
docker-h5ai
Lightweight h5ai 0.30.0 container with Nginx 1.21 & PHP 8 based on Alpine Linux.
Stars: 131
docker-h5ai is a Docker image that provides a modern file indexer for HTTP web servers, enhancing file browsing with different views, a breadcrumb, and a tree overview. It is built on Alpine Linux with Nginx and PHP, supporting h5ai 0.30.0 and enabling PHP 8 JIT compiler. The image supports multiple architectures and can be used to host shared files with customizable configurations. Users can set up authentication using htpasswd and run the image as a real-time service. It is recommended to use HTTPS for data encryption when deploying the service.
README:




I'd like to quote the official website.
h5ai is a modern file indexer for HTTP web servers with focus on your files. Directories are displayed in a appealing way and browsing them is enhanced by different views, a breadcrumb and a tree overview. Initially h5ai was an acronym for HTML5 Apache Index but now it supports other web servers too.
I hope this project would be useful for those who uses Docker for building their server.
I choose Alpine Linux as a base image to make it a light-weight service. And I do choose Nginx-Alpine to get the benefits from some tweaks of Nginx version.
So this is composed of,
- Alpine Linux 3.19
- Nginx 1.27.0
- PHP 8.2.20
with,
- h5ai 0.30.0
And to gather all of these into one together I use supervisor that manages all of these processes.
 h5ai supports extensional functions such as showing thumnails of audio and video, caching for better speed, etc. This image activates all of those functions.
h5ai supports extensional functions such as showing thumnails of audio and video, caching for better speed, etc. This image activates all of those functions.
 JIT compiler that is introduced in PHP 8 is enabled by default.
JIT compiler that is introduced in PHP 8 is enabled by default.
It builds from Github Actions for supporting multiple architectures such as AMD64(x86_64) and ARM64, ARMv7, ARMv6.
So that you can use this on most computers supporting Docker.
First of all, it assumes that you have installed Docker on your system.
Pull the image from docker hub with the following command.
docker pull awesometic/h5aiThis is how it can be a service, in the other word, a container.
You can run it using the following command.
docker run -it --rm \
-p 80:80 \
-v /shared/dir:/h5ai \
-v /config/dir:/config \
-e PUID=$UID \
-e PGID=$GID \
-e TZ=Asia/Seoul \
awesometic/h5aiThe --rm option in the command is added to remove the executed container since this is an example usage.
Basically, two directories should be mapped to the host PC.
-
/h5ai: This will be where the shared files located. -
/config: This will be where stores configurations of h5ai and Nginx settings.
And you should set proper PUID and PGID. If those not set up, the default UID, GID, the number 911, will be used for the /config directory. Not setting PUID/PGID will not significantly affect its operations, but setting up the proper number is still recommended.
Or you can handle some directories that has special permissions using these PUID/PGID.
If you want to run this image as a daemon, use -d option. See the following command.
docker run -d --name=h5ai \
-p 80:80 \
-v /shared/dir:/h5ai \
-v /config/dir:/config \
-e PUID=$UID \
-e PGID=$GID \
-e TZ=Asia/Seoul \
awesometic/h5aiIf you want to run this image permanently, so to speak, to keep it runs after rebooting the server, you can use --restart unless-stopped option. See the following command.
docker run -d --name=h5ai \
-p 80:80 \
-v /shared/dir:/h5ai \
-v /config/dir:/config \
-e PUID=$UID \
-e PGID=$GID \
-e TZ=Asia/Seoul \
--restart unless-stopped \
awesometic/h5aiIf you want to login when visiting the hosted h5ai website so that implement protection from accessing anonymous users, add HTPASSWD environments like the below.
docker run -it --name=h5ai \
-p 80:80 \
-v /shared/dir:/h5ai \
-v /config/dir:/config \
-e PUID=$UID \
-e PGID=$GID \
-e TZ=Asia/Seoul \
-e HTPASSWD=true \
-e HTPASSWD_USER=awesometic \
awesometic/h5aiThen only the user set by HTPASSWD_USER, awesometic can access this h5ai website with these options.
Be aware of that the HTPASSWD environment variable must be true for authentication.
And aware of this too that you have to run in interaction mode by adding -it to set a password for the newly created user for the first time.
Or, you can set the password for Htpasswd by passing an environment variable. In this case, you shouldn't have to use -it option because it is not needed at all.
Consequently, if you want to run this image as a real-time service, check the following command.
docker run -d --name=h5ai \
-p 80:80 \
-v /shared/dir:/h5ai \
-v /config/dir:/config \
-e PUID=$UID \
-e PGID=$GID \
-e TZ=Asia/Seoul \
-e HTPASSWD=true \
-e HTPASSWD_USER=awesometic \
-e HTPASSWD_PW=awesometic \
--restart unless-stopped \
awesometic/h5aiTo do the test drive, when the container runs then just let your browser browses:
http://localhost/ After all, you can see the directories you shared.
After all, you can see the directories you shared.
If the new h5ai version releases, I overwrite all the updated files to the corresponded directories on the project folder. In this sequence, some customized files by you will be replaced into the new one.
So it is highly recommended to make back up files of your edits before update the Docker image.
To prevent an unexpected accident, I put minimal protection into my init.sh script. This checks if the current private/conf/options.json file is outdated from the current about to be run. If the current options.json is older than the newly loaded one, the script makes its backup file under the /config directory. See the followings.
awesometic@awesometic-nas:docker/h5ai $ ll
total 32K
-rwxr-xr-x 1 root root 12K Jul 10 2019 20190710_165345_options.json.bak
-rwxr-xr-x 1 root root 12K Feb 3 14:46 20210203_144624_options.json.bak
drwxr-xr-x 3 root root 4.0K Feb 3 14:46 h5ai
drwxr-xr-x 2 root root 4.0K Dec 14 2018 nginxBut since I don't know how much the users edit their h5ai files like layout or style, it won't make backups for all of the h5ai related files. So it depends on your caution.
If you have any good idea, please let me know. 😀
It is highly recommended to use this web service with HTTPS for data encryption. Without SSL, the attackers can see your data streams even if you set the htpasswd to authenticate to the web page.
In this image, it is not provide any HTTPS related settings but you can set HTTPS with another web server. The most frequently used thing for HTTPS is a reverse proxy server, which can be set easiliy with a docker image called SWAG from LinuxServer.io.
- [x] Easy access to options.json
- [x] Access permission using htpasswd
- [x] Setup PUID/PGID to better handle the permissions
- [ ] Expose Nginx, PHP log files to the host
This project comes with MIT license. Please see the license file.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for docker-h5ai
Similar Open Source Tools
docker-h5ai
docker-h5ai is a Docker image that provides a modern file indexer for HTTP web servers, enhancing file browsing with different views, a breadcrumb, and a tree overview. It is built on Alpine Linux with Nginx and PHP, supporting h5ai 0.30.0 and enabling PHP 8 JIT compiler. The image supports multiple architectures and can be used to host shared files with customizable configurations. Users can set up authentication using htpasswd and run the image as a real-time service. It is recommended to use HTTPS for data encryption when deploying the service.

