Best AI tools for< Speech Engineer >
Infographic
20 - AI tool Sites
Deepgram
Deepgram is a powerful API platform that provides developers with tools for building speech-to-text, text-to-speech, and intelligence applications. With Deepgram, developers can easily add speech recognition, text-to-speech, and other AI-powered features to their applications.
VoxSigma
Vocapia Research develops leading-edge, multilingual speech processing technologies exploiting AI methods such as machine learning. These technologies enable large vocabulary continuous speech recognition, automatic audio segmentation, language identification, speaker diarization and audio-text synchronization. Vocapia's VoxSigma™ speech-to-text software suite delivers state-of-the-art performance in many languages for a variety of audio data types, including broadcast data, parliamentary hearings and conversational data.
SoundHound
SoundHound is a leading innovator of conversational intelligence and voice AI technologies. Our independent voice AI platform is built for more natural conversation, enabling businesses to create customized and scalable voice AI solutions for their specific industries and use cases. With SoundHound, you can build voice assistants, enhance smart devices, improve customer experiences, and drive business value.
Ragobble
Ragobble is an audio to LLM data tool that allows you to easily convert audio files into text data that can be used to train large language models (LLMs). With Ragobble, you can quickly and easily create high-quality training data for your LLM projects.

Speech Studio
Speech Studio is a cloud-based speech-to-text and text-to-speech platform that enables developers to add speech capabilities to their applications. With Speech Studio, developers can easily transcribe audio and video files, generate synthetic speech, and build custom speech models. Speech Studio is a powerful tool that can be used to improve the accessibility, efficiency, and user experience of any application.
Interesting Engineering
Interesting Engineering is a website that covers the latest news and developments in technology, science, innovation, and engineering. The website features articles, videos, and podcasts on a wide range of topics, including artificial intelligence, robotics, space exploration, and renewable energy. Interesting Engineering also offers a variety of educational resources, such as courses, workshops, and webinars.
Respeecher
Respeecher is a voice cloning software that allows users to create synthetic voices that are indistinguishable from the original speaker. The software is used by content creators in a variety of industries, including film, television, gaming, advertising, and audiobooks. Respeecher's technology is based on artificial intelligence and machine learning, and it can replicate the voice of any person with just a few minutes of audio recording. The software is easy to use and can be accessed through a web interface. Respeecher offers a variety of features, including the ability to change the pitch, speed, and volume of the synthetic voice, as well as the ability to add effects such as reverb and delay. The software also includes a library of pre-recorded voices that can be used for a variety of purposes.
AssemblyAI
AssemblyAI is an industry-leading Speech AI tool that offers powerful SpeechAI models for accurate transcription and understanding of speech. It provides breakthrough speech-to-text models, real-time captioning, and advanced speech understanding capabilities. AssemblyAI is designed to help developers build world-class products with unmatched accuracy and transformative audio intelligence.
ChatTTS
ChatTTS is an open-source text-to-speech model designed for dialogue scenarios, supporting both English and Chinese speech generation. Trained on approximately 100,000 hours of Chinese and English data, it delivers speech quality comparable to human dialogue. The tool is particularly suitable for tasks involving large language model assistants and creating dialogue-based audio and video introductions. It provides developers with a powerful and easy-to-use tool based on open-source natural language processing and speech synthesis technologies.

babs.ai
babs.ai is an AI-powered job matching platform that connects talent with opportunities. It leverages intelligent matching algorithms to streamline the recruitment process and ensure a seamless experience for both job seekers and employers. The platform caters to a wide range of job roles and industries, making it a versatile solution for all types of users.

Voam
Voam is a productive AI platform that helps you to automate your tasks and improve your productivity. With Voam, you can create custom AI models to automate any task, from simple data entry to complex decision-making. Voam is easy to use and requires no coding experience. You can create an AI model in minutes and start automating your tasks right away.
