
APOLLO
APOLLO: SGD-like Memory, AdamW-level Performance
Stars: 175
APOLLO is a memory-efficient optimizer designed for large language model (LLM) pre-training and full-parameter fine-tuning. It offers SGD-like memory cost with AdamW-level performance. The optimizer integrates low-rank approximation and optimizer state redundancy reduction to achieve significant memory savings while maintaining or surpassing the performance of Adam(W). Key contributions include structured learning rate updates for LLM training, approximated channel-wise gradient scaling in a low-rank auxiliary space, and minimal-rank tensor-wise gradient scaling. APOLLO aims to optimize memory efficiency during training large language models.
README:
APOLLO is archievd at Figshare with DOI: https://doi.org/10.6084/m9.figshare.28558319.v1 for MLSys artifact evaluation.
A memory-efficient optimizer designed for large language model (LLM) pre-training and full-parameter fine-tuning, offering SGD-like memory cost with AdamW-level performance.
🔗 Paper • Project Page • Video • Hugging Face Transformers • LLaMA-Factory • FluxML • Hacker News

-
[2025/2] APOLLO is accepted to MLSys 2025, cheers!
-
[2025/2] APOLLO is integrated into Hugging Face Transformers. Try APOLLO with Hugging Face trainer!
-
[2025/2] Fix the compatibility issue of quantized APOLLO with bitsandbytes.
-
[2025/1] APOLLO is integrated into LLaMA-Factory. Try it for memory-efficient LLM full-parameter fine-tuning.
-
[2024/12] We are happy to release the official implementation of APOLLO v1.0.0 in PyPI (see here). We support QAPOLLO using int8 weight quantization from Q-Galore.
-
[2024/12] APOLLO validated by third-party Julia implementation!: Our APOLLO optimizer has been independently validated by a third party using a Julia implementation. Check out the post. They are also working to integrate APOLLO into FluxML.
-
[2024/12] APOLLO Paper Released: Our paper is now available on arXiv! Check it out here: [Paper].
We introduce APOLLO (Approximated Gradient Scaling for Memory Efficient LLM Optimization), a novel method designed to optimize the memory efficiency of training large language models (LLM), offering SGD-like memory cost while delivering AdamW-level performance for both pre-training and finetuning!
APOLLO effectively integrates two major ideas for memory-efficient LLM training: low-rank approximation (GaLore) and optimizer state redundancy reduction (Adam-mini). However, APOLLO takes memory efficiency to a new level, achieving significant memory savings (below GaLore and its variants, and close to SGD) while maintaining or surpassing the performance of Adam(W).
Our key contributions include:
-
Structured Learning Rate Updates for LLM Training: We identify that structured learning rate updates, such as channel-wise or tensor-wise scaling, are sufficient for LLM training. This approach explores redundancy in AdamW's element-wise learning rate update rule, forming a basis for our APOLLO method.
-
Approximated Channel-wise Gradient Scaling in a Low-Rank Auxiliary Space (APOLLO):
APOLLO proposes a practical and memory-efficient method to approximate channel-wise gradient scaling factors in an auxiliary low-rank space using pure random projections. This method achieves superior performance compared to AdamW, even with lower-rank approximations, while maintaining excellent memory efficiency. -
Minimal-Rank Tensor-wise Gradient Scaling (APOLLO-Mini):
APOLLO-Mini introduces extreme memory efficiency by applying tensor-wise gradient scaling using only a rank-1 auxiliary sub-space. This results in SGD-level memory costs while outperforming AdamW, showcasing the effectiveness of the approach.
