
llm-twin-course
🤖 𝗟𝗲𝗮𝗿𝗻 for 𝗳𝗿𝗲𝗲 how to 𝗯𝘂𝗶𝗹𝗱 an end-to-end 𝗽𝗿𝗼𝗱𝘂𝗰𝘁𝗶𝗼𝗻-𝗿𝗲𝗮𝗱𝘆 𝗟𝗟𝗠 & 𝗥𝗔𝗚 𝘀𝘆𝘀𝘁𝗲𝗺 using 𝗟𝗟𝗠𝗢𝗽𝘀 best practices: ~ 𝘴𝘰𝘶𝘳𝘤𝘦 𝘤𝘰𝘥𝘦 + 12 𝘩𝘢𝘯𝘥𝘴-𝘰𝘯 𝘭𝘦𝘴𝘴𝘰𝘯𝘴
Stars: 3118
The LLM Twin Course is a free, end-to-end framework for building production-ready LLM systems. It teaches you how to design, train, and deploy a production-ready LLM twin of yourself powered by LLMs, vector DBs, and LLMOps good practices. The course is split into 11 hands-on written lessons and the open-source code you can access on GitHub. You can read everything and try out the code at your own pace.
README:

By finishing the "LLM Twin: Building Your Production-Ready AI Replica" free course, you will learn how to design, train, and deploy a production-ready LLM twin of yourself powered by LLMs, vector DBs, and LLMOps good practices.
No more isolated scripts or Notebooks! Learn production ML by building and deploying an end-to-end production-grade LLM system.
You will learn how to architect and build a real-world LLM system from start to finish - from data collection to deployment.
You will also learn to leverage MLOps best practices, such as experiment trackers, model registries, prompt monitoring, and versioning.
The end goal? Build and deploy your own LLM twin.
What is an LLM Twin? It is an AI character that learns to write like somebody by incorporating its style and personality into an LLM.

- Crawl your digital data from various social media platforms, such as Medium, Substack and GitHub.
- Clean, normalize and load the data to a Mongo NoSQL DB through a series of ETL pipelines.
- Send database changes to a RabbitMQ queue using the CDC pattern.
- Learn to package the crawlers as AWS Lambda functions.
- Consume messages in real-time from a queue through a Bytewax streaming pipeline.
- Every message will be cleaned, chunked, embedded and loaded into a Qdrant vector DB.
- In the bonus series, we refactor the cleaning, chunking, and embedding logic using Superlinked, a specialized vector compute engine. We will also load and index the vectors to a Redis vector DB.
- Create a custom instruction dataset based on your custom digital data to do SFT.
- Fine-tune an LLM using LoRA or QLoRA.
- Use Comet ML's experiment tracker to monitor the experiments.
- Evaluate the LLM using Opik
- Save and version the best model to the Hugging Face model registry.
- Run and automate the training pipeline using AWS SageMaker.
- Load the fine-tuned LLM from the Hugging Face model registry.
- Deploy the LLM as a scalable REST API using AWS SageMaker inference endpoints.
- Enhance the prompts using advanced RAG techniques.
- Monitor the prompts and LLM generated results using Opik
- In the bonus series, we refactor the advanced RAG layer to write more optimal queries using Superlinked.
- Wrap up everything with a Gradio UI (as seen below) where you can start playing around with the LLM Twin to generate content that follows your writing style.

