
awesome-mobile-llm
Awesome Mobile LLMs
Stars: 154

Awesome Mobile LLMs is a curated list of Large Language Models (LLMs) and related studies focused on mobile and embedded hardware. The repository includes information on various LLM models, deployment frameworks, benchmarking efforts, applications, multimodal LLMs, surveys on efficient LLMs, training LLMs on device, mobile-related use-cases, industry announcements, and related repositories. It aims to be a valuable resource for researchers, engineers, and practitioners interested in mobile LLMs.
README:
A curated list of LLMs and related studies targeted at mobile and embedded hardware
Last update: 23rd March 2025
If your publication/work is not included - and you think it should - please open an issue or reach out directly to @stevelaskaridis.
Let's try to make this list as useful as possible to researchers, engineers and practitioners all around the world.
- Mobile-First LLMs
- Infrastructure / Deployment of LLMs on Device
- Benchmarking LLMs on Device
- Mobile-Specific Optimisations
- Applications
- Multimodal LLMs
- Surveys on Efficient LLMs
- Training LLMs on Device
- Mobile-Related Use-Cases
- Benchmarks
- Leaderboards
- Industry Announcements
- Related Awesome Repositories
The following Table shows sub-3B models designed for on-device deployments, sorted by year.
| Name | Year | Sizes | Primary Group/Affiliation | Publication | Code Repository | HF Repository |
|---|---|---|---|---|---|---|
| BlueLM-V | 2024 | 2.7B | CUHK, Vivo AI Lab | paper | code | - |
| PhoneLM | 2024 | 0.5B, 1.5B | BUPT | paper | code | huggingface |
| AMD-Llama-135m | 2024 | 135M | AMD | blog | code | huggingface |
| SmolLM2 | 2024 | 135M, 360M, 1.7B | Huggingface | - | code | huggingface |
| Ministral | 2024 | 3B, ... | Mistral | blog | - | huggingface |
| Llama 3.2 | 2024 | 1B, 3B | Meta | blog | code | huggingface |
| OLMoE | 2024 | 7B (1B active) | AllenAI | paper | code | huggingface |
| Gemma 2 | 2024 | 2B, ... | paper blog | code | huggingface | |
| Apple Intelligence Foundation LMs | 2024 | 3B | Apple | paper | - | - |
| SmolLM | 2024 | 135M, 360M, 1.7B | Huggingface | blog | - | huggingface |
| Fox | 2024 | 1.6B | TensorOpera | blog | - | huggingface |
| Qwen2 | 2024 | 500M, 1.5B, ... | Qwen Team | paper | code | huggingface |
| OpenELM | 2024 | 270M, 450M, 1.08B, 3.04B | Apple | paper | code | huggingface |
| DCLM | 2024 | 400M, 1B, ... | Univerisy of Washington, Apple, Toyota Research Institute, ... | paper | code | huggingface |
| Phi-3 | 2024 | 3.8B | Microsoft | whitepaper | code | huggingface |
| OLMo | 2024 | 1B, ... | AllenAI | paper | code | huggingface |
| Mobile LLMs | 2024 | 125M, 250M | Meta | paper | code | - |
| Gemma | 2024 | 2B, ... | paper, website | code, gemma.cpp | huggingface | |
| MobiLlama | 2024 | 0.5B, 1B | MBZUAI | paper | code | huggingface |
| Stable LM 2 (Zephyr) | 2024 | 1.6B | Stability.ai | paper | - | huggingface |
| TinyLlama | 2024 | 1.1B | Singapore University of Technology and Design | paper | code | huggingface |
| Gemini-Nano | 2024 | 1.8B, 3.25B | paper | - | - | |
| Stable LM (Zephyr) | 2023 | 3B | Stability | blog | code | huggingface |
| OpenLM | 2023 | 11M, 25M, 87M, 160M, 411M, 830M, 1B, 3B, ... | OpenLM team | - | code | huggingface |
| Phi-2 | 2023 | 2.7B | Microsoft | website | - | huggingface |
