
synmetrix
Synmetrix – production-ready open source semantic layer on Cube
Stars: 531
Synmetrix is an open source data engineering platform and semantic layer for centralized metrics management. It provides a complete framework for modeling, integrating, transforming, aggregating, and distributing metrics data at scale. Key features include data modeling and transformations, semantic layer for unified data model, scheduled reports and alerts, versioning, role-based access control, data exploration, caching, and collaboration on metrics modeling. Synmetrix leverages Cube.js to consolidate metrics from various sources and distribute them downstream via a SQL API. Use cases include data democratization, business intelligence and reporting, embedded analytics, and enhancing accuracy in data handling and queries. The tool speeds up data-driven workflows from metrics definition to consumption by combining data engineering best practices with self-service analytics capabilities.
README:
![]()
Website • Docs • Cube.js Models docs • Docker Hub • Slack community
Synmetrix (prev. MLCraft) is an open source data engineering platform and semantic layer for centralized metrics management. It provides a complete framework for modeling, integrating, transforming, aggregating, and distributing metrics data at scale.
- Data modeling and transformations: Flexibly define metrics and dimensions using SQL and Cube data models. Apply transformations and aggregations.
- Semantic layer: Consolidate metrics from across sources into a unified, governed data model. Eliminate metric definition differences.
- Scheduled reports and alerts: Monitor metrics and get notified of changes via configurable reports and alerts.
- Versioning: Track schema changes over time for transparency and auditability.
- Role-based access control: Manage permissions for data models and metrics access.
- Data exploration: Analyze metrics through the UI, or integrate with any BI tool via the SQL API.
- Caching: Optimize performance using pre-aggregations and caching from Cube.
- Teams: Collaborate on metrics modeling across your organization.
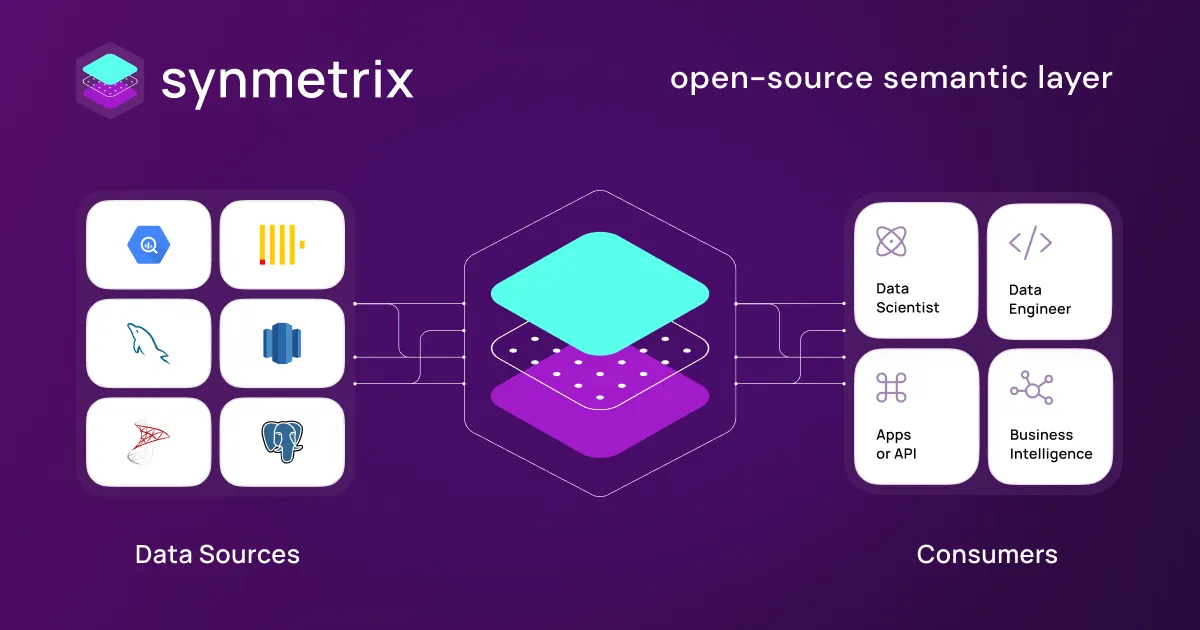
Synmetrix leverages Cube (Cube.js) to implement flexible data models that can consolidate metrics from across warehouses, databases, APIs and more. This unified semantic layer eliminates differences in definitions and calculations, providing a single source of truth.
The metrics data model can then be distributed downstream to any consumer via a SQL API, allowing integration into BI tools, reporting, dashboards, data science, and more.
By combining best practices from data engineering, like caching, orchestration, and transformation, with self-service analytics capabilities, Synmetrix speeds up data-driven workflows from metrics definition to consumption.
-
Data Democratization: Synmetrix makes data accessible to non-experts, enabling everyone in an organization to make data-driven decisions easily.
-
Business Intelligence (BI) and Reporting: Integrate Synmetrix with any BI tool for advanced reporting and analytics, enhancing data visualization and insights.
- Embedded Analytics: Use the Synmetrix API to embed analytics directly into applications, providing users with real-time data insights within their workflows.
- Integrating Synmetrix with Observable: A Quick Guide (Video)
- Guide to Connecting Synmetrix with DBeaver Using SQL API (Video)
- Semantic Layer for LLM: Enhance LLM's accuracy in data handling and queries with Synmetrix's semantic layer, improving data interaction and precision.
Ensure the following software is installed before proceeding:
The repository mlcraft-io/mlcraft/install-manifests houses all the necessary installation manifests for deploying Synmetrix anywhere. You can download the docker compose file from this repository:
Execute this in a new directory
wget https://raw.githubusercontent.com/mlcraft-io/mlcraft/main/install-manifests/docker-compose/docker-compose.yml
Alternatively, you can use curl
curl https://raw.githubusercontent.com/mlcraft-io/mlcraft/main/install-manifests/docker-compose/docker-compose.yml -o docker-compose.yml
NOTE: Ensure to review the environment variables in the docker-compose.yml file. Modify them as necessary.
Execute the following command to start Synmetrix along with a Postgres database for data storage.
docker-compose pull stack && docker-compose up -d
Verify if the containers are operational:
docker ps
Output:
CONTAINER ID IMAGE ... CREATED STATUS PORTS ...
c8f342d086f3 synmetrix/stack ... 1m ago Up 1m 80->8888/tcp ...
30ea14ddaa5e postgres:12 ... 1m ago Up 1m 5432/tcp
The installation of all dependencies will take approximately 5-7 minutes. Wait until you see the Synmetrix Stack is ready message. You can view the logs using docker-compose logs -f to confirm if the process has completed.
First, it's recommended to install Rosetta 2 on your Mac. This will allow Docker to run ARM64v8 containers. Since Docker version 4.25 it allows to run ARM64v8 containers natively, but some users still encounter issues without Rosetta installed.
For ARM64v8, Cubestore requires a specific version. Update the Cubestore version in the docker-compose file to include the -arm64v8 suffix. For instance, use v0.35.33-arm64v8 (refer to the Cubestore tags on Docker Hub for the latest version).