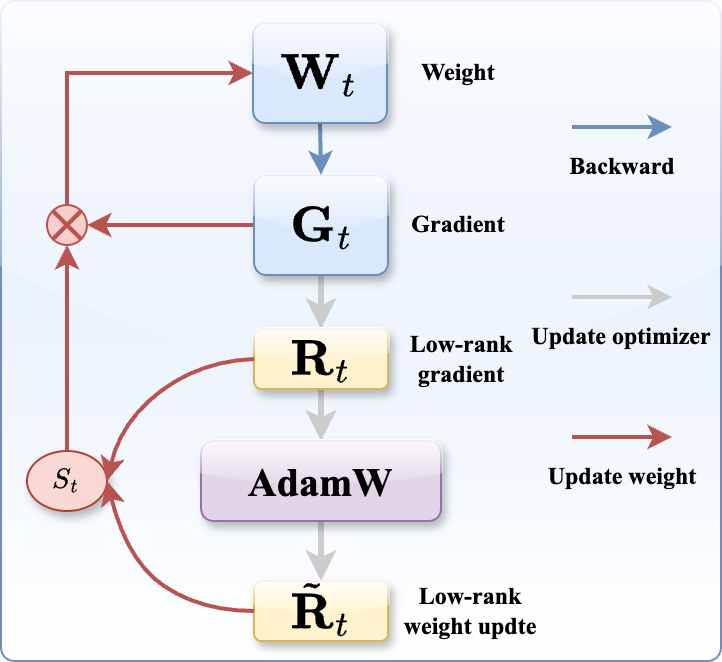
Figure 1: The APOLLO Framework for Memory-Efficient LLM Training. The channel-wise or tensor-wise gradient scaling factor is obtained via an auxiliary low-rank optimizer state, constructed using pure random projection (no SVD required).
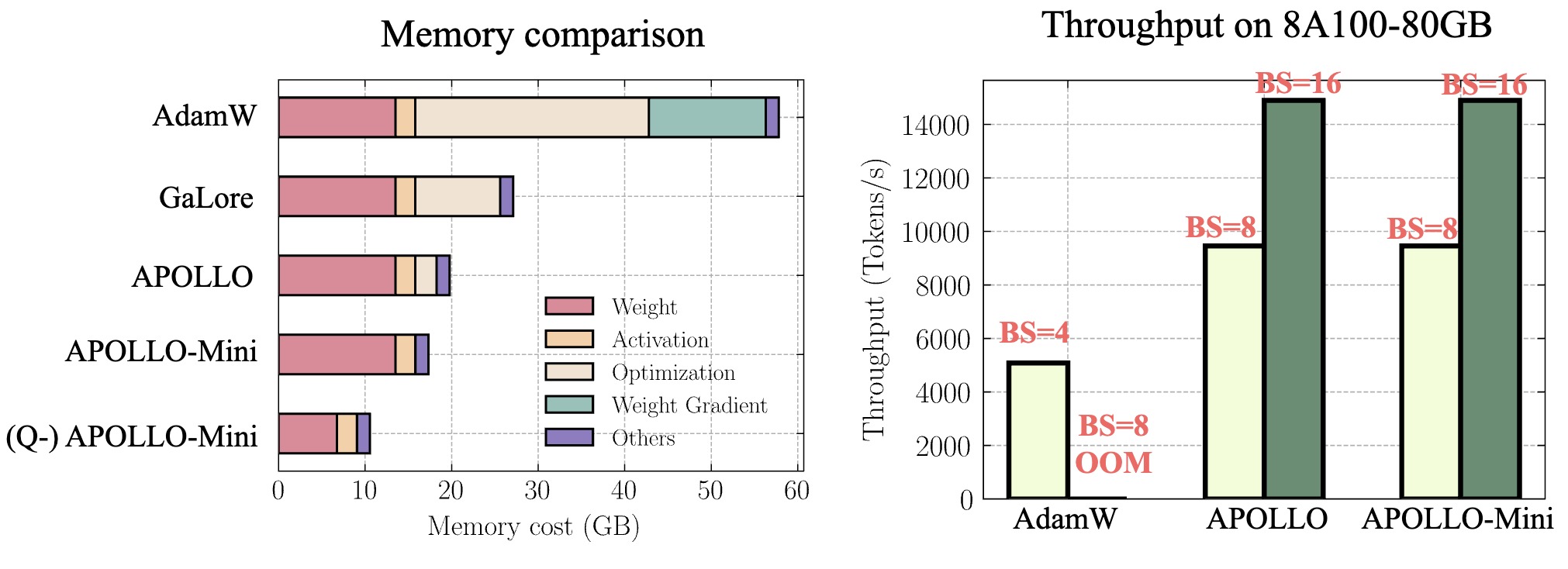
Figure 2: System Benefits of APOLLO for Pre-training LLaMA 7B. (left): Memory breakdown comparison for a single batch size; (right): End-to-end training throughput on 8 A100-80GB GPUs
You can install the APOLLO optimizer directly from pip:
pip install apollo-torchTo install APOLLO from the source code:
git clone https://github.com/zhuhanqing/APOLLO.git
cd APOLLO
pip install -e .pip install -r exp_requirements.txtfrom apollo_torch import APOLLOAdamW
# define param groups as lowrank_params and regular params
param_groups = [{'params': non_lowrank_params},
{'params':
lowrank_params,
'rank': 1,
'proj': 'random',
'scale_type': 'tensor',
'scale': 128,
'update_proj_gap': 200,
'proj_type': 'std'}]
optimizer = APOLLO(param_groups, lr=0.01)
For APOLLO and APOLLO-Mini, we have the following arguments
- Specifies the rank of the auxiliary sub-space used for gradient scaling.
