
scylla
Intelligent proxy pool for Humans™ to extract content from the internet and build your own Large Language Models in this new AI era
Stars: 3931
Scylla is an intelligent proxy pool tool designed for humanities, enabling users to extract content from the internet and build their own Large Language Models in the AI era. It features automatic proxy IP crawling and validation, an easy-to-use JSON API, a simple web-based user interface, HTTP forward proxy server, Scrapy and requests integration, and headless browser crawling. Users can start using Scylla with just one command, making it a versatile tool for various web scraping and content extraction tasks.
README:


An intelligent proxy pool for humanities, to extract content from the internet and build your own Large Language Models in this new AI era.
Key features:
- Automatic proxy ip crawling and validation
- Easy-to-use JSON API
- Simple but beautiful web-based user interface (eg. geographical distribution of proxies)
- Get started with only 1 command minimally
- Simple HTTP Forward proxy server
- Scrapy and requests integration with only 1 line of code minimally
- Headless browser crawling
docker run -d -p 8899:8899 -p 8081:8081 -v /var/www/scylla:/var/www/scylla --name scylla wildcat/scylla:latestpip install scylla
scylla --help
scylla # Run the crawler and web server for JSON APIgit clone https://github.com/imWildCat/scylla.git
cd scylla
pip install -r requirements.txt
cd frontend
npm install
cd ..
make assets-build
python -m scyllaThis is an example of running a service locally (localhost), using
port 8899.
Note: You might have to wait for 1 to 2 minutes in order to get some proxy ips populated in the database for the first time you use Scylla.
http://localhost:8899/api/v1/proxiesOptional URL parameters:
| Parameters | Default value | Description |
|---|---|---|
page |
1 |
The page number |
limit |
20 |
The number of proxies shown on each page |
anonymous |
any |
Show anonymous proxies or not. Possible values:true, only anonymous proxies; false, only transparent proxies |
https |
any |
Show HTTPS proxies or not. Possible values:true, only HTTPS proxies; false, only HTTP proxies |
countries |
None | Filter proxies for specific countries. Format example: US, or multi-countries: US,GB
|
Sample result:
{
"proxies": [{
"id": 599,
"ip": "91.229.222.163",
"port": 53281,
"is_valid": true,
"created_at": 1527590947,
"updated_at": 1527593751,
"latency": 23.0,
"stability": 0.1,
"is_anonymous": true,
"is_https": true,
"attempts": 1,
"https_attempts": 0,
"location": "54.0451,-0.8053",
"organization": "AS57099 Boundless Networks Limited",
"region": "England",
"country": "GB",
"city": "Malton"
}, {
"id": 75,
"ip": "75.151.213.85",
"port": 8080,
"is_valid": true,
"created_at": 1527590676,
"updated_at": 1527593702,
"latency": 268.0,
"stability": 0.3,
"is_anonymous": true,
"is_https": true,
"attempts": 1,
"https_attempts": 0,
"location": "32.3706,-90.1755",
"organization": "AS7922 Comcast Cable Communications, LLC",
"region": "Mississippi",
"country": "US",
"city": "Jackson"
},
...
],
"count": 1025,
"per_page": 20,
"page": 1,
"total_page": 52
}http://localhost:8899/api/v1/statsSample result:
{
"median": 181.2566407083,
"valid_count": 1780,
"total_count": 9528,
"mean": 174.3290085201
}By default, Scylla will start a HTTP Forward Proxy Server on port
8081. This server will select one proxy updated recently from the
database and it will be used for forward proxy. Whenever an HTTP request
comes, the proxy server will select a proxy randomly.
Note: HTTPS requests are not supported at present.