| Phi-1.5 | 2023 | 1.3B | Microsoft | paper | - | huggingface |
| Phi-1 | 2023 | 1.3B | Microsoft | paper | - | huggingface |
| RWKV | 2023 | 169M, 430M, 1.5B, 3B, ... | EleutherAI | paper | code | huggingface |
| Cerebras-GPT | 2023 | 111M, 256M, 590M, 1.3B, 2.7B ... | Cerebras | paper | code | huggingface |
| OPT | 2022 | 125M, 350M, 1.3B, 2.7B, ... | Meta | paper | code | huggingface |
| LaMini-LM | 2023 | 61M, 77M, 111M, 124M, 223M, 248M, 256M, 590M, 774M, 738M, 783M, 1.3B, 1.5B, ... | MBZUAI | paper | code | huggingface |
| Pythia | 2023 | 70M, 160M, 410M, 1B, 1.4B, 2.8B, ... | EleutherAI | paper | code | huggingface |
| Galactica | 2022 | 125M, 1.3B, ... | Meta | paper | code | huggingface |
| BLOOM | 2022 | 560M, 1.1B, 1.7B, 3B, ... | BigScience | paper | code | huggingface |
| XGLM | 2021 | 564M, 1.7B, 2.9B, ... | Meta | paper | code | huggingface |
| GPT-Neo | 2021 | 125M, 350M, 1.3B, 2.7B | EleutherAI | - | code, gpt-neox | huggingface |
| MobileBERT | 2020 | 15.1M, 25.3M | CMU, Google | paper | code | huggingface |
| BART | 2019 | 140M, 400M | Meta | paper | code | huggingface |
| DistilBERT | 2019 | 66M | HuggingFace | paper | code | huggingface |
| T5 | 2019 | 60M, 220M, 770M, 3B, ... | paper | code | huggingface | |
| TinyBERT | 2019 | 14.5M | Huawei | paper | code | huggingface |
| Megatron-LM | 2019 | 336M, 1.3B, ... | Nvidia | paper | code | - |
This section showcases frameworks and contributions for supporting LLM inference on mobile and edge devices.
-
llama.cpp: Inference of Meta's LLaMA model (and others) in pure C/C++. Supports various platforms and builds on top of ggml (now gguf format).
- LLMFarm: iOS frontend for llama.cpp
- LLM.swift: iOS frontend for llama.cpp
- Sherpa: Android frontend for llama.cpp
- iAkashPaul/Portal: Wraps the example android app with tweaked UI, configs & additional model support
- dusty-nv's llama.cpp: Containers for Jetson deployment of llama.cpp
-
MLC-LLM: MLC LLM is a machine learning compiler and high-performance deployment engine for large language models. Supports various platforms and build on top of TVM.
- Android App: MLC Android app
- iOS App: MLC iOS app
- dusty-nv's MLC: Containers for Jetson deployment of MLC
-
PyTorch ExecuTorch: Solution for enabling on-device inference capabilities across mobile and edge devices including wearables, embedded devices and microcontrollers.
- TorchChat: Codebase showcasing the ability to run large language models (LLMs) seamlessly across iOS and Android
- Google MediaPipe: A suite of libraries and tools for you to quickly apply artificial intelligence (AI) and machine learning (ML) techniques in your applications. Support Android, iOS, Python and Web.
-
Apple MLX: MLX is an array framework for machine learning research on Apple silicon, brought to you by Apple machine learning research. Builds upon lazy evaluation and unified memory architecture.
- MLX Swift: Swift API for MLX.
- HF Swift Transformers: Swift Package to implement a transformers-like API in Swift
- Alibaba MNN: MNN supports inference and training of deep learning models and for inference and training on-device.
- llama2.c (More educational, see here for android port)
- tinygrad: Simple neural network framework from tinycorp and @geohot
- TinyChatEngine: Targeted at Nvidia, Apple M1 and RPi, from Song Han's (MIT) group.
