
viitor-voice
An LLM base TTS engine
Stars: 60
ViiTor-Voice is an LLM based TTS Engine that offers a lightweight design with 0.5B parameters for efficient deployment on various platforms. It provides real-time streaming output with low latency experience, a rich voice library with over 300 voice options, flexible speech rate adjustment, and zero-shot voice cloning capabilities. The tool supports both Chinese and English languages and is suitable for applications requiring quick response and natural speech fluency.
README:

-
2024.12.14:
- demo
- Adjusted model input by removing speaker embeddings (we found that existing open-source speaker models struggle to capture speaker characteristics effectively and have limited generalization capabilities).
- Supports zero-shot voice cloning.
- Supports both Chinese and English languages.
-
Lightweight Design
The model is simple and efficient, compatible with most LLM inference engines. With only 0.5B parameters, it achieves extreme optimization of computational resources while maintaining high performance. This design allows the model to be deployed not only on servers but also on mobile devices and edge computing environments, meeting diverse deployment needs.
-
Real-time Streaming Output, Low Latency Experience
The model supports real-time speech generation, suitable for applications that demand low latency. On the Tesla T4 platform, it achieves an industry-leading first-frame latency of 200ms, providing users with nearly imperceptible instant feedback, ideal for interactive applications requiring quick response.
-
Rich Voice Library
Offers more than 300 different voice options, allowing you to choose the most suitable speech style according to your needs and preferences. Whether it’s a formal business presentation or casual entertainment content, the model provides perfect voice matching.
-
Flexible Speech Rate Adjustment
The model supports natural variations in speech rate, allowing users to easily adjust it based on content requirements and audience preferences. Whether speeding up for efficient information delivery or slowing down to enhance emotional depth, it maintains natural speech fluency.
-
Zero-shot Voice Cloning (Under Research)
Decoder-only architecture naturally supports Zero-shot cloning, with future support for rapid voice cloning based on minimal voice samples.
git clone https://github.com/viitor-ai/viitor-voice.git
cd viitor-voice
conda create -n viitor_voice python=3.10
conda activate viitor_voice
pip install -r requirements.txt
### Due to the issue with vllm's tokenizer length calculation, the token limit cannot take effect.
python_package_path=`pip show pip | egrep Location | awk -F ' ' '{print $2}'`
cp viitor_voice/utils/patch.py $python_package_path/vllm/entrypoints/openai/logits_processors.py
-
English(deprecated) -
Chinese(deprecated) - Chinese & English
For GPU users
from viitor_voice.inference.vllm_engine import VllmEngine
import torchaudio
tts_engine = VllmEngine(model_path="ZzWater/viitor-voice-mix")
## chinese example
ref_audio = "reference_samples/reference_samples/chinese_female.wav"
ref_text = "博士,您工作辛苦了!"
text_list = ["我觉得我还能抢救一下的!", "我…我才不要和你一起!"]
audios = tts_engine.batch_infer(text_list, ref_audio, ref_text)
for i, audio in enumerate(audios):
torchaudio.save('test_chinese_{}.wav'.format(i), audios[0], 24000)
# english example
ref_audio = "reference_samples/reference_samples/english_female.wav"
ref_text = "At dinner, he informed me that he was a trouble shooter for a huge international organization."
text_list = ["Working overtime feels like running a marathon with no finish line in sight—just endless tasks and a growing sense that my life is being lived in the office instead of the real world."]
audios = tts_engine.batch_infer(text_list, ref_audio, ref_text)
for i, audio in enumerate(audios):
torchaudio.save('test_english_{}.wav'.format(i), audios[0], 24000) For CPU users
from viitor_voice.inference.transformers_engine import TransformersEngine
import torchaudio
tts_engine = TransformersEngine(model_path="ZzWater/viitor-voice-mix", device='cpu')
## chinese example
ref_audio = "reference_samples/reference_samples/chinese_female.wav"
ref_text = "博士,您工作辛苦了!"
text_list = ["我觉得我还能抢救一下的!", "我…我才不要和你一起!"]
audios = tts_engine.batch_infer(text_list, ref_audio, ref_text)
for i, audio in enumerate(audios):
torchaudio.save('test_chinese_{}.wav'.format(i), audios[0], 24000)
# english example
ref_audio = "reference_samples/reference_samples/english_female.wav"
ref_text = "At dinner, he informed me that he was a trouble shooter for a huge international organization."
text_list = [" Working overtime feels like running a marathon with no finish line in sight", " Just endless tasks and a growing sense that my life is being lived in the office instead of the real world."]
audios = tts_engine.batch_infer(text_list, ref_audio, ref_text)
for i, audio in enumerate(audios):
torchaudio.save('test_english_{}.wav'.format(i), audios[0], 24000) python gradio_demo.pyHave questions about the project? Want to discuss new features, report bugs, or just chat with other contributors? Join our Discord community!
This project is licensed under CC BY-NC 4.0.
You are free to share and modify the code of this project for non-commercial purposes, under the following conditions:
- Attribution: You must give appropriate credit, provide a link to the license, and indicate if changes were made.
- Non-Commercial: You may not use the material for commercial purposes.
Copyright Notice:
© 2024 Livedata. All Rights Reserved.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for viitor-voice
Similar Open Source Tools
viitor-voice
ViiTor-Voice is an LLM based TTS Engine that offers a lightweight design with 0.5B parameters for efficient deployment on various platforms. It provides real-time streaming output with low latency experience, a rich voice library with over 300 voice options, flexible speech rate adjustment, and zero-shot voice cloning capabilities. The tool supports both Chinese and English languages and is suitable for applications requiring quick response and natural speech fluency.
TileRT
TileRT is a project designed to serve large language models (LLMs) in ultra-low-latency scenarios. It aims to push the latency limits of LLMs without compromising model size or quality, enabling models with hundreds of billions of parameters to achieve millisecond-level time per output token. TileRT prioritizes responsiveness for applications like high-frequency trading, interactive AI, real-time decision-making, long-running agents, and AI-assisted coding. It introduces a tile-level runtime engine that dynamically reschedules computation, I/O, and communication across multiple devices to minimize idle time and improve hardware utilization. The project is actively evolving, with compiler techniques gradually shared with the community through TileLang and TileScale.

