Best AI tools for< Deploy Models >
41 - AI tool Sites
Anote
Anote is a human-centered AI company that provides a suite of products and services to help businesses improve their data quality and build better AI models. Anote's products include a data labeler, a private chatbot, a model inference API, and a lead generation tool. Anote's services include data annotation, model training, and consulting.

HappyML
HappyML is an AI tool designed to assist users in machine learning tasks. It provides a user-friendly interface for running machine learning algorithms without the need for complex coding. With HappyML, users can easily build, train, and deploy machine learning models for various applications. The tool offers a range of features such as data preprocessing, model evaluation, hyperparameter tuning, and model deployment. HappyML simplifies the machine learning process, making it accessible to users with varying levels of expertise.

Release.ai
Release.ai is an AI-centric platform that allows developers, operations, and leadership teams to easily deploy and manage AI applications. It offers pre-configured templates for popular open-source technologies, private AI environments for secure development, and access to GPU resources. With Release.ai, users can build, test, and scale AI solutions quickly and efficiently within their own boundaries.
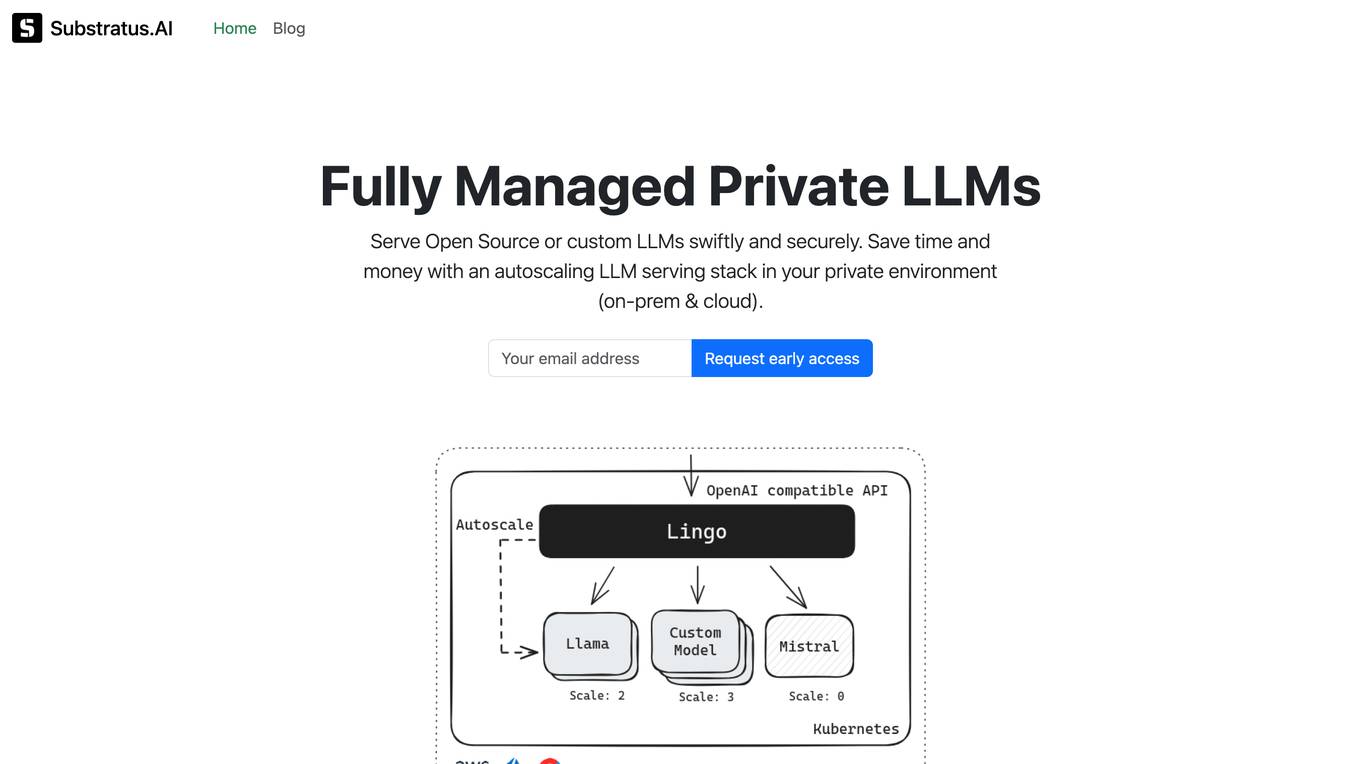
Substratus.AI
Substratus.AI is a fully managed private LLMs platform that allows users to serve LLMs (Llama and Mistral) in their own cloud account. It enables users to keep control of their data while reducing OpenAI costs by up to 10x. With Substratus.AI, users can utilize LLMs in production in hours instead of weeks, making it a convenient and efficient solution for AI model deployment.
Baseten
Baseten is a machine learning infrastructure that provides a unified platform for data scientists and engineers to build, train, and deploy machine learning models. It offers a range of features to simplify the ML lifecycle, including data preparation, model training, and deployment. Baseten also provides a marketplace of pre-built models and components that can be used to accelerate the development of ML applications.
GPUX
GPUX is a cloud platform that provides access to GPUs for running AI workloads. It offers a variety of features to make it easy to deploy and run AI models, including a user-friendly interface, pre-built templates, and support for a variety of programming languages. GPUX is also committed to providing a sustainable and ethical platform, and it has partnered with organizations such as the Climate Leadership Council to reduce its carbon footprint.
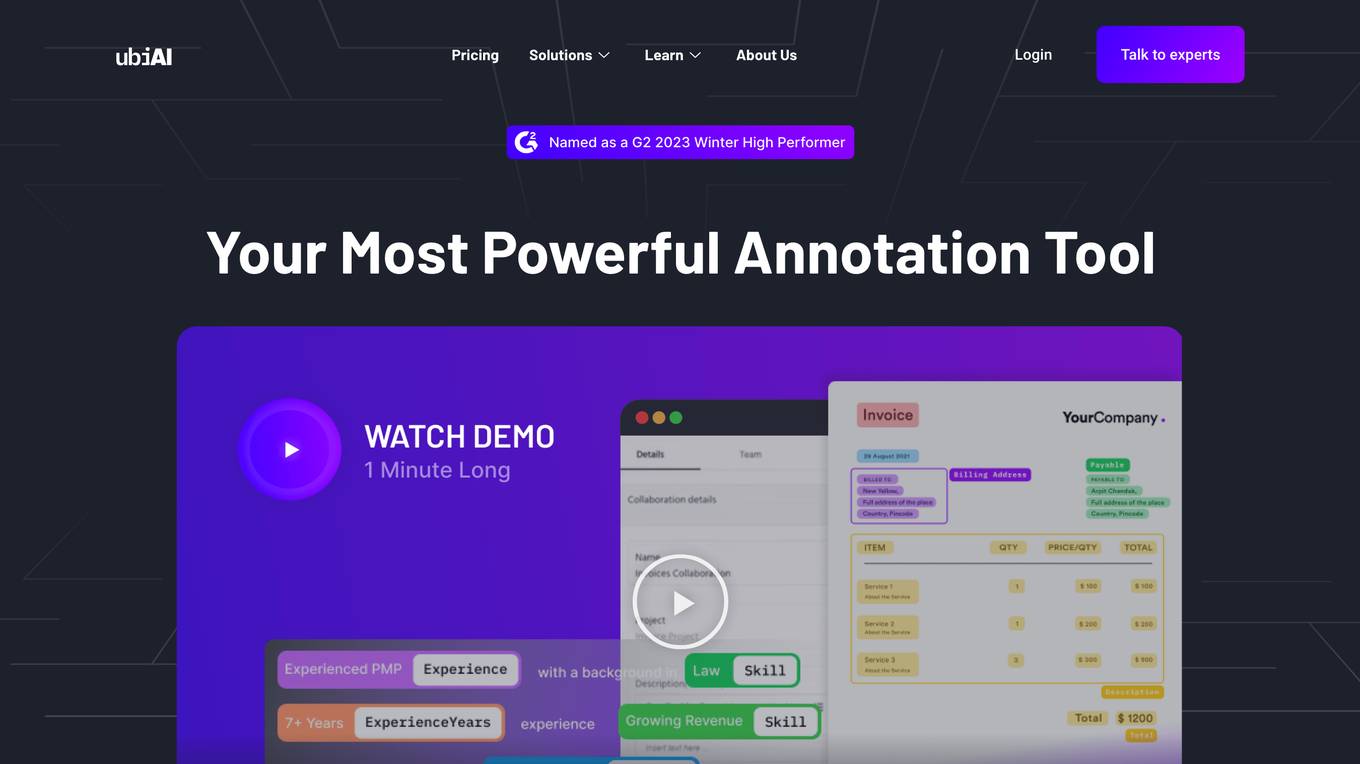
UBIAI
UBIAI is a powerful text annotation tool that helps businesses accelerate their data labeling process. With UBIAI, businesses can annotate any type of document, including PDFs, images, and text. UBIAI also offers a variety of features to make the annotation process easier and more efficient, such as auto-labeling, multi-lingual annotation, and team collaboration. With UBIAI, businesses can save time and money on their data labeling projects.
Tredence
