
Speech-AI-Forge
🍦 Speech-AI-Forge is a project developed around TTS generation model, implementing an API Server and a Gradio-based WebUI.
Stars: 1155
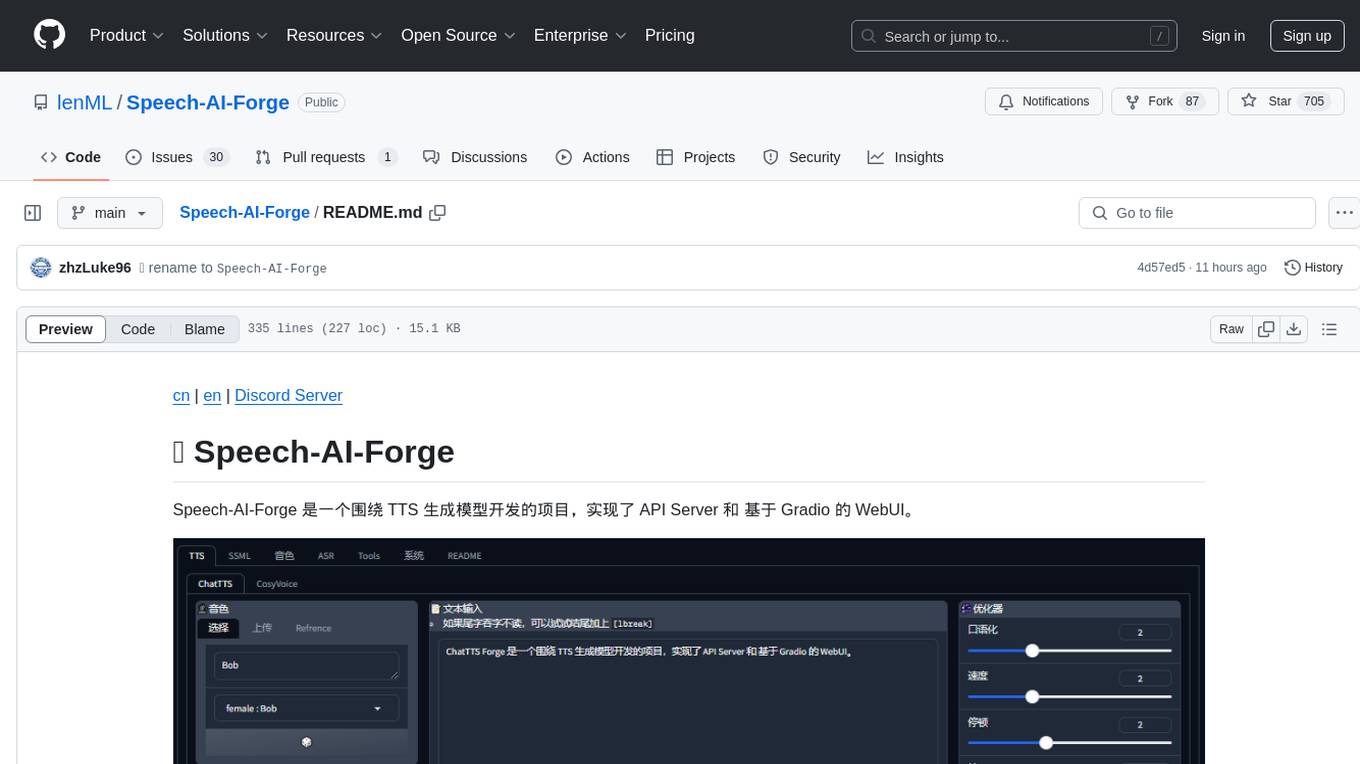
Speech-AI-Forge is a project developed around TTS generation models, implementing an API Server and a WebUI based on Gradio. The project offers various ways to experience and deploy Speech-AI-Forge, including online experience on HuggingFace Spaces, one-click launch on Colab, container deployment with Docker, and local deployment. The WebUI features include TTS model functionality, speaker switch for changing voices, style control, long text support with automatic text segmentation, refiner for ChatTTS native text refinement, various tools for voice control and enhancement, support for multiple TTS models, SSML synthesis control, podcast creation tools, voice creation, voice testing, ASR tools, and post-processing tools. The API Server can be launched separately for higher API throughput. The project roadmap includes support for various TTS models, ASR models, voice clone models, and enhancer models. Model downloads can be manually initiated using provided scripts. The project aims to provide inference services and may include training-related functionalities in the future.
