
crush
Glamourous agentic coding for all 💘
Stars: 20242

Crush is a versatile tool designed to enhance coding workflows in your terminal. It offers support for multiple LLMs, allows for flexible switching between models, and enables session-based work management. Crush is extensible through MCPs and works across various operating systems. It can be installed using package managers like Homebrew and NPM, or downloaded directly. Crush supports various APIs like Anthropic, OpenAI, Groq, and Google Gemini, and allows for customization through environment variables. The tool can be configured locally or globally, and supports LSPs for additional context. Crush also provides options for ignoring files, allowing tools, and configuring local models. It respects `.gitignore` files and offers logging capabilities for troubleshooting and debugging.
README:

![]()

Your new coding bestie, now available in your favourite terminal.
Your tools, your code, and your workflows, wired into your LLM of choice.
终端里的编程新搭档,
无缝接入你的工具、代码与工作流,全面兼容主流 LLM 模型。
- Multi-Model: choose from a wide range of LLMs or add your own via OpenAI- or Anthropic-compatible APIs
- Flexible: switch LLMs mid-session while preserving context
- Session-Based: maintain multiple work sessions and contexts per project
- LSP-Enhanced: Crush uses LSPs for additional context, just like you do
-
Extensible: add capabilities via MCPs (
http,stdio, andsse) - Works Everywhere: first-class support in every terminal on macOS, Linux, Windows (PowerShell and WSL), Android, FreeBSD, OpenBSD, and NetBSD
- Industrial Grade: built on the Charm ecosystem, powering 25k+ applications, from leading open source projects to business-critical infrastructure
Use a package manager:
# Homebrew
brew install charmbracelet/tap/crush
# NPM
npm install -g @charmland/crush
# Arch Linux (btw)
yay -S crush-bin
# Nix
nix run github:numtide/nix-ai-tools#crush
# FreeBSD
pkg install crushWindows users:
# Winget
winget install charmbracelet.crush
# Scoop
scoop bucket add charm https://github.com/charmbracelet/scoop-bucket.git
scoop install crushNix (NUR)
Crush is available via the official Charm NUR in nur.repos.charmbracelet.crush, which is the most up-to-date way to get Crush in Nix.
You can also try out Crush via the NUR with nix-shell:
# Add the NUR channel.
nix-channel --add https://github.com/nix-community/NUR/archive/main.tar.gz nur
nix-channel --update
# Get Crush in a Nix shell.
nix-shell -p '(import <nur> { pkgs = import <nixpkgs> {}; }).repos.charmbracelet.crush'Crush provides NixOS and Home Manager modules via NUR. You can use these modules directly in your flake by importing them from NUR. Since it auto detects whether its a home manager or nixos context you can use the import the exact same way :)
{
inputs = {
nixpkgs.url = "github:NixOS/nixpkgs/nixos-unstable";
nur.url = "github:nix-community/NUR";
};
outputs = { self, nixpkgs, nur, ... }: {
nixosConfigurations.your-hostname = nixpkgs.lib.nixosSystem {
system = "x86_64-linux";
modules = [
nur.modules.nixos.default
nur.repos.charmbracelet.modules.crush
{
programs.crush = {
enable = true;
settings = {
providers = {
openai = {
id = "openai";
name = "OpenAI";
base_url = "https://api.openai.com/v1";
type = "openai";
api_key = "sk-fake123456789abcdef...";
models = [
{
id = "gpt-4";
name = "GPT-4";
}
];
};
};
lsp = {
go = { command = "gopls"; enabled = true; };
nix = { command = "nil"; enabled = true; };
};
options = {
context_paths = [ "/etc/nixos/configuration.nix" ];
tui = { compact_mode = true; };
debug = false;
};
};
};
}
];
};
};
}Debian/Ubuntu
sudo mkdir -p /etc/apt/keyrings
curl -fsSL https://repo.charm.sh/apt/gpg.key | sudo gpg --dearmor -o /etc/apt/keyrings/charm.gpg
echo "deb [signed-by=/etc/apt/keyrings/charm.gpg] https://repo.charm.sh/apt/ * *" | sudo tee /etc/apt/sources.list.d/charm.list
sudo apt update && sudo apt install crushFedora/RHEL
echo '[charm]
name=Charm
baseurl=https://repo.charm.sh/yum/
enabled=1
gpgcheck=1
gpgkey=https://repo.charm.sh/yum/gpg.key' | sudo tee /etc/yum.repos.d/charm.repo
sudo yum install crushOr, download it:
- Packages are available in Debian and RPM formats
- Binaries are available for Linux, macOS, Windows, FreeBSD, OpenBSD, and NetBSD
Or just install it with Go:
go install github.com/charmbracelet/crush@latest
[!WARNING] Productivity may increase when using Crush and you may find yourself nerd sniped when first using the application. If the symptoms persist, join the Discord and nerd snipe the rest of us.
