
clearml
ClearML - Auto-Magical CI/CD to streamline your AI workload. Experiment Management, Data Management, Pipeline, Orchestration, Scheduling & Serving in one MLOps/LLMOps solution
Stars: 5768

ClearML is a suite of tools designed to streamline the machine learning workflow. It includes an experiment manager, MLOps/LLMOps, data management, and model serving capabilities. ClearML is open-source and offers a free tier hosting option. It supports various ML/DL frameworks and integrates with Jupyter Notebook and PyCharm. ClearML provides extensive logging capabilities, including source control info, execution environment, hyper-parameters, and experiment outputs. It also offers automation features, such as remote job execution and pipeline creation. ClearML is designed to be easy to integrate, requiring only two lines of code to add to existing scripts. It aims to improve collaboration, visibility, and data transparency within ML teams.
README:
![]()
![]()
ClearML - Auto-Magical Suite of tools to streamline your AI workflow Experiment Manager, MLOps/LLMOps and Data-Management




🌟 ClearML is open-source - Leave a star to support the project! 🌟
Formerly known as Allegro Trains
ClearML is a ML/DL development and production suite. It contains FIVE main modules:
- Experiment Manager - Automagical experiment tracking, environments and results
- MLOps / LLMOps - Orchestration, Automation & Pipelines solution for ML/DL/GenAI jobs (Kubernetes / Cloud / bare-metal)
- Data-Management - Fully differentiable data management & version control solution on top of object-storage (S3 / GS / Azure / NAS)
-
Model-Serving - cloud-ready Scalable model serving solution!
- Deploy new model endpoints in under 5 minutes
- Includes optimized GPU serving support backed by Nvidia-Triton
- with out-of-the-box Model Monitoring
- Reports - Create and share rich MarkDown documents supporting embeddable online content
- 🔥 Orchestration Dashboard - Live rich dashboard for your entire compute cluster (Cloud / Kubernetes / On-Prem)
- NEW 💥 Fractional GPUs - Container based, driver level GPU memory limitation 🙀 !!!
Instrumenting these components is the ClearML-server, see Self-Hosting & Free tier Hosting
Sign up & Start using in under 2 minutes
Friendly tutorials to get you started
| Step 1 - Experiment Management |
|
| Step 2 - Remote Execution Agent Setup |
|
| Step 3 - Remotely Execute Tasks |
|
| Experiment Management | Datasets |
 |
 |
| Orchestration | Pipelines |
 |
 |
Adding only 2 lines to your code gets you the following
- Complete experiment setup log
- Full source control info, including non-committed local changes
- Execution environment (including specific packages & versions)
- Hyper-parameters
-
argparse/Click/PythonFire for command line parameters with currently used values - Explicit parameters dictionary
- Tensorflow Defines (absl-py)
- Hydra configuration and overrides
-
- Initial model weights file
- Full experiment output automatic capture
- stdout and stderr
- Resource Monitoring (CPU/GPU utilization, temperature, IO, network, etc.)
- Model snapshots (With optional automatic upload to central storage: Shared folder, S3, GS, Azure, Http)