llamafile
llamafile is a tool that enables users to distribute and run Large Language Models (LLMs) with a single file. It combines llama.cpp with Cosmopolitan Libc to create a framework that simplifies the complexity of LLMs into a single-file executable called a 'llamafile'. Users can run these executable files locally on most computers without the need for installation, making open LLMs more accessible to developers and end users. llamafile also provides example llamafiles for various LLM models, allowing users to try out different LLMs locally. The tool supports multiple CPU microarchitectures, CPU architectures, and operating systems, making it versatile and easy to use.
qrev
QRev is an open-source alternative to Salesforce, offering AI agents to scale sales organizations infinitely. It aims to provide digital workers for various sales roles or a superagent named Qai. The tech stack includes TypeScript for frontend, NodeJS for backend, MongoDB for app server database, ChromaDB for vector database, SQLite for AI server SQL relational database, and Langchain for LLM tooling. The tool allows users to run client app, app server, and AI server components. It requires Node.js and MongoDB to be installed, and provides detailed setup instructions in the README file.
SeaGOAT
SeaGOAT is a local search tool that leverages vector embeddings to enable you to search your codebase semantically. It is designed to work on Linux, macOS, and Windows and can process files in various formats, including text, Markdown, Python, C, C++, TypeScript, JavaScript, HTML, Go, Java, PHP, and Ruby. SeaGOAT uses a vector database called ChromaDB and a local vector embedding engine to provide fast and accurate search results. It also supports regular expression/keyword-based matches. SeaGOAT is open-source and licensed under an open-source license, and users are welcome to examine the source code, raise concerns, or create pull requests to fix problems.