Along the 4 microservices, you will learn to integrate 4 serverless tools:
- Comet ML as your experiment tracker and data registry;
- Qdrant as your vector DB;
- AWS SageMaker as your ML infrastructure;
- Opik as your prompt evaluation and monitoring tool.
This course is ideal for:
- ML/AI engineers who want to learn to engineer production-ready LLM & RAG systems using LLMOps good principles
- Data Engineers, Data Scientists, and Software Engineers wanting to understand the engineering behind LLM & RAG systems
Note: This course focuses on engineering practices and end-to-end system implementation rather than theoretical model optimization or research.
| Category | Requirements |
|---|---|
| Skills | Basic understanding of Python and Machine Learning |
| Hardware | Any modern laptop/workstation will do the job, as the LLM fine-tuning and inference will be done on AWS SageMaker. |
| Level | Intermediate |
All tools used throughout the course will stick to their free tier, except:
- OpenAI's API, which will cost ~$1
- AWS for fine-tuning and inference, which will cost < $10 depending on how much you play around with our scripts and your region.
As an open-source course, you don't have to enroll. Everything is self-paced, free of charge and with its resources freely accessible as follows:
- code: this GitHub repository
- articles: Decoding ML
The course contains 10 hands-on written lessons and the open-source code you can access on GitHub, showing how to build an end-to-end LLM system.
Also, it includes 2 bonus lessons on how to improve the RAG system.
You can read everything at your own pace.
This self-paced course consists of 12 comprehensive lessons covering theory, system design, and hands-on implementation.
Our recommendation for each module:
- Read the article
- Run the code to replicate our results
- Go deeper into the code by reading the
srcPython modules
[!NOTE] Check the INSTALL_AND_USAGE doc for a step-by-step installation and usage guide.
| Lesson | Article | Category | Description | Source Code |
|---|---|---|---|---|
| 1 | An End-to-End Framework for Production-Ready LLM Systems | System Design | Learn the overall architecture and design principles of production LLM systems. | No code |
| 2 | Data Crawling | Data Engineering | Learn to crawl and process social media content for LLM training. | src/data_crawling |
| 3 | CDC Magic | Data Engineering | Learn to implement Change Data Capture (CDC) for syncing two data sources. | src/data_cdc |
| 4 | Feature Streaming Pipelines | Feature Pipeline | Build real-time streaming pipelines for LLM and RAG data processing. | src/feature_pipeline |
| 5 | Advanced RAG Algorithms | Feature Pipeline | Implement advanced RAG techniques for better retrieval. | src/feature_pipeline |
| 6 | Generate Fine-Tuning Instruct Datasets | Training Pipeline | Create custom instruct datasets for LLM fine-tuning. | src/feature_pipeline/generate_dataset |
| 7 | LLM Fine-tuning Pipeline | Training Pipeline | Build an end-to-end LLM fine-tuning pipeline and deploy it to AWS SageMaker. | src/training_pipeline |
| 8 | LLM & RAG Evaluation | Training Pipeline | Learn to evaluate LLM and RAG system performance. | src/inference_pipeline/evaluation |
| 9 | Implement and Deploy the RAG Inference Pipeline | Inference Pipeline | Design, implement and deploy the RAG inference to AWS SageMaker. | src/inference_pipeline |
| 10 | Prompt Monitoring | Inference Pipeline | Build the prompt monitoring and production evaluation pipeline. | src/inference_pipeline |
| 11 | Refactor the RAG module using 74.3% Less Code | Bonus on RAG | Optimize the RAG system. | src/bonus_superlinked_rag |
| 12 | Multi-Index RAG Apps | Bonus on RAG | Build advanced multi-index RAG apps. | src/bonus_superlinked_rag |
At Decoding ML we teach how to build production ML systems, thus the course follows the structure of a real-world Python project:
llm-twin-course/
├── src/ # Source code for all the ML pipelines and services
│ ├── data_crawling/ # Data collection pipeline code
│ ├── data_cdc/ # Change Data Capture (CDC) pipeline code
│ ├── feature_pipeline/ # Feature engineering pipeline code
│ ├── training_pipeline/ # Training pipeline code
│ ├── inference_pipeline/ # Inference service code
│ └── bonus_superlinked_rag/ # Bonus RAG optimization code
├── .env.example # Example environment variables template
├── Makefile # Commands to build and run the project
├── pyproject.toml # Project dependencies
To understand how to install and run the LLM Twin code end-to-end, go to the INSTALL_AND_USAGE dedicated document.
[!NOTE] Even though you can run everything solely using the INSTALL_AND_USAGE dedicated document, we recommend that you read the articles to understand the LLM Twin system and design choices fully.
Have questions or running into issues? We're here to help!
Open a GitHub issue for:
- Questions about the course material
- Technical troubleshooting
- Clarification on concepts
As an open-source course, we may not be able to fix all the bugs that arise.
If you find any bugs and know how to fix them, support future readers by contributing to this course with your bug fix.
We will deeply appreciate your support for the AI community and future readers 🤗
A big "Thank you 🙏" to all our contributors! This course is possible only because of their efforts.
Also, another big "Thank you 🙏" to all our sponsors who supported our work and made this course possible.
| Comet | Opik | Bytewax | Qdrant | Superlinked |

