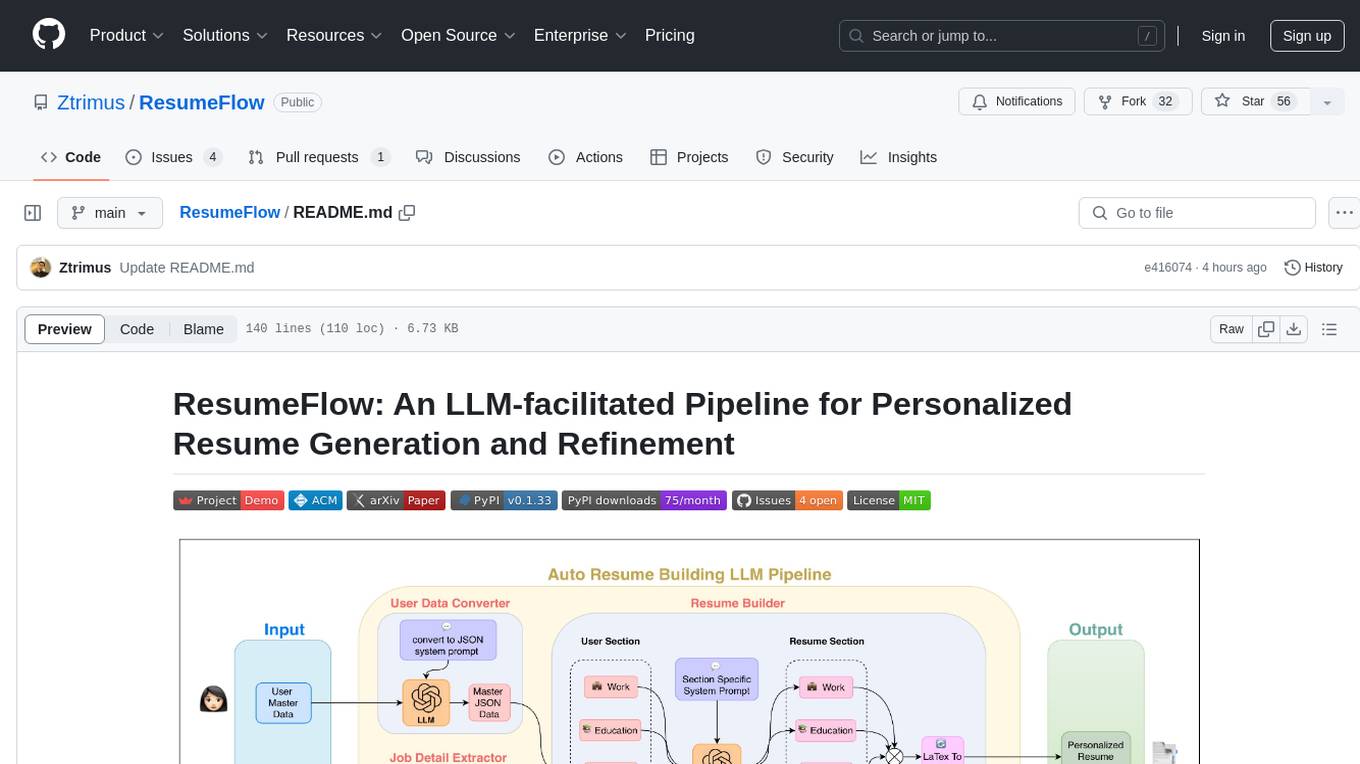
ResumeFlow
ResumeFlow is an automated system that leverages Large Language Models (LLMs) to streamline the job application process. By integrating LLM technology, the tool aims to automate various stages of job hunting, making it easier for users to apply for jobs. Users can access ResumeFlow as a web tool, install it as a Python package, or download the source code from GitHub. The tool requires Python 3.11.6 or above and an LLM API key from OpenAI or Gemini Pro for usage. ResumeFlow offers functionalities such as generating curated resumes and cover letters based on job URLs and user's master resume data.

starwhale
Starwhale is an MLOps/LLMOps platform that brings efficiency and standardization to machine learning operations. It streamlines the model development lifecycle, enabling teams to optimize workflows around key areas like model building, evaluation, release, and fine-tuning. Starwhale abstracts Model, Runtime, and Dataset as first-class citizens, providing tailored capabilities for common workflow scenarios including Models Evaluation, Live Demo, and LLM Fine-tuning. It is an open-source platform designed for clarity and ease of use, empowering developers to build customized MLOps features tailored to their needs.

toolhive-studio
ToolHive Studio is an experimental project under active development and testing, providing an easy way to discover, deploy, and manage Model Context Protocol (MCP) servers securely. Users can launch any MCP server in a locked-down container with just a few clicks, eliminating manual setup, security concerns, and runtime issues. The tool ensures instant deployment, default security measures, cross-platform compatibility, and seamless integration with popular clients like GitHub Copilot, Cursor, and Claude Code.