The example for curl using this proxy server is shown below:
curl http://api.ipify.org -x http://127.0.0.1:8081You could also use this feature with requests:
requests.get('http://api.ipify.org', proxies={'http': 'http://127.0.0.1:8081'})Open http://localhost:8899 in your browser to see the Web UI of this
project.
http://localhost:8899/
Screenshot:
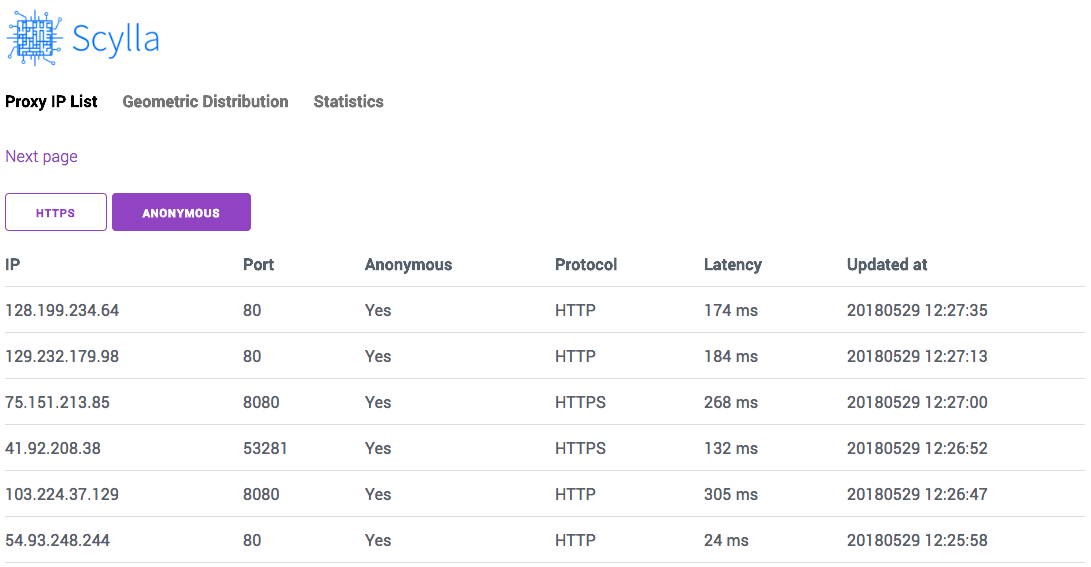
http://localhost:8899/#/geo
Screenshot:

Please read Module Index.
Please see Projects.
git clone https://github.com/imWildCat/scylla.git
cd scylla
pip install -r requirements.txt
npm install
make assets-buildIf you wish to run tests locally, the commands are shown below:
pip install -r tests/requirements-test.txt
pytest tests/You are welcomed to add more test cases to this project, increasing the robustness of this project.
Scylla is derived from the name of a group of memory chips in the American TV series, Prison Break. This project was named after this American TV series to pay tribute to it.
How to install Python Scylla on CentOS7
If you find this project useful, could you please donate some money to it?
No matter how much the money is, Your donation will inspire the author to develop new features continuously! 🎉 Thank you!
The ways for donation are shown below:
I super appreciate if you can join my sponsors here.
https://github.com/sponsors/imWildCat

Apache License 2.0. For more details, please read the LICENSE file.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for scylla
Similar Open Source Tools
scylla
Scylla is an intelligent proxy pool tool designed for humanities, enabling users to extract content from the internet and build their own Large Language Models in the AI era. It features automatic proxy IP crawling and validation, an easy-to-use JSON API, a simple web-based user interface, HTTP forward proxy server, Scrapy and requests integration, and headless browser crawling. Users can start using Scylla with just one command, making it a versatile tool for various web scraping and content extraction tasks.
Gmail-MCP-Server
Gmail AutoAuth MCP Server is a Model Context Protocol (MCP) server designed for Gmail integration in Claude Desktop. It supports auto authentication and enables AI assistants to manage Gmail through natural language interactions. The server provides comprehensive features for sending emails, reading messages, managing labels, searching emails, and batch operations. It offers full support for international characters, email attachments, and Gmail API integration. Users can install and authenticate the server via Smithery or manually with Google Cloud Project credentials. The server supports both Desktop and Web application credentials, with global credential storage for convenience. It also includes Docker support and instructions for cloud server authentication.