- Llama Stack (swift, kotlin): These libraries are a set of SDKs that provide a simple and effective way to integrate AI capabilities into your iOS/Android app, whether it is local (on-device) or remote inference.
- OLMoE.Swift: Ai2 OLMoE is an AI chatbot powered by the OLMoE model. Unlike cloud-based AI assistants, OLMoE runs entirely on your device, ensuring complete privacy and offline accessibility—even in Flight Mode.
- HuggingSnap: HuggingSnap is an iOS app that lets users quickly learn more about the places and objects around them. HuggingSnap runs SmolVLM2, a compact open multimodal model that accepts arbitrary sequences of image, videos, and text inputs to produce text outputs.
- Flower Intelligence: Flower Intelligence is a cross-platform inference library that lets users seamlessly interact with Large-Language Models both locally and remotely in a secure and private way. The library was created by the Flower Labs team. It supports TypeScript, JavaScript and Swift backends.
- PowerInfer-2: Fast Large Language Model Inference on a Smartphone (paper, code)
- [MobiCom'24] Mobile Foundation Model as Firmware (paper, code)
- Merino: Entropy-driven Design for Generative Language Models on IoT Devicess (paper)
- LLM as a System Service on Mobile Devices (paper)
- LLMCad: Fast and Scalable On-device Large Language Model Inference (paper)
- EdgeMoE: Fast On-Device Inference of MoE-based Large Language Models (paper)
This section focuses on measurements and benchmarking efforts for assessing LLM performance when deployed on device.
- PalmBench: A Comprehensive Benchmark of Compressed Large Language Models on Mobile Platforms (paper)
- Large Language Model Performance Benchmarking on Mobile Platforms: A Thorough Evaluation (paper)
- [EdgeFM @ MobiSys'24] Large Language Models on Mobile Devices: Measurements, Analysis, and Insights (paper)
- MobileAIBench: Benchmarking LLMs and LMMs for On-Device Use Cases (paper)
- [MobiCom'24] MELTing point: Mobile Evaluation of Language Transformers (paper, talk, code)
This section focuses on techniques and optimisations that target mobile-specific deployment.
- Mixture of Cache-Conditional Experts for Efficient Mobile Device Inference (paper)
- PhoneLM: An Efficient and Capable Small Language Model Family through Principled Pre-training (paper, code)
- MobileQuant: Mobile-friendly Quantization for On-device Language Models (paper, code)
- Gemma 2: Improving Open Language Models at a Practical Size (paper, code)
- Apple Intelligence Foundation Language Models (paper)
- Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone (paper, code)
- Gemma: Open Models Based on Gemini Research and Technology (paper, code)
- MobiLlama: Towards Accurate and Lightweight Fully Transparent GPT (paper, code)
- [ICML'24] MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases (paper, code)
- TinyLlama: An Open-Source Small Language Model (paper, code)
- Octopus v3: Technical Report for On-device Sub-billion Multimodal AI Agent (paper)
- Octopus v2: On-device language model for super agent (paper)
- Towards an On-device Agent for Text Rewriting (paper)
This section refers to multimodal LLMs, which integrate vision or other modalities in their tasks.
- TinyLLaVA: A Framework of Small-scale Large Multimodal Models (paper, code)
- MobileVLM V2: Faster and Stronger Baseline for Vision Language Model (paper, code)
This section includes survey papers on LLM efficiency, a topic very much related to deploying in constrained devices.
- Small Language Models (SLMs) Can Still Pack a Punch: A survey (paper)
- A Comprehensive Survey of Small Language Models in the Era of Large Language Models: Techniques, Enhancements, Applications, Collaboration with LLMs, and Trustworthiness (paper)
- Small Language Models: Survey, Measurements, and Insights (paper)
- On-Device Language Models: A Comprehensive Review (paper)
- A Survey of Resource-efficient LLM and Multimodal Foundation Models (paper)
- Efficient Large Language Models: A Survey (paper, code)
- Towards Efficient Generative Large Language Model Serving: A Survey from Algorithms to Systems (paper)
- A Survey on Model Compression for Large Language Models (paper)
This section refers to papers attempting to train/fine-tune LLMs on device, in a standalone or federated manner.