Auphonic
Auphonic is an AI-powered audio post-production web tool designed to help users achieve professional-quality audio results effortlessly. It offers a range of features such as Intelligent Leveler, Noise & Reverb Reduction, Filtering & AutoEQ, Cut Filler Words and Silence, Multitrack Algorithms, Loudness Specifications, Speech2Text & Automatic Shownotes, Video Support, Metadata & Chapters, and more. Auphonic is widely used by podcasters, educators, content creators, and audiobook producers to enhance their audio content and streamline their workflows. With its intuitive interface and advanced algorithms, Auphonic simplifies the audio editing process and ensures consistent audio quality across different platforms.
Picovoice
Picovoice is an on-device Voice AI and local LLM platform designed for enterprises. It offers a range of voice AI and LLM solutions, including speech-to-text, noise suppression, speaker recognition, speech-to-index, wake word detection, and more. Picovoice empowers developers to build virtual assistants and AI-powered products with compliance, reliability, and scalability in mind. The platform allows enterprises to process data locally without relying on third-party remote servers, ensuring data privacy and security. With a focus on cutting-edge AI technology, Picovoice enables users to stay ahead of the curve and adapt quickly to changing customer needs.
LMNT
LMNT is an ultrafast lifelike AI speech pricing API that offers low latency streaming for conversational apps, agents, and games. It provides lifelike voices through studio-quality voice clones and instant voice clones. Engineered by an ex-Google team, LMNT ensures reliable performance under pressure with consistent low latency and high availability. The platform enables real-time conversation, content creation at scale, and product marketing through captivating voiceovers. With a user-friendly interface and developer API, LMNT simplifies voice cloning and synthesis for both beginners and professionals.

Error 404 Not Found
The website displays a '404: NOT_FOUND' error message indicating that the deployment cannot be found. It provides a code 'DEPLOYMENT_NOT_FOUND' and an ID 'sin1::t6mdp-1736442717535-3a5d4eeaf597'. Users are directed to refer to the documentation for further information and troubleshooting.
Resemble AI
Resemble AI is an advanced AI tool offering a range of features such as AI Voice Generator, Deepfake Detection, Voice Cloning, Text-to-Speech, Speech-to-Speech, Multilingual support, Audio Editing, and more. It provides state-of-the-art AI models for voice generation and detection, helping users create realistic voices and detect deepfakes across various media types. The platform is trusted by millions of users worldwide, including Fortune 500 companies and government agencies, for its innovative solutions in generative AI and security.
AppTek
AppTek is a global leader in artificial intelligence (AI) and machine learning (ML) technologies for automatic speech recognition (ASR), neural machine translation (NMT), natural language processing/understanding (NLP/U) and text-to-speech (TTS) technologies. The AppTek platform delivers industry-leading solutions for organizations across a breadth of global markets such as media and entertainment, call centers, government, enterprise business, and more. Built by scientists and research engineers who are recognized among the best in the world, AppTek’s solutions cover a wide array of languages/ dialects, channels, domains and demographics.
Respeecher
Respeecher is an AI tool that combines technology and magic to deliver authentic voices across various industries. It uses cutting-edge public models and proprietary technology to provide high-quality voice solutions. The team of dedicated sound professionals at Respeecher ensures ethical use of synthetic media, making it a trusted choice for voice cloning and voice conversion services.
Globose Technology Solutions
Globose Technology Solutions Pvt Ltd (GTS) is an AI data collection company that provides various datasets such as image datasets, video datasets, text datasets, speech datasets, etc., to train machine learning models. They offer premium data collection services with a human touch, aiming to refine AI vision and propel AI forward. With over 25+ years of experience, they specialize in data management, annotation, and effective data collection techniques for AI/ML. The company focuses on unlocking high-quality data, understanding AI's transformative impact, and ensuring data accuracy as the backbone of reliable AI.
