
2024-AICS-EXP
【2024年新版】国科大 陈云霁 智能计算系统AICS实验代码
Stars: 71
This repository contains the complete archive of the 2024 version of the 'Intelligent Computing System' experiment at the University of Chinese Academy of Sciences. The experiment content for 2024 has undergone extensive adjustments to the knowledge system and experimental topics, including the transition from TensorFlow to PyTorch, significant modifications to previous code, and the addition of experiments with large models. The project is continuously updated in line with the course progress, currently up to the seventh experiment. Updates include the addition of experiments like YOLOv5 in Experiment 5-3, updates to theoretical teaching materials, and fixes for bugs in Experiment 6 code. The repository also includes experiment manuals, questions, and answers for various experiments, with some data sets hosted on Baidu Cloud due to size limitations on GitHub.
README:
本项目是国科大《智能计算系统》2024年新版实验的完整资料存档。2024年的智能计算系统实验内容对知识体系和实验题目进行了大范围的调整,调整内容包括但不限于以下几点:
- 不再使用TensorFlow,全面使用PyTorch
- 大量修改旧版的题目代码
- 新增大模型实验等
-
本项目跟随课程进度实时更新,目前已更新至第七次实验(目前还剩最后一个大模型实验,等待老师布置)
-
实验5中仅完成实验5.3,希望有完成实验5.1和5.2的同学可以给仓库提交pr,如有问题欢迎大家提出issue和pr
-
如果有帮到大家的话希望大家能给仓库留个Star~
-
2024/05/24:补充实验五-三选一实验中的yolov5实验
-
2024/05/21:更新理论教学的最新课件
-
2024/05/20:由于实验六老师提供的代码具有众多bug,且无法比较四个result的值,只能比较其中一个,因此直接在答案中上传了修改后的tb_top(0-2).v的代码,可供参考。同时,实验六对应的实验题目中的data_gen.py及tb_top(0-2).v的代码已经替换为修改后的代码,需要重新做实验的同学可以直接使用
-
2024/05/20:更新实验六的parallel_pe部分代码
-
2024/05/18:更新实验七:智能编程语言算子实验的实验手册、题目及答案(由于希冀平台故障,因此未在平台进行评测,但是本地测试都通过了)
-
2024/05/17:更新实验六:modelsim仿真实验的实验手册、题目及答案(安装modelsim的最后一步千万别让他安装那个硬件锁还是啥的,直接让我电脑无限蓝屏了T.T,如果不小心和我一样就进入安全模式然后删除电脑上的hardlock.sys)
-
2024/04/20:由于实验题目配套数据集大小超过Github限制的100MB,因此实验题目改为百度云托管
-
2024/04/20:更新实验五三选一实验手册、题目及答案
| score | |
|---|---|
| exp_2_1(手写数字分类实验:满分100) | 100 |
| exp_2_2(基于DLP平台实现手写数字分类实验:满分100) | 100 |
| exp_3_1(python实现VGG19图像分类实验:满分100) | 100 |
| exp_3_2(基于DLP平台实现图像分类实验:满分100) | 100 |
| exp_3_3(非实时图像风格迁移实验:满分100) | 100 |
| exp_4_1(pytorch实现VGG19图像分类实验:满分100) | 100 |
| exp_4_2(实时风格迁移推断实验:满分100) | 100 |
| exp_4_3(实时风格迁移训练实验:满分100) | 100 |
| exp_4_4(自定义pytorch cpu算子实验:满分100) | 100 |
| exp_5_2(三选一yolov5实验:满分80) | 80 |
| exp_5_3(三选一bert实验:满分100) | 100 |
| exp_6(modelsim实验:满分120) | 120 |
| exp_7_1(智能编程语言算子开发实验:满分100) | 100 |
| exp_7_2(智能编程语言性能优化实验:满分100) | 100 |
感谢以下同学对仓库代码提出的issue和pr:
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for 2024-AICS-EXP
Similar Open Source Tools
2024-AICS-EXP
This repository contains the complete archive of the 2024 version of the 'Intelligent Computing System' experiment at the University of Chinese Academy of Sciences. The experiment content for 2024 has undergone extensive adjustments to the knowledge system and experimental topics, including the transition from TensorFlow to PyTorch, significant modifications to previous code, and the addition of experiments with large models. The project is continuously updated in line with the course progress, currently up to the seventh experiment. Updates include the addition of experiments like YOLOv5 in Experiment 5-3, updates to theoretical teaching materials, and fixes for bugs in Experiment 6 code. The repository also includes experiment manuals, questions, and answers for various experiments, with some data sets hosted on Baidu Cloud due to size limitations on GitHub.