-
Default value:
-
256for APOLLO works well for 1B and 7B model. -
1for APOLLO-Mini.
-
- Determines how the scaling factors are applied:
-
channel: Applies gradient scaling at the channel level (APOLLO) -
tensor: Applies gradient scaling at the tensor level (APOLLO-Mini).
-
The scale parameter plays a crucial role in heuristically adjusting gradient updates to compensate for scaling factor approximation errors arising from the use of a lower rank. Proper tuning of this parameter can significantly improve performance:
-
1: Default value for APOLLO (validated on A100 GPUs). -
128: Default value for APOLLO-Mini. For larger models, experimenting with higher values is recommended.
To stabilize training, we adopt the Norm-Growth Limiter (NL) from Fira, which has shown to be slightly more effective than traditional gradient clipping.
There are two ways to apply the Norm-Growth Limiter based on when it's used relative to the heuristical (scale):
-
After Scaling: NL is applied after the gradient is multiplied by the
scale.- Recommended for when training involves fewer warmup steps, e.g., LLaMA 60M and 130M with APOLLO-Mini.
- Enable this by setting
--scale_front.
-
Before Scaling: NL is applied before the gradient is scaled.
- With sufficient warmup steps, both methods yield similar performance for large models.
We provide the command in scripts/benchmark_c4 for pretraining LLaMA model with sizes from 60M to 7B on C4 dataset.
# num_rank: 1 for APOLLO-Mini, 1/4 of the original dim for APOLLO (same as Galore)
# scale_type: channel or tensor
# projection type: random (option: svd)
# scale: related with rank, larger rank generally works well with smaller scale, we use 128 for rank=1
Compared to academic settings, the industry trains large language models (LLMs) with significantly longer context windows (1k-8k tokens) and on hundreds of billions of tokens.
Accordingly, we further validate the effectiveness of the APOLLO series by pre-training a LLaMA-350M on a 1024-token context window—four times larger than the original GaLore usage. To establish a robust baseline, we vary AdamW’s learning rate across [1e-3, 2.5e-3, 5e-3, 7.5e-3, 1e-2]. We also “lazily” tune the scale factor of the APOLLO series by testing APOLLO in [√1, √2, √3] and APOLLO-Mini in [√128, √256, √384], while keeping the learning rate fixed at 1e-2.
Both APOLLO and APOLLO-Mini demonstrate superior performance compared to AdamW, while drastically reducing optimizer memory usage—by as much as 1/8 or even 1/1024 of AdamW’s requirements. Moreover, these methods tend to exhibit even stronger performance in later stages, when more training tokens are involved. This makes them a highly promising option for partial LLM pre-training scenarios involving long context windows and trillions of training tokens.
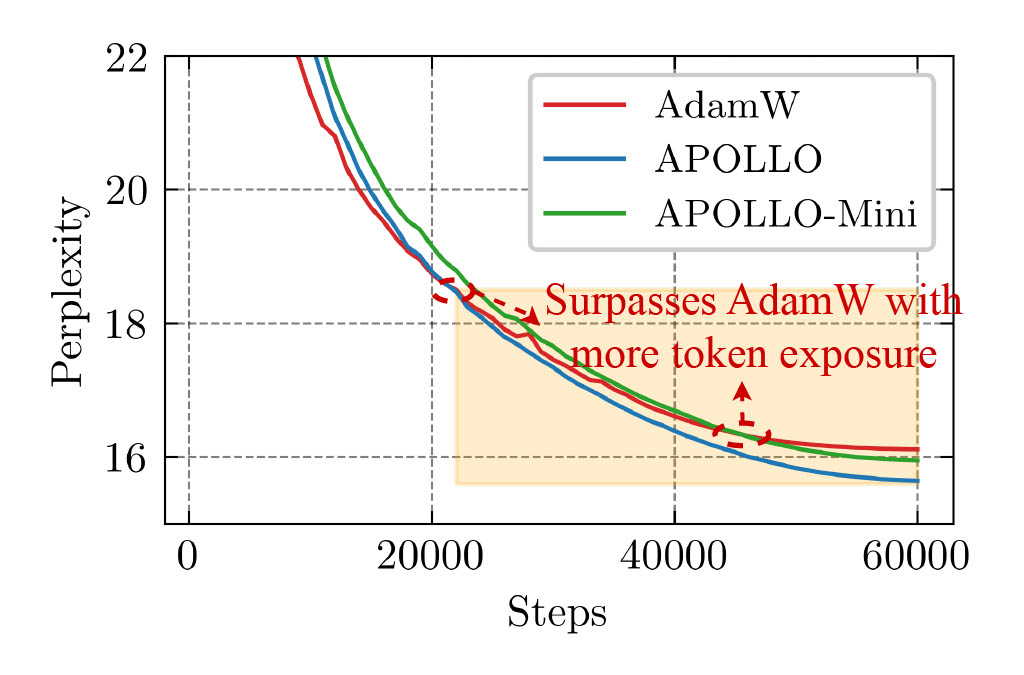
Figure 3: Perplexity curves of the LLaMA-350M model trained in a long-context window setting.