- [Privacy in Natural Language Processing @ ACL'24] PocketLLM: Enabling On-Device Fine-Tuning for Personalized LLMs (paper)
- [MobiCom'23] Federated Few-Shot Learning for Mobile NLP (paper, code)
- FwdLLM: Efficient FedLLM using Forward Gradient (paper, code)
- [Electronics'24] Forward Learning of Large Language Models by Consumer Devices (paper)
- Federated Fine-Tuning of LLMs on the Very Edge: The Good, the Bad, the Ugly (paper)
- Federated Full-Parameter Tuning of Billion-Sized Language Models with Communication Cost under 18 Kilobytes (paper, code)
This section includes paper that are mobile-related, but not necessarily run on device.
- Ferret-UI: Grounded Mobile UI Understanding with Multimodal LLMs (paper)
- Mobile-Agent: Autonomous Multi-Modal Mobile Device Agent with Visual Perception (paper, code)
- [MobiCom'24] MobileGPT: Augmenting LLM with Human-like App Memory for Mobile Task Automation (paper)
- [MobiCom'24] AutoDroid: LLM-powered Task Automation in Android (paper, code)
- [NeurIPS'23] AndroidInTheWild: A Large-Scale Dataset For Android Device Control (paper, code)
- GPT-4V in Wonderland: Large Multimodal Models for Zero-Shot Smartphone GUI Navigation (paper, code)
- [ACL'20] Mapping Natural Language Instructions to Mobile UI Action Sequences (paper)
- WWDC'24 - Apple Foundation Models
- PyTorch Executorch Alpha
- Google - LLMs On-Device with MediaPipe and TFLite
- Qualcomm - The future of AI is Hybrid
- ARM - Generative AI on mobile
If you want to read more about related topics, here are some tangential awesome repositories to visit:
- NexaAI/Awesome-LLMs-on-device on LLMs on Device
- Hannibal046/Awesome-LLM on Large Language Models
- KennethanCeyer/awesome-llm on Large Language Models
- HuangOwen/Awesome-LLM-Compression on Large Language Model Compression
- csarron/awesome-emdl on Embedded and Mobile Deep Learning
Contributions welcome! Read the contribution guidelines first.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for awesome-mobile-llm
Similar Open Source Tools
awesome-mobile-llm
Awesome Mobile LLMs is a curated list of Large Language Models (LLMs) and related studies focused on mobile and embedded hardware. The repository includes information on various LLM models, deployment frameworks, benchmarking efforts, applications, multimodal LLMs, surveys on efficient LLMs, training LLMs on device, mobile-related use-cases, industry announcements, and related repositories. It aims to be a valuable resource for researchers, engineers, and practitioners interested in mobile LLMs.

tt-metal
TT-NN is a python & C++ Neural Network OP library. It provides a low-level programming model, TT-Metalium, enabling kernel development for Tenstorrent hardware.
