
llama-coder
Replace Copilot local AI
Stars: 1175
Llama Coder is a self-hosted Github Copilot replacement for VS Code that provides autocomplete using Ollama and Codellama. It works best with Mac M1/M2/M3 or RTX 4090, offering features like fast performance, no telemetry or tracking, and compatibility with any coding language. Users can install Ollama locally or on a dedicated machine for remote usage. The tool supports different models like stable-code and codellama with varying RAM/VRAM requirements, allowing users to optimize performance based on their hardware. Troubleshooting tips and a changelog are also provided for user convenience.
README:
Llama Coder is a better and self-hosted Github Copilot replacement for VS Code. Llama Coder uses Ollama and codellama to provide autocomplete that runs on your hardware. Works best with Mac M1/M2/M3 or with RTX 4090.
- 🚀 As good as Copilot
- ⚡️ Fast. Works well on consumer GPUs. Apple Silicon or RTX 4090 is recommended for best performance.
- 🔐 No telemetry or tracking
- 🔬 Works with any language coding or human one.
Minimum required RAM: 16GB is a minimum, more is better since even smallest model takes 5GB of RAM. The best way: dedicated machine with RTX 4090. Install Ollama on this machine and configure endpoint in extension settings to offload to this machine. Second best way: run on MacBook M1/M2/M3 with enough RAM (more == better, but 10gb extra would be enough). For windows notebooks: it runs good with decent GPU, but dedicated machine with a good GPU is recommended. Perfect if you have a dedicated gaming PC.
Install Ollama on local machine and then launch the extension in VSCode, everything should work as it is.
Install Ollama on dedicated machine and configure endpoint to it in extension settings. Ollama usually uses port 11434 and binds to 127.0.0.1, to change it you should set OLLAMA_HOST to 0.0.0.0.
Currently Llama Coder supports only Codellama. Model is quantized in different ways, but our tests shows that q4 is an optimal way to run network. When selecting model the bigger the model is, it performs better. Always pick the model with the biggest size and the biggest possible quantization for your machine. Default one is stable-code:3b-code-q4_0 and should work everywhere and outperforms most other models.
| Name | RAM/VRAM | Notes |
|---|---|---|
| stable-code:3b-code-q4_0 | 3GB | |
| codellama:7b-code-q4_K_M | 5GB | |
| codellama:7b-code-q6_K | 6GB | m |
| codellama:7b-code-fp16 | 14GB | g |
| codellama:13b-code-q4_K_M | 10GB | |
| codellama:13b-code-q6_K | 14GB | m |
| codellama:34b-code-q4_K_M | 24GB | |
| codellama:34b-code-q6_K | 32GB | m |
- m - slow on MacOS
- g - slow on older NVidia cards (pre 30xx)
Most of the problems could be seen in output of a plugin in VS Code extension output.
- Ability to pause completition (by @bkyle)
- Bearer token support for remote inference (by @Sinan-Karakaya)
- Fix remote files support
- Remote support
- Fix codellama prompt preparation
- Add trigger delay
- Add jupyter notebooks support
- Added Stable Code model
- Pause download only for specific model instead of all models
- Adding ability to pick a custom model
- Asking user if they want to download model if it is not available
- Adding deepseek 1b model and making it default
- Improved DeepSeek support and language detection
- Added DeepSeek support
- Ability to change temperature and top p
- Fixed some bugs
- Fix ollama links
- Added more models
- Initial release of Llama Coder
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for llama-coder
Similar Open Source Tools
llama-coder
Llama Coder is a self-hosted Github Copilot replacement for VS Code that provides autocomplete using Ollama and Codellama. It works best with Mac M1/M2/M3 or RTX 4090, offering features like fast performance, no telemetry or tracking, and compatibility with any coding language. Users can install Ollama locally or on a dedicated machine for remote usage. The tool supports different models like stable-code and codellama with varying RAM/VRAM requirements, allowing users to optimize performance based on their hardware. Troubleshooting tips and a changelog are also provided for user convenience.

torchtune
Torchtune is a PyTorch-native library for easily authoring, fine-tuning, and experimenting with LLMs. It provides native-PyTorch implementations of popular LLMs using composable and modular building blocks, easy-to-use and hackable training recipes for popular fine-tuning techniques, YAML configs for easily configuring training, evaluation, quantization, or inference recipes, and built-in support for many popular dataset formats and prompt templates to help you quickly get started with training.
kubeai
KubeAI is a highly scalable AI platform that runs on Kubernetes, serving as a drop-in replacement for OpenAI with API compatibility. It can operate OSS model servers like vLLM and Ollama, with zero dependencies and additional OSS addons included. Users can configure models via Kubernetes Custom Resources and interact with models through a chat UI. KubeAI supports serving various models like Llama v3.1, Gemma2, and Qwen2, and has plans for model caching, LoRA finetuning, and image generation.

