
LLM-QAT
Code repo for the paper "LLM-QAT Data-Free Quantization Aware Training for Large Language Models"
Stars: 230
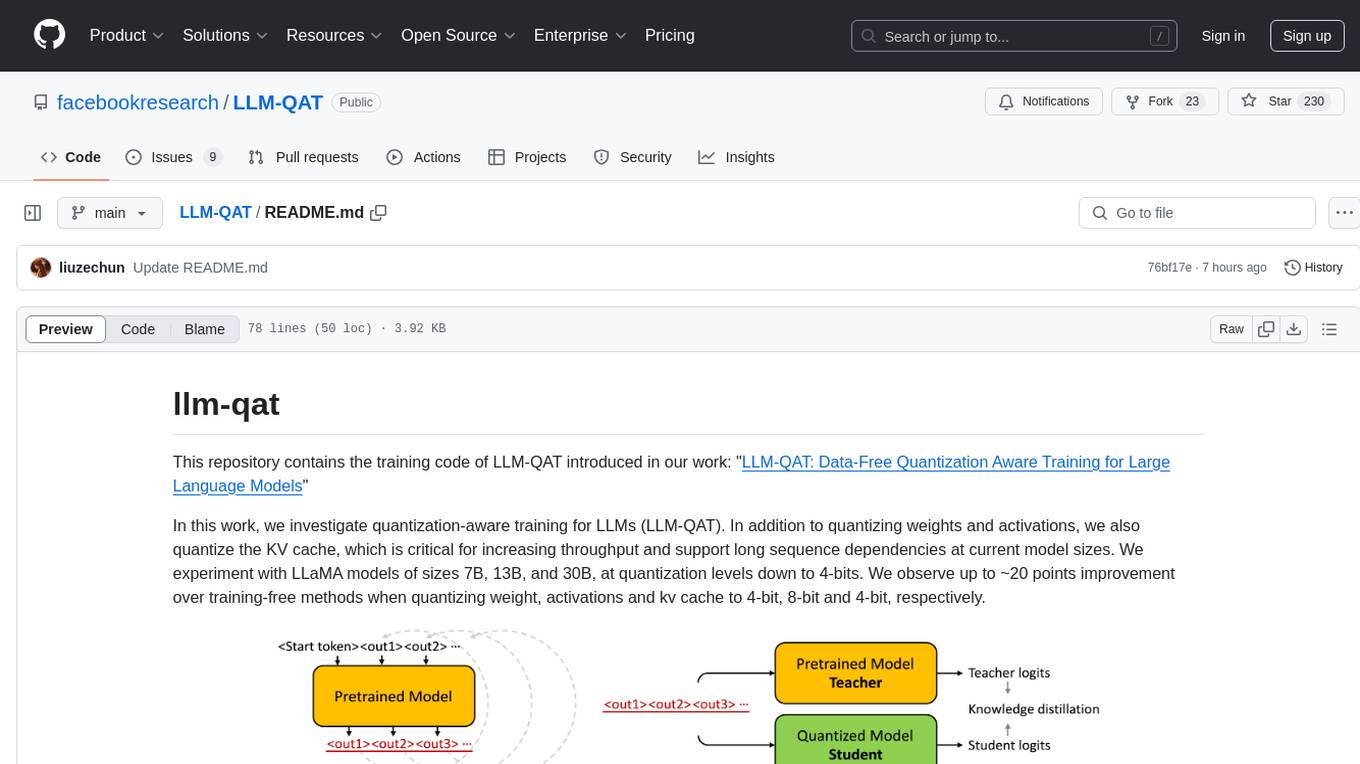
This repository contains the training code of LLM-QAT for large language models. The work investigates quantization-aware training for LLMs, including quantizing weights, activations, and the KV cache. Experiments were conducted on LLaMA models of sizes 7B, 13B, and 30B, at quantization levels down to 4-bits. Significant improvements were observed when quantizing weight, activations, and kv cache to 4-bit, 8-bit, and 4-bit, respectively.
README:
This repository contains the training code of LLM-QAT introduced in our work: "LLM-QAT: Data-Free Quantization Aware Training for Large Language Models"
In this work, we investigate quantization-aware training for LLMs (LLM-QAT). In addition to quantizing weights and activations, we also quantize the KV cache, which is critical for increasing throughput and support long sequence dependencies at current model sizes. We experiment with LLaMA models of sizes 7B, 13B, and 30B, at quantization levels down to 4-bits. We observe up to ~20 points improvement over training-free methods when quantizing weight, activations and kv cache to 4-bit, 8-bit and 4-bit, respectively.