zenml
ZenML is an extensible, open-source MLOps framework for creating portable, production-ready machine learning pipelines. By decoupling infrastructure from code, ZenML enables developers across your organization to collaborate more effectively as they develop to production.

LightAgent
LightAgent is a lightweight, open-source Agentic AI development framework with memory, tools, and a tree of thought. It supports multi-agent collaboration, autonomous learning, tool integration, complex task handling, and multi-model support. It also features a streaming API, tool generator, agent self-learning, adaptive tool mechanism, and more. LightAgent is designed for intelligent customer service, data analysis, automated tools, and educational assistance.

MInference
MInference is a tool designed to accelerate pre-filling for long-context Language Models (LLMs) by leveraging dynamic sparse attention. It achieves up to a 10x speedup for pre-filling on an A100 while maintaining accuracy. The tool supports various decoding LLMs, including LLaMA-style models and Phi models, and provides custom kernels for attention computation. MInference is useful for researchers and developers working with large-scale language models who aim to improve efficiency without compromising accuracy.

sdialog
SDialog is an MIT-licensed open-source toolkit for building, simulating, and evaluating LLM-based conversational agents end-to-end. It aims to bridge agent construction, user simulation, dialog generation, and evaluation in a single reproducible workflow, enabling the generation of reliable, controllable dialog systems or data at scale. The toolkit standardizes a Dialog schema, offers persona-driven multi-agent simulation with LLMs, provides composable orchestration for precise control over behavior and flow, includes built-in evaluation metrics, and offers mechanistic interpretability. It allows for easy creation of user-defined components and interoperability across various AI platforms.

