
UltraRAG
#Less Code, #Lower Barrier, #Faster Deployment!MCP-based low-code RAG framework, enabling researchers to build complex pipelines to creative innovation.
Stars: 1366

The UltraRAG framework is a researcher and developer-friendly RAG system solution that simplifies the process from data construction to model fine-tuning in domain adaptation. It introduces an automated knowledge adaptation technology system, supporting no-code programming, one-click synthesis and fine-tuning, multidimensional evaluation, and research-friendly exploration work integration. The architecture consists of Frontend, Service, and Backend components, offering flexibility in customization and optimization. Performance evaluation in the legal field shows improved results compared to VanillaRAG, with specific metrics provided. The repository is licensed under Apache-2.0 and encourages citation for support.
README:

| 项目主页 | 教程文档 | 数据集 | 简体中文 | English |
更新日志 🔥
- [2025.09.01] 我们录了一期上手视频,手把手教你安装 UltraRAG 并跑通完整的 RAG 👉📺 bilibili
- [2025.08.28] 🎉 发布 UltraRAG 2.0! UltraRAG 2.0 全新升级:几十行代码实现高性能 RAG,让科研专注思想创新!
- [2025.01.23] 发布 UltraRAG! 让大模型读懂善用知识库!我们保留了UltraRAG 1.0的代码,可以点击 v1 查看。
检索增强生成系统(RAG)正从早期“检索+生成”的简单拼接,走向融合 自适应知识组织、多轮推理、动态检索 的复杂知识系统(典型代表如 DeepResearch、Search-o1)。但这种复杂度的提升,使科研人员在 方法复现、快速迭代新想法 时,面临着高昂的工程实现成本。
为了解决这一痛点,清华大学 THUNLP 实验室、东北大学 NEUIR 实验室、OpenBMB 与 AI9stars 联合推出 UltraRAG 2.0 (UR-2.0)—— 首个基于 Model Context Protocol (MCP) 架构设计的 RAG 框架。这一设计让科研人员只需编写 YAML 文件,就可以直接声明串行、循环、条件分支等复杂逻辑,从而以极低的代码量快速实现多阶段推理系统。
其核心思路是:
- 组件化封装:将RAG 的核心组件封装为标准化的独立 MCP Server;
- 灵活调用与扩展:提供 函数级 Tool 接口,支持功能的灵活调用与扩展;
- 轻量流程编排:借助 MCP Client,建立自上而下的简洁化链路搭建;
与传统框架相比,UltraRAG 2.0 显著降低了复杂 RAG 系统的 技术门槛与学习成本,让研究者能够将更多精力投入到 实验设计与算法创新 上,而不是陷入冗长的工程实现。
-
🚀 低代码构建复杂 Pipeline
原生支持 串行、循环、条件分支 等推理控制结构。开发者只需编写 YAML 文件,即可实现几十行代码构建的 迭代式 RAG 流程(如 Search-o1 等)。 -
⚡ 快速复现与功能扩展
基于 MCP 架构,所有模块均封装为独立、可复用的 Server。- 用户可按需自定义 Server 或直接复用现有模块;
- 每个 Server 的功能以函数级 Tool 注册,新增功能仅需添加一个函数即可接入完整流程;
- 同时支持调用 外部 MCP Server,轻松扩展 Pipeline 能力与应用场景。
-
📊 统一评测与对比
内置 标准化评测流程与指标管理,开箱即用支持 17 个主流科研 Benchmark。- 持续集成最新基线;