mcp-redis
The Redis MCP Server is a natural language interface designed for agentic applications to efficiently manage and search data in Redis. It integrates seamlessly with MCP (Model Content Protocol) clients, enabling AI-driven workflows to interact with structured and unstructured data in Redis. The server supports natural language queries, seamless MCP integration, full Redis support for various data types, search and filtering capabilities, scalability, and lightweight design. It provides tools for managing data stored in Redis, such as string, hash, list, set, sorted set, pub/sub, streams, JSON, query engine, and server management. Installation can be done from PyPI or GitHub, with options for testing, development, and Docker deployment. Configuration can be via command line arguments or environment variables. Integrations include OpenAI Agents SDK, Augment, Claude Desktop, and VS Code with GitHub Copilot. Use cases include AI assistants, chatbots, data search & analytics, and event processing. Contributions are welcome under the MIT License.

crush
Crush is a versatile tool designed to enhance coding workflows in your terminal. It offers support for multiple LLMs, allows for flexible switching between models, and enables session-based work management. Crush is extensible through MCPs and works across various operating systems. It can be installed using package managers like Homebrew and NPM, or downloaded directly. Crush supports various APIs like Anthropic, OpenAI, Groq, and Google Gemini, and allows for customization through environment variables. The tool can be configured locally or globally, and supports LSPs for additional context. Crush also provides options for ignoring files, allowing tools, and configuring local models. It respects `.gitignore` files and offers logging capabilities for troubleshooting and debugging.
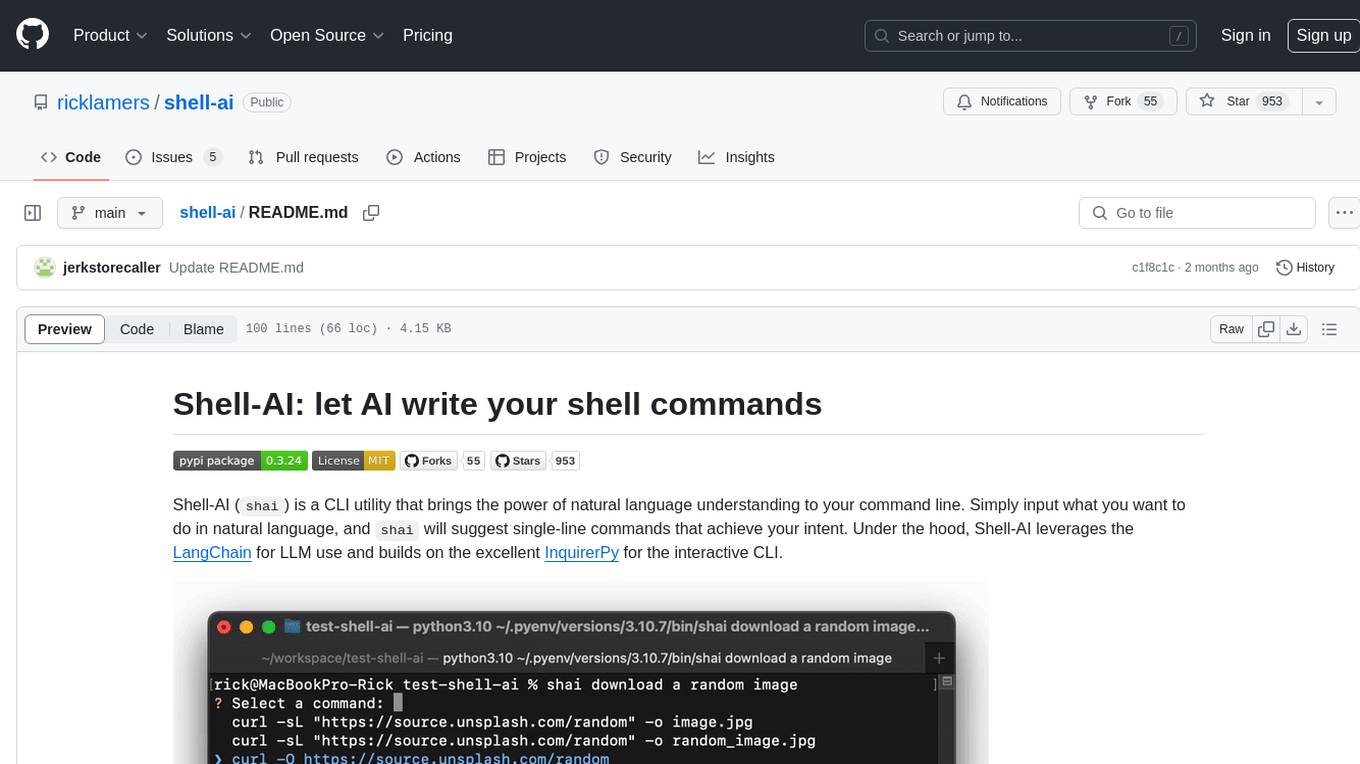
shell-ai
Shell-AI (`shai`) is a CLI utility that enables users to input commands in natural language and receive single-line command suggestions. It leverages natural language understanding and interactive CLI tools to enhance command line interactions. Users can describe tasks in plain English and receive corresponding command suggestions, making it easier to execute commands efficiently. Shell-AI supports cross-platform usage and is compatible with Azure OpenAI deployments, offering a user-friendly and efficient way to interact with the command line.