If you find our code useful for your research, please consider citing:
@article{liu2023llm,
title={LLM-QAT: Data-Free Quantization Aware Training for Large Language Models},
author={Liu, Zechun and Oguz, Barlas and Zhao, Changsheng and Chang, Ernie and Stock, Pierre and Mehdad, Yashar and Shi, Yangyang and Krishnamoorthi, Raghuraman and Chandra, Vikas},
journal={arXiv preprint arXiv:2305.17888},
year={2023}
}
- python 3.9, pytorch >= 1.13
- pip install -r requirement.txt
- Install apex from source (https://github.com/NVIDIA/apex)
(1) Synthesize data:
- Download the llama-7B model from huggingface. Find it in the huggingface cache and update the path in 'generate_data.py'
- Run
python generate_data.py iHereiis the GPU id, ranging from0to63, because we use 64 GPUs to synthesize data in parallel. You can also change 'n_vocab 'in your code to adjust the degree of parallelism. - Run
python merge_gen_data.pyto merge all the generated data in one.jsonlfile.
(2) Quantization-aware training:
- Specify the data path and the pre-trained model path in scrips/run.sh file.
- Run
bash run_train.sh $w_bit $a_bit $kv_bitE.g.bash run_train.sh 4 8 4for 4-bit weight 8-bit activation and 4-bit kv-cache.
The results reported in the paper is run with the internal LLaMA codebase in Meta. We reproduced our experiments with huggingface codebase and released code here. The results are close to those in the paper. For clearity, we list the zero-shot common sense reasoning accuracy of the opensourced version in the following table.
| #bits (W-A-KV) | boolq | piqa | siqa | hellaswag | winogrande | arc_easy | arc_challenge | obqa | avg. |
|---|---|---|---|---|---|---|---|---|---|
| 4-8-4 | 72.4 | 76.9 | 47.6 | 70.5 | 65.8 | 67.5 | 44.4 | 50.4 | 62.0 |
| 4-8-8 | 73.6 | 77.4 | 48.5 | 73.0 | 68.8 | 68.4 | 45.5 | 53.4 | 63.6 |
| 4-6-16 | 70.8 | 76.0 | 46.9 | 70.9 | 65.2 | 66.7 | 43.5 | 49.0 | 61.1 |
| 4-8-16 | 72.9 | 77.9 | 47.9 | 72.9 | 68.0 | 69.1 | 44.8 | 55.6 | 63.6 |
| 4-16-16 | 74.2 | 78.2 | 48.3 | 73.3 | 68.2 | 69.7 | 45.6 | 54.8 | 64.0 |
| 8-8-4 | 74.1 | 78.6 | 49.3 | 73.3 | 67.9 | 70.1 | 45.5 | 52.4 | 63.9 |
| 8-8-8 | 75.5 | 79.1 | 48.7 | 75.5 | 70.1 | 73.1 | 47.2 | 56.0 | 65.6 |
| 8-8-16 | 75.7 | 79.1 | 48.9 | 75.8 | 70.4 | 72.8 | 47.8 | 56.3 | 65.9 |
This code is partially based on HuggingFace transformer repo.
Zechun Liu, Reality Labs, Meta Inc (zechunliu at meta dot com)
Barlas Oguz, Meta AI (barlaso at meta dot com)
Changsheng Zhao, Reality Labs, Meta Inc (cszhao at meta dot com)
MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases [Paper] [Code]
SpinQuant: LLM Quantization with Learned Rotations [Paper] [Code]
BiT is CC-BY-NC 4.0 licensed as of now.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for LLM-QAT
Similar Open Source Tools
LLM-QAT
This repository contains the training code of LLM-QAT for large language models. The work investigates quantization-aware training for LLMs, including quantizing weights, activations, and the KV cache. Experiments were conducted on LLaMA models of sizes 7B, 13B, and 30B, at quantization levels down to 4-bits. Significant improvements were observed when quantizing weight, activations, and kv cache to 4-bit, 8-bit, and 4-bit, respectively.
OpenAI-CLIP-Feature
This repository provides code for extracting image and text features using OpenAI CLIP models, supporting both global and local grid visual features. It aims to facilitate multi visual-and-language downstream tasks by allowing users to customize input and output grid resolution easily. The extracted features have shown comparable or superior results in image captioning tasks without hyperparameter tuning. The repo supports various CLIP models and provides detailed information on supported settings and results on MSCOCO image captioning. Users can get started by setting up experiments with the extracted features using X-modaler.