To run the docker-compose file for ARM64v8, use the following command:
docker-compose pull stack && CUBESTORE_VERSION=v0.35.33-arm64v8 docker-compose up -d
Video guide (MacOS, M3 Max processor):
- You can access Synmetrix at http://localhost/
- The GraphQL endpoint is located at http://localhost/v1/graphql
- The Admin Console (Hasura Console) can be found at http://localhost/console
- The Cube Swagger API can be found at http://localhost:4000/docs
-
Admin Console Access: Ensure to check
HASURA_GRAPHQL_ADMIN_SECRETin the docker-compose file. This is mandatory for accessing the Admin Console. The default value isadminsecret. Remember to modify this in a production environment. -
Environment Variables: Set up all necessary environment variables. Synmetrix will function with the default values, but certain features might not perform as anticipated.
-
Preloaded Seed Data: The project is equipped with preloaded seed data. Use the credentials below to sign in:
- Email:
[email protected] - Password:
demodemo
This account is pre-configured with two demo datasources and their respective SQL API access. For SQL operations, you can use the following credentials with any PostgreSQL client tool such as DBeaver or TablePlus:
Host Port Database User Password localhost 15432 db demo_pg_user demo_pg_pass localhost 15432 db demo_clickhouse_user demo_clickhouse_pass - Email:
Demo: app.synmetrix.org
- Login:
[email protected] - Password:
demodemo
| Database type | Host | Port | Database | User | Password | SSL |
|---|---|---|---|---|---|---|
| ClickHouse | gh-api.clickhouse.tech | 443 | default | play | no password | true |
| PostgreSQL | demo-db-examples.cube.dev | 5432 | ecom | cube | 12345 | false |
Synmetrix leverages Cube for flexible data modeling and transformations.
Cube implements a multi-stage SQL data modeling architecture:
- Raw data sits in a source database such as Postgres, MySQL, etc.
- The raw data is modeled into reusable data marts using Cube Data Models files. These models files allow defining metrics, dimensions, granularities and relationships.
- The models act as an abstraction layer between the raw data and application code.
- Cube then generates optimized analytical SQL queries against the raw data based on the model.
- The Cube Store distributed cache optimizes query performance by caching query results.
This modeling architecture makes it simple to create fast and complex analytical queries with Cube that are optimized to run against large datasets.
The unified data model can consolidate metrics from across different databases and systems, providing a consistent semantic layer for end users.
For production workloads, Synmetrix uses Cube Store as the caching and query execution layer.
Cube Store is a purpose-built database for operational analytics, optimized for fast aggregations and time series data. It provides:
- Distributed querying for scalability
- Advanced caching for fast queries
- columnar storage for analytics performance
- Integration with Cube for modeling
By leveraging Cube Store and Cube together, Synmetrix benefits from excellent analytics performance and flexibility in modeling metrics.
| Repository | Description |
|---|---|
| mlcraft-io/mlcraft | Synmetrix Monorepo |
| mlcraft-io/client-v2 | Synmetrix Client |
| mlcraft-io/docs | Synmetrix Docs |
| mlcraft-io/examples | Synmetrix Examples |
For general help using Synmetrix, please refer to the official Synmetrix documentation. For additional help, you can use one of these channels to ask a question:
- Slack / For live discussion with the Community and Synmetrix team
- GitHub / Bug reports, Contributions
- Twitter / Updates and news
- Youtube / Video tutorials and demos
Check out our roadmap to get informed on what we are currently working on, and what we have in mind for the next weeks, months and years.
The core Synmetrix is available under the Apache License 2.0 (Apache-2.0).
All other contents are available under the MIT License.
| Component | Requirement |
|---|---|
| Processor (CPU) | 3.2 GHz or higher, modern processor with multi-threading and virtualization support. |
| RAM | 8 GB or more to handle computational tasks and data processing. |
| Disk Space | At least 30 GB of free space for software installation and storing working data. |
| Network | Internet connectivity is required for cloud services and software updates. |
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for synmetrix
Similar Open Source Tools
synmetrix
Synmetrix is an open source data engineering platform and semantic layer for centralized metrics management. It provides a complete framework for modeling, integrating, transforming, aggregating, and distributing metrics data at scale. Key features include data modeling and transformations, semantic layer for unified data model, scheduled reports and alerts, versioning, role-based access control, data exploration, caching, and collaboration on metrics modeling. Synmetrix leverages Cube.js to consolidate metrics from various sources and distribute them downstream via a SQL API. Use cases include data democratization, business intelligence and reporting, embedded analytics, and enhancing accuracy in data handling and queries. The tool speeds up data-driven workflows from metrics definition to consumption by combining data engineering best practices with self-service analytics capabilities.