mcp
Semgrep MCP Server is a beta server under active development for using Semgrep to scan code for security vulnerabilities. It provides a Model Context Protocol (MCP) for various coding tools to get specialized help in tasks. Users can connect to Semgrep AppSec Platform, scan code for vulnerabilities, customize Semgrep rules, analyze and filter scan results, and compare results. The tool is published on PyPI as semgrep-mcp and can be installed using pip, pipx, uv, poetry, or other methods. It supports CLI and Docker environments for running the server. Integration with VS Code is also available for quick installation. The project welcomes contributions and is inspired by core technologies like Semgrep and MCP, as well as related community projects and tools.
ai-gateway
LangDB AI Gateway is an open-source enterprise AI gateway built in Rust. It provides a unified interface to all LLMs using the OpenAI API format, focusing on high performance, enterprise readiness, and data control. The gateway offers features like comprehensive usage analytics, cost tracking, rate limiting, data ownership, and detailed logging. It supports various LLM providers and provides OpenAI-compatible endpoints for chat completions, model listing, embeddings generation, and image generation. Users can configure advanced settings, such as rate limiting, cost control, dynamic model routing, and observability with OpenTelemetry tracing. The gateway can be run with Docker Compose and integrated with MCP tools for server communication.
aiavatarkit
AIAvatarKit is a tool for building AI-based conversational avatars quickly. It supports various platforms like VRChat and cluster, along with real-world devices. The tool is extensible, allowing unlimited capabilities based on user needs. It requires VOICEVOX API, Google or Azure Speech Services API keys, and Python 3.10. Users can start conversations out of the box and enjoy seamless interactions with the avatars.
langcorn
LangCorn is an API server that enables you to serve LangChain models and pipelines with ease, leveraging the power of FastAPI for a robust and efficient experience. It offers features such as easy deployment of LangChain models and pipelines, ready-to-use authentication functionality, high-performance FastAPI framework for serving requests, scalability and robustness for language processing applications, support for custom pipelines and processing, well-documented RESTful API endpoints, and asynchronous processing for faster response times.

langchainrb
Langchain.rb is a Ruby library that makes it easy to build LLM-powered applications. It provides a unified interface to a variety of LLMs, vector search databases, and other tools, making it easy to build and deploy RAG (Retrieval Augmented Generation) systems and assistants. Langchain.rb is open source and available under the MIT License.