torchchat
torchchat is a codebase showcasing the ability to run large language models (LLMs) seamlessly. It allows running LLMs using Python in various environments such as desktop, server, iOS, and Android. The tool supports running models via PyTorch, chatting, generating text, running chat in the browser, and running models on desktop/server without Python. It also provides features like AOT Inductor for faster execution, running in C++ using the runner, and deploying and running on iOS and Android. The tool supports popular hardware and OS including Linux, Mac OS, Android, and iOS, with various data types and execution modes available.

airbyte_serverless
AirbyteServerless is a lightweight tool designed to simplify the management of Airbyte connectors. It offers a serverless mode for running connectors, allowing users to easily move data from any source to their data warehouse. Unlike the full Airbyte-Open-Source-Platform, AirbyteServerless focuses solely on the Extract-Load process without a UI, database, or transform layer. It provides a CLI tool, 'abs', for managing connectors, creating connections, running jobs, selecting specific data streams, handling secrets securely, and scheduling remote runs. The tool is scalable, allowing independent deployment of multiple connectors. It aims to streamline the connector management process and provide a more agile alternative to the comprehensive Airbyte platform.
robocorp
Robocorp is a platform that allows users to create, deploy, and operate Python automations and AI actions. It provides an easy way to extend the capabilities of AI agents, assistants, and copilots with custom actions written in Python. Users can create and deploy tools, skills, loaders, and plugins that securely connect any AI Assistant platform to their data and applications. The Robocorp Action Server makes Python scripts compatible with ChatGPT and LangChain by automatically creating and exposing an API based on function declaration, type hints, and docstrings. It simplifies the process of developing and deploying AI actions, enabling users to interact with AI frameworks effortlessly.
actions
Sema4.ai Action Server is a tool that allows users to build semantic actions in Python to connect AI agents with real-world applications. It enables users to create custom actions, skills, loaders, and plugins that securely connect any AI Assistant platform to data and applications. The tool automatically creates and exposes an API based on function declaration, type hints, and docstrings by adding '@action' to Python scripts. It provides an end-to-end stack supporting various connections between AI and user's apps and data, offering ease of use, security, and scalability.
CLI
Bito CLI provides a command line interface to the Bito AI chat functionality, allowing users to interact with the AI through commands. It supports complex automation and workflows, with features like long prompts and slash commands. Users can install Bito CLI on Mac, Linux, and Windows systems using various methods. The tool also offers configuration options for AI model type, access key management, and output language customization. Bito CLI is designed to enhance user experience in querying AI models and automating tasks through the command line interface.

WindowsAgentArena
Windows Agent Arena (WAA) is a scalable Windows AI agent platform designed for testing and benchmarking multi-modal, desktop AI agents. It provides researchers and developers with a reproducible and realistic Windows OS environment for AI research, enabling testing of agentic AI workflows across various tasks. WAA supports deploying agents at scale using Azure ML cloud infrastructure, allowing parallel running of multiple agents and delivering quick benchmark results for hundreds of tasks in minutes.

aider-composer
Aider Composer is a VSCode extension that integrates Aider into your development workflow. It allows users to easily add and remove files, toggle between read-only and editable modes, review code changes, use different chat modes, and reference files in the chat. The extension supports multiple models, code generation, code snippets, and settings customization. It has limitations such as lack of support for multiple workspaces, Git repository features, linting, testing, voice features, in-chat commands, and configuration options.
openui
OpenUI is a tool designed to simplify the process of building UI components by allowing users to describe UI using their imagination and see it rendered live. It supports converting HTML to React, Svelte, Web Components, etc. The tool is open source and aims to make UI development fun, fast, and flexible. It integrates with various AI services like OpenAI, Groq, Gemini, Anthropic, Cohere, and Mistral, providing users with the flexibility to use different models. OpenUI also supports LiteLLM for connecting to various LLM services and allows users to create custom proxy configs. The tool can be run locally using Docker or Python, and it offers a development environment for quick setup and testing.
unsight.dev
unsight.dev is a tool built on Nuxt that helps detect duplicate GitHub issues and areas of concern across related repositories. It utilizes Nitro server API routes, GitHub API, and a GitHub App, along with UnoCSS. The tool is deployed on Cloudflare with NuxtHub, using Workers AI, Workers KV, and Vectorize. It also offers a browser extension soon to be released. Users can try the app locally for tweaking the UI and setting up a full development environment as a GitHub App.
aiyabot
AIYA is a Discord bot interface for Stable Diffusion, offering features like live preview, negative prompts, model swapping, image generation, image captioning, image resizing, and more. It supports various options and bonus features to enhance user experience. Users can set per-channel defaults, view stats, manage queues, upscale images, and perform various commands on images. AIYA requires setup with AUTOMATIC1111's Stable Diffusion AI Web UI or SD.Next, and can be deployed using Docker with additional configuration options. Credits go to AUTOMATIC1111, vladmandic, harubaru, and various contributors for their contributions to AIYA's development.
ai-town
AI Town is a virtual town where AI characters live, chat, and socialize. This project provides a deployable starter kit for building and customizing your own version of AI Town. It features a game engine, database, vector search, auth, text model, deployment, pixel art generation, background music generation, and local inference. You can customize your own simulation by creating characters and stories, updating spritesheets, changing the background, and modifying the background music.