The quickest way to get started is to grab an API key for your preferred provider such as Anthropic, OpenAI, Groq, OpenRouter, or Vercel AI Gateway and just start Crush. You'll be prompted to enter your API key.
That said, you can also set environment variables for preferred providers.
| Environment Variable | Provider |
|---|---|
ANTHROPIC_API_KEY |
Anthropic |
OPENAI_API_KEY |
OpenAI |
VERCEL_API_KEY |
Vercel AI Gateway |
GEMINI_API_KEY |
Google Gemini |
SYNTHETIC_API_KEY |
Synthetic |
ZAI_API_KEY |
Z.ai |
MINIMAX_API_KEY |
MiniMax |
HF_TOKEN |
Hugging Face Inference |
CEREBRAS_API_KEY |
Cerebras |
OPENROUTER_API_KEY |
OpenRouter |
IONET_API_KEY |
io.net |
GROQ_API_KEY |
Groq |
VERTEXAI_PROJECT |
Google Cloud VertexAI (Gemini) |
VERTEXAI_LOCATION |
Google Cloud VertexAI (Gemini) |
AWS_ACCESS_KEY_ID |
Amazon Bedrock (Claude) |
AWS_SECRET_ACCESS_KEY |
Amazon Bedrock (Claude) |
AWS_REGION |
Amazon Bedrock (Claude) |
AWS_PROFILE |
Amazon Bedrock (Custom Profile) |
AWS_BEARER_TOKEN_BEDROCK |
Amazon Bedrock |
AZURE_OPENAI_API_ENDPOINT |
Azure OpenAI models |
AZURE_OPENAI_API_KEY |
Azure OpenAI models (optional when using Entra ID) |
AZURE_OPENAI_API_VERSION |
Azure OpenAI models |
If you prefer subscription-based usage, here are some plans that work well in Crush:
Is there a provider you’d like to see in Crush? Is there an existing model that needs an update?
Crush’s default model listing is managed in Catwalk, a community-supported, open source repository of Crush-compatible models, and you’re welcome to contribute.
Crush runs great with no configuration. That said, if you do need or want to customize Crush, configuration can be added either local to the project itself, or globally, with the following priority:
.crush.jsoncrush.json$HOME/.config/crush/crush.json
Configuration itself is stored as a JSON object:
{
"this-setting": { "this": "that" },
"that-setting": ["ceci", "cela"]
}As an additional note, Crush also stores ephemeral data, such as application state, in one additional location:
# Unix
$HOME/.local/share/crush/crush.json
# Windows
%LOCALAPPDATA%\crush\crush.json[!TIP] You can override the user and data config locations by setting:
CRUSH_GLOBAL_CONFIGCRUSH_GLOBAL_DATA
Crush can use LSPs for additional context to help inform its decisions, just like you would. LSPs can be added manually like so:
{
"$schema": "https://charm.land/crush.json",
"lsp": {
"go": {
"command": "gopls",
"env": {
"GOTOOLCHAIN": "go1.24.5"
}
},
"typescript": {
"command": "typescript-language-server",
"args": ["--stdio"]
},
"nix": {
"command": "nil"
}
}
}Crush also supports Model Context Protocol (MCP) servers through three
transport types: stdio for command-line servers, http for HTTP endpoints,
and sse for Server-Sent Events. Environment variable expansion is supported
using $(echo $VAR) syntax.