- Artifacts log & store (Shared folder, S3, GS, Azure, Http)
- Tensorboard/TensorboardX scalars, metrics, histograms, images, audio and video samples
- Matplotlib & Seaborn
- ClearML Logger interface for complete flexibility.
- Extensive platform support and integrations
- Supported ML/DL frameworks: PyTorch (incl' ignite / lightning), Tensorflow, Keras, AutoKeras, FastAI, XGBoost, LightGBM, MegEngine and Scikit-Learn
- Seamless integration (including version control) with Jupyter Notebook and PyCharm remote debugging
-
Sign up for free to the ClearML Hosted Service (alternatively, you can set up your own server, see here).
ClearML Demo Server: ClearML no longer uses the demo server by default. To enable the demo server, set the
CLEARML_NO_DEFAULT_SERVER=0environment variable. Credentials aren't needed, but experiments launched to the demo server are public, so make sure not to launch sensitive experiments if using the demo server. -
Install the
clearmlpython package:pip install clearml
-
Connect the ClearML SDK to the server by creating credentials, then execute the command below and follow the instructions:
clearml-init
-
Add two lines to your code:
from clearml import Task task = Task.init(project_name='examples', task_name='hello world')
And you are done! Everything your process outputs is now automagically logged into ClearML.
Next step, automation! Learn more about ClearML's two-click automation here.
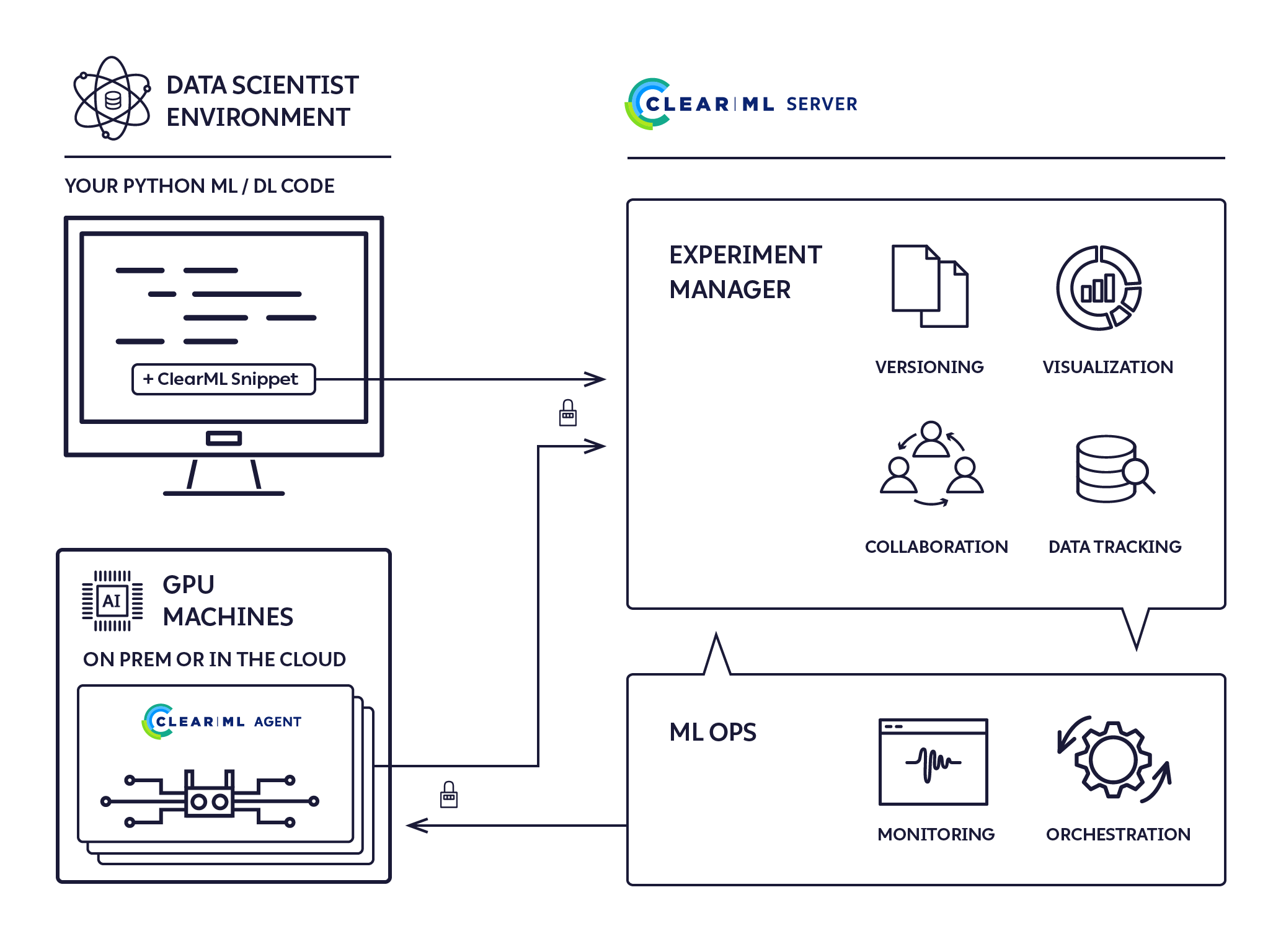
The ClearML run-time components:
- The ClearML Python Package - for integrating ClearML into your existing scripts by adding just two lines of code, and optionally extending your experiments and other workflows with ClearML's powerful and versatile set of classes and methods.
- The ClearML Server - for storing experiment, model, and workflow data; supporting the Web UI experiment manager and MLOps automation for reproducibility and tuning. It is available as a hosted service and open source for you to deploy your own ClearML Server.
- The ClearML Agent - for MLOps orchestration, experiment and workflow reproducibility, and scalability.
- clearml-session - Launch remote JupyterLab / VSCode-server inside any docker, on Cloud/On-Prem machines
- clearml-task - Run any codebase on remote machines with full remote logging of Tensorboard, Matplotlib & Console outputs
- clearml-data - CLI for managing and versioning your datasets, including creating / uploading / downloading of data from S3/GS/Azure/NAS
- AWS Auto-Scaler - Automatically spin EC2 instances based on your workloads with preconfigured budget! No need for AKE!
- Hyper-Parameter Optimization - Optimize any code with black-box approach and state-of-the-art Bayesian optimization algorithms
- Automation Pipeline - Build pipelines based on existing experiments / jobs, supports building pipelines of pipelines!
- Slack Integration - Report experiments progress / failure directly to Slack (fully customizable!)