jailbreak_llms
This is the official repository for the ACM CCS 2024 paper 'Do Anything Now': Characterizing and Evaluating In-The-Wild Jailbreak Prompts on Large Language Models. The project employs a new framework called JailbreakHub to conduct the first measurement study on jailbreak prompts in the wild, collecting 15,140 prompts from December 2022 to December 2023, including 1,405 jailbreak prompts. The dataset serves as the largest collection of in-the-wild jailbreak prompts. The repository contains examples of harmful language and is intended for research purposes only.

RobustVLM
This repository contains code for the paper 'Robust CLIP: Unsupervised Adversarial Fine-Tuning of Vision Embeddings for Robust Large Vision-Language Models'. It focuses on fine-tuning CLIP in an unsupervised manner to enhance its robustness against visual adversarial attacks. By replacing the vision encoder of large vision-language models with the fine-tuned CLIP models, it achieves state-of-the-art adversarial robustness on various vision-language tasks. The repository provides adversarially fine-tuned ViT-L/14 CLIP models and offers insights into zero-shot classification settings and clean accuracy improvements.

are-copilots-local-yet
Current trends and state of the art for using open & local LLM models as copilots to complete code, generate projects, act as shell assistants, automatically fix bugs, and more. This document is a curated list of local Copilots, shell assistants, and related projects, intended to be a resource for those interested in a survey of the existing tools and to help developers discover the state of the art for projects like these.
COLD-Attack
COLD-Attack is a framework designed for controllable jailbreaks on large language models (LLMs). It formulates the controllable attack generation problem and utilizes the Energy-based Constrained Decoding with Langevin Dynamics (COLD) algorithm to automate the search of adversarial LLM attacks with control over fluency, stealthiness, sentiment, and left-right-coherence. The framework includes steps for energy function formulation, Langevin dynamics sampling, and decoding process to generate discrete text attacks. It offers diverse jailbreak scenarios such as fluent suffix attacks, paraphrase attacks, and attacks with left-right-coherence.
2024-AICS-EXP
This repository contains the complete archive of the 2024 version of the 'Intelligent Computing System' experiment at the University of Chinese Academy of Sciences. The experiment content for 2024 has undergone extensive adjustments to the knowledge system and experimental topics, including the transition from TensorFlow to PyTorch, significant modifications to previous code, and the addition of experiments with large models. The project is continuously updated in line with the course progress, currently up to the seventh experiment. Updates include the addition of experiments like YOLOv5 in Experiment 5-3, updates to theoretical teaching materials, and fixes for bugs in Experiment 6 code. The repository also includes experiment manuals, questions, and answers for various experiments, with some data sets hosted on Baidu Cloud due to size limitations on GitHub.

