
langcorn
⛓️ Serving LangChain LLM apps and agents automagically with FastApi. LLMops
Stars: 821
LangCorn is an API server that enables you to serve LangChain models and pipelines with ease, leveraging the power of FastAPI for a robust and efficient experience. It offers features such as easy deployment of LangChain models and pipelines, ready-to-use authentication functionality, high-performance FastAPI framework for serving requests, scalability and robustness for language processing applications, support for custom pipelines and processing, well-documented RESTful API endpoints, and asynchronous processing for faster response times.
README:
LangCorn is an API server that enables you to serve LangChain models and pipelines with ease, leveraging the power of FastAPI for a robust and efficient experience.






- Easy deployment of LangChain models and pipelines
- Ready to use auth functionality
- High-performance FastAPI framework for serving requests
- Scalable and robust solution for language processing applications
- Supports custom pipelines and processing
- Well-documented RESTful API endpoints
- Asynchronous processing for faster response times
To get started with LangCorn, simply install the package using pip:
pip install langcornExample LLM chain ex1.py
import os
from langchain import LLMMathChain, OpenAI
os.environ["OPENAI_API_KEY"] = os.environ.get("OPENAI_API_KEY", "sk-********")
llm = OpenAI(temperature=0)
chain = LLMMathChain(llm=llm, verbose=True)Run your LangCorn FastAPI server:
langcorn server examples.ex1:chain
[INFO] 2023-04-18 14:34:56.32 | api:create_service:75 | Creating service
[INFO] 2023-04-18 14:34:57.51 | api:create_service:85 | lang_app='examples.ex1:chain':LLMChain(['product'])
[INFO] 2023-04-18 14:34:57.51 | api:create_service:104 | Serving
[INFO] 2023-04-18 14:34:57.51 | api:create_service:106 | Endpoint: /docs
[INFO] 2023-04-18 14:34:57.51 | api:create_service:106 | Endpoint: /examples.ex1/run
INFO: Started server process [27843]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://127.0.0.1:8718 (Press CTRL+C to quit)or as an alternative
python -m langcorn server examples.ex1:chain
Run multiple chains
python -m langcorn server examples.ex1:chain examples.ex2:chain
[INFO] 2023-04-18 14:35:21.11 | api:create_service:75 | Creating service
[INFO] 2023-04-18 14:35:21.82 | api:create_service:85 | lang_app='examples.ex1:chain':LLMChain(['product'])
[INFO] 2023-04-18 14:35:21.82 | api:create_service:85 | lang_app='examples.ex2:chain':SimpleSequentialChain(['input'])
[INFO] 2023-04-18 14:35:21.82 | api:create_service:104 | Serving
[INFO] 2023-04-18 14:35:21.82 | api:create_service:106 | Endpoint: /docs
[INFO] 2023-04-18 14:35:21.82 | api:create_service:106 | Endpoint: /examples.ex1/run
[INFO] 2023-04-18 14:35:21.82 | api:create_service:106 | Endpoint: /examples.ex2/run
INFO: Started server process [27863]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://127.0.0.1:8718 (Press CTRL+C to quit)Import the necessary packages and create your FastAPI app:
from fastapi import FastAPI
from langcorn import create_service
app:FastAPI = create_service("examples.ex1:chain")Multiple chains
from fastapi import FastAPI
from langcorn import create_service
app:FastAPI = create_service("examples.ex2:chain", "examples.ex1:chain")or
from fastapi import FastAPI
from langcorn import create_service
app: FastAPI = create_service(
"examples.ex1:chain",
"examples.ex2:chain",
"examples.ex3:chain",
"examples.ex4:sequential_chain",
"examples.ex5:conversation",
"examples.ex6:conversation_with_summary",
"examples.ex7_agent:agent",
)Run your LangCorn FastAPI server:
uvicorn main:app --host 0.0.0.0 --port 8000Now, your LangChain models and pipelines are accessible via the LangCorn API server.
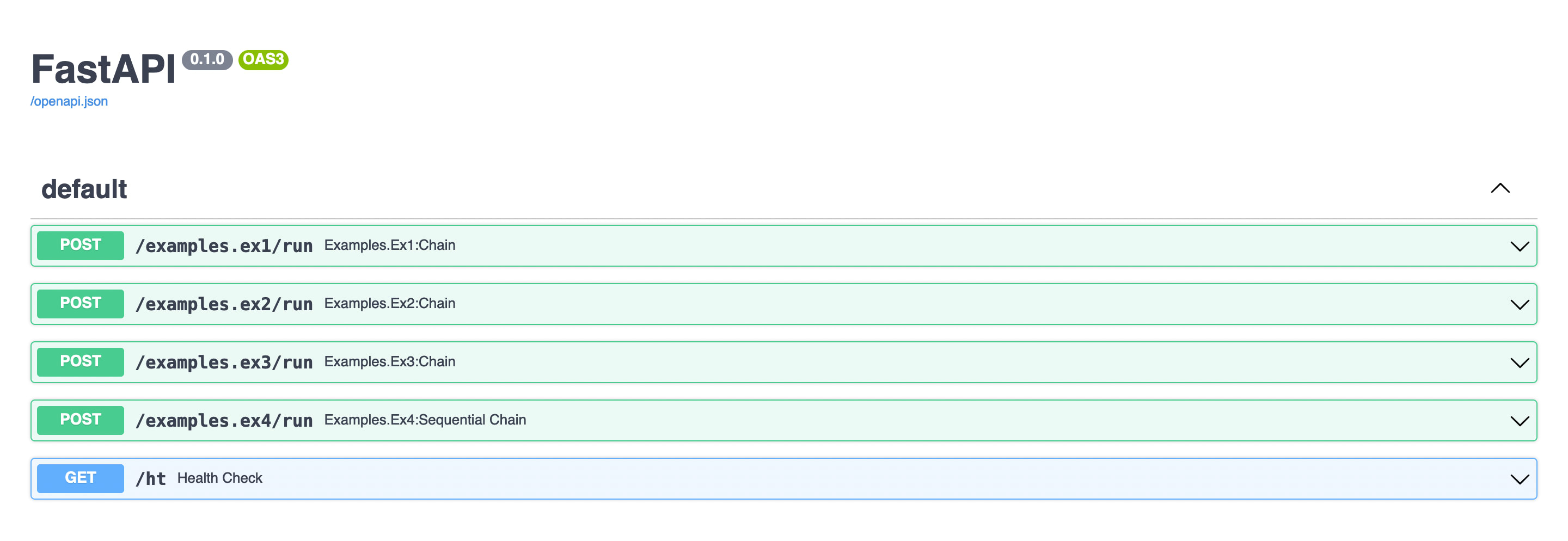
Automatically served FastAPI doc Live example hosted on vercel.
It possible to add a static api token auth by specifying auth_token
python langcorn server examples.ex1:chain examples.ex2:chain --auth_token=api-secret-valueor
app:FastAPI = create_service("examples.ex1:chain", auth_token="api-secret-value")POST http://0.0.0.0:3000/examples.ex6/run