ClearML is our solution to a problem we share with countless other researchers and developers in the machine learning/deep learning universe: Training production-grade deep learning models is a glorious but messy process. ClearML tracks and controls the process by associating code version control, research projects, performance metrics, and model provenance.
We designed ClearML specifically to require effortless integration so that teams can preserve their existing methods and practices.
- Use it on a daily basis to boost collaboration and visibility in your team
- Create a remote job from any experiment with a click of a button
- Automate processes and create pipelines to collect your experimentation logs, outputs, and data
- Store all your data on any object-storage solution, with the most straightforward interface possible
- Make your data transparent by cataloging it all on the ClearML platform
We believe ClearML is ground-breaking. We wish to establish new standards of true seamless integration between experiment management, MLOps, and data management.
ClearML is supported by you and the clear.ml team, which helps enterprise companies build scalable MLOps.
We built ClearML to track and control the glorious but messy process of training production-grade deep learning models. We are committed to vigorously supporting and expanding the capabilities of ClearML.
We promise to always be backwardly compatible, making sure all your logs, data, and pipelines will always upgrade with you.
Apache License, Version 2.0 (see the LICENSE for more information)
If ClearML is part of your development process / project / publication, please cite us ❤️ :
@misc{clearml,
title = {ClearML - Your entire MLOps stack in one open-source tool},
year = {2024},
note = {Software available from http://github.com/allegroai/clearml},
url={https://clear.ml/},
author = {ClearML},
}
For more information, see the official documentation and on YouTube.
For examples and use cases, check the examples folder and corresponding documentation.
If you have any questions: post on our Slack Channel, or tag your questions on stackoverflow with 'clearml' tag (previously trains tag).
For feature requests or bug reports, please use GitHub issues.
Additionally, you can always find us at [email protected]
PRs are always welcome ❤️ See more details in the ClearML Guidelines for Contributing.
May the force (and the goddess of learning rates) be with you!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for clearml
Similar Open Source Tools
clearml
ClearML is a suite of tools designed to streamline the machine learning workflow. It includes an experiment manager, MLOps/LLMOps, data management, and model serving capabilities. ClearML is open-source and offers a free tier hosting option. It supports various ML/DL frameworks and integrates with Jupyter Notebook and PyCharm. ClearML provides extensive logging capabilities, including source control info, execution environment, hyper-parameters, and experiment outputs. It also offers automation features, such as remote job execution and pipeline creation. ClearML is designed to be easy to integrate, requiring only two lines of code to add to existing scripts. It aims to improve collaboration, visibility, and data transparency within ML teams.