README:
cn | en | Discord Server
Speech-AI-Forge 是一个围绕 TTS 生成模型开发的项目,实现了 API Server 和 基于 Gradio 的 WebUI。

你可以通过以下几种方式体验和部署 Speech-AI-Forge:
| - | 描述 | 链接 |
|---|---|---|
| 在线体验 | 部署于 HuggingFace 中 | HuggingFace Spaces |
| 一键启动 | 点击按钮,一键启动 Colab | |
| 容器部署 | 查看 docker 部分 | Docker |
| 本地部署 | 查看环境准备部分 | 本地部署 |
首先,确保 相关依赖 已经正确安装,并查看 模型下载 下载所需模型
启动:
python webui.py
-
TTS (文本转语音): 提供多种强大的 TTS 功能
-
音色切换 (Speaker Switch): 可选择不同音色
-
内置音色: 提供多个内置音色,包括
27 ChatTTS/7 CosyVoice音色 +1 参考音色 - 自定义音色上传: 支持上传自定义音色文件并进行实时推理
- 参考音色: 支持上传参考音频/文本,直接基于参考音频进行 TTS 推理
-
内置音色: 提供多个内置音色,包括
- 风格控制 (Style): 内置多种风格控制选项,调整语音风格
-
长文本推理 (Long Text): 支持超长文本的推理,自动分割文本
-
Batch Size: 支持设置
Batch size,提升支持批量推理模型的长文本推理速度
-
Batch Size: 支持设置
-
Refiner: 支持
ChatTTS原生文本refiner,支持无限长文本处理 -
分割器设置 (Splitter): 调整分割器配置,控制分割结束符(
eos)和分割阈值 -
调节器 (Adjuster): 支持调整
速度/音调/音量,并增加响度均衡功能,优化音频输出 -
人声增强 (Voice Enhancer): 使用
Enhancer模型增强 TTS 输出,提高语音质量 - 生成历史 (Generation History): 保存最近三次生成结果,便于对比和选择
-
多模型支持 (Multi-model Support): 支持多种 TTS 模型推理,包括
ChatTTS/CosyVoice/FishSpeech/GPT-SoVITS/F5-TTS等
-
音色切换 (Speaker Switch): 可选择不同音色
-
SSML (语音合成标记语言): 提供高级 TTS 合成控制工具
- 分割器 (Splitter): 精细控制长文本的分割结果
-
Podcast: 帮助创建
长文本、多角色的音频,适合博客或剧本式的语音合成 - From Subtitle: 从字幕文件生成 SSML 脚本,方便一键生成语音
- 脚本编辑器 (Script Editor): 新增 SSML 脚本编辑器,支持从分割器(Podcast、来自字幕)导出并编辑 SSML 脚本,进一步优化语音生成效果
-
音色管理 (Voice Management):
- 音色构建器 (Builder): 创建自定义音色,可从 ChatTTS seed 创建音色,或使用参考音频生成音色
- 试音功能 (Test Voice): 上传音色文件,进行简单的试音和效果评估
-
ChatTTS 调试工具: 专门针对
ChatTTS音色的调试工具- 音色抽卡 (Random Seed): 使用随机种子抽取不同的音色,生成独特的语音效果
- 音色融合 (Blend): 融合不同种子创建的音色,获得新的语音效果
- 音色 Hub: 从音色库中选择并下载音色到本地,访问音色仓库 Speech-AI-Forge-spks 获取更多音色资源
-
ASR (自动语音识别):
- Whisper: 使用 Whisper 模型进行高质量的语音转文本(ASR)
- SenseVoice: 正在开发中的 ASR 模型,敬请期待
-
工具 (Tools):
- 后处理工具 (Post Process): 提供音频剪辑、调整和增强等功能,优化生成的语音质量
某些情况,你并不需要 webui 或者需要更高的 api 吞吐,那么可以使用这个脚本启动单纯的 api 服务。
启动:
python launch.py
启动之后开启 http://localhost:7870/docs 可以查看开启了哪些 api 端点
更多帮助信息:
- 通过
python launch.py -h查看脚本参数 - 查看 API 文档
WIP 开发中
下载模型: python -m scripts.download_models --source modelscope
此脚本将下载
chat-tts和enhancer模型,如需下载其他模型,请看后续的模型下载介绍
- webui:
docker-compose -f ./docker-compose.webui.yml up -d - api:
docker-compose -f ./docker-compose.api.yml up -d
环境变量配置
- webui: .env.webui
- api: .env.api
| 模型类别 | 模型名称 | 流式级别 | 支持多语言 | 实现情况 |
|---|---|---|---|---|
| TTS | ChatTTS | token 级 | en, zh | ✅ |
| FishSpeech | 句子级 | en, zh, jp, ko | ✅ (1.4) | |
| CosyVoice | 句子级 | en, zh, jp, yue, ko | ✅(v2) | |
| FireRedTTS | 句子级 | en, zh | ✅ | |
| F5-TTS | 句子级 | en, zh | ✅ | |
| GPTSoVits | 句子级 | 🚧 | ||
| ASR | Whisper | 🚧 | ✅ | ✅ |
| SenseVoice | 🚧 | ✅ | 🚧 | |
| Voice Clone | OpenVoice | ✅ | ||
| RVC | 🚧 | |||
| Enhancer | ResembleEnhance | ✅ |
由于 Forge 主要面向 API 功能开发,目前尚未实现自动下载逻辑,下载模型需手动调用下载脚本,具体脚本位于 ./scripts 目录下。
| 功能 | 模型 | 下载命令 |
|---|---|---|
| TTS | ChatTTS | python -m scripts.dl_chattts --source huggingface |