{
"$schema": "https://charm.land/crush.json",
"mcp": {
"filesystem": {
"type": "stdio",
"command": "node",
"args": ["/path/to/mcp-server.js"],
"timeout": 120,
"disabled": false,
"disabled_tools": ["some-tool-name"],
"env": {
"NODE_ENV": "production"
}
},
"github": {
"type": "http",
"url": "https://api.githubcopilot.com/mcp/",
"timeout": 120,
"disabled": false,
"disabled_tools": ["create_issue", "create_pull_request"],
"headers": {
"Authorization": "Bearer $GH_PAT"
}
},
"streaming-service": {
"type": "sse",
"url": "https://example.com/mcp/sse",
"timeout": 120,
"disabled": false,
"headers": {
"API-Key": "$(echo $API_KEY)"
}
}
}
}Crush respects .gitignore files by default, but you can also create a
.crushignore file to specify additional files and directories that Crush
should ignore. This is useful for excluding files that you want in version
control but don't want Crush to consider when providing context.
The .crushignore file uses the same syntax as .gitignore and can be placed
in the root of your project or in subdirectories.
By default, Crush will ask you for permission before running tool calls. If you'd like, you can allow tools to be executed without prompting you for permissions. Use this with care.
{
"$schema": "https://charm.land/crush.json",
"permissions": {
"allowed_tools": [
"view",
"ls",
"grep",
"edit",
"mcp_context7_get-library-doc"
]
}
}You can also skip all permission prompts entirely by running Crush with the
--yolo flag. Be very, very careful with this feature.
If you'd like to prevent Crush from using certain built-in tools entirely, you
can disable them via the options.disabled_tools list. Disabled tools are
completely hidden from the agent.
{
"$schema": "https://charm.land/crush.json",
"options": {
"disabled_tools": [
"bash",
"sourcegraph"
]
}
}To disable tools from MCP servers, see the MCP config section.
Crush supports the Agent Skills open standard for
extending agent capabilities with reusable skill packages. Skills are folders
containing a SKILL.md file with instructions that Crush can discover and
activate on demand.
Skills are discovered from:
-
~/.config/crush/skills/on Unix (default, can be overridden withCRUSH_SKILLS_DIR) -
%LOCALAPPDATA%\crush\skills\on Windows (default, can be overridden withCRUSH_SKILLS_DIR) - Additional paths configured via
options.skills_paths
You can get started with example skills from anthropics/skills:
# Unix
mkdir -p ~/.config/crush/skills
cd ~/.config/crush/skills
git clone https://github.com/anthropics/skills.git _temp
mv _temp/skills/* . && rm -rf _temp# Windows (PowerShell)
mkdir -Force "$env:LOCALAPPDATA\crush\skills"
cd "$env:LOCALAPPDATA\crush\skills"
git clone https://github.com/anthropics/skills.git _temp
mv _temp/skills/* . ; rm -r -force _tempWhen you initialize a project, Crush analyzes your codebase and creates
a context file that helps it work more effectively in future sessions.
By default, this file is named AGENTS.md, but you can customize the
name and location with the initialize_as option:
{
"$schema": "https://charm.land/crush.json",
"options": {
"initialize_as": "AGENTS.md"
}
}This is useful if you prefer a different naming convention or want to
place the file in a specific directory (e.g., CRUSH.md or
docs/LLMs.md). Crush will fill the file with project-specific context
like build commands, code patterns, and conventions it discovered during
initialization.
By default, Crush adds attribution information to Git commits and pull requests
it creates. You can customize this behavior with the attribution option:
{
"$schema": "https://charm.land/crush.json",
"options": {
"attribution": {
"trailer_style": "co-authored-by",
"generated_with": true
}
}
}-
trailer_style: Controls the attribution trailer added to commit messages (default:assisted-by)-
assisted-by: AddsAssisted-by: [Model Name] via Crush <[email protected]>(includes the model name) -
co-authored-by: AddsCo-Authored-By: Crush <[email protected]> -
none: No attribution trailer
-
-
generated_with: When true (default), adds💘 Generated with Crushline to commit messages and PR descriptions
Crush supports custom provider configurations for both OpenAI-compatible and Anthropic-compatible APIs.
[!NOTE] Note that we support two "types" for OpenAI. Make sure to choose the right one to ensure the best experience!
openaishould be used when proxying or routing requests through OpenAI.openai-compatshould be used when using non-OpenAI providers that have OpenAI-compatible APIs.
Here’s an example configuration for Deepseek, which uses an OpenAI-compatible
API. Don't forget to set DEEPSEEK_API_KEY in your environment.