Tredence is a data science and AI services company that provides end-to-end solutions for businesses across various industries. The company's services include data engineering, data analytics, AI consulting, and machine learning operations (MLOps). Tredence has a team of experienced data scientists and engineers who use their expertise to help businesses solve complex data challenges and achieve their business goals.
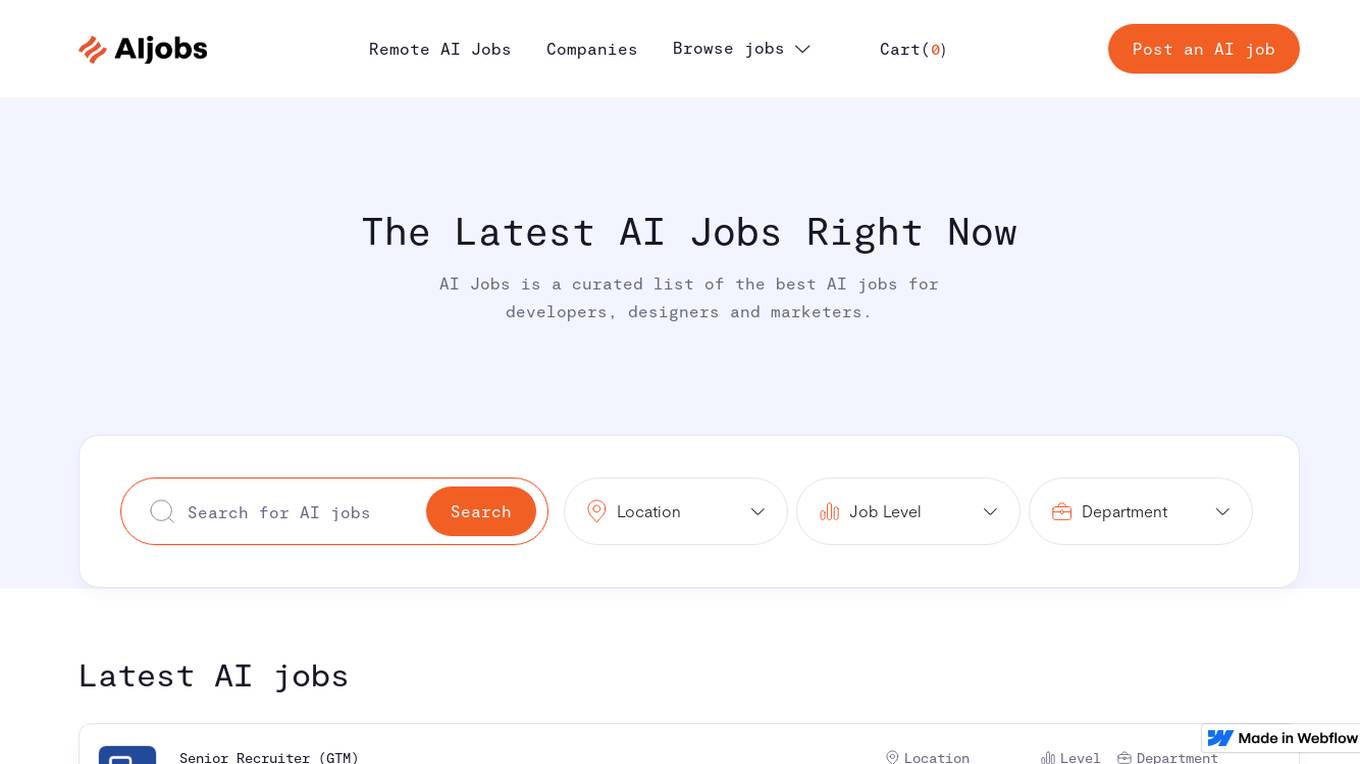
AI Jobs
AI Jobs is a curated list of the best AI jobs for developers, designers and marketers. It provides a platform for companies to post their AI-related job openings and for job seekers to find their dream AI job. The website also includes a blog with articles on the latest AI trends and technologies.
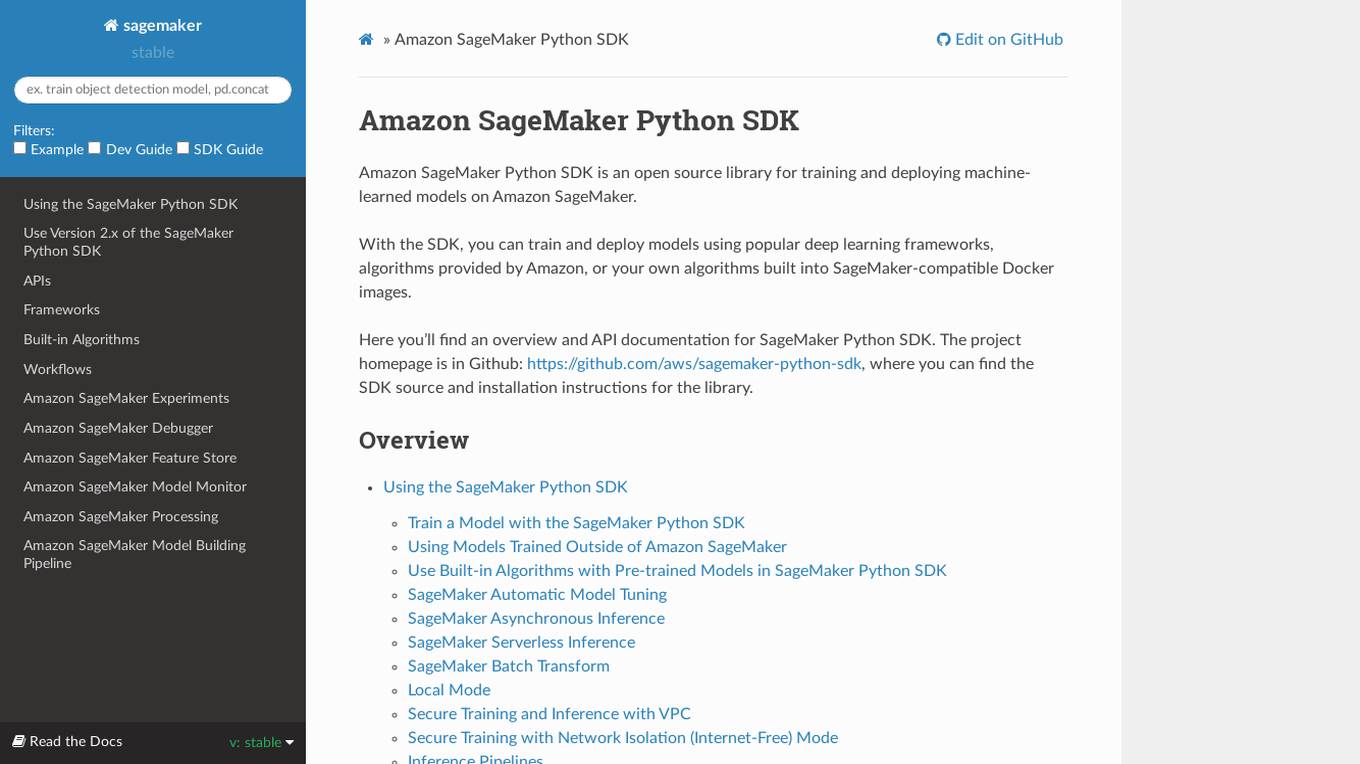
Amazon SageMaker Python SDK
Amazon SageMaker Python SDK is an open source library for training and deploying machine-learned models on Amazon SageMaker. With the SDK, you can train and deploy models using popular deep learning frameworks, algorithms provided by Amazon, or your own algorithms built into SageMaker-compatible Docker images.
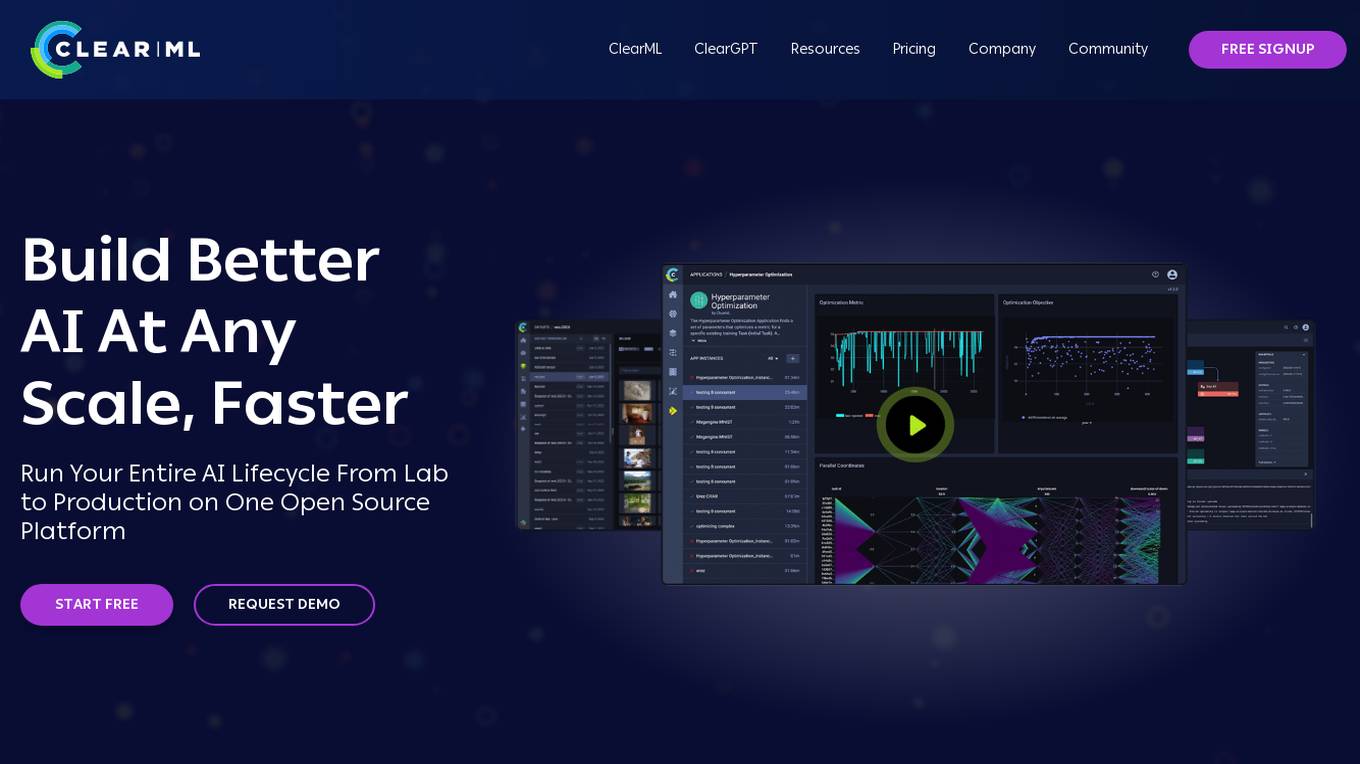
ClearML
ClearML is an open-source, end-to-end platform for continuous machine learning (ML). It provides a unified platform for data management, experiment tracking, model training, deployment, and monitoring. ClearML is designed to make it easy for teams to collaborate on ML projects and to ensure that models are deployed and maintained in a reliable and scalable way.
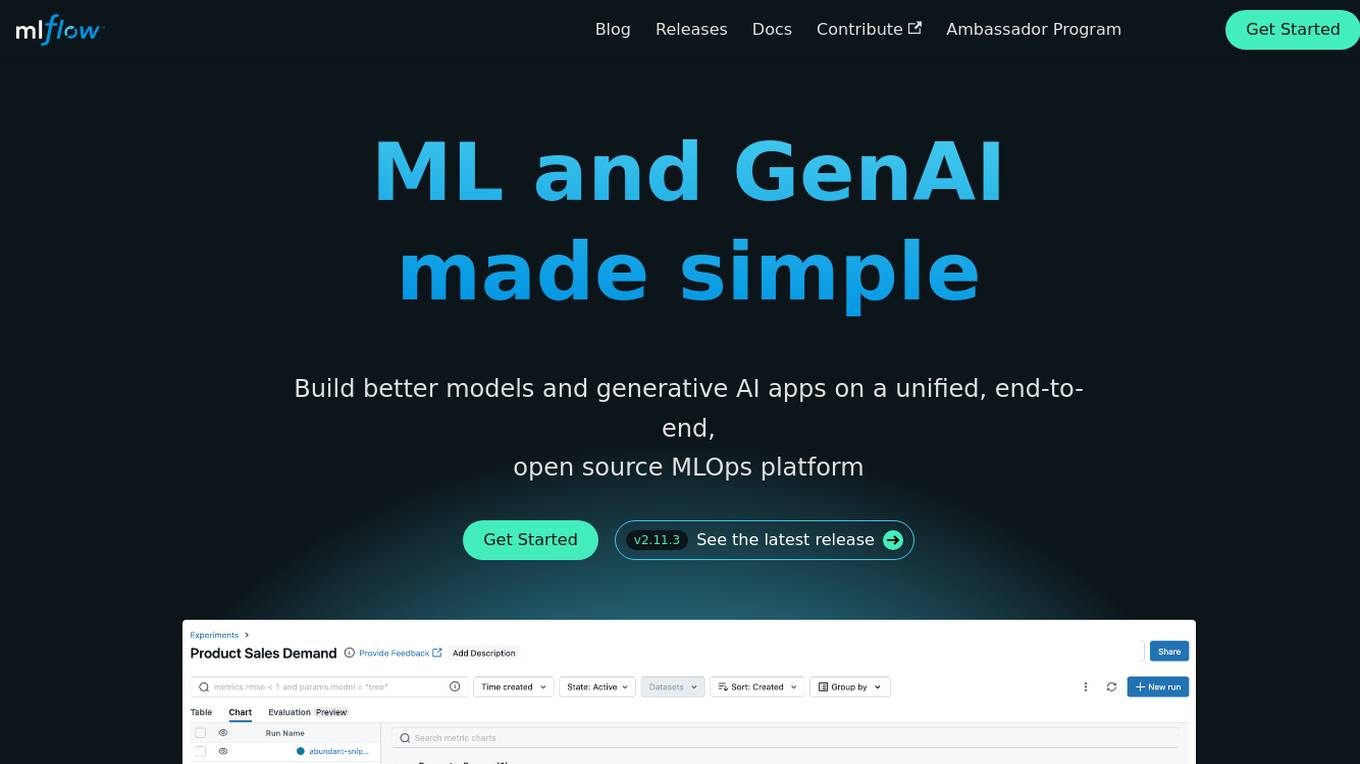
MLflow
MLflow is an open source platform for managing the end-to-end machine learning (ML) lifecycle, including tracking experiments, packaging models, deploying models, and managing model registries. It provides a unified platform for both traditional ML and generative AI applications.
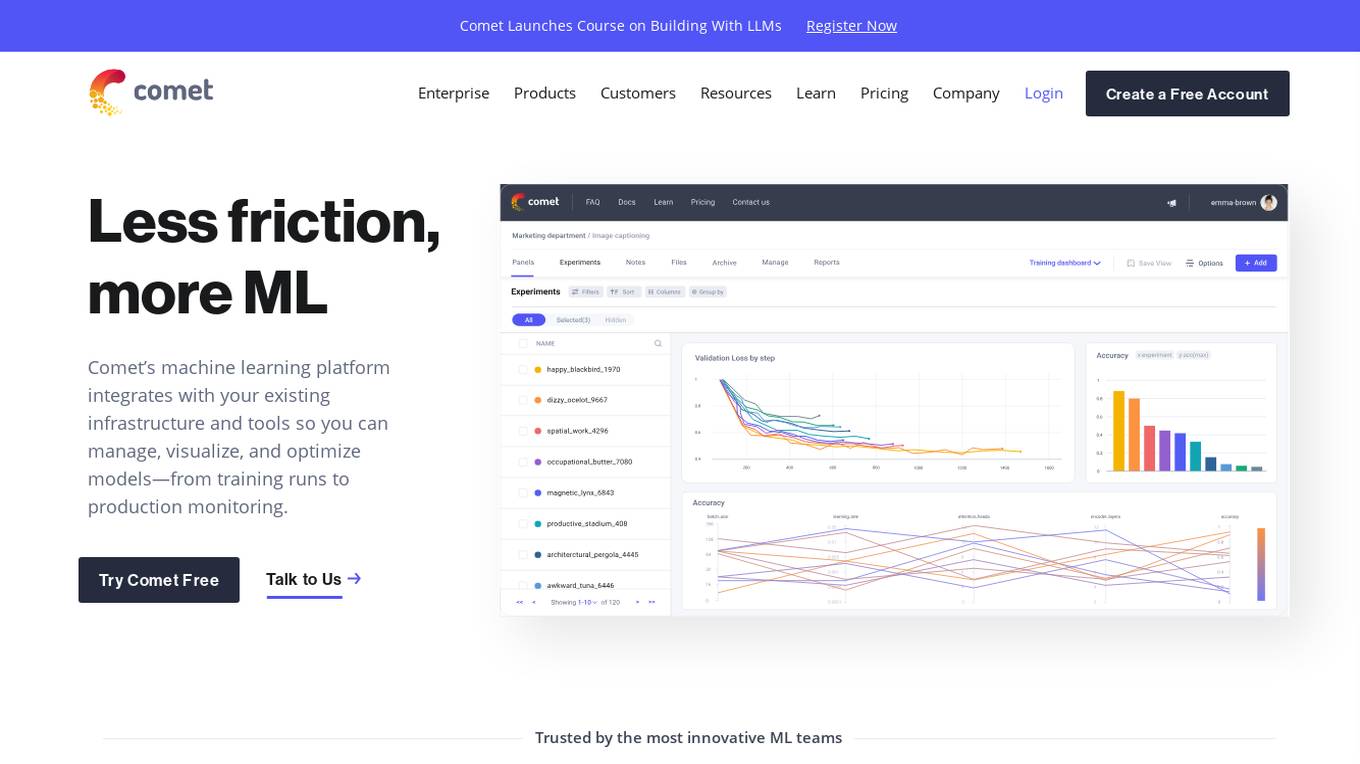
Comet ML
Comet ML is a machine learning platform that integrates with your existing infrastructure and tools so you can manage, visualize, and optimize models—from training runs to production monitoring.
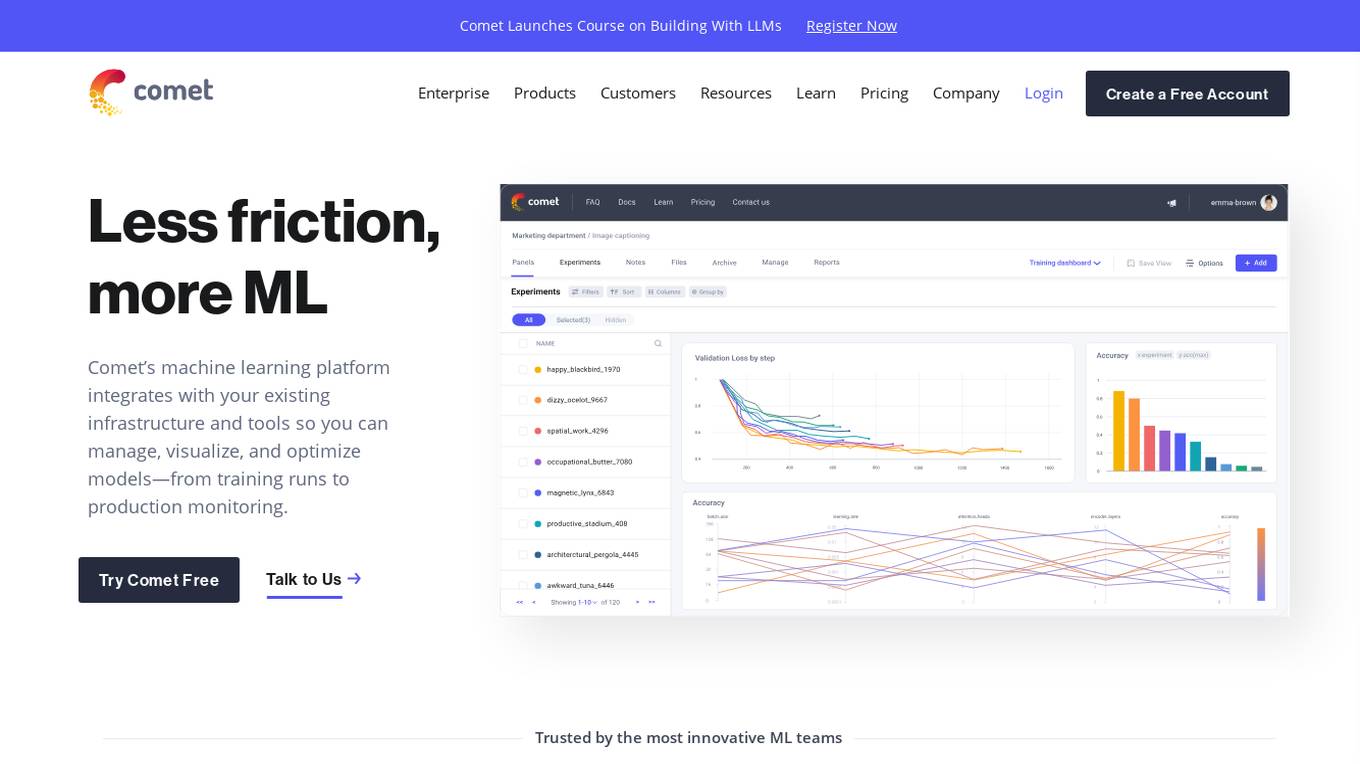
Comet ML
Comet ML is a machine learning platform that integrates with your existing infrastructure and tools so you can manage, visualize, and optimize models—from training runs to production monitoring.
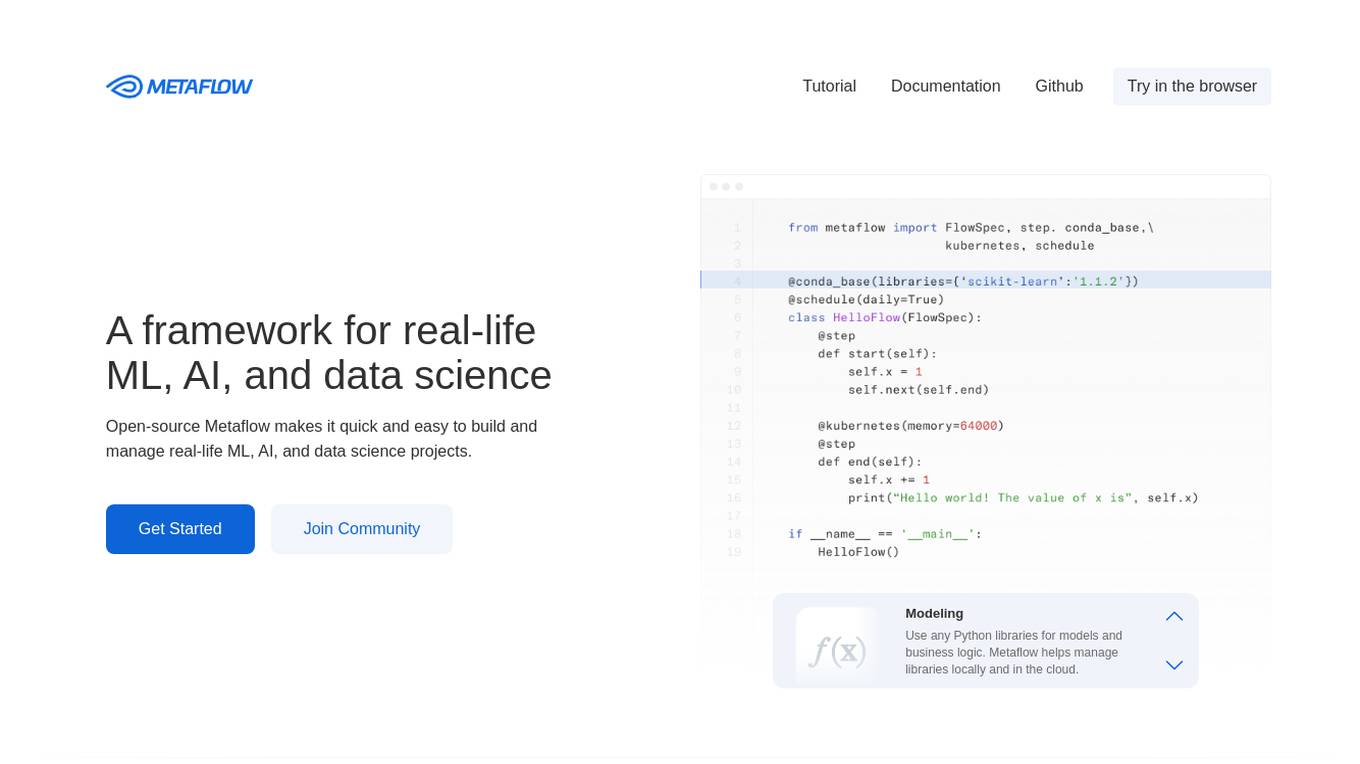
Metaflow
Metaflow is an open-source framework for building and managing real-life ML, AI, and data science projects. It makes it easy to use any Python libraries for models and business logic, deploy workflows to production with a single command, track and store variables inside the flow automatically for easy experiment tracking and debugging, and create robust workflows in plain Python. Metaflow is used by hundreds of companies, including Netflix, 23andMe, and Realtor.com.
PyTorch
PyTorch is an open-source machine learning library based on the Torch library. It is used for applications such as computer vision, natural language processing, and reinforcement learning. PyTorch is known for its flexibility and ease of use, making it a popular choice for researchers and developers in the field of artificial intelligence.