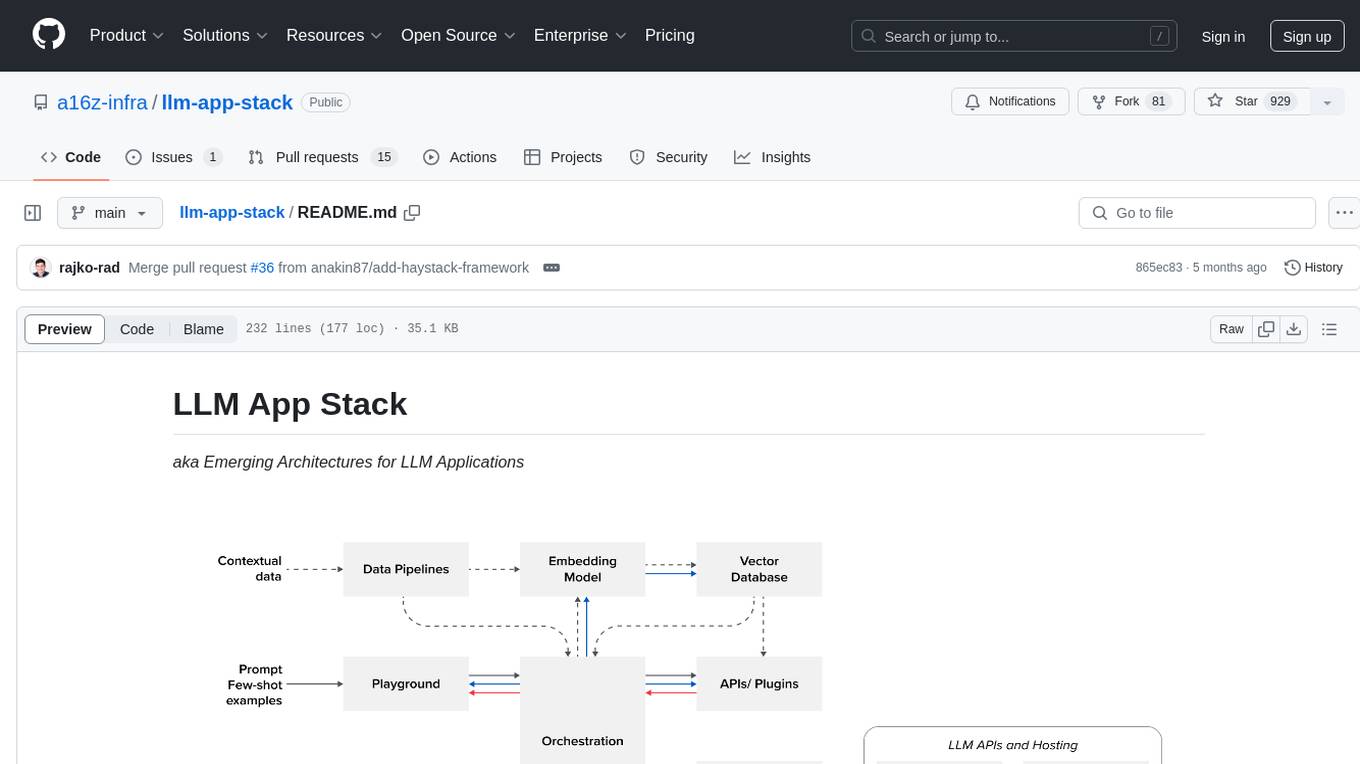
llm-app-stack
LLM App Stack, also known as Emerging Architectures for LLM Applications, is a comprehensive list of available tools, projects, and vendors at each layer of the LLM app stack. It covers various categories such as Data Pipelines, Embedding Models, Vector Databases, Playgrounds, Orchestrators, APIs/Plugins, LLM Caches, Logging/Monitoring/Eval, Validators, LLM APIs (proprietary and open source), App Hosting Platforms, Cloud Providers, and Opinionated Clouds. The repository aims to provide a detailed overview of tools and projects for building, deploying, and maintaining enterprise data solutions, AI models, and applications.
2024-AICS-EXP
This repository contains the complete archive of the 2024 version of the 'Intelligent Computing System' experiment at the University of Chinese Academy of Sciences. The experiment content for 2024 has undergone extensive adjustments to the knowledge system and experimental topics, including the transition from TensorFlow to PyTorch, significant modifications to previous code, and the addition of experiments with large models. The project is continuously updated in line with the course progress, currently up to the seventh experiment. Updates include the addition of experiments like YOLOv5 in Experiment 5-3, updates to theoretical teaching materials, and fixes for bugs in Experiment 6 code. The repository also includes experiment manuals, questions, and answers for various experiments, with some data sets hosted on Baidu Cloud due to size limitations on GitHub.