{
"$schema": "https://charm.land/crush.json",
"providers": {
"deepseek": {
"type": "openai-compat",
"base_url": "https://api.deepseek.com/v1",
"api_key": "$DEEPSEEK_API_KEY",
"models": [
{
"id": "deepseek-chat",
"name": "Deepseek V3",
"cost_per_1m_in": 0.27,
"cost_per_1m_out": 1.1,
"cost_per_1m_in_cached": 0.07,
"cost_per_1m_out_cached": 1.1,
"context_window": 64000,
"default_max_tokens": 5000
}
]
}
}
}Custom Anthropic-compatible providers follow this format:
{
"$schema": "https://charm.land/crush.json",
"providers": {
"custom-anthropic": {
"type": "anthropic",
"base_url": "https://api.anthropic.com/v1",
"api_key": "$ANTHROPIC_API_KEY",
"extra_headers": {
"anthropic-version": "2023-06-01"
},
"models": [
{
"id": "claude-sonnet-4-20250514",
"name": "Claude Sonnet 4",
"cost_per_1m_in": 3,
"cost_per_1m_out": 15,
"cost_per_1m_in_cached": 3.75,
"cost_per_1m_out_cached": 0.3,
"context_window": 200000,
"default_max_tokens": 50000,
"can_reason": true,
"supports_attachments": true
}
]
}
}
}Crush currently supports running Anthropic models through Bedrock, with caching disabled.
- A Bedrock provider will appear once you have AWS configured, i.e.
aws configure - Crush also expects the
AWS_REGIONorAWS_DEFAULT_REGIONto be set - To use a specific AWS profile set
AWS_PROFILEin your environment, i.e.AWS_PROFILE=myprofile crush - Alternatively to
aws configure, you can also just setAWS_BEARER_TOKEN_BEDROCK
Vertex AI will appear in the list of available providers when VERTEXAI_PROJECT and VERTEXAI_LOCATION are set. You will also need to be authenticated:
gcloud auth application-default loginTo add specific models to the configuration, configure as such:
{
"$schema": "https://charm.land/crush.json",
"providers": {
"vertexai": {
"models": [
{
"id": "claude-sonnet-4@20250514",
"name": "VertexAI Sonnet 4",
"cost_per_1m_in": 3,
"cost_per_1m_out": 15,
"cost_per_1m_in_cached": 3.75,
"cost_per_1m_out_cached": 0.3,
"context_window": 200000,
"default_max_tokens": 50000,
"can_reason": true,
"supports_attachments": true
}
]
}
}
}Local models can also be configured via OpenAI-compatible API. Here are two common examples:
{
"providers": {
"ollama": {
"name": "Ollama",
"base_url": "http://localhost:11434/v1/",
"type": "openai-compat",
"models": [
{
"name": "Qwen 3 30B",
"id": "qwen3:30b",
"context_window": 256000,
"default_max_tokens": 20000
}
]
}
}
}{
"providers": {
"lmstudio": {
"name": "LM Studio",
"base_url": "http://localhost:1234/v1/",
"type": "openai-compat",
"models": [
{
"name": "Qwen 3 30B",
"id": "qwen/qwen3-30b-a3b-2507",
"context_window": 256000,
"default_max_tokens": 20000
}
]
}
}
}Sometimes you need to look at logs. Luckily, Crush logs all sorts of
stuff. Logs are stored in ./.crush/logs/crush.log relative to the project.
The CLI also contains some helper commands to make perusing recent logs easier:
# Print the last 1000 lines
crush logs
# Print the last 500 lines
crush logs --tail 500
# Follow logs in real time
crush logs --followWant more logging? Run crush with the --debug flag, or enable it in the
config:
{
"$schema": "https://charm.land/crush.json",
"options": {
"debug": true,
"debug_lsp": true
}
}By default, Crush automatically checks for the latest and greatest list of providers and models from Catwalk, the open source Crush provider database. This means that when new providers and models are available, or when model metadata changes, Crush automatically updates your local configuration.
For those with restricted internet access, or those who prefer to work in air-gapped environments, this might not be want you want, and this feature can be disabled.