| FishSpeech(1.4) | python -m scripts.downloader.fish_speech_1_4 --source huggingface |
|
| CosyVoice(v2) | python -m scripts.downloader.cosyvoice2 --source huggingface |
|
| FireRedTTS | python -m scripts.downloader.fire_red_tts --source huggingface |
|
| F5-TTS | python -m scripts.downloader.f5_tts --source huggingface |
|
| F5-TTS(vocos) | python -m scripts.downloader.vocos_mel_24khz --source huggingface |
|
| ASR | Whisper | python -m scripts.downloader.faster_whisper --source huggingface |
| CV | OpenVoice | python -m scripts.downloader.open_voice --source huggingface |
| Enhancer | 增强模型 | python -m scripts.dl_enhance --source huggingface |
注意:如果需要使用 ModelScope 下载模型,请使用
--source modelscope。部分模型可能无法使用 ModelScope 下载。
目前已经支持各个模型的语音复刻功能,且在 skpv1 格式中也适配了参考音频等格式,下面是几种方法使用语音复刻:
- 在 webui 中:在音色选择栏可以上传参考音色,这里可以最简单的使用语音复刻功能
- 使用 api 时:使用 api 需要通过音色(即说话人)来使用语音复刻功能,所以,首先你需要创建一个你需要的说话人文件(.spkv1.json),并在调用 api 时填入 spk 参数为说话人的 name,即可使用。
- Voice Clone:现在还支持使用 voice clone 模型进行语音复刻,使用 api 时配置相应
参考即可。(由于现目前只支持 OpenVoice 用于 voice clone,所以不需要指定模型名称)
相关讨论 #118
很大可能是上传音频配置有问题,所以建议一下几个方式解决:
- 更新:更新代码更新依赖库版本,最重要的是更新 gradio (不出意外的话推荐尽量用最新版本)
- 处理音频:用 ffmpeg 或者其他软件编辑音频,转为单声道然后再上传,也可以尝试转码为 wav 格式
- 检查文本:检查参考文本是否有不支持的字符。同时,建议参考文本使用
"。"号结尾(这是模型特性 😂) - 用 colab 创建:可以考虑使用
colab环境来创建 spk 文件,最大限度减少运行环境导致的问题 - TTS 测试:目前 webui tts 页面里,你可以直接上传参考音频,可以先测试音频和文本,调整之后,再生成 spk 文件
现在没有,本库主要是提供推理服务框架。 有计划增加一些训练相关的功能,但是预计不会太积极的推进。
首先,无特殊情况本库只计划整合和开发工程化方案,而对于模型推理优化比较依赖上游仓库或者社区实现 如果有好的推理优化欢迎提 issue 和 pr
现目前,最实际的优化是开启多 workers,启动 launch.py 脚本时开启 --workers N 以增加服务吞吐
还有其他待选不完善的提速优化,有兴趣的可尝试探索:
- compile: 模型都支持 compile 加速,大约有 30% 增益,但是编译期很慢
- flash_attn:使用 flash attn 加速,有支持(
--flash_attn参数),但是也不完善 - vllm:未实现,待上游仓库更新
仅限 ChatTTS
Prompt1 和 Prompt2 都是系统提示(system prompt),区别在于插入点不同。因为测试发现当前模型对第一个 [Stts] token 非常敏感,所以需要两个提示。
- Prompt1 插入到第一个 [Stts] 之前
- Prompt2 插入到第一个 [Stts] 之后
仅限 ChatTTS
Prefix 主要用于控制模型的生成能力,类似于官方示例中的 refine prompt。这个 prefix 中应该只包含特殊的非语素 token,如 [laugh_0]、[oral_0]、[speed_0]、[break_0] 等。
Style 中带有 _p 的使用了 prompt + prefix,而不带 _p 的则只使用 prefix。
由于还未实现推理 padding 所以如果每次推理 shape 改变都可能触发 torch 进行 compile
暂时不建议开启
请确保使用 gpu 而非 cpu。
- 点击菜单栏 【修改】
- 点击 【笔记本设置】
- 选择 【硬件加速器】 => T4 GPU
感谢 @Phrixus2023 提供的整合包: https://pan.baidu.com/s/1Q1vQV5Gs0VhU5J76dZBK4Q?pwd=d7xu
相关讨论: https://github.com/lenML/Speech-AI-Forge/discussions/65
在这里可以找到 更多文档
To contribute, clone the repository, make your changes, commit and push to your clone, and submit a pull request.
-
ChatTTS: https://github.com/2noise/ChatTTS
-
PaddleSpeech: https://github.com/PaddlePaddle/PaddleSpeech
-
resemble-enhance: https://github.com/resemble-ai/resemble-enhance
-
OpenVoice: https://github.com/myshell-ai/OpenVoice
-
FishSpeech: https://github.com/fishaudio/fish-speech
-
SenseVoice: https://github.com/FunAudioLLM/SenseVoice
-