- 提供 Leaderboard 结果;
- 方便科研人员进行系统性对比与优化实验。
在不同的 RAG 系统中,检索、生成等核心能力在功能上具有高度相似性,但由于开发者实现策略各异,模块之间往往缺乏统一接口,难以跨项目复用。Model Context Protocol (MCP) 作为一种开放协议,规范了为大型语言模型(LLMs)提供上下文的标准方式,并采用 Client–Server 架构,使得遵循该协议开发的 Server 组件可以在不同系统间无缝复用。
受此启发,UltraRAG 2.0 基于 MCP 架构,将 RAG 系统中的检索、生成、评测等核心功能抽象并封装为相互独立的 MCP Server,并通过标准化的函数级 Tool 接口实现调用。这一设计既保证了模块功能扩展的灵活性,又允许新模块以“热插拔”的方式接入,无需对全局代码进行侵入式修改。在科研场景中,这种架构让研究者能够以极低的代码量快速适配新的模型或算法,同时保持整体系统的稳定性与一致性。

复杂 RAG 推理框架的开发具有显著挑战,而 UltraRAG 2.0 之所以能够在低代码条件下支持复杂系统的构建,核心在于其底层对多结构 Pipeline 流程控制的原生支持。无论是串行、循环还是条件分支,所有控制逻辑均可在 YAML 层完成定义与调度,覆盖复杂推理任务所需的多种流程表达方式。在实际运行中,推理流程的调度由内置 Client 执行,其逻辑完全由用户编写的外部 Pipeline YAML 脚本 脚本描述,从而实现与底层实现的解耦。开发者可以像使用编程语言关键字一样调用 loop、step 等指令,以声明的方式快速构建多阶段推理流程。
通过将 MCP 架构 与 原生流程控制深度融合,UltraRAG 2.0 让复杂 RAG 系统的搭建像“编排流程”一样自然高效。此外,框架内置 17 个主流 benchmark 任务与多种高质量 baseline,配合统一的评测体系与知识库支持,进一步提升了系统开发的效率与实验的可复现性。
conda create -n ultrarag python=3.11
conda activate ultrarag通过 git 克隆项目到本地或服务器:
git clone https://github.com/OpenBMB/UltraRAG.git
cd UltraRAG我们推荐使用 uv 来进行包管理,提供更快、更可靠的 Python 依赖管理体验:
pip install uv
uv pip install -e .如果您更习惯 pip,也可以直接运行:
pip install -e .【可选】UR-2.0支持丰富的Server组件,开发者可根据实际任务灵活安装所需依赖:
# 如需使用faiss进行向量索引:
# 需要根据自己的硬件环境,手动编译安装 CPU 或 GPU 版本的 FAISS:
# CPU版本:
uv pip install faiss-cpu
# GPU 版本(示例:CUDA 12.x)
uv pip install faiss-gpu-cu12
# 其他 CUDA 版本请安装对应的包(例如:CUDA 11.x 使用 faiss-gpu-cu11)
# 如需使用infinity_emb进行语料库编码和索引:
uv pip install -e ".[infinity_emb]"
# 如需使用lancedb向量数据库:
uv pip install -e ".[lancedb]"
# 如需使用vLLM服务部署模型:
uv pip install -e ".[vllm]"
# 如需使用语料库文档解析功能:
uv pip install -e ".[corpus]"
# ====== 安装所有依赖(除faiss) ======
uv pip install -e ".[all]"运行以下命令验证安装是否成功:
# 成功运行显示'Hello, UltraRAG 2.0!' 欢迎语
ultrarag run examples/sayhello.yaml通过 git 克隆项目到本地或服务器:
git clone https://github.com/OpenBMB/UltraRAG.git
cd UltraRAG构建镜像:
docker build -t ultrarag:v2.0.0-beta .运行交互环境:
docker run -it --rm --gpus all ultrarag:v2.0.0-beta bash运行以下命令验证安装是否成功:
# 成功运行显示'Hello, UltraRAG 2.0!' 欢迎语
ultrarag run examples/sayhello.yaml我们提供了从入门到进阶的完整教学示例,欢迎访问教程文档快速上手 UltraRAG 2.0!