Kubeflow
Kubeflow is an open-source machine learning (ML) toolkit that makes deploying ML workflows on Kubernetes simple, portable, and scalable. It provides a unified interface for model training, serving, and hyperparameter tuning, and supports a variety of popular ML frameworks including PyTorch, TensorFlow, and XGBoost. Kubeflow is designed to be used with Kubernetes, a container orchestration system that automates the deployment, management, and scaling of containerized applications.
Apache MXNet
Apache MXNet is a flexible and efficient deep learning library designed for research, prototyping, and production. It features a hybrid front-end that seamlessly transitions between imperative and symbolic modes, enabling both flexibility and speed. MXNet also supports distributed training and performance optimization through Parameter Server and Horovod. With bindings for multiple languages, including Python, Scala, Julia, Clojure, Java, C++, R, and Perl, MXNet offers wide accessibility. Additionally, it boasts a thriving ecosystem of tools and libraries that extend its capabilities in computer vision, NLP, time series, and more.
RunPod
RunPod is a cloud platform specifically designed for AI development and deployment. It offers a range of features to streamline the process of developing, training, and scaling AI models, including a library of pre-built templates, efficient training pipelines, and scalable deployment options. RunPod also provides access to a wide selection of GPUs, allowing users to choose the optimal hardware for their specific AI workloads.

Coursera
Coursera is an online learning platform that offers courses, specializations, and degrees from top universities and companies. It provides a wide range of subjects, including business, computer science, data science, and more. Coursera also offers a variety of learning formats, including self-paced courses, live online classes, and guided projects. With Coursera, you can learn at your own pace and on your own schedule.
Streamlit
Streamlit is an open-source Python library that makes it easy to create and share beautiful and interactive web apps for data science and machine learning.
Practical Deep Learning for Coders
Practical Deep Learning for Coders is a free course designed for individuals with some coding experience who want to learn how to apply deep learning and machine learning to practical problems. The course covers topics such as building and training deep learning models for computer vision, natural language processing, tabular analysis, and collaborative filtering problems. It is based on a 5-star rated book and does not require any special hardware or software. The course is led by Jeremy Howard, a renowned expert in machine learning and the President and Chief Scientist of Kaggle.

SuperAnnotate
SuperAnnotate is an AI data platform that simplifies and accelerates model-building by unifying the AI pipeline. It enables users to create, curate, and evaluate datasets efficiently, leading to the development of better models faster. The platform offers features like connecting any data source, building customizable UIs, creating high-quality datasets, evaluating models, and deploying models seamlessly. SuperAnnotate ensures global security and privacy measures for data protection.
OmniAI
OmniAI is an AI tool that allows teams to deploy AI applications on their existing infrastructure. It provides a unified API experience for building AI applications and offers a wide selection of industry-leading models. With tools like Llama 3, Claude 3, Mistral Large, and AWS Titan, OmniAI excels in tasks such as natural language understanding, generation, safety, ethical behavior, and context retention. It also enables users to deploy and query the latest AI models quickly and easily within their virtual private cloud environment.
Graphcore
Graphcore is a cloud-based platform that accelerates machine learning processes by harnessing the power of IPU-powered generative AI. It offers cloud services, pre-trained models, optimized inference engines, and APIs to streamline operations and bring intelligence to enterprise applications. With Graphcore, users can build and deploy AI-native products and platforms using the latest AI technologies such as LLMs, NLP, and Computer Vision.
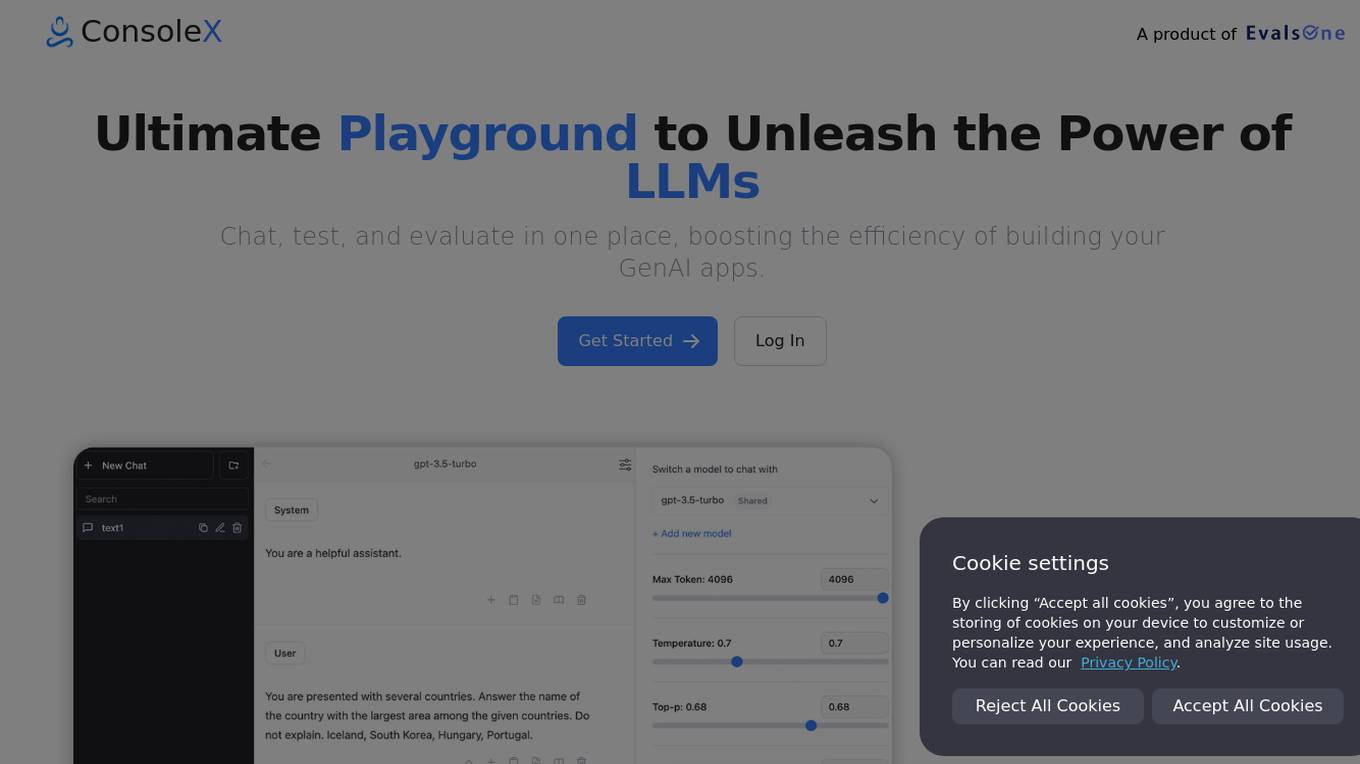
ConsoleX
ConsoleX is an advanced AI tool that offers a wide range of functionalities to unlock infinite possibilities in the field of artificial intelligence. It provides users with a powerful platform to develop, test, and deploy AI models with ease. With cutting-edge features and intuitive interface, ConsoleX is designed to cater to the needs of both beginners and experts in the AI domain. Whether you are a data scientist, researcher, or developer, ConsoleX empowers you to explore the full potential of AI technology and drive innovation in your projects.
Arcee AI
Arcee AI is a platform that offers a cost-effective, secure, end-to-end solution for building and deploying Small Language Models (SLMs). It allows users to merge and train custom language models by leveraging open source models and their own data. The platform is known for its Model Merging technique, which combines the power of pre-trained Large Language Models (LLMs) with user-specific data to create high-performing models across various industries.
Roboflow
Roboflow is an AI tool designed for computer vision tasks, offering a platform that allows users to annotate, train, deploy, and perform inference on models. It provides integrations, ecosystem support, and features like notebooks, autodistillation, and supervision. Roboflow caters to various industries such as aerospace, agriculture, healthcare, finance, and more, with a focus on simplifying the development and deployment of computer vision models.
UbiOps
UbiOps is an AI infrastructure platform that helps teams quickly run their AI & ML workloads as reliable and secure microservices. It offers powerful AI model serving and orchestration with unmatched simplicity, speed, and scale. UbiOps allows users to deploy models and functions in minutes, manage AI workloads from a single control plane, integrate easily with tools like PyTorch and TensorFlow, and ensure security and compliance by design. The platform supports hybrid and multi-cloud workload orchestration, rapid adaptive scaling, and modular applications with unique workflow management system.

Mystic.ai
Mystic.ai is an AI tool designed to deploy and scale Machine Learning models with ease. It offers a fully managed Kubernetes platform that runs in your own cloud, allowing users to deploy ML models in their own Azure/AWS/GCP account or in a shared GPU cluster. Mystic.ai provides cost optimizations, fast inference, simpler developer experience, and performance optimizations to ensure high-performance AI model serving. With features like pay-as-you-go API, cloud integration with AWS/Azure/GCP, and a beautiful dashboard, Mystic.ai simplifies the deployment and management of ML models for data scientists and AI engineers.
Arthur
Arthur is an industry-leading MLOps platform that simplifies deployment, monitoring, and management of traditional and generative AI models. It ensures scalability, security, compliance, and efficient enterprise use. Arthur's turnkey solutions enable companies to integrate the latest generative AI technologies into their operations, making informed, data-driven decisions. The platform offers open-source evaluation products, model-agnostic monitoring, deployment with leading data science tools, and model risk management capabilities. It emphasizes collaboration, security, and compliance with industry standards.
Striveworks
Striveworks is an AI application that offers a Machine Learning Operations Platform designed to help organizations build, deploy, maintain, monitor, and audit machine learning models efficiently. It provides features such as rapid model deployment, data and model auditability, low-code interface, flexible deployment options, and operationalizing AI data science with real returns. Striveworks aims to accelerate the ML lifecycle, save time and money in model creation, and enable non-experts to leverage AI for data-driven decisions.
HostAI
HostAI is a platform that allows users to host their artificial intelligence models and applications with ease. It provides a user-friendly interface for managing and deploying AI projects, eliminating the need for complex server setups. With HostAI, users can seamlessly run their AI algorithms and applications in a secure and efficient environment. The platform supports various AI frameworks and libraries, making it versatile for different AI projects. HostAI simplifies the process of AI deployment, enabling users to focus on developing and improving their AI models.

Wallaroo.AI
Wallaroo.AI is an AI inference platform that offers production-grade AI inference microservices optimized on OpenVINO for cloud and Edge AI application deployments on CPUs and GPUs. It provides hassle-free AI inferencing for any model, any hardware, anywhere, with ultrafast turnkey inference microservices. The platform enables users to deploy, manage, observe, and scale AI models effortlessly, reducing deployment costs and time-to-value significantly.
JFrog ML
JFrog ML is an AI platform designed to streamline AI development from prototype to production. It offers a unified MLOps platform to build, train, deploy, and manage AI workflows at scale. With features like Feature Store, LLMOps, and model monitoring, JFrog ML empowers AI teams to collaborate efficiently and optimize AI & ML models in production.
SentiSight.ai
SentiSight.ai is a machine learning platform for image recognition solutions, offering services such as object detection, image segmentation, image classification, image similarity search, image annotation, computer vision consulting, and intelligent automation consulting. Users can access pre-trained models, background removal, NSFW detection, text recognition, and image recognition API. The platform provides tools for image labeling, project management, and training tutorials for various image recognition models. SentiSight.ai aims to streamline the image annotation process, empower users to build and train their own models, and deploy them for online or offline use.
Groq
Groq is a fast AI inference tool that offers GroqCloud™ Platform and GroqRack™ Cluster for developers to build and deploy AI models with ultra-low-latency inference. It provides instant intelligence for openly-available models like Llama 3.1 and is known for its speed and compatibility with other AI providers. Groq powers leading openly-available AI models and has gained recognition in the AI chip industry. The tool has received significant funding and valuation, positioning itself as a strong challenger to established players like Nvidia.
Unsloth
Unsloth is an AI tool designed to make finetuning large language models like Llama-3, Mistral, Phi-3, and Gemma 2x faster, use 70% less memory, and with no degradation in accuracy. The tool provides documentation to help users navigate through training their custom models, covering essentials such as installing and updating Unsloth, creating datasets, running, and deploying models. Users can also integrate third-party tools and utilize platforms like Google Colab.
Qualcomm AI Hub
Qualcomm AI Hub is a platform that allows users to run AI models on Snapdragon® 8 Elite devices. It provides a collaborative ecosystem for model makers, cloud providers, runtime, and SDK partners to deploy on-device AI solutions quickly and efficiently. Users can bring their own models, optimize for deployment, and access a variety of AI services and resources. The platform caters to various industries such as mobile, automotive, and IoT, offering a range of models and services for edge computing.
NetMind
NetMind is an AI tool that offers a Model Library, Enterprise AI Solutions, and AI Consulting services. It provides cutting-edge inference capabilities, model APIs for various data types, and GPU clusters for accelerated performance. The platform allows rapid deployment of models with flexible scaling options. NetMind caters to a wide range of industries, offering solutions that enhance accuracy, cut costs, and accelerate decision-making processes.

