Best AI tools for< Optimize Llms >
20 - AI tool Sites
Promptech
Promptech is an AI teamspace designed to streamline workflows and enhance productivity. It offers a range of features including AI assistants, a collaborative teamspace, and access to large language models (LLMs). Promptech is suitable for businesses of all sizes and can be used for a variety of tasks such as streamlining tasks, enhancing collaboration, and safeguarding IP. It is a valuable resource for technology leaders and provides a cost-effective AI solution for smaller teams and startups.

Tensoic AI
Tensoic AI is an AI tool designed for custom Large Language Models (LLMs) fine-tuning and inference. It offers ultra-fast fine-tuning and inference capabilities for enterprise-grade LLMs, with a focus on use case-specific tasks. The tool is efficient, cost-effective, and easy to use, enabling users to outperform general-purpose LLMs using synthetic data. Tensoic AI generates small, powerful models that can run on consumer-grade hardware, making it ideal for a wide range of applications.

Freeplay
Freeplay is a tool that helps product teams experiment, test, monitor, and optimize AI features for customers. It provides a single pane of glass for the entire team, lightweight developer SDKs for Python, Node, and Java, and deployment options to meet compliance needs. Freeplay also offers best practices for the entire AI development lifecycle.
Cohere
Cohere is the leading AI platform for enterprise, offering generative AI, search and discovery, and advanced retrieval solutions. Their models are designed to enhance the global workforce, empowering businesses to thrive in the AI era. With features like Cohere Command, Cohere Embed, and Cohere Rerank, the platform enables the development of scalable and efficient AI-powered applications. Cohere focuses on optimizing enterprise data through language-based models, supporting over 100 languages for enhanced accuracy and efficiency.
Entry Point AI
Entry Point AI is a modern AI optimization platform for fine-tuning proprietary and open-source language models. It provides a user-friendly interface to manage prompts, fine-tunes, and evaluations in one place. The platform enables users to optimize models from leading providers, train across providers, work collaboratively, write templates, import/export data, share models, and avoid common pitfalls associated with fine-tuning. Entry Point AI simplifies the fine-tuning process, making it accessible to users without the need for extensive data, infrastructure, or insider knowledge.