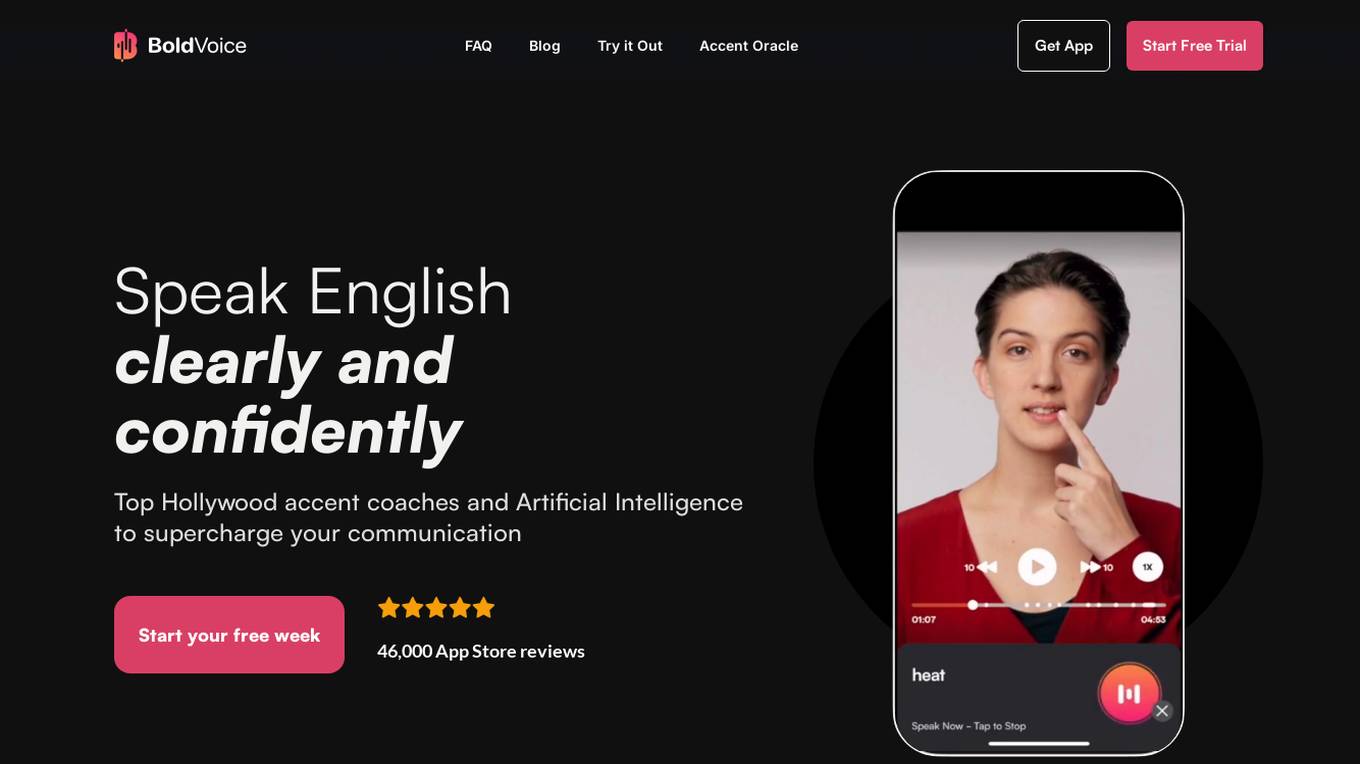
BoldVoice
BoldVoice is an American accent training application that utilizes Artificial Intelligence technology to help users improve their English pronunciation and fluency. The app offers personalized lessons, instant AI feedback on pronunciation, and guidance from top Hollywood accent coaches. Users can practice words, sentences, and conversations to enhance their speaking skills. With just 10 minutes of daily practice, users can see noticeable improvements in their accent within a few months. BoldVoice has received positive reviews from users worldwide, praising its effectiveness in helping them speak English clearly and confidently.
8 - Open Source Tools
ChatTTS-Forge
ChatTTS-Forge is a powerful text-to-speech generation tool that supports generating rich audio long texts using a SSML-like syntax and provides comprehensive API services, suitable for various scenarios. It offers features such as batch generation, support for generating super long texts, style prompt injection, full API services, user-friendly debugging GUI, OpenAI-style API, Google-style API, support for SSML-like syntax, speaker management, style management, independent refine API, text normalization optimized for ChatTTS, and automatic detection and processing of markdown format text. The tool can be experienced and deployed online through HuggingFace Spaces, launched with one click on Colab, deployed using containers, or locally deployed after cloning the project, preparing models, and installing necessary dependencies.

