
awesome-hallucination-detection
List of papers on hallucination detection in LLMs.
Stars: 817
This repository provides a curated list of papers, datasets, and resources related to the detection and mitigation of hallucinations in large language models (LLMs). Hallucinations refer to the generation of factually incorrect or nonsensical text by LLMs, which can be a significant challenge for their use in real-world applications. The resources in this repository aim to help researchers and practitioners better understand and address this issue.
README:
Kernel Language Entropy: Fine-grained Uncertainty Quantification for LLMs from Semantic Similarities
- Metrics: For detection: AUROC, AURAC.
- Datasets: QA: TriviaQA, SQuAD, BioASQ, NQ, SVAMP.
- Comments: This work presents a method for evaluating the semantic uncertainty of LLM responses. The approach generates multiple response samples and measures their semantic similarity, which is represented as a density matrix (semantic kernel). Semantic uncertainty is then quantified using the von Neumann entropy of this matrix. High uncertainty suggests potential hallucinations, alowing for their detection and mitigation.
- Metrics: Exact Match
- Datasets: NQSwap, Macnoise
- Comments: The first work that uses sparse auto-encoders (SAEs) to enhance both the usage of contextual and parametric knowledge.
- Metrics: MC1, MC2, MC3 scores for TruthfulQA multiple-choice task; %Truth, %Info, %Truth*Info for TruthfulQA open-ended generation task; subspan Exact Match for the open-domain QA tasks (NQ-Open, NQ-Swap, TriviaQA, PopQA, MuSiQue); accuracy for MemoTrap; Prompt-level and Instruction-level accuracies for IFEval.
- Datasets: TruthfulQA, NQ-Open, NQ-Swap, TriviaQA, PopQA, MemoTrap, IFEval, MuSiQue
Semantic Density: Uncertainty Quantification for Large Language Models through Confidence Measurement in Semantic Space
- Metrics: AUROC, AUPR
- Datasets: CoQA, TriviaQA, SciQ, NQ
- Comments: Proposes a new method, namely semantic density, to provide response-wise confidence/uncertainty scores for detecting LLM hallucinations. Semantic density extracts uncertainty/confidence information for each response from a probability distribution perspective in semantic space. It has no restriction on task types and is "off-the-shelf" for new models and tasks. Significant improvement over other SOTA methods are consistently observed across different datasets and base LLMs.
- Metrics: Binary hallucination detection (Precision, Recall, F1).
- Datasets: MedHallu – derived from PubMedQA, containing 10k QA pairs with deliberately planted plausible hallucinations.
- Comments: Presents a large-scale medical-focused hallucination detection benchmark. Evaluations show that, on the hardest subset, even top models like GPT-4 achieve only ~0.625 F1 in detecting subtle falsehoods, pointing to the difficulty of medical hallucination detection.
- Metrics: ROUGE-L, BERTScore, factual consistency rate on XSum/CNN-DM (measured via QA-based metrics like QuestEval).
- Datasets: CNN/DailyMail, XSum
- Comments: Proposes training with soft labels from a teacher LLM to reduce overconfidence and lower hallucination rates in summarization tasks. Maintains quality (ROUGE/BERTScore) while significantly decreasing factual errors.
- Metrics: Hallucination rate (% of outputs containing any unsupported legal claim).
- Datasets: Custom set of factual US case queries, where ground-truth outcomes can be verified.
- Comments: Empirical study finding that GPT-3.5 and LLaMA-2 hallucinate in 69% and 88% of legal Q&A, respectively. Highlights the risks of using off-the-shelf LLMs in legal contexts without further training or validation.
- Metrics: Custom confidence score combining factual verification (data overlap), retrieval correctness, and final QA consistency.
- Datasets: Proprietary financial tables and queries.
- Comments: Shows how grounding LLMs in relevant financial data and applying multi-metric validation can exceed 90% confident correctness. Demonstrates an effective approach to curbing hallucinations in finance.
- Metrics: Accuracy, F1-score (hallucination detection performance).
- Datasets: Synthetic Q&A dataset (generated with Llama2-7B and Llama3-8B) labeled for hallucinated vs. non-hallucinated responses.
- Comments: Proposes analyzing the embedding space of LLM outputs to detect hallucinations. By measuring Minkowski distance between embedded keywords in genuine vs. hallucinated answers, it uncovers structural differences and achieves competitive hallucination detection accuracy (~66%) without external fact-checking.
- Metrics: Accuracy, Precision/Recall, F1 (hallucination detection on benchmarks like MHaluBench, MFHaluBench); Hallucination Rate and metrics such as CHAIR, Cover, Hal, Cog (for generation benchmarks like Object HalBench and AMBER).
- Datasets: MHaluBench, MFHaluBench (vision-language hallucination detection datasets); Object HalBench, AMBER, MMHal-Bench, POPE (hallucination mitigation benchmarks for LVLMs).
- Comments: Introduces HSA-DPO, a severity-aware direct preference optimization method that uses fine-grained AI feedback to label hallucination severity and prioritize critical errors in training. This approach achieves state-of-the-art performance in detecting visual hallucinations (outperforming GPT-4V and other models) and significantly lowers hallucination occurrence in generated outputs (e.g., 36% reduction on AMBER, 76% on Object HalBench versus the base model).
Pelican: Correcting Hallucination in Vision-LLMs via Claim Decomposition and Program of Thought Verification
- Metrics: Hallucination rate reduction (%) and factual accuracy improvements on multiple vision–language instruction benchmarks (e.g., MMHal-Bench, GAVIE, MME).
- Datasets: MMHal-Bench, GAVIE (hallucination evaluation benchmarks for LVLMs); MME (general vision-language understanding benchmark).
- Comments: Proposes a framework (Pelican) that detects and mitigates visual hallucinations through claim verification. It decomposes an image-grounded claim into sub-claims and uses program-of-thought (code execution with external tools) to verify each sub-claim’s truth. An LLM then assesses overall consistency. Pelican significantly reduces hallucination rates (approx. 8–32% drop across various LVLMs, and 27% lower than prior mitigation methods) while maintaining or improving the models’ factual accuracy in following visual instructions.
- Metrics: Hallucination type distribution (prevalence of hallucinations despite knowledge vs. due to lack of knowledge); classification accuracy distinguishing HK+ vs. HK- cases; improvements in detection/mitigation when handling these types separately.