|

|

|

|

|
Our LLM Engineer’s Handbook inspired the open-source LLM Twin course.
Consider supporting our work by getting our book to learn a complete framework for building and deploying production LLM & RAG systems — from data to deployment.
Perfect for practitioners who want both theory and hands-on expertise by connecting the dots between DE, research, MLE and MLOps:
Buy the LLM Engineer’s Handbook

This course is an open-source project released under the MIT license. Thus, as long you distribute our LICENSE and acknowledge our work, you can safely clone or fork this project and use it as a source of inspiration for whatever you want (e.g., university projects, college degree projects, personal projects, etc.).
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for llm-twin-course
Similar Open Source Tools
llm-twin-course
The LLM Twin Course is a free, end-to-end framework for building production-ready LLM systems. It teaches you how to design, train, and deploy a production-ready LLM twin of yourself powered by LLMs, vector DBs, and LLMOps good practices. The course is split into 11 hands-on written lessons and the open-source code you can access on GitHub. You can read everything and try out the code at your own pace.

ludwig
Ludwig is a declarative deep learning framework designed for scale and efficiency. It is a low-code framework that allows users to build custom AI models like LLMs and other deep neural networks with ease. Ludwig offers features such as optimized scale and efficiency, expert level control, modularity, and extensibility. It is engineered for production with prebuilt Docker containers, support for running with Ray on Kubernetes, and the ability to export models to Torchscript and Triton. Ludwig is hosted by the Linux Foundation AI & Data.
Generative-AI-for-beginners-dotnet
Generative AI for Beginners .NET is a hands-on course designed for .NET developers to learn how to build Generative AI applications. The repository focuses on real-world applications and live coding, providing fully functional code samples and integration with tools like GitHub Codespaces and GitHub Models. Lessons cover topics such as generative models, text generation, multimodal capabilities, and responsible use of Generative AI in .NET apps. The course aims to simplify the journey of implementing Generative AI into .NET projects, offering practical guidance and references for deeper theoretical understanding.
saga-reader
Saga Reader is an AI-driven think tank-style reader that automatically retrieves information from the internet based on user-specified topics and preferences. It uses cloud or local large models to summarize and provide guidance, and it includes an AI-driven interactive companion reading function, allowing you to discuss and exchange ideas with AI about the content you've read. Saga Reader is completely free and open-source, meaning all data is securely stored on your own computer and is not controlled by third-party service providers. Additionally, you can manage your subscription keywords based on your interests and preferences without being disturbed by advertisements and commercialized content.

agentic-context-engine
Agentic Context Engine (ACE) is a framework that enables AI agents to learn from their execution feedback, continuously improving without fine-tuning or training data. It maintains a Skillbook of evolving strategies, extracting patterns from successful tasks and learning from failures transparently in context. ACE offers self-improving agents, better performance on complex tasks, token reduction in browser automation, and preservation of valuable knowledge over time. Users can integrate ACE with popular agent frameworks and benefit from its innovative approach to in-context learning.