Awesome-LLM-Large-Language-Models-Notes
Awesome-LLM-Large-Language-Models-Notes is a repository that provides a comprehensive collection of information on various Large Language Models (LLMs) classified by year, size, and name. It includes details on known LLM models, their papers, implementations, and specific characteristics. The repository also covers LLM models classified by architecture, must-read papers, blog articles, tutorials, and implementations from scratch. It serves as a valuable resource for individuals interested in understanding and working with LLMs in the field of Natural Language Processing (NLP).

LLM-PowerHouse-A-Curated-Guide-for-Large-Language-Models-with-Custom-Training-and-Inferencing
LLM-PowerHouse is a comprehensive and curated guide designed to empower developers, researchers, and enthusiasts to harness the true capabilities of Large Language Models (LLMs) and build intelligent applications that push the boundaries of natural language understanding. This GitHub repository provides in-depth articles, codebase mastery, LLM PlayLab, and resources for cost analysis and network visualization. It covers various aspects of LLMs, including NLP, models, training, evaluation metrics, open LLMs, and more. The repository also includes a collection of code examples and tutorials to help users build and deploy LLM-based applications.
CS7320-AI
CS7320-AI is a repository containing lecture materials, simple Python code examples, and assignments for the course CS 5/7320 Artificial Intelligence. The code examples cover various chapters of the textbook 'Artificial Intelligence: A Modern Approach' by Russell and Norvig. The repository focuses on basic AI concepts rather than advanced implementation techniques. It includes HOWTO guides for installing Python, working on assignments, and using AI with Python.

llm-compression-intelligence
This repository presents the findings of the paper "Compression Represents Intelligence Linearly". The study reveals a strong linear correlation between the intelligence of LLMs, as measured by benchmark scores, and their ability to compress external text corpora. Compression efficiency, derived from raw text corpora, serves as a reliable evaluation metric that is linearly associated with model capabilities. The repository includes the compression corpora used in the paper, code for computing compression efficiency, and data collection and processing pipelines.
FlipAttack
FlipAttack is a jailbreak attack tool designed to exploit black-box Language Model Models (LLMs) by manipulating text inputs. It leverages insights into LLMs' autoregressive nature to construct noise on the left side of the input text, deceiving the model and enabling harmful behaviors. The tool offers four flipping modes to guide LLMs in denoising and executing malicious prompts effectively. FlipAttack is characterized by its universality, stealthiness, and simplicity, allowing users to compromise black-box LLMs with just one query. Experimental results demonstrate its high success rates against various LLMs, including GPT-4o and guardrail models.

llm-datasets
LLM Datasets is a repository containing high-quality datasets, tools, and concepts for LLM fine-tuning. It provides datasets with characteristics like accuracy, diversity, and complexity to train large language models for various tasks. The repository includes datasets for general-purpose, math & logic, code, conversation & role-play, and agent & function calling domains. It also offers guidance on creating high-quality datasets through data deduplication, data quality assessment, data exploration, and data generation techniques.

dl_model_infer
This project is a c++ version of the AI reasoning library that supports the reasoning of tensorrt models. It provides accelerated deployment cases of deep learning CV popular models and supports dynamic-batch image processing, inference, decode, and NMS. The project has been updated with various models and provides tutorials for model exports. It also includes a producer-consumer inference model for specific tasks. The project directory includes implementations for model inference applications, backend reasoning classes, post-processing, pre-processing, and target detection and tracking. Speed tests have been conducted on various models, and onnx downloads are available for different models.
llm4regression
This project explores the capability of Large Language Models (LLMs) to perform regression tasks using in-context examples. It compares the performance of LLMs like GPT-4 and Claude 3 Opus with traditional supervised methods such as Linear Regression and Gradient Boosting. The project provides preprints and results demonstrating the strong performance of LLMs in regression tasks. It includes datasets, models used, and experiments on adaptation and contamination. The code and data for the experiments are available for interaction and analysis.
nncf
Neural Network Compression Framework (NNCF) provides a suite of post-training and training-time algorithms for optimizing inference of neural networks in OpenVINO™ with a minimal accuracy drop. It is designed to work with models from PyTorch, TorchFX, TensorFlow, ONNX, and OpenVINO™. NNCF offers samples demonstrating compression algorithms for various use cases and models, with the ability to add different compression algorithms easily. It supports GPU-accelerated layers, distributed training, and seamless combination of pruning, sparsity, and quantization algorithms. NNCF allows exporting compressed models to ONNX or TensorFlow formats for use with OpenVINO™ toolkit, and supports Accuracy-Aware model training pipelines via Adaptive Compression Level Training and Early Exit Training.
For similar tasks

BentoML
BentoML is an open-source model serving library for building performant and scalable AI applications with Python. It comes with everything you need for serving optimization, model packaging, and production deployment.