Lambda Docs
Lambda Docs is an AI tool that provides cloud and hardware solutions for individuals, teams, and organizations. It offers services such as Managed Kubernetes, Preinstalled Kubernetes, Slurm, and access to GPU clusters. The platform also provides educational resources and tutorials for machine learning engineers and researchers to fine-tune models and deploy AI solutions.
147 - Open Source AI Tools

ai-on-gke
This repository contains assets related to AI/ML workloads on Google Kubernetes Engine (GKE). Run optimized AI/ML workloads with Google Kubernetes Engine (GKE) platform orchestration capabilities. A robust AI/ML platform considers the following layers: Infrastructure orchestration that support GPUs and TPUs for training and serving workloads at scale Flexible integration with distributed computing and data processing frameworks Support for multiple teams on the same infrastructure to maximize utilization of resources

ray
Ray is a unified framework for scaling AI and Python applications. It consists of a core distributed runtime and a set of AI libraries for simplifying ML compute, including Data, Train, Tune, RLlib, and Serve. Ray runs on any machine, cluster, cloud provider, and Kubernetes, and features a growing ecosystem of community integrations. With Ray, you can seamlessly scale the same code from a laptop to a cluster, making it easy to meet the compute-intensive demands of modern ML workloads.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.

djl
Deep Java Library (DJL) is an open-source, high-level, engine-agnostic Java framework for deep learning. It is designed to be easy to get started with and simple to use for Java developers. DJL provides a native Java development experience and allows users to integrate machine learning and deep learning models with their Java applications. The framework is deep learning engine agnostic, enabling users to switch engines at any point for optimal performance. DJL's ergonomic API interface guides users with best practices to accomplish deep learning tasks, such as running inference and training neural networks.

mlflow
MLflow is a platform to streamline machine learning development, including tracking experiments, packaging code into reproducible runs, and sharing and deploying models. MLflow offers a set of lightweight APIs that can be used with any existing machine learning application or library (TensorFlow, PyTorch, XGBoost, etc), wherever you currently run ML code (e.g. in notebooks, standalone applications or the cloud). MLflow's current components are:
* `MLflow Tracking

tt-metal
TT-NN is a python & C++ Neural Network OP library. It provides a low-level programming model, TT-Metalium, enabling kernel development for Tenstorrent hardware.

burn
Burn is a new comprehensive dynamic Deep Learning Framework built using Rust with extreme flexibility, compute efficiency and portability as its primary goals.

awsome-distributed-training
This repository contains reference architectures and test cases for distributed model training with Amazon SageMaker Hyperpod, AWS ParallelCluster, AWS Batch, and Amazon EKS. The test cases cover different types and sizes of models as well as different frameworks and parallel optimizations (Pytorch DDP/FSDP, MegatronLM, NemoMegatron...).

jetson-generative-ai-playground
This repo hosts tutorial documentation for running generative AI models on NVIDIA Jetson devices. The documentation is auto-generated and hosted on GitHub Pages using their CI/CD feature to automatically generate/update the HTML documentation site upon new commits.
vertex-ai-samples
The Google Cloud Vertex AI sample repository contains notebooks and community content that demonstrate how to develop and manage ML workflows using Google Cloud Vertex AI.

python-aiplatform
The Vertex AI SDK for Python is a library that provides a convenient way to use the Vertex AI API. It offers a high-level interface for creating and managing Vertex AI resources, such as datasets, models, and endpoints. The SDK also provides support for training and deploying custom models, as well as using AutoML models. With the Vertex AI SDK for Python, you can quickly and easily build and deploy machine learning models on Vertex AI.

model_server
OpenVINO™ Model Server (OVMS) is a high-performance system for serving models. Implemented in C++ for scalability and optimized for deployment on Intel architectures, the model server uses the same architecture and API as TensorFlow Serving and KServe while applying OpenVINO for inference execution. Inference service is provided via gRPC or REST API, making deploying new algorithms and AI experiments easy.

byteir
The ByteIR Project is a ByteDance model compilation solution. ByteIR includes compiler, runtime, and frontends, and provides an end-to-end model compilation solution. Although all ByteIR components (compiler/runtime/frontends) are together to provide an end-to-end solution, and all under the same umbrella of this repository, each component technically can perform independently. The name, ByteIR, comes from a legacy purpose internally. The ByteIR project is NOT an IR spec definition project. Instead, in most scenarios, ByteIR directly uses several upstream MLIR dialects and Google Mhlo. Most of ByteIR compiler passes are compatible with the selected upstream MLIR dialects and Google Mhlo.

zenml
ZenML is an extensible, open-source MLOps framework for creating portable, production-ready machine learning pipelines. By decoupling infrastructure from code, ZenML enables developers across your organization to collaborate more effectively as they develop to production.

flower
Flower is a framework for building federated learning systems. It is designed to be customizable, extensible, framework-agnostic, and understandable. Flower can be used with any machine learning framework, for example, PyTorch, TensorFlow, Hugging Face Transformers, PyTorch Lightning, scikit-learn, JAX, TFLite, MONAI, fastai, MLX, XGBoost, Pandas for federated analytics, or even raw NumPy for users who enjoy computing gradients by hand.

kitops
KitOps is a packaging and versioning system for AI/ML projects that uses open standards so it works with the AI/ML, development, and DevOps tools you are already using. KitOps simplifies the handoffs between data scientists, application developers, and SREs working with LLMs and other AI/ML models. KitOps' ModelKits are a standards-based package for models, their dependencies, configurations, and codebases. ModelKits are portable, reproducible, and work with the tools you already use.

supervisely
Supervisely is a computer vision platform that provides a range of tools and services for developing and deploying computer vision solutions. It includes a data labeling platform, a model training platform, and a marketplace for computer vision apps. Supervisely is used by a variety of organizations, including Fortune 500 companies, research institutions, and government agencies.
truss-examples
Truss is the simplest way to serve AI/ML models in production. This repository provides dozens of example models, each ready to deploy as-is or adapt to your needs. To get started, clone the repository, install Truss, and pick a model to deploy by passing a path to that model. Truss will prompt you for an API Key, which can be obtained from the Baseten API keys page. Invocation depends on the model's input and output specifications. Refer to individual model READMEs for invocation details. Contributions of new models and improvements to existing models are welcome. See CONTRIBUTING.md for details.
thinc
Thinc is a lightweight deep learning library that offers an elegant, type-checked, functional-programming API for composing models, with support for layers defined in other frameworks such as PyTorch, TensorFlow and MXNet. You can use Thinc as an interface layer, a standalone toolkit or a flexible way to develop new models.

hqq
HQQ is a fast and accurate model quantizer that skips the need for calibration data. It's super simple to implement (just a few lines of code for the optimizer). It can crunch through quantizing the Llama2-70B model in only 4 minutes! 🚀

LLM-And-More
LLM-And-More is a one-stop solution for training and applying large models, covering the entire process from data processing to model evaluation, from training to deployment, and from idea to service. In this project, users can easily train models through this project and generate the required product services with one click.
MoonshotAI-Cookbook
The MoonshotAI-Cookbook provides example code and guides for accomplishing common tasks with the MoonshotAI API. To run these examples, you'll need an MoonshotAI account and associated API key. Most code examples are written in Python, though the concepts can be applied in any language.

inference
Xorbits Inference (Xinference) is a powerful and versatile library designed to serve language, speech recognition, and multimodal models. With Xorbits Inference, you can effortlessly deploy and serve your or state-of-the-art built-in models using just a single command. Whether you are a researcher, developer, or data scientist, Xorbits Inference empowers you to unleash the full potential of cutting-edge AI models.
effort
Effort is an example implementation of the bucketMul algorithm, which allows for real-time adjustment of the number of calculations performed during inference of an LLM model. At 50% effort, it performs as fast as regular matrix multiplications on Apple Silicon chips; at 25% effort, it is twice as fast while still retaining most of the quality. Additionally, users have the option to skip loading the least important weights.

mscclpp
MSCCL++ is a GPU-driven communication stack for scalable AI applications. It provides a highly efficient and customizable communication stack for distributed GPU applications. MSCCL++ redefines inter-GPU communication interfaces, delivering a highly efficient and customizable communication stack for distributed GPU applications. Its design is specifically tailored to accommodate diverse performance optimization scenarios often encountered in state-of-the-art AI applications. MSCCL++ provides communication abstractions at the lowest level close to hardware and at the highest level close to application API. The lowest level of abstraction is ultra light weight which enables a user to implement logics of data movement for a collective operation such as AllReduce inside a GPU kernel extremely efficiently without worrying about memory ordering of different ops. The modularity of MSCCL++ enables a user to construct the building blocks of MSCCL++ in a high level abstraction in Python and feed them to a CUDA kernel in order to facilitate the user's productivity. MSCCL++ provides fine-grained synchronous and asynchronous 0-copy 1-sided abstracts for communication primitives such as `put()`, `get()`, `signal()`, `flush()`, and `wait()`. The 1-sided abstractions allows a user to asynchronously `put()` their data on the remote GPU as soon as it is ready without requiring the remote side to issue any receive instruction. This enables users to easily implement flexible communication logics, such as overlapping communication with computation, or implementing customized collective communication algorithms without worrying about potential deadlocks. Additionally, the 0-copy capability enables MSCCL++ to directly transfer data between user's buffers without using intermediate internal buffers which saves GPU bandwidth and memory capacity. MSCCL++ provides consistent abstractions regardless of the location of the remote GPU (either on the local node or on a remote node) or the underlying link (either NVLink/xGMI or InfiniBand). This simplifies the code for inter-GPU communication, which is often complex due to memory ordering of GPU/CPU read/writes and therefore, is error-prone.
AI-Horde
The AI Horde is an enterprise-level ML-Ops crowdsourced distributed inference cluster for AI Models. This middleware can support both Image and Text generation. It is infinitely scalable and supports seamless drop-in/drop-out of compute resources. The Public version allows people without a powerful GPU to use Stable Diffusion or Large Language Models like Pygmalion/Llama by relying on spare/idle resources provided by the community and also allows non-python clients, such as games and apps, to use AI-provided generations.

clearml
ClearML is a suite of tools designed to streamline the machine learning workflow. It includes an experiment manager, MLOps/LLMOps, data management, and model serving capabilities. ClearML is open-source and offers a free tier hosting option. It supports various ML/DL frameworks and integrates with Jupyter Notebook and PyCharm. ClearML provides extensive logging capabilities, including source control info, execution environment, hyper-parameters, and experiment outputs. It also offers automation features, such as remote job execution and pipeline creation. ClearML is designed to be easy to integrate, requiring only two lines of code to add to existing scripts. It aims to improve collaboration, visibility, and data transparency within ML teams.

BitMat
BitMat is a Python package designed to optimize matrix multiplication operations by utilizing custom kernels written in Triton. It leverages the principles outlined in the "1bit-LLM Era" paper, specifically utilizing packed int8 data to enhance computational efficiency and performance in deep learning and numerical computing tasks.

pytorch-lightning
PyTorch Lightning is a framework for training and deploying AI models. It provides a high-level API that abstracts away the low-level details of PyTorch, making it easier to write and maintain complex models. Lightning also includes a number of features that make it easy to train and deploy models on multiple GPUs or TPUs, and to track and visualize training progress. PyTorch Lightning is used by a wide range of organizations, including Google, Facebook, and Microsoft. It is also used by researchers at top universities around the world. Here are some of the benefits of using PyTorch Lightning: * **Increased productivity:** Lightning's high-level API makes it easy to write and maintain complex models. This can save you time and effort, and allow you to focus on the research or business problem you're trying to solve. * **Improved performance:** Lightning's optimized training loops and data loading pipelines can help you train models faster and with better performance. * **Easier deployment:** Lightning makes it easy to deploy models to a variety of platforms, including the cloud, on-premises servers, and mobile devices. * **Better reproducibility:** Lightning's logging and visualization tools make it easy to track and reproduce training results.
truss
Truss is a tool that simplifies the process of serving AI/ML models in production. It provides a consistent and easy-to-use interface for packaging, testing, and deploying models, regardless of the framework they were created with. Truss also includes a live reload server for fast feedback during development, and a batteries-included model serving environment that eliminates the need for Docker and Kubernetes configuration.

caikit
Caikit is an AI toolkit that enables users to manage models through a set of developer friendly APIs. It provides a consistent format for creating and using AI models against a wide variety of data domains and tasks.

helix
HelixML is a private GenAI platform that allows users to deploy the best of open AI in their own data center or VPC while retaining complete data security and control. It includes support for fine-tuning models with drag-and-drop functionality. HelixML brings the best of open source AI to businesses in an ergonomic and scalable way, optimizing the tradeoff between GPU memory and latency.
google-research
This repository contains code released by Google Research. All datasets in this repository are released under the CC BY 4.0 International license, which can be found here: https://creativecommons.org/licenses/by/4.0/legalcode. All source files in this repository are released under the Apache 2.0 license, the text of which can be found in the LICENSE file.
ai_all_resources
This repository is a compilation of excellent ML and DL tutorials created by various individuals and organizations. It covers a wide range of topics, including machine learning fundamentals, deep learning, computer vision, natural language processing, reinforcement learning, and more. The resources are organized into categories, making it easy to find the information you need. Whether you're a beginner or an experienced practitioner, you're sure to find something valuable in this repository.
FedML
FedML is a unified and scalable machine learning library for running training and deployment anywhere at any scale. It is highly integrated with FEDML Nexus AI, a next-gen cloud service for LLMs & Generative AI. FEDML Nexus AI provides holistic support of three interconnected AI infrastructure layers: user-friendly MLOps, a well-managed scheduler, and high-performance ML libraries for running any AI jobs across GPU Clouds.
cloudberrydb
Cloudberry Database (CBDB or CloudberryDB) is a next-generation unified database for analytics and AI. It is created by a bunch of original Greenplum Database developers and ASF committers. Cloudberry Database aims to bring modern computing capabilities to the traditional distributed MPP database to support Analytics and AI/ML workloads in one platform.
cookbook
This repository contains community-driven practical examples of building AI applications and solving various tasks with AI using open-source tools and models. Everyone is welcome to contribute, and we value everybody's contribution! There are several ways you can contribute to the Open-Source AI Cookbook: Submit an idea for a desired example/guide via GitHub Issues. Contribute a new notebook with a practical example. Improve existing examples by fixing issues/typos. Before contributing, check currently open issues and pull requests to avoid working on something that someone else is already working on.
ai_wiki
This repository provides a comprehensive collection of resources, open-source tools, and knowledge related to quantitative analysis. It serves as a valuable knowledge base and navigation guide for individuals interested in various aspects of quantitative investing, including platforms, programming languages, mathematical foundations, machine learning, deep learning, and practical applications. The repository is well-structured and organized, with clear sections covering different topics. It includes resources on system platforms, programming codes, mathematical foundations, algorithm principles, machine learning, deep learning, reinforcement learning, graph networks, model deployment, and practical applications. Additionally, there are dedicated sections on quantitative trading and investment, as well as large models. The repository is actively maintained and updated, ensuring that users have access to the latest information and resources.
ort
Ort is an unofficial ONNX Runtime 1.17 wrapper for Rust based on the now inactive onnxruntime-rs. ONNX Runtime accelerates ML inference on both CPU and GPU.

cyclops
Cyclops is a toolkit for facilitating research and deployment of ML models for healthcare. It provides a few high-level APIs namely: data - Create datasets for training, inference and evaluation. We use the popular 🤗 datasets to efficiently load and slice different modalities of data models - Use common model implementations using scikit-learn and PyTorch tasks - Use common ML task formulations such as binary classification or multi-label classification on tabular, time-series and image data evaluate - Evaluate models on clinical prediction tasks monitor - Detect dataset shift relevant for clinical use cases report - Create model report cards for clinical ML models
applied-ai-engineering-samples
The Google Cloud Applied AI Engineering repository provides reference guides, blueprints, code samples, and hands-on labs developed by the Google Cloud Applied AI Engineering team. It contains resources for Generative AI on Vertex AI, including code samples and hands-on labs demonstrating the use of Generative AI models and tools in Vertex AI. Additionally, it offers reference guides and blueprints that compile best practices and prescriptive guidance for running large-scale AI/ML workloads on Google Cloud AI/ML infrastructure.
awesome-ruby-ai
Awesome Ruby AI is a curated list of awesome AI projects built in Ruby. It includes open source API libraries, vector database clients, bot platforms, composability frameworks, and i18n tools. These tools can be used for a variety of tasks, such as natural language processing, computer vision, and machine learning.
vertex-ai-mlops
Vertex AI is a platform for end-to-end model development. It consist of core components that make the processes of MLOps possible for design patterns of all types.
modern_ai_for_beginners
This repository provides a comprehensive guide to modern AI for beginners, covering both theoretical foundations and practical implementation. It emphasizes the importance of understanding both the mathematical principles and the code implementation of AI models. The repository includes resources on PyTorch, deep learning fundamentals, mathematical foundations, transformer-based LLMs, diffusion models, software engineering, and full-stack development. It also features tutorials on natural language processing with transformers, reinforcement learning, and practical deep learning for coders.