awesome-mobile-llm
Awesome Mobile LLMs is a curated list of Large Language Models (LLMs) and related studies focused on mobile and embedded hardware. The repository includes information on various LLM models, deployment frameworks, benchmarking efforts, applications, multimodal LLMs, surveys on efficient LLMs, training LLMs on device, mobile-related use-cases, industry announcements, and related repositories. It aims to be a valuable resource for researchers, engineers, and practitioners interested in mobile LLMs.

are-copilots-local-yet
Current trends and state of the art for using open & local LLM models as copilots to complete code, generate projects, act as shell assistants, automatically fix bugs, and more. This document is a curated list of local Copilots, shell assistants, and related projects, intended to be a resource for those interested in a survey of the existing tools and to help developers discover the state of the art for projects like these.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.
visionOS-examples
visionOS-examples is a repository containing accelerators for Spatial Computing. It includes examples such as Local Large Language Model, Chat Apple Vision Pro, WebSockets, Anchor To Head, Hand Tracking, Battery Life, Countdown, Plane Detection, Timer Vision, and PencilKit for visionOS. The repository showcases various functionalities and features for Apple Vision Pro, offering tools for developers to enhance their visionOS apps with capabilities like hand tracking, plane detection, and real-time cryptocurrency prices.

jailbreak_llms
This is the official repository for the ACM CCS 2024 paper 'Do Anything Now': Characterizing and Evaluating In-The-Wild Jailbreak Prompts on Large Language Models. The project employs a new framework called JailbreakHub to conduct the first measurement study on jailbreak prompts in the wild, collecting 15,140 prompts from December 2022 to December 2023, including 1,405 jailbreak prompts. The dataset serves as the largest collection of in-the-wild jailbreak prompts. The repository contains examples of harmful language and is intended for research purposes only.

LLM-PowerHouse-A-Curated-Guide-for-Large-Language-Models-with-Custom-Training-and-Inferencing
LLM-PowerHouse is a comprehensive and curated guide designed to empower developers, researchers, and enthusiasts to harness the true capabilities of Large Language Models (LLMs) and build intelligent applications that push the boundaries of natural language understanding. This GitHub repository provides in-depth articles, codebase mastery, LLM PlayLab, and resources for cost analysis and network visualization. It covers various aspects of LLMs, including NLP, models, training, evaluation metrics, open LLMs, and more. The repository also includes a collection of code examples and tutorials to help users build and deploy LLM-based applications.

nntrainer
NNtrainer is a software framework for training neural network models on devices with limited resources. It enables on-device fine-tuning of neural networks using user data for personalization. NNtrainer supports various machine learning algorithms and provides examples for tasks such as few-shot learning, ResNet, VGG, and product rating. It is optimized for embedded devices and utilizes CBLAS and CUBLAS for accelerated calculations. NNtrainer is open source and released under the Apache License version 2.0.
data-prep-kit
Data Prep Kit accelerates unstructured data preparation for LLM app developers. It allows developers to cleanse, transform, and enrich unstructured data for pre-training, fine-tuning, instruct-tuning LLMs, or building RAG applications. The kit provides modules for Python, Ray, and Spark runtimes, supporting Natural Language and Code data modalities. It offers a framework for custom transforms and uses Kubeflow Pipelines for workflow automation. Users can install the kit via PyPi and access a variety of transforms for data processing pipelines.

amber-train
Amber is the first model in the LLM360 family, an initiative for comprehensive and fully open-sourced LLMs. It is a 7B English language model with the LLaMA architecture. The model type is a language model with the same architecture as LLaMA-7B. It is licensed under Apache 2.0. The resources available include training code, data preparation, metrics, and fully processed Amber pretraining data. The model has been trained on various datasets like Arxiv, Book, C4, Refined-Web, StarCoder, StackExchange, and Wikipedia. The hyperparameters include a total of 6.7B parameters, hidden size of 4096, intermediate size of 11008, 32 attention heads, 32 hidden layers, RMSNorm ε of 1e^-6, max sequence length of 2048, and a vocabulary size of 32000.

