
veScale
A PyTorch Native LLM Training Framework
Stars: 531
veScale is a PyTorch Native LLM Training Framework. It provides a set of tools and components to facilitate the training of large language models (LLMs) using PyTorch. veScale includes features such as 4D parallelism, fast checkpointing, and a CUDA event monitor. It is designed to be scalable and efficient, and it can be used to train LLMs on a variety of hardware platforms.
README:
An Industrial-Level Framework for Easy-of-Use
-
🔥 PyTorch Native: veScale is rooted in PyTorch-native data structures, operators, and APIs, enjoying the ecosystem of PyTorch that dominates the ML world.
-
🛡 Zero Model Code Change: veScale decouples distributed system design from model architecture, requiring near-zero or zero modification on the model code of users.
-
🚀 Single Device Abstraction: veScale provides single-device semantics to users, automatically distributing and orchestrating model execution in a cluster of devices.
-
🎯 Automatic Parallelism Planning: veScale parallelizes model execution with a synergy of strategies (tensor, sequence, data, ZeRO, pipeline parallelism) under semi- or full-automation [coming soon].
-
⚡ Eager & Compile Mode: veScale supports not only Eager-mode automation for parallel training and inference but also Compile-mode for ultimate performance [coming soon].
-
📀 Automatic Checkpoint Resharding: veScale manages distributed checkpoints automatically with online resharding across different cluster sizes and different parallelism strategies.
-
[2024-7-25] veScale's pipeline parallelism open sourced with API, graph parser, stage abstraction, schedules and execution runtime along with nD distributed timeline.
-
[2024-5-31] veScale's fast checkpointing system open sourced with automatic checkpoint resharding, caching, load-balancing, fast copying, deduplicating, and asynchronous io.
-
[2024-5-21] veScale's examples (Mixtral, LLama2, and nanoGPT) open sourced with bit-wise correctness of training loss curves.
-
[2024-5-13] The debut of veScale in MLSys 2024 as a poster.
-
[2024-4-16] Our internal LLM training system presented in NSDI 2024.
veScale is still in its early phase. We are refactoring our internal LLM training system components to meet open source standard. The tentative timeline is as follows:
-
High-level nD parallel api for extreme ease of use
-
Power-user plan api for easy customization of nD parallel training
-
End-to-end vescale/examples with 5D parallel training (TP, SP, DP, ZeRO, PP)
Table of Content (web view)
Parallel
- Overview
- Tensor Parallel & Sequence Parallel
- Data Parallel
- Optimizer Parallel
- Pipeline Parallel
- nD Device Mesh
Plan
The veScale Project is under the Apache License v2.0.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for veScale
Similar Open Source Tools
veScale
veScale is a PyTorch Native LLM Training Framework. It provides a set of tools and components to facilitate the training of large language models (LLMs) using PyTorch. veScale includes features such as 4D parallelism, fast checkpointing, and a CUDA event monitor. It is designed to be scalable and efficient, and it can be used to train LLMs on a variety of hardware platforms.

dash-infer
DashInfer is a C++ runtime tool designed to deliver production-level implementations highly optimized for various hardware architectures, including x86 and ARMv9. It supports Continuous Batching and NUMA-Aware capabilities for CPU, and can fully utilize modern server-grade CPUs to host large language models (LLMs) up to 14B in size. With lightweight architecture, high precision, support for mainstream open-source LLMs, post-training quantization, optimized computation kernels, NUMA-aware design, and multi-language API interfaces, DashInfer provides a versatile solution for efficient inference tasks. It supports x86 CPUs with AVX2 instruction set and ARMv9 CPUs with SVE instruction set, along with various data types like FP32, BF16, and InstantQuant. DashInfer also offers single-NUMA and multi-NUMA architectures for model inference, with detailed performance tests and inference accuracy evaluations available. The tool is supported on mainstream Linux server operating systems and provides documentation and examples for easy integration and usage.
kserve
KServe provides a Kubernetes Custom Resource Definition for serving predictive and generative machine learning (ML) models. It encapsulates the complexity of autoscaling, networking, health checking, and server configuration to bring cutting edge serving features like GPU Autoscaling, Scale to Zero, and Canary Rollouts to ML deployments. KServe enables a simple, pluggable, and complete story for Production ML Serving including prediction, pre-processing, post-processing, and explainability. It is a standard, cloud agnostic Model Inference Platform for serving predictive and generative AI models on Kubernetes, built for highly scalable use cases.