MathCoder
MathCoder is a repository focused on enhancing mathematical reasoning by fine-tuning open-source language models to use code for modeling and deriving math equations. It introduces MathCodeInstruct dataset with solutions interleaving natural language, code, and execution results. The repository provides MathCoder models capable of generating code-based solutions for challenging math problems, achieving state-of-the-art scores on MATH and GSM8K datasets. It offers tools for model deployment, inference, and evaluation, along with a citation for referencing the work.
Chinese-LLaMA-Alpaca-3
Chinese-LLaMA-Alpaca-3 is a project based on Meta's latest release of the new generation open-source large model Llama-3. It is the third phase of the Chinese-LLaMA-Alpaca open-source large model series projects (Phase 1, Phase 2). This project open-sources the Chinese Llama-3 base model and the Chinese Llama-3-Instruct instruction fine-tuned large model. These models incrementally pre-train with a large amount of Chinese data on the basis of the original Llama-3 and further fine-tune using selected instruction data, enhancing Chinese basic semantics and instruction understanding capabilities. Compared to the second-generation related models, significant performance improvements have been achieved.

aiges
AIGES is a core component of the Athena Serving Framework, designed as a universal encapsulation tool for AI developers to deploy AI algorithm models and engines quickly. By integrating AIGES, you can deploy AI algorithm models and engines rapidly and host them on the Athena Serving Framework, utilizing supporting auxiliary systems for networking, distribution strategies, data processing, etc. The Athena Serving Framework aims to accelerate the cloud service of AI algorithm models and engines, providing multiple guarantees for cloud service stability through cloud-native architecture. You can efficiently and securely deploy, upgrade, scale, operate, and monitor models and engines without focusing on underlying infrastructure and service-related development, governance, and operations.

infinity
Infinity is a high-throughput, low-latency REST API for serving vector embeddings, supporting all sentence-transformer models and frameworks. It is developed under the MIT License and powers inference behind Gradient.ai. The API allows users to deploy models from SentenceTransformers, offers fast inference backends utilizing various accelerators, dynamic batching for efficient processing, correct and tested implementation, and easy-to-use API built on FastAPI with Swagger documentation. Users can embed text, rerank documents, and perform text classification tasks using the tool. Infinity supports various models from Huggingface and provides flexibility in deployment via CLI, Docker, Python API, and cloud services like dstack. The tool is suitable for tasks like embedding, reranking, and text classification.
awesome-local-llms
The 'awesome-local-llms' repository is a curated list of open-source tools for local Large Language Model (LLM) inference, covering both proprietary and open weights LLMs. The repository categorizes these tools into LLM inference backend engines, LLM front end UIs, and all-in-one desktop applications. It collects GitHub repository metrics as proxies for popularity and active maintenance. Contributions are encouraged, and users can suggest additional open-source repositories through the Issues section or by running a provided script to update the README and make a pull request. The repository aims to provide a comprehensive resource for exploring and utilizing local LLM tools.
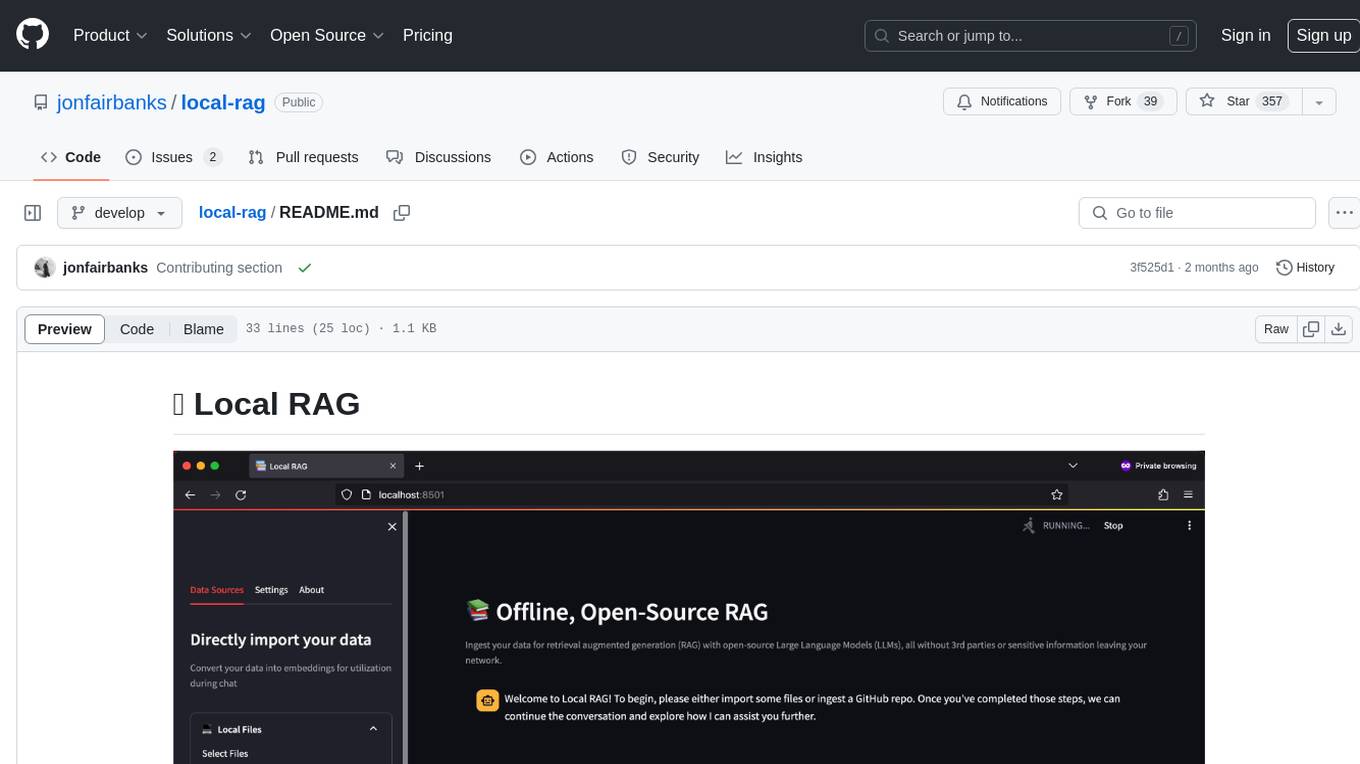
local-rag
Local RAG is an offline, open-source tool that allows users to ingest files for retrieval augmented generation (RAG) using large language models (LLMs) without relying on third parties or exposing sensitive data. It supports offline embeddings and LLMs, multiple sources including local files, GitHub repos, and websites, streaming responses, conversational memory, and chat export. Users can set up and deploy the app, learn how to use Local RAG, explore the RAG pipeline, check planned features, known bugs and issues, access additional resources, and contribute to the project.

oreilly-hands-on-gpt-llm
This repository contains code for the O'Reilly Live Online Training for Deploying GPT & LLMs. Learn how to use GPT-4, ChatGPT, OpenAI embeddings, and other large language models to build applications for experimenting and production. Gain practical experience in building applications like text generation, summarization, question answering, and more. Explore alternative generative models such as Cohere and GPT-J. Understand prompt engineering, context stuffing, and few-shot learning to maximize the potential of GPT-like models. Focus on deploying models in production with best practices and debugging techniques. By the end of the training, you will have the skills to start building applications with GPT and other large language models.

OpenLLM
OpenLLM is a platform that helps developers run any open-source Large Language Models (LLMs) as OpenAI-compatible API endpoints, locally and in the cloud. It supports a wide range of LLMs, provides state-of-the-art serving and inference performance, and simplifies cloud deployment via BentoML. Users can fine-tune, serve, deploy, and monitor any LLMs with ease using OpenLLM. The platform also supports various quantization techniques, serving fine-tuning layers, and multiple runtime implementations. OpenLLM seamlessly integrates with other tools like OpenAI Compatible Endpoints, LlamaIndex, LangChain, and Transformers Agents. It offers deployment options through Docker containers, BentoCloud, and provides a community for collaboration and contributions.
worker-vllm
The worker-vLLM repository provides a serverless endpoint for deploying OpenAI-compatible vLLM models with blazing-fast performance. It supports deploying various model architectures, such as Aquila, Baichuan, BLOOM, ChatGLM, Command-R, DBRX, DeciLM, Falcon, Gemma, GPT-2, GPT BigCode, GPT-J, GPT-NeoX, InternLM, Jais, LLaMA, MiniCPM, Mistral, Mixtral, MPT, OLMo, OPT, Orion, Phi, Phi-3, Qwen, Qwen2, Qwen2MoE, StableLM, Starcoder2, Xverse, and Yi. Users can deploy models using pre-built Docker images or build custom images with specified arguments. The repository also supports OpenAI compatibility for chat completions, completions, and models, with customizable input parameters. Users can modify their OpenAI codebase to use the deployed vLLM worker and access a list of available models for deployment.
dive-into-llms
The 'Dive into Large Language Models' series programming practice tutorial is an extension of the 'Artificial Intelligence Security Technology' course lecture notes from Shanghai Jiao Tong University (Instructor: Zhang Zhuosheng). It aims to provide introductory programming references related to large models. Through simple practice, it helps students quickly grasp large models, better engage in course design, or academic research. The tutorial covers topics such as fine-tuning and deployment, prompt learning and thought chains, knowledge editing, model watermarking, jailbreak attacks, multimodal models, large model intelligent agents, and security. Disclaimer: The content is based on contributors' personal experiences, internet data, and accumulated research work, provided for reference only.
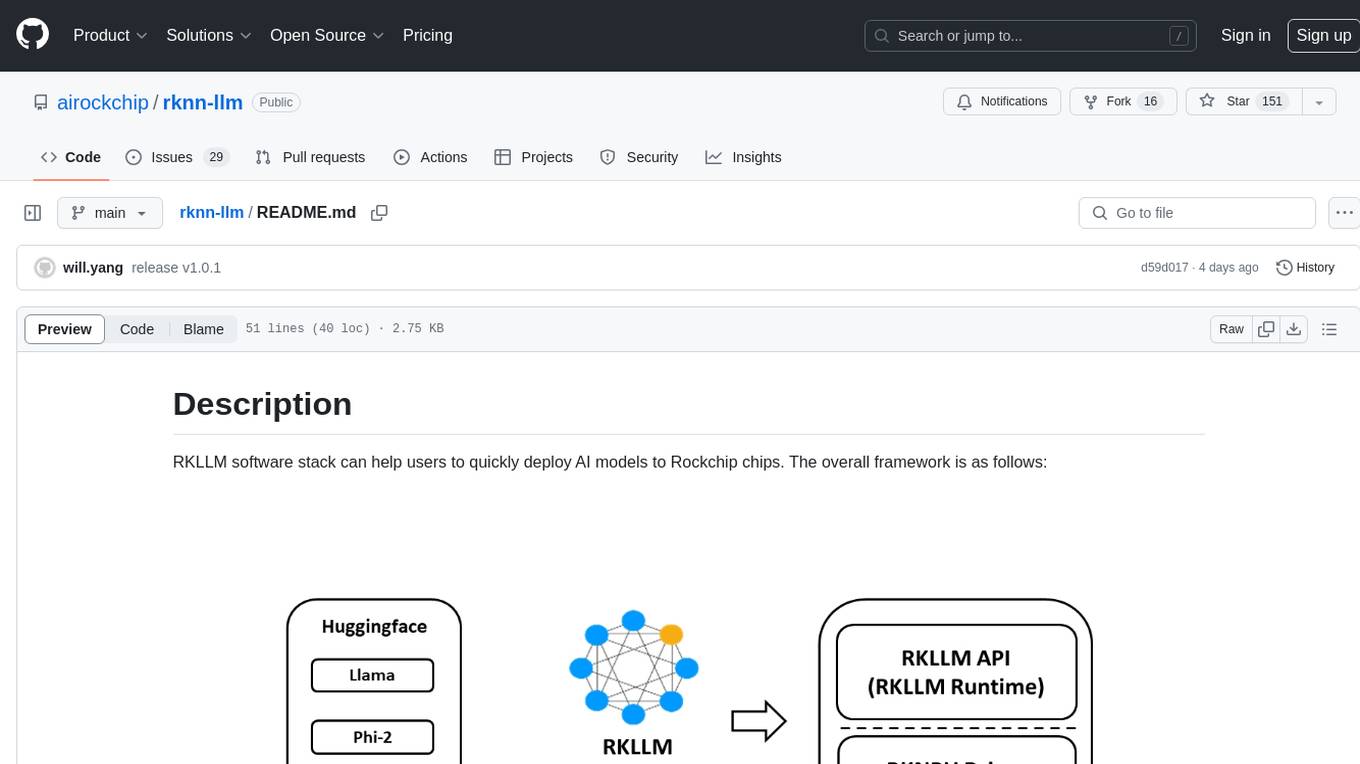
rknn-llm
RKLLM software stack is a toolkit designed to help users quickly deploy AI models to Rockchip chips. It consists of RKLLM-Toolkit for model conversion and quantization, RKLLM Runtime for deploying models on Rockchip NPU platform, and RKNPU kernel driver for hardware interaction. The toolkit supports RK3588 and RK3576 series chips and various models like TinyLLAMA, Qwen, Phi, ChatGLM3, Gemma, InternLM2, and MiniCPM. Users can download packages, docker images, examples, and docs from RKLLM_SDK. Additionally, RKNN-Toolkit2 SDK is available for deploying additional AI models.
ai-accelerators
DataRobot AI Accelerators are code-first workflows to speed up model development, deployment, and time to value using the DataRobot API. The accelerators include approaches for specific business challenges, generative AI, ecosystem integration templates, and advanced ML and API usage. Users can clone the repo, import desired accelerators into notebooks, execute them, learn and modify content to solve their own problems.