Prompt-Engineering-Holy-Grail
The Prompt Engineering Holy Grail repository is a curated resource for prompt engineering enthusiasts, providing essential resources, tools, templates, and best practices to support learning and working in prompt engineering. It covers a wide range of topics related to prompt engineering, from beginner fundamentals to advanced techniques, and includes sections on learning resources, online courses, books, prompt generation tools, prompt management platforms, prompt testing and experimentation, prompt crafting libraries, prompt libraries and datasets, prompt engineering communities, freelance and job opportunities, contributing guidelines, code of conduct, support for the project, and contact information.

llm-compression-intelligence
This repository presents the findings of the paper "Compression Represents Intelligence Linearly". The study reveals a strong linear correlation between the intelligence of LLMs, as measured by benchmark scores, and their ability to compress external text corpora. Compression efficiency, derived from raw text corpora, serves as a reliable evaluation metric that is linearly associated with model capabilities. The repository includes the compression corpora used in the paper, code for computing compression efficiency, and data collection and processing pipelines.
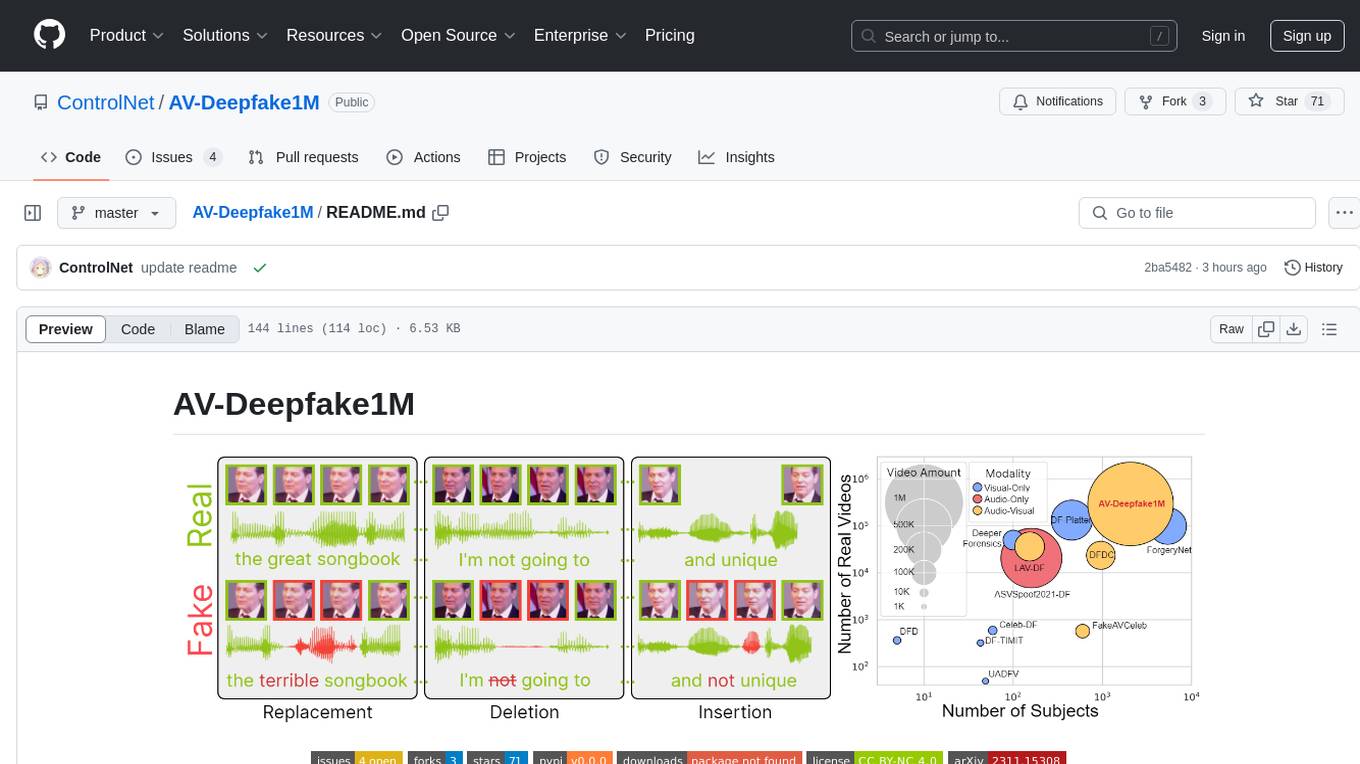
AV-Deepfake1M
The AV-Deepfake1M repository is the official repository for the paper AV-Deepfake1M: A Large-Scale LLM-Driven Audio-Visual Deepfake Dataset. It addresses the challenge of detecting and localizing deepfake audio-visual content by proposing a dataset containing video manipulations, audio manipulations, and audio-visual manipulations for over 2K subjects resulting in more than 1M videos. The dataset is crucial for developing next-generation deepfake localization methods.
llm-deploy
LLM-Deploy focuses on the theory and practice of model/LLM reasoning and deployment, aiming to be your partner in mastering the art of LLM reasoning and deployment. Whether you are a newcomer to this field or a senior professional seeking to deepen your skills, you can find the key path to successfully deploy large language models here. The project covers reasoning and deployment theories, model and service optimization practices, and outputs from experienced engineers. It serves as a valuable resource for algorithm engineers and individuals interested in reasoning deployment.
rubra
Rubra is a collection of open-weight large language models enhanced with tool-calling capability. It allows users to call user-defined external tools in a deterministic manner while reasoning and chatting, making it ideal for agentic use cases. The models are further post-trained to teach instruct-tuned models new skills and mitigate catastrophic forgetting. Rubra extends popular inferencing projects for easy use, enabling users to run the models easily.
linghe
A library of high-performance kernels for LLM training, linghe is designed for MoE training with FP8 quantization. It provides fused quantization kernels, memory-efficiency kernels, and implementation-optimized kernels. The repo benchmarks on H800 with specific configurations and offers examples in tests. Users can refer to the API for more details.
For similar tasks

