
LLM-TPU
Run generative AI models in sophgo BM1684X/BM1688
Stars: 238

LLM-TPU project aims to deploy various open-source generative AI models on the BM1684X chip, with a focus on LLM. Models are converted to bmodel using TPU-MLIR compiler and deployed to PCIe or SoC environments using C++ code. The project has deployed various open-source models such as Baichuan2-7B, ChatGLM3-6B, CodeFuse-7B, DeepSeek-6.7B, Falcon-40B, Phi-3-mini-4k, Qwen-7B, Qwen-14B, Qwen-72B, Qwen1.5-0.5B, Qwen1.5-1.8B, Llama2-7B, Llama2-13B, LWM-Text-Chat, Mistral-7B-Instruct, Stable Diffusion, Stable Diffusion XL, WizardCoder-15B, Yi-6B-chat, Yi-34B-chat. Detailed model deployment information can be found in the 'models' subdirectory of the project. For demonstrations, users can follow the 'Quick Start' section. For inquiries about the chip, users can contact SOPHGO via the official website.
README:






- 2025.05.22:🚀 InternVL3 BM1684X/1688已支持,详情见InternVL3。支持图片和视频。
- 2025.04.30:🚀 Qwen2.5VL BM1684X/1688已支持,详情见Qwen2.5VL。其中demo有python和c++两个版本,且都支持图片和视频。
- 2025.04.29:🚀 Qwen最新推理模型Qwen3,BM1684X/1688已支持,详情见Qwen3 Demo。
- 2025.03.07:🚀 Qwen最新推理模型QWQ-32B和DeepSeek-R1-Distill-Qwen-32B,1684x多芯demo已适配,详情见Qwen2.5 Demo。
- 2025.02.05:🚀 DeepSeek时刻!!我们适配了DeepSeek-R1-Distill-Qwen系列模型,包括1.5B、7B和14B版本,详情见Qwen2.5 Demo。
本项目实现算能BM1684X、BM1688(CV186X)芯片部署各类开源生成式AI模型,其中以LLM/VLM为主。通过TPU-MLIR编译器将模型转换成bmodel,再基于tpu-runtime的推理引擎接口,采用python/c++代码将其部署到PCIE环境或者SoC环境。
如果要编译模型,需要配置TPU-MLIR环境,包括安装docker和编译源码; 也可以直接用各类Demo中编译好的bmodel。
各个模型的Demo见此目录models。
克隆LLM-TPU项目,并执行run.sh脚本
git clone https://github.com/sophgo/LLM-TPU.git
./run.sh --model qwen2.5vl详细请参考Quick Start, 跑通后效果如下图所示:


目前用于演示的模型如下:
| Model | Command |
|---|---|
| Qwen3-4B | ./run.sh --model qwen3 |
| Qwen2.5-VL-3B | ./run.sh --model qwen2.5vl |
| InternVL3-2B | ./run.sh --model internvl3 |
以Qwen2.5-VL为例介绍模型编译方法。
下载LLM模型,注意优先使用AWQ或者GPTQ模型,如下:
git lfs install
git clone [email protected]:Qwen/Qwen2.5-VL-3B-Instruct-AWQMLIR环境支持多种安装方式,请参考:MLIR环境安装指南
编译命令如下:
llm_convert.py -m /workspace/Qwen2.5-VL-3B-Instruct-AWQ -s 2048 -q w4bf16 -c bm1684x --max_pixels 672,896 -o qwen2.5vl_3bllm_convert.py 是一个通用的llm模型导出工具,能够直接将llm原始权重直接导出为bmodel。
支持的主要参数如下:
| 参数名 | 简写 | 必选? | 说明 |
|---|---|---|---|
| model_path | m | 是 | 指定权重路径 |
| seq_length | s | 是 | 指定序列最大长度 |
| quantize | q | 是 | 指定量化类型, w4bf16/w4f16/bf16/f16等等 |
| chip | c | 是 | 指定平台, 如bm1684x/bm1688/cv186x |
| q_group_size | g | 否 | 指定每组量化的组大小, 默认64 |
| max_pixels | - | 否 | qwen vl参数, 指定最大图片尺寸, 可以是672,896,也可以是602112
|
| do_sample | - | 否 | 指定输出是否包含采样模型,默认关闭 |
| out_dir | o | 是 | 指定输出目录 |