clearml
ClearML is an auto-magical suite of tools designed to streamline AI workflows. It includes modules for experiment management, MLOps/LLMOps, data management, model serving, and more. ClearML offers features like experiment tracking, model serving, orchestration, and automation. It supports various ML/DL frameworks and integrates with Jupyter Notebook and PyCharm for remote debugging. ClearML aims to simplify collaboration, automate processes, and enhance visibility in AI projects.
neptune-client
Neptune is a scalable experiment tracker for teams training foundation models. Log millions of runs, effortlessly monitor and visualize model training, and deploy on your infrastructure. Track 100% of metadata to accelerate AI breakthroughs. Log and display any framework and metadata type from any ML pipeline. Organize experiments with nested structures and custom dashboards. Compare results, visualize training, and optimize models quicker. Version models, review stages, and access production-ready models. Share results, manage users, and projects. Integrate with 25+ frameworks. Trusted by great companies to improve workflow.

TaskingAI
TaskingAI brings Firebase's simplicity to **AI-native app development**. The platform enables the creation of GPTs-like multi-tenant applications using a wide range of LLMs from various providers. It features distinct, modular functions such as Inference, Retrieval, Assistant, and Tool, seamlessly integrated to enhance the development process. TaskingAI’s cohesive design ensures an efficient, intelligent, and user-friendly experience in AI application development.

mlflow
MLflow is a platform to streamline machine learning development, including tracking experiments, packaging code into reproducible runs, and sharing and deploying models. MLflow offers a set of lightweight APIs that can be used with any existing machine learning application or library (TensorFlow, PyTorch, XGBoost, etc), wherever you currently run ML code (e.g. in notebooks, standalone applications or the cloud). MLflow's current components are:
* `MLflow Tracking
aiida-core
AiiDA (www.aiida.net) is a workflow manager for computational science with a strong focus on provenance, performance and extensibility. **Features** * **Workflows:** Write complex, auto-documenting workflows in python, linked to arbitrary executables on local and remote computers. The event-based workflow engine supports tens of thousands of processes per hour with full checkpointing. * **Data provenance:** Automatically track inputs, outputs & metadata of all calculations in a provenance graph for full reproducibility. Perform fast queries on graphs containing millions of nodes. * **HPC interface:** Move your calculations to a different computer by changing one line of code. AiiDA is compatible with schedulers like SLURM, PBS Pro, torque, SGE or LSF out of the box. * **Plugin interface:** Extend AiiDA with plugins for new simulation codes (input generation & parsing), data types, schedulers, transport modes and more. * **Open Science:** Export subsets of your provenance graph and share them with peers or make them available online for everyone on the Materials Cloud. * **Open source:** AiiDA is released under the MIT open source license

UltraRAG
The UltraRAG framework is a researcher and developer-friendly RAG system solution that simplifies the process from data construction to model fine-tuning in domain adaptation. It introduces an automated knowledge adaptation technology system, supporting no-code programming, one-click synthesis and fine-tuning, multidimensional evaluation, and research-friendly exploration work integration. The architecture consists of Frontend, Service, and Backend components, offering flexibility in customization and optimization. Performance evaluation in the legal field shows improved results compared to VanillaRAG, with specific metrics provided. The repository is licensed under Apache-2.0 and encourages citation for support.

Kiln
Kiln is an intuitive tool for fine-tuning LLM models, generating synthetic data, and collaborating on datasets. It offers desktop apps for Windows, MacOS, and Linux, zero-code fine-tuning for various models, interactive data generation, and Git-based version control. Users can easily collaborate with QA, PM, and subject matter experts, generate auto-prompts, and work with a wide range of models and providers. The tool is open-source, privacy-first, and supports structured data tasks in JSON format. Kiln is free to use and helps build high-quality AI products with datasets, facilitates collaboration between technical and non-technical teams, allows comparison of models and techniques without code, ensures structured data integrity, and prioritizes user privacy.