Qwen-TensorRT-LLM
Qwen-TensorRT-LLM is a project developed for the NVIDIA TensorRT Hackathon 2023, focusing on accelerating inference for the Qwen-7B-Chat model using TRT-LLM. The project offers various functionalities such as FP16/BF16 support, INT8 and INT4 quantization options, Tensor Parallel for multi-GPU parallelism, web demo setup with gradio, Triton API deployment for maximum throughput/concurrency, fastapi integration for openai requests, CLI interaction, and langchain support. It supports models like qwen2, qwen, and qwen-vl for both base and chat models. The project also provides tutorials on Bilibili and blogs for adapting Qwen models in NVIDIA TensorRT-LLM, along with hardware requirements and quick start guides for different model types and quantization methods.
CodeFuse-ModelCache
Codefuse-ModelCache is a semantic cache for large language models (LLMs) that aims to optimize services by introducing a caching mechanism. It helps reduce the cost of inference deployment, improve model performance and efficiency, and provide scalable services for large models. The project caches pre-generated model results to reduce response time for similar requests and enhance user experience. It integrates various embedding frameworks and local storage options, offering functionalities like cache-writing, cache-querying, and cache-clearing through RESTful API. The tool supports multi-tenancy, system commands, and multi-turn dialogue, with features for data isolation, database management, and model loading schemes. Future developments include data isolation based on hyperparameters, enhanced system prompt partitioning storage, and more versatile embedding models and similarity evaluation algorithms.
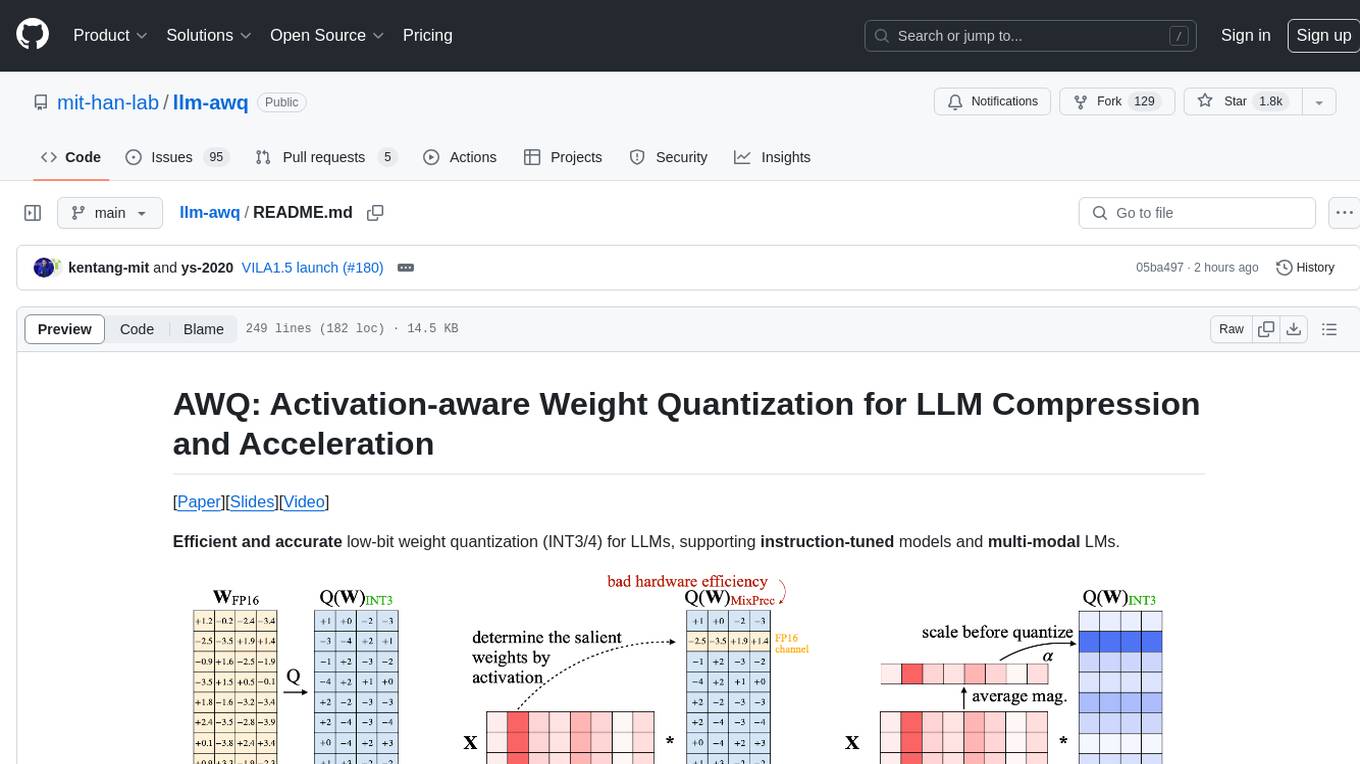
llm-awq
AWQ (Activation-aware Weight Quantization) is a tool designed for efficient and accurate low-bit weight quantization (INT3/4) for Large Language Models (LLMs). It supports instruction-tuned models and multi-modal LMs, providing features such as AWQ search for accurate quantization, pre-computed AWQ model zoo for various LLMs, memory-efficient 4-bit linear in PyTorch, and efficient CUDA kernel implementation for fast inference. The tool enables users to run large models on resource-constrained edge platforms, delivering more efficient responses with LLM/VLM chatbots through 4-bit inference.