阅读快速上手,了解 UltraRAG 的使用流程。整体分为三步:① 编译 Pipeline 文件生成参数配置;② 修改参数文件;③ 运行 Pipeline 文件。
此外,我们整理了一份科研中常用功能的目录,您可以直接点击跳转到所需模块:
UltraRAG 2.0 开箱即用,内置支持当前 RAG 领域最常用的 公开评测数据集、大规模语料库 以及 典型基线方法,方便科研人员快速复现与扩展实验。你也可以参考数据格式说明,灵活地自定义并添加任意数据集或语料库。完整的数据集可通过该链接访问与下载。
| 任务类型 | 数据集名称 | 原始数据数量 | 评测采样数量 |
|---|---|---|---|
| QA | NQ | 3,610 | 1,000 |
| QA | TriviaQA | 11,313 | 1,000 |
| QA | PopQA | 14,267 | 1,000 |
| QA | AmbigQA | 2,002 | 1,000 |
| QA | MarcoQA | 55,636 | 1,000 |
| QA | WebQuestions | 2,032 | 1,000 |
| Multi-hop QA | HotpotQA | 7,405 | 1,000 |
| Multi-hop QA | 2WikiMultiHopQA | 12,576 | 1,000 |
| Multi-hop QA | Musique | 2,417 | 1,000 |
| Multi-hop QA | Bamboogle | 125 | 125 |
| Multi-hop QA | StrategyQA | 2,290 | 1,000 |
| Multiple-choice | ARC | 3,548 | 1,000 |
| Multiple-choice | MMLU | 14,042 | 1,000 |
| Long-form QA | ASQA | 948 | 948 |
| Fact-verification | FEVER | 13,332 | 1,000 |
| Dialogue | WoW | 3,054 | 1,000 |
| Slot-filling | T-REx | 5,000 | 1,000 |
| 语料库名称 | 文档数量 |
|---|---|
| wiki-2018 | 21,015,324 |
| wiki-2024 | 整理中,即将上线 |
| 基线名称 | 脚本 |
|---|---|
| Vanilla LLM | examples/vanilla.yaml |
| Vanilla RAG | examples/rag.yaml |
| IRCoT | examples/IRCoT.yaml |
| IterRetGen | examples/IterRetGen.yaml |
| RankCoT | examples/RankCoT.yaml |
| R1-searcher | examples/r1_searcher.yaml |
| Search-o1 | examples/search_o1.yaml |
| Search-r1 | examples/search_r1.yaml |
| WebNote | examples/webnote.yaml |
感谢以下贡献者在代码提交和测试中的付出。我们也欢迎新的成员加入,共同构建完善的 RAG 生态!
您可以通过以下标准流程来贡献:Fork 本仓库 → 提交 Issue → 发起 Pull Request (PR)。
如果您觉得本项目对您的研究有所帮助,欢迎点亮一颗 ⭐ 来支持我们!
- 关于技术问题及功能请求,请使用 GitHub Issues 功能。
- 关于使用上的问题、意见以及任何关于 RAG 技术的讨论,欢迎加入我们的微信群组,飞书群组和discord,与我们共同交流。
{kind=link}
{kind=link}
 微信群组 |
 飞书群组 |
Discord |
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for UltraRAG
Similar Open Source Tools
UltraRAG
The UltraRAG framework is a researcher and developer-friendly RAG system solution that simplifies the process from data construction to model fine-tuning in domain adaptation. It introduces an automated knowledge adaptation technology system, supporting no-code programming, one-click synthesis and fine-tuning, multidimensional evaluation, and research-friendly exploration work integration. The architecture consists of Frontend, Service, and Backend components, offering flexibility in customization and optimization. Performance evaluation in the legal field shows improved results compared to VanillaRAG, with specific metrics provided. The repository is licensed under Apache-2.0 and encourages citation for support.