X-LLM-API-KEY: sk-******
Content-Type: application/json{
"history": "string",
"input": "What is brain?",
"memory": [
{
"type": "human",
"data": {
"content": "What is memory?",
"additional_kwargs": {}
}
},
{
"type": "ai",
"data": {
"content": " Memory is the ability of the brain to store, retain, and recall information. It is the capacity to remember past experiences, facts, and events. It is also the ability to learn and remember new information.",
"additional_kwargs": {}
}
}
]
}
Response:
{
"output": " The brain is an organ in the human body that is responsible for controlling thought, memory, emotion, and behavior. It is composed of billions of neurons that communicate with each other through electrical and chemical signals. It is the most complex organ in the body and is responsible for all of our conscious and unconscious actions.",
"error": "",
"memory": [
{
"type": "human",
"data": {
"content": "What is memory?",
"additional_kwargs": {}
}
},
{
"type": "ai",
"data": {
"content": " Memory is the ability of the brain to store, retain, and recall information. It is the capacity to remember past experiences, facts, and events. It is also the ability to learn and remember new information.",
"additional_kwargs": {}
}
},
{
"type": "human",
"data": {
"content": "What is brain?",
"additional_kwargs": {}
}
},
{
"type": "ai",
"data": {
"content": " The brain is an organ in the human body that is responsible for controlling thought, memory, emotion, and behavior. It is composed of billions of neurons that communicate with each other through electrical and chemical signals. It is the most complex organ in the body and is responsible for all of our conscious and unconscious actions.",
"additional_kwargs": {}
}
}
]
}To override the default LLM params per request
POST http://0.0.0.0:3000/examples.ex1/run
X-LLM-API-KEY: sk-******
X-LLM-TEMPERATURE: 0.7
X-MAX-TOKENS: 256
X-MODEL-NAME: gpt5
Content-Type: application/jsonSee ex12.py
chain = LLMChain(llm=llm, prompt=prompt, verbose=True)
# Run the chain only specifying the input variable.
def run(query: str) -> Joke:
output = chain.run(query)
return parser.parse(output)
app: FastAPI = create_service("examples.ex12:run")For more detailed information on how to use LangCorn, including advanced features and customization options, please refer to the official documentation.
Contributions to LangCorn are welcome! If you'd like to contribute, please follow these steps:
- Fork the repository on GitHub
- Create a new branch for your changes
- Commit your changes to the new branch
- Push your changes to the forked repository
- Open a pull request to the main LangCorn repository
Before contributing, please read the contributing guidelines.
LangCorn is released under the MIT License.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for langcorn
Similar Open Source Tools
langcorn
LangCorn is an API server that enables you to serve LangChain models and pipelines with ease, leveraging the power of FastAPI for a robust and efficient experience. It offers features such as easy deployment of LangChain models and pipelines, ready-to-use authentication functionality, high-performance FastAPI framework for serving requests, scalability and robustness for language processing applications, support for custom pipelines and processing, well-documented RESTful API endpoints, and asynchronous processing for faster response times.
functionary
Functionary is a language model that interprets and executes functions/plugins. It determines when to execute functions, whether in parallel or serially, and understands their outputs. Function definitions are given as JSON Schema Objects, similar to OpenAI GPT function calls. It offers documentation and examples on functionary.meetkai.com. The newest model, meetkai/functionary-medium-v3.1, is ranked 2nd in the Berkeley Function-Calling Leaderboard. Functionary supports models with different context lengths and capabilities for function calling and code interpretation. It also provides grammar sampling for accurate function and parameter names. Users can deploy Functionary models serverlessly using Modal.com.