还有更多参数可以参考进阶应用。其中量化类型用w4bf16还是w4f16,要看LLM中config.json配置torch_dtype是bfloat16还是float16。
llm_convert.py执行完成后在指定目录会生成对应的bmodel和配置目录config。
支持一键编译的VLM模型包括:
LLM模型包括:
- Qwen系列:Qwen1.5/Qwen2/Qwen2.5/Qwen3/QwQ-32B
- Qwen相关:DeepSeek-R1-Distill-Qwen
- Llama系列:Llama2/Llama3
- MiniCPM系列:MiniCPM4
- Phi系列:Phi3/Phi4
- ChatGLM系列:ChatGLM3
除了一键编译外,其他模型可以采用传统方法编译,先转onnx再转bmodel,具体可以参考每个模型的Demo介绍。
我们已经部署过的LLM模型包括:
Baichuan2
ChatGLM3/ChatGLM4/CodeFuse
DeepSeek-6.7B/DeepSeek-R1-Distill-Qwen
Falcon
Gemma/Gemma2
Llama2/Llama3/LWM-Text-Chat
MiniCPM/MiniCPM3/MiniCPM4/Mistral
Phi-3/Phi-4
Qwen/Qwen1.5/Qwen2/Qwen2.5/QwQ-32B/Qwen3
WizardCoder
Yi
多模态模型包括:
Qwen2.5-VL/Qwen2-VL/Qwen-VL
InternVL3/InternVL2
MiniCPM-V-2_6
Llama3.2-Vision
Stable Diffusion
Molmo
OpenClip
NVILA
DeepSeek-Janus-Pro
如果您想要知道转换细节和源码,可以到本项目models子目录查看各类模型部署细节。
如果您对我们的芯片感兴趣,也可以通过官网SOPHGO联系我们。
默认情况下模型是静态编译,输入按照指定的seq_length长度推理,不足部分会补0和mask掉,当输入长度变化幅度不大的时候,建议用默认方式。
动态编译可以根据输入长度动态推理,在输入长短变化幅度较大的情况下,可以减少短输入的延时。
方法:在llm_converter.py命令加入--dynamic
样例:
默认情况下历史上下文是靠历史token与当前输入token拼凑来实现,延时较长。
采样prefill with kv cache可以减少延时。
方法:在llm_converter.py命令加入--use_block_with_kv参数;
--max_input_length指定单次输入最大长度,不指定时默认是seq_length的1/4;
--max_prefill_kv_length指定输入最大kv长度, 不指定时默认是seq_length。
样例:
默认情况下推理在单芯上进行。可以采用多芯设备支持更大模型,和加速推理。
方法:在llm_converter.py命令加入--num_device参数指定芯片数量
样例:
- Qwen2_5/python_demo_parallel,支持Qwen系列2/4/6/8芯推理
默认情况下采用greedy方式,即topk1取token。可以支持根据generation.json的配置进行随机采样。
方法:在llm_converter.py命令加入--do_sample
样例:
可以对相同模型,加载多次支持多任务;如果是对同一颗芯片,权重只会加载一次;不过不太建议单颗芯片做多任务。 样例:
可以将较长的prompt生成kv cache,后续对话内容始终共用该kv cache。它会将模型分为三个阶段:prompt推理、prefill推理、decode推理。
如果prompt不变,则prompt推理只用进行一次。
方法:在llm_converter.py命令加入--share_prompt,并指定--max_prefill_kv_length
样例:
可以支持模型被第三方库加密,推理时用解密库解密
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for LLM-TPU
Similar Open Source Tools
LLM-TPU
LLM-TPU project aims to deploy various open-source generative AI models on the BM1684X chip, with a focus on LLM. Models are converted to bmodel using TPU-MLIR compiler and deployed to PCIe or SoC environments using C++ code. The project has deployed various open-source models such as Baichuan2-7B, ChatGLM3-6B, CodeFuse-7B, DeepSeek-6.7B, Falcon-40B, Phi-3-mini-4k, Qwen-7B, Qwen-14B, Qwen-72B, Qwen1.5-0.5B, Qwen1.5-1.8B, Llama2-7B, Llama2-13B, LWM-Text-Chat, Mistral-7B-Instruct, Stable Diffusion, Stable Diffusion XL, WizardCoder-15B, Yi-6B-chat, Yi-34B-chat. Detailed model deployment information can be found in the 'models' subdirectory of the project. For demonstrations, users can follow the 'Quick Start' section. For inquiries about the chip, users can contact SOPHGO via the official website.