opencode
Opencode is an AI coding agent designed for the terminal. It is a tool that allows users to interact with AI models for coding tasks in a terminal-based environment. Opencode is open source, provider-agnostic, and focuses on a terminal user interface (TUI) for coding. It offers features such as client/server architecture, support for various AI models, and a strong emphasis on community contributions and feedback.

anything-llm
AnythingLLM is a full-stack application that enables you to turn any document, resource, or piece of content into context that any LLM can use as references during chatting. This application allows you to pick and choose which LLM or Vector Database you want to use as well as supporting multi-user management and permissions.

axoned
Axone is a public dPoS layer 1 designed for connecting, sharing, and monetizing resources in the AI stack. It is an open network for collaborative AI workflow management compatible with any data, model, or infrastructure, allowing sharing of data, algorithms, storage, compute, APIs, both on-chain and off-chain. The 'axoned' node of the AXONE network is built on Cosmos SDK & Tendermint consensus, enabling companies & individuals to define on-chain rules, share off-chain resources, and create new applications. Validators secure the network by maintaining uptime and staking $AXONE for rewards. The blockchain supports various platforms and follows Semantic Versioning 2.0.0. A docker image is available for quick start, with documentation on querying networks, creating wallets, starting nodes, and joining networks. Development involves Go and Cosmos SDK, with smart contracts deployed on the AXONE blockchain. The project provides a Makefile for building, installing, linting, and testing. Community involvement is encouraged through Discord, open issues, and pull requests.

genai-os
Kuwa GenAI OS is an open, free, secure, and privacy-focused Generative-AI Operating System. It provides a multi-lingual turnkey solution for GenAI development and deployment on Linux and Windows. Users can enjoy features such as concurrent multi-chat, quoting, full prompt-list import/export/share, and flexible orchestration of prompts, RAGs, bots, models, and hardware/GPUs. The system supports various environments from virtual hosts to cloud, and it is open source, allowing developers to contribute and customize according to their needs.
openmeter
OpenMeter is a real-time and scalable usage metering tool for AI, usage-based billing, infrastructure, and IoT use cases. It provides a REST API for integrations and offers client SDKs in Node.js, Python, Go, and Web. OpenMeter is licensed under the Apache 2.0 License.
For similar tasks

h2ogpt
h2oGPT is an Apache V2 open-source project that allows users to query and summarize documents or chat with local private GPT LLMs. It features a private offline database of any documents (PDFs, Excel, Word, Images, Video Frames, Youtube, Audio, Code, Text, MarkDown, etc.), a persistent database (Chroma, Weaviate, or in-memory FAISS) using accurate embeddings (instructor-large, all-MiniLM-L6-v2, etc.), and efficient use of context using instruct-tuned LLMs (no need for LangChain's few-shot approach). h2oGPT also offers parallel summarization and extraction, reaching an output of 80 tokens per second with the 13B LLaMa2 model, HYDE (Hypothetical Document Embeddings) for enhanced retrieval based upon LLM responses, a variety of models supported (LLaMa2, Mistral, Falcon, Vicuna, WizardLM. With AutoGPTQ, 4-bit/8-bit, LORA, etc.), GPU support from HF and LLaMa.cpp GGML models, and CPU support using HF, LLaMa.cpp, and GPT4ALL models. Additionally, h2oGPT provides Attention Sinks for arbitrarily long generation (LLaMa-2, Mistral, MPT, Pythia, Falcon, etc.), a UI or CLI with streaming of all models, the ability to upload and view documents through the UI (control multiple collaborative or personal collections), Vision Models LLaVa, Claude-3, Gemini-Pro-Vision, GPT-4-Vision, Image Generation Stable Diffusion (sdxl-turbo, sdxl) and PlaygroundAI (playv2), Voice STT using Whisper with streaming audio conversion, Voice TTS using MIT-Licensed Microsoft Speech T5 with multiple voices and Streaming audio conversion, Voice TTS using MPL2-Licensed TTS including Voice Cloning and Streaming audio conversion, AI Assistant Voice Control Mode for hands-free control of h2oGPT chat, Bake-off UI mode against many models at the same time, Easy Download of model artifacts and control over models like LLaMa.cpp through the UI, Authentication in the UI by user/password via Native or Google OAuth, State Preservation in the UI by user/password, Linux, Docker, macOS, and Windows support, Easy Windows Installer for Windows 10 64-bit (CPU/CUDA), Easy macOS Installer for macOS (CPU/M1/M2), Inference Servers support (oLLaMa, HF TGI server, vLLM, Gradio, ExLLaMa, Replicate, OpenAI, Azure OpenAI, Anthropic), OpenAI-compliant, Server Proxy API (h2oGPT acts as drop-in-replacement to OpenAI server), Python client API (to talk to Gradio server), JSON Mode with any model via code block extraction. Also supports MistralAI JSON mode, Claude-3 via function calling with strict Schema, OpenAI via JSON mode, and vLLM via guided_json with strict Schema, Web-Search integration with Chat and Document Q/A, Agents for Search, Document Q/A, Python Code, CSV frames (Experimental, best with OpenAI currently), Evaluate performance using reward models, and Quality maintained with over 1000 unit and integration tests taking over 4 GPU-hours.