BlueLM
BlueLM is a large-scale pre-trained language model developed by vivo AI Global Research Institute, featuring 7B base and chat models. It includes high-quality training data with a token scale of 26 trillion, supporting both Chinese and English languages. BlueLM-7B-Chat excels in C-Eval and CMMLU evaluations, providing strong competition among open-source models of similar size. The models support 32K long texts for better context understanding while maintaining base capabilities. BlueLM welcomes developers for academic research and commercial applications.
prisma-ai
Prisma-AI is an open-source tool designed to assist users in their job search process by addressing common challenges such as lack of project highlights, mismatched resumes, difficulty in learning, and lack of answers in interview experiences. The tool utilizes AI to analyze user experiences, generate actionable project highlights, customize resumes for specific job positions, provide study materials for efficient learning, and offer structured interview answers. It also features a user-friendly interface for easy deployment and supports continuous improvement through user feedback and collaboration.
nndeploy
nndeploy is a tool that allows you to quickly build your visual AI workflow without the need for frontend technology. It provides ready-to-use algorithm nodes for non-AI programmers, including large language models, Stable Diffusion, object detection, image segmentation, etc. The workflow can be exported as a JSON configuration file, supporting Python/C++ API for direct loading and running, deployment on cloud servers, desktops, mobile devices, edge devices, and more. The framework includes mainstream high-performance inference engines and deep optimization strategies to help you transform your workflow into enterprise-level production applications.

ChatGPT-Next-Web-Pro
ChatGPT-Next-Web-Pro is a tool that provides an enhanced version of ChatGPT-Next-Web with additional features and functionalities. It offers complete ChatGPT-Next-Web functionality, file uploading and storage capabilities, drawing and video support, multi-modal support, reverse model support, knowledge base integration, translation, customizations, and more. The tool can be deployed with or without a backend, allowing users to interact with AI models, manage accounts, create models, manage API keys, handle orders, manage memberships, and more. It supports various cloud services like Aliyun OSS, Tencent COS, and Minio for file storage, and integrates with external APIs like Azure, Google Gemini Pro, and Luma. The tool also provides options for customizing website titles, subtitles, icons, and plugin buttons, and offers features like voice input, file uploading, real-time token count display, and more.
Speech-AI-Forge
Speech-AI-Forge is a project developed around TTS generation models, implementing an API Server and a WebUI based on Gradio. The project offers various ways to experience and deploy Speech-AI-Forge, including online experience on HuggingFace Spaces, one-click launch on Colab, container deployment with Docker, and local deployment. The WebUI features include TTS model functionality, speaker switch for changing voices, style control, long text support with automatic text segmentation, refiner for ChatTTS native text refinement, various tools for voice control and enhancement, support for multiple TTS models, SSML synthesis control, podcast creation tools, voice creation, voice testing, ASR tools, and post-processing tools. The API Server can be launched separately for higher API throughput. The project roadmap includes support for various TTS models, ASR models, voice clone models, and enhancer models. Model downloads can be manually initiated using provided scripts. The project aims to provide inference services and may include training-related functionalities in the future.
Feishu-MCP
Feishu-MCP is a server that provides access, editing, and structured processing capabilities for Feishu documents for Cursor, Windsurf, Cline, and other AI-driven coding tools, based on the Model Context Protocol server. This project enables AI coding tools to directly access and understand the structured content of Feishu documents, significantly improving the intelligence and efficiency of document processing. It covers the real usage process of Feishu documents, allowing efficient utilization of document resources, including folder directory retrieval, content retrieval and understanding, smart creation and editing, efficient search and retrieval, and more. It enhances the intelligent access, editing, and searching of Feishu documents in daily usage, improving content processing efficiency and experience.
bailing
Bailing is an open-source voice assistant designed for natural conversations with users. It combines Automatic Speech Recognition (ASR), Voice Activity Detection (VAD), Large Language Model (LLM), and Text-to-Speech (TTS) technologies to provide a high-quality voice interaction experience similar to GPT-4o. Bailing aims to achieve GPT-4o-like conversation effects without the need for GPU, making it suitable for various edge devices and low-resource environments. The project features efficient open-source models, modular design allowing for module replacement and upgrades, support for memory function, tool integration for information retrieval and task execution via voice commands, and efficient task management with progress tracking and reminders.