FineTuneAIs.com
FineTuneAIs.com is a platform that specializes in custom AI model fine-tuning. Users can fine-tune their AI models to achieve better performance and accuracy. The platform requires JavaScript to be enabled for optimal functionality.
FutureGPT
FutureGPT is an AI tool that leverages the power of GPT-4 to provide advanced predictive capabilities. Users can enhance their results by utilizing this tool, which offers paid predictions. By enabling JavaScript, users can access the app and explore its features to receive accurate and insightful predictions for various purposes. FutureGPT aims to streamline decision-making processes and optimize outcomes through cutting-edge AI technology.
Cohere
Cohere is the leading AI platform for enterprise, offering products optimized for generative AI, search and discovery, and advanced retrieval. Their models are designed to enhance the global workforce, enabling businesses to thrive in the AI era. Cohere provides Command R+, Cohere Command, Cohere Embed, and Cohere Rerank for building efficient AI-powered applications. The platform also offers deployment options for enterprise-grade AI on any cloud or on-premises, along with developer resources like Playground, LLM University, and Developer Docs.
Arcee AI
Arcee AI is a platform that offers a cost-effective, secure, end-to-end solution for building and deploying Small Language Models (SLMs). It allows users to merge and train custom language models by leveraging open source models and their own data. The platform is known for its Model Merging technique, which combines the power of pre-trained Large Language Models (LLMs) with user-specific data to create high-performing models across various industries.
Lunary
Lunary is an AI developer platform designed to bring AI applications to production. It offers a comprehensive set of tools to manage, improve, and protect LLM apps. With features like Logs, Metrics, Prompts, Evaluations, and Threads, Lunary empowers users to monitor and optimize their AI agents effectively. The platform supports tasks such as tracing errors, labeling data for fine-tuning, optimizing costs, running benchmarks, and testing open-source models. Lunary also facilitates collaboration with non-technical teammates through features like A/B testing, versioning, and clean source-code management.