Stable-Diffusion-Android
Stable Diffusion AI is an easy-to-use app for generating images from text or other images. It allows communication with servers powered by various AI technologies like AI Horde, Hugging Face Inference API, OpenAI, StabilityAI, and LocalDiffusion. The app supports Txt2Img and Img2Img modes, positive and negative prompts, dynamic size and sampling methods, unique seed input, and batch image generation. Users can also inpaint images, select faces from gallery or camera, and export images. The app offers settings for server URL, SD Model selection, auto-saving images, and clearing cache.
piccolo
Piccolo AI is an open-source software development toolkit for constructing sensor-based AI inference models optimized to run on low-power microcontrollers and IoT edge platforms. It includes SensiML's ML Engine, Embedded ML SDK, Analytic Studio UI, and SensiML Python Client. The tool is intended for individual developers, researchers, and AI enthusiasts, offering support for time-series sensor data classification and various applications such as acoustic event detection, activity recognition, gesture detection, anomaly detection, keyword spotting, and vibration classification.
ai-engine-direct-helper
A simple way to build AI applications based on Qualcomm® AI Runtime SDK. QAI AppBuilder simplifies the deployment of QNN models by encapsulating model execution APIs into simplified interfaces for loading models onto NPU/HTP and performing inference. It supports both C++ and Python projects, Windows and Linux platforms, Genie (Large Language Model), LLM on CPU & NPU, multimodal LLM, float & native input/output data, multi-graph, LoRA, multiple models, inputs & outputs. It makes app development easier, model testing faster, and provides plenty of sample code.

one-click-llms
The one-click-llms repository provides templates for quickly setting up an API for language models. It includes advanced inferencing scripts for function calling and offers various models for text generation and fine-tuning tasks. Users can choose between Runpod and Vast.AI for different GPU configurations, with recommendations for optimal performance. The repository also supports Trelis Research and offers templates for different model sizes and types, including multi-modal APIs and chat models.
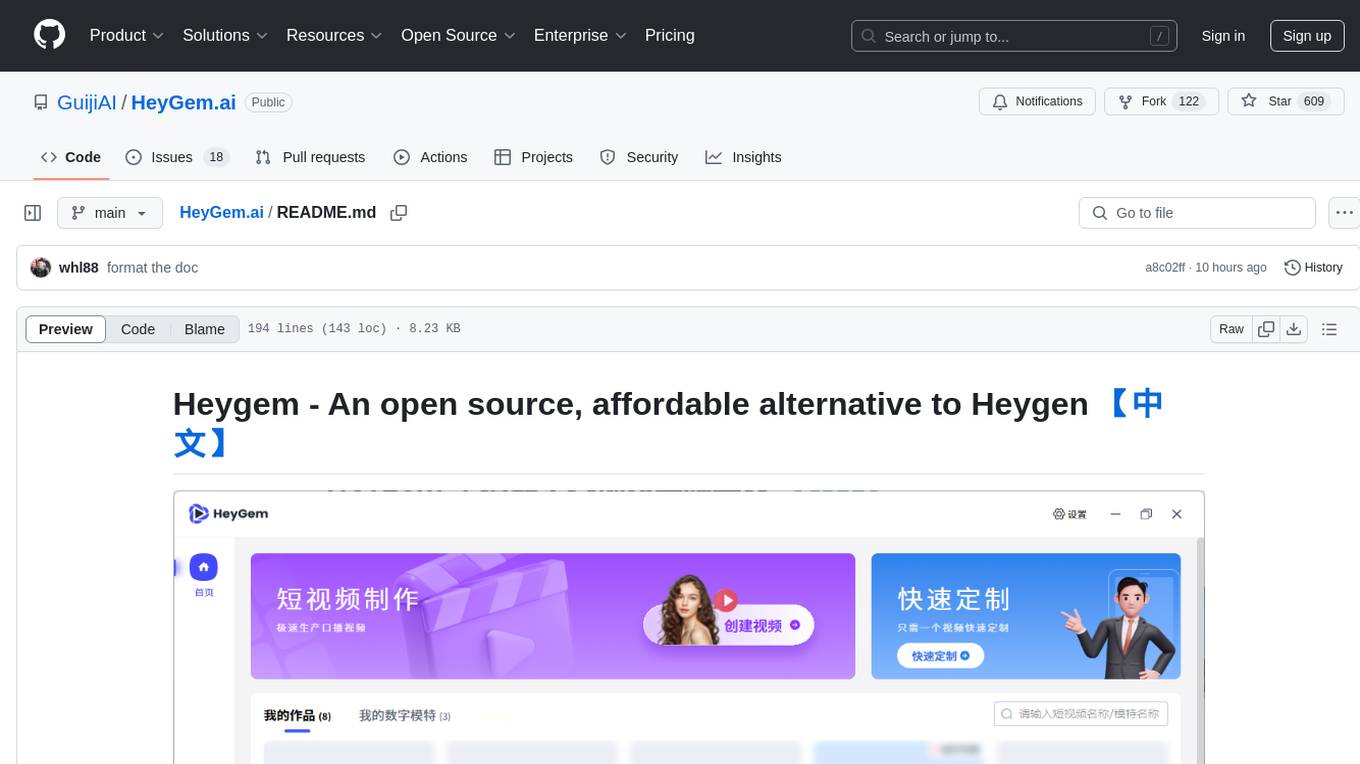
HeyGem.ai
Heygem is an open-source, affordable alternative to Heygen, offering a fully offline video synthesis tool for Windows systems. It enables precise appearance and voice cloning, allowing users to digitalize their image and drive virtual avatars through text and voice for video production. With core features like efficient video synthesis and multi-language support, Heygem ensures a user-friendly experience with fully offline operation and support for multiple models. The tool leverages advanced AI algorithms for voice cloning, automatic speech recognition, and computer vision technology to enhance the virtual avatar's performance and synchronization.