k8m
k8m is an AI-driven Mini Kubernetes AI Dashboard lightweight console tool designed to simplify cluster management. It is built on AMIS and uses 'kom' as the Kubernetes API client. k8m has built-in Qwen2.5-Coder-7B model interaction capabilities and supports integration with your own private large models. Its key features include miniaturized design for easy deployment, user-friendly interface for intuitive operation, efficient performance with backend in Golang and frontend based on Baidu AMIS, pod file management for browsing, editing, uploading, downloading, and deleting files, pod runtime management for real-time log viewing, log downloading, and executing shell commands within pods, CRD management for automatic discovery and management of CRD resources, and intelligent translation and diagnosis based on ChatGPT for YAML property translation, Describe information interpretation, AI log diagnosis, and command recommendations, providing intelligent support for managing k8s. It is cross-platform compatible with Linux, macOS, and Windows, supporting multiple architectures like x86 and ARM for seamless operation. k8m's design philosophy is 'AI-driven, lightweight and efficient, simplifying complexity,' helping developers and operators quickly get started and easily manage Kubernetes clusters.
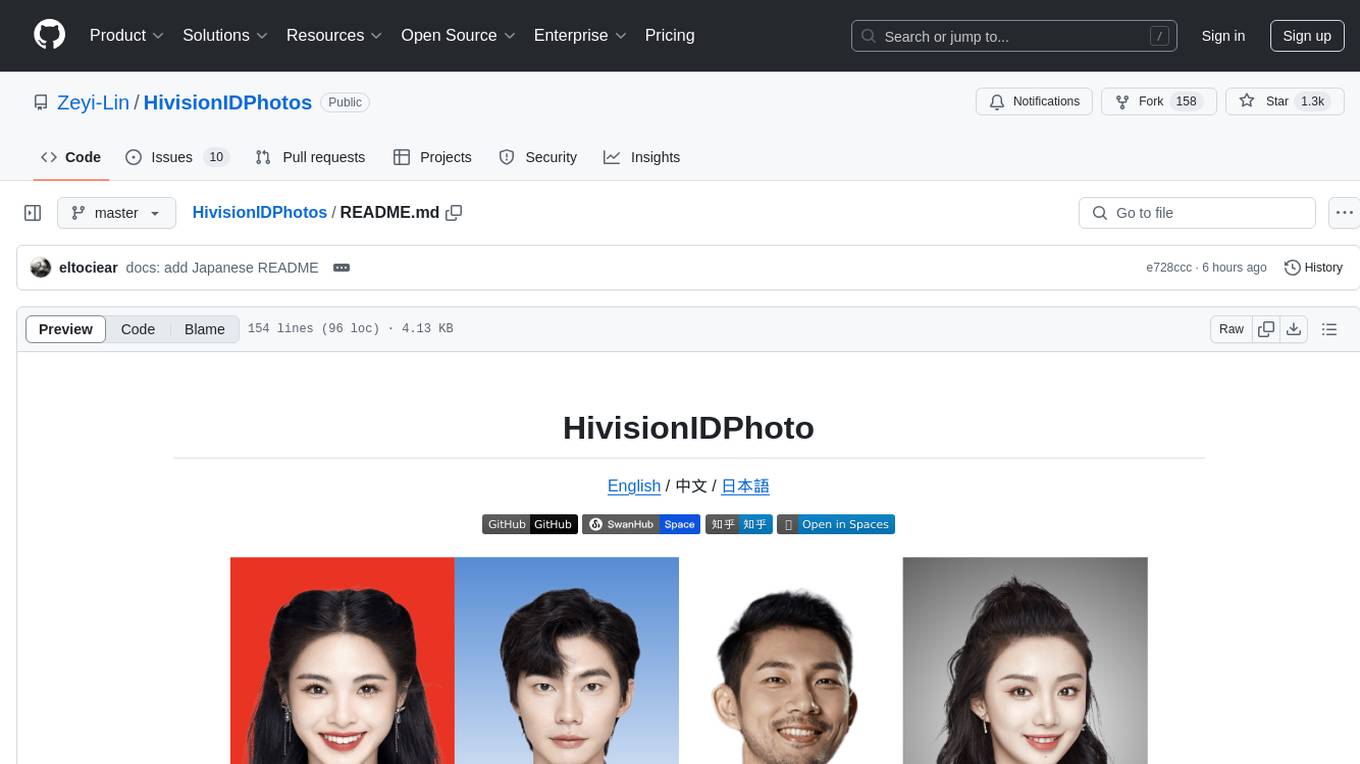
HivisionIDPhotos
HivisionIDPhoto is a practical algorithm for intelligent ID photo creation. It utilizes a comprehensive model workflow to recognize, cut out, and generate ID photos for various user photo scenarios. The tool offers lightweight cutting, standard ID photo generation based on different size specifications, six-inch layout photo generation, beauty enhancement (waiting), and intelligent outfit swapping (waiting). It aims to solve emergency ID photo creation issues.