LitServe
LitServe is a high-throughput serving engine designed for deploying AI models at scale. It generates an API endpoint for models, handles batching, streaming, and autoscaling across CPU/GPUs. LitServe is built for enterprise scale with a focus on minimal, hackable code-base without bloat. It supports various model types like LLMs, vision, time-series, and works with frameworks like PyTorch, JAX, Tensorflow, and more. The tool allows users to focus on model performance rather than serving boilerplate, providing full control and flexibility.

ai-edge-torch
AI Edge Torch is a Python library that supports converting PyTorch models into a .tflite format for on-device applications on Android, iOS, and IoT devices. It offers broad CPU coverage with initial GPU and NPU support, closely integrating with PyTorch and providing good coverage of Core ATen operators. The library includes a PyTorch converter for model conversion and a Generative API for authoring mobile-optimized PyTorch Transformer models, enabling easy deployment of Large Language Models (LLMs) on mobile devices.

onnxruntime-server
ONNX Runtime Server is a server that provides TCP and HTTP/HTTPS REST APIs for ONNX inference. It aims to offer simple, high-performance ML inference and a good developer experience. Users can provide inference APIs for ONNX models without writing additional code by placing the models in the directory structure. Each session can choose between CPU or CUDA, analyze input/output, and provide Swagger API documentation for easy testing. Ready-to-run Docker images are available, making it convenient to deploy the server.

awesome-RK3588
RK3588 is a flagship 8K SoC chip by Rockchip, integrating Cortex-A76 and Cortex-A55 cores with NEON coprocessor for 8K video codec. This repository curates resources for developing with RK3588, including official resources, RKNN models, projects, development boards, documentation, tools, and sample code.
vscode-ai-toolkit
AI Toolkit for Visual Studio Code simplifies generative AI app development by bringing together cutting-edge AI development tools and models from Azure AI Studio Catalog and other catalogs like Hugging Face. Users can browse the AI models catalog, download them locally, fine-tune, test, and deploy them to the cloud. The toolkit offers actions such as finding supported models, testing model inference, fine-tuning models locally or remotely, and deploying fine-tuned models to the cloud. It also provides optimized AI models for Windows and a Q&A section for common issues and resolutions.
langdrive
LangDrive is an open-source AI library that simplifies training, deploying, and querying open-source large language models (LLMs) using private data. It supports data ingestion, fine-tuning, and deployment via a command-line interface, YAML file, or API, with a quick, easy setup. Users can build AI applications such as question/answering systems, chatbots, AI agents, and content generators. The library provides features like data connectors for ingestion, fine-tuning of LLMs, deployment to Hugging Face hub, inference querying, data utilities for CRUD operations, and APIs for model access. LangDrive is designed to streamline the process of working with LLMs and making AI development more accessible.

starwhale
Starwhale is an MLOps/LLMOps platform that brings efficiency and standardization to machine learning operations. It streamlines the model development lifecycle, enabling teams to optimize workflows around key areas like model building, evaluation, release, and fine-tuning. Starwhale abstracts Model, Runtime, and Dataset as first-class citizens, providing tailored capabilities for common workflow scenarios including Models Evaluation, Live Demo, and LLM Fine-tuning. It is an open-source platform designed for clarity and ease of use, empowering developers to build customized MLOps features tailored to their needs.

InternLM
InternLM is a powerful language model series with features such as 200K context window for long-context tasks, outstanding comprehensive performance in reasoning, math, code, chat experience, instruction following, and creative writing, code interpreter & data analysis capabilities, and stronger tool utilization capabilities. It offers models in sizes of 7B and 20B, suitable for research and complex scenarios. The models are recommended for various applications and exhibit better performance than previous generations. InternLM models may match or surpass other open-source models like ChatGPT. The tool has been evaluated on various datasets and has shown superior performance in multiple tasks. It requires Python >= 3.8, PyTorch >= 1.12.0, and Transformers >= 4.34 for usage. InternLM can be used for tasks like chat, agent applications, fine-tuning, deployment, and long-context inference.

TensorRT-Model-Optimizer
The NVIDIA TensorRT Model Optimizer is a library designed to quantize and compress deep learning models for optimized inference on GPUs. It offers state-of-the-art model optimization techniques including quantization and sparsity to reduce inference costs for generative AI models. Users can easily stack different optimization techniques to produce quantized checkpoints from torch or ONNX models. The quantized checkpoints are ready for deployment in inference frameworks like TensorRT-LLM or TensorRT, with planned integrations for NVIDIA NeMo and Megatron-LM. The tool also supports 8-bit quantization with Stable Diffusion for enterprise users on NVIDIA NIM. Model Optimizer is available for free on NVIDIA PyPI, and this repository serves as a platform for sharing examples, GPU-optimized recipes, and collecting community feedback.
oci-data-science-ai-samples
The Oracle Cloud Infrastructure Data Science and AI services Examples repository provides demos, tutorials, and code examples showcasing various features of the OCI Data Science service and AI services. It offers tools for data scientists to develop and deploy machine learning models efficiently, with features like Accelerated Data Science SDK, distributed training, batch processing, and machine learning pipelines. Whether you're a beginner or an experienced practitioner, OCI Data Science Services provide the resources needed to build, train, and deploy models easily.

max
The Modular Accelerated Xecution (MAX) platform is an integrated suite of AI libraries, tools, and technologies that unifies commonly fragmented AI deployment workflows. MAX accelerates time to market for the latest innovations by giving AI developers a single toolchain that unlocks full programmability, unparalleled performance, and seamless hardware portability.
ai-on-openshift
AI on OpenShift is a site providing installation recipes, patterns, and demos for AI/ML tools and applications used in Data Science and Data Engineering projects running on OpenShift. It serves as a comprehensive resource for developers looking to deploy AI solutions on the OpenShift platform.

LLM-TPU
LLM-TPU project aims to deploy various open-source generative AI models on the BM1684X chip, with a focus on LLM. Models are converted to bmodel using TPU-MLIR compiler and deployed to PCIe or SoC environments using C++ code. The project has deployed various open-source models such as Baichuan2-7B, ChatGLM3-6B, CodeFuse-7B, DeepSeek-6.7B, Falcon-40B, Phi-3-mini-4k, Qwen-7B, Qwen-14B, Qwen-72B, Qwen1.5-0.5B, Qwen1.5-1.8B, Llama2-7B, Llama2-13B, LWM-Text-Chat, Mistral-7B-Instruct, Stable Diffusion, Stable Diffusion XL, WizardCoder-15B, Yi-6B-chat, Yi-34B-chat. Detailed model deployment information can be found in the 'models' subdirectory of the project. For demonstrations, users can follow the 'Quick Start' section. For inquiries about the chip, users can contact SOPHGO via the official website.
BentoDiffusion
BentoDiffusion is a BentoML example project that demonstrates how to serve and deploy diffusion models in the Stable Diffusion (SD) family. These models are specialized in generating and manipulating images based on text prompts. The project provides a guide on using SDXL Turbo as an example, along with instructions on prerequisites, installing dependencies, running the BentoML service, and deploying to BentoCloud. Users can interact with the deployed service using Swagger UI or other methods. Additionally, the project offers the option to choose from various diffusion models available in the repository for deployment.
LLM_Learning_Database
LLM Learning Database is a comprehensive repository dedicated to AI large models, offering a curated collection of resources covering fundamental knowledge, cutting-edge technologies, and practical applications. It includes guides, case studies, code examples for model training, optimization, and deployment, as well as insightful articles from industry experts and scholars. Whether you are a beginner or an experienced learner in the field of AI large models, this repository aims to support your learning journey and foster continuous growth and progress.
AMchat
AMchat is a large language model that integrates advanced math concepts, exercises, and solutions. The model is based on the InternLM2-Math-7B model and is specifically designed to answer advanced math problems. It provides a comprehensive dataset that combines Math and advanced math exercises and solutions. Users can download the model from ModelScope or OpenXLab, deploy it locally or using Docker, and even retrain it using XTuner for fine-tuning. The tool also supports LMDeploy for quantization, OpenCompass for evaluation, and various other features for model deployment and evaluation. The project contributors have provided detailed documentation and guides for users to utilize the tool effectively.

Step-DPO
Step-DPO is a method for enhancing long-chain reasoning ability of LLMs with a data construction pipeline creating a high-quality dataset. It significantly improves performance on math and GSM8K tasks with minimal data and training steps. The tool fine-tunes pre-trained models like Qwen2-7B-Instruct with Step-DPO, achieving superior results compared to other models. It provides scripts for training, evaluation, and deployment, along with examples and acknowledgements.
cgft-llm
The cgft-llm repository is a collection of video tutorials and documentation for implementing large models. It provides guidance on topics such as fine-tuning llama3 with llama-factory, lightweight deployment and quantization using llama.cpp, speech generation with ChatTTS, introduction to Ollama for large model deployment, deployment tools for vllm and paged attention, and implementing RAG with llama-index. Users can find detailed code documentation and video tutorials for each project in the repository.

biochatter
Generative AI models have shown tremendous usefulness in increasing accessibility and automation of a wide range of tasks. This repository contains the `biochatter` Python package, a generic backend library for the connection of biomedical applications to conversational AI. It aims to provide a common framework for deploying, testing, and evaluating diverse models and auxiliary technologies in the biomedical domain. BioChatter is part of the BioCypher ecosystem, connecting natively to BioCypher knowledge graphs.
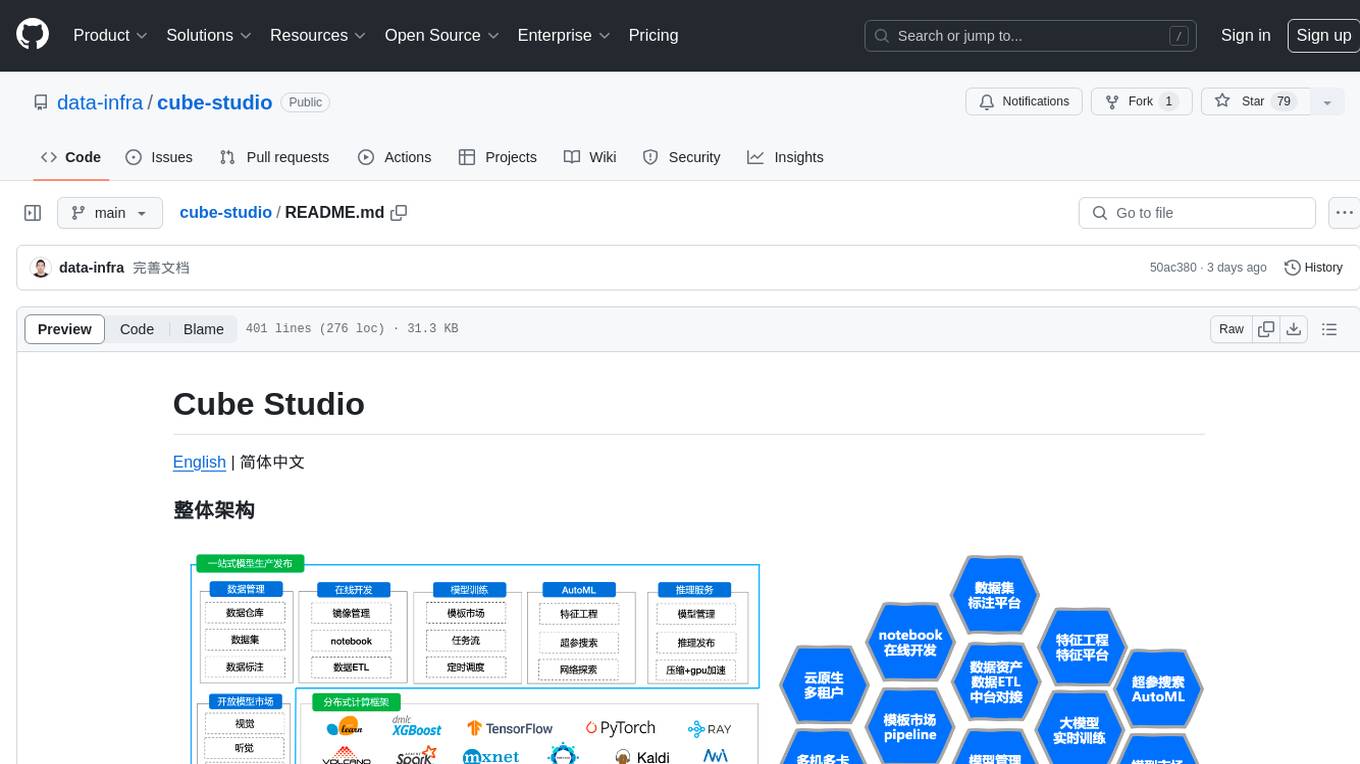
cube-studio
Cube Studio is an open-source all-in-one cloud-native machine learning platform that provides various functionalities such as project group management, network configuration, user management, role management, billing functions, SSO single sign-on, support for multiple computing power types, support for multiple resource groups and clusters, edge cluster support, serverless cluster mode support, database storage support, machine resource management, storage disk management, internationalization capabilities, data map management, data calculation, ETL orchestration, data set management, data annotation, image/audio/text dataset support, feature processing, traditional machine learning algorithms, distributed deep learning frameworks, distributed acceleration frameworks, model evaluation, model format conversion, model registration, model deployment, distributed media processing, custom operators, automatic learning, custom training images, automatic parameter tuning, TensorBoard jobs, internal services, model management, inference services, monitoring, model application management, model marketplace, model development, model fine-tuning, web model deployment, automated annotation, dataset SDK, notebook SDK, pipeline training SDK, inference service SDK, large model distributed training, large model inference, large model fine-tuning, intelligent conversation, private knowledge base, model deployment for WeChat public accounts, enterprise WeChat group chatbot integration, DingTalk group chatbot integration, and more. Cube Studio offers template-based functionality for data import/export, data processing, feature processing, machine learning frameworks, machine learning algorithms, deep learning frameworks, model processing, model serving, monitoring, and more.
NeMo-Framework-Launcher
The NeMo Framework Launcher is a cloud-native tool designed for launching end-to-end NeMo Framework training jobs. It focuses on foundation model training for generative AI models, supporting large language model pretraining with techniques like model parallelism, tensor, pipeline, sequence, distributed optimizer, mixed precision training, and more. The tool scales to thousands of GPUs and can be used for training LLMs on trillions of tokens. It simplifies launching training jobs on cloud service providers or on-prem clusters, generating submission scripts, organizing job results, and supporting various model operations like fine-tuning, evaluation, export, and deployment.
clearml-serving
ClearML Serving is a command line utility for model deployment and orchestration, enabling model deployment including serving and preprocessing code to a Kubernetes cluster or custom container based solution. It supports machine learning models like Scikit Learn, XGBoost, LightGBM, and deep learning models like TensorFlow, PyTorch, ONNX. It provides a customizable RestAPI for serving, online model deployment, scalable solutions, multi-model per container, automatic deployment, canary A/B deployment, model monitoring, usage metric reporting, metric dashboard, and model performance metrics. ClearML Serving is modular, scalable, flexible, customizable, and open source.

llm-on-ray
LLM-on-Ray is a comprehensive solution for building, customizing, and deploying Large Language Models (LLMs). It simplifies complex processes into manageable steps by leveraging the power of Ray for distributed computing. The tool supports pretraining, finetuning, and serving LLMs across various hardware setups, incorporating industry and Intel optimizations for performance. It offers modular workflows with intuitive configurations, robust fault tolerance, and scalability. Additionally, it provides an Interactive Web UI for enhanced usability, including a chatbot application for testing and refining models.