Easy-Voice-Toolkit
Easy Voice Toolkit is a toolkit based on open source voice projects, providing automated audio tools including speech model training. Users can seamlessly integrate functions like audio processing, voice recognition, voice transcription, dataset creation, model training, and voice conversion to transform raw audio files into ideal speech models. The toolkit supports multiple languages and is currently only compatible with Windows systems. It acknowledges the contributions of various projects and offers local deployment options for both users and developers. Additionally, cloud deployment on Google Colab is available. The toolkit has been tested on Windows OS devices and includes a FAQ section and terms of use for academic exchange purposes.

aphrodite-engine
Aphrodite is the official backend engine for PygmalionAI, serving as the inference endpoint for the website. It allows serving Hugging Face-compatible models with fast speeds. Features include continuous batching, efficient K/V management, optimized CUDA kernels, quantization support, distributed inference, and 8-bit KV Cache. The engine requires Linux OS and Python 3.8 to 3.12, with CUDA >= 11 for build requirements. It supports various GPUs, CPUs, TPUs, and Inferentia. Users can limit GPU memory utilization and access full commands via CLI.

gpt4all
GPT4All is an ecosystem to run powerful and customized large language models that work locally on consumer grade CPUs and any GPU. Note that your CPU needs to support AVX or AVX2 instructions. Learn more in the documentation. A GPT4All model is a 3GB - 8GB file that you can download and plug into the GPT4All open-source ecosystem software. Nomic AI supports and maintains this software ecosystem to enforce quality and security alongside spearheading the effort to allow any person or enterprise to easily train and deploy their own on-edge large language models.
zylos-core
Zylos is an AI framework that gives life to Claude Code, providing memory persistence, scheduling capabilities, communication through various channels, self-maintenance, and evolution. It ensures Claude Code can program, evolve, and integrate new services, growing alongside the user. Zylos offers features like unified consciousness across channels, guaranteed context preservation, self-healing mechanisms, cost-effective pricing, and integration with Claude Code for automatic updates and new capabilities.
sbnb
Sbnb Linux is a minimalist Linux distribution designed for bare-metal servers, offering fast tunnels for remote connections. It supports confidential computing and is ideal for environments from home labs to distributed data centers. The OS runs in memory, is immutable, and features a predictable update cadence. Users can deploy popular AI tools on bare metal using Sbnb Linux in an automated way. The system is resilient to power outages and supports flexible environments with Docker containers. Sbnb Linux is built with Buildroot, ensuring easy maintenance and updates.