CosyVoice: https://github.com/FunAudioLLM/CosyVoice
-
FireRedTTS: https://github.com/FireRedTeam/FireRedTTS
-
F5-TTS: https://github.com/SWivid/F5-TTS
-
Whisper: https://github.com/openai/whisper
-
ChatTTS 默认说话人: https://github.com/2noise/ChatTTS/issues/238
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Speech-AI-Forge
Similar Open Source Tools
Speech-AI-Forge
Speech-AI-Forge is a project developed around TTS generation models, implementing an API Server and a WebUI based on Gradio. The project offers various ways to experience and deploy Speech-AI-Forge, including online experience on HuggingFace Spaces, one-click launch on Colab, container deployment with Docker, and local deployment. The WebUI features include TTS model functionality, speaker switch for changing voices, style control, long text support with automatic text segmentation, refiner for ChatTTS native text refinement, various tools for voice control and enhancement, support for multiple TTS models, SSML synthesis control, podcast creation tools, voice creation, voice testing, ASR tools, and post-processing tools. The API Server can be launched separately for higher API throughput. The project roadmap includes support for various TTS models, ASR models, voice clone models, and enhancer models. Model downloads can be manually initiated using provided scripts. The project aims to provide inference services and may include training-related functionalities in the future.
prisma-ai
Prisma-AI is an open-source tool designed to assist users in their job search process by addressing common challenges such as lack of project highlights, mismatched resumes, difficulty in learning, and lack of answers in interview experiences. The tool utilizes AI to analyze user experiences, generate actionable project highlights, customize resumes for specific job positions, provide study materials for efficient learning, and offer structured interview answers. It also features a user-friendly interface for easy deployment and supports continuous improvement through user feedback and collaboration.
bailing
Bailing is an open-source voice assistant designed for natural conversations with users. It combines Automatic Speech Recognition (ASR), Voice Activity Detection (VAD), Large Language Model (LLM), and Text-to-Speech (TTS) technologies to provide a high-quality voice interaction experience similar to GPT-4o. Bailing aims to achieve GPT-4o-like conversation effects without the need for GPU, making it suitable for various edge devices and low-resource environments. The project features efficient open-source models, modular design allowing for module replacement and upgrades, support for memory function, tool integration for information retrieval and task execution via voice commands, and efficient task management with progress tracking and reminders.