ServerlessLLM
ServerlessLLM is a fast, affordable, and easy-to-use library designed for multi-LLM serving, optimized for environments with limited GPU resources. It supports loading various leading LLM inference libraries, achieving fast load times, and reducing model switching overhead. The library facilitates easy deployment via Ray Cluster and Kubernetes, integrates with the OpenAI Query API, and is actively maintained by contributors.
awesome-ai-repositories
A curated list of open source repositories for AI Engineers. The repository provides a comprehensive collection of tools and frameworks for various AI-related tasks such as AI Gateway, AI Workload Manager, Copilot Development, Dataset Engineering, Evaluation, Fine Tuning, Function Calling, Graph RAG, Guardrails, Local Model Inference, LLM Agent Framework, Model Serving, Observability, Pre Training, Prompt Engineering, RAG Framework, Security, Structured Extraction, Structured Generation, Vector DB, and Voice Agent.
AI-Engineering.academy
AI Engineering Academy aims to provide a structured learning path for individuals looking to learn Applied AI effectively. The platform offers multiple roadmaps covering topics like Retrieval Augmented Generation, Fine-tuning, and Deployment. Each roadmap equips learners with the knowledge and skills needed to excel in applied GenAI. Additionally, the platform will feature Hands-on End-to-End AI projects in the future.
gpt_server
The GPT Server project leverages the basic capabilities of FastChat to provide the capabilities of an openai server. It perfectly adapts more models, optimizes models with poor compatibility in FastChat, and supports loading vllm, LMDeploy, and hf in various ways. It also supports all sentence_transformers compatible semantic vector models, including Chat templates with function roles, Function Calling (Tools) capability, and multi-modal large models. The project aims to reduce the difficulty of model adaptation and project usage, making it easier to deploy the latest models with minimal code changes.
fastapi
智元 Fast API is a one-stop API management system that unifies various LLM APIs in terms of format, standards, and management, achieving the ultimate in functionality, performance, and user experience. It supports various models from companies like OpenAI, Azure, Baidu, Keda Xunfei, Alibaba Cloud, Zhifu AI, Google, DeepSeek, 360 Brain, and Midjourney. The project provides user and admin portals for preview, supports cluster deployment, multi-site deployment, and cross-zone deployment. It also offers Docker deployment, a public API site for registration, and screenshots of the admin and user portals. The API interface is similar to OpenAI's interface, and the project is open source with repositories for API, web, admin, and SDK on GitHub and Gitee.
evalscope
Eval-Scope is a framework designed to support the evaluation of large language models (LLMs) by providing pre-configured benchmark datasets, common evaluation metrics, model integration, automatic evaluation for objective questions, complex task evaluation using expert models, reports generation, visualization tools, and model inference performance evaluation. It is lightweight, easy to customize, supports new dataset integration, model hosting on ModelScope, deployment of locally hosted models, and rich evaluation metrics. Eval-Scope also supports various evaluation modes like single mode, pairwise-baseline mode, and pairwise (all) mode, making it suitable for assessing and improving LLMs.
generative-ai-cdk-constructs-samples
This repository contains sample applications showcasing the use of AWS Generative AI CDK Constructs to build solutions for document exploration, content generation, image description, and deploying various models on SageMaker. It also includes samples for deploying Amazon Bedrock Agents and automating contract compliance analysis. The samples cover a range of backend and frontend technologies such as TypeScript, Python, and React.
FATE-LLM
FATE-LLM is a framework supporting federated learning for large and small language models. It promotes training efficiency of federated LLMs using Parameter-Efficient methods, protects the IP of LLMs using FedIPR, and ensures data privacy during training and inference through privacy-preserving mechanisms.

ms-swift
ms-swift is an official framework provided by the ModelScope community for fine-tuning and deploying large language models and multi-modal large models. It supports training, inference, evaluation, quantization, and deployment of over 400 large models and 100+ multi-modal large models. The framework includes various training technologies and accelerates inference, evaluation, and deployment modules. It offers a Gradio-based Web-UI interface and best practices for easy application of large models. ms-swift supports a wide range of model types, dataset types, hardware support, lightweight training methods, distributed training techniques, quantization training, RLHF training, multi-modal training, interface training, plugin and extension support, inference acceleration engines, model evaluation, and model quantization.

gradient-cli
Gradient CLI is a tool designed to facilitate the end-to-end MLOps process, allowing individuals and organizations to develop, train, and deploy Deep Learning models efficiently. It supports various ML/DL frameworks and provides features such as 1-click Jupyter Notebooks, scalable model training workflows, and model deployment as API endpoints. The tool can run on different infrastructures like AWS, GCP, on-premise, and Paperspace GPUs, offering automatic versioning, distributed training, hyperparameter search, and more.

slideflow
Slideflow is a deep learning library for digital pathology, offering a user-friendly interface for model development. It is designed for medical researchers and AI enthusiasts, providing an accessible platform for developing state-of-the-art pathology models. Slideflow offers customizable training pipelines, robust slide processing and stain normalization toolkit, support for weakly-supervised or strongly-supervised labels, built-in foundation models, multiple-instance learning, self-supervised learning, generative adversarial networks, explainability tools, layer activation analysis tools, uncertainty quantification, interactive user interface for model deployment, and more. It supports both PyTorch and Tensorflow, with optional support for Libvips for slide reading. Slideflow can be installed via pip, Docker container, or from source, and includes non-commercial add-ons for additional tools and pretrained models. It allows users to create projects, extract tiles from slides, train models, and provides evaluation tools like heatmaps and mosaic maps.
2021-13th-ironman
This repository is a part of the 13th iT Help Ironman competition, focusing on exploring explainable artificial intelligence (XAI) in machine learning and deep learning. The content covers the basics of XAI, its applications, cases, challenges, and future directions. It also includes practical machine learning algorithms, model deployment, and integration concepts. The author aims to provide detailed resources on AI and share knowledge with the audience through this competition.
ollama-operator
Ollama Operator is a Kubernetes operator designed to facilitate running large language models on Kubernetes clusters. It simplifies the process of deploying and managing multiple models on the same cluster, providing an easy-to-use interface for users. With support for various Kubernetes environments and seamless integration with Ollama models, APIs, and CLI, Ollama Operator streamlines the deployment and management of language models. By leveraging the capabilities of lama.cpp, Ollama Operator eliminates the need to worry about Python environments and CUDA drivers, making it a reliable tool for running large language models on Kubernetes.
kubeai
KubeAI is a highly scalable AI platform that runs on Kubernetes, serving as a drop-in replacement for OpenAI with API compatibility. It can operate OSS model servers like vLLM and Ollama, with zero dependencies and additional OSS addons included. Users can configure models via Kubernetes Custom Resources and interact with models through a chat UI. KubeAI supports serving various models like Llama v3.1, Gemma2, and Qwen2, and has plans for model caching, LoRA finetuning, and image generation.
llm-inference-solutions
A collection of available inference solutions for Large Language Models (LLMs) including high-throughput engines, optimization libraries, deployment toolkits, and deep learning frameworks for production environments.

aphrodite-engine
Aphrodite is the official backend engine for PygmalionAI, serving as the inference endpoint for the website. It allows serving Hugging Face-compatible models with fast speeds. Features include continuous batching, efficient K/V management, optimized CUDA kernels, quantization support, distributed inference, and 8-bit KV Cache. The engine requires Linux OS and Python 3.8 to 3.12, with CUDA >= 11 for build requirements. It supports various GPUs, CPUs, TPUs, and Inferentia. Users can limit GPU memory utilization and access full commands via CLI.

BentoVLLM
BentoVLLM is an example project demonstrating how to serve and deploy open-source Large Language Models using vLLM, a high-throughput and memory-efficient inference engine. It provides a basis for advanced code customization, such as custom models, inference logic, or vLLM options. The project allows for simple LLM hosting with OpenAI compatible endpoints without the need to write any code. Users can interact with the server using Swagger UI or other methods, and the service can be deployed to BentoCloud for better management and scalability. Additionally, the repository includes integration examples for different LLM models and tools.
uTensor
uTensor is an extremely light-weight machine learning inference framework built on Tensorflow and optimized for Arm targets. It consists of a runtime library and an offline tool that handles most of the model translation work. The core runtime is only ~2KB. The workflow involves constructing and training a model in Tensorflow, then using uTensor to produce C++ code for inferencing. The runtime ensures system safety, guarantees RAM usage, and focuses on clear, concise, and debuggable code. The high-level API simplifies tensor handling and operator execution for embedded systems.

kafka-ml
Kafka-ML is a framework designed to manage the pipeline of Tensorflow/Keras and PyTorch machine learning models on Kubernetes. It enables the design, training, and inference of ML models with datasets fed through Apache Kafka, connecting them directly to data streams like those from IoT devices. The Web UI allows easy definition of ML models without external libraries, catering to both experts and non-experts in ML/AI.
cortex.cpp
Cortex is a C++ AI engine with a Docker-like command-line interface and client libraries. It supports running AI models using ONNX, TensorRT-LLM, and llama.cpp engines. Cortex can function as a standalone server or be integrated as a library. The tool provides support for various engines and models, allowing users to easily deploy and interact with AI models. It offers a range of CLI commands for managing models, embeddings, and engines, as well as a REST API for interacting with models. Cortex is designed to simplify the deployment and usage of AI models in C++ applications.

nexa-sdk
Nexa SDK is a comprehensive toolkit supporting ONNX and GGML models for text generation, image generation, vision-language models (VLM), and text-to-speech (TTS) capabilities. It offers an OpenAI-compatible API server with JSON schema mode and streaming support, along with a user-friendly Streamlit UI. Users can run Nexa SDK on any device with Python environment, with GPU acceleration supported. The toolkit provides model support, conversion engine, inference engine for various tasks, and differentiating features from other tools.

project_alice
Alice is an agentic workflow framework that integrates task execution and intelligent chat capabilities. It provides a flexible environment for creating, managing, and deploying AI agents for various purposes, leveraging a microservices architecture with MongoDB for data persistence. The framework consists of components like APIs, agents, tasks, and chats that interact to produce outputs through files, messages, task results, and URL references. Users can create, test, and deploy agentic solutions in a human-language framework, making it easy to engage with by both users and agents. The tool offers an open-source option, user management, flexible model deployment, and programmatic access to tasks and chats.

outspeed
Outspeed is a PyTorch-inspired SDK for building real-time AI applications on voice and video input. It offers low-latency processing of streaming audio and video, an intuitive API familiar to PyTorch users, flexible integration of custom AI models, and tools for data preprocessing and model deployment. Ideal for developing voice assistants, video analytics, and other real-time AI applications processing audio-visual data.
jax-ai-stack
JAX AI Stack is a suite of libraries built around the JAX Python package for array-oriented computation and program transformation. It provides a growing ecosystem of packages for specialized numerical computing across various domains, encouraging modularity and innovation in domain-specific libraries. The stack includes core packages like JAX, flax for building neural networks, ml_dtypes for NumPy dtype extensions, optax for gradient processing and optimization, and orbax for checkpointing and persistence utilities. Optional packages like grain data loader and tensorflow are also available for installation.
PC-Agent
PC Agent introduces a novel framework to empower autonomous digital agents through human cognition transfer. It consists of PC Tracker for data collection, Cognition Completion for transforming raw data, and a multi-agent system for decision-making and visual grounding. Users can set up the tool in Python environment, customize data collection with PC Tracker, process data into cognitive trajectories, and run the multi-agent system. The tool aims to enable AI to work autonomously while users sleep, providing a cognitive journey into the digital world.
LLMForEverybody
LLMForEverybody is a comprehensive repository covering various aspects of large language models (LLMs) including pre-training, architecture, optimizers, activation functions, attention mechanisms, tokenization, parallel strategies, training frameworks, deployment, fine-tuning, quantization, GPU parallelism, prompt engineering, agent design, RAG architecture, enterprise deployment challenges, evaluation metrics, and current hot topics in the field. It provides detailed explanations, tutorials, and insights into the workings and applications of LLMs, making it a valuable resource for researchers, developers, and enthusiasts interested in understanding and working with large language models.
LLMInterviewQuestions
LLMInterviewQuestions is a repository containing over 100+ interview questions for Large Language Models (LLM) used by top companies like Google, NVIDIA, Meta, Microsoft, and Fortune 500 companies. The questions cover various topics related to LLMs, including prompt engineering, retrieval augmented generation, chunking, embedding models, internal working of vector databases, advanced search algorithms, language models internal working, supervised fine-tuning of LLM, preference alignment, evaluation of LLM system, hallucination control techniques, deployment of LLM, agent-based system, prompt hacking, and miscellaneous topics. The questions are organized into 15 categories to facilitate learning and preparation.

ai-enablement-stack
The AI Enablement Stack is a curated collection of venture-backed companies, tools, and technologies that enable developers to build, deploy, and manage AI applications. It provides a structured view of the AI development ecosystem across five key layers: Agent Consumer Layer, Observability and Governance Layer, Engineering Layer, Intelligence Layer, and Infrastructure Layer. Each layer focuses on specific aspects of AI development, from end-user interaction to model training and deployment. The stack aims to help developers find the right tools for building AI applications faster and more efficiently, assist engineering leaders in making informed decisions about AI infrastructure and tooling, and help organizations understand the AI development landscape to plan technology adoption.
awesome-generative-ai-data-scientist
A curated list of 50+ resources to help you become a Generative AI Data Scientist. This repository includes resources on building GenAI applications with Large Language Models (LLMs), and deploying LLMs and GenAI with Cloud-based solutions.
LLMLanding
LLMLanding is a repository focused on practical implementation of large models, covering topics from theory to practice. It provides a structured learning path for training large models, including specific tasks like training 1B-scale models, exploring SFT, and working on specialized tasks such as code generation, NLP tasks, and domain-specific fine-tuning. The repository emphasizes a dual learning approach: quickly applying existing tools for immediate output benefits and delving into foundational concepts for long-term understanding. It offers detailed resources and pathways for in-depth learning based on individual preferences and goals, combining theory with practical application to avoid overwhelm and ensure sustained learning progress.
efficient-transformers
Efficient Transformers Library provides reimplemented blocks of Large Language Models (LLMs) to make models functional and highly performant on Qualcomm Cloud AI 100. It includes graph transformations, handling for under-flows and overflows, patcher modules, exporter module, sample applications, and unit test templates. The library supports seamless inference on pre-trained LLMs with documentation for model optimization and deployment. Contributions and suggestions are welcome, with a focus on testing changes for model support and common utilities.
awesome-ai-tools
This repository contains a curated list of awesome AI tools that can be used for various machine learning and artificial intelligence projects. It includes tools for data preprocessing, model training, evaluation, and deployment. The list is regularly updated with new tools and resources to help developers and data scientists in their AI projects.

lumigator
Lumigator is an open-source platform developed by Mozilla.ai to help users select the most suitable language model for their specific needs. It supports the evaluation of summarization tasks using sequence-to-sequence models such as BART and BERT, as well as causal models like GPT and Mistral. The platform aims to make model selection transparent, efficient, and empowering by providing a framework for comparing LLMs using task-specific metrics to evaluate how well a model fits a project's needs. Lumigator is in the early stages of development and plans to expand support to additional machine learning tasks and use cases in the future.
LLMs-Zero-to-Hero
LLMs-Zero-to-Hero is a repository dedicated to training large language models (LLMs) from scratch, covering topics such as dense models, MOE models, pre-training, supervised fine-tuning, direct preference optimization, reinforcement learning from human feedback, and deploying large models. The repository provides detailed learning notes for different chapters, code implementations, and resources for training and deploying LLMs. It aims to guide users from being beginners to proficient in building and deploying large language models.
Tutorial-of-AI-Kit-with-Raspberry-Pi-From-Zero-to-Hero
This course is designed to teach you how to harness the power of AI on the Raspberry Pi, with a focus on using an AI kit for computer vision tasks. Learn to integrate AI into IoT applications, from object detection to visual recognition. Suitable for hobbyists, students, and professionals to bring AI-driven solutions to life on resource-constrained devices like the Raspberry Pi.

aphrodite-engine
Aphrodite is an inference engine optimized for serving HuggingFace-compatible models at scale. It leverages vLLM's Paged Attention technology to deliver high-performance model inference for multiple concurrent users. The engine supports continuous batching, efficient key/value management, optimized CUDA kernels, quantization support, distributed inference, and modern samplers. It can be easily installed and launched, with Docker support for deployment. Aphrodite requires Linux or Windows OS, Python 3.8 to 3.12, and CUDA >= 11. It is designed to utilize 90% of GPU VRAM but offers options to limit memory usage. Contributors are welcome to enhance the engine.