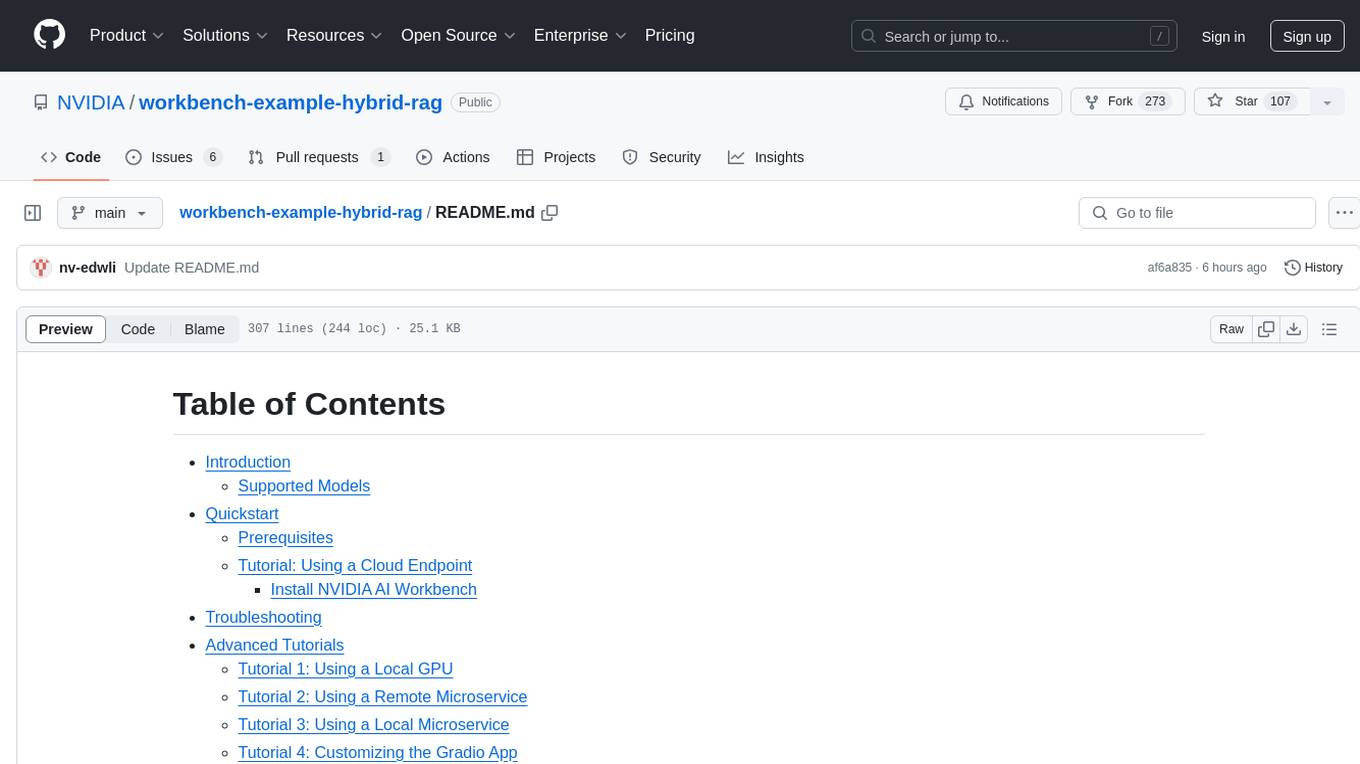
workbench-example-hybrid-rag
This NVIDIA AI Workbench project is designed for developing a Retrieval Augmented Generation application with a customizable Gradio Chat app. It allows users to embed documents into a locally running vector database and run inference locally on a Hugging Face TGI server, in the cloud using NVIDIA inference endpoints, or using microservices via NVIDIA Inference Microservices (NIMs). The project supports various models with different quantization options and provides tutorials for using different inference modes. Users can troubleshoot issues, customize the Gradio app, and access advanced tutorials for specific tasks.