- Datasets: WACK (Wrong Answers despite Correct Knowledge) – a constructed dataset based on TriviaQA and NaturalQuestions, containing QA instances labeled as HK- (hallucination caused by missing knowledge) or HK+ (hallucination even though the model knows the answer) for specific LLMs.
- Comments: Investigates two distinct causes of hallucination: when the model truly doesn’t know the answer (ignorance) vs. when it knows the answer but still responds incorrectly (error). Introduces an automated approach to generate model-specific labeled examples (the WACK dataset) by testing the model under various prompted scenarios. Shows that a simple classifier on the LLM’s internal representations can differentiate these cases, and that tailoring detection/mitigation to a model’s HK+ (knowledgeable error) cases yields better results than a one-size-fits-all approach.
- Metrics: Factuality verification accuracy (FEVER-style support/refute classification of answers), and answer relevance metrics (n-gram overlap, ROUGE/NDCG) in open-domain QA.
- Datasets: TREC Deep Learning 2019 & 2020 (passage ranking QA tasks) and a subset of MS MARCO Dev (for open-domain answer generation).
- Comments: Models the generative information retrieval process as a genetic algorithm (called GAuGE: Genetic Approach using Grounded Evolution) to reduce hallucinations in answers. Candidate answers evolve through iterative “mutation” and selection, guided by a simple n-gram overlap fitness score to ensure consistency with retrieved documents. Experiments across several IR datasets show that GAuGE produces highly relevant answers with significantly fewer hallucinated statements (substantially higher fact verification scores) compared to standard RAG-style generation, all without sacrificing answer relevance.
- Metrics: Hallucination detection accuracy and F1-score (token-level and response-level) on the new HELM benchmark; detection latency and throughput.
- Datasets: Wikipedia (used to extract pseudo training data); HELM (Hallucination Evaluation for multiple LLMs) – a benchmark with outputs from six different LLMs on Wikipedia-derived prompts, annotated with human labels for hallucinated content along with each model’s internal states.
- Comments: Introduces an unsupervised, real-time hallucination detection framework that taps into an LLM’s own hidden states. MIND leverages unannotated Wikipedia text to auto-generate training pairs (prompt, LLM output with hallucination label inferred) and trains a lightweight MLP to predict hallucinations from the model’s activations during inference. This approach avoids heavy external fact-checkers, greatly speeds up detection, and remains model-agnostic. On the HELM benchmark, MIND demonstrates strong hallucination detection performance while significantly reducing computational overhead compared to prior post-processing methods.
- Metrics: AUROC
- Datasets: TriviaQA, NaturalQA, WebQA
- Comments: The LLM uncertainty estimation technique called MARS replaces length-normalized probability scoring by assigning greater weights to tokens that contribute more significantly to correctness.
- Metrics: AUROC, PRR
- Datasets: TriviaQA, GSM8k, NaturalQA, WebQA
- Comments: The LLM uncertainty estimation technique called LARS trains an encoder-based transformer that takes a query, generation, and token probabilities as input and returns an uncertainty score as output
- Metrics: Accuracy, Precision/Recall/Auroc
- Datasets: TriviaQA, GSM8k, SVAMP, Common-sense QA
- Comments: LLM uncertainty estimation technique called BSDetector that combines self-reflection certainty and observed consistency into a single confidence score. Detects incorrect/hallucinated LLM responses with high precision/recall, and can also automatically boost the accuracy of LLM responses.
- Metrics: MAE, F_{beta}, S_{alpha}
- Datasets: CHAMELEON, CAMO, COD10K, CVC-ColonDB, Kvasir, ISIC
- Comments: The first study does not regard hallucinations as purely negative, but as a common aspect of model pre-training. Unlike previous approaches that directly eliminate hallucinations, ProMaC first stimulates hallucinations to mine the prior knowledge from model pre-training to gather task-relevant information in images. Then, it eliminates irrelevant hallucinations to mitigate their negative impact. The effectiveness of this method has been demonstrated in multiple challenging segmentation tasks.
- Metrics: Accuracy (detection), Rouge (correction)
- Datasets: SummEval, QAGS-C, QAGS-X
- Comments: Proposes a hallucination detection GraphEval and corection framework GraphCorrect. Hallucination detection is done by extracting KG triples from an LLM output and comparing the entailment of the triples with respect to the provided context. Correction is done by taking triples likely to contain hallucinations (entailment below 0.5) are then prompting an LLM to generate a new, factually correct triple with respect to a provided context. Afterwards in a seperate inference pass an LLM is prompted to replace the information in the non-factual LLM output based on the corrected triple. Underlying NLI models that are used for experiments are HHEM (DeBERTaV3), TRUE and TrueTeacher (T5-XXL). The underlying LLM used is Claude2. Final experiments are conducted by computing Rouge scores between reference text and the proposed mitigation method.
- Metrics: Accuracy
- Datasets: HaluBench (consists of ~500 random samples from CovidQA, PubMedQA, DROP, FinanceBench and another set of perturbations based on the retrieved samples)
- Comments: Proposes a resource HaluBench and Lynx (Llama3-70bn-instruct based model) for a reference-free metric evaluation. The focus is on instrinsic hallucination evaluation, meaning answers faithful to the given context instead of world knowledge. Hallucinated examples for HaluBench are gathered with GPT-4o. Training of Lynx is done on 2400 samples from RAGTruth, DROP, CovidQA, PubMedQA with GPT4o generated reasoning as part of the training samples. Evaluation is done by extracting a response-level binary label indicating response's faithfulness to the context.
- Metrics: Graph edit distance, spectral distance, distance between degree distributions.
- Datasets: Graph Atlas Distance
- Comments: This benchmark presents the capability to directly prompt LLMs for known graph structures. Distances from the outputs of LLMs and of the ground truth graphs are studied. A ranking based on graph edit distance sorts LLMs in their hallucination amplitude.
HallusionBench: An Advanced Diagnostic Suite for Entangled Language Hallucination and Visual Illusion in Large Vision-Language Models
- Metrics: Accuracy.
- Datasets: HallusionBench
- Comments: This benchmark presents significant challenges to advanced large visual-language models (LVLMs), such as GPT-4V(Vision), Gemini Pro Vision, Claude 3, and LLaVA-1.5, by emphasizing nuanced understanding and interpretation of visual data. This paper introduces a novel structure for these visual questions designed to establish control groups. This structure is able to conduct a quantitative analysis of the models' response tendencies, logical consistency, and various failure modes.
- Metrics: Accuracy, F1/Precision/Recall.