Awesome-ChatTTS
Awesome-ChatTTS is an official recommended guide for ChatTTS beginners, compiling common questions and related resources. It provides a comprehensive overview of the project, including official introduction, quick experience options, popular branches, parameter explanations, voice seed details, installation guides, FAQs, and error troubleshooting. The repository also includes video tutorials, discussion community links, and project trends analysis. Users can explore various branches for different functionalities and enhancements related to ChatTTS.
prisma-ai
Prisma-AI is an open-source tool designed to assist users in their job search process by addressing common challenges such as lack of project highlights, mismatched resumes, difficulty in learning, and lack of answers in interview experiences. The tool utilizes AI to analyze user experiences, generate actionable project highlights, customize resumes for specific job positions, provide study materials for efficient learning, and offer structured interview answers. It also features a user-friendly interface for easy deployment and supports continuous improvement through user feedback and collaboration.

Qwen-TensorRT-LLM
Qwen-TensorRT-LLM is a project developed for the NVIDIA TensorRT Hackathon 2023, focusing on accelerating inference for the Qwen-7B-Chat model using TRT-LLM. The project offers various functionalities such as FP16/BF16 support, INT8 and INT4 quantization options, Tensor Parallel for multi-GPU parallelism, web demo setup with gradio, Triton API deployment for maximum throughput/concurrency, fastapi integration for openai requests, CLI interaction, and langchain support. It supports models like qwen2, qwen, and qwen-vl for both base and chat models. The project also provides tutorials on Bilibili and blogs for adapting Qwen models in NVIDIA TensorRT-LLM, along with hardware requirements and quick start guides for different model types and quantization methods.
Element-Plus-X
Element-Plus-X is an out-of-the-box enterprise-level AI component library based on Vue 3 + Element-Plus. It features built-in scenario components such as chatbots and voice interactions, seamless integration with zero configuration based on Element-Plus design system, and support for on-demand loading with Tree Shaking optimization.
SakuraLLM
SakuraLLM is a project focused on building large language models for Japanese to Chinese translation in the light novel and galgame domain. The models are based on open-source large models and are pre-trained and fine-tuned on general Japanese corpora and specific domains. The project aims to provide high-performance language models for galgame/light novel translation that are comparable to GPT3.5 and can be used offline. It also offers an API backend for running the models, compatible with the OpenAI API format. The project is experimental, with version 0.9 showing improvements in style, fluency, and accuracy over GPT-3.5.
kirara-ai
Kirara AI is a chatbot that supports mainstream large language models and chat platforms. It provides features such as image sending, keyword-triggered replies, multi-account support, personality settings, and support for various chat platforms like QQ, Telegram, Discord, and WeChat. The tool also supports HTTP server for Web API, popular large models like OpenAI and DeepSeek, plugin mechanism, conditional triggers, admin commands, drawing models, voice replies, multi-turn conversations, cross-platform message sending, custom workflows, web management interface, and built-in Frpc intranet penetration.
XianyuAutoAgent
Xianyu AutoAgent is an AI customer service robot system specifically designed for the Xianyu platform, providing 24/7 automated customer service, supporting multi-expert collaborative decision-making, intelligent bargaining, and context-aware conversations. The system includes intelligent conversation engine with features like context awareness and expert routing, business function matrix with modules like core engine, bargaining system, technical support, and operation monitoring. It requires Python 3.8+ and NodeJS 18+ for installation and operation. Users can customize prompts for different experts and contribute to the project through issues or pull requests.