openedai-speech
OpenedAI Speech is a free, private text-to-speech server compatible with the OpenAI audio/speech API. It offers custom voice cloning and supports various models like tts-1 and tts-1-hd. Users can map their own piper voices and create custom cloned voices. The server provides multilingual support with XTTS voices and allows fixing incorrect sounds with regex. Recent changes include bug fixes, improved error handling, and updates for multilingual support. Installation can be done via Docker or manual setup, with usage instructions provided. Custom voices can be created using Piper or Coqui XTTS v2, with guidelines for preparing audio files. The tool is suitable for tasks like generating speech from text, creating custom voices, and multilingual text-to-speech applications.
RealtimeSTT_LLM_TTS
RealtimeSTT is an easy-to-use, low-latency speech-to-text library for realtime applications. It listens to the microphone and transcribes voice into text, making it ideal for voice assistants and applications requiring fast and precise speech-to-text conversion. The library utilizes Voice Activity Detection, Realtime Transcription, and Wake Word Activation features. It supports GPU-accelerated transcription using PyTorch with CUDA support. RealtimeSTT offers various customization options for different parameters to enhance user experience and performance. The library is designed to provide a seamless experience for developers integrating speech-to-text functionality into their applications.
Speech-AI-Forge
Speech-AI-Forge is a project developed around TTS generation models, implementing an API Server and a WebUI based on Gradio. The project offers various ways to experience and deploy Speech-AI-Forge, including online experience on HuggingFace Spaces, one-click launch on Colab, container deployment with Docker, and local deployment. The WebUI features include TTS model functionality, speaker switch for changing voices, style control, long text support with automatic text segmentation, refiner for ChatTTS native text