To disable automatic provider updates, set disable_provider_auto_update into
your crush.json config:
{
"$schema": "https://charm.land/crush.json",
"options": {
"disable_provider_auto_update": true
}
}Or set the CRUSH_DISABLE_PROVIDER_AUTO_UPDATE environment variable:
export CRUSH_DISABLE_PROVIDER_AUTO_UPDATE=1Manually updating providers is possible with the crush update-providers
command:
# Update providers remotely from Catwalk.
crush update-providers
# Update providers from a custom Catwalk base URL.
crush update-providers https://example.com/
# Update providers from a local file.
crush update-providers /path/to/local-providers.json
# Reset providers to the embedded version, embedded at crush at build time.
crush update-providers embedded
# For more info:
crush update-providers --helpCrush records pseudonymous usage metrics (tied to a device-specific hash), which maintainers rely on to inform development and support priorities. The metrics include solely usage metadata; prompts and responses are NEVER collected.
Details on exactly what’s collected are in the source code (here and here).
You can opt out of metrics collection at any time by setting the environment variable by setting the following in your environment:
export CRUSH_DISABLE_METRICS=1Or by setting the following in your config:
{
"options": {
"disable_metrics": true
}
}Crush also respects the DO_NOT_TRACK convention which can be enabled via
export DO_NOT_TRACK=1.
See the contributing guide.
We’d love to hear your thoughts on this project. Need help? We gotchu. You can find us on:
Part of Charm.

Charm热爱开源 • Charm loves open source
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for crush
Similar Open Source Tools
crush
Crush is a versatile tool designed to enhance coding workflows in your terminal. It offers support for multiple LLMs, allows for flexible switching between models, and enables session-based work management. Crush is extensible through MCPs and works across various operating systems. It can be installed using package managers like Homebrew and NPM, or downloaded directly. Crush supports various APIs like Anthropic, OpenAI, Groq, and Google Gemini, and allows for customization through environment variables. The tool can be configured locally or globally, and supports LSPs for additional context. Crush also provides options for ignoring files, allowing tools, and configuring local models. It respects `.gitignore` files and offers logging capabilities for troubleshooting and debugging.
mcp-server-odoo
The MCP Server for Odoo is a tool that enables AI assistants like Claude to interact with Odoo ERP systems. Users can access business data, search records, create new entries, update existing data, and manage their Odoo instance through natural language. The server works with any Odoo instance and offers features like search and retrieve, create new records, update existing data, delete records, browse multiple records, count records, inspect model fields, secure access, smart pagination, LLM-optimized output, and YOLO Mode for quick access. Installation and configuration instructions are provided for different environments, along with troubleshooting tips. The tool supports various tasks such as searching and retrieving records, creating and managing records, listing models, updating records, deleting records, and accessing Odoo data through resource URIs.
vim-ai
vim-ai is a plugin that adds Artificial Intelligence (AI) capabilities to Vim and Neovim. It allows users to generate code, edit text, and have interactive conversations with GPT models powered by OpenAI's API. The plugin uses OpenAI's API to generate responses, requiring users to set up an account and obtain an API key. It supports various commands for text generation, editing, and chat interactions, providing a seamless integration of AI features into the Vim text editor environment.

ruby-openai
Use the OpenAI API with Ruby! 🤖🩵 Stream text with GPT-4, transcribe and translate audio with Whisper, or create images with DALL·E... Hire me | 🎮 Ruby AI Builders Discord | 🐦 Twitter | 🧠 Anthropic Gem | 🚂 Midjourney Gem ## Table of Contents * Ruby OpenAI * Table of Contents * Installation * Bundler * Gem install * Usage * Quickstart * With Config * Custom timeout or base URI * Extra Headers per Client * Logging * Errors * Faraday middleware * Azure * Ollama * Counting Tokens * Models * Examples * Chat * Streaming Chat * Vision * JSON Mode * Functions * Edits * Embeddings * Batches * Files * Finetunes * Assistants * Threads and Messages * Runs * Runs involving function tools * Image Generation * DALL·E 2 * DALL·E 3 * Image Edit * Image Variations * Moderations * Whisper * Translate * Transcribe * Speech * Errors * Development * Release * Contributing * License * Code of Conduct

openmacro
Openmacro is a multimodal personal agent that allows users to run code locally. It acts as a personal agent capable of completing and automating tasks autonomously via self-prompting. The tool provides a CLI natural-language interface for completing and automating tasks, analyzing and plotting data, browsing the web, and manipulating files. Currently, it supports API keys for models powered by SambaNova, with plans to add support for other hosts like OpenAI and Anthropic in future versions.