LTEngine
LTEngine is a free and open-source local AI machine translation API written in Rust. It is self-hosted and compatible with LibreTranslate. LTEngine utilizes large language models (LLMs) via llama.cpp, offering high-quality translations that rival or surpass DeepL for certain languages. It supports various accelerators like CUDA, Metal, and Vulkan, with the largest model 'gemma3-27b' fitting on a single consumer RTX 3090. LTEngine is actively developed, with a roadmap outlining future enhancements and features.

crush
Crush is a versatile tool designed to enhance coding workflows in your terminal. It offers support for multiple LLMs, allows for flexible switching between models, and enables session-based work management. Crush is extensible through MCPs and works across various operating systems. It can be installed using package managers like Homebrew and NPM, or downloaded directly. Crush supports various APIs like Anthropic, OpenAI, Groq, and Google Gemini, and allows for customization through environment variables. The tool can be configured locally or globally, and supports LSPs for additional context. Crush also provides options for ignoring files, allowing tools, and configuring local models. It respects `.gitignore` files and offers logging capabilities for troubleshooting and debugging.

npi
NPi is an open-source platform providing Tool-use APIs to empower AI agents with the ability to take action in the virtual world. It is currently under active development, and the APIs are subject to change in future releases. NPi offers a command line tool for installation and setup, along with a GitHub app for easy access to repositories. The platform also includes a Python SDK and examples like Calendar Negotiator and Twitter Crawler. Join the NPi community on Discord to contribute to the development and explore the roadmap for future enhancements.
ai-gateway
LangDB AI Gateway is an open-source enterprise AI gateway built in Rust. It provides a unified interface to all LLMs using the OpenAI API format, focusing on high performance, enterprise readiness, and data control. The gateway offers features like comprehensive usage analytics, cost tracking, rate limiting, data ownership, and detailed logging. It supports various LLM providers and provides OpenAI-compatible endpoints for chat completions, model listing, embeddings generation, and image generation. Users can configure advanced settings, such as rate limiting, cost control, dynamic model routing, and observability with OpenTelemetry tracing. The gateway can be run with Docker Compose and integrated with MCP tools for server communication.
firecrawl-mcp-server
Firecrawl MCP Server is a Model Context Protocol (MCP) server implementation that integrates with Firecrawl for web scraping capabilities. It offers features such as web scraping, crawling, and discovery, search and content extraction, deep research and batch scraping, automatic retries and rate limiting, cloud and self-hosted support, and SSE support. The server can be configured to run with various tools like Cursor, Windsurf, SSE Local Mode, Smithery, and VS Code. It supports environment variables for cloud API and optional configurations for retry settings and credit usage monitoring. The server includes tools for scraping, batch scraping, mapping, searching, crawling, and extracting structured data from web pages. It provides detailed logging and error handling functionalities for robust performance.