- Datasets: MHaluBench
- Framework: UniHD
- Comments: This paper proposes a more unified problem setting for hallucination detection in MLLMs, unveils a meta-evaluation benchmark MHaluBench that encompasses various hallucination categories and multimodal tasks, and introduces UNIHD, a unified framework for the detection of hallucinations in content produced by MLLMs.
- Metrics: F1 of detection, Match of explanation
- Datasets: FactCHD
- Highlights: This paper introduces the FACTCHD benchmark, which focuses on detecting fact-conflicting hallucinations. FACTCHD integrates factual knowledge from multiple domains, encompassing a wide range of fact patterns, including raw facts, multi-hop reasoning, comparison, and set operations. Its distinguishing feature lies in its goal to combine evidence chains rooted in factual information, enabling persuasive reasoning in predicting the factuality or non-factuality of a claim.
- Metrics: AUROC, risk-coverage curve operating points
- Datasets: CounterFact, factual queries generated from Wikidata
- Comments: This paper models factual queries as constraint-satisfaction problems and finds that attention to constraint tokens significantly correlates with factual correctness/hallucinations.
- Metrics: AUROC, across multiple datasets and evaluation methods
- Datasets: PAWS, XSum, QAGS, FRANK, SummEval, BEGIN, Q^2, DialFact, FEVER, VitaminC
- Metrics: AUROC, across multiple datasets and evaluation methods
- Datasets: XSum, QAGS, FRANK, SummEval
SAC$^3$: Reliable Hallucination Detection in Black-Box Language Models via Semantic-aware Cross-check Consistency
- Metrics: Accuracy and AUROC: classification QA and open-domain QA
- Datasets: Prime number and senator search from Snowball Hallucination, HotpotQA and Nq-open QA
- Metrics: Faithfulness between predicted response and ground-truth knowledge (Tab. 1) -- Critic, Q², BERT F1, F1.
- Datasets: Wizard-of-Wikipedia (WoW), the DSTC9 and DSTC11 extensions of MultiWoZ 2.1, FaithDial -- a de-hallucinated subset of WoW.
- Metrics: Factual consistency of summaries: BERT-Precision and FactKB. MemoTrap and NQ-Swap: Exact Match.
- Datasets: Summarisation: CNN-DM, XSUM. Knowledge Conflicts: MemoTrap, NQ-Swap.
When Not to Trust Language Models: Investigating Effectiveness of Parametric and Non-Parametric Memories
- Metrics: Exact Match/Accuracy.
- Datasets: QA datasets with long-tail entities: PopQA, EntityQuestions; NQ.
- Metrics: Generation: Perplexity, Unigram Overlap (F1), BLEU-4, ROUGE-L. Overlap between generation and knowledge on which the human grounded during dataset collection: Knowledge F1; only consider words that are infrequent in the dataset when calculating F1: Rare F1.
- Datasets: Wow, CMU Document Grounded Conversations (CMU_DoG). Knowledge source: KiLT Wikipedia dump.
Just Ask for Calibration: Strategies for Eliciting Calibrated Confidence Scores from Language Models Fine-Tuned with Human Feedback
- Metrics: Expected Calibration Error (ECE) with temperature scaling (ECE-t); accuracy@coverage and coverage@accuracy.
- Datasets: Question Answering datasets assessing factual knowledge: TriviaQA, SciQ, TruthfulQA.
- Metrics: Percentage of Wrong Answers (Hallucinations) and cases where "the model knows it's wrong" (Snowballed Hallucinations).
- Datasets: Primality Testing, Senator Search, Graph Connectivity.
- Metrics: Faithfulness evaluation for Knowledge-Grounded response generation on FaithDial -- FaithCritic, CoLA (Fluency), Dialog Engagement, Length-penalised TF-IDF Diversity.
- Datasets: Faithful Knowledge-Grounded Dialog: FaithDial, a more faithful subset of WoW.
- Metrics: AUROC, AUARC, Uncertainty and Confidence metrics (NumSet, Deg, EigV).
- Datasets: CoQA (Open-book Conversational QA dataset), TriviaQA and Natural Questions (Closed-book QA).
- Metrics: AUROC, AUARC; Improved sequence likelihood (log probability of generated sequence) used in Confidence or Uncertainty computation.
- Datasets: CoQA (Open-book Conversational QA dataset), TriviaQA and Natural Questions (Closed-book QA).
- Metrics: Metrics measure either the degree of hallucination of generated responses wrt to some given knowledge or their overlap with gold faithful responses: Critic, Q² (F1, NLI), BERTScore, F1, BLEU, ROUGE.
- Datasets: FaithDial, WoW.
- Metrics: FeQA, a faithfulness metric; Critic, a hallucination critic; BLEU.
- Datasets: OpenDialKG, a dataset that provides open-ended dialogue responses grounded on paths from a KG.
- Metrics: Accuracy: QA, Dialogue, Summarisation.
- Datasets: HaluEval, a collection of generated and human-annotated hallucinated samples for evaluating the performance of LLMs in recognising hallucinations.
- Metrics: After generating sentence pairs, it measures precision, recall, and F1 score in detection tasks.
- Datasets: 12 selected topics from Wikipedia.
- Metrics: Coverage: a binary metric that determines whether all the correct gold answer values are included in the generated value. Hallucination: a binary indicator that assesses the presence of generated values that do not exist in the question values and gold grounding values. User Simulator: user simulator as an "oracle" language model with access to attribution information about the target answer.
- Datasets: FuzzyQA, a dataset based on HybridDialogue and MuSiQue where complex questions were simplified using ChatGPT.
Check Your Facts and Try Again: Improving Large Language Models with External Knowledge and Automated Feedback
- Metrics: KF1, BLEU, ROUGE, chrF, METEOR, BERTScore, BARTScore, BLEURT, Avg length.
- Datasets: News Chat: DSTC7 Track 2 was repurposed as an evaluation corpus for news conversation. Customer Service: uses DSTC11 Track 5 as a showcase in a conversational customer service scenario, expanding upon DSTC9 Track 1 by incorporating subjective information.
- Metrics: Sentence-level Hallucination Detection (AUC-PR), and Passage-level Hallucination Detection (Pearson and Spearman's correlation coefficients).
- Datasets: Generated Wikipedia articles from WikiBio, with annotated hallucinations.
- Metrics: Per-topic and average accuracy.
- Datasets: The True-False Dataset contains true and false statements covering several topics -- Cities, Inventions, Chemical Elements, Animals, Companies, and Scientific Facts.
- Metrics: Exact Match.