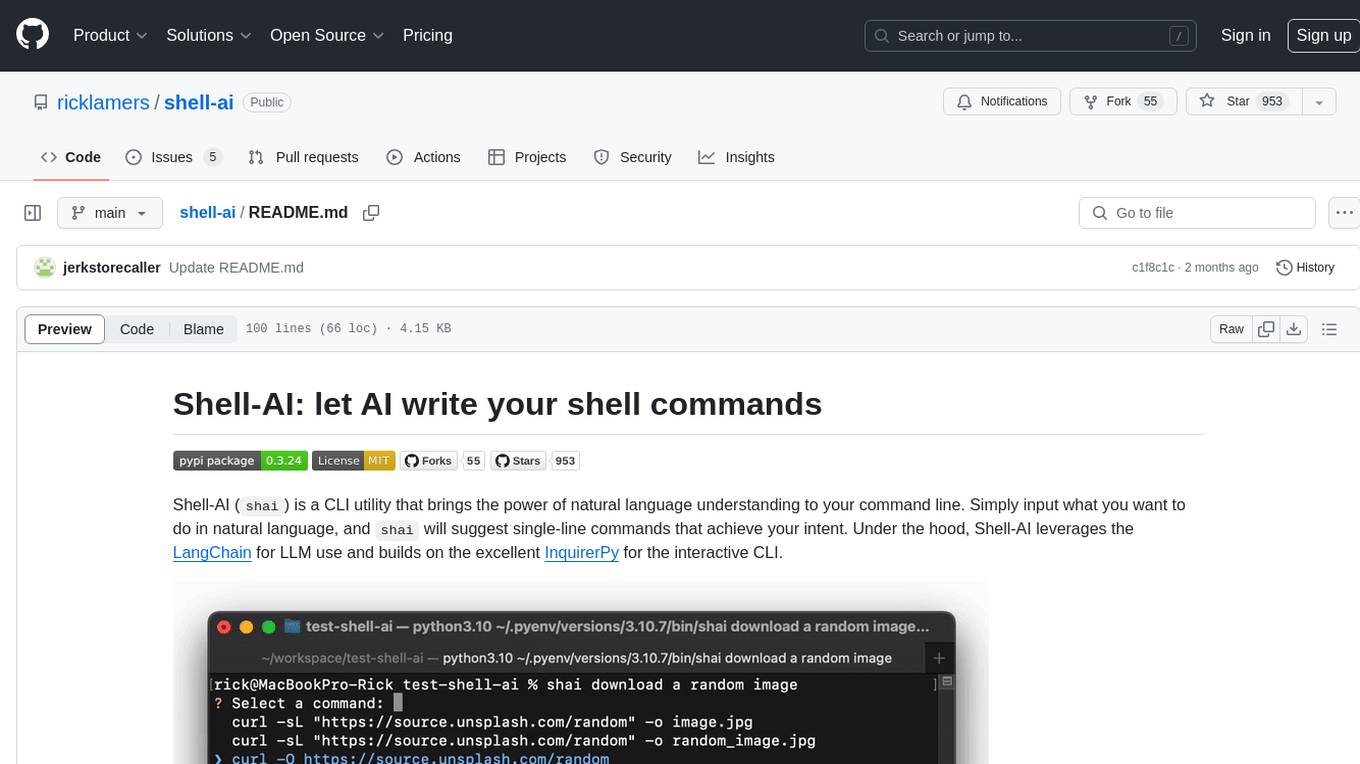
shell-ai
Shell-AI (`shai`) is a CLI utility that enables users to input commands in natural language and receive single-line command suggestions. It leverages natural language understanding and interactive CLI tools to enhance command line interactions. Users can describe tasks in plain English and receive corresponding command suggestions, making it easier to execute commands efficiently. Shell-AI supports cross-platform usage and is compatible with Azure OpenAI deployments, offering a user-friendly and efficient way to interact with the command line.

clawlet
Clawlet is an ultra-lightweight and efficient personal AI assistant that comes as a single binary with no CGO, runtime, or dependencies. It features hybrid semantic memory search and is inspired by OpenClaw and nanobot. Users can easily download Clawlet from GitHub Releases and drop it on any machine to enable memory search functionality. The tool supports various LLM providers like OpenAI, OpenRouter, Anthropic, Gemini, and local endpoints. Users can configure Clawlet for memory search setup and chat app integrations for platforms like Telegram, WhatsApp, Discord, and Slack. Clawlet CLI provides commands for initializing workspace, running the agent, managing channels, scheduling jobs, and more.