The command of training LLaMA-7B model on single GPU as provided within scripts/single_gpu. With 1 batch size, the following scripts can pre-train a LLaMA-7B model within 11GB memory (tested on a single A100 GPU)
Now we support APOLLO in LLaMA-Factory. We have added a test in the examples/extras/apollo directory.
We conducted a comparative evaluation with GaLore by fine-tuning models and testing on the MMLU task.
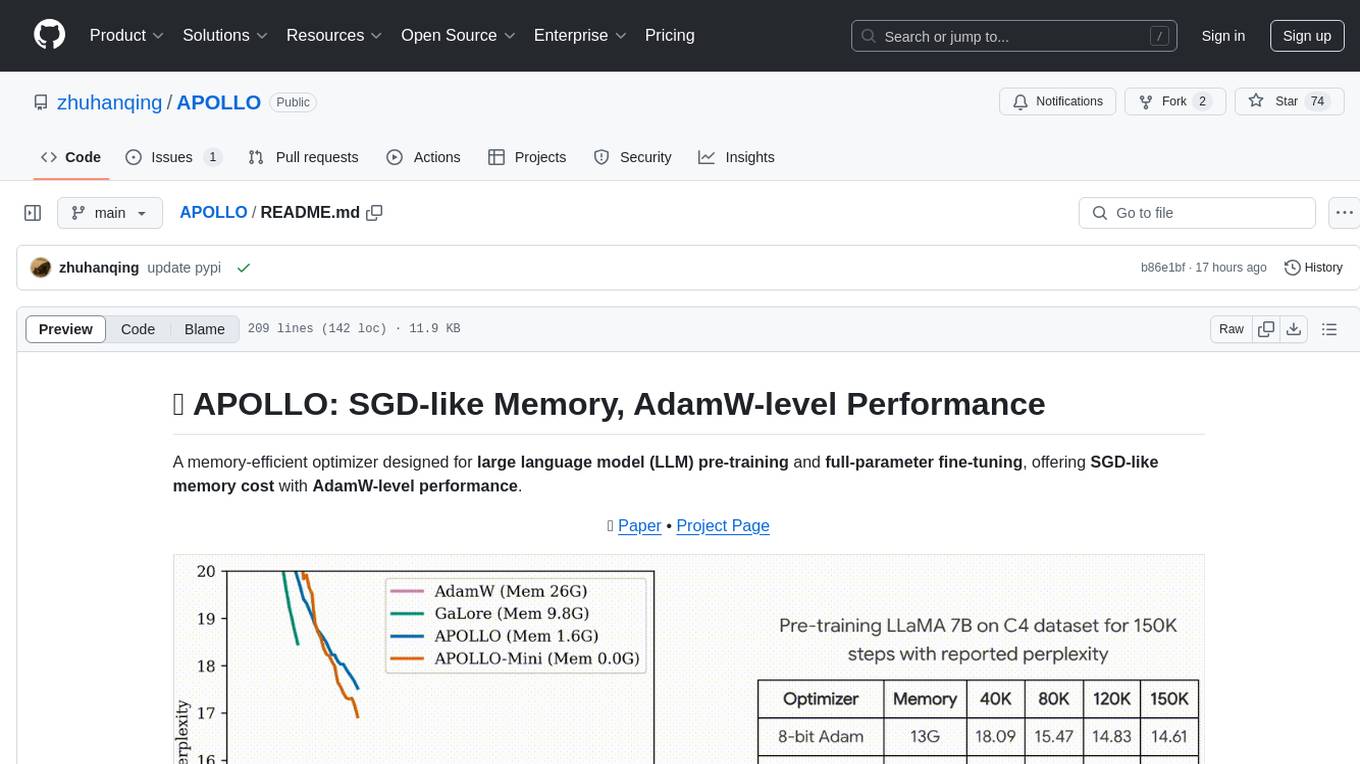
Average: 64.96
STEM: 55.43
Social Sciences: 75.66
Humanities: 59.72
Other: 71.25
With a scaling factor derived from the ratio of LLaMA-8B dimension (4096) to rank (128):
Average: 65.03
STEM: 55.47
Social Sciences: 76.15
Humanities: 59.60
Other: 71.28
Large language models (LLMs) demonstrate remarkable capabilities but are notoriously memory-intensive during training, particularly with the popular Adam optimizer. This memory burden often necessitates using more GPUs, smaller batch sizes, or high-end hardware, thereby limiting scalability and training efficiency. To address this, various memory-efficient optimizers have been proposed to reduce optimizer memory usage. However, they face key challenges: (i) reliance on costly SVD operations (e.g., GaLore, Fira); (ii) significant performance trade-offs compared to AdamW (e.g., Flora); and (iii) still substantial memory overhead of optimization states in order to maintain competitive performance (e.g., 1/4 rank in Galore, and full-rank first momentum in Adam-mini).
In this work, we investigate the redundancy in Adam's learning rate adaption rule and identify that it can be coarsened as a structured learning rate update (channel-wise or tensor-wise). Based on this insight, we propose a novel approach, Approximated Gradient Scaling for Memory Efficient LLM Optimization (APOLLO), which approximate the channel-wise learning rate scaling with an auxiliary low-rank optimizer state based on pure random projection. The structured learning rate update rule makes APOLLO highly tolerant to further memory reduction with lower rank, halving the rank while delivering similar pre-training performance. We further propose an extreme memory-efficient version, APOLLO-mini, which utilizes tensor-wise scaling with only a rank-1 auxiliary sub-space, achieving SGD-level memory cost but superior pre-training performance than Adam(W).