amber-train
Amber is the first model in the LLM360 family, an initiative for comprehensive and fully open-sourced LLMs. It is a 7B English language model with the LLaMA architecture. The model type is a language model with the same architecture as LLaMA-7B. It is licensed under Apache 2.0. The resources available include training code, data preparation, metrics, and fully processed Amber pretraining data. The model has been trained on various datasets like Arxiv, Book, C4, Refined-Web, StarCoder, StackExchange, and Wikipedia. The hyperparameters include a total of 6.7B parameters, hidden size of 4096, intermediate size of 11008, 32 attention heads, 32 hidden layers, RMSNorm ε of 1e^-6, max sequence length of 2048, and a vocabulary size of 32000.
Efficient-Multimodal-LLMs-Survey
Efficient Multimodal Large Language Models: A Survey provides a comprehensive review of efficient and lightweight Multimodal Large Language Models (MLLMs), focusing on model size reduction and cost efficiency for edge computing scenarios. The survey covers the timeline of efficient MLLMs, research on efficient structures and strategies, and applications. It discusses current limitations and future directions in efficient MLLM research.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.
visionOS-examples
visionOS-examples is a repository containing accelerators for Spatial Computing. It includes examples such as Local Large Language Model, Chat Apple Vision Pro, WebSockets, Anchor To Head, Hand Tracking, Battery Life, Countdown, Plane Detection, Timer Vision, and PencilKit for visionOS. The repository showcases various functionalities and features for Apple Vision Pro, offering tools for developers to enhance their visionOS apps with capabilities like hand tracking, plane detection, and real-time cryptocurrency prices.
Efficient-Multimodal-LLMs-Survey
Efficient Multimodal Large Language Models: A Survey provides a comprehensive review of efficient and lightweight Multimodal Large Language Models (MLLMs), focusing on model size reduction and cost efficiency for edge computing scenarios. The survey covers the timeline of efficient MLLMs, research on efficient structures and strategies, and their applications, while also discussing current limitations and future directions.

nntrainer
NNtrainer is a software framework for training neural network models on devices with limited resources. It enables on-device fine-tuning of neural networks using user data for personalization. NNtrainer supports various machine learning algorithms and provides examples for tasks such as few-shot learning, ResNet, VGG, and product rating. It is optimized for embedded devices and utilizes CBLAS and CUBLAS for accelerated calculations. NNtrainer is open source and released under the Apache License version 2.0.
awesome-openclaw
Awesome OpenClaw is a curated collection of resources, tools, skills, tutorials, and articles for the open-source AI agent OpenClaw. It provides official resources, installation guides, skills & plugins, integrations with messaging platforms and external services, MCP support, tutorials & guides, articles & news, community information, community projects, alternatives & comparisons, security best practices and tools, and guidelines for contributing. OpenClaw is an autonomous AI agent that connects to 50+ integrations and allows chatting with AI through various messaging platforms.
ts-bench
TS-Bench is a performance benchmarking tool for TypeScript projects. It provides detailed insights into the performance of TypeScript code, helping developers optimize their projects. With TS-Bench, users can measure and compare the execution time of different code snippets, functions, or modules. The tool offers a user-friendly interface for running benchmarks and analyzing the results. TS-Bench is a valuable asset for developers looking to enhance the performance of their TypeScript applications.

HuatuoGPT-II
HuatuoGPT2 is an innovative domain-adapted medical large language model that excels in medical knowledge and dialogue proficiency. It showcases state-of-the-art performance in various medical benchmarks, surpassing GPT-4 in expert evaluations and fresh medical licensing exams. The open-source release includes HuatuoGPT2 models in 7B, 13B, and 34B versions, training code for one-stage adaptation, partial pre-training and fine-tuning instructions, and evaluation methods for medical response capabilities and professional pharmacist exams. The tool aims to enhance LLM capabilities in the Chinese medical field through open-source principles.