mlcraft
Synmetrix (prev. MLCraft) is an open source data engineering platform and semantic layer for centralized metrics management. It provides a complete framework for modeling, integrating, transforming, aggregating, and distributing metrics data at scale. Key features include data modeling and transformations, semantic layer for unified data model, scheduled reports and alerts, versioning, role-based access control, data exploration, caching, and collaboration on metrics modeling. Synmetrix leverages Cube (Cube.js) for flexible data models that consolidate metrics from various sources, enabling downstream distribution via a SQL API for integration into BI tools, reporting, dashboards, and data science. Use cases include data democratization, business intelligence, embedded analytics, and enhancing accuracy in data handling and queries. The tool speeds up data-driven workflows from metrics definition to consumption by combining data engineering best practices with self-service analytics capabilities.

doris
Doris is a lightweight and user-friendly data visualization tool designed for quick and easy exploration of datasets. It provides a simple interface for users to upload their data and generate interactive visualizations without the need for coding. With Doris, users can easily create charts, graphs, and dashboards to analyze and present their data in a visually appealing way. The tool supports various data formats and offers customization options to tailor visualizations to specific needs. Whether you are a data analyst, researcher, or student, Doris simplifies the process of data exploration and presentation.
OpenContracts
OpenContracts is an Apache-2 licensed enterprise document analytics tool that supports multiple formats, including PDF and txt-based formats. It features multiple document ingestion pipelines with a pluggable architecture for easy format and ingestion engine support. Users can create custom document analytics tools with beautiful result displays, support mass document data extraction with a LlamaIndex wrapper, and manage document collections, layout parsing, automatic vector embeddings, and human annotation. The tool also offers pluggable parsing pipelines, human annotation interface, LlamaIndex integration, data extraction capabilities, and custom data extract pipelines for bulk document querying.
accelerated-intelligent-document-processing-on-aws
Accelerated Intelligent Document Processing on AWS is a scalable, serverless solution for automated document processing and information extraction using AWS services. It combines OCR capabilities with generative AI to convert unstructured documents into structured data at scale. The solution features a serverless architecture built on AWS technologies, modular processing patterns, advanced classification support, few-shot example support, custom business logic integration, high throughput processing, built-in resilience, cost optimization, comprehensive monitoring, web user interface, human-in-the-loop integration, AI-powered evaluation, extraction confidence assessment, and document knowledge base query. The architecture uses nested CloudFormation stacks to support multiple document processing patterns while maintaining common infrastructure for queueing, tracking, and monitoring.