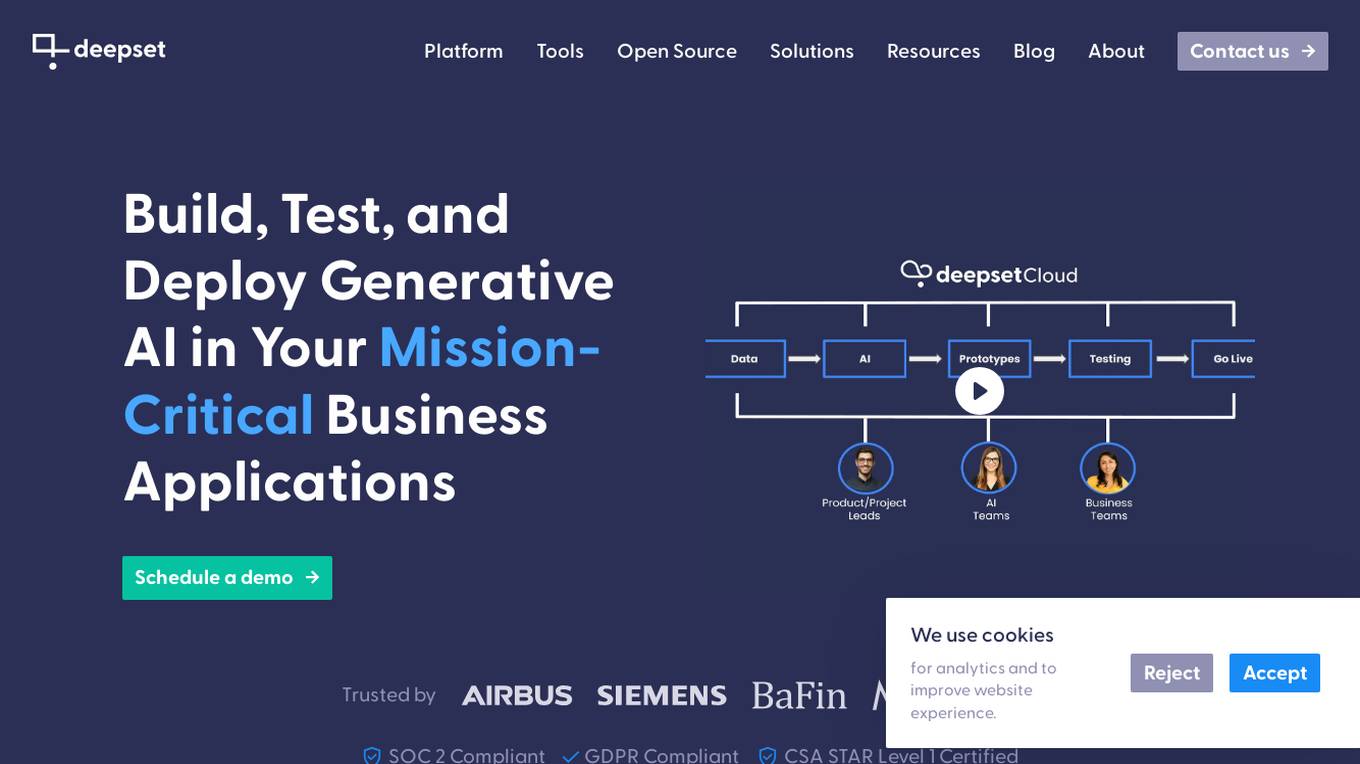
deepset
deepset is an AI platform that offers enterprise-level products and solutions for AI teams. It provides deepset Cloud, a platform built with Haystack, enabling fast and accurate prototyping, building, and launching of advanced AI applications. The platform streamlines the AI application development lifecycle, offering processes, tools, and expertise to move from prototype to production efficiently. With deepset Cloud, users can optimize solution accuracy, performance, and cost, and deploy AI applications at any scale with one click. The platform also allows users to explore new models and configurations without limits, extending their team with access to world-class AI engineers for guidance and support.
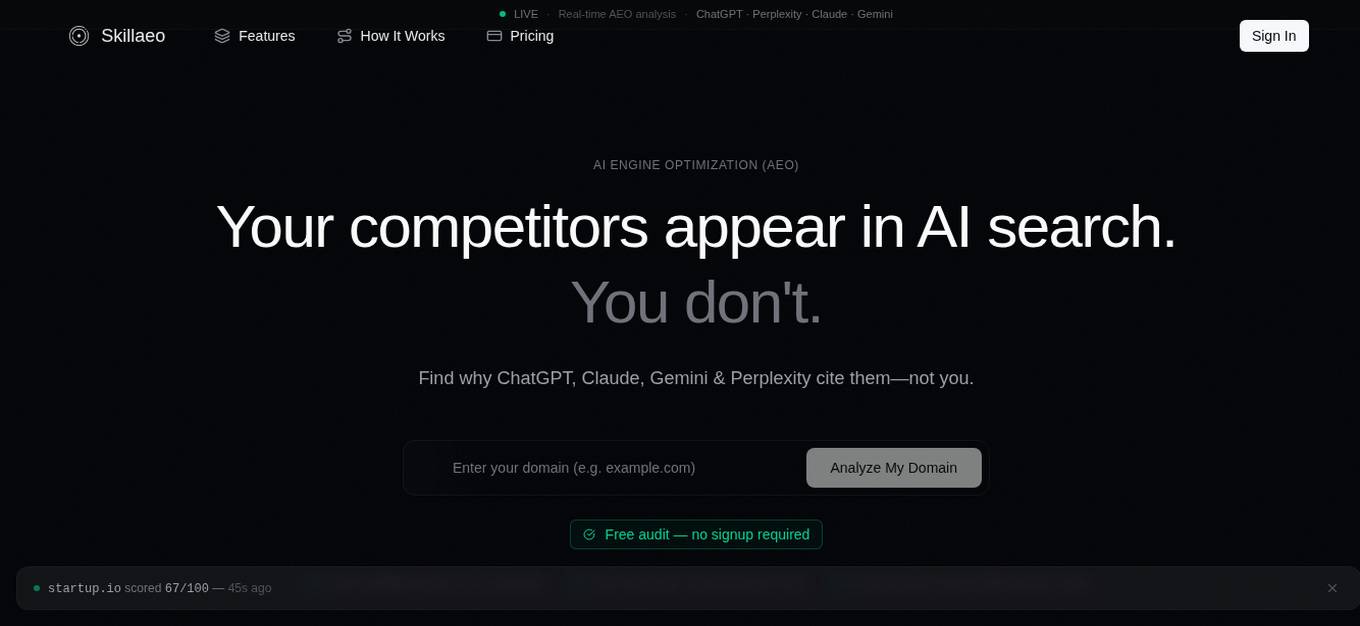
Skillaeo
Skillaeo is an AI Engine Optimization (AEO) platform that helps websites optimize their content to be favorably understood and cited by AI search engines like ChatGPT, Perplexity, Claude, and Gemini. It focuses on improving AI visibility by providing evidence-based fixes, competitor insights, and Skills Pack generation to enhance brand citations in AI-generated answers and recommendations. Skillaeo offers real-time AI audits, citation tracking, competitor analysis, and prioritized fixes to help websites improve their AEO score and visibility in AI search results.
Arthur
Arthur is an industry-leading MLOps platform that simplifies deployment, monitoring, and management of traditional and generative AI models. It ensures scalability, security, compliance, and efficient enterprise use. Arthur's turnkey solutions enable companies to integrate the latest generative AI technologies into their operations, making informed, data-driven decisions. The platform offers open-source evaluation products, model-agnostic monitoring, deployment with leading data science tools, and model risk management capabilities. It emphasizes collaboration, security, and compliance with industry standards.