OmAgent
OmAgent is an open-source agent framework designed to streamline the development of on-device multimodal agents. It enables agents to empower various hardware devices, integrates speed-optimized SOTA multimodal models, provides SOTA multimodal agent algorithms, and focuses on optimizing the end-to-end computing pipeline for real-time user interaction experience. Key features include easy connection to diverse devices, scalability, flexibility, and workflow orchestration. The architecture emphasizes graph-based workflow orchestration, native multimodality, and device-centricity, allowing developers to create bespoke intelligent agent programs.

swirl-search
Swirl is an open-source software that allows users to simultaneously search multiple content sources and receive AI-ranked results. It connects to various data sources, including databases, public data services, and enterprise sources, and utilizes AI and LLMs to generate insights and answers based on the user's data. Swirl is easy to use, requiring only the download of a YML file, starting in Docker, and searching with Swirl. Users can add credentials to preloaded SearchProviders to access more sources. Swirl also offers integration with ChatGPT as a configured AI model. It adapts and distributes user queries to anything with a search API, re-ranking the unified results using Large Language Models without extracting or indexing anything. Swirl includes five Google Programmable Search Engines (PSEs) to get users up and running quickly. Key features of Swirl include Microsoft 365 integration, SearchProvider configurations, query adaptation, synchronous or asynchronous search federation, optional subscribe feature, pipelining of Processor stages, results stored in SQLite3 or PostgreSQL, built-in Query Transformation support, matching on word stems and handling of stopwords, duplicate detection, re-ranking of unified results using Cosine Vector Similarity, result mixers, page through all results requested, sample data sets, optional spell correction, optional search/result expiration service, easily extensible Connector and Mixer objects, and a welcoming community for collaboration and support.

plandex
Plandex is an open source, terminal-based AI coding engine designed for complex tasks. It uses long-running agents to break up large tasks into smaller subtasks, helping users work through backlogs, navigate unfamiliar technologies, and save time on repetitive tasks. Plandex supports various AI models, including OpenAI, Anthropic Claude, Google Gemini, and more. It allows users to manage context efficiently in the terminal, experiment with different approaches using branches, and review changes before applying them. The tool is platform-independent and runs from a single binary with no dependencies.
LiteRT
LiteRT is Google's open-source high-performance runtime for on-device AI, previously known as TensorFlow Lite. The repository is currently not intended for open-source development, but aims to evolve to allow direct building and contributions. LiteRT supports Python versions 3.9, 3.10, 3.11 on Linux and MacOS. It ensures compatibility with existing .tflite file extension and format, offering conversion tools and continued active development under the name LiteRT.
FuzzyAI
The FuzzyAI Fuzzer is a powerful tool for automated LLM fuzzing, designed to help developers and security researchers identify jailbreaks and mitigate potential security vulnerabilities in their LLM APIs. It supports various fuzzing techniques, provides input generation capabilities, can be easily integrated into existing workflows, and offers an extensible architecture for customization and extension. The tool includes attacks like ArtPrompt, Taxonomy-based paraphrasing, Many-shot jailbreaking, Genetic algorithm, Hallucinations, DAN (Do Anything Now), WordGame, Crescendo, ActorAttack, Back To The Past, Please, Thought Experiment, and Default. It supports models from providers like Anthropic, OpenAI, Gemini, Azure, Bedrock, AI21, and Ollama, with the ability to add support for newer models. The tool also supports various cloud APIs and datasets for testing and experimentation.

lerobot
LeRobot is a state-of-the-art AI library for real-world robotics in PyTorch. It aims to provide models, datasets, and tools to lower the barrier to entry to robotics, focusing on imitation learning and reinforcement learning. LeRobot offers pretrained models, datasets with human-collected demonstrations, and simulation environments. It plans to support real-world robotics on affordable and capable robots. The library hosts pretrained models and datasets on the Hugging Face community page.