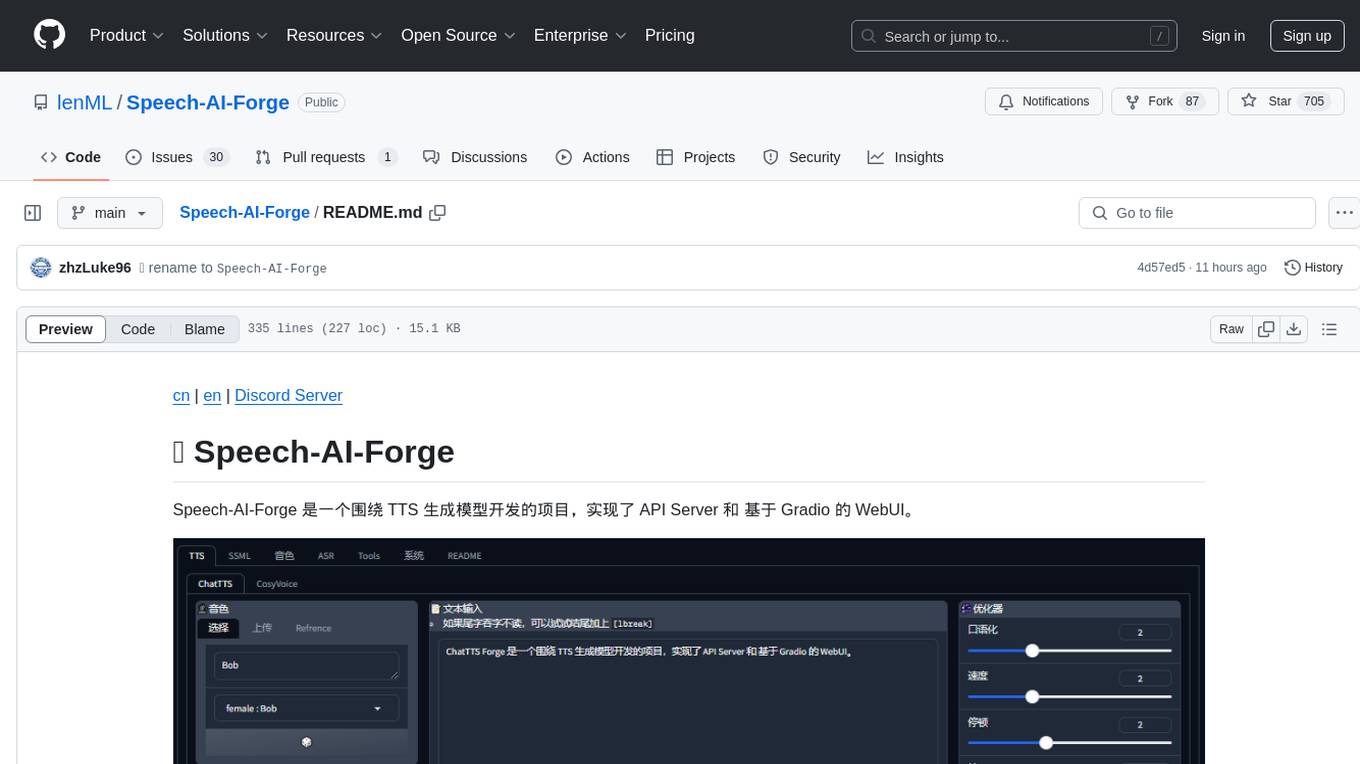
Speech-AI-Forge
Speech-AI-Forge is a project developed around TTS generation models, implementing an API Server and a WebUI based on Gradio. The project offers various ways to experience and deploy Speech-AI-Forge, including online experience on HuggingFace Spaces, one-click launch on Colab, container deployment with Docker, and local deployment. The WebUI features include TTS model functionality, speaker switch for changing voices, style control, long text support with automatic text segmentation, refiner for ChatTTS native text refinement, various tools for voice control and enhancement, support for multiple TTS models, SSML synthesis control, podcast creation tools, voice creation, voice testing, ASR tools, and post-processing tools. The API Server can be launched separately for higher API throughput. The project roadmap includes support for various TTS models, ASR models, voice clone models, and enhancer models. Model downloads can be manually initiated using provided scripts. The project aims to provide inference services and may include training-related functionalities in the future.
