
rag-time
RAG Time: A 5-week Learning Journey to Mastering RAG
Stars: 91
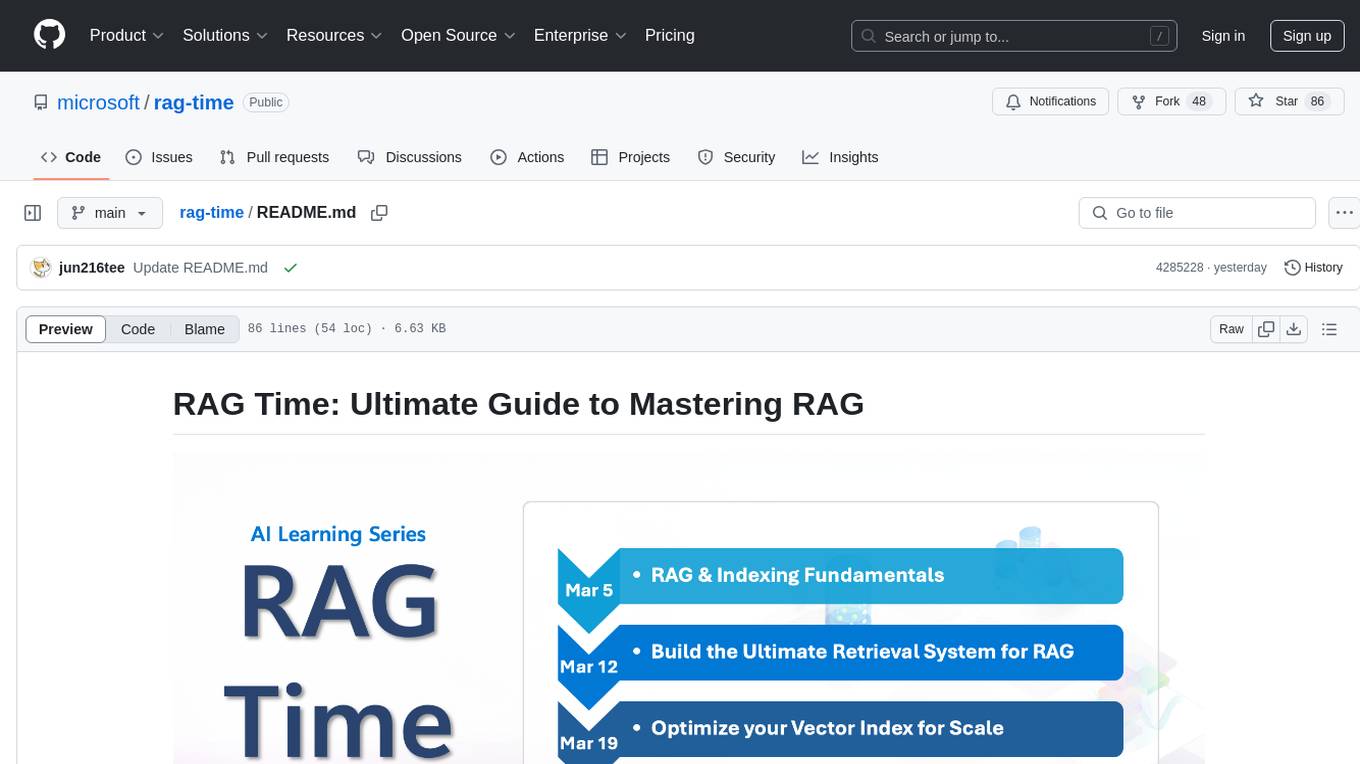
RAG Time is a 5-week AI learning series focusing on Retrieval-Augmented Generation (RAG) concepts. The repository contains code samples, step-by-step guides, and resources to help users master RAG. It aims to teach foundational and advanced RAG concepts, demonstrate real-world applications, and provide hands-on samples for practical implementation.
README:




🎉 Welcome to RAG Time, a 5-week AI learning series where Retrieval-Augmented Generation (RAG) meets innovation! This repository is your companion to the video series, containing code samples, step-by-step guides, and resources to help you master RAG concepts.
The RAG Time series aims to:
- Teach foundational and advanced RAG concepts.
- Demonstrate how RAG can be applied to real-world scenarios.
- Provide hands-on samples for practical implementation.
To run the code samples included in this repository:
- Fork the repository.
- Clone the repository to your local machine:
git clone https://github.com/your-org/rag-time.git
cd rag-time- Navigate to the Journey of your choice and follow the README Instructions.
RAG Time runs every Wednesday at 9AM PT from March 5th to April 2nd. Each journey covers unique topics with leadership insights, tech talks, and code samples
| Journey Page | Description | Video | Code Sample | Blog |
|---|---|---|---|---|
| RAG and Knowledge Retrieval fundamentals | Understand the strategic importance of RAG and indexing | Watch now | Sample | Journey 1 |
| Build the Ultimate Retrieval System | Explore how Azure AI Search powers retrieval system | 📺 Streaming on March 12th, 9AM PT | Sample | Coming soon! |
| Optimize Your Vector Index at Scale | Learn real-world optimization techniques for scaling vector indexes | 📺 Streaming on March 19th, 9AM PT | Sample | Coming soon! |
| RAG for All Your Data | Discover how multimodal data can be indexed and retrieved | 📺 Streaming on March 26th, 9AM PT | Sample | Coming soon! |
| Hero Use-Cases for RAG | Get inspired by hero use cases of RAG in action | 📺 Streaming on April 2nd, 9AM PT | Sample | Coming soon! |

We'd love to see you contributing to our repo and engaging with the experts with your questions!
- 🤔 Do you have suggestions or have you found spelling or code errors? Raise an issue or Create a pull request.
- 🚀 If you get stuck or have any questions about RAG, join our Azure AI Community Discord.

This project welcomes contributions and suggestions. Most contributions require you to agree to a Contributor License Agreement (CLA) declaring that you have the right to, and actually do, grant us the rights to use your contribution. For details, visit https://cla.opensource.microsoft.com.
When you submit a pull request, a CLA bot will automatically determine whether you need to provide a CLA and decorate the PR appropriately (e.g., status check, comment). Simply follow the instructions provided by the bot. You will only need to do this once across all repos using our CLA.
This project has adopted the Microsoft Open Source Code of Conduct. For more information, see the Code of Conduct FAQ or contact [email protected] with any additional questions or comments.
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft trademarks or logos is subject to and must follow Microsoft's Trademark & Brand Guidelines. Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship. Any use of third-party trademarks or logos is subject to those third parties' policies.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for rag-time
Similar Open Source Tools
rag-time
RAG Time is a 5-week AI learning series focusing on Retrieval-Augmented Generation (RAG) concepts. The repository contains code samples, step-by-step guides, and resources to help users master RAG. It aims to teach foundational and advanced RAG concepts, demonstrate real-world applications, and provide hands-on samples for practical implementation.

second-brain-ai-assistant-course
This open-source course teaches how to build an advanced RAG and LLM system using LLMOps and ML systems best practices. It helps you create an AI assistant that leverages your personal knowledge base to answer questions, summarize documents, and provide insights. The course covers topics such as LLM system architecture, pipeline orchestration, large-scale web crawling, model fine-tuning, and advanced RAG features. It is suitable for ML/AI engineers and data/software engineers & data scientists looking to level up to production AI systems. The course is free, with minimal costs for tools like OpenAI's API and Hugging Face's Dedicated Endpoints. Participants will build two separate Python applications for offline ML pipelines and online inference pipeline.
uptrain
UpTrain is an open-source unified platform to evaluate and improve Generative AI applications. We provide grades for 20+ preconfigured evaluations (covering language, code, embedding use cases), perform root cause analysis on failure cases and give insights on how to resolve them.

aws-machine-learning-university-responsible-ai
This repository contains slides, notebooks, and data for the Machine Learning University (MLU) Responsible AI class. The mission is to make Machine Learning accessible to everyone, covering widely used ML techniques and applying them to real-world problems. The class includes lectures, final projects, and interactive visuals to help users learn about Responsible AI and core ML concepts.

agent-lightning
Agent Lightning is a lightweight and efficient tool for automating repetitive tasks in the field of data analysis and machine learning. It provides a user-friendly interface to create and manage automated workflows, allowing users to easily schedule and execute data processing, model training, and evaluation tasks. With its intuitive design and powerful features, Agent Lightning streamlines the process of building and deploying machine learning models, making it ideal for data scientists, machine learning engineers, and AI enthusiasts looking to boost their productivity and efficiency in their projects.
openfoodfacts-ai
The openfoodfacts-ai repository is dedicated to tracking and storing experimental AI endeavors, models training, and wishlists related to nutrition table detection, category prediction, logos and labels detection, spellcheck, and other AI projects for Open Food Facts. It serves as a hub for integrating AI models into production and collaborating on AI-related issues. The repository also hosts trained models and datasets for public use and experimentation.
wppconnect
WPPConnect is an open source project developed by the JavaScript community with the aim of exporting functions from WhatsApp Web to the node, which can be used to support the creation of any interaction, such as customer service, media sending, intelligence recognition based on phrases artificial and many other things.
daydreams
Daydreams is a generative agent library designed for playing onchain games by injecting context. It is chain agnostic and allows users to perform onchain tasks, including playing any onchain game. The tool is lightweight and powerful, enabling users to define game context, register actions, set goals, monitor progress, and integrate with external agents. Daydreams aims to be 'lite' and 'composable', dynamically generating code needed to play games. It is currently in pre-alpha stage, seeking feedback and collaboration for further development.
generative-ai-use-cases
Generative AI Use Cases (GenU) is an application that provides well-architected implementation with business use cases for utilizing generative AI in business operations. It offers a variety of standard use cases leveraging generative AI, such as chat interaction, text generation, summarization, meeting minutes generation, writing assistance, translation, web content extraction, image generation, video generation, video analysis, diagram generation, voice chat, RAG technique, custom agent creation, and custom use case building. Users can experience generative AI use cases, perform RAG technique, use custom agents, and create custom use cases using GenU.