Geoweaver
Geoweaver is an in-browser software that enables users to easily compose and execute full-stack data processing workflows using online spatial data facilities, high-performance computation platforms, and open-source deep learning libraries. It provides server management, code repository, workflow orchestration software, and history recording capabilities. Users can run it from both local and remote machines. Geoweaver aims to make data processing workflows manageable for non-coder scientists and preserve model run history. It offers features like progress storage, organization, SSH connection to external servers, and a web UI with Python support.
vts
VTS (Vector Transport Service) is an open-source tool developed by Zilliz based on Apache Seatunnel for moving vectors and unstructured data. It addresses data migration needs, supports real-time data streaming and offline import, simplifies unstructured data transformation, and ensures end-to-end data quality. Core capabilities include rich connectors, stream and batch processing, distributed snapshot support, high performance, and real-time monitoring. Future developments include incremental synchronization, advanced data transformation, and enhanced monitoring. VTS supports various connectors for data migration and offers advanced features like Transformers, cluster mode deployment, RESTful API, Docker deployment, and more.

postgresml
PostgresML is a powerful Postgres extension that seamlessly combines data storage and machine learning inference within your database. It enables running machine learning and AI operations directly within PostgreSQL, leveraging GPU acceleration for faster computations, integrating state-of-the-art large language models, providing built-in functions for text processing, enabling efficient similarity search, offering diverse ML algorithms, ensuring high performance, scalability, and security, supporting a wide range of NLP tasks, and seamlessly integrating with existing PostgreSQL tools and client libraries.