Awesome-ChatTTS
Awesome-ChatTTS is an official recommended guide for ChatTTS beginners, compiling common questions and related resources. It provides a comprehensive overview of the project, including official introduction, quick experience options, popular branches, parameter explanations, voice seed details, installation guides, FAQs, and error troubleshooting. The repository also includes video tutorials, discussion community links, and project trends analysis. Users can explore various branches for different functionalities and enhancements related to ChatTTS.

UltraRAG
The UltraRAG framework is a researcher and developer-friendly RAG system solution that simplifies the process from data construction to model fine-tuning in domain adaptation. It introduces an automated knowledge adaptation technology system, supporting no-code programming, one-click synthesis and fine-tuning, multidimensional evaluation, and research-friendly exploration work integration. The architecture consists of Frontend, Service, and Backend components, offering flexibility in customization and optimization. Performance evaluation in the legal field shows improved results compared to VanillaRAG, with specific metrics provided. The repository is licensed under Apache-2.0 and encourages citation for support.
Feishu-MCP
Feishu-MCP is a server that provides access, editing, and structured processing capabilities for Feishu documents for Cursor, Windsurf, Cline, and other AI-driven coding tools, based on the Model Context Protocol server. This project enables AI coding tools to directly access and understand the structured content of Feishu documents, significantly improving the intelligence and efficiency of document processing. It covers the real usage process of Feishu documents, allowing efficient utilization of document resources, including folder directory retrieval, content retrieval and understanding, smart creation and editing, efficient search and retrieval, and more. It enhances the intelligent access, editing, and searching of Feishu documents in daily usage, improving content processing efficiency and experience.
XianyuAutoAgent
Xianyu AutoAgent is an AI customer service robot system specifically designed for the Xianyu platform, providing 24/7 automated customer service, supporting multi-expert collaborative decision-making, intelligent bargaining, and context-aware conversations. The system includes intelligent conversation engine with features like context awareness and expert routing, business function matrix with modules like core engine, bargaining system, technical support, and operation monitoring. It requires Python 3.8+ and NodeJS 18+ for installation and operation. Users can customize prompts for different experts and contribute to the project through issues or pull requests.
nndeploy
nndeploy is a tool that allows you to quickly build your visual AI workflow without the need for frontend technology. It provides ready-to-use algorithm nodes for non-AI programmers, including large language models, Stable Diffusion, object detection, image segmentation, etc. The workflow can be exported as a JSON configuration file, supporting Python/C++ API for direct loading and running, deployment on cloud servers, desktops, mobile devices, edge devices, and more. The framework includes mainstream high-performance inference engines and deep optimization strategies to help you transform your workflow into enterprise-level production applications.

agentica
Agentica is a human-centric framework for building large language model agents. It provides functionalities for planning, memory management, tool usage, and supports features like reflection, planning and execution, RAG, multi-agent, multi-role, and workflow. The tool allows users to quickly code and orchestrate agents, customize prompts, and make API calls to various services. It supports API calls to OpenAI, Azure, Deepseek, Moonshot, Claude, Ollama, and Together. Agentica aims to simplify the process of building AI agents by providing a user-friendly interface and a range of functionalities for agent development.

LLM-TPU
LLM-TPU project aims to deploy various open-source generative AI models on the BM1684X chip, with a focus on LLM. Models are converted to bmodel using TPU-MLIR compiler and deployed to PCIe or SoC environments using C++ code. The project has deployed various open-source models such as Baichuan2-7B, ChatGLM3-6B, CodeFuse-7B, DeepSeek-6.7B, Falcon-40B, Phi-3-mini-4k, Qwen-7B, Qwen-14B, Qwen-72B, Qwen1.5-0.5B, Qwen1.5-1.8B, Llama2-7B, Llama2-13B, LWM-Text-Chat, Mistral-7B-Instruct, Stable Diffusion, Stable Diffusion XL, WizardCoder-15B, Yi-6B-chat, Yi-34B-chat. Detailed model deployment information can be found in the 'models' subdirectory of the project. For demonstrations, users can follow the 'Quick Start' section. For inquiries about the chip, users can contact SOPHGO via the official website.