Gradient
Gradient is an AI automation platform designed specifically for enterprise AI purposes. It offers a seamless way to automate manual workflows with minimal effort, providing business intuition and industry expertise. The platform ensures unmatched compliance with various regulations and prioritizes privacy and security. Gradient's Agent Foundry enables users to automate tasks, integrate data, and optimize workflows efficiently, making it a valuable tool for modern enterprises.

OdiaGenAI
OdiaGenAI is a collaborative initiative focused on conducting research on Generative AI and Large Language Models (LLM) for the Odia Language. The project aims to leverage AI technology to develop Generative AI and LLM-based solutions for the overall development of Odisha and the Odia language through collaboration among Odia technologists. The initiative offers pre-trained models, codes, and datasets for non-commercial and research purposes, with a focus on building language models for Indic languages like Odia and Bengali.
Placeholder Website
The website is a simple and straightforward platform that seems to lack content or functionality. It appears to be a placeholder or under construction. There is no specific information available on the site, and it seems to be in a basic state of development.

Unify
Unify is an AI tool that offers a unified platform for accessing and comparing various Language Models (LLMs) from different providers. It allows users to combine models for faster, cheaper, and better responses, optimizing for quality, speed, and cost-efficiency. Unify simplifies the complex task of selecting the best LLM by providing transparent benchmarks, personalized routing, and performance optimization tools.
Composio
Composio is an integration platform for AI Agents and LLMs that allows users to access over 150 tools with just one line of code. It offers seamless integrations, managed authentication, a repository of tools, and powerful RPA tools to streamline and optimize the connection and interaction between AI Agents/LLMs and various APIs/services. Composio simplifies JSON structures, improves variable names, and enhances error handling to increase reliability by 30%. The platform is SOC Type II compliant, ensuring maximum security of user data.
GPTBots
GPTBots.ai is a powerful no-code platform for creating AI-driven business applications. It seamlessly integrates large language models with organizational data, services, and workflows to empower AI bots in driving business growth. The platform allows users to build and train AI bots without coding experience, access best-practice AI bot templates, optimize and customize AI knowledge base, and adapt to various scenarios with intelligent agent bots. GPTBots supports diverse input types, offers versatile language models, enables seamless chatbot-human handoff, and provides robust API and SDK for embedding capabilities into products. Trusted by over 100k companies worldwide, GPTBots helps enterprises enhance customer service, leads generation, SEO writing, data analysis, and more.
JFrog ML
JFrog ML is an AI platform designed to streamline AI development from prototype to production. It offers a unified MLOps platform to build, train, deploy, and manage AI workflows at scale. With features like Feature Store, LLMOps, and model monitoring, JFrog ML empowers AI teams to collaborate efficiently and optimize AI & ML models in production.
4 - Open Source AI Tools
veScale
veScale is a PyTorch Native LLM Training Framework. It provides a set of tools and components to facilitate the training of large language models (LLMs) using PyTorch. veScale includes features such as 4D parallelism, fast checkpointing, and a CUDA event monitor. It is designed to be scalable and efficient, and it can be used to train LLMs on a variety of hardware platforms.
LLMSys-PaperList
This repository provides a comprehensive list of academic papers, articles, tutorials, slides, and projects related to Large Language Model (LLM) systems. It covers various aspects of LLM research, including pre-training, serving, system efficiency optimization, multi-model systems, image generation systems, LLM applications in systems, ML systems, survey papers, LLM benchmarks and leaderboards, and other relevant resources. The repository is regularly updated to include the latest developments in this rapidly evolving field, making it a valuable resource for researchers, practitioners, and anyone interested in staying abreast of the advancements in LLM technology.
TensorRT-LLM
TensorRT-LLM is an easy-to-use Python API to define Large Language Models (LLMs) and build TensorRT engines that contain state-of-the-art optimizations to perform inference efficiently on NVIDIA GPUs. TensorRT-LLM contains components to create Python and C++ runtimes that execute those TensorRT engines. It also includes a backend for integration with the NVIDIA Triton Inference Server; a production-quality system to serve LLMs. Models built with TensorRT-LLM can be executed on a wide range of configurations going from a single GPU to multiple nodes with multiple GPUs (using Tensor Parallelism and/or Pipeline Parallelism).

mLoRA
mLoRA (Multi-LoRA Fine-Tune) is an open-source framework for efficient fine-tuning of multiple Large Language Models (LLMs) using LoRA and its variants. It allows concurrent fine-tuning of multiple LoRA adapters with a shared base model, efficient pipeline parallelism algorithm, support for various LoRA variant algorithms, and reinforcement learning preference alignment algorithms. mLoRA helps save computational and memory resources when training multiple adapters simultaneously, achieving high performance on consumer hardware.
20 - OpenAI Gpts
Agent Prompt Generator for LLM's
This GPT generates the best possible LLM-agents for your system prompts. You can also specify the model size, like 3B, 33B, 70B, etc.

CV & Resume ATS Optimize + 🔴Match-JOB🔴
Professional Resume & CV Assistant 📝 Optimize for ATS 🤖 Tailor to Job Descriptions 🎯 Compelling Content ✨ Interview Tips 💡



Website Conversion by B12
I'll help you optimize your website for more conversions, and compare your site's CRO potential to competitors’.

Thermodynamics Advisor
Advises on thermodynamics processes to optimize system efficiency.

Cloud Architecture Advisor
Guides cloud strategy and architecture to optimize business operations.

International Tax Advisor
Advises on international tax matters to optimize company's global tax position.
Investment Management Advisor
Provides strategic financial guidance for investment behavior to optimize organization's wealth.
ESG Strategy Navigator 🌱🧭
Optimize your business with sustainable practices! ESG Strategy Navigator helps integrate Environmental, Social, Governance (ESG) factors into corporate strategy, ensuring compliance, ethical impact, and value creation. 🌟
Floor Plan Optimization Assistant
Help optimize floor plan, for better experience, please visit collov.ai
AI Business Transformer
Top AI for business automation, data analytics, content creation. Optimize efficiency, gain insights, and innovate with AI Business Transformer.
Business Pricing Strategies & Plans Toolkit
A variety of business pricing tools and strategies! Optimize your price strategy and tactics with AI-driven insights. Critical pricing tools for businesses of all sizes looking to strategically navigate the market.
Purchase Order Management Advisor
Manages purchase orders to optimize procurement operations.
E-Procurement Systems Advisor
Advises on e-procurement systems to optimize purchasing processes.