fluid
Fluid is an open source Kubernetes-native Distributed Dataset Orchestrator and Accelerator for data-intensive applications, such as big data and AI applications. It implements dataset abstraction, scalable cache runtime, automated data operations, elasticity and scheduling, and is runtime platform agnostic. Key concepts include Dataset and Runtime. Prerequisites include Kubernetes version > 1.16, Golang 1.18+, and Helm 3. The tool offers features like accelerating remote file accessing, machine learning, accelerating PVC, preloading dataset, and on-the-fly dataset cache scaling. Contributions are welcomed, and the project is under the Apache 2.0 license with a vendor-neutral approach.
refly
Refly.AI is an open-source AI-native creation engine that empowers users to transform ideas into production-ready content. It features a free-form canvas interface with multi-threaded conversations, knowledge base integration, contextual memory, intelligent search, WYSIWYG AI editor, and more. Users can leverage AI-powered capabilities, context memory, knowledge base integration, quotes, and AI document editing to enhance their content creation process. Refly offers both cloud and self-hosting options, making it suitable for individuals, enterprises, and organizations. The tool is designed to facilitate human-AI collaboration and streamline content creation workflows.
neuro-san-studio
Neuro SAN Studio is an open-source library for building agent networks across various industries. It simplifies the development of collaborative AI systems by enabling users to create sophisticated multi-agent applications using declarative configuration files. The tool offers features like data-driven configuration, adaptive communication protocols, safe data handling, dynamic agent network designer, flexible tool integration, robust traceability, and cloud-agnostic deployment. It has been used in various use-cases such as automated generation of multi-agent configurations, airline policy assistance, banking operations, market analysis in consumer packaged goods, insurance claims processing, intranet knowledge management, retail operations, telco network support, therapy vignette supervision, and more.
seatunnel
SeaTunnel is a high-performance, distributed data integration tool trusted by numerous companies for synchronizing vast amounts of data daily. It addresses common data integration challenges by seamlessly integrating with diverse data sources, supporting multimodal data integration, complex synchronization scenarios, resource efficiency, and quality monitoring. With over 100 connectors, SeaTunnel offers batch-stream integration, distributed snapshot algorithm, multi-engine support, JDBC multiplexing, and log parsing. It provides high throughput, low latency, real-time monitoring, and supports two job development methods. Users can configure jobs, select execution engines, and parallelize data using source connectors. SeaTunnel also supports multimodal data integration, Apache SeaTunnel tools, real-world use cases, and visual management of jobs through the SeaTunnel Web Project.

UltraRAG
The UltraRAG framework is a researcher and developer-friendly RAG system solution that simplifies the process from data construction to model fine-tuning in domain adaptation. It introduces an automated knowledge adaptation technology system, supporting no-code programming, one-click synthesis and fine-tuning, multidimensional evaluation, and research-friendly exploration work integration. The architecture consists of Frontend, Service, and Backend components, offering flexibility in customization and optimization. Performance evaluation in the legal field shows improved results compared to VanillaRAG, with specific metrics provided. The repository is licensed under Apache-2.0 and encourages citation for support.
aistore
AIStore is a lightweight object storage system designed for AI applications. It is highly scalable, reliable, and easy to use. AIStore can be deployed on any commodity hardware, and it can be used to store and manage large datasets for deep learning and other AI applications.
fast-wiki
FastWiki is an enterprise-level artificial intelligence customer service management system. It is a high-performance knowledge base system designed for large-scale information retrieval and intelligent search. Leveraging Microsoft's Semantic Kernel for deep learning and natural language processing, combined with .NET 8 and React framework, it provides an efficient, user-friendly, and scalable intelligent vector search platform. The system aims to offer an intelligent search solution that can understand and process complex queries, assisting users in quickly and accurately obtaining the needed information.
app
WebDB is a comprehensive and free database Integrated Development Environment (IDE) designed to maximize efficiency in database development and management. It simplifies and enhances database operations with features like DBMS discovery, query editor, time machine, NoSQL structure inferring, modern ERD visualization, and intelligent data generator. Developed with robust web technologies, WebDB is suitable for both novice and experienced database professionals.
For similar tasks
langtrace
Langtrace is an open source observability software that lets you capture, debug, and analyze traces and metrics from all your applications that leverage LLM APIs, Vector Databases, and LLM-based Frameworks. It supports Open Telemetry Standards (OTEL), and the traces generated adhere to these standards. Langtrace offers both a managed SaaS version (Langtrace Cloud) and a self-hosted option. The SDKs for both Typescript/Javascript and Python are available, making it easy to integrate Langtrace into your applications. Langtrace automatically captures traces from various vendors, including OpenAI, Anthropic, Azure OpenAI, Langchain, LlamaIndex, Pinecone, and ChromaDB.
mlcraft
Synmetrix (prev. MLCraft) is an open source data engineering platform and semantic layer for centralized metrics management. It provides a complete framework for modeling, integrating, transforming, aggregating, and distributing metrics data at scale. Key features include data modeling and transformations, semantic layer for unified data model, scheduled reports and alerts, versioning, role-based access control, data exploration, caching, and collaboration on metrics modeling. Synmetrix leverages Cube (Cube.js) for flexible data models that consolidate metrics from various sources, enabling downstream distribution via a SQL API for integration into BI tools, reporting, dashboards, and data science. Use cases include data democratization, business intelligence, embedded analytics, and enhancing accuracy in data handling and queries. The tool speeds up data-driven workflows from metrics definition to consumption by combining data engineering best practices with self-service analytics capabilities.
synmetrix
Synmetrix is an open source data engineering platform and semantic layer for centralized metrics management. It provides a complete framework for modeling, integrating, transforming, aggregating, and distributing metrics data at scale. Key features include data modeling and transformations, semantic layer for unified data model, scheduled reports and alerts, versioning, role-based access control, data exploration, caching, and collaboration on metrics modeling. Synmetrix leverages Cube.js to consolidate metrics from various sources and distribute them downstream via a SQL API. Use cases include data democratization, business intelligence and reporting, embedded analytics, and enhancing accuracy in data handling and queries. The tool speeds up data-driven workflows from metrics definition to consumption by combining data engineering best practices with self-service analytics capabilities.