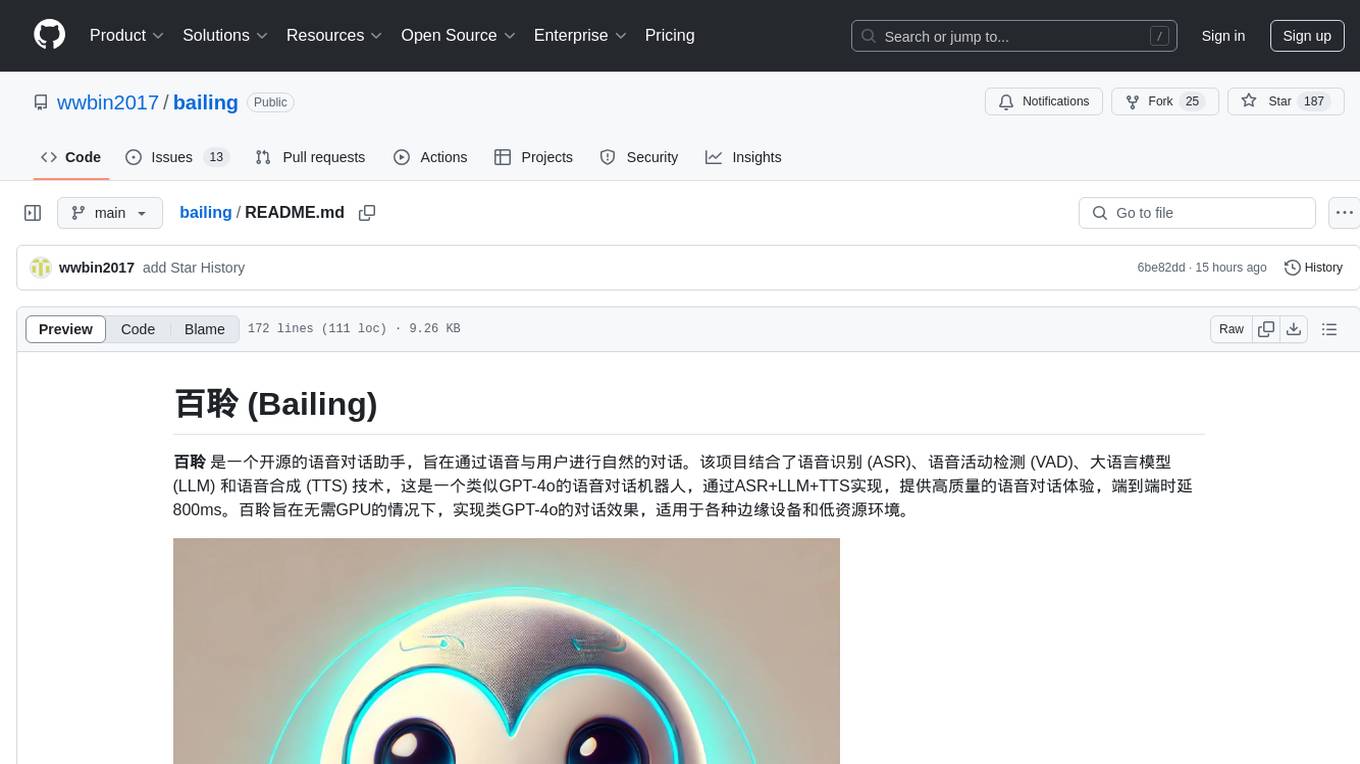
bailing
Bailing is an open-source voice assistant designed for natural conversations with users. It combines Automatic Speech Recognition (ASR), Voice Activity Detection (VAD), Large Language Model (LLM), and Text-to-Speech (TTS) technologies to provide a high-quality voice interaction experience similar to GPT-4o. Bailing aims to achieve GPT-4o-like conversation effects without the need for GPU, making it suitable for various edge devices and low-resource environments. The project features efficient open-source models, modular design allowing for module replacement and upgrades, support for memory function, tool integration for information retrieval and task execution via voice commands, and efficient task management with progress tracking and reminders.
torch-rechub
Torch-RecHub is a lightweight, efficient, and user-friendly PyTorch recommendation system framework. It provides easy-to-use solutions for industrial-level recommendation systems, with features such as generative recommendation models, modular design for adding new models and datasets, PyTorch-based implementation for GPU acceleration, a rich library of 30+ classic and cutting-edge recommendation algorithms, standardized data loading, training, and evaluation processes, easy configuration through files or command-line parameters, reproducibility of experimental results, ONNX model export for production deployment, cross-engine data processing with PySpark support, and experiment visualization and tracking with integrated tools like WandB, SwanLab, and TensorBoardX.