YuE
YuE (乐) is an open-source foundation model designed for music generation, specifically transforming lyrics into full songs. It can generate complete songs in various genres and vocal styles, ensuring a polished and cohesive result. The model requires significant GPU memory for generating long sequences and recommends specific configurations for optimal performance. Users can customize the number of sessions for memory usage. The tool provides a quickstart guide for generating music using Transformers and includes tips for execution time and tag selection. The project is licensed under Creative Commons Attribution Non Commercial 4.0.
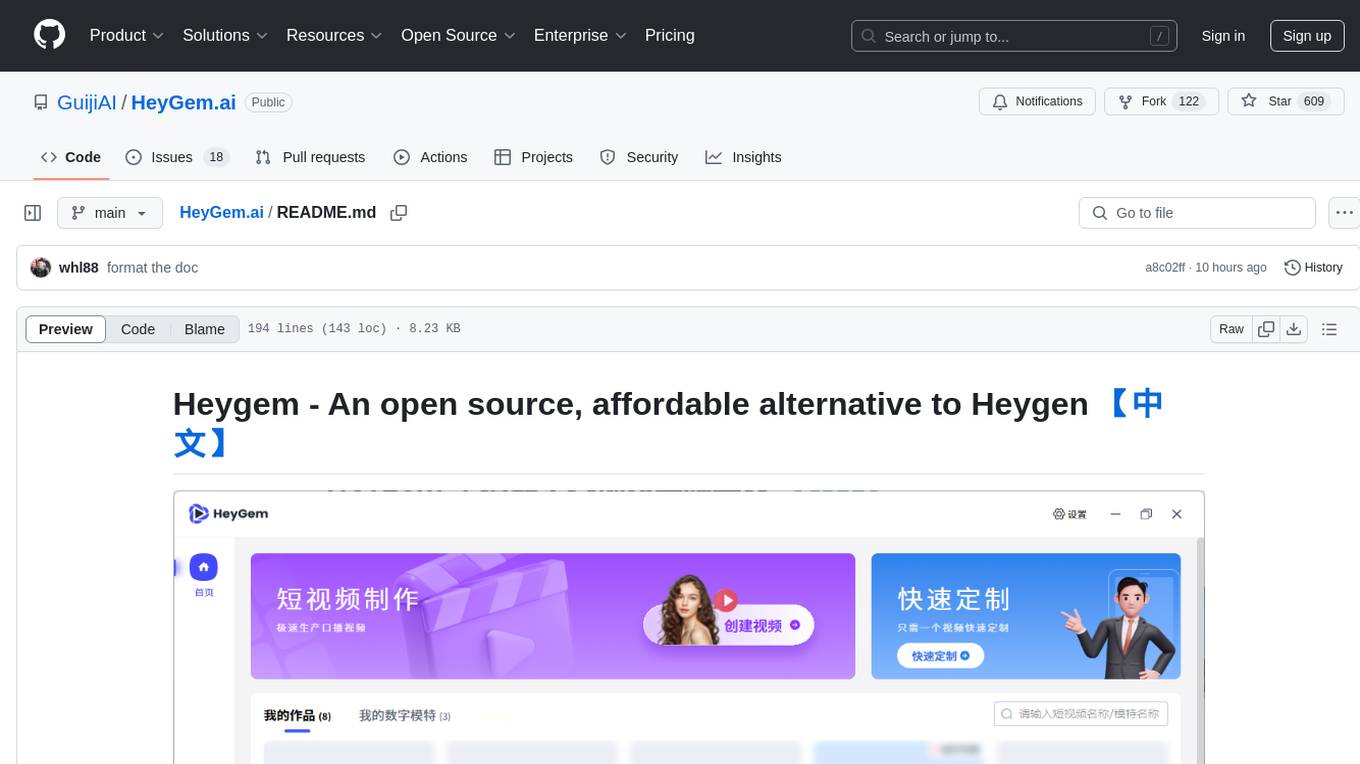
HeyGem.ai
Heygem is an open-source, affordable alternative to Heygen, offering a fully offline video synthesis tool for Windows systems. It enables precise appearance and voice cloning, allowing users to digitalize their image and drive virtual avatars through text and voice for video production. With core features like efficient video synthesis and multi-language support, Heygem ensures a user-friendly experience with fully offline operation and support for multiple models. The tool leverages advanced AI algorithms for voice cloning, automatic speech recognition, and computer vision technology to enhance the virtual avatar's performance and synchronization.
Open-LLM-VTuber
Open-LLM-VTuber is a voice-interactive AI companion supporting real-time voice conversations and featuring a Live2D avatar. It can run offline on Windows, macOS, and Linux, offering web and desktop client modes. Users can customize appearance and persona, with rich LLM inference, text-to-speech, and speech recognition support. The project is highly customizable, extensible, and actively developed with exciting features planned. It provides privacy with offline mode, persistent chat logs, and various interaction features like voice interruption, touch feedback, Live2D expressions, pet mode, and more.