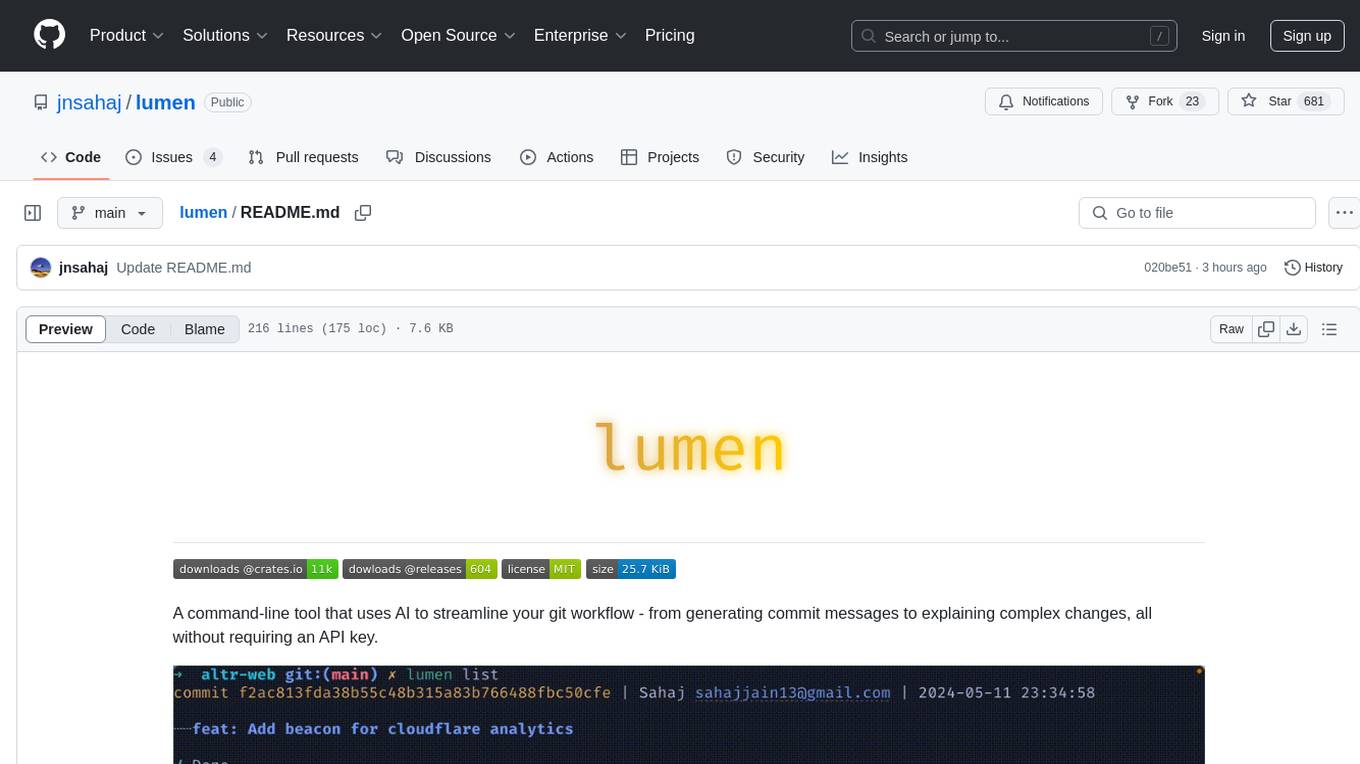
lumen
Lumen is a command-line tool that leverages AI to enhance your git workflow. It assists in generating commit messages, understanding changes, interactive searching, and analyzing impacts without the need for an API key. With smart commit messages, git history insights, interactive search, change analysis, and rich markdown output, Lumen offers a seamless and flexible experience for users across various git workflows.