XianyuAutoAgent
Xianyu AutoAgent is an AI customer service robot system specifically designed for the Xianyu platform, providing 24/7 automated customer service, supporting multi-expert collaborative decision-making, intelligent bargaining, and context-aware conversations. The system includes intelligent conversation engine with features like context awareness and expert routing, business function matrix with modules like core engine, bargaining system, technical support, and operation monitoring. It requires Python 3.8+ and NodeJS 18+ for installation and operation. Users can customize prompts for different experts and contribute to the project through issues or pull requests.
torra-community
Torra Community Edition is a modern AI workflow and intelligent agent visualization editor based on Nuxt 4. It offers a lightweight but production-ready architecture with frontend VueFlow + Tailwind v4 + shadcn/ui, backend FeathersJS, and built-in LangChain.js runtime. It supports multiple databases (SQLite/MySQL/MongoDB) and local ↔ cloud hot switching. The tool covers various tasks such as visual workflow editing, modern UI, native integration of LangChain.js, pluggable storage options, full-stack TypeScript implementation, and more. It is designed for enterprises looking for an easy-to-deploy and scalable solution for AI workflows.
ChuanhuChatGPT
Chuanhu Chat is a user-friendly web graphical interface that provides various additional features for ChatGPT and other language models. It supports GPT-4, file-based question answering, local deployment of language models, online search, agent assistant, and fine-tuning. The tool offers a range of functionalities including auto-solving questions, online searching with network support, knowledge base for quick reading, local deployment of language models, GPT 3.5 fine-tuning, and custom model integration. It also features system prompts for effective role-playing, basic conversation capabilities with options to regenerate or delete dialogues, conversation history management with auto-saving and search functionalities, and a visually appealing user experience with themes, dark mode, LaTeX rendering, and PWA application support.
Awesome-ChatTTS
Awesome-ChatTTS is an official recommended guide for ChatTTS beginners, compiling common questions and related resources. It provides a comprehensive overview of the project, including official introduction, quick experience options, popular branches, parameter explanations, voice seed details, installation guides, FAQs, and error troubleshooting. The repository also includes video tutorials, discussion community links, and project trends analysis. Users can explore various branches for different functionalities and enhancements related to ChatTTS.

Open-dLLM
Open-dLLM is the most open release of a diffusion-based large language model, providing pretraining, evaluation, inference, and checkpoints. It introduces Open-dCoder, the code-generation variant of Open-dLLM. The repo offers a complete stack for diffusion LLMs, enabling users to go from raw data to training, checkpoints, evaluation, and inference in one place. It includes pretraining pipeline with open datasets, inference scripts for easy sampling and generation, evaluation suite with various metrics, weights and checkpoints on Hugging Face, and transparent configs for full reproducibility.
HaE
HaE is a framework project in the field of network security (data security) that combines artificial intelligence (AI) large models to achieve highlighting and information extraction of HTTP messages (including WebSocket). It aims to reduce testing time, focus on valuable and meaningful messages, and improve vulnerability discovery efficiency. The project provides a clear and visual interface design, simple interface interaction, and centralized data panel for querying and extracting information. It also features built-in color upgrade algorithm, one-click export/import of data, and integration of AI large models API for optimized data processing.

chatless
Chatless is a modern AI chat desktop application built on Tauri and Next.js. It supports multiple AI providers, can connect to local Ollama models, supports document parsing and knowledge base functions. All data is stored locally to protect user privacy. The application is lightweight, simple, starts quickly, and consumes minimal resources.
lawyer-llama
Lawyer LLaMA is a large language model that has been specifically trained on legal data, including Chinese laws, regulations, and case documents. It has been fine-tuned on a large dataset of legal questions and answers, enabling it to understand and respond to legal inquiries in a comprehensive and informative manner. Lawyer LLaMA is designed to assist legal professionals and individuals with a variety of law-related tasks, including: * **Legal research:** Quickly and efficiently search through vast amounts of legal information to find relevant laws, regulations, and case precedents. * **Legal analysis:** Analyze legal issues, identify potential legal risks, and provide insights on how to proceed. * **Document drafting:** Draft legal documents, such as contracts, pleadings, and legal opinions, with accuracy and precision. * **Legal advice:** Provide general legal advice and guidance on a wide range of legal matters, helping users understand their rights and options. Lawyer LLaMA is a powerful tool that can significantly enhance the efficiency and effectiveness of legal research, analysis, and decision-making. It is an invaluable resource for lawyers, paralegals, law students, and anyone else who needs to navigate the complexities of the legal system.