Native-LLM-for-Android
This repository provides a demonstration of running a native Large Language Model (LLM) on Android devices. It supports various models such as Qwen2.5-Instruct, MiniCPM-DPO/SFT, Yuan2.0, Gemma2-it, StableLM2-Chat/Zephyr, and Phi3.5-mini-instruct. The demo models are optimized for extreme execution speed after being converted from HuggingFace or ModelScope. Users can download the demo models from the provided drive link, place them in the assets folder, and follow specific instructions for decompression and model export. The repository also includes information on quantization methods and performance benchmarks for different models on various devices.
vscode-antigravity-cockpit
VS Code extension for monitoring Google Antigravity AI model quotas. It provides a webview dashboard, QuickPick mode, quota grouping, automatic grouping, renaming, card view, drag-and-drop sorting, status bar monitoring, threshold notifications, and privacy mode. Users can monitor quota status, remaining percentage, countdown, reset time, progress bar, and model capabilities. The extension supports local and authorized quota monitoring, multiple account authorization, and model wake-up scheduling. It also offers settings customization, user profile display, notifications, and group functionalities. Users can install the extension from the Open VSX Marketplace or via VSIX file. The source code can be built using Node.js and npm. The project is open-source under the MIT license.
MaiBot
MaiBot is an interactive intelligent agent based on a large language model. It aims to be an 'entity' active in QQ group chats, focusing on human-like interactions. It features personification in language style, behavior planning, expression learning, plugin system for unlimited extensions, and emotion expression. The project's design philosophy emphasizes creating a 'life form' in group chats that feels real rather than perfect, with the goal of providing companionship through an AI that makes mistakes and has its own perceptions and thoughts. The code is open-source, but the runtime data of MaiBot is intended to remain closed to maintain its autonomy and conversational nature.
ChatTTS-Forge
ChatTTS-Forge is a powerful text-to-speech generation tool that supports generating rich audio long texts using a SSML-like syntax and provides comprehensive API services, suitable for various scenarios. It offers features such as batch generation, support for generating super long texts, style prompt injection, full API services, user-friendly debugging GUI, OpenAI-style API, Google-style API, support for SSML-like syntax, speaker management, style management, independent refine API, text normalization optimized for ChatTTS, and automatic detection and processing of markdown format text. The tool can be experienced and deployed online through HuggingFace Spaces, launched with one click on Colab, deployed using containers, or locally deployed after cloning the project, preparing models, and installing necessary dependencies.
AI0x0.com
AI 0x0 is a versatile AI query generation desktop floating assistant application that supports MacOS and Windows. It allows users to utilize AI capabilities in any desktop software to query and generate text, images, audio, and video data, helping them work more efficiently. The application features a dynamic desktop floating ball, floating dialogue bubbles, customizable presets, conversation bookmarking, preset packages, network acceleration, query mode, input mode, mouse navigation, deep customization of ChatGPT Next Web, support for full-format libraries, online search, voice broadcasting, voice recognition, voice assistant, application plugins, multi-model support, online text and image generation, image recognition, frosted glass interface, light and dark theme adaptation for each language model, and free access to all language models except Chat0x0 with a key.

Open-dLLM
Open-dLLM is the most open release of a diffusion-based large language model, providing pretraining, evaluation, inference, and checkpoints. It introduces Open-dCoder, the code-generation variant of Open-dLLM. The repo offers a complete stack for diffusion LLMs, enabling users to go from raw data to training, checkpoints, evaluation, and inference in one place. It includes pretraining pipeline with open datasets, inference scripts for easy sampling and generation, evaluation suite with various metrics, weights and checkpoints on Hugging Face, and transparent configs for full reproducibility.
For similar tasks
Speech-AI-Forge
Speech-AI-Forge is a project developed around TTS generation models, implementing an API Server and a WebUI based on Gradio. The project offers various ways to experience and deploy Speech-AI-Forge, including online experience on HuggingFace Spaces, one-click launch on Colab, container deployment with Docker, and local deployment. The WebUI features include TTS model functionality, speaker switch for changing voices, style control, long text support with automatic text segmentation, refiner for ChatTTS native text refinement, various tools for voice control and enhancement, support for multiple TTS models, SSML synthesis control, podcast creation tools, voice creation, voice testing, ASR tools, and post-processing tools. The API Server can be launched separately for higher API throughput. The project roadmap includes support for various TTS models, ASR models, voice clone models, and enhancer models. Model downloads can be manually initiated using provided scripts. The project aims to provide inference services and may include training-related functionalities in the future.