We conduct extensive experiments across different tasks and model architectures, showing that APOLLO series performs generally on-par with, or even better than Adam(W). Meanwhile, APOLLO achieves even greater memory savings than Galore, by almost eliminating the optimization states in AdamW. These savings translate into significant system benefits:
- Enhanced Throughput: APOLLO and APOLLO-mini achieve up to 3x throughput on a 4xA100-80GB setup compared to Adam by fully utilizing memory to support 4x larger batch sizes.
- Improved Model Scalability: APOLLO-mini for the first time enables pre-training LLaMA-13B model with naive DDP on A100-80G without requiring other system-level optimizations
- Low-End GPU Pre-training: Combined with quantization, the APOLLO series for the first time enables the training of LLaMA-7B from scratch using less than 12 GB of memory.
- [ ] Support APOLLO with FSDP.
For questions or collaboration inquiries, feel free to reach out our core contributors:
- 📧 Email: [email protected]
- 📧 Email: [email protected]
If you find APOLLO useful in your work, please consider citing our paper:
@misc{zhu2024apollosgdlikememoryadamwlevel,
title={APOLLO: SGD-like Memory, AdamW-level Performance},
author={Hanqing Zhu and Zhenyu Zhang and Wenyan Cong and Xi Liu and Sem Park and Vikas Chandra and Bo Long and David Z. Pan and Zhangyang Wang and Jinwon Lee},
year={2024},
eprint={2412.05270},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2412.05270},
}The majority of APOLLO is licensed under CC-BY-NC, however portions of the project are available under separate license terms: GaLore is licensed under the Apache 2.0 license.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for APOLLO
Similar Open Source Tools
APOLLO
APOLLO is a memory-efficient optimizer designed for large language model (LLM) pre-training and full-parameter fine-tuning. It offers SGD-like memory cost with AdamW-level performance. The optimizer integrates low-rank approximation and optimizer state redundancy reduction to achieve significant memory savings while maintaining or surpassing the performance of Adam(W). Key contributions include structured learning rate updates for LLM training, approximated channel-wise gradient scaling in a low-rank auxiliary space, and minimal-rank tensor-wise gradient scaling. APOLLO aims to optimize memory efficiency during training large language models.