UltraRAG
The UltraRAG framework is a researcher and developer-friendly RAG system solution that simplifies the process from data construction to model fine-tuning in domain adaptation. It introduces an automated knowledge adaptation technology system, supporting no-code programming, one-click synthesis and fine-tuning, multidimensional evaluation, and research-friendly exploration work integration. The architecture consists of Frontend, Service, and Backend components, offering flexibility in customization and optimization. Performance evaluation in the legal field shows improved results compared to VanillaRAG, with specific metrics provided. The repository is licensed under Apache-2.0 and encourages citation for support.
BMAD-METHOD
BMAD-METHOD™ is a universal AI agent framework that revolutionizes Agile AI-Driven Development. It offers specialized AI expertise across various domains, including software development, entertainment, creative writing, business strategy, and personal wellness. The framework introduces two key innovations: Agentic Planning, where dedicated agents collaborate to create detailed specifications, and Context-Engineered Development, which ensures complete understanding and guidance for developers. BMAD-METHOD™ simplifies the development process by eliminating planning inconsistency and context loss, providing a seamless workflow for creating AI agents and expanding functionality through expansion packs.
appwrite
Appwrite is a best-in-class, developer-first platform that provides everything needed to create scalable, stable, and production-ready software quickly. It is an end-to-end platform for building Web, Mobile, Native, or Backend apps, packaged as Docker microservices. Appwrite abstracts the complexity of building modern apps and allows users to build secure, full-stack applications faster. It offers features like user authentication, database management, storage, file management, image manipulation, Cloud Functions, messaging, and more services.

co-op-translator
Co-op Translator is a tool designed to facilitate communication between team members working on cooperative projects. It allows users to easily translate messages and documents in real-time, enabling seamless collaboration across language barriers. The tool supports multiple languages and provides accurate translations to ensure clear and effective communication within the team. With Co-op Translator, users can improve efficiency, productivity, and teamwork in their cooperative endeavors.
ai-that-works
AI That Works is a weekly live coding event focused on exploring advanced AI engineering techniques and tools to take AI applications from demo to production. The sessions cover topics such as token efficiency, downsides of JSON, writing drop-ins for coding agents, and advanced tricks like .shims for coding tools. The event aims to help participants get the most out of today's AI models and tools through live coding, Q&A sessions, and production-ready insights.
For similar tasks
llm-twin-course
The LLM Twin Course is a free, end-to-end framework for building production-ready LLM systems. It teaches you how to design, train, and deploy a production-ready LLM twin of yourself powered by LLMs, vector DBs, and LLMOps good practices. The course is split into 11 hands-on written lessons and the open-source code you can access on GitHub. You can read everything and try out the code at your own pace.
Agent
Agent is a RustSBI specialized domain knowledge quiz LLM tool that extracts domain knowledge from various sources such as Rust Documentation, RISC-V Documentation, Bouffalo Docs, Bouffalo SDK, and Xiangshan Docs. It also provides resources for LLM prompt engineering and RAG engineering, including guides and existing projects related to retrieval-augmented generation (RAG) systems.

maxtext
MaxText is a high-performance, highly scalable, open-source LLM written in pure Python/Jax and targeting Google Cloud TPUs and GPUs for training and inference. MaxText achieves high MFUs and scales from single host to very large clusters while staying simple and "optimization-free" thanks to the power of Jax and the XLA compiler. MaxText aims to be a launching off point for ambitious LLM projects both in research and production. We encourage users to start by experimenting with MaxText out of the box and then fork and modify MaxText to meet their needs.