refinement, various tools for voice control and enhancement, support for multiple TTS models, SSML synthesis control, podcast creation tools, voice creation, voice testing, ASR tools, and post-processing tools. The API Server can be launched separately for higher API throughput. The project roadmap includes support for various TTS models, ASR models, voice clone models, and enhancer models. Model downloads can be manually initiated using provided scripts. The project aims to provide inference services and may include training-related functionalities in the future.
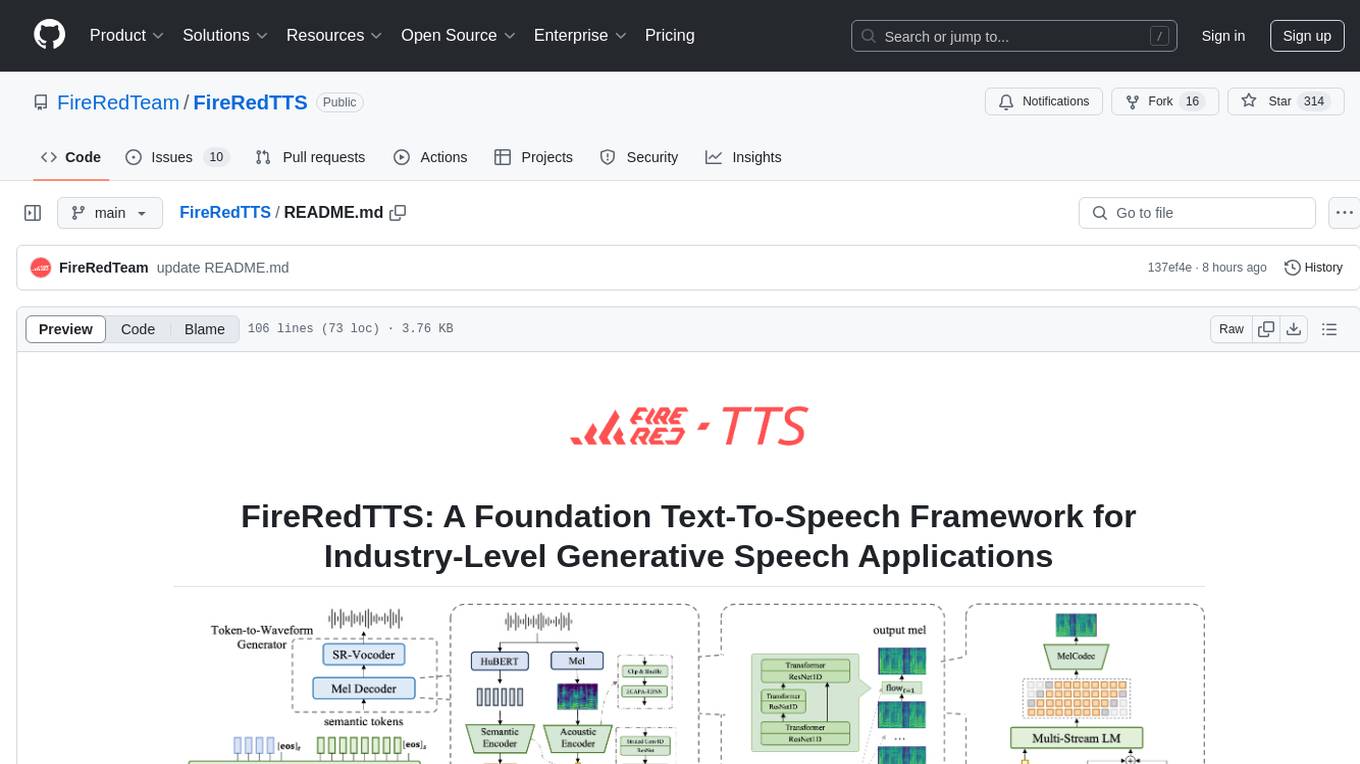
FireRedTTS
FireRedTTS is a foundation text-to-speech framework designed for industry-level generative speech applications. It offers a rich-punctuation model with expanded punctuation coverage and enhanced audio production consistency. The tool provides pre-trained checkpoints, inference code, and an interactive demo space. Users can clone the repository, create a conda environment, download required model files, and utilize the tool for synthesizing speech in various languages. FireRedTTS aims to enhance stability and provide controllable human-like speech generation capabilities.
viitor-voice
ViiTor-Voice is an LLM based TTS Engine that offers a lightweight design with 0.5B parameters for efficient deployment on various platforms. It provides real-time streaming output with low latency experience, a rich voice library with over 300 voice options, flexible speech rate adjustment, and zero-shot voice cloning capabilities. The tool supports both Chinese and English languages and is suitable for applications requiring quick response and natural speech fluency.
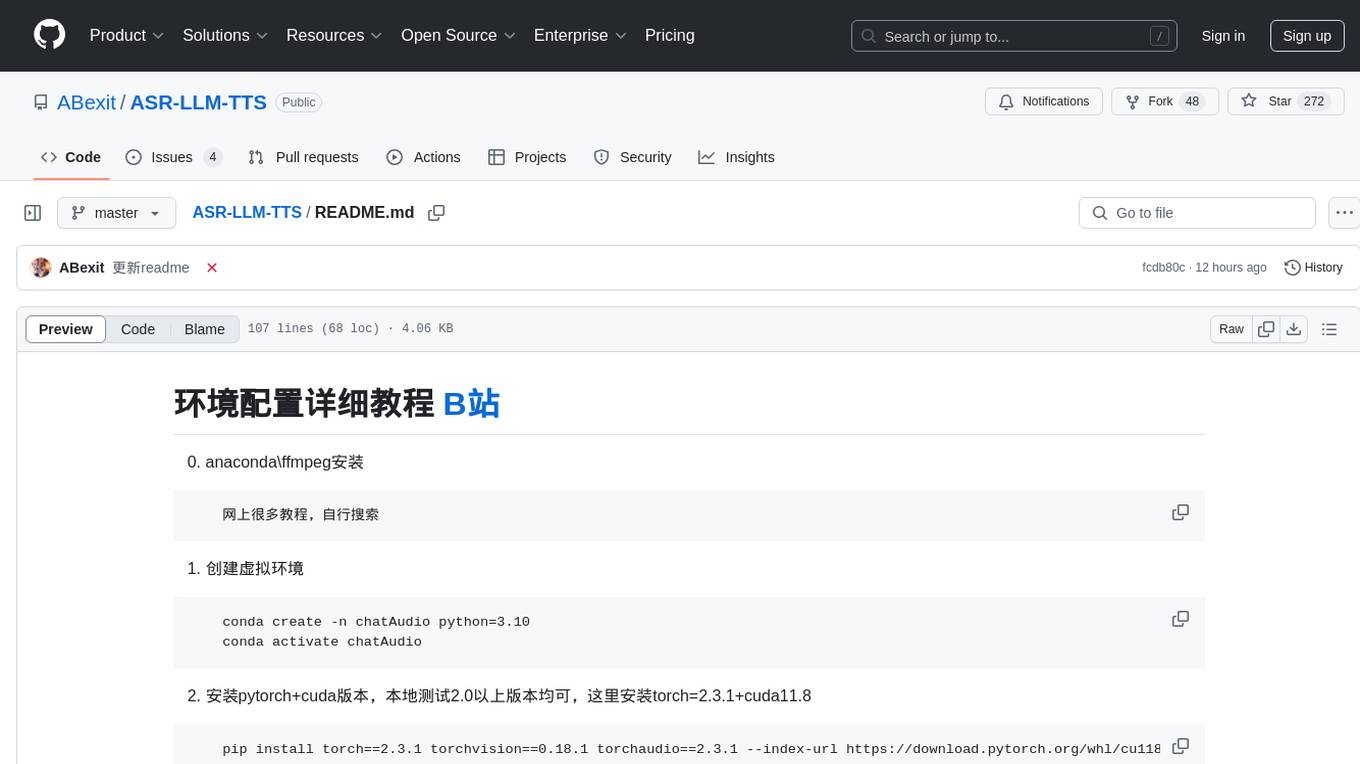
ASR-LLM-TTS
ASR-LLM-TTS is a repository that provides detailed tutorials for setting up the environment, including installing anaconda, ffmpeg, creating virtual environments, and installing necessary libraries such as pytorch, torchaudio, edge-tts, funasr, and more. It also introduces features like voiceprint recognition, custom wake