MM-RLHF
MM-RLHF is a comprehensive project for aligning Multimodal Large Language Models (MLLMs) with human preferences. It includes a high-quality MLLM alignment dataset, a Critique-Based MLLM reward model, a novel alignment algorithm MM-DPO, and benchmarks for reward models and multimodal safety. The dataset covers image understanding, video understanding, and safety-related tasks with model-generated responses and human-annotated scores. The reward model generates critiques of candidate texts before assigning scores for enhanced interpretability. MM-DPO is an alignment algorithm that achieves performance gains with simple adjustments to the DPO framework. The project enables consistent performance improvements across 10 dimensions and 27 benchmarks for open-source MLLMs.

joliGEN
JoliGEN is an integrated framework for training custom generative AI image-to-image models. It implements GAN, Diffusion, and Consistency models for various image translation tasks, including domain and style adaptation with conservation of semantics. The tool is designed for real-world applications such as Controlled Image Generation, Augmented Reality, Dataset Smart Augmentation, and Synthetic to Real transforms. JoliGEN allows for fast and stable training with a REST API server for simplified deployment. It offers a wide range of options and parameters with detailed documentation available for models, dataset formats, and data augmentation.
shards
Shards is a high-performance, multi-platform, type-safe programming language designed for visual development. It is a dataflow visual programming language that enables building full-fledged apps and games without traditional coding. Shards features automatic type checking, optimized shard implementations for high performance, and an intuitive visual workflow for beginners. The language allows seamless round-trip engineering between code and visual models, empowering users to create multi-platform apps easily. Shards also powers an upcoming AI-powered game creation system, enabling real-time collaboration and game development in a low to no-code environment.