Acontext
Acontext is a context data platform designed for production AI agents, offering unified storage, built-in context management, and observability features. It helps agents scale from local demos to production without the need to rebuild context infrastructure. The platform provides solutions for challenges like scattered context data, long-running agents requiring context management, and tracking states from multi-modal agents. Acontext offers core features such as context storage, session management, disk storage, agent skills management, and sandbox for code execution and analysis. Users can connect to Acontext, install SDKs, initialize clients, store and retrieve messages, perform context engineering, and utilize agent storage tools. The platform also supports building agents using end-to-end scripts in Python and Typescript, with various templates available. Acontext's architecture includes client layer, backend with API and core components, infrastructure with PostgreSQL, S3, Redis, and RabbitMQ, and a web dashboard. Join the Acontext community on Discord and follow updates on GitHub.

openmacro
Openmacro is a multimodal personal agent that allows users to run code locally. It acts as a personal agent capable of completing and automating tasks autonomously via self-prompting. The tool provides a CLI natural-language interface for completing and automating tasks, analyzing and plotting data, browsing the web, and manipulating files. Currently, it supports API keys for models powered by SambaNova, with plans to add support for other hosts like OpenAI and Anthropic in future versions.

LocalAGI
LocalAGI is a powerful, self-hostable AI Agent platform that allows you to design AI automations without writing code. It provides a complete drop-in replacement for OpenAI's Responses APIs with advanced agentic capabilities. With LocalAGI, you can create customizable AI assistants, automations, chat bots, and agents that run 100% locally, without the need for cloud services or API keys. The platform offers features like no-code agents, web-based interface, advanced agent teaming, connectors for various platforms, comprehensive REST API, short & long-term memory capabilities, planning & reasoning, periodic tasks scheduling, memory management, multimodal support, extensible custom actions, fully customizable models, observability, and more.

langchainrb
Langchain.rb is a Ruby library that makes it easy to build LLM-powered applications. It provides a unified interface to a variety of LLMs, vector search databases, and other tools, making it easy to build and deploy RAG (Retrieval Augmented Generation) systems and assistants. Langchain.rb is open source and available under the MIT License.

ruby-openai
Use the OpenAI API with Ruby! 🤖🩵 Stream text with GPT-4, transcribe and translate audio with Whisper, or create images with DALL·E... Hire me | 🎮 Ruby AI Builders Discord | 🐦 Twitter | 🧠 Anthropic Gem | 🚂 Midjourney Gem ## Table of Contents * Ruby OpenAI * Table of Contents * Installation * Bundler * Gem install * Usage * Quickstart * With Config * Custom timeout or base URI * Extra Headers per Client * Logging * Errors * Faraday middleware * Azure * Ollama * Counting Tokens * Models * Examples * Chat * Streaming Chat * Vision * JSON Mode * Functions * Edits * Embeddings * Batches * Files * Finetunes * Assistants * Threads and Messages * Runs * Runs involving function tools * Image Generation * DALL·E 2 * DALL·E 3 * Image Edit * Image Variations * Moderations * Whisper * Translate * Transcribe * Speech * Errors * Development * Release * Contributing * License * Code of Conduct
open-edison
OpenEdison is a secure MCP control panel that connects AI to data/software with additional security controls to reduce data exfiltration risks. It helps address the lethal trifecta problem by providing visibility, monitoring potential threats, and alerting on data interactions. The tool offers features like data leak monitoring, controlled execution, easy configuration, visibility into agent interactions, a simple API, and Docker support. It integrates with LangGraph, LangChain, and plain Python agents for observability and policy enforcement. OpenEdison helps gain observability, control, and policy enforcement for AI interactions with systems of records, existing company software, and data to reduce risks of AI-caused data leakage.

ai00_server
AI00 RWKV Server is an inference API server for the RWKV language model based upon the web-rwkv inference engine. It supports VULKAN parallel and concurrent batched inference and can run on all GPUs that support VULKAN. No need for Nvidia cards!!! AMD cards and even integrated graphics can be accelerated!!! No need for bulky pytorch, CUDA and other runtime environments, it's compact and ready to use out of the box! Compatible with OpenAI's ChatGPT API interface. 100% open source and commercially usable, under the MIT license. If you are looking for a fast, efficient, and easy-to-use LLM API server, then AI00 RWKV Server is your best choice. It can be used for various tasks, including chatbots, text generation, translation, and Q&A.

firecrawl
Firecrawl is an API service that empowers AI applications with clean data from any website. It features advanced scraping, crawling, and data extraction capabilities. The repository is still in development, integrating custom modules into the mono repo. Users can run it locally but it's not fully ready for self-hosted deployment yet. Firecrawl offers powerful capabilities like scraping, crawling, mapping, searching, and extracting structured data from single pages, multiple pages, or entire websites with AI. It supports various formats, actions, and batch scraping. The tool is designed to handle proxies, anti-bot mechanisms, dynamic content, media parsing, change tracking, and more. Firecrawl is available as an open-source project under the AGPL-3.0 license, with additional features offered in the cloud version.