swirl-search
Swirl is an open-source software that allows users to simultaneously search multiple content sources and receive AI-ranked results. It connects to various data sources, including databases, public data services, and enterprise sources, and utilizes AI and LLMs to generate insights and answers based on the user's data. Swirl is easy to use, requiring only the download of a YML file, starting in Docker, and searching with Swirl. Users can add credentials to preloaded SearchProviders to access more sources. Swirl also offers integration with ChatGPT as a configured AI model. It adapts and distributes user queries to anything with a search API, re-ranking the unified results using Large Language Models without extracting or indexing anything. Swirl includes five Google Programmable Search Engines (PSEs) to get users up and running quickly. Key features of Swirl include Microsoft 365 integration, SearchProvider configurations, query adaptation, synchronous or asynchronous search federation, optional subscribe feature, pipelining of Processor stages, results stored in SQLite3 or PostgreSQL, built-in Query Transformation support, matching on word stems and handling of stopwords, duplicate detection, re-ranking of unified results using Cosine Vector Similarity, result mixers, page through all results requested, sample data sets, optional spell correction, optional search/result expiration service, easily extensible Connector and Mixer objects, and a welcoming community for collaboration and support.
duix.ai
Duix is a silicon-based digital human SDK for intelligent interaction, providing users with instant virtual human interaction experience on devices like Android and iOS. The SDK offers intuitive effect display and supports user customization through open documentation. It is fully open-source, allowing developers to understand its workings, optimize, and innovate further.
For similar tasks
llama-coder
Llama Coder is a self-hosted Github Copilot replacement for VS Code that provides autocomplete using Ollama and Codellama. It works best with Mac M1/M2/M3 or RTX 4090, offering features like fast performance, no telemetry or tracking, and compatibility with any coding language. Users can install Ollama locally or on a dedicated machine for remote usage. The tool supports different models like stable-code and codellama with varying RAM/VRAM requirements, allowing users to optimize performance based on their hardware. Troubleshooting tips and a changelog are also provided for user convenience.
pearai-app
PearAI is an AI-powered code editor designed to enhance development by reducing the amount of coding required. It is a fork of VSCode and the main functionality lies within the 'extension/pearai' submodule. Users can contribute to the project by fixing issues, submitting bugs and feature requests, reviewing source code changes, and improving documentation. The tool aims to streamline the coding process and provide an efficient environment for developers to work in.

crush
Crush is a versatile tool designed to enhance coding workflows in your terminal. It offers support for multiple LLMs, allows for flexible switching between models, and enables session-based work management. Crush is extensible through MCPs and works across various operating systems. It can be installed using package managers like Homebrew and NPM, or downloaded directly. Crush supports various APIs like Anthropic, OpenAI, Groq, and Google Gemini, and allows for customization through environment variables. The tool can be configured locally or globally, and supports LSPs for additional context. Crush also provides options for ignoring files, allowing tools, and configuring local models. It respects `.gitignore` files and offers logging capabilities for troubleshooting and debugging.
llm-agents.nix
Nix packages for AI coding agents and development tools. Automatically updated daily. This repository provides a wide range of AI coding agents and tools that can be used in the terminal environment. The tools cover various functionalities such as code assistance, AI-powered development agents, CLI tools for AI coding, workflow and project management, code review, utilities like search tools and browser automation, and usage analytics for AI coding sessions. The repository also includes experimental features like sandboxed execution, provider abstraction, and tool composition to explore how Nix can enhance AI-powered development.
Kaku
Kaku is a fast and out-of-the-box terminal designed for AI coding. It is a deeply customized fork of WezTerm, offering polished defaults, built-in shell suite, Lua scripting, safe update flow, and a suite of CLI tools for immediate productivity. Kaku is fast, lightweight, and fully configurable via Lua scripts, providing a ready-to-work environment for coding enthusiasts.
llm.nvim
llm.nvim is a neovim plugin designed for LLM-assisted programming. It provides a no-frills approach to integrating language model assistance into the coding workflow. Users can configure the plugin to interact with various AI services such as GROQ, OpenAI, and Anthropics. The plugin offers functions to trigger the LLM assistant, create new prompt files, and customize key bindings for seamless interaction. With a focus on simplicity and efficiency, llm.nvim aims to enhance the coding experience by leveraging AI capabilities within the neovim environment.
ai-auto-free
AI Auto Free is a comprehensive automation tool that enables unlimited usage of AI-powered IDEs like Cursor and Windsurf. It offers cross-platform support and multiple language capabilities. The tool automates tasks such as account creation and email verification, overcoming trial limits and unauthorized requests. Users can use it for educational and research purposes to enhance their coding experience with AI.
copilot-lsp
Copilot LSP is a configuration tool for Neovim that enhances the native LSP functionality. It provides features such as text document focusing, inline completion, next edit suggestion, and status notifications. Users can easily integrate Copilot LSP into their Neovim setup to improve their coding experience. The tool offers smart clearing of suggestions, customizable defaults for Next Edit Suggestion (NES), and integration with Blink for inline completions. Copilot LSP requires installation via Mason or system and should be added to the PATH for seamless usage.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.