rtdl-num-embeddings
This repository provides the official implementation of the paper 'On Embeddings for Numerical Features in Tabular Deep Learning'. It focuses on transforming scalar continuous features into vectors before integrating them into the main backbone of tabular neural networks, showcasing improved performance. The embeddings for continuous features are shown to enhance the performance of tabular DL models and are applicable to various conventional backbones, offering efficiency comparable to Transformer-based models. The repository includes Python packages for practical usage, exploration of metrics and hyperparameters, and reproducing reported results for different algorithms and datasets.
VulBench
This repository contains materials for the paper 'How Far Have We Gone in Vulnerability Detection Using Large Language Model'. It provides a tool for evaluating vulnerability detection models using datasets such as d2a, ctf, magma, big-vul, and devign. Users can query the model 'Llama-2-7b-chat-hf' and store results in a SQLite database for analysis. The tool supports binary and multiple classification tasks with concurrency settings. Additionally, users can evaluate the results and generate a CSV file with metrics for each dataset and prompt type.

agentneo
AgentNeo is a Python package that provides functionalities for project, trace, dataset, experiment management. It allows users to authenticate, create projects, trace agents and LangGraph graphs, manage datasets, and run experiments with metrics. The tool aims to streamline AI project management and analysis by offering a comprehensive set of features.
hyperfy
Hyperfy is a powerful tool for automating social media marketing tasks. It provides a user-friendly interface to schedule posts, analyze performance metrics, and engage with followers across multiple platforms. With Hyperfy, users can save time and effort by streamlining their social media management processes in one centralized platform.
rill
Rill delivers rapid, self-service dashboards for data engineers and analysts directly on raw data lakes, ensuring reliable, fast-loading dashboards with accurate, real-time metrics. It comes with an embedded in-memory database for lightning-fast performance and supports bringing your own OLAP engine. Rill implements BI-as-code through SQL-based definitions, YAML configuration, Git integration, and CLI tools. Its metrics layer provides a unified way to define, compute, and serve business metrics, while AI agents can access fresh metrics instantly for precise decision-making and intelligent automation.
For similar jobs
mlcraft
Synmetrix (prev. MLCraft) is an open source data engineering platform and semantic layer for centralized metrics management. It provides a complete framework for modeling, integrating, transforming, aggregating, and distributing metrics data at scale. Key features include data modeling and transformations, semantic layer for unified data model, scheduled reports and alerts, versioning, role-based access control, data exploration, caching, and collaboration on metrics modeling. Synmetrix leverages Cube (Cube.js) for flexible data models that consolidate metrics from various sources, enabling downstream distribution via a SQL API for integration into BI tools, reporting, dashboards, and data science. Use cases include data democratization, business intelligence, embedded analytics, and enhancing accuracy in data handling and queries. The tool speeds up data-driven workflows from metrics definition to consumption by combining data engineering best practices with self-service analytics capabilities.
synmetrix
Synmetrix is an open source data engineering platform and semantic layer for centralized metrics management. It provides a complete framework for modeling, integrating, transforming, aggregating, and distributing metrics data at scale. Key features include data modeling and transformations, semantic layer for unified data model, scheduled reports and alerts, versioning, role-based access control, data exploration, caching, and collaboration on metrics modeling. Synmetrix leverages Cube.js to consolidate metrics from various sources and distribute them downstream via a SQL API. Use cases include data democratization, business intelligence and reporting, embedded analytics, and enhancing accuracy in data handling and queries. The tool speeds up data-driven workflows from metrics definition to consumption by combining data engineering best practices with self-service analytics capabilities.