toolhive-studio
ToolHive Studio is an experimental project under active development and testing, providing an easy way to discover, deploy, and manage Model Context Protocol (MCP) servers securely. Users can launch any MCP server in a locked-down container with just a few clicks, eliminating manual setup, security concerns, and runtime issues. The tool ensures instant deployment, default security measures, cross-platform compatibility, and seamless integration with popular clients like GitHub Copilot, Cursor, and Claude Code.
aegis-stack
Aegis Stack is a system for creating and evolving modular Python applications quickly, without the need for extensive testing or clean architecture. It allows users to go from idea to working prototype rapidly, using familiar tools. The stack includes a CLI, a built-in system dashboard called Overseer, and an optional conversational interface named Illiana. Users can start with basic components and add or remove features as needed, without being locked into initial choices. Aegis Stack aims to provide a flexible and efficient development environment for Python applications.
agentgateway
Agentgateway is an open source data plane optimized for agentic AI connectivity within or across any agent framework or environment. It provides drop-in security, observability, and governance for agent-to-agent and agent-to-tool communication, supporting leading interoperable protocols like Agent2Agent (A2A) and Model Context Protocol (MCP). Highly performant, security-first, multi-tenant, dynamic, and supporting legacy API transformation, agentgateway is designed to handle any scale and run anywhere with any agent framework.
ros-mcp-server
The ros-mcp-server repository contains a ROS (Robot Operating System) package that provides a server for Multi-Contact Planning (MCP) in robotics. The server facilitates the planning of multiple contacts between a robot and its environment, enabling complex manipulation tasks. It includes functionalities for collision checking, motion planning, and contact stability analysis. This tool is designed to enhance the capabilities of robotic systems by enabling them to perform tasks that involve multiple points of contact with the environment. The repository includes documentation and examples to help users integrate the MCP server into their robotic applications.

kalavai-client
Kalavai is an open-source platform that transforms everyday devices into an AI supercomputer by aggregating resources from multiple machines. It facilitates matchmaking of resources for large AI projects, making AI hardware accessible and affordable. Users can create local and public pools, connect with the community's resources, and share computing power. The platform aims to be a management layer for research groups and organizations, enabling users to unlock the power of existing hardware without needing a devops team. Kalavai CLI tool helps manage both versions of the platform.
docq
Docq is a private and secure GenAI tool designed to extract knowledge from business documents, enabling users to find answers independently. It allows data to stay within organizational boundaries, supports self-hosting with various cloud vendors, and offers multi-model and multi-modal capabilities. Docq is extensible, open-source (AGPLv3), and provides commercial licensing options. The tool aims to be a turnkey solution for organizations to adopt AI innovation safely, with plans for future features like more data ingestion options and model fine-tuning.

starwhale
Starwhale is an MLOps/LLMOps platform that brings efficiency and standardization to machine learning operations. It streamlines the model development lifecycle, enabling teams to optimize workflows around key areas like model building, evaluation, release, and fine-tuning. Starwhale abstracts Model, Runtime, and Dataset as first-class citizens, providing tailored capabilities for common workflow scenarios including Models Evaluation, Live Demo, and LLM Fine-tuning. It is an open-source platform designed for clarity and ease of use, empowering developers to build customized MLOps features tailored to their needs.

instill-core
Instill Core is an open-source orchestrator comprising a collection of source-available projects designed to streamline every aspect of building versatile AI features with unstructured data. It includes Instill VDP (Versatile Data Pipeline) for unstructured data, AI, and pipeline orchestration, Instill Model for scalable MLOps and LLMOps for open-source or custom AI models, and Instill Artifact for unified unstructured data management. Instill Core can be used for tasks such as building, testing, and sharing pipelines, importing, serving, fine-tuning, and monitoring ML models, and transforming documents, images, audio, and video into a unified AI-ready format.
For similar tasks

autogen
AutoGen is a framework that enables the development of LLM applications using multiple agents that can converse with each other to solve tasks. AutoGen agents are customizable, conversable, and seamlessly allow human participation. They can operate in various modes that employ combinations of LLMs, human inputs, and tools.