TileRT
TileRT is a project designed to serve large language models (LLMs) in ultra-low-latency scenarios. It aims to push the latency limits of LLMs without compromising model size or quality, enabling models with hundreds of billions of parameters to achieve millisecond-level time per output token. TileRT prioritizes responsiveness for applications like high-frequency trading, interactive AI, real-time decision-making, long-running agents, and AI-assisted coding. It introduces a tile-level runtime engine that dynamically reschedules computation, I/O, and communication across multiple devices to minimize idle time and improve hardware utilization. The project is actively evolving, with compiler techniques gradually shared with the community through TileLang and TileScale.
zo2
ZO2 (Zeroth-Order Offloading) is an innovative framework designed to enhance the fine-tuning of large language models (LLMs) using zeroth-order (ZO) optimization techniques and advanced offloading technologies. It is tailored for setups with limited GPU memory, enabling the fine-tuning of models with over 175 billion parameters on single GPUs with as little as 18GB of memory. ZO2 optimizes CPU offloading, incorporates dynamic scheduling, and has the capability to handle very large models efficiently without extra time costs or accuracy losses.

MInference
MInference is a tool designed to accelerate pre-filling for long-context Language Models (LLMs) by leveraging dynamic sparse attention. It achieves up to a 10x speedup for pre-filling on an A100 while maintaining accuracy. The tool supports various decoding LLMs, including LLaMA-style models and Phi models, and provides custom kernels for attention computation. MInference is useful for researchers and developers working with large-scale language models who aim to improve efficiency without compromising accuracy.

MathVerse
MathVerse is an all-around visual math benchmark designed to evaluate the capabilities of Multi-modal Large Language Models (MLLMs) in visual math problem-solving. It collects high-quality math problems with diagrams to assess how well MLLMs can understand visual diagrams for mathematical reasoning. The benchmark includes 2,612 problems transformed into six versions each, contributing to 15K test samples. It also introduces a Chain-of-Thought (CoT) Evaluation strategy for fine-grained assessment of output answers.

tinyllm
tinyllm is a lightweight framework designed for developing, debugging, and monitoring LLM and Agent powered applications at scale. It aims to simplify code while enabling users to create complex agents or LLM workflows in production. The core classes, Function and FunctionStream, standardize and control LLM, ToolStore, and relevant calls for scalable production use. It offers structured handling of function execution, including input/output validation, error handling, evaluation, and more, all while maintaining code readability. Users can create chains with prompts, LLM models, and evaluators in a single file without the need for extensive class definitions or spaghetti code. Additionally, tinyllm integrates with various libraries like Langfuse and provides tools for prompt engineering, observability, logging, and finite state machine design.

PowerInfer
PowerInfer is a high-speed Large Language Model (LLM) inference engine designed for local deployment on consumer-grade hardware, leveraging activation locality to optimize efficiency. It features a locality-centric design, hybrid CPU/GPU utilization, easy integration with popular ReLU-sparse models, and support for various platforms. PowerInfer achieves high speed with lower resource demands and is flexible for easy deployment and compatibility with existing models like Falcon-40B, Llama2 family, ProSparse Llama2 family, and Bamboo-7B.
LLM-as-HH
LLM-as-HH is a codebase that accompanies the paper ReEvo: Large Language Models as Hyper-Heuristics with Reflective Evolution. It introduces Language Hyper-Heuristics (LHHs) that leverage LLMs for heuristic generation with minimal manual intervention and open-ended heuristic spaces. Reflective Evolution (ReEvo) is presented as a searching framework that emulates the reflective design approach of human experts while surpassing human capabilities with scalable LLM inference, Internet-scale domain knowledge, and powerful evolutionary search. The tool can improve various algorithms on problems like Traveling Salesman Problem, Capacitated Vehicle Routing Problem, Orienteering Problem, Multiple Knapsack Problems, Bin Packing Problem, and Decap Placement Problem in both black-box and white-box settings.
Mooncake
Mooncake is a serving platform for Kimi, a leading LLM service provided by Moonshot AI. It features a KVCache-centric disaggregated architecture that separates prefill and decoding clusters, leveraging underutilized CPU, DRAM, and SSD resources of the GPU cluster. Mooncake's scheduler balances throughput and latency-related SLOs, with a prediction-based early rejection policy for highly overloaded scenarios. It excels in long-context scenarios, achieving up to a 525% increase in throughput while handling 75% more requests under real workloads.