- Datasets: FEVER, Adversarial HotpotQA.
- Metrics: HaloCheck and SelfCheckGPT scores; consistency, factuality.
- Datasets: Generated and reviewed questions in the NBA domain.
A Stitch in Time Saves Nine: Detecting and Mitigating Hallucinations of LLMs by Validating Low-Confidence Generation
- Metrics: Precision and Recall when detecting Sentence-level and Concept-level Hallucinations.
- Datasets: ChatGPT-generated paragraphs spanning 150 topics from diverse domains.
- Metrics: Directional Levy/Holt precision and recall with entity insertions and replacements.
- Datasets: Levy/Holt dataset, containing premise-hypothesis pairs with a task formatted as Given [premise P], is it true that [hypothesis H]?, where the model is evaluated with random premises.
- Metrics: Rate to which MT system produces hallucinations under perturbation (Language Pair fraction, rate).
- Datasets: Flores-101, WMT, TICO.
- Metrics: N/A
- Datasets: N/A
- Metrics: Hallucinatory instruction classification: AUC, ACC, F1, PEA.
- Datasets: Concept-7, which focuses on classifying potential hallucinatory instructions.
- Metrics: Attributable to Identified Sources (AIS) scores before and after editing.
- Datasets: Generated statements by creating task inputs from three datasets and prompting different models to produce long-form outputs which may contain hallucinations -- Factoid statements, Reasoning chains, and Knowledge-intensive dialogues.
Q²: Evaluating Factual Consistency in Knowledge-Grounded Dialogues via Question Generation and Question Answering
- Metrics: Q² is a metric itself, and it is compared with F1 token-level overlap, Precision and Recall, Q² w/o NLI, E2E NLI, Overlap, BERTScore, and BLEU.
- Datasets: WoW which contains dialogues in which a bot needs to respond to user inputs in a knowledgeable way; Topical-Chat, a human-human knowledge-grounded conversation dataset; Dialogue NLI, a dataset based on the Persona-Chat dialogue task consisting of premise-hypothesis pairs.
- Metrics: EM on All, "Has answer", and "IDK"
- Datasets: MNLI, SQuAD 2.0, ACE-whQA.
- Metrics: Wikidata and Wiki-Category List: test precision, average number of positive and negative (hallucination) entities for list-based questions; MultiSpanQA: F1, Precision, Recall; Longform generation of biographies: FactScore.
- Datasets: Wikidata, Wiki-Category List, MultiSpanQA, Longform Generation of Biographies.
- Metrics: mFACT, a novel multilingual faithful metric developed from four English faithfulness metrics: DAE, QAFactEval, ENFS%, and EntFA.
- Datasets: XL-Sum, a multilingual summarisation dataset.
- Metrics: XEnt: Hallucination (Accuracy, F1), Factuality (Accuracy, F1), ROUGE, % of novel n-gram, Faithfulness (%ENFS, FEQA, DAE), EntFA (% Factual Ent., % Factual Hal.)
- Datasets: A novel dataset, XEnt, for analysing entity hallucination and factuality in abstractive summarisation, consisting of 800 summaries generated by BART and annotated. MEnt, a set of factuality and hallucination annotations for XSum.
- Comments: Tab. 2 outlines several types of hallucinations (e.g., factual, non-factual, intrinsic).
- Metrics: Fluency (MAUVE), Correctness (EM recall for ASQA, recall-5 for QAMPARI, claim recall for ELI5), Citation quality (citation recall, citation precision).
- Datasets: QA datasets such that 1) they contain factual questions in which references are important, 2) questions require long-text answers covering multiple aspects, and 3) answering the questions requires synthesising multiple sources: ASQA, QAMPARI, ELI5.
- Metrics: Acc, G-Mean, BSS, AUC, Not Hallucination (P, R, F1), Hallucination (P, R, F1).
- Datasets: HaDes (HAllucination DEtection dataSet), a novel token-level reference-free annotated hallucination detection dataset obtained by perturbing a large number of text segments extracted from the English Wikipedia and verified with crowd-sourced annotations.
- Comments: Fig. 3 outlines several hallucination types (domain-specific knowledge, commonsense knowledge, incoherence or improper collocation, unrelated to central topic, conflict with preceding context, conflict with succeeding context, ..)
- Metrics: Percentage of examples it assigns the highest probability to the factual completion.
- Datasets: Wiki-FACTOR and News-FACTOR: two novel factuality evaluation benchmarks for LLMs, based on Wikipedia and News articles. Each example consists of a prefix, a factual completion and three similar but non-factual alternatives.
- Comments: The paper introduces a framework for automatically generating such datasets from a given corpus, detailed in Section 3.
- Metrics: Hallucination rate (H%, out of 1000 generated titles)
- Datasets: Generated (true and hallucinated) references on topics from the ACM Computing Classification System.
- Metrics: #Correct and #Wrong answers, and different type of failure counts: Comprehension, Factualness, Specificity, Inference.
- Datasets: HotpotQA, BoolQ
- Comments: This has a nice taxonomy on different error types -- e.g., comprehension, factualness, specifity, inference.
- Metrics: Precision, Recall, F1 (under different cross-examination strategies: AYS, IDK, Confidence-Based, IC-IDK)
- Datasets: TriviaQA, NQ, PopQA
- Metrics: BLEU, ROUGE-L; FeQA, QuestEval, EntityCoverage (Precision, Recall, F1) to estimate the hallucination degree -- FrQA and QuestEval are QA-based metrics for evaluating the faithfulness of the output in the generation task.
- Datasets: OpenDialKG
- Metrics: %Supported statements across varying frequency levels of human entities.
- Datasets: People biographies generated from LLMs, where human annotators break them into supporting facts.
- Metrics: zero-shot (P, R, F1) and fine-tuned (P, R, F1) of AutoAIS labels; FActScore F1 scores on reference factuality labels; AutoAIS (Attributable to Identified Sources) scores.
- Datasets: Expert-curated questions across multiple fields (e.g., Anthropology, Architecture, Biology, Chemistry, Engineering & Technology, Healthcare/Medicine; see Tab. 1 for a sample) organised by Question Type (e.g., Directed question with single unambiguous answer, open-ended potentially ambiguous question, summarisation of information of a topic, advice or suggestion on how to approach a problem; see Tab. 2)
- Metrics: TruthffulQA: MC1, MC2, MC3 scores; FACTOR: News, Wiki; these were multiple-choice results. Open-ended generation: for TruthfulQA, they use %Truth, %Info, %Truth*Info, %Reject; for CoT tasks (StrategyQA and GSM8K) they go with accuracy.