fasttrackml
FastTrackML is an experiment tracking server focused on speed and scalability, fully compatible with MLFlow. It provides a user-friendly interface to track and visualize your machine learning experiments, making it easy to compare different models and identify the best performing ones. FastTrackML is open source and can be easily installed and run with pip or Docker. It is also compatible with the MLFlow Python package, making it easy to integrate with your existing MLFlow workflows.
For similar tasks

LLM-Finetuning-Toolkit
LLM Finetuning toolkit is a config-based CLI tool for launching a series of LLM fine-tuning experiments on your data and gathering their results. It allows users to control all elements of a typical experimentation pipeline - prompts, open-source LLMs, optimization strategy, and LLM testing - through a single YAML configuration file. The toolkit supports basic, intermediate, and advanced usage scenarios, enabling users to run custom experiments, conduct ablation studies, and automate fine-tuning workflows. It provides features for data ingestion, model definition, training, inference, quality assurance, and artifact outputs, making it a comprehensive tool for fine-tuning large language models.
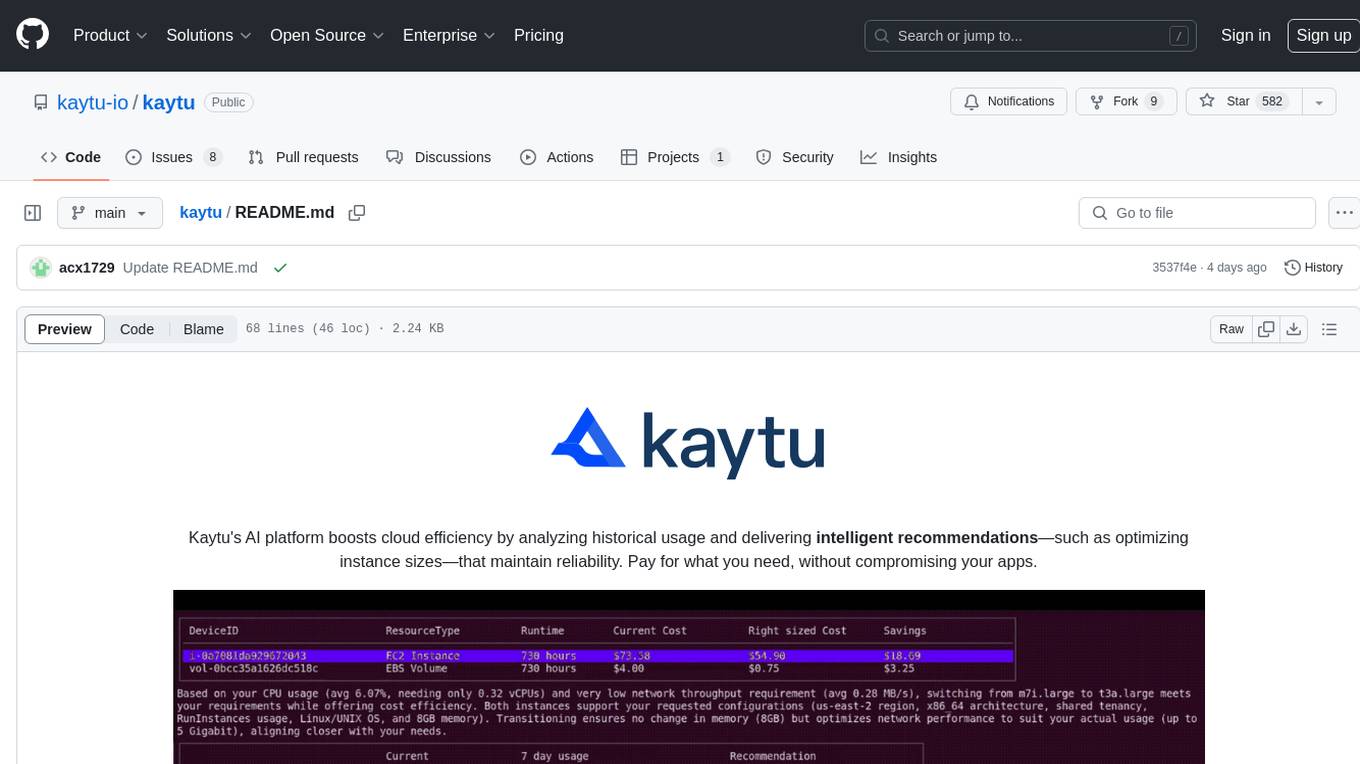
kaytu
Kaytu is an AI platform that enhances cloud efficiency by analyzing historical usage data and providing intelligent recommendations for optimizing instance sizes. Users can pay for only what they need without compromising the performance of their applications. The platform is easy to use with a one-line command, allows customization for specific requirements, and ensures security by extracting metrics from the client side. Kaytu is open-source and supports AWS services, with plans to expand to GCP, Azure, GPU optimization, and observability data from Prometheus in the future.