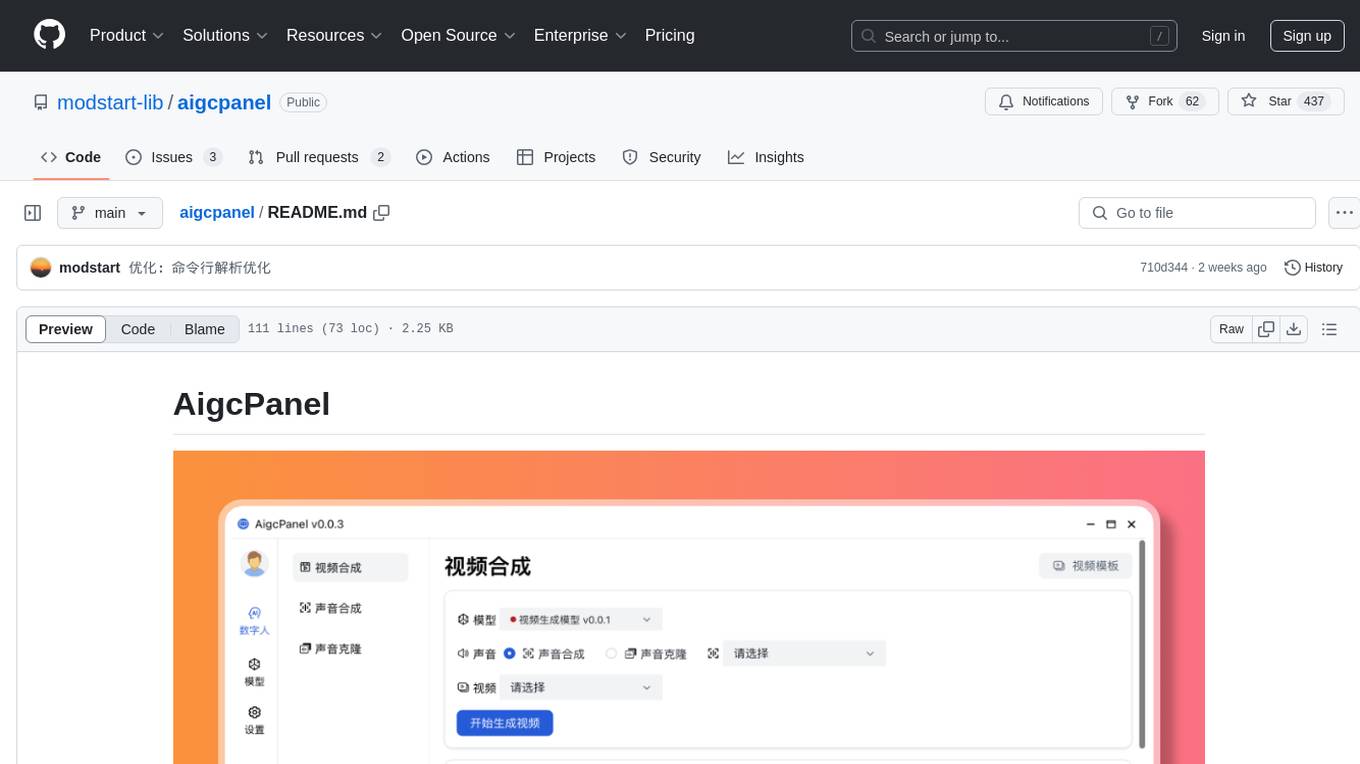
aigcpanel
AigcPanel is a simple and easy-to-use all-in-one AI digital human system that even beginners can use. It supports video synthesis, voice synthesis, voice cloning, simplifies local model management, and allows one-click import and use of AI models. It prohibits the use of this product for illegal activities and users must comply with the laws and regulations of the People's Republic of China.
AivisSpeech
AivisSpeech is a Japanese text-to-speech software based on the VOICEVOX editor UI. It incorporates the AivisSpeech Engine for generating emotionally rich voices easily. It supports AIVMX format voice synthesis model files and specific model architectures like Style-Bert-VITS2. Users can download AivisSpeech and AivisSpeech Engine for Windows and macOS PCs, with minimum memory requirements specified. The development follows the latest version of VOICEVOX, focusing on minimal modifications, rebranding only where necessary, and avoiding refactoring. The project does not update documentation, maintain test code, or refactor unused features to prevent conflicts with VOICEVOX.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.