k2
K2 (GeoLLaMA) is a large language model for geoscience, trained on geoscience literature and fine-tuned with knowledge-intensive instruction data. It outperforms baseline models on objective and subjective tasks. The repository provides K2 weights, core data of GeoSignal, GeoBench benchmark, and code for further pretraining and instruction tuning. The model is available on Hugging Face for use. The project aims to create larger and more powerful geoscience language models in the future.

TokenFormer
TokenFormer is a fully attention-based neural network architecture that leverages tokenized model parameters to enhance architectural flexibility. It aims to maximize the flexibility of neural networks by unifying token-token and token-parameter interactions through the attention mechanism. The architecture allows for incremental model scaling and has shown promising results in language modeling and visual modeling tasks. The codebase is clean, concise, easily readable, state-of-the-art, and relies on minimal dependencies.

pytorch-forecasting
PyTorch Forecasting is a PyTorch-based package designed for state-of-the-art timeseries forecasting using deep learning architectures. It offers a high-level API and leverages PyTorch Lightning for efficient training on GPU or CPU with automatic logging. The package aims to simplify timeseries forecasting tasks by providing a flexible API for professionals and user-friendly defaults for beginners. It includes features such as a timeseries dataset class for handling data transformations, missing values, and subsampling, various neural network architectures optimized for real-world deployment, multi-horizon timeseries metrics, and hyperparameter tuning with optuna. Built on pytorch-lightning, it supports training on CPUs, single GPUs, and multiple GPUs out-of-the-box.
VeritasGraph
VeritasGraph is an enterprise-grade graph RAG framework designed for secure, on-premise AI applications. It leverages a knowledge graph to perform complex, multi-hop reasoning, providing transparent, auditable reasoning paths with full source attribution. The framework excels at answering complex questions that traditional vector search engines struggle with, ensuring trust and reliability in enterprise AI. VeritasGraph offers full control over data and AI models, verifiable attribution for every claim, advanced graph reasoning capabilities, and open-source deployment with sovereignty and customization.

Biomni
Biomni is a general-purpose biomedical AI agent designed to autonomously execute a wide range of research tasks across diverse biomedical subfields. By integrating cutting-edge large language model (LLM) reasoning with retrieval-augmented planning and code-based execution, Biomni helps scientists dramatically enhance research productivity and generate testable hypotheses.
RAGEN
RAGEN is a reinforcement learning framework designed to train reasoning-capable large language model (LLM) agents in interactive, stochastic environments. It addresses challenges such as multi-turn interactions and stochastic environments through a Markov Decision Process (MDP) formulation, Reason-Interaction Chain Optimization (RICO) algorithm, and progressive reward normalization strategies. The framework enables LLMs to reason and interact with the environment, optimizing entire trajectories for long-horizon reasoning while maintaining computational efficiency.
viitor-voice
ViiTor-Voice is an LLM based TTS Engine that offers a lightweight design with 0.5B parameters for efficient deployment on various platforms. It provides real-time streaming output with low latency experience, a rich voice library with over 300 voice options, flexible speech rate adjustment, and zero-shot voice cloning capabilities. The tool supports both Chinese and English languages and is suitable for applications requiring quick response and natural speech fluency.
For similar tasks
APOLLO
APOLLO is a memory-efficient optimizer designed for large language model (LLM) pre-training and full-parameter fine-tuning. It offers SGD-like memory cost with AdamW-level performance. The optimizer integrates low-rank approximation and optimizer state redundancy reduction to achieve significant memory savings while maintaining or surpassing the performance of Adam(W). Key contributions include structured learning rate updates for LLM training, approximated channel-wise gradient scaling in a low-rank auxiliary space, and minimal-rank tensor-wise gradient scaling. APOLLO aims to optimize memory efficiency during training large language models.
Awesome-Efficient-Agents
This repository, Awesome Efficient Agents, is a curated collection of papers focusing on memory, tool learning, and planning in agentic systems. It provides a comprehensive survey of efficient agent design, emphasizing memory construction, tool learning, and planning strategies. The repository categorizes papers based on memory processes, tool selection, tool calling, tool-integrated reasoning, and planning efficiency. It aims to help readers quickly access representative work in the field of efficient agent design.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.