LocalAGI
LocalAGI is a powerful, self-hostable AI Agent platform that allows you to design AI automations without writing code. It provides a complete drop-in replacement for OpenAI's Responses APIs with advanced agentic capabilities. With LocalAGI, you can create customizable AI assistants, automations, chat bots, and agents that run 100% locally, without the need for cloud services or API keys. The platform offers features like no-code agents, web-based interface, advanced agent teaming, connectors for various platforms, comprehensive REST API, short & long-term memory capabilities, planning & reasoning, periodic tasks scheduling, memory management, multimodal support, extensible custom actions, fully customizable models, observability, and more.
typst-mcp
Typst MCP Server is an implementation of the Model Context Protocol (MCP) that facilitates interaction between AI models and Typst, a markup-based typesetting system. The server offers tools for converting between LaTeX and Typst, validating Typst syntax, and generating images from Typst code. It provides functions such as listing documentation chapters, retrieving specific chapters, converting LaTeX snippets to Typst, validating Typst syntax, and rendering Typst code to images. The server is designed to assist Language Model Managers (LLMs) in handling Typst-related tasks efficiently and accurately.

promptic
Promptic is a tool designed for LLM app development, providing a productive and pythonic way to build LLM applications. It leverages LiteLLM, allowing flexibility to switch LLM providers easily. Promptic focuses on building features by providing type-safe structured outputs, easy-to-build agents, streaming support, automatic prompt caching, and built-in conversation memory.
AICentral
AI Central is a powerful tool designed to take control of your AI services with minimal overhead. It is built on Asp.Net Core and dotnet 8, offering fast web-server performance. The tool enables advanced Azure APIm scenarios, PII stripping logging to Cosmos DB, token metrics through Open Telemetry, and intelligent routing features. AI Central supports various endpoint selection strategies, proxying asynchronous requests, custom OAuth2 authorization, circuit breakers, rate limiting, and extensibility through plugins. It provides an extensibility model for easy plugin development and offers enriched telemetry and logging capabilities for monitoring and insights.

firecrawl
Firecrawl is an API service that takes a URL, crawls it, and converts it into clean markdown. It crawls all accessible subpages and provides clean markdown for each, without requiring a sitemap. The API is easy to use and can be self-hosted. It also integrates with Langchain and Llama Index. The Python SDK makes it easy to crawl and scrape websites in Python code.
sonarqube-mcp-server
The SonarQube MCP Server is a Model Context Protocol (MCP) server that enables seamless integration with SonarQube Server or Cloud for code quality and security. It supports the analysis of code snippets directly within the agent context. The server provides various tools for analyzing code, managing issues, accessing metrics, and interacting with SonarQube projects. It also supports advanced features like dependency risk analysis, enterprise portfolio management, and system health checks. The server can be configured for different transport modes, proxy settings, and custom certificates. Telemetry data collection can be disabled if needed.
firecrawl-mcp-server
Firecrawl MCP Server is a Model Context Protocol (MCP) server implementation that integrates with Firecrawl for web scraping capabilities. It offers features such as web scraping, crawling, and discovery, search and content extraction, deep research and batch scraping, automatic retries and rate limiting, cloud and self-hosted support, and SSE support. The server can be configured to run with various tools like Cursor, Windsurf, SSE Local Mode, Smithery, and VS Code. It supports environment variables for cloud API and optional configurations for retry settings and credit usage monitoring. The server includes tools for scraping, batch scraping, mapping, searching, crawling, and extracting structured data from web pages. It provides detailed logging and error handling functionalities for robust performance.

ollama-ex
Ollama is a powerful tool for running large language models locally or on your own infrastructure. It provides a full implementation of the Ollama API, support for streaming requests, and tool use capability. Users can interact with Ollama in Elixir to generate completions, chat messages, and perform streaming requests. The tool also supports function calling on compatible models, allowing users to define tools with clear descriptions and arguments. Ollama is designed to facilitate natural language processing tasks and enhance user interactions with language models.