DemoGPT
DemoGPT is an all-in-one agent library that provides tools, prompts, frameworks, and LLM models for streamlined agent development. It leverages GPT-3.5-turbo to generate LangChain code, creating interactive Streamlit applications. The tool is designed for creating intelligent, interactive, and inclusive solutions in LLM-based application development. It offers model flexibility, iterative development, and a commitment to user engagement. Future enhancements include integrating Gorilla for autonomous API usage and adding a publicly available database for refining the generation process.

swiftide
Swiftide is a fast, streaming indexing and query library tailored for Retrieval Augmented Generation (RAG) in AI applications. It is built in Rust, utilizing parallel, asynchronous streams for blazingly fast performance. With Swiftide, users can easily build AI applications from idea to production in just a few lines of code. The tool addresses frustrations around performance, stability, and ease of use encountered while working with Python-based tooling. It offers features like fast streaming indexing pipeline, experimental query pipeline, integrations with various platforms, loaders, transformers, chunkers, embedders, and more. Swiftide aims to provide a platform for data indexing and querying to advance the development of automated Large Language Model (LLM) applications.

basiclingua-LLM-Based-NLP
BasicLingua is a Python library that provides functionalities for linguistic tasks such as tokenization, stemming, lemmatization, and many others. It is based on the Gemini Language Model, which has demonstrated promising results in dealing with text data. BasicLingua can be used as an API or through a web demo. It is available under the MIT license and can be used in various projects.

tinyllm
tinyllm is a lightweight framework designed for developing, debugging, and monitoring LLM and Agent powered applications at scale. It aims to simplify code while enabling users to create complex agents or LLM workflows in production. The core classes, Function and FunctionStream, standardize and control LLM, ToolStore, and relevant calls for scalable production use. It offers structured handling of function execution, including input/output validation, error handling, evaluation, and more, all while maintaining code readability. Users can create chains with prompts, LLM models, and evaluators in a single file without the need for extensive class definitions or spaghetti code. Additionally, tinyllm integrates with various libraries like Langfuse and provides tools for prompt engineering, observability, logging, and finite state machine design.
autonomous-intelligence
Tau is an autonomous robot project inspired by Pi.AI, designed for continual conversation with a single context. It features speech-based interaction, memory management, and integration with vision services. The project aims to create a local AI companion with personality, suitable for experimentation and development. Key components include long and immediate memory, speech-to-text and text-to-speech capabilities, and integration with Nvidia Jetson and Hailo vision services. Tau is open-source and encourages community contributions and experimentation.
lorax
LoRAX is a framework that allows users to serve thousands of fine-tuned models on a single GPU, dramatically reducing the cost of serving without compromising on throughput or latency. It features dynamic adapter loading, heterogeneous continuous batching, adapter exchange scheduling, optimized inference, and is ready for production with prebuilt Docker images, Helm charts for Kubernetes, Prometheus metrics, and distributed tracing with Open Telemetry. LoRAX supports a number of Large Language Models as the base model including Llama, Mistral, and Qwen, and any of the linear layers in the model can be adapted via LoRA and loaded in LoRAX.
tuff
Tuff is a local-first, AI-native, and infinitely extensible desktop command center designed to enhance workflow efficiency. It offers a seamless integration of core utilities, AI-powered search, contextual intelligence, and extensibility through custom plugins. With a beautiful UI design, rich functionality, simple operations, and a focus on security and reliability, Tuff provides users with a cross-platform desktop software that is easy to use and offers a good user experience.
For similar tasks
viitor-voice
ViiTor-Voice is an LLM based TTS Engine that offers a lightweight design with 0.5B parameters for efficient deployment on various platforms. It provides real-time streaming output with low latency experience, a rich voice library with over 300 voice options, flexible speech rate adjustment, and zero-shot voice cloning capabilities. The tool supports both Chinese and English languages and is suitable for applications requiring quick response and natural speech fluency.
langport
LangPort is an open-source platform for serving large language models. It aims to provide a super fast LLM inference service with core features including Huggingface transformers support, distributed serving system, streaming generation, batch inference, and support for various model architectures. It offers compatibility with OpenAI, FauxPilot, HuggingFace, and Tabby APIs. The project supports model architectures like LLaMa, GLM, GPT2, and GPT Neo, and has been tested with models such as NingYu, Vicuna, ChatGLM, and WizardLM. LangPort also provides features like dynamic batch inference, int4 quantization, and generation logprobs parameter.