databerry
Chaindesk is a no-code platform that allows users to easily set up a semantic search system for personal data without technical knowledge. It supports loading data from various sources such as raw text, web pages, files (Word, Excel, PowerPoint, PDF, Markdown, Plain Text), and upcoming support for web sites, Notion, and Airtable. The platform offers a user-friendly interface for managing datastores, querying data via a secure API endpoint, and auto-generating ChatGPT Plugins for each datastore. Chaindesk utilizes a Vector Database (Qdrant), Openai's text-embedding-ada-002 for embeddings, and has a chunk size of 1024 tokens. The technology stack includes Next.js, Joy UI, LangchainJS, PostgreSQL, Prisma, and Qdrant, inspired by the ChatGPT Retrieval Plugin.

OAD
OAD is a powerful open-source tool for analyzing and visualizing data. It provides a user-friendly interface for exploring datasets, generating insights, and creating interactive visualizations. With OAD, users can easily import data from various sources, clean and preprocess data, perform statistical analysis, and create customizable visualizations to communicate findings effectively. Whether you are a data scientist, analyst, or researcher, OAD can help you streamline your data analysis workflow and uncover valuable insights from your data.

sqlcoder
Defog's SQLCoder is a family of state-of-the-art large language models (LLMs) designed for converting natural language questions into SQL queries. It outperforms popular open-source models like gpt-4 and gpt-4-turbo on SQL generation tasks. SQLCoder has been trained on more than 20,000 human-curated questions based on 10 different schemas, and the model weights are licensed under CC BY-SA 4.0. Users can interact with SQLCoder through the 'transformers' library and run queries using the 'sqlcoder launch' command in the terminal. The tool has been tested on NVIDIA GPUs with more than 16GB VRAM and Apple Silicon devices with some limitations. SQLCoder offers a demo on their website and supports quantized versions of the model for consumer GPUs with sufficient memory.

TableLLM
TableLLM is a large language model designed for efficient tabular data manipulation tasks in real office scenarios. It can generate code solutions or direct text answers for tasks like insert, delete, update, query, merge, and chart operations on tables embedded in spreadsheets or documents. The model has been fine-tuned based on CodeLlama-7B and 13B, offering two scales: TableLLM-7B and TableLLM-13B. Evaluation results show its performance on benchmarks like WikiSQL, Spider, and self-created table operation benchmark. Users can use TableLLM for code and text generation tasks on tabular data.

data-scientist-roadmap2024
The Data Scientist Roadmap2024 provides a comprehensive guide to mastering essential tools for data science success. It includes programming languages, machine learning libraries, cloud platforms, and concepts categorized by difficulty. The roadmap covers a wide range of topics from programming languages to machine learning techniques, data visualization tools, and DevOps/MLOps tools. It also includes web development frameworks and specific concepts like supervised and unsupervised learning, NLP, deep learning, reinforcement learning, and statistics. Additionally, it delves into DevOps tools like Airflow and MLFlow, data visualization tools like Tableau and Matplotlib, and other topics such as ETL processes, optimization algorithms, and financial modeling.

VMind
VMind is an open-source solution for intelligent visualization, providing an intelligent chart component based on LLM by VisActor. It allows users to create chart narrative works with natural language interaction, edit charts through dialogue, and export narratives as videos or GIFs. The tool is easy to use, scalable, supports various chart types, and offers one-click export functionality. Users can customize chart styles, specify themes, and aggregate data using LLM models. VMind aims to enhance efficiency in creating data visualization works through dialogue-based editing and natural language interaction.