swift
SWIFT (Scalable lightWeight Infrastructure for Fine-Tuning) supports training, inference, evaluation and deployment of nearly **200 LLMs and MLLMs** (multimodal large models). Developers can directly apply our framework to their own research and production environments to realize the complete workflow from model training and evaluation to application. In addition to supporting the lightweight training solutions provided by [PEFT](https://github.com/huggingface/peft), we also provide a complete **Adapters library** to support the latest training techniques such as NEFTune, LoRA+, LLaMA-PRO, etc. This adapter library can be used directly in your own custom workflow without our training scripts. To facilitate use by users unfamiliar with deep learning, we provide a Gradio web-ui for controlling training and inference, as well as accompanying deep learning courses and best practices for beginners. Additionally, we are expanding capabilities for other modalities. Currently, we support full-parameter training and LoRA training for AnimateDiff.
ipex-llm
IPEX-LLM is a PyTorch library for running Large Language Models (LLMs) on Intel CPUs and GPUs with very low latency. It provides seamless integration with various LLM frameworks and tools, including llama.cpp, ollama, Text-Generation-WebUI, HuggingFace transformers, and more. IPEX-LLM has been optimized and verified on over 50 LLM models, including LLaMA, Mistral, Mixtral, Gemma, LLaVA, Whisper, ChatGLM, Baichuan, Qwen, and RWKV. It supports a range of low-bit inference formats, including INT4, FP8, FP4, INT8, INT2, FP16, and BF16, as well as finetuning capabilities for LoRA, QLoRA, DPO, QA-LoRA, and ReLoRA. IPEX-LLM is actively maintained and updated with new features and optimizations, making it a valuable tool for researchers, developers, and anyone interested in exploring and utilizing LLMs.
Awesome-LLM-Inference
Awesome-LLM-Inference: A curated list of 📙Awesome LLM Inference Papers with Codes, check 📖Contents for more details. This repo is still updated frequently ~ 👨💻 Welcome to star ⭐️ or submit a PR to this repo!
lingo
Lingo is a lightweight ML model proxy that runs on Kubernetes, allowing you to run text-completion and embedding servers without changing OpenAI client code. It supports serving OSS LLMs, is compatible with OpenAI API, plug-and-play with messaging systems, scales from zero based on load, and has zero dependencies. Namespaced with no cluster privileges needed.
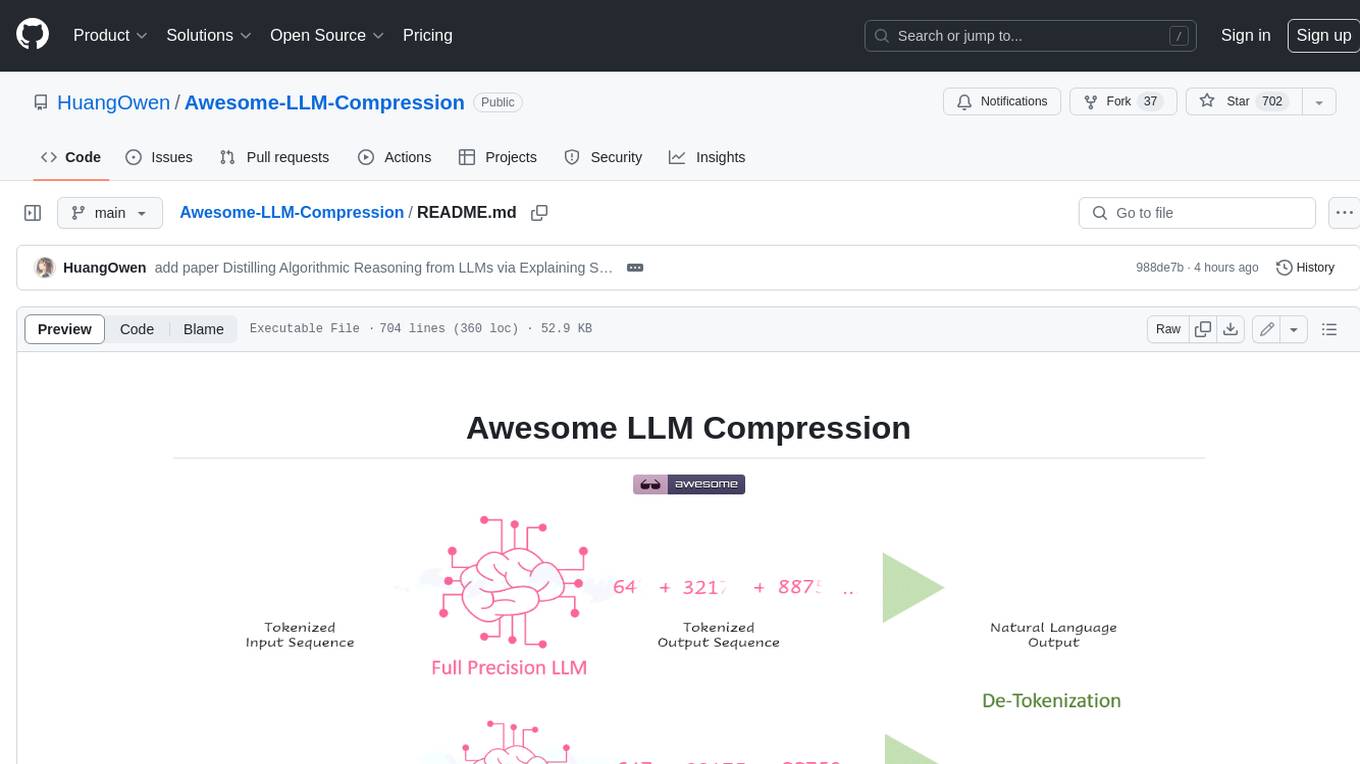
Awesome-LLM-Compression
Awesome LLM compression research papers and tools to accelerate LLM training and inference.
For similar jobs