katib
Katib is a Kubernetes-native project for automated machine learning (AutoML). Katib supports Hyperparameter Tuning, Early Stopping and Neural Architecture Search. Katib is the project which is agnostic to machine learning (ML) frameworks. It can tune hyperparameters of applications written in any language of the users’ choice and natively supports many ML frameworks, such as TensorFlow, Apache MXNet, PyTorch, XGBoost, and others. Katib can perform training jobs using any Kubernetes Custom Resources with out of the box support for Kubeflow Training Operator, Argo Workflows, Tekton Pipelines and many more.

babilong
BABILong is a generative benchmark designed to evaluate the performance of NLP models in processing long documents with distributed facts. It consists of 20 tasks that simulate interactions between characters and objects in various locations, requiring models to distinguish important information from irrelevant details. The tasks vary in complexity and reasoning aspects, with test samples potentially containing millions of tokens. The benchmark aims to challenge and assess the capabilities of Large Language Models (LLMs) in handling complex, long-context information.

Hands-On-Large-Language-Models
Hands-On Large Language Models is a repository containing code examples from the book 'The Illustrated LLM Book' by Jay Alammar and Maarten Grootendorst. The repository provides practical tools and concepts for using Large Language Models with over 250 custom-made figures. It covers topics such as language model introduction, tokens and embeddings, transformer LLMs, text classification, text clustering, prompt engineering, text generation techniques, semantic search, multimodal LLMs, text embedding models, fine-tuning representation models, and fine-tuning generation models. The examples are designed to be run on Google Colab with T4 GPU support, but can be adapted to other cloud platforms as well.
reasoning-from-scratch
This repository contains the code for developing a large language model (LLM) reasoning model. The book 'Build a Reasoning Model (From Scratch)' provides a hands-on approach to understanding and implementing reasoning capabilities in LLMs. It guides users through creating a small but functional reasoning model, mirroring approaches used in large-scale models like DeepSeek R1 and GPT-5 Thinking. The code includes methods for loading weights of pretrained models.

ludwig
Ludwig is a declarative deep learning framework designed for scale and efficiency. It is a low-code framework that allows users to build custom AI models like LLMs and other deep neural networks with ease. Ludwig offers features such as optimized scale and efficiency, expert level control, modularity, and extensibility. It is engineered for production with prebuilt Docker containers, support for running with Ray on Kubernetes, and the ability to export models to Torchscript and Triton. Ludwig is hosted by the Linux Foundation AI & Data.

WrenAI
WrenAI is a data assistant tool that helps users get results and insights faster by asking questions in natural language, without writing SQL. It leverages Large Language Models (LLM) with Retrieval-Augmented Generation (RAG) technology to enhance comprehension of internal data. Key benefits include fast onboarding, secure design, and open-source availability. WrenAI consists of three core services: Wren UI (intuitive user interface), Wren AI Service (processes queries using a vector database), and Wren Engine (platform backbone). It is currently in alpha version, with new releases planned biweekly.
fAIr
fAIr is an open AI-assisted mapping service developed by the Humanitarian OpenStreetMap Team (HOT) to improve mapping efficiency and accuracy for humanitarian purposes. It uses AI models, specifically computer vision techniques, to detect objects like buildings, roads, waterways, and trees from satellite and UAV imagery. The service allows OSM community members to create and train their own AI models for mapping in their region of interest and ensures models are relevant to local communities. Constant feedback loop with local communities helps eliminate model biases and improve model accuracy.
For similar tasks
rag-time
RAG Time is a 5-week AI learning series focusing on Retrieval-Augmented Generation (RAG) concepts. The repository contains code samples, step-by-step guides, and resources to help users master RAG. It aims to teach foundational and advanced RAG concepts, demonstrate real-world applications, and provide hands-on samples for practical implementation.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.