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.

InternVL
InternVL scales up the ViT to _**6B parameters**_ and aligns it with LLM. It is a vision-language foundation model that can perform various tasks, including: **Visual Perception** - Linear-Probe Image Classification - Semantic Segmentation - Zero-Shot Image Classification - Multilingual Zero-Shot Image Classification - Zero-Shot Video Classification **Cross-Modal Retrieval** - English Zero-Shot Image-Text Retrieval - Chinese Zero-Shot Image-Text Retrieval - Multilingual Zero-Shot Image-Text Retrieval on XTD **Multimodal Dialogue** - Zero-Shot Image Captioning - Multimodal Benchmarks with Frozen LLM - Multimodal Benchmarks with Trainable LLM - Tiny LVLM InternVL has been shown to achieve state-of-the-art results on a variety of benchmarks. For example, on the MMMU image classification benchmark, InternVL achieves a top-1 accuracy of 51.6%, which is higher than GPT-4V and Gemini Pro. On the DocVQA question answering benchmark, InternVL achieves a score of 82.2%, which is also higher than GPT-4V and Gemini Pro. InternVL is open-sourced and available on Hugging Face. It can be used for a variety of applications, including image classification, object detection, semantic segmentation, image captioning, and question answering.

clarifai-python
The Clarifai Python SDK offers a comprehensive set of tools to integrate Clarifai's AI platform to leverage computer vision capabilities like classification , detection ,segementation and natural language capabilities like classification , summarisation , generation , Q&A ,etc into your applications. With just a few lines of code, you can leverage cutting-edge artificial intelligence to unlock valuable insights from visual and textual content.

X-AnyLabeling
X-AnyLabeling is a robust annotation tool that seamlessly incorporates an AI inference engine alongside an array of sophisticated features. Tailored for practical applications, it is committed to delivering comprehensive, industrial-grade solutions for image data engineers. This tool excels in swiftly and automatically executing annotations across diverse and intricate tasks.

ailia-models
The collection of pre-trained, state-of-the-art AI models. ailia SDK is a self-contained, cross-platform, high-speed inference SDK for AI. The ailia SDK provides a consistent C++ API across Windows, Mac, Linux, iOS, Android, Jetson, and Raspberry Pi platforms. It also supports Unity (C#), Python, Rust, Flutter(Dart) and JNI for efficient AI implementation. The ailia SDK makes extensive use of the GPU through Vulkan and Metal to enable accelerated computing. # Supported models 323 models as of April 8th, 2024

edenai-apis
Eden AI aims to simplify the use and deployment of AI technologies by providing a unique API that connects to all the best AI engines. With the rise of **AI as a Service** , a lot of companies provide off-the-shelf trained models that you can access directly through an API. These companies are either the tech giants (Google, Microsoft , Amazon) or other smaller, more specialized companies, and there are hundreds of them. Some of the most known are : DeepL (translation), OpenAI (text and image analysis), AssemblyAI (speech analysis). There are **hundreds of companies** doing that. We're regrouping the best ones **in one place** !

NanoLLM
NanoLLM is a tool designed for optimized local inference for Large Language Models (LLMs) using HuggingFace-like APIs. It supports quantization, vision/language models, multimodal agents, speech, vector DB, and RAG. The tool aims to provide efficient and effective processing for LLMs on local devices, enhancing performance and usability for various AI applications.

open-ai
Open AI is a powerful tool for artificial intelligence research and development. It provides a wide range of machine learning models and algorithms, making it easier for developers to create innovative AI applications. With Open AI, users can explore cutting-edge technologies such as natural language processing, computer vision, and reinforcement learning. The platform offers a user-friendly interface and comprehensive documentation to support users in building and deploying AI solutions. Whether you are a beginner or an experienced AI practitioner, Open AI offers the tools and resources you need to accelerate your AI projects and stay ahead in the rapidly evolving field of artificial intelligence.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.