- Datasets: TruthfulQA, FACTOR (news/wiki), StrategyQA, GSM8K
- Metrics: Accuracy (Strict, Relaxed on Fast-changing questions, Slow-changing questions, Never-changing questions, False-premise questions involve knowledge before 2022 and since 2022, 1-hop and multi-hop questions, and Overall).
- Datasets: FreshQA, a new QA benchmark with 600 questions covering a wide spectrum of question and answer types.
- Metrics: Factuality, Relevance, Coherence, Informativeness, Helpfulness and Validity.
- Datasets: Natural Questions, Wizard of Wikipedia.
- Metrics: Accuracy, MAE, Macro-F1, soft accuracy.
- Datasets: ClaimDecomp, which contains 1200 complex claims from PolitiFactL each claim is labeled with one of the six veracity labels, a justification paragraph written by expect fact-checkers, and subquestions annotated by prior work.
- Metrics: Accuracy, F1/Precision/Recall.
- Datasets: Reasoning, Math, Writing/Rec, Science/Tech, World Knowledge: GSM8K, ChatGPT, MATH, TruthfulQA, Quora, MMLU/hc3.
- Metrics: Humand and GPT-4 evaluations.
- Datasets: HalluQA (which they propose), and mention TruthfulQA, ChineseFactEval, HaluEval.
- Metrics: ROUGE, BERTScore; human assessment (identify hallucinatory spans, and whether it's intrinsic or extrinsic) -- intrinsic hallucinations are manipulations of the information in the input document, while extrinsic hallucinations are information not directly inferable from the input document. Humans were asked to annotate intrinsic and extrinsic hallucinations.
- Datasets: XSum.
- Metrics: QuestEval (proposed in this work), for testing for consistency, coherence, fluency, and relevance. ROUGE, BLUE, METEOR, BERTScore. SummaQA, QAGS.
- Datasets: SummEval, QAGS-XSUM, SQuAD-v2.
- Metrics: QAFactEval (proposed in this work), measuring answer selection, question generation, question answering, answer overlap, and filtering/answerability.
- Datasets: SummaC, a collection of benchmarks for binary factual consistency evaluation; CGS, correct and incorrect sentences from CNN/DailyMail; XSF; Polytope; FactCC; SummEval; FRANK; QAGs.
- Metrics: SCALE (new metric proposed in this work). Compared with Q², ANLI, SummaC, F1, BLEURT, QuestEval, BARTScore, BERTScore (Table 3).
- Datasets: TRUE benchmark and ScreenEval, new dataset proposed in this work to assess the factual inconsistency in long-form dialogues (52 documents from SummScreen).
Understanding Factuality in Abstractive Summarization with FRANK: A Benchmark for Factuality Metrics
- Metrics: BERTScore, FEQA, QGFS, DAE, FactCC
- Datasets: Proposed a new dataset FRANK: human annotated factual errors for CNN/DM and XSum dataset
- Metrics: Q², ANLI, SummaC, BLEURT, QuestEval, FactCC, BARTScore, BERTScore
- Datasets: Consolidation of 11 different human annotated datasets for fctual consistency.
- Metrics: (classification) F-1, Exact Match, (token) F-1
- Datasets: SQuAD, Natural Questions, MuSiQue
- Comments: This paper models explores LLMs' handling of (un)answerable questions in a closed-book setting, namely answering a question based on a given passage, where the passage doesn't have the answer. The paper shows that despite LLMs' tendency to hallucinate contextual answers, rather than state that they cannot answer the question, they possess internal understanding of the question's (un)answerability.
- Metrics: (Hallucination detection) Response-level F1, Span-level Partial Credit Match F1
- Datasets: Organically generated and synthetically edited CNN DailyMail, ConvFEVER, and E2E, labeled span-wise for hallucinations
- Comments: Language models know when they're hallucinating, and we can train probes on LLM hidden states during decoding to reliably detect them.
- Metrics: AlignScore, FactCC, BS-Fact, ROUGE-L
- Datasets: CNN/DM, XSum, Newsroom
- Metrics: Precision, Recall, F1.
- Datasets: Custom fine-grained hallucination detection/editing dataset for various types of (factual) hallucinations: Entity, Relation, Contradictory, Invented, Subjective, Unverifiable.
- Metrics: Accuracy for various error types -- positive examples, date swap, entity swap, negated sentences, number swap, pronoun swap.
- Datasets: They propose SummEdits, a 10-domain inconsistency detection benchmark.
- Metrics: They propose FactCC, a metric that measures the factual consistency of abstractive text summarization (intuition: a summary is factually consistent if it contains the same facts as the source document)
- Datasets: CNN/DM for generating training data; MNLI and FEVER for training models. Human-based experiments for evaluation on claims about CNN/DM articles.
- Metrics: Each dataset comes with its metrics (e.g., CoGenSumm uses a reranking-based measure; XSumFaith, SummEval, and FRANK propose several metrics and analyse how they correlate with human annotations; etc.) -- for SummaC, authors propose using balanced accuracy.
- Datasets: They propose SummaC (Summary Consistency), a benchmark consisting of six large inconsistency detection datasets: CoGenSumm, XSumFaith, Polytope, FactCC, SummEval, and FRANK.
- Metrics: Expert and non-expert annotations: Partial Hallucination, Entailment, Hallucination, Uncoop, Generic (each of these categories has more fine-grained sub-classes -- see e.g., Fig. 2) -- annotations follow the BEGIN and VRM taxonomies.
- Datasets: Knowledge-grounded conversational benchmarks: Wizard of Wikipedia (WoW), CMU-DoG, and TopicalChat -- datasets consisting of dialogues between two speakers where the goal is to communicate information about particular topics while speakers are presented with a knowledge snippet relevant to the current turn.
- Metrics: Hallucination rate in several settings (original, with optimised system message, with full LLM weights, with synthetic data, or with mixtures of synthetic and reference data); BLEU, ROUGE-1, ROUGE-2, ROUGE-L.
- Datasets: Search-and-retrieve (MS MARCO), meeting summarisation (QMSum), automated clinical report generation (ACI-Bench).
- Metrics: ROUGE-L, BERTScore, BS-Fact, FactCC, DAE, QuestEval
- Datasets: CNN/DM, XSum
- Metrics: Conversational QA: models fine-tuned on MNLI, SNLI, FEVER, PAWS, ScTail, and VitaminC. Summarisation: models fine-tuned on ANLI and XNLI.