serverless-chat-langchainjs
This sample shows how to build a serverless chat experience with Retrieval-Augmented Generation using LangChain.js and Azure. The application is hosted on Azure Static Web Apps and Azure Functions, with Azure Cosmos DB for MongoDB vCore as the vector database. You can use it as a starting point for building more complex AI applications.

react-native-vercel-ai
Run Vercel AI package on React Native, Expo, Web and Universal apps. Currently React Native fetch API does not support streaming which is used as a default on Vercel AI. This package enables you to use AI library on React Native but the best usage is when used on Expo universal native apps. On mobile you get back responses without streaming with the same API of `useChat` and `useCompletion` and on web it will fallback to `ai/react`

LLamaSharp
LLamaSharp is a cross-platform library to run 🦙LLaMA/LLaVA model (and others) on your local device. Based on llama.cpp, inference with LLamaSharp is efficient on both CPU and GPU. With the higher-level APIs and RAG support, it's convenient to deploy LLM (Large Language Model) in your application with LLamaSharp.
gpt4all
GPT4All is an ecosystem to run powerful and customized large language models that work locally on consumer grade CPUs and any GPU. Note that your CPU needs to support AVX or AVX2 instructions. Learn more in the documentation. A GPT4All model is a 3GB - 8GB file that you can download and plug into the GPT4All open-source ecosystem software. Nomic AI supports and maintains this software ecosystem to enforce quality and security alongside spearheading the effort to allow any person or enterprise to easily train and deploy their own on-edge large language models.

ChatGPT-Telegram-Bot
ChatGPT Telegram Bot is a Telegram bot that provides a smooth AI experience. It supports both Azure OpenAI and native OpenAI, and offers real-time (streaming) response to AI, with a faster and smoother experience. The bot also has 15 preset bot identities that can be quickly switched, and supports custom bot identities to meet personalized needs. Additionally, it supports clearing the contents of the chat with a single click, and restarting the conversation at any time. The bot also supports native Telegram bot button support, making it easy and intuitive to implement required functions. User level division is also supported, with different levels enjoying different single session token numbers, context numbers, and session frequencies. The bot supports English and Chinese on UI, and is containerized for easy deployment.

twinny
Twinny is a free and open-source AI code completion plugin for Visual Studio Code and compatible editors. It integrates with various tools and frameworks, including Ollama, llama.cpp, oobabooga/text-generation-webui, LM Studio, LiteLLM, and Open WebUI. Twinny offers features such as fill-in-the-middle code completion, chat with AI about your code, customizable API endpoints, and support for single or multiline fill-in-middle completions. It is easy to install via the Visual Studio Code extensions marketplace and provides a range of customization options. Twinny supports both online and offline operation and conforms to the OpenAI API standard.

agnai
Agnaistic is an AI roleplay chat tool that allows users to interact with personalized characters using their favorite AI services. It supports multiple AI services, persona schema formats, and features such as group conversations, user authentication, and memory/lore books. Agnaistic can be self-hosted or run using Docker, and it provides a range of customization options through its settings.json file. The tool is designed to be user-friendly and accessible, making it suitable for both casual users and developers.
For similar jobs

ChatFAQ
ChatFAQ is an open-source comprehensive platform for creating a wide variety of chatbots: generic ones, business-trained, or even capable of redirecting requests to human operators. It includes a specialized NLP/NLG engine based on a RAG architecture and customized chat widgets, ensuring a tailored experience for users and avoiding vendor lock-in.
agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.
anything-llm
AnythingLLM is a full-stack application that enables you to turn any document, resource, or piece of content into context that any LLM can use as references during chatting. This application allows you to pick and choose which LLM or Vector Database you want to use as well as supporting multi-user management and permissions.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.

glide
Glide is a cloud-native LLM gateway that provides a unified REST API for accessing various large language models (LLMs) from different providers. It handles LLMOps tasks such as model failover, caching, key management, and more, making it easy to integrate LLMs into applications. Glide supports popular LLM providers like OpenAI, Anthropic, Azure OpenAI, AWS Bedrock (Titan), Cohere, Google Gemini, OctoML, and Ollama. It offers high availability, performance, and observability, and provides SDKs for Python and NodeJS to simplify integration.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.