ReaLHF
ReaLHF is a distributed system designed for efficient RLHF training with Large Language Models (LLMs). It introduces a novel approach called parameter reallocation to dynamically redistribute LLM parameters across the cluster, optimizing allocations and parallelism for each computation workload. ReaL minimizes redundant communication while maximizing GPU utilization, achieving significantly higher Proximal Policy Optimization (PPO) training throughput compared to other systems. It supports large-scale training with various parallelism strategies and enables memory-efficient training with parameter and optimizer offloading. The system seamlessly integrates with HuggingFace checkpoints and inference frameworks, allowing for easy launching of local or distributed experiments. ReaLHF offers flexibility through versatile configuration customization and supports various RLHF algorithms, including DPO, PPO, RAFT, and more, while allowing the addition of custom algorithms for high efficiency.
docker-h5ai
docker-h5ai is a Docker image that provides a modern file indexer for HTTP web servers, enhancing file browsing with different views, a breadcrumb, and a tree overview. It is built on Alpine Linux with Nginx and PHP, supporting h5ai 0.30.0 and enabling PHP 8 JIT compiler. The image supports multiple architectures and can be used to host shared files with customizable configurations. Users can set up authentication using htpasswd and run the image as a real-time service. It is recommended to use HTTPS for data encryption when deploying the service.

MEGREZ
MEGREZ is a modern and elegant open-source high-performance computing platform that efficiently manages GPU resources. It allows for easy container instance creation, supports multiple nodes/multiple GPUs, modern UI environment isolation, customizable performance configurations, and user data isolation. The platform also comes with pre-installed deep learning environments, supports multiple users, features a VSCode web version, resource performance monitoring dashboard, and Jupyter Notebook support.

crush
Crush is a versatile tool designed to enhance coding workflows in your terminal. It offers support for multiple LLMs, allows for flexible switching between models, and enables session-based work management. Crush is extensible through MCPs and works across various operating systems. It can be installed using package managers like Homebrew and NPM, or downloaded directly. Crush supports various APIs like Anthropic, OpenAI, Groq, and Google Gemini, and allows for customization through environment variables. The tool can be configured locally or globally, and supports LSPs for additional context. Crush also provides options for ignoring files, allowing tools, and configuring local models. It respects `.gitignore` files and offers logging capabilities for troubleshooting and debugging.

plexe
Plexe is a tool that allows users to create machine learning models by describing them in plain language. Users can explain their requirements, provide a dataset, and the AI-powered system will build a fully functional model through an automated agentic approach. It supports multiple AI agents and model building frameworks like XGBoost, CatBoost, and Keras. Plexe also provides Docker images with pre-configured environments, YAML configuration for customization, and support for multiple LiteLLM providers. Users can visualize experiment results using the built-in Streamlit dashboard and extend Plexe's functionality through custom integrations.
For similar jobs