- Datasets: Question Rewriting in Conversational Context (QReCC), XLSum.
- Metrics: Hallucination Risk Metrics (HaRiM+), SummaC, SummaCzs, SummaCconv, Hallucination Risk Ratio (HRR)
- Datasets: FactCC, Polytope, SummEval, Legal Contracts, RCT
- Metrics: EM, Memorisation ratio.
- Datasets: NQ Dev with Answer Overlap (AO) and No Answer Overlap (NAO), NewsQA.
- Metrics: MC1/MC2/MC3 scores for TruthffulQA multiple-choice task; %Truth, %Info, %Truth*Info for TruthffulQA open-ended generation task; Choice accuracy for Natural Questions, TriviaQA and FACTOR (news, expert, wiki).
- Datasets: TruthfulQA, Natural Questions, TriviaQA, FACTOR (news, expert, wiki)
- Metrics: Accuracy, Final Answer Truncation Sensitivity, Final Answer Corruption Sensitivity, Biased-Context Accuracy Change.
- Datasets: HotpotQA, OpenbookQA, StrategyQA, TruthfulQA.
- Metrics: For detection: Precision, Recall, F1. For Mitigation: Ratio of self-contradiction removed, Ratio of informative facts retained, perplexity increased.
- Datasets: Custom Open-domain Text Generation dataset, LLM-generated encyclopedic text descriptions for Wikipedia entities, PopQA.
- Metrics: For detection: AUROC, AURAC.
- Datasets: QA: TriviaQA, SQuAD, BioASQ, NQ-Open, SVAMP. FactualBio, a biography-generation dataset, accompanying this paper.
- Metrics: Propose CAST, a simple self-consistency metric that seeks to evaluate whether multimodal models are consistent across modalities. This works in two stage, in the first stage the models generate similarities/true statements comparing two inputs, and in the second stage the model judges its own output for truthfulness. A consistent model should therefore always evaluate its own outputs as true.
- Metrics: Reasoning Hallucination Tests (False Confidence Tests, None of the Above Tests, Fake Questions Tests), Memory Hallucination Tests (Abstract-to-Link Tests, PMID-to-Title Tests, Title-to-Link Tests, Link-to-Title Tests); Accuracy, Pointwise Score.
- Datasets: Med-HALT: MEDMCQA, Headqa, Medqa USMILE, Medqa (Taiwan), Pubmed.
- Metrics: Accuracy, Accuracy plausible match
- Datasets: ATLAS dataset, TFix dataset
- Comments:: Published at ICSE 2023
- Mitigating LLM Hallucinations: a multifaceted approach
- Siren’s Song in the AI Ocean: A Survey on Hallucination in Large Language Models
- Survey of Hallucination in Natural Language Generation
- A Survey of Hallucination in Large Foundation Models
-
A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions
- Paper available here
- Two main categories: factuality hallucinations and faithfulness hallucinations. Factuality hallucinations emphasise the discrepancy between generated content and verifiable real-world facts, typically manifesting as factual inconsistencies or fabrications. Faithfulness hallucinations refer to the divergence of generated content from user instructions or the context provided by the input, as well as self-consistency within generated content.
- LLM Powered Autonomous Agents
- SemEval-2024 Task-6 - SHROOM, a Shared-task on Hallucinations and Related Observable Overgeneration Mistakes
- llm-hallucination-survey
- How Do Large Language Models Capture the Ever-changing World Knowledge? A Review of Recent Advances
- The Dawn After the Dark: An Empirical Study on Factuality Hallucination in Large Language Models

Survey of Hallucination in Natural Language Generation classifies metrics in Statistical (ROUGE, BLEU, PARENT, Knowledge F1, ..) and Model-based metrics. The latter are further structured in the following classes:
- Information-Extraction (IE)-based: retrieve an answer from a knowledge source and compare it with the generated answer -- there might be problems due to the error propagation from the IE model.
- QA-based: measure the overlap/consistency between generation and source reference, based on the intuition that similar answers will be generated from the same question if the generation is factually consistent with the source reference. Used to evaluate hallucinations in summarisation, dialogue, and data2text generation. Composed of a question generation model and a question answering model.
- Natural Language Inference (NLI)-based: based on the idea that only the source knowledge reference should entail the entirety of the information in faithful and hallucination-free generation.
A Survey of Hallucination in “Large” Foundation Models surveys papers flagging them for detection, mitigation, tasks, datasets, and evaluation metrics. Regarding hallucinations in text, it categorises papers by LLMs, Multilingual LLMs, and Domain-specific LLMs.
The Dawn After the Dark: An Empirical Study on Factuality Hallucination in Large Language Models proposed a taxonomy of different types of hallucinations: Entity-error Hallucination, Relation-error Hallucination, Incompleteness Hallucination, Outdatedness Hallucination, Overclaim Hallucination, Unverifiability Hallucination.
Internal Consistency and Self-Feedback in Large Language Models: A Survey proposed a new perspective, Internal Consistency, to approach "enhancing reasoning" and ""alleviating hallucinations". This perspective allowed us to unify many seemingly unrelated works into a single framework. To improve internal consistency (which in turn enhances reasoning ability and mitigates hallucinations), this paper identified common elements across various works and summarized them into a Self-Feedback framework.
This framework consists of three components: Self-Evaluation, Internal Consistency Signal, and Self-Update.
- Self-Evaluation: Responsible for evaluating the model's internal consistency based on its language expressions, decoding layer probability distributions, and hidden states.
- Internal Consistency Signal: Through Self-Evaluation, we can obtain numerical, textual, external, and even comparative signals.
- Self-Update: Using these signals, we can update the model's expressions or even the model itself to improve internal consistency.
- AnyScale - Llama 2 is about as factually accurate as GPT-4 for summaries and is 30X cheaper
- Arthur.ai - Hallucination Experiment
- Vectara - Cut the Bull…. Detecting Hallucinations in Large Language Models
- Vectara LLM Hallucination Leaderboard
- TofuEval: Evaluating Hallucinations of LLMs on Topic-Focused Dialogue Summarization
- MiniCheck Code and Model - GitHub
- AlignScore Code and Model - GitHub
- Google True Teacher Model - HuggingFace
- Hallucination Evaluation Model - HuggingFace
- Summac Code and Model - GitHub
- SCALE Code and Model - GitHub
Neural Path Hunter defines as extrinsic hallucination as an utterance that brings a new span of text that does not correspond to a valid triple in a KG, and as intrinsic hallucination as an utterance that misuses either the subject or object in a KG triple such that there is no direct path between the two entities. Survey of Hallucination in Natural Language Generation defines as extrinsic hallucination a case where the generated output that cannot be verified from the source content, and as an intrinsic hallucination a case where the generated output contradicts the source content.