words, and conversation history memory. The repository combines CosyVoice for speech synthesis, SenceVoice for speech recognition, and QWen2.5 for dialogue understanding. It offers multiple speech synthesis methods including CoosyVoice, pyttsx3, and edgeTTS, with scripts for interactive inference provided. The repository aims to enable real-time speech interaction and multi-modal interactions involving audio and video.

MOSS-TTS
MOSS-TTS Family is an open-source speech and sound generation model family designed for high-fidelity, high-expressiveness, and complex real-world scenarios. It includes five production-ready models: MOSS-TTS, MOSS-TTSD, MOSS-VoiceGenerator, MOSS-TTS-Realtime, and MOSS-SoundEffect, each serving specific purposes in speech generation, dialogue, voice design, real-time interactions, and sound effect generation. The models offer features like long-speech generation, fine-grained control over phonemes and duration, multilingual synthesis, voice cloning, and real-time voice agents.
20 - OpenAI Gpts
Deep Learning Master
Guiding you through the depths of deep learning with accuracy and respect.
AI Speech Guide
A helpful coach for speech writing, offering constructive advice and support
Dedicated Speech-Language Pathologist
Expert Speech-Language Pathologist offering tailored medical consultations.
Speech Parody
Create speech transcript parodies. Copyright (C) 2023, Sourceduty - All Rights Reserved.

Detailed Speech Drafting Wizard
Crafts speeches from PowerPoint slides and reference materials, adding depth and context.
AI.EX Wedding Speech Consultant
Your partner in crafting perfect wedding speeches. Let me be your guide to writing impactful, memorable speeches for unforgettable moments.

AI Phonetics and Reading Coach with Speech
Phonetics and reading coach with interactive voice capabilities, tailored for adult beginners.

SpeechTherapist GPT
Your very own speech therapy assistant. Completely private and confidential.

Cat Translator
Your Feline Language Specialist for translating human speech to cat sounds.