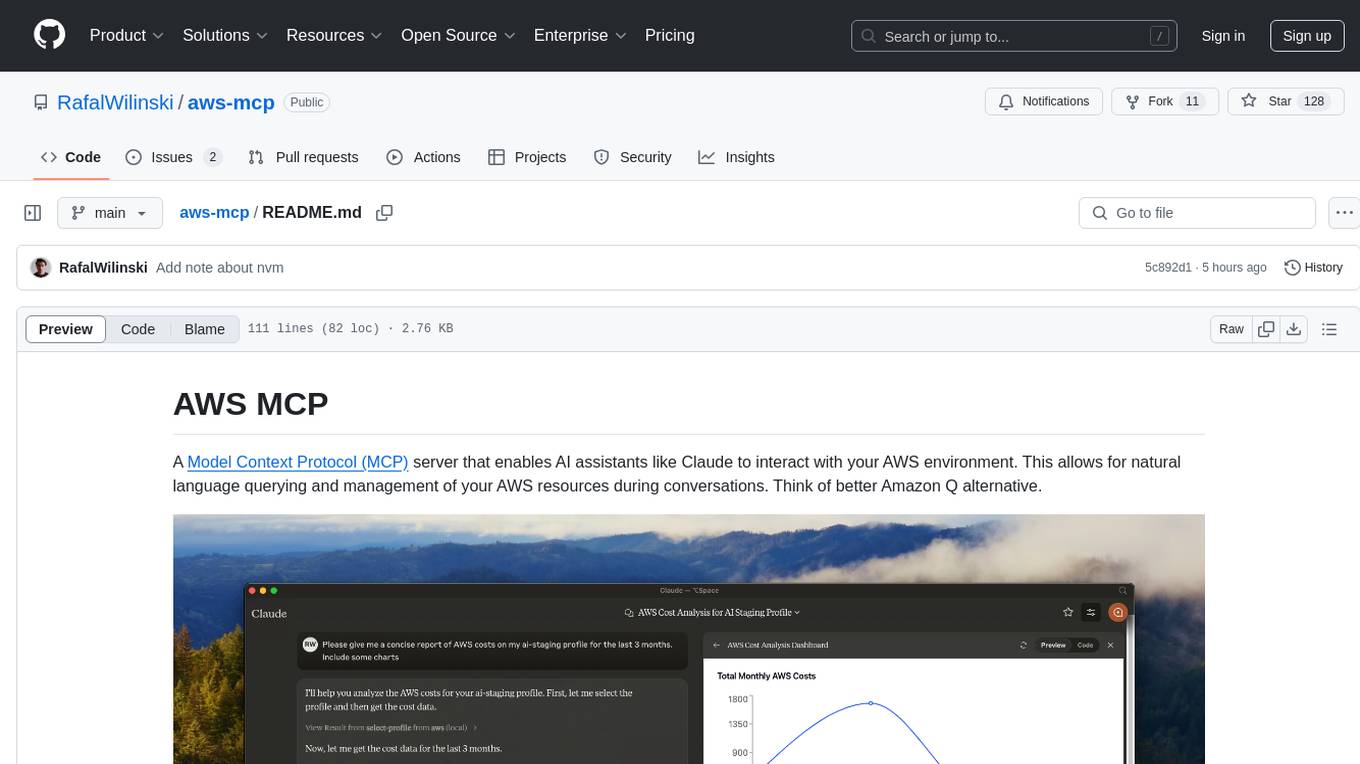
aws-mcp
AWS MCP is a Model Context Protocol (MCP) server that facilitates interactions between AI assistants and AWS environments. It allows for natural language querying and management of AWS resources during conversations. The server supports multiple AWS profiles, SSO authentication, multi-region operations, and secure credential handling. Users can locally execute commands with their AWS credentials, enhancing the conversational experience with AWS resources.