promptic
Promptic is a tool designed for LLM app development, providing a productive and pythonic way to build LLM applications. It leverages LiteLLM, allowing flexibility to switch LLM providers easily. Promptic focuses on building features by providing type-safe structured outputs, easy-to-build agents, streaming support, automatic prompt caching, and built-in conversation memory.
For similar tasks

flashinfer
FlashInfer is a library for Language Languages Models that provides high-performance implementation of LLM GPU kernels such as FlashAttention, PageAttention and LoRA. FlashInfer focus on LLM serving and inference, and delivers state-the-art performance across diverse scenarios.
langcorn
LangCorn is an API server that enables you to serve LangChain models and pipelines with ease, leveraging the power of FastAPI for a robust and efficient experience. It offers features such as easy deployment of LangChain models and pipelines, ready-to-use authentication functionality, high-performance FastAPI framework for serving requests, scalability and robustness for language processing applications, support for custom pipelines and processing, well-documented RESTful API endpoints, and asynchronous processing for faster response times.

Awesome-LLM
Awesome-LLM is a curated list of resources related to large language models, focusing on papers, projects, frameworks, tools, tutorials, courses, opinions, and other useful resources in the field. It covers trending LLM projects, milestone papers, other papers, open LLM projects, LLM training frameworks, LLM evaluation frameworks, tools for deploying LLM, prompting libraries & tools, tutorials, courses, books, and opinions. The repository provides a comprehensive overview of the latest advancements and resources in the field of large language models.
ChuanhuChatGPT
Chuanhu Chat is a user-friendly web graphical interface that provides various additional features for ChatGPT and other language models. It supports GPT-4, file-based question answering, local deployment of language models, online search, agent assistant, and fine-tuning. The tool offers a range of functionalities including auto-solving questions, online searching with network support, knowledge base for quick reading, local deployment of language models, GPT 3.5 fine-tuning, and custom model integration. It also features system prompts for effective role-playing, basic conversation capabilities with options to regenerate or delete dialogues, conversation history management with auto-saving and search functionalities, and a visually appealing user experience with themes, dark mode, LaTeX rendering, and PWA application support.

dash-infer
DashInfer is a C++ runtime tool designed to deliver production-level implementations highly optimized for various hardware architectures, including x86 and ARMv9. It supports Continuous Batching and NUMA-Aware capabilities for CPU, and can fully utilize modern server-grade CPUs to host large language models (LLMs) up to 14B in size. With lightweight architecture, high precision, support for mainstream open-source LLMs, post-training quantization, optimized computation kernels, NUMA-aware design, and multi-language API interfaces, DashInfer provides a versatile solution for efficient inference tasks. It supports x86 CPUs with AVX2 instruction set and ARMv9 CPUs with SVE instruction set, along with various data types like FP32, BF16, and InstantQuant. DashInfer also offers single-NUMA and multi-NUMA architectures for model inference, with detailed performance tests and inference accuracy evaluations available. The tool is supported on mainstream Linux server operating systems and provides documentation and examples for easy integration and usage.

awesome-mobile-llm
Awesome Mobile LLMs is a curated list of Large Language Models (LLMs) and related studies focused on mobile and embedded hardware. The repository includes information on various LLM models, deployment frameworks, benchmarking efforts, applications, multimodal LLMs, surveys on efficient LLMs, training LLMs on device, mobile-related use-cases, industry announcements, and related repositories. It aims to be a valuable resource for researchers, engineers, and practitioners interested in mobile LLMs.
llm_note
LLM notes repository contains detailed analysis on transformer models, language model compression, inference and deployment, high-performance computing, and system optimization methods. It includes discussions on various algorithms, frameworks, and performance analysis related to large language models and high-performance computing. The repository serves as a comprehensive resource for understanding and optimizing language models and computing systems.

llmaz
llmaz is an easy, advanced inference platform for large language models on Kubernetes. It aims to provide a production-ready solution that integrates with state-of-the-art inference backends. The platform supports efficient model distribution, accelerator fungibility, SOTA inference, various model providers, multi-host support, and scaling efficiency. Users can quickly deploy LLM services with minimal configurations and benefit from a wide range of advanced inference backends. llmaz is designed to optimize cost and performance while supporting cutting-edge researches like Speculative Decoding or Splitwise on Kubernetes.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.