For similar tasks
UltraRAG
The UltraRAG framework is a researcher and developer-friendly RAG system solution that simplifies the process from data construction to model fine-tuning in domain adaptation. It introduces an automated knowledge adaptation technology system, supporting no-code programming, one-click synthesis and fine-tuning, multidimensional evaluation, and research-friendly exploration work integration. The architecture consists of Frontend, Service, and Backend components, offering flexibility in customization and optimization. Performance evaluation in the legal field shows improved results compared to VanillaRAG, with specific metrics provided. The repository is licensed under Apache-2.0 and encourages citation for support.

BentoML
BentoML is an open-source model serving library for building performant and scalable AI applications with Python. It comes with everything you need for serving optimization, model packaging, and production deployment.

Qwen-TensorRT-LLM
Qwen-TensorRT-LLM is a project developed for the NVIDIA TensorRT Hackathon 2023, focusing on accelerating inference for the Qwen-7B-Chat model using TRT-LLM. The project offers various functionalities such as FP16/BF16 support, INT8 and INT4 quantization options, Tensor Parallel for multi-GPU parallelism, web demo setup with gradio, Triton API deployment for maximum throughput/concurrency, fastapi integration for openai requests, CLI interaction, and langchain support. It supports models like qwen2, qwen, and qwen-vl for both base and chat models. The project also provides tutorials on Bilibili and blogs for adapting Qwen models in NVIDIA TensorRT-LLM, along with hardware requirements and quick start guides for different model types and quantization methods.
CodeFuse-ModelCache
Codefuse-ModelCache is a semantic cache for large language models (LLMs) that aims to optimize services by introducing a caching mechanism. It helps reduce the cost of inference deployment, improve model performance and efficiency, and provide scalable services for large models. The project caches pre-generated model results to reduce response time for similar requests and enhance user experience. It integrates various embedding frameworks and local storage options, offering functionalities like cache-writing, cache-querying, and cache-clearing through RESTful API. The tool supports multi-tenancy, system commands, and multi-turn dialogue, with features for data isolation, database management, and model loading schemes. Future developments include data isolation based on hyperparameters, enhanced system prompt partitioning storage, and more versatile embedding models and similarity evaluation algorithms.