aigne-framework
AIGNE Framework is a functional AI application development framework designed to simplify and accelerate the process of building modern applications. It combines functional programming features, powerful artificial intelligence capabilities, and modular design principles to help developers easily create scalable solutions. With key features like modular design, TypeScript support, multiple AI model support, flexible workflow patterns, MCP protocol integration, code execution capabilities, and Blocklet ecosystem integration, AIGNE Framework offers a comprehensive solution for developers. The framework provides various workflow patterns such as Workflow Router, Workflow Sequential, Workflow Concurrency, Workflow Handoff, Workflow Reflection, Workflow Orchestration, Workflow Code Execution, and Workflow Group Chat to address different application scenarios efficiently. It also includes built-in MCP support for running MCP servers and integrating with external MCP servers, along with packages for core functionality, agent library, CLI, and various models like OpenAI, Gemini, Claude, and Nova.
GhidrAssist
GhidrAssist is an advanced LLM-powered plugin for interactive reverse engineering assistance in Ghidra. It integrates Large Language Models (LLMs) to provide intelligent assistance for binary exploration and reverse engineering. The tool supports various OpenAI v1-compatible APIs, including local models and cloud providers. Key features include code explanation, interactive chat, custom queries, Graph-RAG knowledge system with semantic knowledge graph, community detection, security feature extraction, semantic graph tab, extended thinking/reasoning control, ReAct agentic mode, MCP integration, function calling, actions tab, RAG (Retrieval Augmented Generation), and RLHF dataset generation. The plugin uses a modular, service-oriented architecture with core services, Graph-RAG backend, data layer, and UI components.
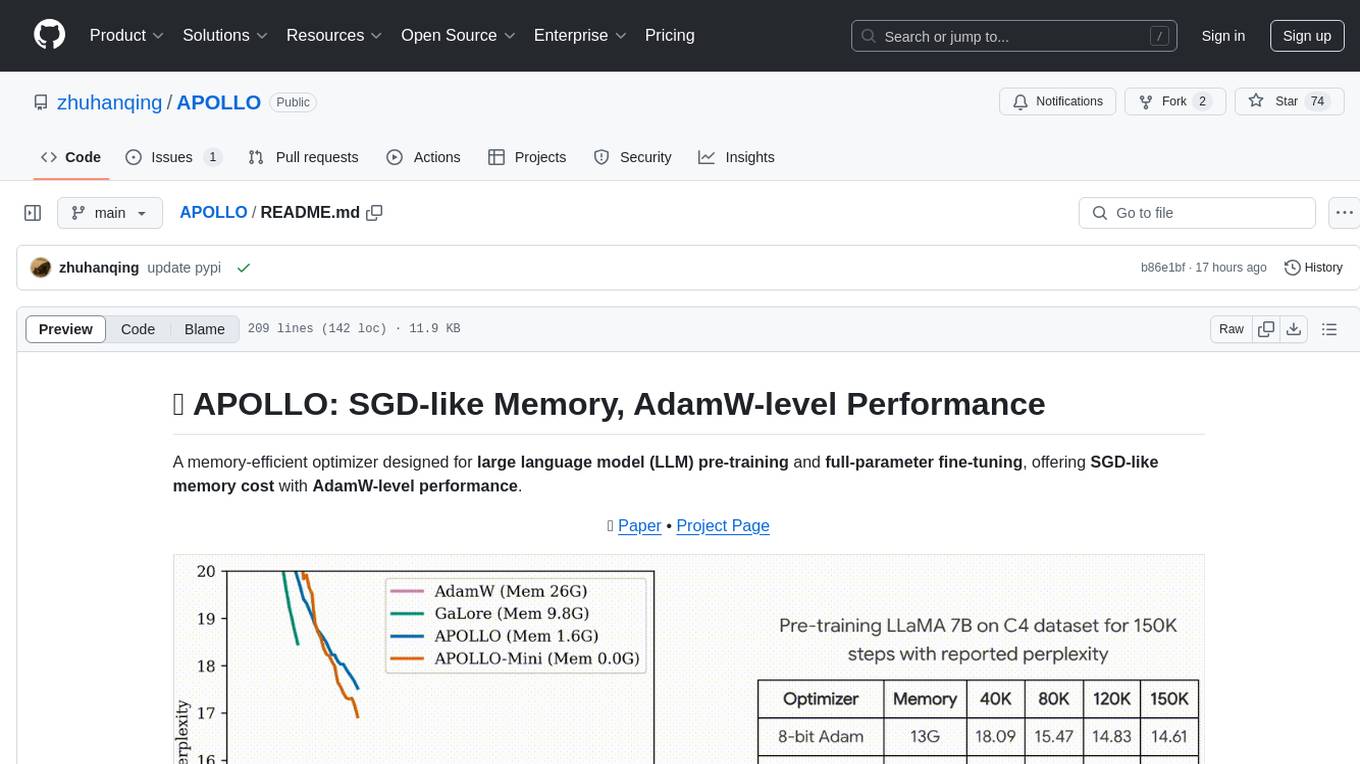
APOLLO
APOLLO is a memory-efficient optimizer designed for large language model (LLM) pre-training and full-parameter fine-tuning. It offers SGD-like memory cost with AdamW-level performance. The optimizer integrates low-rank approximation and optimizer state redundancy reduction to achieve significant memory savings while maintaining or surpassing the performance of Adam(W). Key contributions include structured learning rate updates for LLM training, approximated channel-wise gradient scaling in a low-rank auxiliary space, and minimal-rank tensor-wise gradient scaling. APOLLO aims to optimize memory efficiency during training large language models.
abi
ABI (Agentic Brain Infrastructure) is a Python-based AI Operating System designed to serve as the core infrastructure for building an Agentic AI Ontology Engine. It empowers organizations to integrate, manage, and scale AI-driven operations with multiple AI models, focusing on ontology, agent-driven workflows, and analytics. ABI emphasizes modularity and customization, providing a customizable framework aligned with international standards and regulatory frameworks. It offers features such as configurable AI agents, ontology management, integrations with external data sources, data processing pipelines, workflow automation, analytics, and data handling capabilities.
llms-interview-questions
This repository contains a comprehensive collection of 63 must-know Large Language Models (LLMs) interview questions. It covers topics such as the architecture of LLMs, transformer models, attention mechanisms, training processes, encoder-decoder frameworks, differences between LLMs and traditional statistical language models, handling context and long-term dependencies, transformers for parallelization, applications of LLMs, sentiment analysis, language translation, conversation AI, chatbots, and more. The readme provides detailed explanations, code examples, and insights into utilizing LLMs for various tasks.
VisioFirm
VisioFirm is an open-source, AI-powered image annotation tool designed to accelerate labeling for computer vision tasks like classification, object detection, oriented bounding boxes (OBB), segmentation and video annotation. Built for speed and simplicity, it leverages state-of-the-art models for semi-automated pre-annotations, allowing you to focus on refining rather than starting from scratch. Whether you're preparing datasets for YOLO, SAM, or custom models, VisioFirm streamlines your workflow with an intuitive web interface and powerful backend. Perfect for researchers, data scientists, and ML engineers handling large image datasets—get high-quality annotations in minutes, not hours!

astron-agent
Astron Agent is an enterprise-grade, commercial-friendly Agentic Workflow development platform that integrates AI workflow orchestration, model management, AI and MCP tool integration, RPA automation, and team collaboration features. It supports high-availability deployment, enabling organizations to rapidly build scalable, production-ready intelligent agent applications and establish their AI foundation for the future. The platform is stable, reliable, and business-friendly, with key features such as enterprise-grade high availability, intelligent RPA integration, ready-to-use tool ecosystem, and flexible large model support.