data-prep-kit
Data Prep Kit accelerates unstructured data preparation for LLM app developers. It allows developers to cleanse, transform, and enrich unstructured data for pre-training, fine-tuning, instruct-tuning LLMs, or building RAG applications. The kit provides modules for Python, Ray, and Spark runtimes, supporting Natural Language and Code data modalities. It offers a framework for custom transforms and uses Kubeflow Pipelines for workflow automation. Users can install the kit via PyPi and access a variety of transforms for data processing pipelines.
AI-For-Beginners
AI-For-Beginners is a comprehensive 12-week, 24-lesson curriculum designed by experts at Microsoft to introduce beginners to the world of Artificial Intelligence (AI). The curriculum covers various topics such as Symbolic AI, Neural Networks, Computer Vision, Natural Language Processing, Genetic Algorithms, and Multi-Agent Systems. It includes hands-on lessons, quizzes, and labs using popular frameworks like TensorFlow and PyTorch. The focus is on providing a foundational understanding of AI concepts and principles, making it an ideal starting point for individuals interested in AI.
For similar tasks
pyllms
PyLLMs is a minimal Python library designed to connect to various Language Model Models (LLMs) such as OpenAI, Anthropic, Google, AI21, Cohere, Aleph Alpha, and HuggingfaceHub. It provides a built-in model performance benchmark for fast prototyping and evaluating different models. Users can easily connect to top LLMs, get completions from multiple models simultaneously, and evaluate models on quality, speed, and cost. The library supports asynchronous completion, streaming from compatible models, and multi-model initialization for testing and comparison. Additionally, it offers features like passing chat history, system messages, counting tokens, and benchmarking models based on quality, speed, and cost.
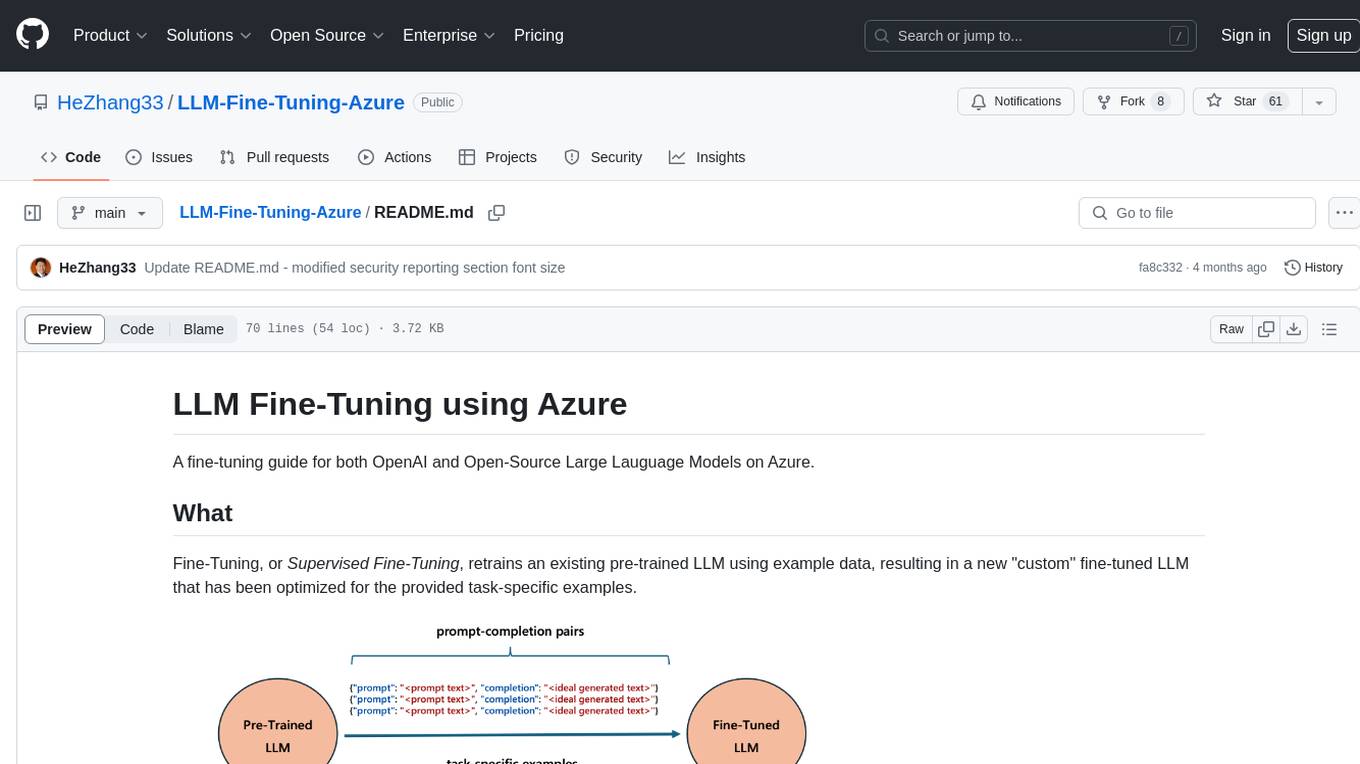
LLM-Fine-Tuning-Azure
A fine-tuning guide for both OpenAI and Open-Source Large Language Models on Azure. Fine-Tuning retrains an existing pre-trained LLM using example data, resulting in a new 'custom' fine-tuned LLM optimized for task-specific examples. Use cases include improving LLM performance on specific tasks and introducing information not well represented by the base LLM model. Suitable for cases where latency is critical, high accuracy is required, and clear evaluation metrics are available. Learning path includes labs for fine-tuning GPT and Llama2 models via Dashboards and Python SDK.

cellseg_models.pytorch