AirGo
AirGo is a front and rear end separation, multi user, multi protocol proxy service management system, simple and easy to use. It supports vless, vmess, shadowsocks, and hysteria2.

mosec
Mosec is a high-performance and flexible model serving framework for building ML model-enabled backend and microservices. It bridges the gap between any machine learning models you just trained and the efficient online service API. * **Highly performant** : web layer and task coordination built with Rust 🦀, which offers blazing speed in addition to efficient CPU utilization powered by async I/O * **Ease of use** : user interface purely in Python 🐍, by which users can serve their models in an ML framework-agnostic manner using the same code as they do for offline testing * **Dynamic batching** : aggregate requests from different users for batched inference and distribute results back * **Pipelined stages** : spawn multiple processes for pipelined stages to handle CPU/GPU/IO mixed workloads * **Cloud friendly** : designed to run in the cloud, with the model warmup, graceful shutdown, and Prometheus monitoring metrics, easily managed by Kubernetes or any container orchestration systems * **Do one thing well** : focus on the online serving part, users can pay attention to the model optimization and business logic

llm-code-interpreter
The 'llm-code-interpreter' repository is a deprecated plugin that provides a code interpreter on steroids for ChatGPT by E2B. It gives ChatGPT access to a sandboxed cloud environment with capabilities like running any code, accessing Linux OS, installing programs, using filesystem, running processes, and accessing the internet. The plugin exposes commands to run shell commands, read files, and write files, enabling various possibilities such as running different languages, installing programs, starting servers, deploying websites, and more. It is powered by the E2B API and is designed for agents to freely experiment within a sandboxed environment.

pezzo
Pezzo is a fully cloud-native and open-source LLMOps platform that allows users to observe and monitor AI operations, troubleshoot issues, save costs and latency, collaborate, manage prompts, and deliver AI changes instantly. It supports various clients for prompt management, observability, and caching. Users can run the full Pezzo stack locally using Docker Compose, with prerequisites including Node.js 18+, Docker, and a GraphQL Language Feature Support VSCode Extension. Contributions are welcome, and the source code is available under the Apache 2.0 License.

learn-generative-ai
Learn Cloud Applied Generative AI Engineering (GenEng) is a course focusing on the application of generative AI technologies in various industries. The course covers topics such as the economic impact of generative AI, the role of developers in adopting and integrating generative AI technologies, and the future trends in generative AI. Students will learn about tools like OpenAI API, LangChain, and Pinecone, and how to build and deploy Large Language Models (LLMs) for different applications. The course also explores the convergence of generative AI with Web 3.0 and its potential implications for decentralized intelligence.

gcloud-aio
This repository contains shared codebase for two projects: gcloud-aio and gcloud-rest. gcloud-aio is built for Python 3's asyncio, while gcloud-rest is a threadsafe requests-based implementation. It provides clients for Google Cloud services like Auth, BigQuery, Datastore, KMS, PubSub, Storage, and Task Queue. Users can install the library using pip and refer to the documentation for usage details. Developers can contribute to the project by following the contribution guide.

fluid
Fluid is an open source Kubernetes-native Distributed Dataset Orchestrator and Accelerator for data-intensive applications, such as big data and AI applications. It implements dataset abstraction, scalable cache runtime, automated data operations, elasticity and scheduling, and is runtime platform agnostic. Key concepts include Dataset and Runtime. Prerequisites include Kubernetes version > 1.16, Golang 1.18+, and Helm 3. The tool offers features like accelerating remote file accessing, machine learning, accelerating PVC, preloading dataset, and on-the-fly dataset cache scaling. Contributions are welcomed, and the project is under the Apache 2.0 license with a vendor-neutral approach.

aiges
AIGES is a core component of the Athena Serving Framework, designed as a universal encapsulation tool for AI developers to deploy AI algorithm models and engines quickly. By integrating AIGES, you can deploy AI algorithm models and engines rapidly and host them on the Athena Serving Framework, utilizing supporting auxiliary systems for networking, distribution strategies, data processing, etc. The Athena Serving Framework aims to accelerate the cloud service of AI algorithm models and engines, providing multiple guarantees for cloud service stability through cloud-native architecture. You can efficiently and securely deploy, upgrade, scale, operate, and monitor models and engines without focusing on underlying infrastructure and service-related development, governance, and operations.