@misc{MinerviniAHD2024,
author = {Pasquale Minervini and Aryo Pradipta Gema and others},
title = {awesome-hallucination-detection},
year = {2024},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/EdinburghNLP/awesome-hallucination-detection}}
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for awesome-hallucination-detection
Similar Open Source Tools
awesome-hallucination-detection
This repository provides a curated list of papers, datasets, and resources related to the detection and mitigation of hallucinations in large language models (LLMs). Hallucinations refer to the generation of factually incorrect or nonsensical text by LLMs, which can be a significant challenge for their use in real-world applications. The resources in this repository aim to help researchers and practitioners better understand and address this issue.
llm_benchmarks
llm_benchmarks is a collection of benchmarks and datasets for evaluating Large Language Models (LLMs). It includes various tasks and datasets to assess LLMs' knowledge, reasoning, language understanding, and conversational abilities. The repository aims to provide comprehensive evaluation resources for LLMs across different domains and applications, such as education, healthcare, content moderation, coding, and conversational AI. Researchers and developers can leverage these benchmarks to test and improve the performance of LLMs in various real-world scenarios.

HuixiangDou2
HuixiangDou2 is a robustly optimized GraphRAG approach that integrates multiple open-source projects to improve performance in graph-based augmented generation. It conducts comparative experiments and achieves a significant score increase, leading to a GraphRAG implementation with recognized performance. The repository provides code improvements, dense retrieval for querying entities and relationships, real domain knowledge testing, and impact analysis on accuracy.

llms-learning
A repository sharing literatures and resources about Large Language Models (LLMs) and beyond. It includes tutorials, notebooks, course assignments, development stages, modeling, inference, training, applications, study, and basics related to LLMs. The repository covers various topics such as language models, transformers, state space models, multi-modal language models, training recipes, applications in autonomous driving, code, math, embodied intelligence, and more. The content is organized by different categories and provides comprehensive information on LLMs and related topics.

Slow_Thinking_with_LLMs
STILL is an open-source project exploring slow-thinking reasoning systems, focusing on o1-like reasoning systems. The project has released technical reports on enhancing LLM reasoning with reward-guided tree search algorithms and implementing slow-thinking reasoning systems using an imitate, explore, and self-improve framework. The project aims to replicate the capabilities of industry-level reasoning systems by fine-tuning reasoning models with long-form thought data and iteratively refining training datasets.

TurtleBenchmark
Turtle Benchmark is a novel and cheat-proof benchmark test used to evaluate large language models (LLMs). It is based on the Turtle Soup game, focusing on logical reasoning and context understanding abilities. The benchmark does not require background knowledge or model memory, providing all necessary information for judgment from stories under 200 words. The results are objective and unbiased, quantifiable as correct/incorrect/unknown, and impossible to cheat due to using real user-generated questions and dynamic data generation during online gameplay.

MMStar
MMStar is an elite vision-indispensable multi-modal benchmark comprising 1,500 challenge samples meticulously selected by humans. It addresses two key issues in current LLM evaluation: the unnecessary use of visual content in many samples and the existence of unintentional data leakage in LLM and LVLM training. MMStar evaluates 6 core capabilities across 18 detailed axes, ensuring a balanced distribution of samples across all dimensions.

MMMU
MMMU is a benchmark designed to evaluate multimodal models on college-level subject knowledge tasks, covering 30 subjects and 183 subfields with 11.5K questions. It focuses on advanced perception and reasoning with domain-specific knowledge, challenging models to perform tasks akin to those faced by experts. The evaluation of various models highlights substantial challenges, with room for improvement to stimulate the community towards expert artificial general intelligence (AGI).

cleanlab
Cleanlab helps you **clean** data and **lab** els by automatically detecting issues in a ML dataset. To facilitate **machine learning with messy, real-world data** , this data-centric AI package uses your _existing_ models to estimate dataset problems that can be fixed to train even _better_ models.
AI6127
AI6127 is a course focusing on deep neural networks for natural language processing (NLP). It covers core NLP tasks and machine learning models, emphasizing deep learning methods using libraries like Pytorch. The course aims to teach students state-of-the-art techniques for practical NLP problems, including writing, debugging, and training deep neural models. It also explores advancements in NLP such as Transformers and ChatGPT.
llm_benchmark
The 'llm_benchmark' repository is a personal evaluation project that tracks and tests various large models in areas such as logic, mathematics, programming, and human intuition. The evaluation consists of a private question bank with around 30 questions and 240 test cases, updated monthly. The scoring method involves assigning points based on correct deductions and meeting specific requirements, with scores normalized to a scale of 10. The repository aims to observe the long-term evolution trends of different large models from a subjective perspective, providing insights and a testing approach for individuals to assess large models.
MathPile
MathPile is a generative AI tool designed for math, offering a diverse and high-quality math-centric corpus comprising about 9.5 billion tokens. It draws from various sources such as textbooks, arXiv, Wikipedia, ProofWiki, StackExchange, and web pages, catering to different educational levels and math competitions. The corpus is meticulously processed to ensure data quality, with extensive documentation and data contamination detection. MathPile aims to enhance mathematical reasoning abilities of language models.