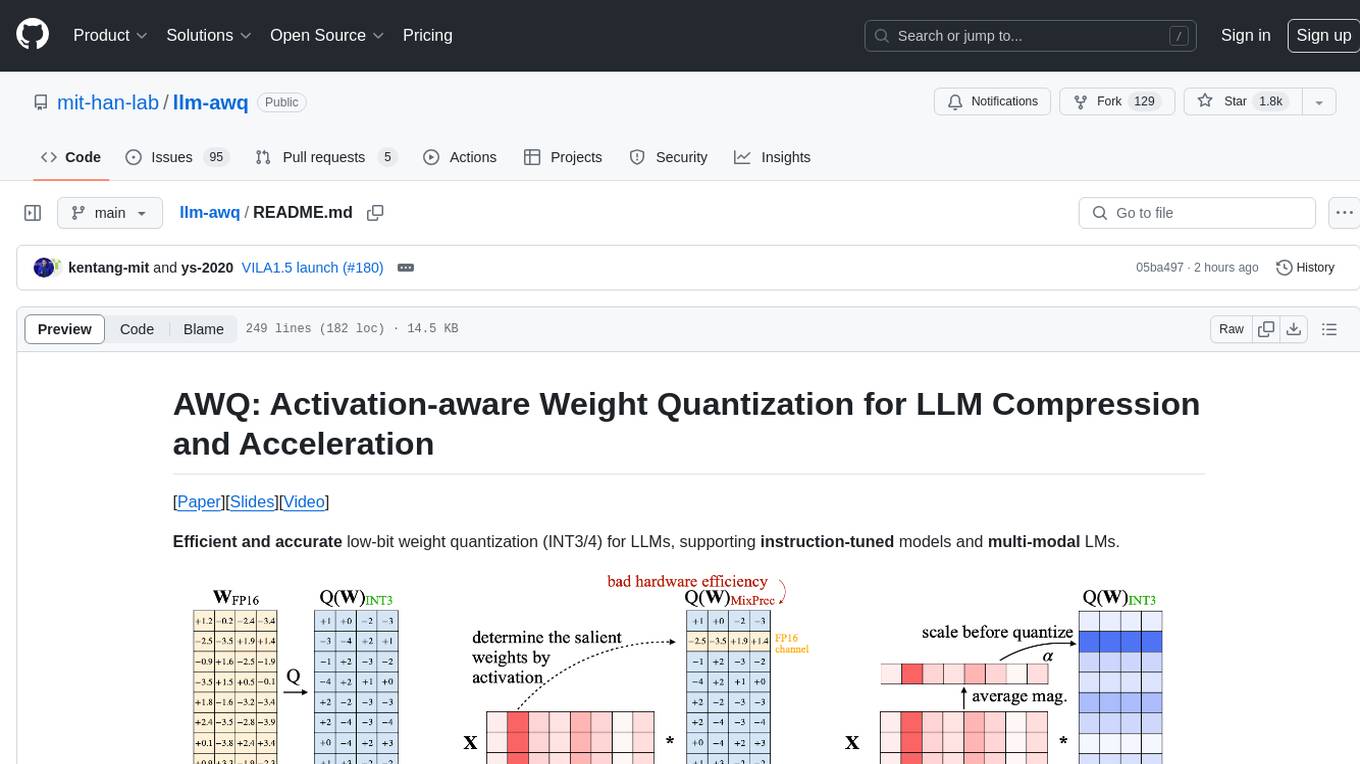
llm-awq
AWQ (Activation-aware Weight Quantization) is a tool designed for efficient and accurate low-bit weight quantization (INT3/4) for Large Language Models (LLMs). It supports instruction-tuned models and multi-modal LMs, providing features such as AWQ search for accurate quantization, pre-computed AWQ model zoo for various LLMs, memory-efficient 4-bit linear in PyTorch, and efficient CUDA kernel implementation for fast inference. The tool enables users to run large models on resource-constrained edge platforms, delivering more efficient responses with LLM/VLM chatbots through 4-bit inference.

LazyLLM
LazyLLM is a low-code development tool for building complex AI applications with multiple agents. It assists developers in building AI applications at a low cost and continuously optimizing their performance. The tool provides a convenient workflow for application development and offers standard processes and tools for various stages of application development. Users can quickly prototype applications with LazyLLM, analyze bad cases with scenario task data, and iteratively optimize key components to enhance the overall application performance. LazyLLM aims to simplify the AI application development process and provide flexibility for both beginners and experts to create high-quality applications.
ktransformers
KTransformers is a flexible Python-centric framework designed to enhance the user's experience with advanced kernel optimizations and placement/parallelism strategies for Transformers. It provides a Transformers-compatible interface, RESTful APIs compliant with OpenAI and Ollama, and a simplified ChatGPT-like web UI. The framework aims to serve as a platform for experimenting with innovative LLM inference optimizations, focusing on local deployments constrained by limited resources and supporting heterogeneous computing opportunities like GPU/CPU offloading of quantized models.
LLM-QAT
This repository contains the training code of LLM-QAT for large language models. The work investigates quantization-aware training for LLMs, including quantizing weights, activations, and the KV cache. Experiments were conducted on LLaMA models of sizes 7B, 13B, and 30B, at quantization levels down to 4-bits. Significant improvements were observed when quantizing weight, activations, and kv cache to 4-bit, 8-bit, and 4-bit, respectively.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.