Langchain-Chatchat
LangChain-Chatchat is an open-source, offline-deployable retrieval-enhanced generation (RAG) large model knowledge base project based on large language models such as ChatGLM and application frameworks such as Langchain. It aims to establish a knowledge base Q&A solution that is friendly to Chinese scenarios, supports open-source models, and can run offline.
vscode-antigravity-cockpit
VS Code extension for monitoring Google Antigravity AI model quotas. It provides a webview dashboard, QuickPick mode, quota grouping, automatic grouping, renaming, card view, drag-and-drop sorting, status bar monitoring, threshold notifications, and privacy mode. Users can monitor quota status, remaining percentage, countdown, reset time, progress bar, and model capabilities. The extension supports local and authorized quota monitoring, multiple account authorization, and model wake-up scheduling. It also offers settings customization, user profile display, notifications, and group functionalities. Users can install the extension from the Open VSX Marketplace or via VSIX file. The source code can be built using Node.js and npm. The project is open-source under the MIT license.
chatgpt-mirai-qq-bot
Kirara AI is a chatbot that supports mainstream language models and chat platforms. It features various functionalities such as image sending, keyword-triggered replies, multi-account support, content moderation, personality settings, and support for platforms like QQ, Telegram, Discord, and WeChat. It also offers HTTP server capabilities, plugin support, conditional triggers, admin commands, drawing models, voice replies, multi-turn conversations, cross-platform message sending, and custom workflows. The tool can be accessed via HTTP API for integration with other platforms.
For similar tasks
LLM-TPU
LLM-TPU project aims to deploy various open-source generative AI models on the BM1684X chip, with a focus on LLM. Models are converted to bmodel using TPU-MLIR compiler and deployed to PCIe or SoC environments using C++ code. The project has deployed various open-source models such as Baichuan2-7B, ChatGLM3-6B, CodeFuse-7B, DeepSeek-6.7B, Falcon-40B, Phi-3-mini-4k, Qwen-7B, Qwen-14B, Qwen-72B, Qwen1.5-0.5B, Qwen1.5-1.8B, Llama2-7B, Llama2-13B, LWM-Text-Chat, Mistral-7B-Instruct, Stable Diffusion, Stable Diffusion XL, WizardCoder-15B, Yi-6B-chat, Yi-34B-chat. Detailed model deployment information can be found in the 'models' subdirectory of the project. For demonstrations, users can follow the 'Quick Start' section. For inquiries about the chip, users can contact SOPHGO via the official website.

ai-on-gke
This repository contains assets related to AI/ML workloads on Google Kubernetes Engine (GKE). Run optimized AI/ML workloads with Google Kubernetes Engine (GKE) platform orchestration capabilities. A robust AI/ML platform considers the following layers: Infrastructure orchestration that support GPUs and TPUs for training and serving workloads at scale Flexible integration with distributed computing and data processing frameworks Support for multiple teams on the same infrastructure to maximize utilization of resources

ray
Ray is a unified framework for scaling AI and Python applications. It consists of a core distributed runtime and a set of AI libraries for simplifying ML compute, including Data, Train, Tune, RLlib, and Serve. Ray runs on any machine, cluster, cloud provider, and Kubernetes, and features a growing ecosystem of community integrations. With Ray, you can seamlessly scale the same code from a laptop to a cluster, making it easy to meet the compute-intensive demands of modern ML workloads.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.

djl
Deep Java Library (DJL) is an open-source, high-level, engine-agnostic Java framework for deep learning. It is designed to be easy to get started with and simple to use for Java developers. DJL provides a native Java development experience and allows users to integrate machine learning and deep learning models with their Java applications. The framework is deep learning engine agnostic, enabling users to switch engines at any point for optimal performance. DJL's ergonomic API interface guides users with best practices to accomplish deep learning tasks, such as running inference and training neural networks.

mlflow
MLflow is a platform to streamline machine learning development, including tracking experiments, packaging code into reproducible runs, and sharing and deploying models. MLflow offers a set of lightweight APIs that can be used with any existing machine learning application or library (TensorFlow, PyTorch, XGBoost, etc), wherever you currently run ML code (e.g. in notebooks, standalone applications or the cloud). MLflow's current components are:
* `MLflow Tracking

tt-metal
TT-NN is a python & C++ Neural Network OP library. It provides a low-level programming model, TT-Metalium, enabling kernel development for Tenstorrent hardware.

burn
Burn is a new comprehensive dynamic Deep Learning Framework built using Rust with extreme flexibility, compute efficiency and portability as its primary goals.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.