openops
OpenOps is a No-Code FinOps automation platform designed to help organizations reduce cloud costs and streamline financial operations. It offers customizable workflows for automating key FinOps processes, comes with its own Excel-like database and visualization system, and enables collaboration between different teams. OpenOps integrates seamlessly with major cloud providers, third-party FinOps tools, communication platforms, and project management tools, providing a comprehensive solution for efficient cost-saving measures implementation.
kornia
Kornia is a differentiable computer vision library for PyTorch. It consists of a set of routines and differentiable modules to solve generic computer vision problems. At its core, the package uses PyTorch as its main backend both for efficiency and to take advantage of the reverse-mode auto-differentiation to define and compute the gradient of complex functions.
llmxcpg
LLMxCPG is a framework for vulnerability detection using Code Property Graphs (CPG) and Large Language Models (LLM). It involves a two-phase process: Slice Construction where an LLM generates queries for a CPG to extract a code slice, and Vulnerability Detection where another LLM classifies the code slice as vulnerable or safe. The repository includes implementations of baseline models, information on datasets, scripts for running models, prompt templates, query generation examples, and configurations for fine-tuning models.
For similar tasks
veScale
veScale is a PyTorch Native LLM Training Framework. It provides a set of tools and components to facilitate the training of large language models (LLMs) using PyTorch. veScale includes features such as 4D parallelism, fast checkpointing, and a CUDA event monitor. It is designed to be scalable and efficient, and it can be used to train LLMs on a variety of hardware platforms.
LLMSys-PaperList
This repository provides a comprehensive list of academic papers, articles, tutorials, slides, and projects related to Large Language Model (LLM) systems. It covers various aspects of LLM research, including pre-training, serving, system efficiency optimization, multi-model systems, image generation systems, LLM applications in systems, ML systems, survey papers, LLM benchmarks and leaderboards, and other relevant resources. The repository is regularly updated to include the latest developments in this rapidly evolving field, making it a valuable resource for researchers, practitioners, and anyone interested in staying abreast of the advancements in LLM technology.
TensorRT-LLM
TensorRT-LLM is an easy-to-use Python API to define Large Language Models (LLMs) and build TensorRT engines that contain state-of-the-art optimizations to perform inference efficiently on NVIDIA GPUs. TensorRT-LLM contains components to create Python and C++ runtimes that execute those TensorRT engines. It also includes a backend for integration with the NVIDIA Triton Inference Server; a production-quality system to serve LLMs. Models built with TensorRT-LLM can be executed on a wide range of configurations going from a single GPU to multiple nodes with multiple GPUs (using Tensor Parallelism and/or Pipeline Parallelism).

mLoRA
mLoRA (Multi-LoRA Fine-Tune) is an open-source framework for efficient fine-tuning of multiple Large Language Models (LLMs) using LoRA and its variants. It allows concurrent fine-tuning of multiple LoRA adapters with a shared base model, efficient pipeline parallelism algorithm, support for various LoRA variant algorithms, and reinforcement learning preference alignment algorithms. mLoRA helps save computational and memory resources when training multiple adapters simultaneously, achieving high performance on consumer hardware.

EdgeChains
EdgeChains is an open-source chain-of-thought engineering framework tailored for Large Language Models (LLMs)- like OpenAI GPT, LLama2, Falcon, etc. - With a focus on enterprise-grade deployability and scalability. EdgeChains is specifically designed to **orchestrate** such applications. At EdgeChains, we take a unique approach to Generative AI - we think Generative AI is a deployment and configuration management challenge rather than a UI and library design pattern challenge. We build on top of a tech that has solved this problem in a different domain - Kubernetes Config Management - and bring that to Generative AI. Edgechains is built on top of jsonnet, originally built by Google based on their experience managing a vast amount of configuration code in the Borg infrastructure.

NeMo
NeMo Framework is a generative AI framework built for researchers and pytorch developers working on large language models (LLMs), multimodal models (MM), automatic speech recognition (ASR), and text-to-speech synthesis (TTS). The primary objective of NeMo is to provide a scalable framework for researchers and developers from industry and academia to more easily implement and design new generative AI models by being able to leverage existing code and pretrained models.

llm.c
LLM training in simple, pure C/CUDA. There is no need for 245MB of PyTorch or 107MB of cPython. For example, training GPT-2 (CPU, fp32) is ~1,000 lines of clean code in a single file. It compiles and runs instantly, and exactly matches the PyTorch reference implementation. I chose GPT-2 as the first working example because it is the grand-daddy of LLMs, the first time the modern stack was put together.

torchtune
Torchtune is a PyTorch-native library for easily authoring, fine-tuning, and experimenting with LLMs. It provides native-PyTorch implementations of popular LLMs using composable and modular building blocks, easy-to-use and hackable training recipes for popular fine-tuning techniques, YAML configs for easily configuring training, evaluation, quantization, or inference recipes, and built-in support for many popular dataset formats and prompt templates to help you quickly get started with training.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.