db2rest
DB2Rest is a modern low-code REST DATA API platform that simplifies the development of intelligent applications. It seamlessly integrates existing and new databases with language models (LMs/LLMs) and vector stores, enabling the rapid delivery of context-aware, reasoning applications without vendor lock-in.

mage-ai
Mage is an open-source data pipeline tool for transforming and integrating data. It offers an easy developer experience, engineering best practices built-in, and data as a first-class citizen. Mage makes it easy to build, preview, and launch data pipelines, and provides observability and scaling capabilities. It supports data integrations, streaming pipelines, and dbt integration.

airbyte
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.

telemetry-airflow
This repository codifies the Airflow cluster that is deployed at workflow.telemetry.mozilla.org (behind SSO) and commonly referred to as "WTMO" or simply "Airflow". Some links relevant to users and developers of WTMO: * The `dags` directory in this repository contains some custom DAG definitions * Many of the DAGs registered with WTMO don't live in this repository, but are instead generated from ETL task definitions in bigquery-etl * The Data SRE team maintains a WTMO Developer Guide (behind SSO)

airflow
Apache Airflow (or simply Airflow) is a platform to programmatically author, schedule, and monitor workflows. When workflows are defined as code, they become more maintainable, versionable, testable, and collaborative. Use Airflow to author workflows as directed acyclic graphs (DAGs) of tasks. The Airflow scheduler executes your tasks on an array of workers while following the specified dependencies. Rich command line utilities make performing complex surgeries on DAGs a snap. The rich user interface makes it easy to visualize pipelines running in production, monitor progress, and troubleshoot issues when needed.

airbyte-platform
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's low-code Connector Development Kit (CDK). Airbyte is used by data engineers and analysts at companies of all sizes to move data for a variety of purposes, including data warehousing, data analysis, and machine learning.

chronon
Chronon is a platform that simplifies and improves ML workflows by providing a central place to define features, ensuring point-in-time correctness for backfills, simplifying orchestration for batch and streaming pipelines, offering easy endpoints for feature fetching, and guaranteeing and measuring consistency. It offers benefits over other approaches by enabling the use of a broad set of data for training, handling large aggregations and other computationally intensive transformations, and abstracting away the infrastructure complexity of data plumbing.