metavoice-src
MetaVoice-1B is a 1.2B parameter base model trained on 100K hours of speech for TTS (text-to-speech). It has been built with the following priorities: * Emotional speech rhythm and tone in English. * Zero-shot cloning for American & British voices, with 30s reference audio. * Support for (cross-lingual) voice cloning with finetuning. * We have had success with as little as 1 minute training data for Indian speakers. * Synthesis of arbitrary length text

wunjo.wladradchenko.ru
Wunjo AI is a comprehensive tool that empowers users to explore the realm of speech synthesis, deepfake animations, video-to-video transformations, and more. Its user-friendly interface and privacy-first approach make it accessible to both beginners and professionals alike. With Wunjo AI, you can effortlessly convert text into human-like speech, clone voices from audio files, create multi-dialogues with distinct voice profiles, and perform real-time speech recognition. Additionally, you can animate faces using just one photo combined with audio, swap faces in videos, GIFs, and photos, and even remove unwanted objects or enhance the quality of your deepfakes using the AI Retouch Tool. Wunjo AI is an all-in-one solution for your voice and visual AI needs, offering endless possibilities for creativity and expression.

Pandrator
Pandrator is a GUI tool for generating audiobooks and dubbing using voice cloning and AI. It transforms text, PDF, EPUB, and SRT files into spoken audio in multiple languages. It leverages XTTS, Silero, and VoiceCraft models for text-to-speech conversion and voice cloning, with additional features like LLM-based text preprocessing and NISQA for audio quality evaluation. The tool aims to be user-friendly with a one-click installer and a graphical interface.
ruoyi-ai
ruoyi-ai is a platform built on top of ruoyi-plus to implement AI chat and drawing functionalities on the backend. The project is completely open source and free. The backend management interface uses elementUI, while the server side is built using Java 17 and SpringBoot 3.X. It supports various AI models such as ChatGPT4, Dall-E-3, ChatGPT-4-All, voice cloning based on GPT-SoVITS, GPTS, and MidJourney. Additionally, it supports WeChat mini programs, personal QR code real-time payments, monitoring and AI auto-reply in live streaming rooms like Douyu and Bilibili, and personal WeChat integration with ChatGPT. The platform also includes features like private knowledge base management and provides various demo interfaces for different platforms such as mobile, web, and PC.

ebook2audiobook
ebook2audiobook is a CPU/GPU converter tool that converts eBooks to audiobooks with chapters and metadata using tools like Calibre, ffmpeg, XTTSv2, and Fairseq. It supports voice cloning and a wide range of languages. The tool is designed to run on 4GB RAM and provides a new v2.0 Web GUI interface for user-friendly interaction. Users can convert eBooks to text format, split eBooks into chapters, and utilize high-quality text-to-speech functionalities. Supported languages include Arabic, Chinese, English, French, German, Hindi, and many more. The tool can be used for legal, non-DRM eBooks only and should be used responsibly in compliance with applicable laws.
HeyGem.ai
Heygem is an open-source, affordable alternative to Heygen, offering a fully offline video synthesis tool for Windows systems. It enables precise appearance and voice cloning, allowing users to digitalize their image and drive virtual avatars through text and voice for video production. With core features like efficient video synthesis and multi-language support, Heygem ensures a user-friendly experience with fully offline operation and support for multiple models. The tool leverages advanced AI algorithms for voice cloning, automatic speech recognition, and computer vision technology to enhance the virtual avatar's performance and synchronization.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.