cellseg-models.pytorch is a Python library built upon PyTorch for 2D cell/nuclei instance segmentation models. It provides multi-task encoder-decoder architectures and post-processing methods for segmenting cell/nuclei instances. The library offers high-level API to define segmentation models, open-source datasets for training, flexibility to modify model components, sliding window inference, multi-GPU inference, benchmarking utilities, regularization techniques, and example notebooks for training and finetuning models with different backbones.
awesome-mobile-llm
Awesome Mobile LLMs is a curated list of Large Language Models (LLMs) and related studies focused on mobile and embedded hardware. The repository includes information on various LLM models, deployment frameworks, benchmarking efforts, applications, multimodal LLMs, surveys on efficient LLMs, training LLMs on device, mobile-related use-cases, industry announcements, and related repositories. It aims to be a valuable resource for researchers, engineers, and practitioners interested in mobile LLMs.
Medical_Image_Analysis
The Medical_Image_Analysis repository focuses on X-ray image-based medical report generation using large language models. It provides pre-trained models and benchmarks for CheXpert Plus dataset, context sample retrieval for X-ray report generation, and pre-training on high-definition X-ray images. The goal is to enhance diagnostic accuracy and reduce patient wait times by improving X-ray report generation through advanced AI techniques.

AngelSlim
AngelSlim is a comprehensive and efficient large model compression toolkit designed to be user-friendly. It integrates mainstream compression algorithms for easy one-click access, continuously innovates compression algorithms, and optimizes end-to-end performance in model compression and deployment. It supports various models for quantization and speculative sampling, with a focus on performance optimization and ease of use.
speculators
Speculators is a unified library for building, training, and storing speculative decoding algorithms for large language model (LLM) inference. It speeds up LLM inference by using a smaller, faster draft model (the speculator) to propose tokens, which are then verified by the larger base model, reducing latency without compromising output quality. Trained models can seamlessly run in vLLM, enabling the deployment of speculative decoding in production-grade inference servers.

flashinfer
FlashInfer is a library for Language Languages Models that provides high-performance implementation of LLM GPU kernels such as FlashAttention, PageAttention and LoRA. FlashInfer focus on LLM serving and inference, and delivers state-the-art performance across diverse scenarios.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.
TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.