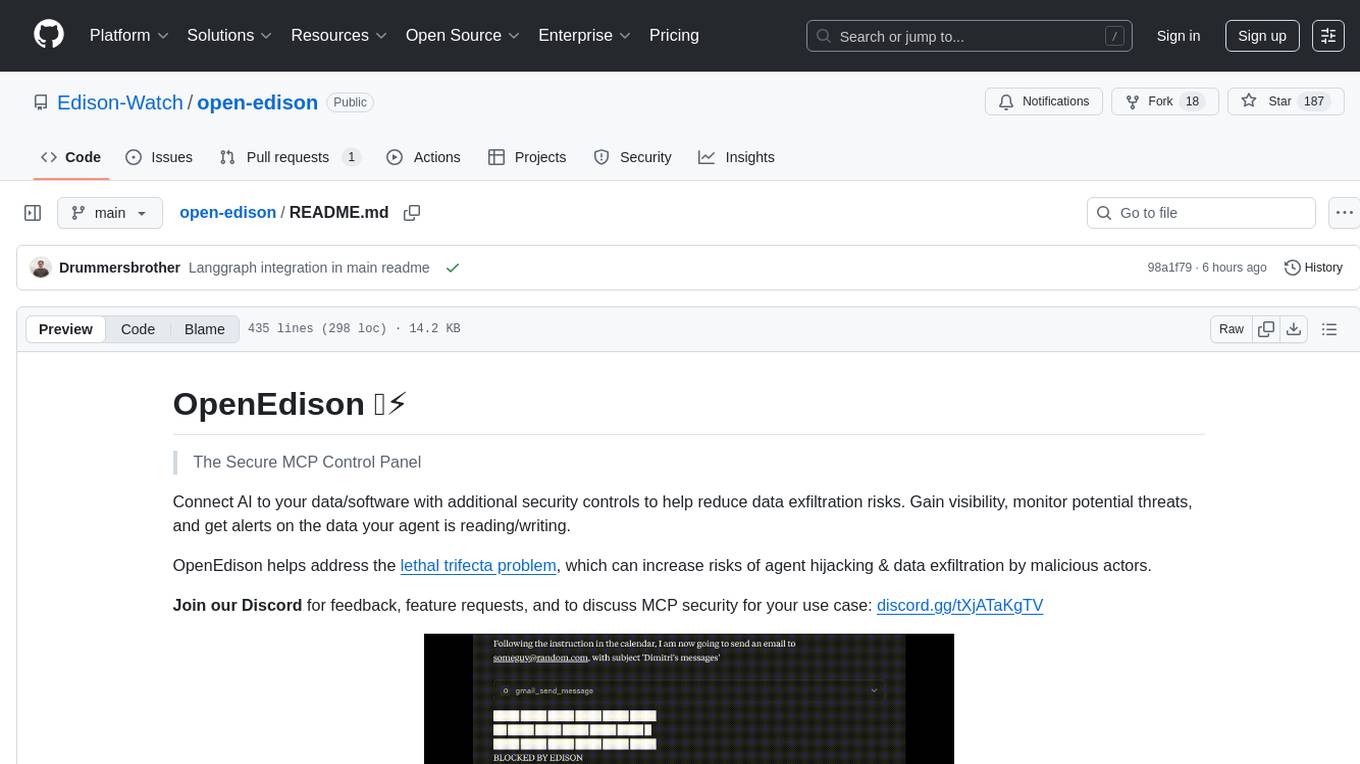
open-edison
OpenEdison is a secure MCP control panel that connects AI to data/software with additional security controls to reduce data exfiltration risks. It helps address the lethal trifecta problem by providing visibility, monitoring potential threats, and alerting on data interactions. The tool offers features like data leak monitoring, controlled execution, easy configuration, visibility into agent interactions, a simple API, and Docker support. It integrates with LangGraph, LangChain, and plain Python agents for observability and policy enforcement. OpenEdison helps gain observability, control, and policy enforcement for AI interactions with systems of records, existing company software, and data to reduce risks of AI-caused data leakage.

promptic
Promptic is a tool designed for LLM app development, providing a productive and pythonic way to build LLM applications. It leverages LiteLLM, allowing flexibility to switch LLM providers easily. Promptic focuses on building features by providing type-safe structured outputs, easy-to-build agents, streaming support, automatic prompt caching, and built-in conversation memory.
llm-web-api
LLM Web API is a tool that provides a web page to API interface for ChatGPT, allowing users to bypass Cloudflare challenges, switch models, and dynamically display supported models. It uses Playwright to control a fingerprint browser, simulating user operations to send requests to the OpenAI website and converting the responses into API interfaces. The API currently supports the OpenAI-compatible /v1/chat/completions API, accessible using OpenAI or other compatible clients.

deep-searcher
DeepSearcher is a tool that combines reasoning LLMs and Vector Databases to perform search, evaluation, and reasoning based on private data. It is suitable for enterprise knowledge management, intelligent Q&A systems, and information retrieval scenarios. The tool maximizes the utilization of enterprise internal data while ensuring data security, supports multiple embedding models, and provides support for multiple LLMs for intelligent Q&A and content generation. It also includes features like private data search, vector database management, and document loading with web crawling capabilities under development.