For similar tasks
llama-coder
Llama Coder is a self-hosted Github Copilot replacement for VS Code that provides autocomplete using Ollama and Codellama. It works best with Mac M1/M2/M3 or RTX 4090, offering features like fast performance, no telemetry or tracking, and compatibility with any coding language. Users can install Ollama locally or on a dedicated machine for remote usage. The tool supports different models like stable-code and codellama with varying RAM/VRAM requirements, allowing users to optimize performance based on their hardware. Troubleshooting tips and a changelog are also provided for user convenience.
pearai-app
PearAI is an AI-powered code editor designed to enhance development by reducing the amount of coding required. It is a fork of VSCode and the main functionality lies within the 'extension/pearai' submodule. Users can contribute to the project by fixing issues, submitting bugs and feature requests, reviewing source code changes, and improving documentation. The tool aims to streamline the coding process and provide an efficient environment for developers to work in.
crush
Crush is a versatile tool designed to enhance coding workflows in your terminal. It offers support for multiple LLMs, allows for flexible switching between models, and enables session-based work management. Crush is extensible through MCPs and works across various operating systems. It can be installed using package managers like Homebrew and NPM, or downloaded directly. Crush supports various APIs like Anthropic, OpenAI, Groq, and Google Gemini, and allows for customization through environment variables. The tool can be configured locally or globally, and supports LSPs for additional context. Crush also provides options for ignoring files, allowing tools, and configuring local models. It respects `.gitignore` files and offers logging capabilities for troubleshooting and debugging.
llm-agents.nix
Nix packages for AI coding agents and development tools. Automatically updated daily. This repository provides a wide range of AI coding agents and tools that can be used in the terminal environment. The tools cover various functionalities such as code assistance, AI-powered development agents, CLI tools for AI coding, workflow and project management, code review, utilities like search tools and browser automation, and usage analytics for AI coding sessions. The repository also includes experimental features like sandboxed execution, provider abstraction, and tool composition to explore how Nix can enhance AI-powered development.
Kaku
Kaku is a fast and out-of-the-box terminal designed for AI coding. It is a deeply customized fork of WezTerm, offering polished defaults, built-in shell suite, Lua scripting, safe update flow, and a suite of CLI tools for immediate productivity. Kaku is fast, lightweight, and fully configurable via Lua scripts, providing a ready-to-work environment for coding enthusiasts.

LLM-Finetuning-Toolkit
LLM Finetuning toolkit is a config-based CLI tool for launching a series of LLM fine-tuning experiments on your data and gathering their results. It allows users to control all elements of a typical experimentation pipeline - prompts, open-source LLMs, optimization strategy, and LLM testing - through a single YAML configuration file. The toolkit supports basic, intermediate, and advanced usage scenarios, enabling users to run custom experiments, conduct ablation studies, and automate fine-tuning workflows. It provides features for data ingestion, model definition, training, inference, quality assurance, and artifact outputs, making it a comprehensive tool for fine-tuning large language models.
kaytu
Kaytu is an AI platform that enhances cloud efficiency by analyzing historical usage data and providing intelligent recommendations for optimizing instance sizes. Users can pay for only what they need without compromising the performance of their applications. The platform is easy to use with a one-line command, allows customization for specific requirements, and ensures security by extracting metrics from the client side. Kaytu is open-source and supports AWS services, with plans to expand to GCP, Azure, GPU optimization, and observability data from Prometheus in the future.

ReaLHF
ReaLHF is a distributed system designed for efficient RLHF training with Large Language Models (LLMs). It introduces a novel approach called parameter reallocation to dynamically redistribute LLM parameters across the cluster, optimizing allocations and parallelism for each computation workload. ReaL minimizes redundant communication while maximizing GPU utilization, achieving significantly higher Proximal Policy Optimization (PPO) training throughput compared to other systems. It supports large-scale training with various parallelism strategies and enables memory-efficient training with parameter and optimizer offloading. The system seamlessly integrates with HuggingFace checkpoints and inference frameworks, allowing for easy launching of local or distributed experiments. ReaLHF offers flexibility through versatile configuration customization and supports various RLHF algorithms, including DPO, PPO, RAFT, and more, while allowing the addition of custom algorithms for high efficiency.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.
{ "$schema": "https://charm.land/crush.json", "options": { "skills_paths": [ "~/.config/crush/skills", // Windows: "%LOCALAPPDATA%\\crush\\skills", "./project-skills" ] } }