LazyLLM
LazyLLM is a low-code development tool for building complex AI applications with multiple agents. It assists developers in building AI applications at a low cost and continuously optimizing their performance. The tool provides a convenient workflow for application development and offers standard processes and tools for various stages of application development. Users can quickly prototype applications with LazyLLM, analyze bad cases with scenario task data, and iteratively optimize key components to enhance the overall application performance. LazyLLM aims to simplify the AI application development process and provide flexibility for both beginners and experts to create high-quality applications.
ktransformers
KTransformers is a flexible Python-centric framework designed to enhance the user's experience with advanced kernel optimizations and placement/parallelism strategies for Transformers. It provides a Transformers-compatible interface, RESTful APIs compliant with OpenAI and Ollama, and a simplified ChatGPT-like web UI. The framework aims to serve as a platform for experimenting with innovative LLM inference optimizations, focusing on local deployments constrained by limited resources and supporting heterogeneous computing opportunities like GPU/CPU offloading of quantized models.
LLM-QAT
This repository contains the training code of LLM-QAT for large language models. The work investigates quantization-aware training for LLMs, including quantizing weights, activations, and the KV cache. Experiments were conducted on LLaMA models of sizes 7B, 13B, and 30B, at quantization levels down to 4-bits. Significant improvements were observed when quantizing weight, activations, and kv cache to 4-bit, 8-bit, and 4-bit, respectively.

UltraRAG
The UltraRAG framework is a researcher and developer-friendly RAG system solution that simplifies the process from data construction to model fine-tuning in domain adaptation. It introduces an automated knowledge adaptation technology system, supporting no-code programming, one-click synthesis and fine-tuning, multidimensional evaluation, and research-friendly exploration work integration. The architecture consists of Frontend, Service, and Backend components, offering flexibility in customization and optimization. Performance evaluation in the legal field shows improved results compared to VanillaRAG, with specific metrics provided. The repository is licensed under Apache-2.0 and encourages citation for support.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.