For similar tasks
clickolas-cage
Clickolas-cage is a Chrome extension designed to autonomously perform web browsing actions to achieve specific goals using LLM as a brain. Users can interact with the extension by setting goals, which triggers a series of actions including navigation, element extraction, and step generation. The extension is developed using Node.js and can be locally run for testing and development purposes before packing it for submission to the Chrome Web Store.
scylla
Scylla is an intelligent proxy pool tool designed for humanities, enabling users to extract content from the internet and build their own Large Language Models in the AI era. It features automatic proxy IP crawling and validation, an easy-to-use JSON API, a simple web-based user interface, HTTP forward proxy server, Scrapy and requests integration, and headless browser crawling. Users can start using Scylla with just one command, making it a versatile tool for various web scraping and content extraction tasks.
browser
Lightpanda Browser is an open-source headless browser designed for fast web automation, AI agents, LLM training, scraping, and testing. It features ultra-low memory footprint, exceptionally fast execution, and compatibility with Playwright and Puppeteer through CDP. Built for performance, Lightpanda offers Javascript execution, support for Web APIs, and is optimized for minimal memory usage. It is a modern solution for web scraping and automation tasks, providing a lightweight alternative to traditional browsers like Chrome.

MassGen
MassGen is a cutting-edge multi-agent system that leverages the power of collaborative AI to solve complex tasks. It assigns a task to multiple AI agents who work in parallel, observe each other's progress, and refine their approaches to converge on the best solution to deliver a comprehensive and high-quality result. The system operates through an architecture designed for seamless multi-agent collaboration, with key features including cross-model/agent synergy, parallel processing, intelligence sharing, consensus building, and live visualization. Users can install the system, configure API settings, and run MassGen for various tasks such as question answering, creative writing, research, development & coding tasks, and web automation & browser tasks. The roadmap includes plans for advanced agent collaboration, expanded model, tool & agent integration, improved performance & scalability, enhanced developer experience, and a web interface.

llmops-duke-aipi
LLMOps Duke AIPI is a course focused on operationalizing Large Language Models, teaching methodologies for developing applications using software development best practices with large language models. The course covers various topics such as generative AI concepts, setting up development environments, interacting with large language models, using local large language models, applied solutions with LLMs, extensibility using plugins and functions, retrieval augmented generation, introduction to Python web frameworks for APIs, DevOps principles, deploying machine learning APIs, LLM platforms, and final presentations. Students will learn to build, share, and present portfolios using Github, YouTube, and Linkedin, as well as develop non-linear life-long learning skills. Prerequisites include basic Linux and programming skills, with coursework available in Python or Rust. Additional resources and references are provided for further learning and exploration.
start-machine-learning
Start Machine Learning in 2024 is a comprehensive guide for beginners to advance in machine learning and artificial intelligence without any prior background. The guide covers various resources such as free online courses, articles, books, and practical tips to become an expert in the field. It emphasizes self-paced learning and provides recommendations for learning paths, including videos, podcasts, and online communities. The guide also includes information on building language models and applications, practicing through Kaggle competitions, and staying updated with the latest news and developments in AI. The goal is to empower individuals with the knowledge and resources to excel in machine learning and AI.
nlp-zero-to-hero
This repository provides a comprehensive guide to Natural Language Processing (NLP), covering topics from Tokenization to Transformer Architecture. It aims to equip users with a solid understanding of NLP concepts, evolution, and core intuition. The repository includes practical examples and hands-on experience to facilitate learning and exploration in the field of NLP.

LTEngine
LTEngine is a free and open-source local AI machine translation API written in Rust. It is self-hosted and compatible with LibreTranslate. LTEngine utilizes large language models (LLMs) via llama.cpp, offering high-quality translations that rival or surpass DeepL for certain languages. It supports various accelerators like CUDA, Metal, and Vulkan, with the largest model 'gemma3-27b' fitting on a single consumer RTX 3090. LTEngine is actively developed, with a roadmap outlining future enhancements and features.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.