MNN
MNN is a highly efficient and lightweight deep learning framework that supports inference and training of deep learning models. It has industry-leading performance for on-device inference and training. MNN has been integrated into various Alibaba Inc. apps and is used in scenarios like live broadcast, short video capture, search recommendation, and product searching by image. It is also utilized on embedded devices such as IoT. MNN-LLM and MNN-Diffusion are specific runtime solutions developed based on the MNN engine for deploying language models and diffusion models locally on different platforms. The framework is optimized for devices, supports various neural networks, and offers high performance with optimized assembly code and GPU support. MNN is versatile, easy to use, and supports hybrid computing on multiple devices.
deep-research-web-ui
This web UI tool is designed to enhance the user experience of the deep-research repository by providing a safe and secure environment for conducting AI research. It offers features such as real-time feedback, search visualization, export as PDF, support for various AI models, and Docker deployment. Users can interact with multiple AI providers and web search services, making research processes more efficient and accessible. The tool also includes recent updates that improve functionality and fix bugs, ensuring a seamless experience for users.

second-brain-ai-assistant-course
This open-source course teaches how to build an advanced RAG and LLM system using LLMOps and ML systems best practices. It helps you create an AI assistant that leverages your personal knowledge base to answer questions, summarize documents, and provide insights. The course covers topics such as LLM system architecture, pipeline orchestration, large-scale web crawling, model fine-tuning, and advanced RAG features. It is suitable for ML/AI engineers and data/software engineers & data scientists looking to level up to production AI systems. The course is free, with minimal costs for tools like OpenAI's API and Hugging Face's Dedicated Endpoints. Participants will build two separate Python applications for offline ML pipelines and online inference pipeline.
Awesome-LLM-Resources-List
Awesome LLM Resources is a curated collection of resources for Large Language Models (LLMs) covering various aspects such as serverless hosting, accessing off-the-shelf models via API, local inference, LLM serving frameworks, open-source LLM web chat UIs, renting GPUs for fine-tuning, fine-tuning with no-code UI, fine-tuning frameworks, OS agentic/AI workflow, AI agents, co-pilots, voice API, open-source TTS models, OS RAG frameworks, research papers on chain-of-thought prompting, CoT implementations, CoT fine-tuned models & datasets, and more.
UMbreLLa
UMbreLLa is a tool designed for deploying Large Language Models (LLMs) for personal agents. It combines offloading, speculative decoding, and quantization to optimize single-user LLM deployment scenarios. With UMbreLLa, 70B-level models can achieve performance comparable to human reading speed on an RTX 4070Ti, delivering exceptional efficiency and responsiveness, especially for coding tasks. The tool supports deploying models on various GPUs and offers features like code completion and CLI/Gradio chatbots. Users can configure the LLM engine for optimal performance based on their hardware setup.
ComfyUI-Copilot
ComfyUI-Copilot is an intelligent assistant built on the Comfy-UI framework that simplifies and enhances the AI algorithm debugging and deployment process through natural language interactions. It offers intuitive node recommendations, workflow building aids, and model querying services to streamline development processes. With features like interactive Q&A bot, natural language node suggestions, smart workflow assistance, and model querying, ComfyUI-Copilot aims to lower the barriers to entry for beginners, boost development efficiency with AI-driven suggestions, and provide real-time assistance for developers.
argo
Local Agent platform with generative AI models, RAG and tools to make AI helpful for everyone. Argo is a versatile tool that provides a user-friendly interface for leveraging AI capabilities. It offers a range of features and functionalities to assist users in various tasks related to artificial intelligence. The platform aims to democratize AI by simplifying complex processes and making them accessible to a wider audience. With Argo, users can easily deploy AI models, interact with generative AI technologies, and utilize a suite of tools designed to enhance their AI experience. Whether you are a beginner or an experienced AI practitioner, Argo provides a seamless environment for exploring and utilizing AI solutions.
AingDesk
AingDesk is a tool that allows users to deploy DeepSeek or other AI models on their computer with just one click. It features a user-friendly interface, multi-source knowledge base support, built-in chat interface, and the ability to share projects online. The tool is optimized for performance on both local and cloud environments, with a focus on hassle-free setup and extensibility through a modular architecture. The development plan includes support for third-party API integrations and local deployment of text-to-image hybrid models for creative workflows.
solo-server
Solo Server is a lightweight server designed for managing hardware-aware inference. It provides seamless setup through a simple CLI and HTTP servers, an open model registry for pulling models from platforms like Ollama and Hugging Face, cross-platform compatibility for effortless deployment of AI models on hardware, and a configurable framework that auto-detects hardware components (CPU, GPU, RAM) and sets optimal configurations.
watsonx-ai-samples
Sample notebooks for IBM Watsonx.ai for IBM Cloud and IBM Watsonx.ai software product. The notebooks demonstrate capabilities such as running experiments on model building using AutoAI or Deep Learning, deploying third-party models as web services or batch jobs, monitoring deployments with OpenScale, managing model lifecycles, inferencing Watsonx.ai foundation models, and integrating LangChain with Watsonx.ai. Notebooks with Python code and the Python SDK can be found in the `python_sdk` folder. The REST API examples are organized in the `rest_api` folder.
Ling
Ling is a MoE LLM provided and open-sourced by InclusionAI. It includes two different sizes, Ling-Lite with 16.8 billion parameters and Ling-Plus with 290 billion parameters. These models show impressive performance and scalability for various tasks, from natural language processing to complex problem-solving. The open-source nature of Ling encourages collaboration and innovation within the AI community, leading to rapid advancements and improvements. Users can download the models from Hugging Face and ModelScope for different use cases. Ling also supports offline batched inference and online API services for deployment. Additionally, users can fine-tune Ling models using Llama-Factory for tasks like SFT and DPO.
AmazonSageMakerCourse
Amazon SageMaker Course is a comprehensive guide for AWS Certified Machine Learning Specialty (MLS-C01) that covers training, optimizing, deploying, and integrating machine learning models in the AWS cloud. The course includes hands-on experience with AWS built-in algorithms, Bring Your Own models, and ready-to-use AI capabilities. It also provides a complete guide to AWS Certified Machine Learning – Specialty certification, along with a high-quality timed practice test. Participants will learn how to integrate trained models into their applications and receive prompt support through the course Q&A forum and private messaging.
chitu
Chitu is a high-performance inference framework for large language models, focusing on efficiency, flexibility, and availability. It supports various mainstream large language models, including DeepSeek, LLaMA series, Mixtral, and more. Chitu integrates latest optimizations for large language models, provides efficient operators with online FP8 to BF16 conversion, and is deployed for real-world production. The framework is versatile, supporting various hardware environments beyond NVIDIA GPUs. Chitu aims to enhance output speed per unit computing power, especially in decoding processes dependent on memory bandwidth.
FastDeploy
FastDeploy is an inference and deployment toolkit for large language models and visual language models based on PaddlePaddle. It provides production-ready deployment solutions with core acceleration technologies such as load-balanced PD disaggregation, unified KV cache transmission, OpenAI API server compatibility, comprehensive quantization format support, advanced acceleration techniques, and multi-hardware support. The toolkit supports various hardware platforms like NVIDIA GPUs, Kunlunxin XPUs, Iluvatar GPUs, Enflame GCUs, and Hygon DCUs, with plans for expanding support to Ascend NPU and MetaX GPU. FastDeploy aims to optimize resource utilization, throughput, and performance for inference and deployment tasks.

ERNIE
ERNIE 4.5 is a family of large-scale multimodal models with 10 distinct variants, including Mixture-of-Experts (MoE) models with 47B and 3B active parameters. The models feature a novel heterogeneous modality structure supporting parameter sharing across modalities while allowing dedicated parameters for each individual modality. Trained with optimal efficiency using PaddlePaddle deep learning framework, ERNIE 4.5 models achieve state-of-the-art performance across text and multimodal benchmarks, enhancing multimodal understanding without compromising performance on text-related tasks. The open-source development toolkits for ERNIE 4.5 offer industrial-grade capabilities, resource-efficient training and inference workflows, and multi-hardware compatibility.

kaito
KAITO is an operator that automates the AI/ML model inference or tuning workload in a Kubernetes cluster. It manages large model files using container images, provides preset configurations to avoid adjusting workload parameters based on GPU hardware, supports popular open-sourced inference runtimes, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry. Using KAITO simplifies the workflow of onboarding large AI inference models in Kubernetes.

oumi
Oumi is an open-source platform for building state-of-the-art foundation models, offering tools for data preparation, training, evaluation, and deployment. It supports training and fine-tuning models with various parameters, working with text and multimodal models, synthesizing and curating training data, deploying models efficiently, evaluating models comprehensively, and running on different platforms. Oumi provides a consistent API, reliability, and flexibility for research purposes.
modular
The Modular Platform is a unified suite of AI libraries and tools designed for AI development and deployment. It abstracts hardware complexity to enable running popular open models with high GPU and CPU performance without code changes. The repository contains over 450,000 lines of code from 6000+ contributors, making it one of the largest open-source repositories for CPU and GPU kernels. Key components include the Mojo standard library, MAX GPU and CPU kernels, MAX inference server, MAX model pipelines, and code examples. The repository has main and stable branches for nightly builds and stable releases, respectively. Contributions are accepted for the Mojo standard library, MAX AI kernels, code examples, and Mojo docs.

DashAI
DashAI is a powerful tool for building interactive web applications with Python. It allows users to create data visualization dashboards and deploy machine learning models with ease. The tool provides a simple and intuitive way to design and customize web apps without the need for extensive front-end development knowledge. With DashAI, users can easily showcase their data analysis results and predictive models in a user-friendly and interactive manner, making it ideal for data scientists, developers, and business professionals looking to share insights and predictions with stakeholders.

ml-retreat
ML-Retreat is a comprehensive machine learning library designed to simplify and streamline the process of building and deploying machine learning models. It provides a wide range of tools and utilities for data preprocessing, model training, evaluation, and deployment. With ML-Retreat, users can easily experiment with different algorithms, hyperparameters, and feature engineering techniques to optimize their models. The library is built with a focus on scalability, performance, and ease of use, making it suitable for both beginners and experienced machine learning practitioners.
dataforce.studio
DataForce Studio is an open-source MLOps platform designed to help build, manage, and deploy AI/ML models with ease. It supports the entire model lifecycle, from creation to deployment and monitoring, within a user-friendly interface. The platform is in active early development, aiming to provide features like post-deployment monitoring, model deployment, data science agent, experiment snapshots, model cards, Python SDK, model registry, notebooks, in-browser runtime, and express tasks for prompt optimization and tabular data.
shimmy
Shimmy is a 5.1MB single-binary local inference server providing OpenAI-compatible endpoints for GGUF models. It offers fast, reliable AI inference with sub-second responses, zero configuration, and automatic port management. Perfect for developers seeking privacy, cost-effectiveness, speed, and easy integration with popular tools like VSCode and Cursor. Shimmy is designed to be invisible infrastructure that simplifies local AI development and deployment.
kserve
KServe provides a Kubernetes Custom Resource Definition for serving predictive and generative machine learning (ML) models. It encapsulates the complexity of autoscaling, networking, health checking, and server configuration to bring cutting edge serving features like GPU Autoscaling, Scale to Zero, and Canary Rollouts to ML deployments. KServe enables a simple, pluggable, and complete story for Production ML Serving including prediction, pre-processing, post-processing, and explainability. It is a standard, cloud agnostic Model Inference Platform for serving predictive and generative AI models on Kubernetes, built for highly scalable use cases.
ai-platform-engineering
The AI Platform Engineering repository provides a collection of tools and resources for building and deploying AI models. It includes libraries for data preprocessing, model training, and model serving. The repository also contains example code and tutorials to help users get started with AI development. Whether you are a beginner or an experienced AI engineer, this repository offers valuable insights and best practices to streamline your AI projects.
ai-sdk-tools
The ai-sdk-tools repository contains a collection of tools and utilities for developing and deploying AI models. It includes modules for data preprocessing, model training, evaluation, and deployment. The tools are designed to streamline the AI development process and improve efficiency. With a focus on usability and performance, this toolkit aims to support developers in building robust and scalable AI applications.
miles-credit
CREDIT is an open software platform for training and deploying AI atmospheric prediction models. It offers fast models with flexible configuration options for input data and neural network architecture. The user-friendly interface enables quick setup and iteration. Developed by the MILES group and NSF National Center for Atmospheric Research, CREDIT combines advanced AI/ML with atmospheric science expertise. It provides a stable release with various models, training, and deployment options, with ongoing development. Detailed documentation is available for installation, training, deployment, config file interpretation, and API usage.
llm_model_hub
Model Hub V2 is a one-stop platform for model fine-tuning, deployment, and debugging without code, providing users with a visual interface to quickly validate the effects of fine-tuning various open-source models, facilitating rapid experimentation and decision-making, and lowering the threshold for users to fine-tune large models. For detailed instructions, please refer to the Feishu documentation.
FLAME
FLAME is a lightweight and efficient deep learning framework designed for edge devices. It provides a simple and user-friendly interface for developing and deploying deep learning models on resource-constrained devices. With FLAME, users can easily build and optimize neural networks for tasks such as image classification, object detection, and natural language processing. The framework supports various neural network architectures and optimization techniques, making it suitable for a wide range of applications in the field of edge computing.
LMForge-End-to-End-LLMOps-Platform-for-Multi-Model-Agents
LMForge is an end-to-end LLMOps platform designed for multi-model agents. It provides a comprehensive solution for managing and deploying large language models efficiently. The platform offers tools for training, fine-tuning, and deploying various types of language models, enabling users to streamline the development and deployment process. With LMForge, users can easily experiment with different model architectures, optimize hyperparameters, and scale their models to meet specific requirements. The platform also includes features for monitoring model performance, managing datasets, and collaborating with team members, making it a versatile tool for researchers and developers working with language models.
ai-accelerator
The AI Accelerator project source code is designed to initialize an OpenShift cluster with a recommended set of operators and components for training, deploying, serving, and monitoring Machine Learning models. It provides core OpenShift features for Data Science environments and can be customized for specific scenarios. The project automates IT infrastructure using GitOps practices, including Git, code review, and CI/CD. ArgoCD Application objects are used to manage the installation of operators on the cluster.

MiniCPM-V-CookBook
MiniCPM-V & o Cookbook is a comprehensive repository for building multimodal AI applications effortlessly. It provides easy-to-use documentation, supports a wide range of users, and offers versatile deployment scenarios. The repository includes live demonstrations, inference recipes for vision and audio capabilities, fine-tuning recipes, serving recipes, quantization recipes, and a framework support matrix. Users can customize models, deploy them efficiently, and compress models to improve efficiency. The repository also showcases awesome works using MiniCPM-V & o and encourages community contributions.
LLMOne
LLMOne is an open-source, lightweight enterprise-level platform for deploying and serving large language models. It aims to address pain points in traditional large model private deployment such as long cycles, complex configurations, performance challenges, and high operational costs. LLMOne simplifies the deployment process with highly automated workflows and optimized runtime environments, ensuring enterprise-level performance and stability. It caters to developers, manufacturers, and users of large language models, providing features like rapid deployment, professional inference performance, broad compatibility with AI hardware, flexible model and application management, visual operational monitoring, and an open application ecosystem.
18 - OpenAI Gpts

Instructor GCP ML
Formador para la certificación de ML Engineer en GCP, con respuestas y explicaciones detalladas.



HuggingFace Helper
A witty yet succinct guide for HuggingFace, offering technical assistance on using the platform - based on their Learning Hub

TensorFlow Oracle
I'm an expert in TensorFlow, providing detailed, accurate guidance for all skill levels.

![[latest] FastAPI GPT Screenshot](/screenshots_gpts/g-BhYCAfVXk.jpg)
[latest] FastAPI GPT
Up-to-date FastAPI coding assistant with knowledge of the latest version. Part of the [latest] GPTs family.

ML Engineer GPT
I'm a Python and PyTorch expert with knowledge of ML infrastructure requirements ready to help you build and scale your ML projects.