tracecat
Tracecat is an open-source automation platform for security teams. It's designed to be simple but powerful, with a focus on AI features and a practitioner-obsessed UI/UX. Tracecat can be used to automate a variety of tasks, including phishing email investigation, evidence collection, and remediation plan generation.

ciso-assistant-community
CISO Assistant is a tool that helps organizations manage their cybersecurity posture and compliance. It provides a centralized platform for managing security controls, threats, and risks. CISO Assistant also includes a library of pre-built frameworks and tools to help organizations quickly and easily implement best practices.

ck
Collective Mind (CM) is a collection of portable, extensible, technology-agnostic and ready-to-use automation recipes with a human-friendly interface (aka CM scripts) to unify and automate all the manual steps required to compose, run, benchmark and optimize complex ML/AI applications on any platform with any software and hardware: see online catalog and source code. CM scripts require Python 3.7+ with minimal dependencies and are continuously extended by the community and MLCommons members to run natively on Ubuntu, MacOS, Windows, RHEL, Debian, Amazon Linux and any other operating system, in a cloud or inside automatically generated containers while keeping backward compatibility - please don't hesitate to report encountered issues here and contact us via public Discord Server to help this collaborative engineering effort! CM scripts were originally developed based on the following requirements from the MLCommons members to help them automatically compose and optimize complex MLPerf benchmarks, applications and systems across diverse and continuously changing models, data sets, software and hardware from Nvidia, Intel, AMD, Google, Qualcomm, Amazon and other vendors: * must work out of the box with the default options and without the need to edit some paths, environment variables and configuration files; * must be non-intrusive, easy to debug and must reuse existing user scripts and automation tools (such as cmake, make, ML workflows, python poetry and containers) rather than substituting them; * must have a very simple and human-friendly command line with a Python API and minimal dependencies; * must require minimal or zero learning curve by using plain Python, native scripts, environment variables and simple JSON/YAML descriptions instead of inventing new workflow languages; * must have the same interface to run all automations natively, in a cloud or inside containers. CM scripts were successfully validated by MLCommons to modularize MLPerf inference benchmarks and help the community automate more than 95% of all performance and power submissions in the v3.1 round across more than 120 system configurations (models, frameworks, hardware) while reducing development and maintenance costs.

zenml
ZenML is an extensible, open-source MLOps framework for creating portable, production-ready machine learning pipelines. By decoupling infrastructure from code, ZenML enables developers across your organization to collaborate more effectively as they develop to production.
clearml
ClearML is a suite of tools designed to streamline the machine learning workflow. It includes an experiment manager, MLOps/LLMOps, data management, and model serving capabilities. ClearML is open-source and offers a free tier hosting option. It supports various ML/DL frameworks and integrates with Jupyter Notebook and PyCharm. ClearML provides extensive logging capabilities, including source control info, execution environment, hyper-parameters, and experiment outputs. It also offers automation features, such as remote job execution and pipeline creation. ClearML is designed to be easy to integrate, requiring only two lines of code to add to existing scripts. It aims to improve collaboration, visibility, and data transparency within ML teams.
devchat
DevChat is an open-source workflow engine that enables developers to create intelligent, automated workflows for engaging with users through a chat panel within their IDEs. It combines script writing flexibility, latest AI models, and an intuitive chat GUI to enhance user experience and productivity. DevChat simplifies the integration of AI in software development, unlocking new possibilities for developers.

LLM-Finetuning-Toolkit
LLM Finetuning toolkit is a config-based CLI tool for launching a series of LLM fine-tuning experiments on your data and gathering their results. It allows users to control all elements of a typical experimentation pipeline - prompts, open-source LLMs, optimization strategy, and LLM testing - through a single YAML configuration file. The toolkit supports basic, intermediate, and advanced usage scenarios, enabling users to run custom experiments, conduct ablation studies, and automate fine-tuning workflows. It provides features for data ingestion, model definition, training, inference, quality assurance, and artifact outputs, making it a comprehensive tool for fine-tuning large language models.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.