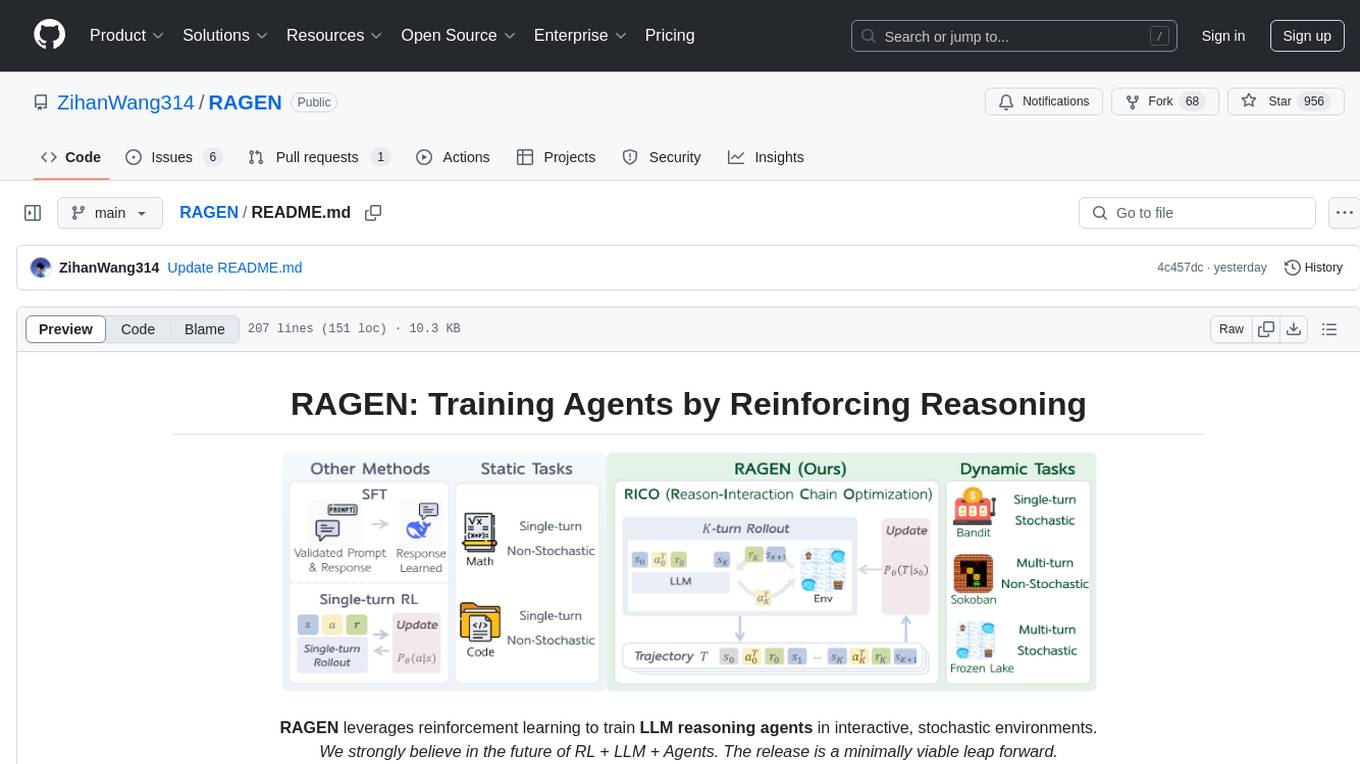
RAGEN
RAGEN is a reinforcement learning framework designed to train reasoning-capable large language model (LLM) agents in interactive, stochastic environments. It addresses challenges such as multi-turn interactions and stochastic environments through a Markov Decision Process (MDP) formulation, Reason-Interaction Chain Optimization (RICO) algorithm, and progressive reward normalization strategies. The framework enables LLMs to reason and interact with the environment, optimizing entire trajectories for long-horizon reasoning while maintaining computational efficiency.
VeritasGraph
VeritasGraph is an enterprise-grade graph RAG framework designed for secure, on-premise AI applications. It leverages a knowledge graph to perform complex, multi-hop reasoning, providing transparent, auditable reasoning paths with full source attribution. The framework excels at answering complex questions that traditional vector search engines struggle with, ensuring trust and reliability in enterprise AI. VeritasGraph offers full control over data and AI models, verifiable attribution for every claim, advanced graph reasoning capabilities, and open-source deployment with sovereignty and customization.
learn-agentic-ai
Learn Agentic AI is a repository that is part of the Panaversity Certified Agentic and Robotic AI Engineer program. It covers AI-201 and AI-202 courses, providing fundamentals and advanced knowledge in Agentic AI. The repository includes video playlists, projects, and project submission guidelines for students to enhance their understanding and skills in the field of AI engineering.
For similar tasks
awesome-hallucination-detection
This repository provides a curated list of papers, datasets, and resources related to the detection and mitigation of hallucinations in large language models (LLMs). Hallucinations refer to the generation of factually incorrect or nonsensical text by LLMs, which can be a significant challenge for their use in real-world applications. The resources in this repository aim to help researchers and practitioners better understand and address this issue.
For similar jobs

LLM-FineTuning-Large-Language-Models
This repository contains projects and notes on common practical techniques for fine-tuning Large Language Models (LLMs). It includes fine-tuning LLM notebooks, Colab links, LLM techniques and utils, and other smaller language models. The repository also provides links to YouTube videos explaining the concepts and techniques discussed in the notebooks.

lloco
LLoCO is a technique that learns documents offline through context compression and in-domain parameter-efficient finetuning using LoRA, which enables LLMs to handle long context efficiently.

camel
CAMEL is an open-source library designed for the study of autonomous and communicative agents. We believe that studying these agents on a large scale offers valuable insights into their behaviors, capabilities, and potential risks. To facilitate research in this field, we implement and support various types of agents, tasks, prompts, models, and simulated environments.
llm-baselines
LLM-baselines is a modular codebase to experiment with transformers, inspired from NanoGPT. It provides a quick and easy way to train and evaluate transformer models on a variety of datasets. The codebase is well-documented and easy to use, making it a great resource for researchers and practitioners alike.
python-tutorial-notebooks
This repository contains Jupyter-based tutorials for NLP, ML, AI in Python for classes in Computational Linguistics, Natural Language Processing (NLP), Machine Learning (ML), and Artificial Intelligence (AI) at Indiana University.
EvalAI
EvalAI is an open-source platform for evaluating and comparing machine learning (ML) and artificial intelligence (AI) algorithms at scale. It provides a central leaderboard and submission interface, making it easier for researchers to reproduce results mentioned in papers and perform reliable & accurate quantitative analysis. EvalAI also offers features such as custom evaluation protocols and phases, remote evaluation, evaluation inside environments, CLI support, portability, and faster evaluation.
Weekly-Top-LLM-Papers
This repository provides a curated list of weekly published Large Language Model (LLM) papers. It includes top important LLM papers for each week, organized by month and year. The papers are categorized into different time periods, making it easy to find the most recent and relevant research in the field of LLM.
self-llm
This project is a Chinese tutorial for domestic beginners based on the AutoDL platform, providing full-process guidance for various open-source large models, including environment configuration, local deployment, and efficient fine-tuning. It simplifies the deployment, use, and application process of open-source large models, enabling more ordinary students and researchers to better use open-source large models and helping open and free large models integrate into the lives of ordinary learners faster.